| Oracle Rdb SQLリファレンス・マニュアル リリース7.2 E06178-01 |
|


 戻る |
 次へ |
ストアド・モジュールは、データベース内にオブジェクトとして存在します。CREATE MODULE文を使用すると、モジュールおよびそのプロシージャとファンクションを格納できます。
AUTHORIZATION句で指定されている認可識別子を使用すると、モジュールを実行するユーザーをOracle Rdbで識別できるようになります。
ストアド・モジュールの定義で認可識別子を指定する場合、そのストアド・モジュールは定義者権限モジュールと呼ばれます。このタイプのモジュールを使用すると、モジュールに対してEXECUTE権限を持つユーザーは、ルーチンで参照する基底スキーマ・オブジェクトに対する権限がなくても、モジュール内のすべてのルーチンを実行できます。ルーチンは、それを実行するユーザーの権利識別子ではなく、モジュール定義者の権利識別子の下で実行されます。スキーマ・オブジェクトに直接アクセスせずに、ストアド・ルーチンのコールを介してユーザーがスキーマ・オブジェクトにアクセスできるという特性は、ストアド・モジュールの重要な利点です。
反対に、ストアド・モジュールの定義でAUTHORIZATION句を省略すると、そのストアド・モジュールは実行者権限モジュールと呼ばれます。このタイプのモジュールでは、特定のモジュールに対してEXECUTE権限を持つユーザーは、このモジュール内で実行するルーチンに関連付けられたすべての基底スキーマ・オブジェクトに対する権限も持っている必要があります。
次の例は、ストアド・モジュールおよびストアド・プロシージャに関係しています。AUTHORIZATIONおよびCURRENT_USERの処理は、いずれのタイプのストアド・ルーチンでも同じです。
プロシージャP1とAuthorization Brownが含まれている次のストアド・モジュール定義、モジュールM1について考えてみます。次に例を示します。
CREATE MODULE M1
LANGUAGE SQL
AUTHORIZATION BROWN
PROCEDURE P1 ();
BEGIN
TRACE CURRENT_USER;
CALL P2 ();
END;
END MODULE;
|
前述の例で示すように、P1は別のストアド・プロシージャP2をコールします。プロシージャP2は、次の例に示すようにモジュールM2で定義されています。
CREATE MODULE M2
LANGUAGE SQL
-- no authorization
PROCEDURE P2 ();
BEGIN
TRACE CURRENT_USER;
CALL P3 ();
END;
END MODULE;
|
プロシージャP2は、次の例に示すようにモジュールM3から別のプロシージャP3をコールします。
CREATE MODULE M3
LANGUAGE SQL
-- no authorization
PROCEDURE P3 ();
BEGIN
TRACE CURRENT_USER;
.
.
.
END;
END MODULE;
|
それぞれのプロシージャでCURRENT_USERをトレースできます。
図2-1は、これらのストアド・プロシージャをユーザーが起動するとどのような処理が行われるかを図で示しています。
図2-1 認可識別子およびストアド・モジュール
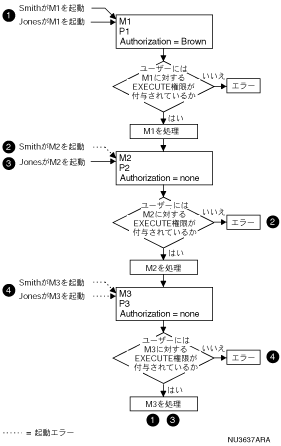
次のように想定します。
P1が実行されると、モジュールM1のAUTHORIZATION句で定義されているように、CURRENT_USERによって常にBrownが返されます。P2またはP3が実行されると、CURRENT_USERは次のいずれかになります。
最初のコール側ルーチンにAUTHORIZATION句が存在しない場合、CURRENT_USERはSESSION_USERから継承されます。
次のリストでは、図2-1の番号付きコールアウトについて説明します。
非ストアド・モジュールは、SQLモジュール・ファイル内のデータベースの外部に存在します。
AUTHORIZATION句は、モジュールの認可識別子を指定します。認可識別子を省略すると、モジュールをコンパイルしているユーザーのユーザー名がSQLによりデフォルト権限として選択されます。したがって、RIGHTS句を使用すると、モジュールを実行するユーザーのユーザー名が、モジュールのコンパイルに使用された認可識別子と比較され、そのモジュールをコンパイルしたユーザー以外のすべてのユーザーはそのモジュールを起動できなくなります。RIGHTS句を使用すると、ANSI/ISO規格に準拠して、デフォルトの認可識別子に基づいてSQLで権限チェックが行われます。
