Desarrollo local de aplicaciones de Oracle Cloud Infrastructure Data Flow y despliegue en la nube
Oracle Cloud Infrastructure Data Flow es un servicio de Apache Spark en la nube totalmente gestionado. Permite ejecutar aplicaciones de Spark a cualquier escala y con un trabajo administrativo o de configuración mínimo. Data Flow es ideal para programar trabajos fiables de procesamiento por lotes de larga duración.
Puede desarrollar aplicaciones de Spark sin estar conectado a la nube. Puede desarrollarlos, probarlos e iterarlos rápidamente en su PC portátil. Cuando estén listos, puede desplegarlos en Data Flow sin necesidad de volver a configurarlos, realizar cambios en el código ni aplicar perfiles de despliegue.
- La mayoría de las bibliotecas y el código de origen que se utilizan para ejecutar Data Flow están ocultos. Ya no necesitará coincidir con las versiones del SDK de Data Flow y dejará de tener conflictos de dependencia de terceros con Data Flow.
- Los SDK son compatibles con Spark, por lo que ya no necesita mover dependencias de terceros en conflicto, lo que le permite separar su aplicación de las bibliotecas para obtener compilaciones más rápidas, menos complicadas, más pequeñas y más flexibles.
- El nuevo archivo pom.xml de plantilla descarga y crea una copia casi idéntica de Data Flow en la máquina local. Puede ejecutar el depurador de pasos en la máquina local para detectar y resolver problemas antes de ejecutar su aplicación en Data Flow. Puede compilar y ejecutar exactamente en las mismas versiones de biblioteca que ejecuta Data Flow. Oracle puede decidir rápidamente si la incidencia es un problema con Data Flow o su código de aplicación.
Antes de empezar
Antes de empezar a desarrollar aplicaciones, necesita que lo siguiente esté configurado y funcionando:
- Una conexión a Oracle Cloud con la función Clave de API activada. Cargue el usuario en Identidad /Usuarios y confirme que puede crear claves de API.

- Una clave de API registrada y desplegada en el entorno local. Consulte Registro de una clave de API para obtener más información.
- Una instalación local de Apache Spark 2.4.4, 3.0.2, 3.2.1 o 3.5.0 en funcionamiento. Puede confirmarlo mediante la ejecución de spark-shell en la CLI.
- Apache Maven instalado. En las instrucciones y ejemplos se utiliza Maven para descargar las dependencias que necesita.
Antes de empezar, consulte Seguridad de ejecución en Data Flow. Utiliza un token de delegación que le permite realizar operaciones en la nube en su nombre. Cualquier cosa que su cuenta pueda hacer en la consola de de de Oracle Cloud Infrastructure, su trabajo de Spark puede hacerlo con Data Flow. Cuando se ejecuta en modo local, debe utilizar una clave de API que permita a la aplicación local realizar solicitudes autenticadas en varios servicios de Oracle Cloud Infrastructure.
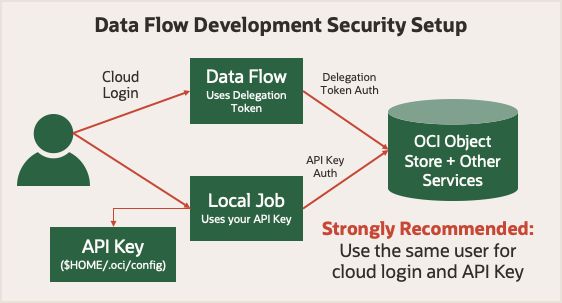
Para simplificar las cosas, utilice una clave de API generada para el mismo usuario que se haya utilizado al conectarse a la consola de Oracle Cloud Infrastructure. Significa que sus aplicaciones tienen los mismos privilegios que si las ejecuta local o en Data Flow.
1. Conceptos del desarrollo local
- Personalice la instalación local de Spark con los archivos de biblioteca de Oracle Cloud Infrastructure, de modo que se asemeje al entorno de tiempo de ejecución de Data Flow.
- Detecte dónde se está ejecuta su código.
- Configure de la forma adecuada el cliente HDFS de Oracle Cloud Infrastructure.
