| Oracle Rdb SQLƒٹƒtƒ@ƒŒƒ“ƒXپEƒ}ƒjƒ…ƒAƒ‹ ƒٹƒٹپ[ƒX7.2 E06178-01 |
|


 –ك‚é |
 ژں‚ض |
چsƒLƒƒƒbƒVƒ…“à‚جچs‚جچإ‘ه’·‚ح65535ƒoƒCƒg‚إ‚·پB
ƒLƒƒƒbƒVƒ…‚ج–¼‘O‚ئٹù‘¶‚جک_——جˆو‚ج–¼‘O‚ھˆê’v‚·‚éڈêچ‡پAADD CACHE‚إ‚حپA•\‚جچs‚جƒTƒCƒY‚ـ‚½‚حپiSORTED RANKEDچُˆّ‚ـ‚½‚حUNIQUE SORTEDچُˆّ—p‚جپjچُˆّƒmپ[ƒh‚جƒTƒCƒY‚ةٹî‚أ‚¢‚ؤROW LENGTH‚ھŒvژZ‚³‚ê‚ـ‚·پB‚±‚جƒLƒƒƒbƒVƒ…‚حپAک_——جˆوƒLƒƒƒbƒVƒ…‚ئŒؤ‚خ‚ê‚ـ‚·پB
ƒfƒtƒHƒ‹ƒg‚حENABLED‚إ‚·پB
ƒfƒtƒHƒ‹ƒg‚إ‚حپAگV‹K‚جƒLƒƒƒbƒVƒ…‚ة‘خ‚µ‚ؤ‚àٹù‘¶‚جƒLƒƒƒbƒVƒ…‚ة‘خ‚µ‚ؤ‚àپA‚±‚ج‹@”\‚ح–³Œّ‚إ‚·پB
ROW SNAPSHOT IS ENABLEDƒIƒvƒVƒ‡ƒ“‚ةCACHE SIZE‹ه‚ًژw’肵‚ب‚¢ڈêچ‡‚حپAƒXƒiƒbƒvƒVƒ‡ƒbƒgچs‚ً1000چs‚ـ‚إٹـ‚ق‚±‚ئ‚ھ‚إ‚«‚éƒLƒƒƒbƒVƒ…‚ھچىگ¬‚³‚ê‚ـ‚·پB
ƒvƒچƒZƒX—جˆو‚ةچىگ¬‚³‚ꂽƒLƒƒƒbƒVƒ…پEƒOƒچپ[ƒoƒ‹پEƒZƒNƒVƒ‡ƒ“‚ًژg—p‚·‚éڈêچ‡‚حپA•،گ”‚جƒ†پ[ƒUپ[‚إ•¨—ƒپƒ‚ƒٹپ[‚ً‹¤—L‚µ‚ـ‚·پB‚ـ‚½پAOpenVMS AlphaƒIƒyƒŒپ[ƒeƒBƒ“ƒOپEƒVƒXƒeƒ€‚ة‚و‚èپAچsƒLƒƒƒbƒVƒ…‚ھٹeƒ†پ[ƒUپ[‚جƒvƒ‰ƒCƒxپ[ƒgپEƒAƒhƒŒƒX‹َٹش‚ةƒ}ƒbƒv‚³‚ê‚ـ‚·پB‚±‚جŒ‹‰تپA‚·‚ׂؤ‚جƒ†پ[ƒUپ[‚ح‹َ‚«‚ج‚ ‚鉼‘zƒAƒhƒŒƒX”حˆح‚ةگ§Œہ‚³‚êپA‚»‚ꂼ‚ê‚ھƒIپ[ƒoپ[ƒwƒbƒh‚ة‰‚¶‚½ˆê’è‚جٹ„چ‡‚إƒپƒ‚ƒٹپ[‚ًژg—p‚·‚邱‚ئ‚ة‚ب‚è‚ـ‚·پB‘½گ”‚جƒ†پ[ƒUپ[‚ھƒfپ[ƒ^ƒxپ[ƒX‚ةƒAƒNƒZƒX‚µ‚½ڈêچ‡پAƒIپ[ƒoپ[ƒwƒbƒh‚ح‘ه‚«‚‚ب‚è‚ـ‚·پB
‘½گ”‚جƒ†پ[ƒUپ[‚ھƒfپ[ƒ^ƒxپ[ƒX‚ةƒAƒNƒZƒX‚·‚éڈêچ‡‚حپASHARED MEMORY IS SYSTEM‹ه‚جژg—p‚ًŒں“¢‚µ‚ـ‚·پB‚±‚ê‚ًژg—p‚·‚é‚ئپAƒ†پ[ƒUپ[‚حƒپƒ‚ƒٹپ[‚جƒVƒXƒeƒ€—جˆو‚ً‹¤—L‚·‚邱‚ئ‚ة‚ب‚èپAƒپƒ‚ƒٹپ[‚جƒvƒچƒZƒX—جˆو‚ةٹضکA‚·‚éƒIپ[ƒoپ[ƒwƒbƒh‚ح”گ¶‚µ‚ب‚¢‚½‚كپAƒ†پ[ƒUپ[‚ح‚و‚葽‚‚ج•¨—ƒپƒ‚ƒٹپ[‚ًژg—p‚إ‚«‚é‚و‚¤‚ة‚ب‚è‚ـ‚·پB
- چsƒLƒƒƒbƒVƒ…‚ج–¼‘O‚ھ‚¢‚¸‚ê‚©‚جک_——جˆو‚ج–¼‘Oپi•\–¼پAچُˆّ–¼پARDB$SEGMENTED_STRINGSپARDB$SYSTEM_RECORD‚ب‚اپj‚ئ“¯‚¶‚إ‚ ‚éڈêچ‡پA‚»‚جچsƒLƒƒƒbƒVƒ…‚حک_——جˆوƒLƒƒƒbƒVƒ…‚إ‚ ‚èپA“¯‚¶–¼‘O‚ًژ‚آک_——جˆو‚ھژ©“®“I‚ةƒLƒƒƒbƒVƒ…‚³‚ê‚ـ‚·پB‚»‚¤‚إ‚ب‚¢ڈêچ‡‚حپA‚»‚جƒLƒƒƒbƒVƒ…‚ة‚¢‚¸‚ê‚©‚ج‹L‰¯ˆو‚ًٹضکA•t‚¯‚é•K—v‚ھ‚ ‚è‚ـ‚·پB
- ADD CACHE‹ه‚¨‚و‚رCREATE CACHE‹ه‚ج‚ا‚؟‚ç‚ًژg—p‚µ‚ؤ‚àپAچsƒLƒƒƒbƒVƒ…‚ح‹L‰¯ˆو‚ةٹ„‚è“–‚ؤ‚ç‚ê‚ـ‚¹‚ٌپBCACHE USING‹ه‚ًCREATE DATABASE•¶‚جCREATE STORAGE AREA‹هپA‚ـ‚½‚حALTER DATABASE•¶‚جADD STORAGE AREA‹ه‚ـ‚½‚حALTER STORAGE AREA‹ه‚ئ•¹—p‚·‚é•K—v‚ھ‚ ‚è‚ـ‚·پB
- CACHE SIZE‚¨‚و‚رROW LENGTH‚جگف’è‚ج“à—e‚ة‰‚¶‚ؤپAچsƒLƒƒƒbƒVƒ…‚ة•K—v‚بƒپƒ‚ƒٹپ[‚ج—ت‚ھŒˆ’肳‚ê‚ـ‚·پi’ا‰ء‚جƒIپ[ƒoپ[ƒwƒbƒh‚¨‚و‚رƒyپ[ƒW‹«ٹE‚ض‚ج’[گ”‚جگطڈم‚°ڈˆ—‚حپAƒfپ[ƒ^ƒxپ[ƒXپEƒVƒXƒeƒ€‚إژہچs‚³‚ê‚ـ‚·پjپB
- چsƒLƒƒƒbƒVƒ…‚حپA‚¢‚¸‚ê‚©1‚آ‚جƒmپ[ƒhڈم‚جƒfپ[ƒ^ƒxپ[ƒX‚ةƒAƒ^ƒbƒ`‚·‚é‚·‚ׂؤ‚جƒvƒچƒZƒX‚ة‚و‚ء‚ؤ‹¤—L‚³‚ê‚ـ‚·پB
- چsƒLƒƒƒbƒVƒ…‹@”\‚ًژg—p‚·‚éڈêچ‡‚ج—vŒڈ‚ًژں‚ةژ¦‚µ‚ـ‚·پB
