Développer des applications Flux de données pour Oracle Cloud Infrastructure localement, déployer dans le nuage
Oracle Cloud Infrastructure Data Flow est un service en nuage Apache Spark entièrement géré. Il vous permet d'exécuter des applications Spark à l'échelle de votre choix et requiert un minimum de travail d'administration et de configuration. Le service Flux de données est idéal pour planifier des tâches de traitement par lots à long terme fiables.
Vous pouvez développer des applications Spark sans être connecté au nuage. Vous pouvez les développer, les tester et les itérer rapidement sur votre ordinateur portable. Lorsqu'elles sont prêtes, vous pouvez les déployer dans le service de flux de données sans avoir à les reconfigurer, à modifier le code ni à appliquer des profils de déploiement.
- La plupart du code source et des bibliothèques utilisés pour exécuter le service de flux de données sont masqués. Il n'est plus nécessaire de mettre en correspondance les versions de la trousse SDK du service de flux de données et il n'y a plus de dépendance de tierce partie en conflit avec le service de flux de données.
- Les trousses SDK sont compatibles avec Spark. Vous n'avez donc plus besoin de déplacer les dépendances de tierce partie en conflit, ce qui vous permet de séparer votre application de vos bibliothèques pour des compilations plus rapides, moins compliquées, plus petites et plus flexibles.
- Le nouveau fichier de modèle pom.xml télécharge et crée une copie quasi identique du service de flux de données sur votre machine locale. Vous pouvez exécuter le débogueur d'étape sur votre machine locale pour détecter et résoudre les problèmes avant d'exécuter votre application dans le service de flux de données. Vous pouvez compiler et exécuter les mêmes versions de bibliothèque que le service de flux de données. Oracle peut rapidement décider si votre problème concerne le service de flux de données ou le code de votre application.
Avant de commencer
Avant de commencer à développer vos applications, vous devez disposer des éléments suivants configurés et fonctionnels :
- Un identificateur Oracle Cloud avec la fonctionnalité de clés d'API activée. Chargez votre utilisateur sous Identité /Utilisateurs et vérifiez que vous avez la possibilité de créer des clés d'API.

- Une clé d'API enregistrée et déployée dans votre environnement local. Pour plus d'informations, voir Enregistrer une clé d'API.
- Une installation locale fonctionnelle d'Apache Spark 2.4.4, 3.0.2, 3.2.1 ou 3.5.0. Pour vérifier cet élément, exécutez spark-shell dans l'interface de ligne de commande.
- Apache Maven installé. Les instructions et exemples utilisent Maven pour télécharger les dépendances dont vous avez besoin.
Avant de commencer, voir Sécurité de l'exécution dans Flux de données. Il utilise un jeton de délégation qui lui permet d'effectuer des opérations en nuage en votre nom. Tout ce que votre compte peut faire dans la console Oracle Cloud Infrastructure, votre tâche Spark peut faire à l'aide du service Flux de données. Lors de l'exécution en mode local, vous devez utiliser une clé d'API qui permet à votre application locale d'envoyer des demandes authentifiées à divers services Oracle Cloud Infrastructure.
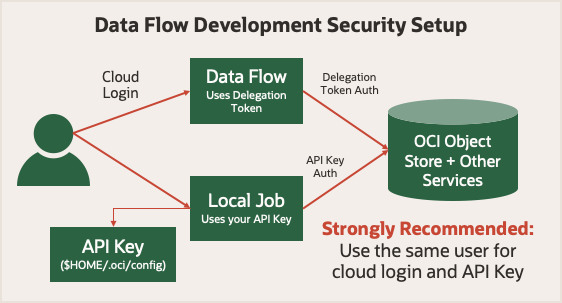
Pour vous simplifier la tâche, utilisez une clé d'API générée pour le même utilisateur que celui utilisé pour la connexion à la console Oracle Cloud Infrastructure. Cela signifie que vos applications ont les mêmes privilèges, que vous les exécutez localement ou dans le service Flux de données.
1. Concepts de développement local
- Personnalisez votre installation Spark locale avec les fichiers de bibliothèque Oracle Cloud Infrastructure, de sorte qu'elle ressemble à l'environnement d'exécution du service de flux de données.
- Identifiez l'emplacement où votre code s'exécute.
- Configurez correctement le client HDFS pour Oracle Cloud Infrastructure.
