
Uogólniony eksport danych
Metoda uogólnionego eksportu danych zapewnia eksport danych oparty na plikach w formacie JSON. Eksportowanie danych obiektu obsługi przy użyciu tej metody obejmuje początkowy eksport wszystkich danych podmiotu, po którym następuje bieżący eksport zmian dokonywanych w miarę upływu czasu. Te procesy zostały przedstawione na poniższym schemacie:
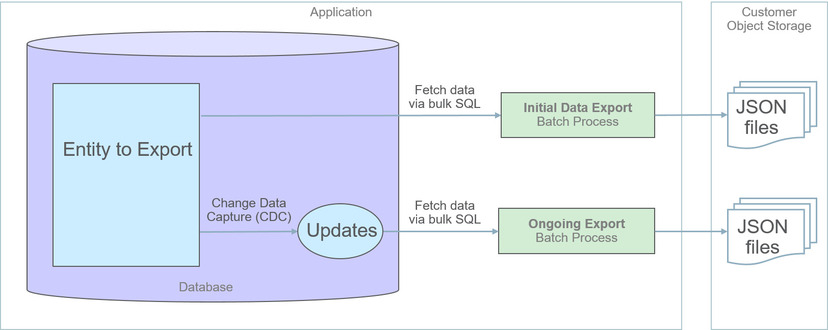
-
Włączenie obiektów na potrzeby eksportu w portalu Kartoteka eksportu uogólnionego. Jednocześnie można włączyć wiele obiektów. Ten krok umożliwia również bieżący eksport tych obiektów.
-
Przesłanie procesu zadania inicjatora uogólnionego eksportu początkowego (F1-GEXPI), aby wyeksportować bieżącą zawartość wszystkich włączonych obiektów. Ten krok służy do przesłania osobnego procesu zadania dotyczącego każdego obiektu włączonego na potrzeby eksportu.
-
Zaplanowanie procesu zadania uogólnionego eksportu bieżącego (F1-GEEXO), aby uruchamiało się okresowo.
W poniższych sekcjach omówiono koncepcje i wytyczne związane z metodą uogólnionego eksportu danych.
Gotowość
-
Obiekt zarządza bardzo dużą ilością danych. Śledzenie zmian w takim obiekcie podwaja wolumen zarządzanych danych i wpływa na ogólną wydajność.
-
Obiekt jest bardzo często aktualizowany. Śledzenie tych zdarzeń może mieć wpływ na ogólną wydajność.
-
Obiekt jest używany w infrastrukturze produktu i procesach operacyjnych. Obiekty te są obsługiwane w inny sposób i nie mogą podlegać metodom uogólnionego eksportu danych.
Domyślnie obiekt obsługi jest gotowy do zastosowania metody uogólnionego eksportu danych, chyba że wyraźnie oznaczono inaczej w opcji Klasa eksportu danych. Opcja ta może być używana do oznaczenia obiektu jako niedozwolonego do jakiegokolwiek typu eksportu lub dozwolonego tylko do specjalistycznego eksportu. Brak tej wyraźnie określonej opcji oznacza, że obiekt obsługi jest gotowy do uogólnionego eksportu.
Jedna metoda do wszystkich obiektów
Metoda uogólnionego eksportu danych jest przeznaczona do uwzględniania wielu gotowych obiektów obsługi w sposób ogólny, który musi również brać pod uwagę wydajność. Z tego powodu ta metoda nie obsługuje opcji filtrowania specyficznych dla obiektu ani jakichkolwiek reguł niestandardowych.
-
Eksport wszystkich danych.
-
Eksportowane są wszystkie pola ze wszystkich tabel, które należą do obiektu obsługi, z wyjątkiem tabel "klucz" i "dziennik", jeśli występują.