- ƒAƒtƒ^پ[پEƒCƒپپ[ƒWپEƒWƒƒپ[ƒiƒ‹‚ھ—LŒّ‚ة‚ب‚ء‚ؤ‚¢‚邱‚ئپB
- چ‚‘¬ƒRƒ~ƒbƒg‚ھ—LŒّ‚ة‚ب‚ء‚ؤ‚¢‚邱‚ئپB
- ƒNƒ‰ƒXƒ^پEƒmپ[ƒh‚جگ”‚ھ1‚إ‚ ‚邱‚ئپA‚ـ‚½‚حƒVƒXƒeƒ€‚إOpenVMS Galaxyچ\گ¬‚ھژہچs‚³‚ê‚ؤ‚¨‚èپANUMBER OF CLUSTER NODE ... (SINGLE INSTANCE)‚ھ—LŒّ‚ة‚ب‚ء‚ؤ‚¢‚邱‚ئپB
- SHOW CACHE•¶‚ًژg—p‚µ‚ؤƒLƒƒƒbƒVƒ…‚ةٹض‚·‚éڈî•ٌ‚ً•\ژ¦‚µ‚ـ‚·پB
- ƒfپ[ƒ^ƒxپ[ƒX“à‚ة’è‹`‚³‚ꂽٹeچsƒLƒƒƒbƒVƒ…‚ًژw’è‚·‚é‚ئپAژw’肵‚½گ”‚جƒXƒiƒbƒvƒVƒ‡ƒbƒgچs‚ًƒLƒƒƒbƒVƒ…‚ةٹi”[‚إ‚«‚ـ‚·پBٹi”[‚إ‚«‚éƒXƒiƒbƒvƒVƒ‡ƒbƒgچs‚جگ”‚حپAƒLƒƒƒbƒVƒ…‚ةٹi”[‚إ‚«‚錻چف—LŒّ‚بƒfپ[ƒ^ƒxپ[ƒXچs‚جگ”‚ة‰ء‚¦‚ؤژw’肵‚ـ‚·پBƒLƒƒƒbƒVƒ…‚جƒXƒiƒbƒvƒVƒ‡ƒbƒg•”•ھ‚ة‚حپA“¯‚¶چs‚ة‘خ‚·‚鑽گ”‚جƒoپ[ƒWƒ‡ƒ“‚ًٹi”[‚إ‚«‚邽‚كپAƒXƒiƒbƒvƒVƒ‡ƒbƒgچs‚جگ”‚ئŒ»چف—LŒّ‚بƒLƒƒƒbƒVƒ…چs‚جگ”‚حŒآ•ت‚ةژw’肵‚ـ‚·پBچsƒLƒƒƒbƒVƒ…‚جƒXƒiƒbƒvƒVƒ‡ƒbƒg•”•ھ‚حپAژہژ؟“I‚ة‚حچsƒLƒƒƒbƒVƒ…ژ©‘ج‚ًٹg’£‚µ‚½‚à‚ج‚إ‚ ‚邽‚كپAƒLƒƒƒbƒVƒ…‚ج‚»‚ج‘¼‚ج‘®گ«‚حƒXƒiƒbƒvƒVƒ‡ƒbƒg•”•ھ‚ئ‹¤—L‚³‚ê‚ـ‚·پB
- چsƒLƒƒƒbƒVƒ…‚جƒXƒiƒbƒvƒVƒ‡ƒbƒg•”•ھ‚حپAŒ»چف—LŒّ‚ب•”•ھ‚و‚è‘ه‚«‚‚·‚éپiٹi”[‚إ‚«‚éچs‚جگ”‚ً‘½‚‚·‚éپj‚±‚ئ‚àڈ¬‚³‚‚·‚éپiٹi”[‚إ‚«‚éچs‚جگ”‚ًڈ‚ب‚‚·‚éپj‚±‚ئ‚à‚إ‚«‚ـ‚·پB•دچX‚إ‚«‚éƒfپ[ƒ^ƒxپ[ƒXچs‚جگ”‚¨‚و‚ر‚»‚ê‚ةٹضکA‚·‚éƒgƒ‰ƒ“ƒUƒNƒVƒ‡ƒ“’·‚حƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“‚ج“®چى‚âƒڈپ[ƒNƒچپ[ƒh‚جڈَ‹µ‚ة‚و‚ء‚ؤŒˆ‚ـ‚邽‚كپA‚·‚ׂؤ‚جƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“‚¨‚و‚رƒfپ[ƒ^ƒxپ[ƒXŒ^‚جƒLƒƒƒbƒVƒ…‚جƒXƒiƒbƒvƒVƒ‡ƒbƒg•”•ھ‚جƒTƒCƒY‚ة‚آ‚¢‚ؤ“ء’è‚جگ„ڈ§ژ–چ€‚ًگف’è‚·‚é‚ج‚ح“Kگط‚إ‚ح‚ ‚è‚ـ‚¹‚ٌپB‚½‚¾‚µپAƒپƒCƒ“پEƒLƒƒƒbƒVƒ…‚جƒXƒiƒbƒvƒVƒ‡ƒbƒgپEƒLƒƒƒbƒVƒ…‚جƒTƒCƒY‚جٹ„چ‡‚حپAŒ»چف—LŒّ‚ب‹L‰¯ˆو‚جƒfپ[ƒ^ƒxپ[ƒXپEƒXƒiƒbƒvƒVƒ‡ƒbƒg‚ج‹L‰¯ˆو‚جٹ„چ‡‚ئ“¯—l‚إ‚ ‚é‚ئ‘z’肳‚ê‚ـ‚·پBƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“‚ةپA’·ژٹشژہچs‚³‚ê‚éƒgƒ‰ƒ“ƒUƒNƒVƒ‡ƒ“‚¨‚و‚رƒLƒƒƒbƒVƒ…‚³‚ꂽƒfپ[ƒ^‚ً•دچX‚·‚éƒAƒNƒeƒBƒu‚ب“اژو‚è/ڈ‘چ‚فƒgƒ‰ƒ“ƒUƒNƒVƒ‡ƒ“‚ھ‚ ‚éڈêچ‡پA•دچX‚³‚ꂽ‘½گ”‚جƒfپ[ƒ^‚جƒXƒiƒbƒvƒVƒ‡ƒbƒgپEƒRƒsپ[‚ج•غژ‚ھ•K—v‚بڈêچ‡‚ھ‚ ‚è‚ـ‚·پB‚±‚ê‚ة‚و‚èپA‘ه—e—ت‚جچXگVƒAƒNƒeƒBƒrƒeƒB‚ً”؛‚¤‚±‚ê‚ç‚جƒLƒƒƒbƒVƒ…‚إ‚حپA‘½گ”‚جƒXƒiƒbƒvƒVƒ‡ƒbƒgچs‚جƒLƒƒƒbƒVƒ…‚ھ•K—v‚بڈêچ‡‚ھ‚ ‚è‚ـ‚·پB
- SHARED MEMORY IS PROCESS RESIDENT‚ـ‚½‚حLARGE MEMORY‚ً—LŒّ‰»‚ـ‚½‚ح–³Œّ‰»‚·‚é‚ة‚حپAƒRƒ}ƒ“ƒh‚ًژہچs‚·‚éƒvƒچƒZƒX‚ةپAVMS$MEM_RESIDENT_USERŒ —کژ¯•تژq‚ھ•t—^‚³‚ê‚ؤ‚¢‚é•K—v‚ھ‚ ‚è‚ـ‚·پB‚±‚ج‹@”\‚ً—LŒّ‚ة‚µ‚½ڈêچ‡‚حپAƒfپ[ƒ^ƒxپ[ƒX‚ًƒIپ[ƒvƒ“‚·‚邽‚ك‚جƒvƒچƒZƒX‚ة‚àVMS$MEM_RESIDENT_USERژ¯•تژq‚ھ•t—^‚³‚ê‚é•K—v‚ھ‚ ‚è‚ـ‚·پB‚±‚ج‹@”\‚ج—ک—pژ‚ة‚حRMU/OPENƒRƒ}ƒ“ƒh‚جژg—p‚ً‚¨‘E‚ك‚µ‚ـ‚·پB
