
Diagrama de secuencia de lógica
El diagrama de secuencia siguiente resulta útil para comprender la funcionalidad del analizador de ficheros. La clase personalizada debe implantar las interfaces FileParser y FileParser2 de Java descritas en el jar SGG D1 para comprobar si cumple los requisitos como analizador de ficheros. Para obtener más información, consulte Interfaz de FileParser e Interfaz de FileParser2.
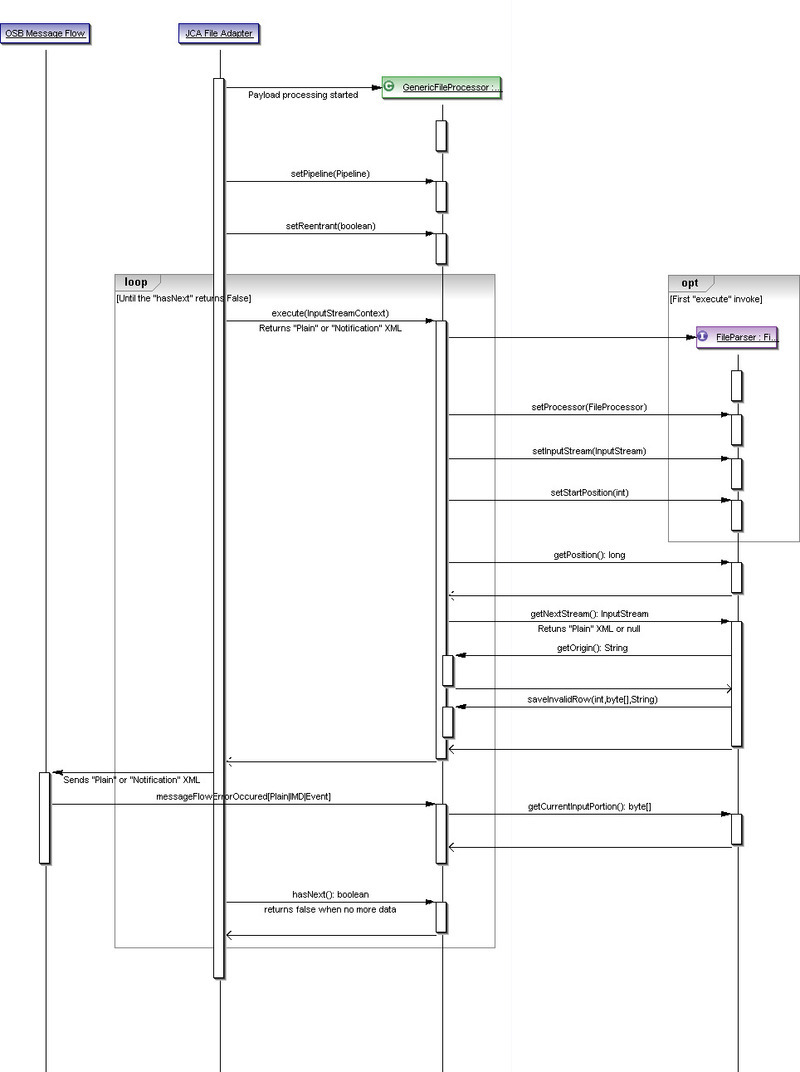
Cuando el adaptador de ficheros encuentra un fichero en el directorio de entrada, crea instancias y llama al procesador de ficheros genéricos que, a su vez, inicia una interacción con el analizador de ficheros. La interacción se puede clasificar en las tres fases siguientes:
-
Creación de instancias e inicialización
-
setProcessor()
-
setInputStream()
-
setStartPosition()
-
-
Transacción
-
getPosition()
-
getNextStream()
-
-
Gestión de excepciones
-
getCurrentInputPortion()
-
Fase de creación de instancias e inicialización
Se crean instancias para el procesador de ficheros genéricos y este recibe una cadena de entrada cuando un fichero entra en el directorio de entrada. En ese momento se crea una instancia del analizador de ficheros. Como se ha indicado anteriormente, se llama a determinados métodos en el analizador de ficheros para inicializar.
Fase de transacción
Una vez que se ha inicializado el analizador de ficheros, el procesador de ficheros genéricos utiliza la instancia del analizador de ficheros para generar la estructura XML sin formato. Esto ocurre con la llamada al método getNextStream() en el analizador de ficheros.
