Introducción a Oracle Cloud Infrastructure Data Flow
En este tutorial se presenta Oracle Cloud Infrastructure Data Flow, un servicio que le permite ejecutar cualquier aplicación de Apache Spark a cualquier escala sin infraestructura que desplegar o gestionar.
Si ha utilizado Spark antes, podrá sacar más provecho de este tutorial, si bien no se necesita ningún conocimiento previo de Spark. Se le han proporcionado todas las aplicaciones y datos de Spark necesarios. En este tutorial se muestra cómo Data Flow hace que la ejecución de aplicaciones de Spark sea fácil, repetible, segura y sencilla en toda la empresa.
- Cómo utilizar Java para realizar ETL en una aplicación de Data Flow.
- Cómo utilizar SparkSQL en una aplicación SQL.
- Cómo crear y ejecutar una aplicación de Python para realizar una tarea de Machine Learning sencilla.
También puede realizar el tutorial mediante spark-submit desde la CLI o spark-submit y Java SDK.
- No tiene servidor, lo que significa que no necesita expertos para aprovisionar, aplicar parches, actualizar o mantener los clusters de Spark. Esto significa que se podrá centrar en el código de Spark y solo en eso.
- Incluye operaciones y ajustes simples. El acceso a la interfaz de usuario de Spark es una selección y se rige por políticas de autorización de IAM. Si un usuario se queja porque un trabajo se está ejecutando de forma demasiada lenta, cualquier usuario con acceso a la ejecución puede abrir la interfaz de usuario de Spark y saber cuál es la causa raíz. Acceder al servidor de historiales de Spark de los trabajos que ya se hayan realizado es muy sencillo.
- Es idóneo para el procesamiento por lotes. Las API de REST capturan y ponen a disposición automáticamente la salida de la aplicación. ¿Necesita ejecutar un trabajo SQL de Spark de cuatro horas y cargar los resultados en el sistema de gestión de pipelines? En Data Flow, solo recibirá dos llamadas a la API de REST.
- Cuenta con control consolidado. Data Flow ofrece una vista consolidada de todas las aplicaciones de Spark, de quién las están ejecutando y de lo que consumen. ¿Desea saber qué aplicaciones están escribiendo más datos y quién las está ejecutando? Solo hay que ordenar por la columna Datos escritos. ¿Se está ejecutando un trabajo durante demasiado tiempo? Cualquier usuario que tenga los permisos correctos de IAM puede ver el trabajo y detenerlo.

Antes de empezar
Para realizar correctamente este tutorial, debe haber configurado su arrendamiento y puede acceder al flujo de datos.
Para que se pueda ejecutar Data Flow, debe otorgar permisos que permitan la captura de logs eficaz y la gestión de ejecuciones. Consulte la sección Configuración de la administración de la Guía de servicio de Data Flow y siga las instrucciones proporcionadas en ella.
- En la consola, seleccione el menú de navegación para mostrar la lista de servicios disponibles.
- Seleccione Analytics & AI.
- En Big Data, seleccione Data Flow.
- Seleccione Aplicaciones.
1. ETL con Java
Ejercicio para aprender a crear una aplicación de Java en Data Flow
Los pasos que se indican a continuación son para utilizar la IU de la consola. Puede resolver este ejercicio con spark-submit desde la CLI o spark-submit con Java SDK.
El primer paso más habitual en las aplicaciones de procesamiento de datos es tomar datos de un origen y convertirlos en un formato adecuado para la generación de informes y otros métodos de análisis. En una base de datos habría que cargar un archivo plano en ella y que crear los índices. En Spark, el primer paso es limpiar y convertir los datos de un formato de texto en formato de Parquet. Parquet es un formato binario optimizado que soporta lecturas eficaces, lo que lo hace idóneo para la generación de informes y el análisis. En este ejercicio, toma datos de origen, los convierte en Parquet y, a continuación, realiza una serie de acciones interesantes con ellos. El juego de datos es Berlin Airbnb Data, descargado del sitio web de Kaggle según las condiciones de la licencia Creative Commons CC0 1.0 Universal (CC0 1.0) "Dedicación de Dominio Público".