-
Tabele dziennika obiektów obsługi zwykle nie zawierają przydatnych informacji biznesowych i jako takie są pomijane w eksporcie ze względu na wydajność i ilość danych. Istnieją jednak obiekty, dla których rekordy dziennika zawierają wartość analityczną. W stosownych przypadkach należy użyć opcji Eksportowanie tabel dziennika, aby wyraźnie uwzględnić tabele dziennika w określonym obiekcie obsługi.
-
-
Ta sama struktura i format danych są używane dla wszystkich obiektów. Więcej informacji zawiera sekcja Format rekordu.
-
Dane są eksportowane tylko do plików. Więcej informacji zawiera sekcja Eksport tylko do plików.
-
Pobierane są wszystkie zmiany. Nie można wykluczyć niektórych zmian ze śledzenia bieżącego eksportu na podstawie niestandardowych reguł biznesowych.
-
W przypadku zmiany danych wyeksportowany zostanie pełen zapis danych dotyczących tego obiektu, aby uniknąć scalania dużych ilości danych po stronie rekordu docelowego.
-
Po skasowaniu obiektu eksportowany jest tylko klucz główny obiektu wraz ze wskazaniem, że obiekt został skasowany.
Eksport tylko do plików
Bezpośrednim miejscem docelowym procesów początkowego i bieżącego eksportu są pliki w lokalizacji określonej przez klienta. W chmurze pliki instalacyjne tworzone są w należącej do klienta pamięci obiektu.
W zależności od wymagań biznesowych można dodatkowo korzystać z tych plików do zastosowań podrzędnych, takich jak jeziora danych itp.
Włączanie eksportu danych
Aby włączyć eksport danych kwalifikującego się obiektu obsługi, należy utworzyć rekord Kontrolki eksportu danych. Rekord zachowuje wskazanie, czy początkowy eksport obiektu obsługi został zakończony, czy też nie i czy zmiany wprowadzone w obiekcie powinny być śledzone i eksportowane na bieżąco. Wyznaczony portal umożliwia włączenie uogólnionego eksportu danych wielu obiektów obsługi jednocześnie, a także szybkie monitorowanie ich bieżącego statusu eksportu. Więcej informacji zawiera portal Kartoteka eksportu uogólnionego.
Opcje bieżącego eksportu są buforowane w różnych buforach online i buforach zadania. Aby te opcje zaczęły obowiązywać i aby śledzić zmiany obiektów wprowadzone przez dowolny proces online lub proces zadania, konieczne jest poprawne opróżnianie poszczególnych buforów po zmianie tych opcji. Użycie wyznaczonych portali w celu włączenia obiektów do eksportu wyzwala "globalne" opróżnianie buforów. Jest to jedyny wymagany krok, jeśli procesy robocze puli wątków zadania są skonfigurowane tak, aby ich bufory były odświeżane w momencie żądania globalnego opróżniania. W przeciwnym razie należy również przesłać zadanie F1–FLUSH, aby odświeżyć bufory używane w przetwarzaniu zadania. Więcej informacji na ten temat można znaleźć w sekcji Ogólne informacje o buforowaniu.
Początkowy eksport danych
Każdy obiekt obsługi, który kwalifikuje się do metody uogólnionego eksportu danych, jest powiązany z kontrolką zadania początkowego eksportu danych, do której odwołuje się obiekt obsługi przy użyciu opcji Kontrolka zadania eksportu. Wszystkie te kontrolki zadania używają tego samego wspólnego programu zadania do eksportowania wszystkich danych obiektu do plików. Proces jest wielowątkowy i domyślnie generuje jeden plik na wątek. Opcjonalny parametr zadania umożliwia generowanie wielu mniejszych plików na wątek poprzez ustawienie limitu liczby rekordów zapisywanych w każdym pliku. Więcej informacji zawiera sekcja Rozmiar pliku.
Zamiast ręcznie przesyłać proces zadania uogólnionego eksportu początkowego dla każdego obiektu obsługi, który włączono do eksportu, należy przesłać proces zadania inicjatora uogólnionego eksportu początkowego F1-GEXPI, aby automatycznie przesłać je wszystkie jednocześnie.