Para que pueda moverse sin problemas entre la computadora y Data Flow, debe utilizar determinadas versiones de Spark, Scala y Python en su configuración local. Agregue el archivo JAR del conector HDFS de Oracle Cloud Infrastructure. Agregue también diez bibliotecas de dependencias a la instalación de Spark que estén instaladas cuando la aplicación se ejecuta en Data Flow. En estos pasos se muestra cómo descargar e instalar estas diez bibliotecas de dependencias.
| Versión de Spark | Versión de Scala | Versión de Python |
|---|---|---|
| 3,5 | 2,12 | 3,11 |
| 3.2.1 | 2.12.15 | 3.8 |
| 3.0.2 | 2.12.10 | 3.6.8 |
| 2.4.4 | 2.11.12 | 3.6.8 |
CONNECTOR=com.oracle.oci.sdk:oci-hdfs-connector:3.3.4.1.4.2
mkdir -p deps
touch emptyfile
mvn install:install-file -DgroupId=org.projectlombok -DartifactId=lombok -Dversion=1.18.26 -Dpackaging=jar -Dfile=emptyfile
mvn org.apache.maven.plugins:maven-dependency-plugin:2.7:get -Dartifact=$CONNECTOR -Ddest=deps
mvn org.apache.maven.plugins:maven-dependency-plugin:2.7:get -Dartifact=$CONNECTOR -Ddest=deps -Dtransitive=true -Dpackaging=pom
mvn org.apache.maven.plugins:maven-dependency-plugin:2.7:copy-dependencies -f deps/*.pom -DoutputDirectory=.echo 'sc.getConf.get("spark.home")' | spark-shellscala> sc.getConf.get("spark.home")
res0: String = /usr/local/lib/python3.11/site-packages/pyspark/usr/local/lib/python3.11/site-packages/pyspark/jarsdeps contiene muchos archivos JAR, la mayoría de los cuales ya están disponibles en la instalación de Spark. Solo necesita copiar un subconjunto de estos archivos JAR en el entorno de Spark:bcpkix-jdk15to18-1.74.jar
bcprov-jdk15to18-1.74.jar
guava-32.0.1-jre.jar
jersey-media-json-jackson-2.35.jar
oci-hdfs-connector-3.3.4.1.4.2.jar
oci-java-sdk-addons-apache-configurator-jersey-3.34.0.jar
oci-java-sdk-common-*.jar
oci-java-sdk-objectstorage-extensions-3.34.0.jar
jersey-apache-connector-2.35.jar
oci-java-sdk-addons-apache-configurator-jersey-3.34.0.jar
jersey-media-json-jackson-2.35.jar
oci-java-sdk-objectstorage-generated-3.34.0.jar
oci-java-sdk-circuitbreaker-3.34.0.jar
resilience4j-circuitbreaker-1.7.1.jar
resilience4j-core-1.7.1.jar
vavr-match-0.10.2.jar
vavr-0.10.2.jardeps en el subdirectorio jars que ha encontrado en el paso 2.import com.oracle.bmc.hdfs.BmcFilesystemArchivos JAR desplegados correctamente 
Si hay un error, ha puesto los archivos en el lugar equivocado. En este ejemplo, hay un error:
Archivos JAR desplegados de forma incorrecta 
- Puede utilizar el valor
spark.masteren el objetoSparkConfque está definido en k8s://https://kubernetes.default.svc:443 cuando se ejecuta en Data Flow. - La variable de entorno
HOMEse define en/home/dataflowcuando se ejecuta en Data Flow.
En las aplicaciones PySpark, un objeto SparkConf recién creado está vacío. Para ver los valores correctos, utilice el método getConf de ejecución de SparkContext.
| Entorno de inicio |
Configuración de spark.master |
|---|---|
| Data Flow |
|
| spark-submit local |
spark.master: local[*] $HOME: variable |
| Eclipse |
Sin definir $HOME: variable |
Cuando se esté ejecutando en Data Flow, no cambie el valor de
spark.master. Si es así, su trabajo no utiliza todos los recursos que haya aprovisionado. Cuando la aplicación se ejecuta en Data Flow, el conector HDFS de Oracle Cloud Infrastructure se configura automáticamente. Cuando se ejecuta localmente, debe configurarlo usted mismo definiendo las propiedades de configuración del conector HDFS.
