Datenpipelines auf einer autonomen KI-Datenbank
Datenpipelines der autonomen KI-Datenbank sind entweder Ladepipelines oder Exportpipelines.
Load-Pipelines bieten kontinuierliches inkrementelles Laden von Daten aus externen Quellen (wenn Daten im Objektspeicher eintreffen, werden sie in eine Datenbanktabelle geladen). Exportpipelines bieten kontinuierlichen inkrementellen Datenexport in den Objektspeicher (wenn neue Daten in einer Datenbanktabelle angezeigt werden, werden sie in den Objektspeicher exportiert). Pipelines verwenden den Datenbank-Scheduler, um inkrementelle Daten kontinuierlich zu laden oder zu exportieren.
Die Datenpipelines der autonomen KI-Datenbank bieten Folgendes:
-
Einheitliche Vorgänge: Mit Pipelines können Sie Daten schnell und einfach laden oder exportieren und diese Vorgänge in regelmäßigen Abständen für neue Daten wiederholen. Das Package
DBMS_CLOUD_PIPELINEstellt ein einheitliches Set von PL/SQL-Prozeduren für die Pipelinekonfiguration und zum Erstellen und Starten eines geplanten Jobs für Lade- oder Exportvorgänge bereit. -
Geplante Datenverarbeitung: Pipelines überwachen ihre Datenquelle und laden oder exportieren die Daten regelmäßig, wenn neue Daten eintreffen.
-
Hohe Performance: Pipelines skalieren die Datenübertragungsvorgänge mit den verfügbaren Ressourcen in Ihrer autonomen KI-Datenbank. Pipelines verwenden standardmäßig Parallelität für alle Lade- oder Exportvorgänge und skalieren basierend auf den CPU-Ressourcen, die in Ihrer autonomen KI-Datenbank verfügbar sind, oder auf einem konfigurierbaren Prioritätsattribut.
-
Atomizität und Recovery: Pipelines garantieren Atomarität, sodass Dateien im Objektspeicher genau einmal für eine Ladepipeline geladen werden.
-
Monitoring und Fehlerbehebung: Pipelines stellen detaillierte Log- und Statustabellen bereit, mit denen Sie Pipelinevorgänge überwachen und debuggen können.
-
Multicloud-kompatibel: Pipelines auf einer autonomen KI-Datenbank unterstützen den einfachen Wechsel zwischen Cloud-Providern ohne Anwendungsänderungen. Pipelines unterstützen alle Zugangsdaten- und Objektspeicher-URI-Formate, die Autonomous AI Database unterstützt (Oracle Cloud Infrastructure Object Storage, Amazon S3, Azure Blob Storage oder Azure Data Lake Storage, Google Cloud Storage und Amazon S3-kompatible Objektspeicher).
Informationen zum Datenpipeline-Lebenszyklus in einer autonomen KI-Datenbank
Das DBMS_CLOUD_PIPELINE-Package enthält Prozeduren zum Erstellen, Konfigurieren, Testen und Starten einer Pipeline. Der Pipelinelebenszyklus und die Pipelineprozeduren sind für Lade- und Exportpipelines identisch.
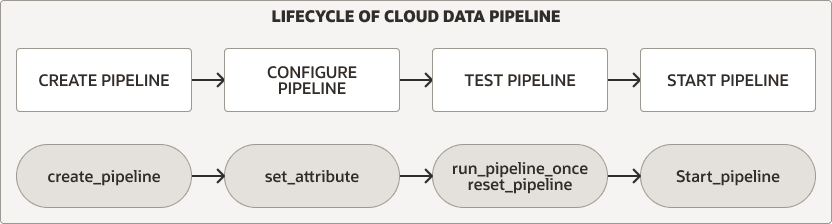
Beschreibung der Abbildung Pipeline_lifecycle.png
Führen Sie für einen der beiden Pipelinetypen die folgenden Schritte aus, um eine Pipeline zu erstellen und zu verwenden:
-
Erstellen und Konfigurieren der Pipeline. Weitere Informationen finden Sie unter Pipelines erstellen und konfigurieren.