Afin de pouvoir passer facilement de votre ordinateur au service Flux de données, vous devez utiliser certaines versions de Spark, Scala et Python dans votre configuration locale. Ajoutez le fichier JAR du connecteur HDFS Oracle Cloud Infrastructure. Ajoutez également dix bibliothèques de dépendances à votre installation Spark, qui sont installées lors de l'exécution de votre application dans le service de flux de données. Les étapes ci-dessous montrent comment télécharger et installer ces dix bibliothèques de dépendances.
| Version de Spark | Version de Scala | Version de Python |
|---|---|---|
| 3.5 | 2.12 | 3.11 |
| 3.2.1 | 2.12.15 | 3.8 |
| 3.0.2 | 2.12.10 | 3.6.8 |
| 2.4.4 | 2.11.12 | 3.6.8 |
CONNECTOR=com.oracle.oci.sdk:oci-hdfs-connector:3.3.4.1.4.2
mkdir -p deps
touch emptyfile
mvn install:install-file -DgroupId=org.projectlombok -DartifactId=lombok -Dversion=1.18.26 -Dpackaging=jar -Dfile=emptyfile
mvn org.apache.maven.plugins:maven-dependency-plugin:2.7:get -Dartifact=$CONNECTOR -Ddest=deps
mvn org.apache.maven.plugins:maven-dependency-plugin:2.7:get -Dartifact=$CONNECTOR -Ddest=deps -Dtransitive=true -Dpackaging=pom
mvn org.apache.maven.plugins:maven-dependency-plugin:2.7:copy-dependencies -f deps/*.pom -DoutputDirectory=.echo 'sc.getConf.get("spark.home")' | spark-shellscala> sc.getConf.get("spark.home")
res0: String = /usr/local/lib/python3.11/site-packages/pyspark/usr/local/lib/python3.11/site-packages/pyspark/jarsdeps contient de nombreux fichiers JAR, dont la plupart sont déjà disponibles dans l'installation Spark. Il vous suffit de copier un sous-ensemble de ces fichiers JAR dans l'environnement Spark :bcpkix-jdk15to18-1.74.jar
bcprov-jdk15to18-1.74.jar
guava-32.0.1-jre.jar
jersey-media-json-jackson-2.35.jar
oci-hdfs-connector-3.3.4.1.4.2.jar
oci-java-sdk-addons-apache-configurator-jersey-3.34.0.jar
oci-java-sdk-common-*.jar
oci-java-sdk-objectstorage-extensions-3.34.0.jar
jersey-apache-connector-2.35.jar
oci-java-sdk-addons-apache-configurator-jersey-3.34.0.jar
jersey-media-json-jackson-2.35.jar
oci-java-sdk-objectstorage-generated-3.34.0.jar
oci-java-sdk-circuitbreaker-3.34.0.jar
resilience4j-circuitbreaker-1.7.1.jar
resilience4j-core-1.7.1.jar
vavr-match-0.10.2.jar
vavr-0.10.2.jardeps dans le sous- répertoire jars trouvé à l'étape 2.import com.oracle.bmc.hdfs.BmcFilesystemFichiers JAR déployés correctement 
S'il y a une erreur, alors vous avez placé les fichiers au mauvais endroit. Dans cet exemple, il y a une erreur :
Fichiers JAR déployés incorrectement 
- Vous pouvez utiliser la valeur de
spark.masterdans l'objetSparkConf, réglée à k8s ://https://kubernetes.default.svc:443 lors de l'exécution dans le service Flux de données. - La variable d'environnement
HOMEest réglée à/home/dataflowlors de l'exécution dans le service Flux de données.
Dans les applications PySpark, un objet SparkConf qui vient d'être créé est vide. Pour voir les valeurs correctes, utilisez la méthode getConf pour exécuter SparkContext.
| Environnement de lancement |
Valeur de spark.master |
|---|---|
| Flux de données |
|
| Spark-submit local |
spark.master: local[*] $HOME: Variable |
| Eclipse |
Non défini $HOME: Variable |
Lorsque vous exécutez le service de flux de données, ne modifiez pas la valeur de
spark.master. Si vous le faites, votre tâche n'utilise pas toutes les ressources que vous avez provisionnées. Lors de l'exécution de votre application dans le service Flux de données, le connecteur HDF Oracle Cloud Infrastructure est configuré automatiquement. Lors de l'exécution locale, vous devez le configurer vous-même en définissant les propriétés de configuration du connecteur HDFS.
