



|
|
クラスタ化された Oracle WebLogic Integration アプリケーションには、スケーラビリティと高可用性が備わります。高可用性デプロイメントには、ハードウェアやネットワークに障害が発生したときの回復処理が備えられており、障害発生時に制御をバックアップ コンポーネントに移行させることができます。
高可用性を備えた Oracle WebLogic Integration アプリケーションに関する推奨事項およびデータベース固有のコンフィグレーション要件の詳細については、「可用性の維持」を参照してください。
高可用性を提供するクラスタでは、サービス障害からの回復が可能です。Oracle WebLogic Server では、レプリケートされた HTTP セッション ステート、クラスタ化されたオブジェクト、およびクラスタ化環境のサーバに固定されたサービスのフェイルオーバがサポートされます。
Oracle WebLogic Server でフェイルオーバを処理する方法については、『クラスタの使用』の「クラスタでの通信」を参照してください。
高可用性を備えた Oracle WebLogic Integration 環境で使用できる基本コンポーネントは次のとおりです。
| 注意 : | さまざまなタイプの JDBC ドライバの可用性と各ドライバのパフォーマンスに関する考慮事項については、Oracle WebLogic Server Administration Console オンライン ヘルプの「JDBC データ ソースのコンフィグレーション」を参照してください。 |
クラスタ システムのネットワーク トポロジのプランニングについての詳細説明は、この節で扱う内容の範囲を越えています。Web アプリケーションで、ロード バランサ、ファイアウォール、Web サーバについて、1 つまたは複数の Oracle WebLogic Server クラスタを組織化することにより、ロード バランシングとフェイルオーバの機能をフルに活用する方法は、『クラスタの使用』の「クラスタ アーキテクチャ」を参照してください。
クラスタの簡単な表示、HTTP ロード バランサの表示、高可用性データベースとマルチポート ファイル システムについては次の図を参照してください。
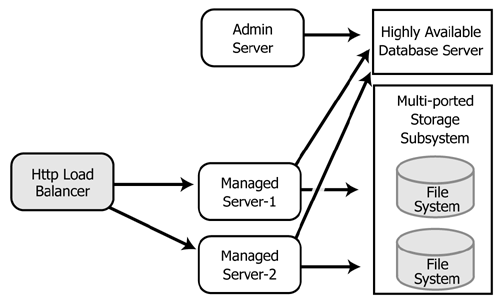
デフォルトの Oracle WebLogic Integration ドメインのコンフィグレーションでは、JMS サーバに JDBC ストアを使用します。上図の構成のとおり、高可用性のマルチポートのディスクを管理対象サーバ間で共有できる場合には、ファイル ストアを JMS の永続性のために使用することができます。通常、ファイル ストアは JDBC ストアよりも高性能です。
JMS ファイル ストアをコンフィグレーションする方法については、Oracle WebLogic Server Administration Console オンライン ヘルプを参照してください。
ソフトウェアまたはハードウェアの問題により、サーバに障害が発生することがあります。以下の節では、障害が起こったときに自動的に発生するプロセスと、手動で行わなければならない手順について説明します。
ソフトウェアの障害が発生すると、ノード マネージャは Oracle WebLogic Server を再起動します (再起動するようにコンフィグレーションされている場合)。ノード マネージャの詳細については、「ノード マネージャの概要」を参照してください。セキュア インストールの回復処理を準備する手順については、「サーバ障害の回避とサーバ障害からの回復」を参照してください。
ハードウェアの障害が発生すると、物理マシンの修理が必要になり、長期間使用できなくなることがあります。ハードウェアの障害時には、以下のイベントが発生します。
障害が長引いた場合は、オペレーション可能な別の管理対象サーバに移行することが必要になります。障害の発生したサーバを別の管理対象サーバに手動で移行する場合、以下の操作が必要です。
Oracle WebLogic Server の移行の詳細については、Oracle WebLogic Server ドキュメントの次のトピックを参照してください。
Oracle WebLogic Server の高可用性機能に加え、Oracle WebLogic Integration には、Oracle WebLogic Integration ソリューションの実装とコンフィグレーション単位での障害回復処理の機能があります。
Oracle WebLogic Integration の障害と回復処理の詳細については、『WebLogic Integration ソリューションのベスト プラクティスに関する FAQ』の「WebLogic Integration アプリケーションの回復処理」を参照してください。
RosettaNet と ebXML では、ビジネス プロトコルが異なるため、別々の方法で障害と回復処理を扱います。ただし、いずれのプロトコルも、指定された回数だけ wli.b2b.failedmessage.queue に再試行した後で、配信されなかったメッセージを送信します。エラーになったメッセージに追加の処理が必要な場合は、このキューにカスタム メッセージ リスナを実装できます。
RosettaNet メッセージで配信エラーになった場合、Oracle WebLogic Integration プロトコル レイヤはメッセージを再試行しません。代わりに、HttpStatus コードをワークフロー レイヤに戻します。RosettaNet ワークフローは、通常、再試行を処理するように設計されています。
Oracle WebLogic Integration Administration Console により、使用している PIP を基にさまざまなトレーディング パートナの再試行の間隔、再試行回数、およびプロセス タイムアウトなどを指定できます。たとえば、RosettaNet は通常、2 時間の間に 3 回再試行します。実際の PIP 通信が存続している場合に 24 時間でタイムアウトになります。これらの設定を変更する方法については、『WebLogic Integration Administration Console の使用』の「トレーディング パートナ管理」にある「バインディングの表示および変更」を参照してください。
Oracle WebLogic Integration のあるインスタンスから別のインスタンスにメッセージが送信され、送り先のインスタンスに障害が発生している場合、サーバ コンソールに 1 つまたは複数のエラー メッセージが表示され、その後にスタック トレースが表示される場合があります。
ebXML メッセージの再試行は、Oracle WebLogic Integration Administration Console、トレーディング パートナ管理の Bulk Loader、またはサード パーティのトレーディング パートナ管理メッセージ Bean を使用して指定できます。ebXML 配信セマンティクスを OnceAndOnlyOnce または AtLeastOnce に設定した場合、メッセージは、再試行回数と再試行間隔で指定した値に従って再試行されます。Oracle WebLogic Integration Administration Console を使用して ebXML メッセージの再試行を設定する方法については、『WebLogic Integration Administration Console の使用』の「トレーディング パートナ管理」にある「プロトコル バインディングの定義」を参照してください。
ebXML プロセスの場合、アクション モードの値をデフォルト以外に設定すると、回復処理と高可用性を確保できます。アクション モードの設定方法については、『Trading Partner Integration の紹介』の「ebXML ソリューションの紹介」にある「ebXML ビジネス プロセス」を参照してください。
 
|