—ل1: چsƒLƒƒƒbƒVƒ…‚جچىگ¬ژں‚ج—ل‚إ‚حپAƒfپ[ƒ^ƒxپ[ƒX‚ًچىگ¬‚µپAچsƒLƒƒƒbƒVƒ…‚ًچىگ¬‚µ‚ؤپA‚»‚جچsƒLƒƒƒbƒVƒ…‚ً‹L‰¯ˆو‚ةٹ„‚è“–‚ؤ‚ـ‚·پB
SQL> CREATE DATABASE FILENAME test_db cont> ROW CACHE IS ENABLED cont> CREATE CACHE test1 cont> CACHE SIZE IS 100 ROWS cont> CREATE STORAGE AREA area1 cont> CACHE USING test1; SQL> SHOW CACHE Cache Objects in database with filename test_db TEST1 SQL> SHOW CACHE test1 TEST1 Cache Size: 100 rows Row Length: 256 bytes Row Replacement: Enabled Shared Memory: Process Large Memory: Disabled Window Count: 100 Reserved Rows: 20 Sweep Rows: 3000 No Sweep Thresholds Allocation: 100 blocks Extent: 100 blocks SQL> SHOW STORAGE AREA area1 AREA1 Access is: Read write Page Format: Uniform Page Size: 2 blocks Area File: SQL_USER1:[DAY.V70]AREA1.RDA;1 Area Allocation: 402 pages Area Extent Minimum: 99 pages Area Extent Maximum: 9999 pages Area Extent Percent: 20 percent Snapshot File: SQL_USER1:[DAY.V70]AREA1.SNP;1 Snapshot Allocation: 100 pages Snapshot Extent Minimum: 99 pages Snapshot Extent Maximum: 9999 pages Snapshot Extent Percent: 20 percent Extent : Enabled Locking is Row Level Using Cache TEST1 No database objects use Storage Area AREA1
—ل2: —lپX‚بƒLƒƒƒbƒVƒ…‚جچىگ¬‚¨‚و‚ر•دچX
- CUSTOMER_STATUS‚ئ‚¢‚¤–¼‘O‚إچىگ¬‚³‚ê‚éƒLƒƒƒbƒVƒ…‚إ‚حپAچs‚ج’·‚³‚ھ577ƒoƒCƒgپAŒ»چف—LŒّ‚بƒfپ[ƒ^ƒxپ[ƒXچs‚جٹi”[‚ةژg—p‚·‚éƒLƒƒƒbƒVƒ…پEƒXƒچƒbƒg‚جگ”‚ھ88000پAچs‚جƒXƒiƒbƒvƒVƒ‡ƒbƒgپEƒRƒsپ[‚جٹi”[‚ةژg—p‚·‚éƒXƒچƒbƒg‚جگ”‚ھ7000‚ةگف’肳‚ê‚ؤ‚¢‚ـ‚·پB‚ـ‚½پA‚±‚جƒLƒƒƒbƒVƒ…‚حƒپƒ‚ƒٹپ[ڈي’“Œ^‚ئ‚µ‚ؤچ\گ¬‚³‚ê‚ؤ‚¢‚ـ‚·پB
- MACHINE_FLOW_IDX_1‚ئ‚¢‚¤–¼‘O‚إچىگ¬‚³‚ê‚éƒLƒƒƒbƒVƒ…‚إ‚حپAچs‚ج’·‚³‚ھ430ƒoƒCƒgپAŒ»چف—LŒّ‚بƒfپ[ƒ^ƒxپ[ƒXچs‚جٹi”[‚ةژg—p‚·‚éƒLƒƒƒbƒVƒ…پEƒXƒچƒbƒg‚جگ”‚ھ5000پAچs‚جƒXƒiƒbƒvƒVƒ‡ƒbƒgپEƒRƒsپ[‚جٹi”[‚ةژg—p‚·‚éƒXƒچƒbƒg‚جگ”‚ھ12000‚ةگف’肳‚ê‚ؤ‚¢‚ـ‚·پB‚±‚جƒLƒƒƒbƒVƒ…‚ة‘خ‚µ‚ؤ‚حپAƒLƒƒƒbƒVƒ…“à‚جچs‚ج’uٹ·‚ح–³Œّ‚ةگف’肳‚ê‚ـ‚·پB
- SALES_CALLS‚ئ‚¢‚¤–¼‘O‚إچىگ¬‚³‚ê‚éƒLƒƒƒbƒVƒ…‚إ‚حپAچs‚ج’·‚³‚ھ160ƒoƒCƒgپAŒ»چف—LŒّ‚بƒfپ[ƒ^ƒxپ[ƒXچs‚جٹi”[‚ةژg—p‚·‚éƒLƒƒƒbƒVƒ…پEƒXƒچƒbƒg‚جگ”‚ھ3000‚ةگف’肳‚ê‚ؤ‚¢‚ـ‚·پBچs‚جƒXƒiƒbƒvƒVƒ‡ƒbƒgپEƒRƒsپ[‚جٹi”[‚ةژg—p‚·‚éƒXƒچƒbƒg‚جگ”‚حپA–¾ژ¦“I‚ةژw’肳‚ê‚ؤ‚¢‚ب‚¢‚½‚كپAƒfƒtƒHƒ‹ƒg‚ج1000‚ةگف’肳‚ê‚ـ‚·پB
- CUSTOMER_ORDER‚ئ‚¢‚¤–¼‘O‚جƒLƒƒƒbƒVƒ…‚ة‚حROW SNAPSHOT IS ENABLED‚ھژw’肳‚ê‚ؤ‚¢‚ـ‚¹‚ٌپB‚»‚ج‚½‚كپA‚±‚جƒLƒƒƒbƒVƒ…‚ة‚حچs‚جƒXƒiƒbƒvƒVƒ‡ƒbƒgپEƒRƒsپ[‚حٹi”[‚³‚ê‚ـ‚¹‚ٌپB