Los datos se proporcionan en formato CSV y el primer paso consiste en convertir estos datos en Parquet y almacenarlos en el almacén de objetos para realizar el procesamiento descendente. Se proporciona una aplicación Spark, denominada oow-lab-2019-java-etl-1.0-SNAPSHOT.jar, para realizar esta conversión. El objetivo es crear una aplicación de Data Flow que ejecute esta aplicación Spark y ejecutarla con los parámetros correctos. Debido a que está empezando, este ejercicio le guía por pasos y proporciona los parámetros que necesita. Posteriormente, usted tendrá que proporcionar los parámetros, por lo que debe entender lo que está introduciendo y por qué.
Cree una aplicación Java de Data Flow desde la consola, o con Spark-submit desde la línea de comandos o mediante SDK.
Cree una aplicación Java en Data Flow desde la consola.
Creación de una aplicación de Data Flow.
- Vaya al servicio Data Flow en la consola. Para ello, amplíe el menú de hamburguesa de la parte superior izquierda y vaya a la parte inferior.
- Resalte Data Flow y, a continuación, seleccione Aplicaciones. Seleccione el compartimento en el que desea que se creen las aplicaciones de Data Flow. Por último, seleccione Crear aplicación.

- Seleccione Aplicación Java e introduzca un nombre para la aplicación, por ejemplo,
Tutorial Example 1.
- Desplácese hacia abajo hasta Configuración de recursos. Deje para todos estos valores su configuración por defecto.

- Desplácese hacia abajo hasta Configuración de la aplicación. Configure la aplicación de la siguiente forma:
-
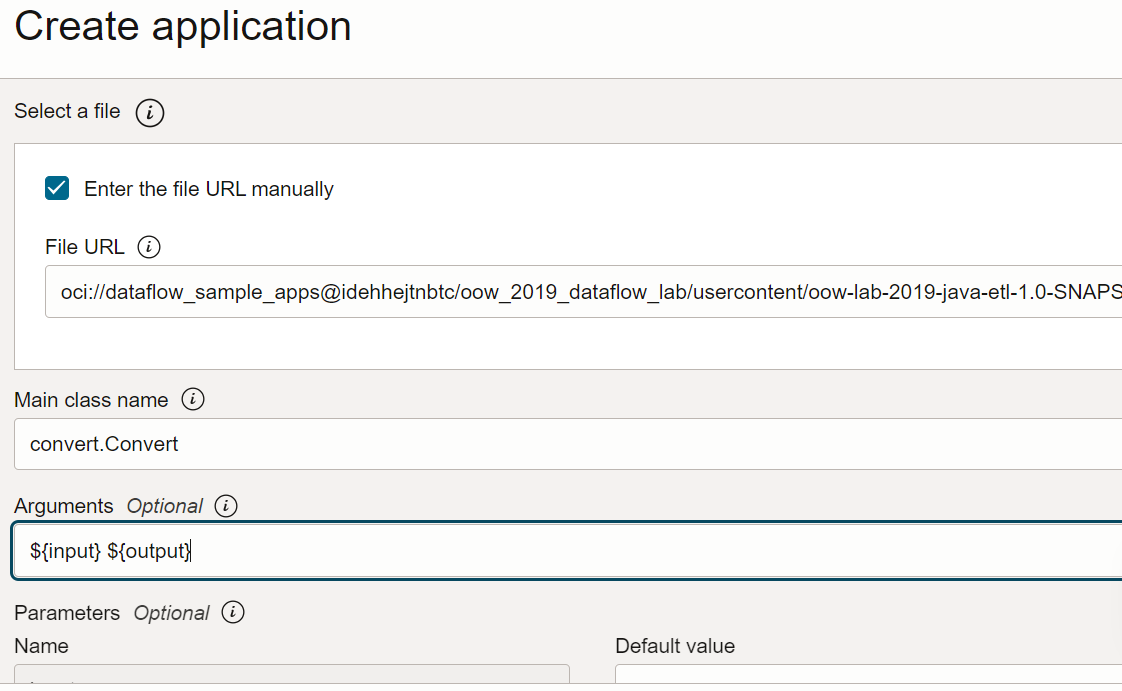
Dirección URL de archivo: es la ubicación del archivo JAR de Object Storage. La ubicación de esta aplicación es:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow-lab-2019-java-etl-1.0-SNAPSHOT.jar -
Nombre de la clase principal: las aplicaciones de Java necesitan un nombre de clase principal que depende de la aplicación. Para este ejercicio, introduzca
convert.Convert -
Argumentos: la aplicación Spark espera dos parámetros de línea de comandos, uno para la entrada y otro para la salida. En el campo Argumentos, introduzca Se le solicitarán valores por defecto y es una buena idea introducirlos ahora.
${input} ${output}
-
Dirección URL de archivo: es la ubicación del archivo JAR de Object Storage. La ubicación de esta aplicación es:
- Los argumentos de entrada y salida son:
-
Entrada:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/kaggle_berlin_airbnb_listings_summary.csv -
Salida:
oci://<yourbucket>@<namespace>/optimized_listings
Vuelva a comprobar la configuración de la aplicaciones para confirmar que tiene una apariencia similar a la siguiente:
 Nota
Nota
Debe personalizar la ruta de acceso de salida para que apunte a un cubo del inquilino. -
Entrada:
- Cuando haya terminado, seleccione Crear. Cuando se haya creado la aplicación, la verá en la lista Aplicación.