Proces eksportu początkowego dotyczącego każdego obiektu obsługi aktualizuje odpowiedni rekord kontrolki eksportu danych obiektu obsługi, aby wskazać, że proces został uruchomiony i aktualizuje go ponownie po zakończeniu. Umożliwia to wyświetlanie ogólnego statusu początkowego eksportu wśród wszystkich włączonych obiektów w portalu Kartoteka eksportu uogólnionego.
Należy zauważyć, że proces zadania inicjatora przesyła tylko procesy zadania dotyczące włączonych obiektów obsługi, których początkowy eksport jeszcze się nie rozpoczął zgodnie z ich rekordem kontrolki eksportu danych. Jeśli konieczne jest ponowne wyeksportowanie jednego lub więcej obiektów, należy zresetować wskazanie statusu eksportu początkowego w ich rekordach kontrolki eksportu danych i ponownie przesłać proces zadania inicjatora.
INIT_EXPORT[_file prefix(optional)]_[maintenance object]_[batch run]_[thread]_[thread count]_[timestamp][_file sequence].json.gz
Więcej informacji można znaleźć w dowolnej z poszczególnych kontrolek zadania uogólnionego eksportu początkowego i kontrolce zadania inicjatora.
Ograniczanie początkowego eksportu wg daty
Domyślnie w procesie zadania "Początkowy eksport danych" eksportowane są wszystkie dane obiektu. W niektórych sytuacjach, zwykle w przypadku dużej ilości danych historycznych, może zaistnieć potrzeba ograniczenia eksportu do nowszych danych, na przykład danych z ostatnich kilku miesięcy.
Proces zadania początkowego eksportu obsługuje opcjonalny parametr zadania Ograniczenie według daty, którego można użyć w celu ograniczenia zakresu eksportowanych danych. Parametr odwołuje się do pola daty i żądanego przedziału czasowego pod względem liczby dni przed datą roboczą. Więcej informacji zawiera kontrolka zadania szablonu uogólnionego eksportu początkowego F1-GEIXP.
Bieżący eksport danych
Zmiany danych są śledzone przez algorytm audytu Pobieraj zmiany na potrzeby bieżącego eksportu obiektu obsługi (F1-MO-REGCHN). Algorytm rejestruje klucz główny zmienionego obiektu w wyznaczonej tabeli Aktualizacja eksportu danych, która służy jako kolejka zmienionych obiektów do wyeksportowania. Kolejka jest później wykorzystywana przez proces zadania bieżącego eksportu danych.
Reguła audytu jest dodawana do obiektu obsługi, gdy włączona jest opcja bieżącego eksportu danych w odpowiadającym mu rekordzie kontrolki eksportu danych. W ten sam sposób reguła audytu zostaje usunięta z obiektu obsługi po wyłączeniu opcji bieżącego eksportu.
W przeciwieństwie do procesu zadania eksportu początkowego, który wymaga zdefiniowania kontrolki zadania dotyczącej każdego kwalifikującego się obiektu obsługi, pojedynczy proces zadania jest używany do eksportowania bieżących zmian dokonanych we wszystkich obiektach.
-
Wszystkie zmiany w kolejce w tabeli "Aktualizacja eksportu danych" są eksportowane do wyznaczonego pliku eksportu bieżącego. Więcej informacji zawiera sekcja Zarządzanie dużą liczbą zaległości.
-
Wyeksportowany zostaje pełen zapis danych dotyczących tego zmienionego obiektu, aby uniknąć scalania dużych ilości danych po stronie rekordu docelowego.
-
Po wyeksportowaniu rekordy są usuwane z tabeli Aktualizacja eksportu danych.
Proces jest wielowątkowy, a dla każdego wątku domyślnie tworzony jest osobny plik. Opcjonalny parametr zadania umożliwia generowanie wielu mniejszych plików na wątek poprzez ustawienie limitu liczby rekordów zapisywanych w każdym pliku. Więcej informacji zawiera sekcja Rozmiar pliku.