- SALES‚ئ‚¢‚¤–¼‘O‚جƒLƒƒƒbƒVƒ…‚حپAƒLƒƒƒbƒVƒ…“à‚جƒXƒiƒbƒvƒVƒ‡ƒbƒgچs‚جٹi”[‚ھ–³Œّ‚ة‚ب‚é‚و‚¤‚ة•دچX‚³‚ê‚ؤ‚¢‚ـ‚·پB
- CLEARING‚ئ‚¢‚¤–¼‘O‚جƒLƒƒƒbƒVƒ…‚حپAƒLƒƒƒbƒVƒ…“à‚جƒXƒiƒbƒvƒVƒ‡ƒbƒgچs‚جٹi”[‚ھ—LŒّ‚ة‚ب‚é‚و‚¤‚ة•دچX‚³‚ê‚ؤ‚¨‚èپAƒXƒiƒbƒvƒVƒ‡ƒbƒgپEƒLƒƒƒbƒVƒ…‚جƒTƒCƒY‚ھ12,345چs‚ةگف’肳‚ê‚ؤ‚¢‚ـ‚·پB
SQL> ALTER DATABASE FILENAME HDB_DB (1) ADD CACHE CUSTOMER_STATUS ROW LENGTH IS 577 BYTES CACHE SIZE IS 88000 ROWS ROW SNAPSHOT IS ENABLED (CACHE SIZE IS 7000 ROWS) SHARED MEMORY IS PROCESS RESIDENT (2) ADD CACHE MACHINE_FLOW_IDX_1 ROW LENGTH IS 430 BYTES CACHE SIZE IS 5000 ROWS ROW REPLACEMENT IS DISABLED ROW SNAPSHOT IS ENABLED (CACHE SIZE IS 12000 ROWS) (3) ADD CACHE SALES_CALLS ROW LENGTH IS 160 BYTES CACHE SIZE IS 3000 ROWS ROW SNAPSHOT IS ENABLED (4) ADD CACHE CUSTOMER_ORDER ROW LENGTH IS 760 BYTES CACHE SIZE IS 9000 ROWS CHECKPOINT UPDATED ROWS TO DATABASE (5) ALTER CACHE SALES ROW SNAPSHOT IS DISABLED (6) ALTER CACHE CLEARING ROW SNAPSHOT IS ENABLED (CACHE SIZE IS 12345 ROWS); SQL> SHOW CACHE CUSTOMER_STATUS CUSTOMER_STATUS Cache Size: 88000 rows Row Length: 580 bytes Row Replacement: Enabled Shared Memory: Process Resident Large Memory: Disabled Window Count: 100 Working Set Count: 10 Reserved Rows: 20 Allocation: 100 blocks Extent: 100 blocks Snapshot in Cache: Enabled Snapshot Cache Size: 7000 rows SQL> SHOW CACHE MACHINE_FLOW_IDX_1 MACHINE_FLOW_IDX_1 Cache Size: 5000 rows Row Length: 432 bytes Row Replacement: Disabled Shared Memory: Process Large Memory: Disabled Window Count: 100 Working Set Count: 10 Reserved Rows: 20 Allocation: 100 blocks Extent: 100 blocks Snapshot in Cache: Enabled Snapshot Cache Size: 12000 rows SQL> SHOW CACHE SALES_CALLS SALES_CALLS Cache Size: 3000 rows Row Length: 160 bytes Row Replacement: Enabled Shared Memory: Process Large Memory: Disabled Window Count: 100 Working Set Count: 10 Reserved Rows: 20 Allocation: 100 blocks Extent: 100 blocks Snapshot in Cache: Enabled Snapshot Cache Size: 1000 rows SQL> SHOW CACHE CUSTOMER_ORDER CUSTOMER_ORDER Cache Size: 9000 rows Row Length: 760 bytes Row Replacement: Enabled Shared Memory: Process Large Memory: Disabled Window Count: 100 Working Set Count: 10 Reserved Rows: 20 Allocation: 100 blocks Extent: 100 blocks Row cache: checkpoint updated rows to database