Felicidades! Ha creado su primera aplicación de Data Flow. Ahora puede ejecutarla.
Utilice spark-submit y CLI para crear una aplicación Java.
Complete el ejercicio para crear una aplicación Java en Data Flow mediante spark-submit y el SDK de Java.
Estos son los archivos para ejecutar este ejercicio y están disponibles en los siguientes URI públicos de Object Storage:
- Archivos de entrada en formato CSV:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/kaggle_berlin_airbnb_listings_summary.csv - Archivo JAR:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow-lab-2019-java-etl-1.0-SNAPSHOT.jar
Una vez que hemos creado una aplicación Java, puede ejecutarla.
- Si ha seguido los pasos con precisión, todo lo que tiene que hacer es resaltar la aplicación en la lista, seleccionar el menú Acciones y seleccionar Ejecutar.
- Tiene la opción de personalizar parámetros antes de ejecutar la aplicación. En su caso, ha introducido los valores precisos con anticipación y puede empezar la ejecución haciendo clic en Ejecutar.

-
Si la aplicación se está ejecutando, puede cargar la IU de Spark para supervisar el progreso. En el menú Acciones de la ejecución en cuestión, seleccione IU de Spark.

- Se le redirigirá automáticamente a la interfaz de usuario de Apache Spark, que es útil para realizar la depuración y el ajuste del rendimiento.

-
Después de aproximadamente un minuto, la ejecución muestra la finalización correcta con el estado
Succeeded:
-
Aumente el detalle de la ejecución para ver más información y desplácese hasta la parte inferior para ver una lista de logs.

-
Al seleccionar el archivo spark_application_stdout.log.gz, verá la salida del log,
Conversion was successful:
- También puede desplazarse al bucket de almacenamiento de objetos de salida para confirmar que se han creado nuevos archivos.

Las aplicaciones posteriores utilizan estos nuevos archivos. Asegúrese de que puede verlos en su bucket antes de pasar a los ejercicios siguientes.
2. SparkSQL simplificado
En este ejercicio, se ejecuta un script SQL para la creación de perfiles básicos de un juego de datos.
En este ejercicio se utiliza la salida que ha generado en 1. ETL con Java. Debe haberlo completado correctamente antes de poder probar este.
Los pasos que se indican a continuación son para utilizar la IU de la consola. Puede resolver este ejercicio con spark-submit desde la CLI o spark-submit con Java SDK.
Al igual que con otras aplicaciones de Data Flow, los archivos SQL se almacenan en el almacenamiento de objetos y se pueden compartir entre varios usuarios de SQL. Para ayudar a esto, Data Flow permite parametrizar scripts SQL y personalizarlos en tiempo de ejecución. Al igual que ocurre con otras aplicaciones, puede proporcionar valores por defecto para los parámetros que a menudo sirven como valiosas pistas para las personas que ejecutan estos scripts.
El script SQL se puede usar directamente en la aplicación Data Flow y no es necesario que cree una copia. El script se reproduce aquí para ilustrar algunos aspectos.
Texto de referencia del script de SparkSQL: 
- El script comienza con la creación de las tablas SQL que necesitamos. Actualmente, Data Flow no tiene un catálogo SQL persistente, por lo que todos los scripts deben empezar con la definición de las tablas que necesitan.
- La ubicación de la tabla se define como
${location}. Es un parámetro que el usuario debe proporcionar en tiempo de ejecución. Esto proporciona a Data Flow la flexibilidad necesaria para utilizar un script para procesar varias ubicaciones diferentes y para compartir código entre diferentes usuarios. Para este laboratorio, es necesario personalizar${location}para que apunte a la ubicación de salida utilizada en el ejercicio 1. - Como veremos, la salida del script SQL se captura y se pone a nuestra disposición en Ejecutar.
- En Data Flow, cree una aplicación SQL, seleccione SQL como tipo y acepte los recursos por defecto.