-
Neue Pipeline testen Weitere Informationen finden Sie unter Pipelines testen.
-
Pipeline starten. Weitere Informationen finden Sie unter Pipeline starten.
Darüber hinaus können Sie Pipelines überwachen, stoppen oder löschen:
-
Während eine Pipeline ausgeführt wird, können Sie die Pipeline entweder während des Tests oder während der regulären Verwendung überwachen, nachdem Sie die Pipeline gestartet haben. Weitere Informationen finden Sie unter Pipelines überwachen und Fehler beheben.
-
Sie können eine Pipeline stoppen und später erneut starten oder eine Pipeline löschen, wenn Sie mit der Pipeline fertig sind. Weitere Informationen finden Sie unter Pipeline stoppen und Pipeline löschen.
Informationen zu Load Pipelines auf einer autonomen KI-Datenbank
Verwenden Sie eine Ladepipeline zum kontinuierlichen inkrementellen Laden von Daten aus externen Dateien im Objektspeicher in eine Datenbanktabelle. Eine Lade-Pipeline identifiziert regelmäßig neue Dateien im Objektspeicher und lädt die neuen Daten in die Datenbanktabelle.
Eine Ladepipeline wird wie folgt ausgeführt (einige dieser Features können mit Pipelineattributen konfiguriert werden):
-
Objektspeicherdateien werden parallel in eine Datenbanktabelle geladen.
-
Eine Lade-Pipeline verwendet den Namen der Objektspeicherdatei, um neuere Dateien eindeutig zu identifizieren und zu laden.
-
Wenn eine Datei im Objektspeicher in die Datenbanktabelle geladen wurde und sich der Dateiinhalt im Objektspeicher ändert, wird sie nicht erneut geladen.
-
Wenn die Objektspeicherdatei gelöscht wird, wirkt sich dies nicht auf die Daten in der Datenbanktabelle aus.
-
-
Wenn Fehler auftreten, wiederholt eine Ladepipeline den Vorgang automatisch. Bei jeder nachfolgenden Ausführung des geplanten Jobs der Pipeline werden Wiederholungen versucht.
-
Wenn die Daten in einer Datei nicht mit der Datenbanktabelle übereinstimmen, wird sie als
FAILEDmarkiert und kann geprüft werden, um das Problem zu debuggen und zu beheben.- Wenn eine Datei nicht geladen werden kann, wird die Pipeline nicht gestoppt, und die anderen Dateien werden weiterhin geladen.
-
Ladepipelines unterstützen mehrere Eingabedateiformate, einschließlich: JSON, CSV, XML, Avro, ORC und Parquet.
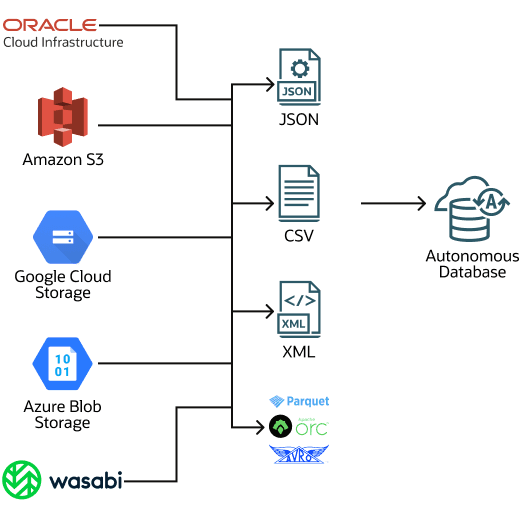
Die Migration von Nicht-Oracle-Datenbanken ist ein möglicher Anwendungsfall für eine Load Pipeline. Wenn Sie Ihre Daten aus einer Nicht-Oracle-Datenbank in Oracle Autonomous AI Database migrieren müssen, können Sie die Daten extrahieren und in eine autonome KI-Datenbank laden (das Oracle Data Pump-Format kann nicht für Migrationen aus Nicht-Oracle-Datenbanken verwendet werden). Wenn Sie ein generisches Dateiformat wie CSV verwenden, um Daten aus einer Nicht-Oracle-Datenbank zu exportieren, können Sie Ihre Daten in Dateien speichern und die Dateien in den Objektspeicher hochladen. Erstellen Sie als Nächstes eine Pipeline zum Laden der Daten in die autonome KI-Datenbank. Die Verwendung einer Ladepipeline zum Laden einer großen Gruppe von CSV-Dateien bietet wichtige Vorteile wie Fehlertoleranz sowie Wiederaufnahme- und Wiederholungsvorgänge. Bei einer Migration mit einem großen Dataset können Sie mehrere Pipelines erstellen, eine pro Tabelle für die Nicht-Oracle-Datenbankdateien, um Daten in die autonome KI-Datenbank zu laden.