Au minimum, vous devez mettre à jour l'objet SparkConf pour définir des valeurs pour fs.oci.client.auth.fingerprint, fs.oci.client.auth.pemfilepath, fs.oci.client.auth.tenantId, fs.oci.client.auth.userId et fs.oci.client.hostname.
Si votre clé API utilise une phrase secrète, vous devez définir fs.oci.client.auth.passphrase.
Ces variables peuvent être définies après la création de la session. Dans votre environnement de programmation, utilisez les SDK appropriés pour charger correctement la configuration des clés d'API.
ConfigFileAuthenticationDetailsProvider selon le cas :import com.oracle.bmc.auth.ConfigFileAuthenticationDetailsProvider;
import com.oracle.bmc.ConfigFileReader;
//If your key is encrypted call setPassPhrase:
ConfigFileAuthenticationDetailsProvider authenticationDetailsProvider = new ConfigFileAuthenticationDetailsProvider(ConfigFileReader.DEFAULT_FILE_PATH, "<DEFAULT>");
configuration.put("fs.oci.client.auth.tenantId", authenticationDetailsProvider.getTenantId());
configuration.put("fs.oci.client.auth.userId", authenticationDetailsProvider.getUserId());
configuration.put("fs.oci.client.auth.fingerprint", authenticationDetailsProvider.getFingerprint());
String guessedPath = new File(configurationFilePath).getParent() + File.separator + "oci_api_key.pem";
configuration.put("fs.oci.client.auth.pemfilepath", guessedPath);
// Set the storage endpoint:
String region = authenticationDetailsProvider.getRegion().getRegionId();
String hostName = MessageFormat.format("https://objectstorage.{0}.oraclecloud.com", new Object[] { region });
configuration.put("fs.oci.client.hostname", hostName);oci.config.from_file selon le cas :import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
# Check to see if we're in Data Flow or not.
if os.environ.get("HOME") == "/home/dataflow":
spark_session = SparkSession.builder.appName("app").getOrCreate()
else:
conf = SparkConf()
oci_config = oci.config.from_file(oci.config.DEFAULT_LOCATION, "<DEFAULT>")
conf.set("fs.oci.client.auth.tenantId", oci_config["tenancy"])
conf.set("fs.oci.client.auth.userId", oci_config["user"])
conf.set("fs.oci.client.auth.fingerprint", oci_config["fingerprint"])
conf.set("fs.oci.client.auth.pemfilepath", oci_config["key_file"])
conf.set(
"fs.oci.client.hostname",
"https://objectstorage.{0}.oraclecloud.com".format(oci_config["region"]),
)
spark_builder = SparkSession.builder.appName("app")
spark_builder.config(conf=conf)
spark_session = spark_builder.getOrCreate()
spark_context = spark_session.sparkContext
Dans SparkSQL, la configuration est gérée différemment. Ces paramètres sont transmis à l'aide du commutateur --hiveconf. Pour exécuter des interrogations Spark SQL, utilisez un script d'encapsuleur similaire à celui de l'exemple. Lorsque vous exécutez votre script dans Data Flow, ces paramètres sont créés automatiquement.
#!/bin/sh
CONFIG=$HOME/.oci/config
USER=$(egrep ' user' $CONFIG | cut -f2 -d=)
FINGERPRINT=$(egrep ' fingerprint' $CONFIG | cut -f2 -d=)
KEYFILE=$(egrep ' key_file' $CONFIG | cut -f2 -d=)
TENANCY=$(egrep ' tenancy' $CONFIG | cut -f2 -d=)
REGION=$(egrep ' region' $CONFIG | cut -f2 -d=)
REMOTEHOST="https://objectstorage.$REGION.oraclecloud.com"
spark-sql \
--hiveconf fs.oci.client.auth.tenantId=$TENANCY \
--hiveconf fs.oci.client.auth.userId=$USER \
--hiveconf fs.oci.client.auth.fingerprint=$FINGERPRINT \
--hiveconf fs.oci.client.auth.pemfilepath=$KEYFILE \
--hiveconf fs.oci.client.hostname=$REMOTEHOST \
-f script.sql
Les exemples ci-dessus ne modifient que la façon dont vous créez votre contexte Spark. Rien d'autre n'a besoin d'être modifié, vous pouvez donc développer les autres aspects de votre application Spark normalement. Lorsque vous déployez votre application Spark dans le service de flux de données, vous n'avez pas besoin de modifier le code ni la configuration.