2.2.3 カタログ名
CREATE DATABASE文にMULTISCHEMA IS ON句を含めると、メタデータを複数のスキーマに格納できます。複数のスキーマが存在するデータベースは、カタログ内で構成する必要があります。カタログとは、1つのデータベース内に存在するスキーマのグループのことです。
カタログには、CREATE CATALOG文またはCREATE DATABASE文を使用して名前を付けます。また、カタログ名を使用すると、スキーマ、表およびビューなどの他のデータベース要素の名前を修飾することもできます。
構文図では、column-nameの構文要素は、CREATE文でカタログに付けた名前の修飾済または未修飾のいずれかの形式を参照します。つまり、構文図ではcatalog-nameは常に次のように定義されます。 
|
マルチスキーマ・データベースごとに、RDB$CATALOGという名前のカタログがSQLにより作成されます。デフォルトでは、すべてのスキーマがRDB$CATALOGに格納されます。データベースごとに複数のカタログを作成できますが、マルチスキーマ・データベースには少なくとも1つのカタログが含まれている必要があります。RDB$CATALOG以外のカタログにスキーマを格納するには、CREATE SCHEMA文で他のカタログ名を使用してスキーマ名を修飾するか、CREATE SCHEMA文を発行する前にSET CATALOG文を使用してデフォルトのカタログを変更します。
次の例では、デフォルトのカタログRDB$CATALOGに新しいスキーマPACIFIC_NORTHWESTを追加します。EAST_COASTカタログでスキーマを作成するには、カタログ名EAST_COASTを使用してスキーマNEW_ENGLANDを修飾する必要があります。デフォルトのカタログをEAST_COASTに変更する場合は、RDB$CATALOGなどの他のカタログにあるスキーマの名前を修飾する必要があります。
SQL> ATTACH 'FILENAME corporate_data';
SQL> CREATE SCHEMA PACIFIC_NORTHWEST;
SQL> CREATE CATALOG EAST_COAST;
SQL> CREATE SCHEMA EAST_COAST.NEW_ENGLAND;
SQL> SHOW SCHEMAS;
Schemas in database with filename corporate_data
ADMINISTRATION.ACCOUNTING
ADMINISTRATION.PERSONNEL
ADMINISTRATION.RECRUITING
EAST_COAST.NEW_ENGLAND
PACIFIC_NORTHWEST
RDB$SCHEMA
SQL> SET CATALOG 'EAST_COAST';
SQL> SHOW SCHEMAS;
Schemas in database with filename corporate_data
ADMINISTRATION.ACCOUNTING
ADMINISTRATION.PERSONNEL
ADMINISTRATION.RECRUITING
NEW_ENGLAND
RDB$CATALOG.PACIFIC_NORTHWEST
RDB$CATALOG.RDB$SCHEMA
|
1つのデータベース内では、異なるカタログに存在する表を1つのSQL文で使用できますが、データベースが異なるカタログの表の場合は使用できません。マルチスキーマ・データベースでオブジェクトを指定する場合にカタログ名を省略すると、現在のデフォルトのカタログの名前が使用されます。
2.2.4 列名
列には、CREATE TABLE文およびALTER TABLE文で名前を付けます。他のSQL文では、CREATE文およびALTER文で列に付けた名前を表名、ビュー名または相関名で修飾できます。
構文図では、column-nameの構文要素は、CREATE TABLE文またはALTER TABLE文で列に付けた名前の修飾済または未修飾のいずれかの形式を参照します。つまり、構文図ではcolumn-nameは常に次のように定義されます。

|
列名の修飾は、列名があいまいな場合にのみ必要です。1つの表をそれ自体と結合する場合(例は第2.2.4.1項を参照)、および2つの表を共通の列名で結合する場合(次の例を参照)の2つのケースでは、修飾済の列名が必要です。また、コロンなしで列名と同じパラメータを使用する場合も、その列の参照を修飾する必要があります。
ただし、列名の修飾は常にオプションです。複雑な文では、このような修飾子を使用することで文が読みやすくなることがあります。(モジュール言語およびプリコンパイルされたプログラムでは、列名を常に修飾してください。このようにしないと、変更した結果、修飾されていない列があいまいになった場合に、プログラムを変更して列名を修飾する必要が生じます。)