Informationen zum Export von Pipelines auf einer autonomen KI-Datenbank
Verwenden Sie eine Exportpipeline für den kontinuierlichen inkrementellen Export von Daten aus der Datenbank in den Objektspeicher. Eine Exportpipeline identifiziert regelmäßig Kandidatendaten und lädt die Daten in den Objektspeicher hoch.
Es gibt drei Exportpipelineoptionen (die Exportoptionen können mit Pipelineattributen konfiguriert werden):
-
Exportieren Sie inkrementelle Ergebnisse einer Abfrage in den Objektspeicher, indem Sie eine Datums- oder Zeitstempelspalte als Schlüssel für die Verfolgung neuerer Daten verwenden.
-
Exportieren Sie inkrementelle Daten einer Tabelle in den Objektspeicher, indem Sie eine Datums- oder Zeitstempelspalte als Schlüssel für die Verfolgung neuerer Daten verwenden.
-
Exportieren Sie Daten einer Tabelle in einen Objektspeicher mit einer Abfrage, um Daten ohne Referenz auf eine Datums- oder Zeitstempelspalte auszuwählen (so dass die Pipeline alle Daten exportiert, die von der Abfrage für jede Scheduler-Ausführung ausgewählt werden).
Exportpipelines verfügen über die folgenden Features (einige davon können mit Pipelineattributen konfiguriert werden):
-
Ergebnisse werden parallel zum Objektspeicher exportiert.
-
Im Falle eines Fehlers wiederholt ein späterer Pipelinejob den Exportvorgang.
-
Exportpipelines unterstützen mehrere Exportdateiformate, einschließlich: CSV, JSON, Parquet oder XML.
Von Oracle verwaltete Pipelines
Die autonome KI-Datenbank bietet integrierte Pipelines zum Exportieren von Logs in den Objektspeicher. Diese Pipelines sind vorkonfiguriert und können vom ADMIN-Benutzer gestartet werden.
Die von Oracle verwalteten Pipelines sind:
-
ORA$AUDIT_EXPORT: Diese Pipeline exportiert die Datenbankauditlogs in den Objektspeicher im JSON-Format und wird alle 15 Minuten nach dem Start der Pipeline ausgeführt (basierend auf dem Attributwertinterval). -
ORA$APEX_ACTIVITY_EXPORT: Diese Pipeline exportiert das Aktivitätslog des Oracle APEX-Workspace in den Objektspeicher im JSON-Format. Diese Pipeline ist mit der SQL-Abfrage zum Abrufen von APEX-Aktivitätsdatensätzen vorkonfiguriert und wird alle 15 Minuten nach dem Start der Pipeline ausgeführt (basierend auf dem Attributwertinterval).
Die von Oracle verwalteten Pipelines gehören dem ADMIN-Benutzer, und Attribute von von von Oracle verwalteten Pipelines können vom ADMIN-Benutzer geändert werden.
Standardmäßig verwenden die von Oracle verwalteten Pipelines OCI$RESOURCE_PRINCIPAL als credential_name.
Weitere Informationen finden Sie unter Von Oracle verwaltete Pipelines verwenden.