Como mínimo, debe actualizar el objeto SparkConf para definir valores para fs.oci.client.auth.fingerprint, fs.oci.client.auth.pemfilepath, fs.oci.client.auth.tenantId, fs.oci.client.auth.userId y fs.oci.client.hostname.
Si la clave de API tiene una frase de contraseña, debe definir fs.oci.client.auth.passphrase.
Estas variables se pueden definir después de crear la sesión. En el entorno de programación, utilice los SDK respectivos para cargar correctamente la configuración de la clave de API.
ConfigFileAuthenticationDetailsProvider según corresponda:import com.oracle.bmc.auth.ConfigFileAuthenticationDetailsProvider;
import com.oracle.bmc.ConfigFileReader;
//If your key is encrypted call setPassPhrase:
ConfigFileAuthenticationDetailsProvider authenticationDetailsProvider = new ConfigFileAuthenticationDetailsProvider(ConfigFileReader.DEFAULT_FILE_PATH, "<DEFAULT>");
configuration.put("fs.oci.client.auth.tenantId", authenticationDetailsProvider.getTenantId());
configuration.put("fs.oci.client.auth.userId", authenticationDetailsProvider.getUserId());
configuration.put("fs.oci.client.auth.fingerprint", authenticationDetailsProvider.getFingerprint());
String guessedPath = new File(configurationFilePath).getParent() + File.separator + "oci_api_key.pem";
configuration.put("fs.oci.client.auth.pemfilepath", guessedPath);
// Set the storage endpoint:
String region = authenticationDetailsProvider.getRegion().getRegionId();
String hostName = MessageFormat.format("https://objectstorage.{0}.oraclecloud.com", new Object[] { region });
configuration.put("fs.oci.client.hostname", hostName);oci.config.from_file según corresponda:import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
# Check to see if we're in Data Flow or not.
if os.environ.get("HOME") == "/home/dataflow":
spark_session = SparkSession.builder.appName("app").getOrCreate()
else:
conf = SparkConf()
oci_config = oci.config.from_file(oci.config.DEFAULT_LOCATION, "<DEFAULT>")
conf.set("fs.oci.client.auth.tenantId", oci_config["tenancy"])
conf.set("fs.oci.client.auth.userId", oci_config["user"])
conf.set("fs.oci.client.auth.fingerprint", oci_config["fingerprint"])
conf.set("fs.oci.client.auth.pemfilepath", oci_config["key_file"])
conf.set(
"fs.oci.client.hostname",
"https://objectstorage.{0}.oraclecloud.com".format(oci_config["region"]),
)
spark_builder = SparkSession.builder.appName("app")
spark_builder.config(conf=conf)
spark_session = spark_builder.getOrCreate()
spark_context = spark_session.sparkContext
En SparkSQL, la configuración se gestiona de forma diferente. Estos valores se transfieren mediante el conmutador --hiveconf. Para ejecutar consultas SQL de Spark, utilice un script de contenedor similar al ejemplo. Cuando ejecuta el script en Data Flow, esta configuración se realiza automáticamente para usted.
#!/bin/sh
CONFIG=$HOME/.oci/config
USER=$(egrep ' user' $CONFIG | cut -f2 -d=)
FINGERPRINT=$(egrep ' fingerprint' $CONFIG | cut -f2 -d=)
KEYFILE=$(egrep ' key_file' $CONFIG | cut -f2 -d=)
TENANCY=$(egrep ' tenancy' $CONFIG | cut -f2 -d=)
REGION=$(egrep ' region' $CONFIG | cut -f2 -d=)
REMOTEHOST="https://objectstorage.$REGION.oraclecloud.com"
spark-sql \
--hiveconf fs.oci.client.auth.tenantId=$TENANCY \
--hiveconf fs.oci.client.auth.userId=$USER \
--hiveconf fs.oci.client.auth.fingerprint=$FINGERPRINT \
--hiveconf fs.oci.client.auth.pemfilepath=$KEYFILE \
--hiveconf fs.oci.client.hostname=$REMOTEHOST \
-f script.sql
Los ejemplos anteriores solo cambian la forma en que se crea el contexto de Spark. No es necesario cambiar nada más en la aplicación de Spark, por lo que puede desarrollar otros aspectos de la aplicación de Spark como lo haría normalmente. Al desplegar la aplicación Spark en Data Flow, no es necesario cambiar el código ni la configuración.