ƒ}ƒ‹ƒ`ƒXƒLپ[ƒ}پEƒfپ[ƒ^ƒxپ[ƒX“à‚جƒXƒLپ[ƒ}‚جƒOƒ‹پ[ƒv‚ج–¼‘O‚ًچىگ¬‚µ‚ـ‚·پB
CREATE CATALOG•¶‚حژں‚جٹآ‹«‚إژg—p‚إ‚«‚ـ‚·پB
- ‘خکbŒ^SQL“à
- ƒvƒٹƒRƒ“ƒpƒCƒ‹‘خڈغ‚جƒzƒXƒgŒ¾ŒêƒvƒچƒOƒ‰ƒ€‚ة–„‚كچ‚ـ‚ê‚éڈêچ‡
- SQLƒ‚ƒWƒ…پ[ƒ‹‚جƒvƒچƒVپ[ƒWƒƒ‚جˆê•”‚ئ‚µ‚ؤ
- “®“ISQL‚إ“®“I‚ةژہچs‚³‚ê‚镶‚ئ‚µ‚ؤ



"alias.name-of-catalog"
ƒfپ[ƒ^ƒxپ[ƒX‚ةƒAƒ^ƒbƒ`‚·‚éƒIƒvƒVƒ‡ƒ“‚ج–¼‘O‚ًژw’肵‚ـ‚·پBƒvƒچƒOƒ‰ƒ€‚ـ‚½‚ح‘خکbŒ^SQL•¶‚إ•،گ”‚جƒfپ[ƒ^ƒxپ[ƒX‚ًژQڈئ‚µ‚ؤ‚¢‚éڈêچ‡‚حپAڈي‚ةƒJƒ^ƒچƒO–¼‚ً•ت–¼‚إڈCڈü‚µ‚ـ‚·پBƒJƒ^ƒچƒO–¼‚ئ‚»‚ج•ت–¼‚حƒsƒٹƒIƒh‚إ‹وگط‚èپAڈCڈü‚µ‚½–¼‘O‚ح“ٌڈdˆّ—p•„‚إˆح‚ف‚ـ‚·پBcatalog-name
چىگ¬‚·‚éƒJƒ^ƒچƒO’è‹`‚ج–¼‘O‚إ‚·پB–¼‘O‚ة‚حپAƒfپ[ƒ^ƒxپ[ƒX“à‚ج‚·‚ׂؤ‚جƒJƒ^ƒچƒO–¼‚إˆêˆس‚ئ‚ب‚é—LŒّ‚بSQL–¼‚ًژg—p‚µ‚ـ‚·پBƒJƒ^ƒچƒO–¼‚جڈعچׂحپA‘و2.2.3چ€‚ًژQڈئ‚µ‚ؤ‚‚¾‚³‚¢پBcreate-schema-statement
ڈعچׂحپAپuCREATE SCHEMA•¶پv‚ًژQڈئ‚µ‚ؤ‚‚¾‚³‚¢پBschema-element
CREATE•¶‚ـ‚½‚حGRANT•¶‚ً1‚آˆبڈمژw’肵‚ـ‚·پBڈعچׂحپAپuCREATE SCHEMA•¶پv‚ًژQڈئ‚µ‚ؤ‚‚¾‚³‚¢پB
- ƒJƒ^ƒچƒO‚حپAƒ}ƒ‹ƒ`ƒXƒLپ[ƒ}‘®گ«‚ًژ‚آƒfپ[ƒ^ƒxپ[ƒX“à‚إ‚ج‚فچىگ¬‚إ‚«‚ـ‚·پBƒfپ[ƒ^ƒxپ[ƒX‚ةƒ}ƒ‹ƒ`ƒXƒLپ[ƒ}‘®گ«‚ًگف’è‚·‚éڈêچ‡‚حپACREATE DATABASE•¶‚ـ‚½‚حALTER DATABASE•¶‚ةMULTISCHEMA IS ON‹ه‚ًژg—p‚µ‚ـ‚·پB
- ƒ}ƒ‹ƒ`ƒXƒLپ[ƒ}‘®گ«‚ًژ‚آƒfپ[ƒ^ƒxپ[ƒX‚إ‚àپAƒ}ƒ‹ƒ`ƒXƒLپ[ƒ}پEƒlپ[ƒ~ƒ“ƒO‚ھ–³Œّ‚ة‚ب‚ء‚ؤ‚¢‚éڈêچ‡‚حپAƒJƒ^ƒچƒO‚ًچىگ¬‚إ‚«‚ـ‚¹‚ٌپBƒ}ƒ‹ƒ`ƒXƒLپ[ƒ}‘®گ«‚ًژ‚آƒfپ[ƒ^ƒxپ[ƒX‚إ‚حپAƒ}ƒ‹ƒ`ƒXƒLپ[ƒ}پEƒlپ[ƒ~ƒ“ƒO‚حƒfƒtƒHƒ‹ƒg‚إ—LŒّ‚ة‚ب‚ء‚ؤ‚¢‚ـ‚·‚ھپADECLARE ALIAS•¶‚ـ‚½‚حATTACH•¶‚جMULTISCHEMA IS OFF‹ه‚ًژg—p‚µ‚ؤ–³Œّ‚ة‚إ‚«‚ـ‚·پB
- •ت–¼‚ًژg—p‚µ‚ؤƒfپ[ƒ^ƒxپ[ƒX‚ةƒAƒ^ƒbƒ`‚µ‚½ڈêچ‡پA‚»‚جƒfپ[ƒ^ƒxپ[ƒX“à‚ج—v‘f‚ًŒم‘±‚ج•¶‚ةژw’è‚·‚é‚ة‚حپA“¯‚¶•ت–¼‚ًژg—p‚·‚é•K—v‚ھ‚ ‚è‚ـ‚·پBƒJƒ^ƒچƒO–¼‚ً•ت–¼‚إڈCڈü‚µ‚½ڈêچ‡‚حپA•ت–¼‚ئƒJƒ^ƒچƒO–¼‚حƒsƒٹƒIƒh‚إ‹وگط‚èپA‚»‚ج–¼‘O‚جƒyƒA‚ً“ٌڈdˆّ—p•„‚إˆح‚ق•K—v‚ھ‚ ‚è‚ـ‚·پB
ڈCڈü‚µ‚½ƒJƒ^ƒچƒO–¼‚ًژg—p‚µ‚½•¶‚ً”چs‚·‚éڈêچ‡‚حپA‚»‚ج‘O‚ةSET QUOTING RULES•¶‚ً”چs‚µپAƒvƒچƒOƒ‰ƒ€‚ة–„‚كچ‚ـ‚ꂽDECLARE MODULE•¶‚ةQUOTING RULES‹ه‚ًژw’è‚·‚é‚©پA‚ـ‚½‚حSQLƒ‚ƒWƒ…پ[ƒ‹پEƒtƒ@ƒCƒ‹‚ةQUOTING RULES‹ه‚ًژw’è‚·‚é•K—v‚ھ‚ ‚è‚ـ‚·پB- ANSI/ISO SQL‹Kٹi‚جƒtƒ‰ƒKپ[‚ًƒIƒ“‚ةگف’肵‚½ڈêچ‡پACREATE CATALOG•¶‚ح”ٌ•Wڈ€چ\•¶‚ئ‚µ‚ؤƒtƒ‰ƒO‚ھ•t‚¯‚ç‚ê‚ـ‚·پB
- ƒfƒtƒHƒ‹ƒg‚جƒJƒ^ƒچƒO‚ً•دچX‚µ‚ب‚¢ڈêچ‡پASQL‚ة‚و‚èƒXƒLپ[ƒ}‚¨‚و‚رƒXƒLپ[ƒ}—v‘f‚ھRDB$CATALOG‚ةٹi”[‚³‚ê‚ـ‚·پB
- CREATE CATALOG‚ًژg—p‚µ‚ؤچىگ¬‚³‚ꂽƒJƒ^ƒچƒO‚ج–¼‘O‚ھپA•¶‘S‘ج‚ة‚¨‚¯‚éƒfƒtƒHƒ‹ƒg‚جƒJƒ^ƒچƒO‚إ‚·پB