列名の修飾には、次の2つの方法があります。
column-name修飾子(表名またはビュー名にかかわりなく)自体は、別名で修飾できます。
この項のこれ以降では、表名またはビュー名を使用した列名の修飾例を示します。相関名の使用例は、第2.2.4.1項を参照してください。
次の例は、列名のオプションの修飾を示しています。この問合せではEMPLOYEES表からのみ列値が取得されるため、表の結合は行われません。かわりに、マーケティング部門の従業員をリストするために、別の文の条件で選択式がネストされます。この問合せでは列名に修飾子は必要ありませんが、EMPLOYEE_ID列が参照する表を明確に区別するために修飾子が使用されます。
SQL> SELECT EMPLOYEE_ID, FIRST_NAME, LAST_NAME cont> FROM EMPLOYEES cont> WHERE EMPLOYEES.EMPLOYEE_ID IN cont> (SELECT JOB_HISTORY.EMPLOYEE_ID cont> FROM JOB_HISTORY cont> WHERE JOB_END IS NULL cont> AND DEPARTMENT_CODE = 'MKTG'); EMPLOYEE_ID FIRST_NAME LAST_NAME 00197 Chris Danzig 00218 Lawrence Hall 00354 Paul Belliveau 3 rows selected |
次の例では前の例と同じ情報を取得しますが、列名EMPLOYEE_IDがあいまいであるためそれを修飾する必要があるケースを示しています。SELECT文によってEMPLOYEES表とJOB_HISTORY表が結合され、マーケティング部門の従業員が表示されます。EMPLOYEESおよびJOB_HISTORYにはいずれにもEMPLOYEE_IDという列が存在するため、この列を修飾する必要があります。
SQL> SELECT EMPLOYEES.EMPLOYEE_ID, cont> FIRST_NAME, LAST_NAME cont> FROM EMPLOYEES, JOB_HISTORY cont> WHERE JOB_END IS NULL cont> AND cont> DEPARTMENT_CODE = 'MKTG' cont> AND cont> JOB_HISTORY.EMPLOYEE_ID = EMPLOYEES.EMPLOYEE_ID; EMPLOYEES.EMPLOYEE_ID EMPLOYEES.FIRST_NAME EMPLOYEES.LAST_NAME 00197 Chris Danzig 00218 Lawrence Hall 00354 Paul Belliveau 3 rows selected |
表名またはビュー名を使用して列名を修飾するのみでなく、相関名で列名を修飾することもできます。相関名は別名と類似していますが、データベースではなく表を参照します。別名ではあいまいな表名を修飾するためにデータベースに対して一時名が指定されるのと同様に、相関名ではあいまいな列名を修飾するために表に対して一時名が指定されます。
選択式、DELETE文またはUPDATE文のFROM句の中で、表名の後に相関名を指定します。相関名または相関名なしの表名としてFROM句でまだ使用されていない有効な名前を使用してください。
1つの表をそれ自体と結合する文では、相関名を使用して列名を修飾する必要があります。ただし、表名およびビュー名の場合と同様に、明確にするために相関名を常に指定してもかまいません(第2.2.4.2項ではこの例を外部参照で示しています)。
次の例では、相関名を使用する必要があります。この例では、JOBS表をそれ自体と結合し、賃金クラス2の仕事のうち最大給与が賃金クラス4の仕事の最低給与と重なり合っているものを見つけます。
文のFROM句では、相関名であるSTAFFとMGRが指定されています。これらの相関名は、JOBSがそれ自体と結合された結果表で列名を区別する唯一の方法です。
SQL> SELECT STAFF.JOB_CODE, cont> STAFF.MAXIMUM_SALARY, cont> MGR.JOB_CODE, cont> MGR.MINIMUM_SALARY cont> FROM JOBS AS STAFF, cont> JOBS AS MGR cont> WHERE MGR.WAGE_CLASS = '4' cont> AND cont> STAFF.WAGE_CLASS = '2' cont> AND cont> STAFF.MAXIMUM_SALARY > MGR.MINIMUM_SALARY; STAFF.JOB_CODE STAFF.MAXIMUM_SALARY MGR.JOB_CODE MGR.MINIMUM_SALARY CLRK 20000.00 APGM 15000.00 1 row selected |