2. Creación de "archivos Fat JAR" para aplicaciones de Java
Las aplicaciones de Java y Scala generalmente necesitan incluir más dependencias en un archivo JAR conocido como "Fat JAR".
Si utiliza Maven, puede hacerlo mediante el plugin Shade. Los siguientes ejemplos son de archivos pom.xml de Maven. Puede utilizarlos como punto de partida para su proyecto. Al crear la aplicación, las dependencias se descargan e insertan automáticamente en el entorno de tiempo de ejecución.
Si utiliza Spark 3.5.0 o 3.2.1, este capítulo no se aplica. En su lugar, siga el capítulo 2. Gestión de dependencias de Java para aplicaciones Apache Spark en Data Flow.
Esta parte pom.xml incluye las versiones adecuadas de la biblioteca de Spark y Oracle Cloud Infrastructure para Data Flow (Spark 3.0.2). Se aplica a Java 8 y oculta los archivos de clases habituales con conflictos.
<properties>
<oci-java-sdk-version>1.25.2</oci-java-sdk-version>
</properties>
<dependencies>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-hdfs-connector</artifactId>
<version>3.2.1.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-core</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-objectstorage</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.2</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.0</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>example.Example</mainClass>
</transformer>
</transformers>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<relocations>
<relocation>
<pattern>com.oracle.bmc</pattern>
<shadedPattern>shaded.com.oracle.bmc</shadedPattern>
<includes>
<include>com.oracle.bmc.**</include>
</includes>
<excludes>
<exclude>com.oracle.bmc.hdfs.**</exclude>
</excludes>
</relocation>
</relocations>
<artifactSet>
<excludes>
<exclude>org.bouncycastle:bcpkix-jdk15on</exclude>
<exclude>org.bouncycastle:bcprov-jdk15on</exclude>
<!-- Including jsr305 in the shaded jar causes a SecurityException
due to signer mismatch for class "javax.annotation.Nonnull" -->
<exclude>com.google.code.findbugs:jsr305</exclude>
</excludes>
</artifactSet>
</configuration>
</plugin>
</plugins>
</build>Esta parte pom.xml incluye las versiones adecuadas de la biblioteca de Spark y Oracle Cloud Infrastructure para Data Flow (Spark 2.4.4). Se aplica a Java 8 y oculta los archivos de clases habituales con conflictos.
<properties>
<oci-java-sdk-version>1.15.4</oci-java-sdk-version>
</properties>
<dependencies>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-hdfs-connector</artifactId>
<version>2.7.7.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-core</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-objectstorage</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.4</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>2.4.4</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.0</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>example.Example</mainClass>
</transformer>
</transformers>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<relocations>
<relocation>
<pattern>com.oracle.bmc</pattern>
<shadedPattern>shaded.com.oracle.bmc</shadedPattern>
<includes>
<include>com.oracle.bmc.**</include>
</includes>
<excludes>
<exclude>com.oracle.bmc.hdfs.**</exclude>
</excludes>
</relocation>
</relocations>
<artifactSet>
<excludes>
<exclude>org.bouncycastle:bcpkix-jdk15on</exclude>
<exclude>org.bouncycastle:bcprov-jdk15on</exclude>
<!-- Including jsr305 in the shaded jar causes a SecurityException
due to signer mismatch for class "javax.annotation.Nonnull" -->
<exclude>com.google.code.findbugs:jsr305</exclude>
</excludes>
</artifactSet>
</configuration>
</plugin>
</plugins>
</build>3. Prueba local de la aplicación
Antes de desplegar la aplicación, puede probarla localmente para asegurarse de que funciona. Hay tres técnicas que puede utilizar. Seleccione la que más le convenga. En estos ejemplos se asume que el artefacto de la aplicación se denomina application.jar (para Java) o application.py (para Python).