—ل1: •ت–¼‚ًژg—p‚µ‚½ƒfپ[ƒ^ƒxپ[ƒX‚جƒJƒ^ƒچƒO‚جچىگ¬ژں‚ج—ل‚إ‚حپA‘خکbŒ^ƒ†پ[ƒUپ[‚ھpersonnel‚ئ‚¢‚¤ƒTƒ“ƒvƒ‹پEƒfپ[ƒ^ƒxپ[ƒX‚ةƒAƒ^ƒbƒ`‚µپA‚»‚جƒfپ[ƒ^ƒxپ[ƒX“à‚ةƒJƒ^ƒچƒO‚ًچىگ¬‚·‚é•û–@‚ًژ¦‚µ‚ـ‚·پBپi‚±‚ج—ل‚إ‚حپAƒ}ƒ‹ƒ`ƒXƒLپ[ƒ}‘®گ«‚ًژg—p‚µ‚ؤچىگ¬‚³‚ꂽƒTƒ“ƒvƒ‹پEƒfپ[ƒ^ƒxپ[ƒXpersonnel‚ًژg—p‚·‚é•K—v‚ھ‚ ‚è‚ـ‚·پBپjƒ†پ[ƒUپ[‚ح•ت–¼‚ًژg—p‚·‚邱‚ئ‚ة‚و‚èپApersonnelƒfپ[ƒ^ƒxپ[ƒX‚ئپAŒم‚إ“¯‚¶ƒZƒbƒVƒ‡ƒ““à‚إƒAƒ^ƒbƒ`‚·‚é‰آ”\گ«‚ھ‚ ‚鑼‚جƒfپ[ƒ^ƒxپ[ƒX‚ً‹و•ت‚µ‚ـ‚·پB
SQL> ATTACH 'ALIAS CORPORATE FILENAME personnel - cont> MULTISCHEMA IS ON'; SQL> -- SQL> -- SQL creates a default catalog called RDB$CATALOG in SQL> -- each multischema database. SQL> -- SQL> SHOW CATALOG; Catalogs in database personnel "CORPORATE.RDB$CATALOG" SQL> -- SQL> -- The SET QUOTING RULES 'SQL99' statement allows the use of SQL> -- double quotation marks, which SQL requires when you SQL> -- qualify a catalog name with an alias. SQL> -- SQL> SET QUOTING RULES 'SQL99'; SQL> CREATE CATALOG "CORPORATE.MARKETING"; SQL> -- SQL> SHOW CATALOG; Catalogs in database personnel "CORPORATE.MARKETING" "CORPORATE.RDB$CATALOG"
—ل2: ƒfƒtƒHƒ‹ƒg‚ج•ت–¼‚ًژg—p‚µ‚½ƒfپ[ƒ^ƒxپ[ƒX“à‚إ‚جƒJƒ^ƒچƒO‚جچىگ¬
ژں‚ج—ل‚إ‚حپA‘خکbŒ^‚جCREATE DATABASE•¶‚إژg—p‚·‚éCREATE CATALOG‹ه‚ًژ¦‚µ‚ـ‚·پB‚±‚ج—ل‚إ‚حپAƒ†پ[ƒUپ[‚ح•ت–¼‚ًژw’肹‚¸‚ةƒfپ[ƒ^ƒxپ[ƒX‚ًچىگ¬‚µ‚ـ‚·پBƒ†پ[ƒUپ[‚ح‘¼‚جƒfپ[ƒ^ƒxپ[ƒX‚ةƒAƒ^ƒbƒ`‚³‚ê‚ؤ‚¢‚ب‚¢‚½‚كپAگV‹K‚ةچىگ¬‚µ‚½ƒfپ[ƒ^ƒxپ[ƒX‚ھƒfƒtƒHƒ‹ƒg‚ج•ت–¼‚ة‚ب‚è‚ـ‚·پB
SQL> CREATE DATABASE FILENAME inventory cont> MULTISCHEMA IS ON cont> CREATE CATALOG PARTS cont> CREATE SCHEMA PRINTERS AUTHORIZATION DAVIS cont> CREATE TABLE LASER EXTERNAL NAME IS DEPT_2_LASER cont> (SERIAL_NO INT, LOCATION CHAR) cont> CREATE SCHEMA TERMINALS AUTHORIZATION DAVIS cont> CREATE TABLE TERM100 EXTERNAL NAME IS DEPT_2_TERM100 cont> (SERIAL_NO INT, LOCATION CHAR); SQL> SHOW CATALOG; Catalogs in database with filename inventory PARTS RDB$CATALOG SQL> show schemas; Schemas in database with filename inventory PARTS.PRINTERS PARTS.TERMINALS RDB$SCHEMA
OpenVMS National Character SetپiNCSپj‚جƒ†پ[ƒeƒBƒٹƒeƒB‚ًژg—p‚µ‚ؤپA’è‹`‚³‚ê‚ؤ‚¢‚éڈئچ‡ڈ‡”ش‚ًژ¯•ت‚µ‚ـ‚·پBCREATE COLLATING SEQUENCE•¶‚ًژg—p‚·‚é‚ئپA“ء’è‚جƒhƒپƒCƒ“‚إژg—p‚·‚éƒfپ[ƒ^ƒxپ[ƒX‚جƒfƒtƒHƒ‹ƒg‚جڈئچ‡ڈ‡”ش‚ئ‚ح•ت‚جڈئچ‡ڈ‡”ش‚ًژw’è‚إ‚«‚ـ‚·پBپiƒfپ[ƒ^ƒxپ[ƒX‚جƒfƒtƒHƒ‹ƒg‚جڈئچ‡ڈ‡”ش‚حپACREATE SCHEMA•¶‚جCOLLATING SEQUENCE IS‹ه‚ة‚و‚èٹm—§‚³‚ê‚ـ‚·پBƒfپ[ƒ^ƒxپ[ƒX‚ج’è‹`ژ‚ة‚±‚ج‹ه‚ًڈب—ھ‚µ‚½ڈêچ‡پAƒfƒtƒHƒ‹ƒg‚جڈ‡ڈک‚حASCII‚إ‚·پBپjژں‚ج‚¢‚¸‚ê‚©‚ج•¶‚ةڈئچ‡ڈ‡”ش‚ج–¼‘O‚ً“ü—ح‚·‚é‘O‚ةپAڈئچ‡ڈ‡”ش‚ًژw’è‚·‚éCREATE COLLATING SEQUENCE•¶‚ً“ü—ح‚·‚é•K—v‚ھ‚ ‚è‚ـ‚·پB