例は、事務員の最大給与が準プログラマの最小給与を超えていることを示しています。賃金クラス2の仕事の最大給与が賃金クラス4の仕事の最低給与を超えているのは、この2つの職種のみです。
明示的な相関名が存在しない場合は、表名またはビュー名を使用せずに選択リストで列名を明示的に修飾しても、表名またはビュー名がデフォルトの相関名であるとみなされます。このため、相関名を指定せずにFROM句で同じ表名を2回指定すると、SQLによりエラーが生成されます。
SELECT JOB_CODE, MINIMUM_SALARY FROM JOBS, JOBS; %SQL-F-CONVARDEF, Column qualifier JOBS is already defined |
この例では相関名が指定されていないため、デフォルトで、最初に出現するJOBS表に対してJOBSが修飾子であるとみなされます。2回目に出現するJOBSにも相関名が指定されていないと、2つ目のJOBSが2つ目のあいまいなデフォルト相関名として使用されるため、SQLによりエラーが生成されます。このエラーを防ぐには、FROM句でJOBSのいずれかの出現に対して相関名を指定してから、選択リスト内で列名を修飾します。
表に対して相関名を指定すると、列名の修飾に表名を使用できなくなります。次の例では、EMPLOYEES表に対してEを相関名として指定しています。これは、EMPLOYEE_ID列名の修飾子としてEMPLOYEESを使用できないことを意味します。
SELECT * FROM EMPLOYEES E WHERE EMPLOYEES.EMPLOYEE_ID = '00169'; %SQL-F-CONVARUND, Column qualifier EMPLOYEES is not defined |
外部参照で列名の修飾が必要な場合があります。外部参照とは、副問合せを含む外部問合せで指定された表に対して、副問合せ内で行う参照のことです。外部参照は相関参照とも呼ばれます。
たとえば、マーケティング部門の従業員名を取得する前述の例を、外部参照を使用するように変更できます。
SQL> SELECT FIRST_NAME, -- cont> LAST_NAME -- cont> FROM EMPLOYEES -- cont> WHERE 'MKTG' IN -- cont> (SELECT DEPARTMENT_CODE -- -- Outer cont> FROM JOB_HISTORY -- -- Query cont> WHERE JOB_END IS NULL -- Sub- -- cont> AND -- query -- cont> EMPLOYEE_ID = cont> EMPLOYEES.EMPLOYEE_ID) -- -- cont> -- --------------------- cont> -- outer reference cont> ; FIRST_NAME LAST_NAME Chris Danzig Lawrence Hall Paul Belliveau 3 rows selected |
この例で示すEMPLOYEE_IDへの外部参照が表名EMPLOYEESで修飾されていない場合は、外部問合せではなく副問合せのEMPLOYEE_ID列を参照することになります。EMPLOYEE_IDのNULL以外のすべての値に対して条件EMPLOYEE_ID = EMPLOYEE_IDがTRUEになるため、この文はエラーを生成しませんが、予期しない結果となります。3人のマーケティング従業員のかわりに、EMPLOYEE_ID列の値がNULLでないすべての行がEMPLOYEES表から選択されます。
外部参照は副問合せ内に含まれますが、その値は外部問合せから取得されます。このため、外部参照が外部問合せから値を受け取るたびに、副問合せを評価する必要があります。これが、外部参照の顕著な特性です。
前述の例では、文の最後の行EMPLOYEES.EMPLOYEE_IDにある外部参照によって、表EMPLOYEESの行ごとに異なる値が取得されます。表EMPLOYEESのEMPLOYEE_IDの値ごとに、EMPLOYEES.EMPLOYEE_IDを含む副問合せがSQLで評価されます。
副問合せ内の参照と外部問合せ内の表との相関関係を明確にするために、次の例に示すMAIN_QUERYおよびSUBQUERYなどの相関名を指定できます。