- Data Flow oculta la mayor parte del código fuente y las bibliotecas que utiliza para ejecutarse, por lo que las versiones del SDK de Data Flow ya no necesitan coincidencia y no deben producirse conflictos de dependencia de terceros con Data Flow.
- Spark se ha actualizado para que los SDK de OCI ahora sean compatibles con él. Esto significa que las dependencias de terceros en conflicto no necesitan moverse, por lo que las bibliotecas de aplicaciones y bibliotecas se pueden separar para compilaciones más rápidas, menos complicadas, más pequeñas y más flexibles.
- El nuevo archivo pom.xml de plantilla descarga y crea una copia casi idéntica de Data Flow en la máquina local de un desarrollador. Esto significa que:
- Los desarrolladores pueden ejecutar el depurador de pasos en su máquina local para detectar y resolver problemas rápidamente antes de ejecutarlo en Data Flow.
- Los desarrolladores pueden compilar y ejecutar exactamente en las mismas versiones de biblioteca que ejecuta Data Flow. Por lo tanto, el equipo de Data Flow puede decidir rápidamente si un problema es un problema con Data Flow o el código de aplicación.
Método 1: Ejecución desde el IDE
Si ha desarrollado un IDE como Eclipse, no necesita hacer nada más que hacer clic en Ejecutar y seleccionar la clase principal adecuada. 
Cuando se ejecuta, es normal que Spark muestre mensajes de advertencia en la consola, lo que le permite saber que se está llamando a Spark. 
Método 2: Ejecución de PySpark desde la línea de comandos
python3 application.py$ python3 example.py
Warning: Ignoring non-Spark config property: fs.oci.client.hostname
Warning: Ignoring non-Spark config property: fs.oci.client.auth.fingerprint
Warning: Ignoring non-Spark config property: fs.oci.client.auth.tenantId
Warning: Ignoring non-Spark config property: fs.oci.client.auth.pemfilepath
Warning: Ignoring non-Spark config property: fs.oci.client.auth.userId
20/08/01 06:52:00 WARN Utils: Your hostname resolves to a loopback address: 127.0.0.1; using 192.168.1.41 instead (on interface en0)
20/08/01 06:52:00 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
20/08/01 06:52:01 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableMétodo 3: Uso de Spark-Submit
La utilidad spark-submit se incluye en la distribución de Spark. Utilice este método en algunas situaciones, por ejemplo, cuando una aplicación PySpark necesita archivos JAR adicionales.
spark-submit:spark-submit --class example.Example example.jarComo necesita proporcionar el nombre de la clase principal a Data Flow, este código es una buena forma de confirmar que está utilizando el nombre de clase correcto. Recuerde que los nombres de clase son sensibles a mayúsculas/minúsculas.
spark-submit para ejecutar una aplicación PySpark que necesita archivos JAR de Oracle JDBC:
spark-submit \
--jars java/oraclepki-18.3.jar,java/ojdbc8-18.3.jar,java/osdt_cert-18.3.jar,java/ucp-18.3.jar,java/osdt_core-18.3.jar \
example.py4. Desplegar la aplicación
- Copie el artefacto de aplicación (archivo
jar, script de Python o script de SQL) en Oracle Cloud Infrastructure Object Storage. - Si la aplicación de Java tiene dependencias no proporcionadas por Data Flow, recuerde copiar el archivo
jardel ensamblaje. - Cree una aplicación de Data Flow que haga referencia a este artefacto en Oracle Cloud Infrastructure Object Storage.
Después del paso 3, puede ejecutar la aplicación tantas veces como desee. Para obtener más información, el tutorial Introducción a Oracle Cloud Infrastructure Data Flow le guiará a través de este proceso paso a paso.
Siguiente paso
Ahora sabe cómo desarrollar sus aplicaciones localmente y desplegarlas en Data Flow.