- CREATE DOMAIN ... COLLATING SEQUENCE
- DROP COLLATING SEQUENCE
- ALTER DOMAIN ... COLLATING SEQUENCE
- SHOW COLLATING SEQUENCE
CREATE COLLATING SEQUENCE•¶‚حژں‚جٹآ‹«‚إژg—p‚إ‚«‚ـ‚·پB
- ‘خکbŒ^SQL“à
- ƒvƒٹƒRƒ“ƒpƒCƒ‹‘خڈغ‚جƒzƒXƒgŒ¾ŒêƒvƒچƒOƒ‰ƒ€‚ة–„‚كچ‚ـ‚ê‚éڈêچ‡
- SQLƒ‚ƒWƒ…پ[ƒ‹‚جƒvƒچƒVپ[ƒWƒƒ‚جˆê•”‚ئ‚µ‚ؤ
- “®“ISQL‚إ“®“I‚ةژہچs‚³‚ê‚镶‚ئ‚µ‚ؤ
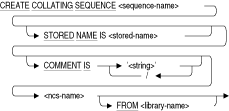
COMMENT IS 'string'
ڈئچ‡ڈ‡”ش‚ةٹض‚·‚éƒRƒپƒ“ƒg‚ً’ا‰ء‚µ‚ـ‚·پBSQL‚إ‚حپA‘خکbŒ^SQL‚إ‚جSHOW COLLATING SEQUENCE•¶‚جژہچsژ‚ةƒeƒLƒXƒg‚ھ•\ژ¦‚³‚ê‚ـ‚·پBƒRƒپƒ“ƒg‚حˆêڈdˆّ—p•„پi'پj‚إˆح‚فپAƒRƒپƒ“ƒg“à‚ج•،گ”‚جچs‚حƒXƒ‰ƒbƒVƒ…پi/پj‚إ‹وگط‚è‚ـ‚·پBFROM library-name
ƒfƒtƒHƒ‹ƒgˆبٹO‚جNCSƒ‰ƒCƒuƒ‰ƒٹ‚ج–¼‘O‚ًژw’肵‚ـ‚·پBƒfƒtƒHƒ‹ƒg‚جNCSƒ‰ƒCƒuƒ‰ƒٹ‚حSYS$LIBRARY:NCS$LIBRARY‚إ‚·پBncs-name
ƒfƒtƒHƒ‹ƒg‚جNCSƒ‰ƒCƒuƒ‰ƒٹ‚إ‚ ‚éSYS$LIBRARY:NCS$LIBRARY‚ـ‚½‚حlibrary-nameˆّگ”‚إژw’肳‚ꂽNCSƒ‰ƒCƒuƒ‰ƒٹ‚جڈئچ‡ڈ‡”ش‚ج–¼‘O‚ًژw’肵‚ـ‚·پBڈئچ‡ڈ‡”ش‚حپAژ–‘O’è‹`‚³‚ꂽNCSڈئچ‡ڈ‡”ش‚ج‚¢‚¸‚ê‚©‚ـ‚½‚حNCS‚ًژg—p‚µ‚ؤƒ†پ[ƒUپ[‚ھ’è‹`‚µ‚½‚à‚ج‚ة‚إ‚«‚ـ‚·پB
sequence-name
ncs-nameˆّگ”‚إژw’肳‚ꂽڈئچ‡ڈ‡”ش‚ھƒXƒLپ[ƒ}‚إ”Fژ¯‚³‚ê‚é–¼‘O‚ًژw’肵‚ـ‚·پBncs-nameˆّگ”‚¨‚و‚رsequence-nameˆّگ”‚حپA“¯‚¶‚à‚ج‚ة‚إ‚«‚ـ‚·پBSTORED NAME IS stored-name
ƒ}ƒ‹ƒ`ƒXƒLپ[ƒ}پEƒfپ[ƒ^ƒxپ[ƒX‚ةچىگ¬‚µ‚½ڈئچ‡ڈ‡”ش‚ض‚جƒAƒNƒZƒX‚ةژg—p‚³‚ê‚é–¼‘O‚ًژw’肵‚ـ‚·پBƒXƒgƒAƒh–¼‚ًژg—p‚·‚é‚ئپAOracle Rdbٹا—ƒ†پ[ƒeƒBƒٹƒeƒB‚إ‚ ‚éOracle RMU‚ب‚ا‚جƒCƒ“ƒ^ƒtƒFپ[ƒX‚ًژg—p‚µ‚ؤپAƒ}ƒ‹ƒ`ƒXƒLپ[ƒ}’è‹`‚ةƒAƒNƒZƒX‚إ‚«‚ـ‚·پB‚±‚جƒ†پ[ƒeƒBƒٹƒeƒB‚إ‚حپA1‚آ‚جƒfپ[ƒ^ƒxپ[ƒX“à‚إ•،گ”‚جƒXƒLپ[ƒ}‚ً”Fژ¯‚µ‚ـ‚¹‚ٌپB•،گ”‚جƒXƒLپ[ƒ}‚ة‘خ‰‚µ‚ب‚¢ƒfپ[ƒ^ƒxپ[ƒX“à‚إ‚حپAڈئچ‡ڈ‡”ش‚جƒXƒgƒAƒh–¼‚حژw’è‚إ‚«‚ـ‚¹‚ٌپB
- ƒhƒپƒCƒ“‚ة•ت‚جڈئچ‡ڈ‡”ش‚ًژw’è‚·‚éڈêچ‡‚حپAچإڈ‰‚ةCREATE COLLATING SEQUENCE•¶‚ًژہچs‚µ‚ـ‚·پBڈئچ‡ڈ‡”ش‚ًچىگ¬‚µ‚½ŒمپA‚»‚جڈئچ‡ڈ‡”ش‚ً“ء’è‚جƒhƒپƒCƒ“‚ة“K—p‚إ‚«‚ـ‚·پB
- ژں‚جƒٹƒXƒg‚إ‚حپAڈئچ‡ڈ‡”ش‚ةٹضکA‚·‚é‚·‚ׂؤ‚ج•¶‚ًڈب—ھ•\‹L‚إژ¦‚µ‚ـ‚·پB
- CREATE DOMAIN ... COLLATING SEQUENCE sequence-name
- CREATE DOMAIN ... NO COLLATING SEQUENCE
- ALTER DOMAIN ... COLLATING SEQUENCE sequence-name
- ALTER DOMAIN ... NO COLLATING SEQUENCE
- DROP COLLATING SEQUENCE sequence-name
- CREATE SCHEMA ... create-collating-sequence-statement
- CREATE DATABASE ... COLLATING SEQUENCE sequence-name ...
- IMPORT ... COLLATING SEQUENCE sequence-name ...