INC_EXPORT_[batch run]_[thread]_[thread count]_[timestamp][_file sequence].json.gz Więcej informacji zawiera kontrolka zadania uogólnionego eksportu bieżącego (F1-GEEXO).
Rozmiar pliku
W procesie zadania eksportu początkowego domyślnie tworzony jest jeden plik na wątek. W przypadku niektórych obiektów o dużych rozmiarach może się okazać, że pliki będą zbyt duże, aby można było nimi zarządzać. Aby utworzyć wiele mniejszych plików dla określonego obiektu, należy ograniczyć liczbę rekordów zapisywanych w każdym pliku, ustawiając odpowiedni parametr w kontrolce zadania eksportu początkowego zdefiniowanej dla obiektu. Ten sam parametr można podać podczas uruchamiania procesu zadania "Proces inicjujący eksport początkowy". W takim przypadku wartość procesu inicjującego jest używana tylko wtedy, gdy odpowiednia wartość nie została zdefiniowana w rekordzie kontrolki zadania specyficznym dla obiektu.
Analogicznie w procesie zadania eksportu bieżącego domyślnie tworzony jest jeden plik na wątek. Aby utworzyć wiele mniejszych plików, należy ograniczyć liczbę rekordów zapisywanych w każdym pliku, ustawiając odpowiedni parametr w kontrolce zadania.
Aby uniknąć tworzenia zbyt wielu plików w jednym uruchomieniu zadania, system ustawia maksymalny limit około 500 plików na uruchomienie. Jeśli żądana liczba rekordów na plik powoduje, że liczba generowanych plików przekracza limit systemowy, rzeczywista użyta wartość jest dostosowywana do limitu systemowego.
Zarządzanie dużą liczbą zaległości
Gdy z jakiegoś powodu w kolejce bieżącego eksportu gromadzi się duża liczba zaległych zmian, eksportowanie następnej partii zajmuje więcej czasu, co opóźnia dalszy krok importu. Lepszym rozwiązaniem jest usuwanie zaległości w mniejszych "fragmentach", co umożliwi dalszemu procesowi importowanie ich w miarę udostępniania.
Liczbę rekordów eksportowanych w ramach procesu zadania można ograniczyć za pomocą parametru zadania Limit przetwarzania wątku. Po jego określeniu liczba rekordów eksportowanych w każdym wątku jest ograniczona na podstawie określonego limitu, a pozostałe rekordy zostaną wykorzystane w kolejnych uruchomieniach zadania. Zamiast czekać na następne zaplanowane uruchomienie zadania, można automatycznie uruchomić nowy proces zadania, jeśli takie żądanie zostanie wyraźnie przesłane za pomocą parametru zadania Automatyczne usuwanie zaległości.
Ważne jest, aby upewnić się, że zaległości są stopniowo usuwane, a kolejka wraca do swojego normalnego rozmiaru w odpowiednim czasie. Limit przetwarzania musi zatem zostać ustawiony na odpowiednią wartość, która będzie sprzyjać prawidłowemu usuwaniu zaległości z kolejki. W tym celu co najmniej 20% kolejki i nie mniej niż 100 000 rekordów musi zostać wykorzystanych w każdym uruchomieniu zadania we wszystkich wątkach. Jeśli określony limit nie spełnia minimalnego wymogu dotyczącego usuwania zaległości, wówczas limit przetwarzania jest odpowiednio dostosowywany.
Format rekordu
Ze względu na wydajność dane są pobierane i eksportowane bezpośrednio z bazy danych w ramach operacji odczytu zbiorczego. Z tego powodu użyta struktura nie odzwierciedla logicznego modelu danych obiektu, ale jego fizyczną listę tabel. Dane określonego wystąpienia są porządkowane według tabel, a następnie według wierszy w każdej tabeli i w dalszej kolejności według listy pól w formacie JSON każdego wiersza.