- En Configuración de la aplicación, configure la aplicación SQL de la siguiente forma:
-
Dirección URL de archivo: es la ubicación del archivo SQL de Object Storage. La ubicación de esta aplicación es:
oci://oow_2019_dataflow_lab@idehhejtnbtc/oow_2019_dataflow_lab/usercontent/oow_lab_2019_sparksql_report.sql -
Argumentos: el script SQL espera un parámetro, la ubicación de la salida del paso anterior. Seleccione Agregar parámetro e introduzca un parámetro denominado
locationcon el valor utilizado como ruta de acceso de salida en el paso a, según la plantillaoci://[bucket]@[namespace]/optimized_listings
Cuando termine, confirme que la configuración de la aplicación tiene un aspecto similar al siguiente:

-
Dirección URL de archivo: es la ubicación del archivo SQL de Object Storage. La ubicación de esta aplicación es:
- Personalice el valor de la ubicación con una ruta de acceso válida de su arrendamiento.
- Guardar la aplicación y ejecutarla desde la lista Aplicaciones.

- Una vez finalizada la ejecución, ábrala:

- Acceda a los logs de ejecución:

- Abra spark_application_stdout.log.gz y confirme que la salida coincide con la siguiente. Nota
Puede que las filas aparezcan en un orden diferente al de la imagen, pero los valores deben coincidir.
- En función de su función de creación de perfiles SQL, puede concluir diciendo que en este juego de datos, Neukolln tiene el precio de lista medio más bajo con 46,57 $, mientras que Charlottenburg-Wilmersdorf tiene la media más alta con 114,27 $ (Nota: El juego de datos de origen muestra los precios en USD en lugar de en EUR).
En este ejercicio se han mostrado algunos aspectos clave de Data Flow. Cuando una aplicación SQL está en su lugar, cualquier persona puede ejecutarla fácilmente sin preocuparse por la capacidad del cluster, el acceso a los datos y su retención, la gestión de credenciales u otras consideraciones de seguridad. Por ejemplo, un analista empresarial puede utilizar fácilmente los informes basados en Spark con Data Flow.
3. Machine Learning con PySpark
Utilice PySpark para realizar una tarea de Machine Learning sencilla sobre los datos de entrada.
En este ejercicio se utiliza el resultado de 1. ETL con Java como datos de entrada. Debe haber completado correctamente el primer ejercicio antes de empezar este. Esta vez, el objetivo es identificar las mejores ofertas entre varios anuncios de Airbnb utilizando algoritmos de Machine Learning de Spark.
Los pasos que se indican a continuación son para utilizar la IU de la consola. Puede resolver este ejercicio con spark-submit desde la CLI o spark-submit con Java SDK.
Puede utilizar una aplicación PySpark directamente en las aplicaciones de Data Flow. No es necesario crear una copia.
Aquí se proporciona el texto de referencia del script de PySpark para ilustrar algunos aspectos: 
- El script de Python espera un argumento de la línea de comandos (resaltado en rojo). Cuando crea la aplicación de Data Flow, necesita crear un parámetro que el usuario definirá en la ruta de acceso de entrada.
- El script utiliza la regresión lineal para predecir un precio por anuncio y encuentra la mejor oferta restando el precio de lista de la predicción. El valor más negativo indica la mejor relación calidad-precio por modelo.
- El modelo de este script está simplificado y solo tiene en cuenta la superficie en pies cuadrados. En una configuración real, se utilizarían más variables, como el vecindario y otras variables de predictor importantes.
Cree una aplicación PySpark desde la consola o con spark-submit desde la línea de comandos o mediante SDK.
Cree una aplicación PySpark en Data Flow mediante la consola.
-
Cree una aplicación y seleccione el tipo Python.

-
Vuelva a comprobar la configuración de la aplicación y confirme que es similar a lo siguiente:

Cree una aplicación PySpark en Data Flow mediante Spark-submit y CLI.
Cree una aplicación PySpark en Data Flow mediante Spark-submit y SDK.
- Ejecute la aplicación desde la lista Aplicación.

-
Cuando la ejecución termine, ábrala y desplácese a los logs.

- Abra el archivo spark_application_stdout.log.gz. La salida debe ser idéntica a la siguiente:

-
En esta salida ve que el ID de anuncio 690578 es la mejor oferta con un precio previsto de 313,70 $ en comparación con el precio de lista de 35,00 $ con una superficie en pies cuadrados de 4.639 pies cuadrados. Si suena demasiado bien como para ser verdad, el ID único significa que puede profundizar en los datos para comprender mejor si se trata a ciencia cierta del trato del siglo. De nuevo, un analista de negocio sin duda podría utilizar la salida de este algoritmo de Machine Learning para un análisis más detallado.
Siguiente paso
Ahora puede crear y ejecutar aplicaciones Java, Python o SQL con Data Flow y explorar los resultados.
Data Flow gestiona todos los detalles del despliegue, el desmontaje, la gestión de logs, la seguridad y el acceso a la interfaz de usuario. Con Data Flow, se centra en el desarrollo de aplicaciones Spark sin preocuparse por la infraestructura.