En cada llamada, el analizador de ficheros devuelve exactamente un XML sin formato. Las llamadas del analizador de ficheros continúan hasta que devuelve NULL. NULL indica el final del fichero y que ha finalizado el análisis de un fichero específico. El procesador de ficheros genéricos deja de llamar a getNextStream() para un fichero de entrada concreto cuando recibe NULL del analizador de ficheros.
El analizador de ficheros utiliza la cadena de entrada de ficheros para leer el fichero por partes. Puede leerse byte a byte o línea a línea, pero al final de cada llamada al método getNextStream(), habrá leído lo suficiente para crear una estructura XML sin formato. Por ejemplo, en un fichero de entrada, si hay suficientes datos para un solo XML sin formato, la primera llamada a getNextStream() devolverá un XML sin formato y la siguiente devolverá NULL. Pero si hay más de uno, las llamadas de getNextStream() continuarán devolviendo estructuras XML sin formato para cada parte entrante, hasta que se llegue al final del fichero.
Fase de gestión de excepciones
La gestión de excepciones dentro del analizador de ficheros se puede clasificar en dos fases: reactiva y recuperación:
Fase reactiva
Esta fase implica captar una excepción y notificarla al procesador de ficheros genéricos. Esto se consigue llamando al método saveInvalidRow() en el procesador de ficheros genéricos (this.fileProcessor).
Tenga en cuenta que, cuando se produce una excepción, no se realiza más análisis y se transfiere NULL de vuelta desde getNextStream().
Si uno falla al devolver NULL, se pueden encontrar errores como, por ejemplo, “el analizador de ficheros ha devuelto resultados buenos y malos simultáneamente” en el log del servidor de Weblogic.
Cuando se notifica una excepción al procesador de ficheros genéricos, hace tres cosas:
-
Crea una D1-PayloadErrorNotif de carga útil de XML y la transfiere al flujo de mensajes de OSB. El mensaje se publica en la cola de notificaciones desde dentro del servicio proxy de procesamiento del proyecto BASE OSB.
-
Aumenta la variable de “error de transacción producido” llamando al método de utilidad del jar D1. Se capturan todos los errores que se producen durante el ciclo de vida de un análisis de fichero y se notifican mediante el mensaje D1-PayloadSummary, que se vuelve a publicar en la cola de notificaciones.
-
Por último, crea un fichero de datos en el directorio de errores con la parte de datos sin formato que se ha leído cuando se produjo el error. También crea un fichero del descriptor de ficheros rechazados. La parte de entrada sin formato está disponible utilizando el método getCurrentInputPortion(), que se describe más adelante.
Como se observa en la imagen anterior, el método saveInvalidRow() toma tres parámetros de entrada:
-
La posición en la que empezó el análisis. Se escribirá en un fichero del descriptor de ficheros rechazados. Resulta útil para identificar la ubicación de un error en el fichero de entrada.
-
Los datos sin formato se escribirán en un fichero de datos de error. Debe tener el mismo formato que el del fichero entrante y debe contener datos que se lean desde que se inicia la llamada actual al método getNextStream(). Permitirá que se corrijan los datos con problemas y colocará el fichero “corregido” en una carpeta entrante para volver a procesarlo más adelante.
-
El mensaje de error que se notifica en el mensaje D1-PayloadErrorNotif. Tenga en cuenta que el desarrollador del analizador de ficheros debe definir el contenido del mensaje de error.
Fase de recuperación
Esta fase no se debe confundir con la recuperación de una excepción gestionada descrita con anterioridad. Este caso es cuando el análisis de ficheros se interrumpe por completo debido a un fallo de suministro eléctrico o a una interrupción en la red.
Preparación para recuperación: el procesador de ficheros genéricos mantiene un índice interno en la posición de lectura actual del fichero. Para lograrlo, el procesador de ficheros genéricos llama al método getPosition() en el analizador de ficheros antes de cada llamada del método getNextStream().

Recuperación: en caso de que se produzca una interrupción y se restablezca posteriormente, el procesador de ficheros genéricos define la posición inicial en el analizador de ficheros. Por ejemplo, si el fallo se ha producido en el byte 415, la posición inicial se establecerá en 415 para que el analizador de ficheros empiece a leer desde ese punto y no desde 0. El valor 415 puede definirse como el punto de recuperación.

Cuando el analizador de ficheros empieza a analizar de nuevo, deben ocurrir dos cosas para garantizar que comienza a analizar desde el punto de recuperación:
-
Almacenamiento del punto de recuperación en el campo startPosition.
-
Incorporación de la lógica de omisión para iniciar el puntero desde el punto de recuperación.