Poniżej opisano użyty format i strukturę:
{
"OBJ": "<mo name>",
"TIMESTAMP": "<export time in ISO format for example 2019-07-25T11:06:04.740615Z>",
"PK1": "<mo pk1 value>",
"PK2": "<mo pk2 value if any>", ← PK2-5 should only be included when applicable
"PK3": "<mo pk3 value if any>",
"PK4": "<mo pk4 value if any>",
"PK5": "<mo pk5 value if any>",
"DELETED": true, ← should only be included when the entity is deleted
"DATA":
{
"<MO table name 1>":
[
{<name value pairs of all fields in row 1 in that table>},
{<name value pairs of all fields in row 2 in that table>},...
{<name value pairs of all fields in row n in that table>},...
],
"<MO table name 2>":
[
{<name value pairs of all fields in row 1 in that table>},
{<name value pairs of all fields in row 2 in that table>},...
{<name value pairs of all fields in row n in that table>}
],...
"<MO table name n>":
[
{<name value pairs of all fields in row 1 in that table>},
{<name value pairs of all fields in row 2 in that table>},...
{<name value pairs of all fields in row n in that table>}
]
}
Uwagi dotyczące wartości i formatów pól:
-
Wszystkie pola dotyczące wiersza są uwzględniane, nawet jeśli pole jest puste lub ma wartość null.
-
Wszystkie wartości ciągów są pozbawiane nadmiarowych spacji końcowych, ale jeśli pole jest puste, jest eksportowane jako pusty ciąg "" a nie pole z wartością null.
-
W przypadku braku rekordów dotyczących obiektu w tabeli używana jest pusta tablica węzła tabeli.
-
Informacje dotyczące daty i godziny są przekształcane na strefę czasową UTC i eksportowane w formacie ISO, np. 2019-07-25T11:06:04.740615Z.
-
Usunięcia mają wyraźne oznaczenie w nagłówku.
Kolejność używania plików
Ważne jest, aby zastosować wszystkie pliki eksportu początkowego do obiektu obsługi przed zastosowaniem plików bieżących zmian, aby zapewnić spójność danych.
-
Należy stosować wszystkie pliki początkowego eksportu danych przed plikami eksportu bieżącego.
-
Należy stosować pliki początkowe do obiektu obsługi w kolejności według numeru uruchomienia.
-
Należy stosować pliki eksportu bieżącego w kolejności według numeru uruchomienia.
-
Jeśli dostępny jest nowy eksport początkowy, należy tymczasowo zmienić procedurę używania plików w następujący sposób:
-
Zatrzymanie używania plików eksportu bieżącego.
-
Zastosowanie nowych plików eksportu początkowego.
-
Wznowienie używania plików eksportu bieżącego.
-
Odzyskiwanie danych z utraconego pliku eksportu bieżącego
W procesie zadania eksportu bieżącego przechowywana jest kopia zapasowa wszystkich kluczy obiektów, które zostały wyeksportowane podczas określonego uruchomienia zadania, w wyznaczonej tabeli kopii zapasowych. W rzadkich sytuacjach, gdy plik eksportu bieżącego zostanie usunięty lub ulegnie uszkodzeniu przed jego przetworzeniem, można użyć tabeli kopii zapasowych w celu zidentyfikowania brakujących zmian i wyeksportowania ich ponownie.
W tej sytuacji do odzyskania danych należy użyć procesu zadania "Przywracanie kluczy eksportu uogólnionego" (F1-GERST). Proces identyfikuje obiekty, które zostały wyeksportowane podczas określonego uruchomienia zadania, i dodaje je z powrotem do kolejki bieżących zmian z tabeli kopii zapasowych. Obiekty zostaną następnie ponownie wyeksportowane w kolejnych uruchomieniach eksportu bieżącego. Ta metoda nie umożliwia przywrócenia dokładnej zawartości pierwotnego pliku, który został utracony, ponieważ nie można go odtworzyć. Zamiast tego proces zapewnia, że obiekty zawarte w utraconym pliku zostaną ponownie wyeksportowane.