SQL> SELECT MAIN_QUERY.FIRST_NAME, cont> MAIN_QUERY.LAST_NAME cont> FROM EMPLOYEES MAIN_QUERY cont> WHERE 'MKTG' IN cont> (SELECT SUBQUERY.DEPARTMENT_CODE cont> FROM JOB_HISTORY SUBQUERY cont> WHERE SUBQUERY.JOB_END IS NULL cont> AND cont> SUBQUERY.EMPLOYEE_ID = MAIN_QUERY.EMPLOYEE_ID); FIRST_NAME LAST_NAME Chris Danzig Lawrence Hall Paul Belliveau 3 rows selected |
アプリケーションが1つ以上のデータベースにアタッチする場合、SQLによりデータベースが(データベースで処理する)一連の別名に関連付けられます。CONNECT文、DISCONNECT文またはSET CONNECT文では、この関連を接続名として参照します。接続名は、動的SQLのパラメータ・マーカー、プリコンパイルされたSQLプログラムのホスト言語変数、SQLモジュールの言語モジュールのパラメータ、または文字列リテラルとして指定できます。
1単位としてアタッチまたはデタッチできるデータベースのセットはデータベース環境と呼ばれます。アプリケーション内では、すべてのモジュールで宣言されたすべてのデータベースが、実行時にそのアプリケーションに対するデフォルトのデータベース環境になります。接続の詳細は、「CONNECT文」を参照してください。
2.2.6 制約名
制約では、表に格納できる値を制限する条件を定義します。列値を挿入および更新すると、制約で指定された条件に突き合せて値がチェックされます。値が制約に違反している場合は、エラー・メッセージが生成され(SQLによってどの時点で制約が評価されるかに応じて、INSERT文、UPDATE文またはDELETE文の実行時または次のCOMMIT文の実行時に)文が失敗します。
制約は、CREATE文およびALTER TABLE文で指定します。オプションで、CONSTRAINTキーワードの後に制約名を指定します。
2.2.7 カーソル名
カーソルを使用して、結果表の個々の行にアクセスできます。結果表とは、1つ以上の表またはビューの列および行の一時的なコレクションのことです。カーソル用の結果表は、DECLARE CURSOR文の選択式によって指定されます。
他の結果表とは異なり、カーソル用の結果表は、複数の文の実行を通じて存在できます。ホスト言語プログラムでは1行ずつ操作を実行する必要があるため、カーソルが必要です。したがって、文を複数回実行して結果表全体を処理できます。
カーソル用の結果表の名前はDECLARE CURSOR文で指定し、その名前をOPEN文、CLOSE文、FETCH文、UPDATE文およびDELETE文で参照します。カーソル名は修飾できません。
2.2.8 データベース名
データベースは、ルート・ファイルやストレージ領域の指定などの物理データ・ストレージ特性、表やドメインなどのメタデータ定義およびユーザー・データで構成されています。
デフォルトでは、1つのデータベースに1つのスキーマが存在し、カタログは存在しません。データベースを作成するときにマルチスキーマ属性を指定すると、1つ以上のカタログ内の1つ以上のスキーマでデータ定義をグループ化できます。マルチスキーマ・データベースの作成方法の詳細は、「CREATE DATABASE文」を参照してください。
データベースを作成する場合、CREATE DATABASE文でファイル名およびオプションのリポジトリ・パス名を指定してデータベースに名前を付けます。完全または部分的なファイル仕様を指定できますが、システムで提供されるデフォルト値も使用できます。データベース名にはASCII英数字を使用する必要があります。
データベースで操作を実行するために、そのデータベースに対する別名と呼ばれるアタッチメントを介してデータベース名が参照されます。SQLで最初にデータベースを参照する場合は、別名を宣言することによって、そのデータベースのデータ定義のソースおよびデータベース・ファイルの場所を指定する必要があります。別名は次のいずれかの文を使用して宣言できます。
使用しているインタフェース(対話型SQL、SQLモジュール言語またはプリコンパイルされたSQL)および目的(新しい別名の宣言、または別名とデータベース名との間の関連のオーバーライド)に応じて文を選択します。詳細は、第6章の各文の項を参照してください。別名の詳細は、第2.2.1項を参照してください。
データ定義のソースの識別には、次の2つの方法があります。