- SHOW ... COLLATING SEQUENCE
- ‚±‚ج•¶‚ح“اژو‚è/ڈ‘چ‚فƒgƒ‰ƒ“ƒUƒNƒVƒ‡ƒ“‚إژہچs‚·‚é•K—v‚ھ‚ ‚è‚ـ‚·پBƒAƒNƒeƒBƒu‚بƒgƒ‰ƒ“ƒUƒNƒVƒ‡ƒ“‚ھ‚ب‚¢ڈêچ‡‚ة‚±‚ج•¶‚ً”چs‚·‚é‚ئپASQL‚إ‚حپA“اژو‚è/ڈ‘چ‚فƒgƒ‰ƒ“ƒUƒNƒVƒ‡ƒ“‚ھˆأ–ظ“I‚ةٹJژn‚³‚ê‚ـ‚·پB
- CREATE COLLATING SEQUENCE•¶‚ً”چs‚·‚é‚ئپA‘¼‚جƒ†پ[ƒUپ[‚ھƒfپ[ƒ^ƒxپ[ƒX‚ةƒAƒ^ƒbƒ`‚إ‚«‚é‚و‚¤‚ة‚ب‚è‚ـ‚·پB
- ژں‚جڈئچ‡ڈ‡”ش‚ًژg—p‚µ‚ؤƒfپ[ƒ^ƒxپ[ƒX‚ً’è‹`‚µ‚و‚¤‚ئ‚·‚é‚ئپARDMS$$MCS$NCS_RECODE_8 + 00000665‚ج—لٹO‚إƒoƒOƒ`ƒFƒbƒNپEƒ_ƒ“ƒv‚ھ”گ¶‚µ‚ـ‚·پB
native_2_upper_lower = cs( sequence = (%X00,"#"," ","A","a","B","b","C","c","D","d","E", "e","8","F","f","5"-"4","G","g","H","h","I","i","J","j","K","k", "L","l","M","m","N","n","9","O","o","1","P","p","Q","q","R","r", "S","s","7"-"6","T","t","3"-"2","U","u","V","v","W","w","X","x", "Y","y","Z","z"), modifications = (%X01-%X1F=%X00,"!"-""""=%X00,"$"-"0"=%X00,":"-"@"= %X00, "{"-%XFF=%X00,""="A"));
ڈئچ‡ڈ‡”ش‚جmodifications‚ج‰سڈٹ‚إ‚حپA‘½‚·‚¬‚镶ژڑ‚ھƒkƒ‹•¶ژڑ‚ة•دٹ·‚³‚ê‚ؤ‚¢‚ـ‚·پBOracle Rdb‚إڈˆ—‰آ”\‚بƒkƒ‹•¶ژڑ‚ض‚ج•دٹ·‚حپA80•¶ژڑ’ِ“x‚إ‚·پB
‚±‚ê‚ً‰ٌ”ً‚·‚é‚ة‚حپAMULTINATIONAL2ƒLƒƒƒ‰ƒNƒ^پEƒZƒbƒg‚ً–ع“I‚جڈ‡ڈک‚إƒ\پ[ƒg‚·‚é‚و‚¤‚ة•دچX‚µ‚ـ‚·پB- ژں‚ج•¶ژڑ—ٌ‚ح‚¢‚¸‚ê‚àپAڈئچ‡ڈ‡”ش‚ج–¼‘O‚ئ‚µ‚ؤژg—p‚إ‚«‚ـ‚¹‚ٌپB
- "MCS"
- "ASCII"
- " "پi‚·‚ׂؤ‹َ”’پj
- ƒkƒ‹•¶ژڑپi•¶ژڑƒRپ[ƒh‚ھ0‚ج“ءژꕶژڑپj
- ƒmƒ‹ƒEƒFپ[Œê‚جڈئچ‡ڈ‡”ش‚ة‚ح“ءژꕶژڑ‚ھˆê•”ژg—p‚³‚ê‚ؤ‚¢‚邽‚كپAƒfپ[ƒ^ƒxپ[ƒX“à‚إƒmƒ‹ƒEƒFپ[Œê‚جڈئچ‡ڈ‡”ش‚ًچىگ¬‚·‚éڈêچ‡پAˆê’è‚جگ§Œہ‚ھ“K—p‚³‚ê‚ـ‚·پBNCSƒ‰ƒCƒuƒ‰ƒٹ‚ة‚¨‚¯‚éƒmƒ‹ƒEƒFپ[Œê‚جڈئچ‡ڈ‡”ش‚ج–¼‘O‚حپAگو“ھ•”•ھ‚ًNORWEGIAN‚ئ‚¢‚¤•¶ژڑ—ٌ‚ة‚·‚é•K—v‚ھ‚ ‚è‚ـ‚·پB
OpenVMS‚ة•Wڈ€‚إگف’肳‚ê‚ؤ‚¢‚éڈئچ‡ڈ‡”ش‚ج–¼‘O‚حNORWEGIAN‚ئ‚ب‚ء‚ؤ‚¨‚èپA‚±‚جگ§Œہ‚ً–‚½‚µ‚ؤ‚¢‚ـ‚·پBƒmƒ‹ƒEƒFپ[Œê‚جڈئچ‡ڈ‡”ش‚حپA“à—e‚ًژلٹ±•دچX‚·‚é‚©پA‚ـ‚½‚ح–¼‘O‚ً•دچX‚إ‚«‚ـ‚·پBƒmƒ‹ƒEƒFپ[Œê‚جڈئچ‡ڈ‡”ش‚جƒoƒٹƒGپ[ƒVƒ‡ƒ“‚ةپANORWEGIAN_1‚âNORWEGIANA‚ب‚ا‚ج–¼‘O‚ً•t‚¯‚邱‚ئ‚ً‚¨‘E‚ك‚µ‚ـ‚·پB- ڈئچ‡ڈ‡”ش‚جƒRƒپƒ“ƒg‚ً•دچX‚·‚éڈêچ‡‚حپACOMMENT ON COLLATING SEQUENCE‚ًژg—p‚µ‚ـ‚·پB
—ل1: ƒtƒ‰ƒ“ƒXŒê‚جڈئچ‡ڈ‡”ش‚جچىگ¬ژں‚ج—ل‚إ‚حپAژ–‘O’è‹`‚³‚ꂽڈئچ‡ڈ‡”شFRENCH‚ًژg—p‚µ‚ؤڈئچ‡ڈ‡”ش‚ھچىگ¬‚³‚ê‚ـ‚·پB‚»‚جŒمپA’è‹`‚³‚ꂽڈئچ‡ڈ‡”ش‚ھSHOW COLLATING SEQUENCE•¶‚ًژg—p‚µ‚ؤ•\ژ¦‚³‚ê‚ـ‚·پB
SQL> CREATE COLLATING SEQUENCE FRENCH FRENCH; SQL> -- SQL> SHOW COLLATING SEQUENCE User collating sequences in schema with filename SQL$DATABASE FRENCH
—ل2: •،گ”‚جƒRƒپƒ“ƒg‚ًژw’肵‚½ƒXƒyƒCƒ“Œê‚جڈئچ‡ڈ‡”ش‚جچىگ¬
SQL> CREATE COLLATING SEQUENCE SPANISH_COL cont> COMMENT IS 'first comment' / 'second comment' cont> SPANISH; SQL> SHOW COLLATING SEQUENCE SPANISH_COL; SPANISH_COL Comment: first comment second comment