2. Création de fichiers "Fat JAR" pour les applications Java
Les applications Java et Scala doivent généralement inclure des dépendances supplémentaires dans un fichier JAR appelé "Fat JAR".
Si vous utilisez Maven, vous pouvez faire cela à l'aide du plugiciel Shade. Les exemples suivants proviennent de fichiers Maven pom.xml. Vous pouvez les utiliser comme point de départ pour votre projet. Lorsque vous créez votre application, les dépendances sont automatiquement téléchargées et insérées dans votre environnement d'exécution.
Si vous utilisez Spark 3.5.0 ou 3.2.1, ce chapitre ne s'applique pas. Reportez-vous plutôt au chapitre 2. Gestion des dépendances Java pour les applications Apache Spark dans le service de flux de données.
Cette partie pom.xml comprend les versions de bibliothèque Spark et Oracle Cloud Infrastructure appropriées pour le service Flux de données (Spark 3.0.2). Elle cible Java 8 et "ombre" (shade) les fichiers de classe communs en conflit.
<properties>
<oci-java-sdk-version>1.25.2</oci-java-sdk-version>
</properties>
<dependencies>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-hdfs-connector</artifactId>
<version>3.2.1.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-core</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-objectstorage</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.2</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.0</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>example.Example</mainClass>
</transformer>
</transformers>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<relocations>
<relocation>
<pattern>com.oracle.bmc</pattern>
<shadedPattern>shaded.com.oracle.bmc</shadedPattern>
<includes>
<include>com.oracle.bmc.**</include>
</includes>
<excludes>
<exclude>com.oracle.bmc.hdfs.**</exclude>
</excludes>
</relocation>
</relocations>
<artifactSet>
<excludes>
<exclude>org.bouncycastle:bcpkix-jdk15on</exclude>
<exclude>org.bouncycastle:bcprov-jdk15on</exclude>
<!-- Including jsr305 in the shaded jar causes a SecurityException
due to signer mismatch for class "javax.annotation.Nonnull" -->
<exclude>com.google.code.findbugs:jsr305</exclude>
</excludes>
</artifactSet>
</configuration>
</plugin>
</plugins>
</build>Cette partie pom.xml comprend les versions de bibliothèque Spark et Oracle Cloud Infrastructure appropriées pour le service Flux de données (Spark 2.4.4). Elle cible Java 8 et "ombre" (shade) les fichiers de classe communs en conflit.
<properties>
<oci-java-sdk-version>1.15.4</oci-java-sdk-version>
</properties>
<dependencies>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-hdfs-connector</artifactId>
<version>2.7.7.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-core</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-objectstorage</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.4</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>2.4.4</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.0</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>example.Example</mainClass>
</transformer>
</transformers>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<relocations>
<relocation>
<pattern>com.oracle.bmc</pattern>
<shadedPattern>shaded.com.oracle.bmc</shadedPattern>
<includes>
<include>com.oracle.bmc.**</include>
</includes>
<excludes>
<exclude>com.oracle.bmc.hdfs.**</exclude>
</excludes>
</relocation>
</relocations>
<artifactSet>
<excludes>
<exclude>org.bouncycastle:bcpkix-jdk15on</exclude>
<exclude>org.bouncycastle:bcprov-jdk15on</exclude>
<!-- Including jsr305 in the shaded jar causes a SecurityException
due to signer mismatch for class "javax.annotation.Nonnull" -->
<exclude>com.google.code.findbugs:jsr305</exclude>
</excludes>
</artifactSet>
</configuration>
</plugin>
</plugins>
</build>3. Tester votre application localement
Avant de déployer votre application, vous pouvez la tester localement pour vous assurer qu'elle fonctionne. Vous pouvez utiliser trois techniques. Sélectionnez celle qui fonctionne le mieux pour vous. Ces exemples supposent que le nom de votre artefact d'application soit application.jar (pour Java) ou application.py (pour Python).
- Le service de flux de données masque la plupart du code source et des bibliothèques qu'il utilise pour s'exécuter. Ainsi, les versions de la trousse SDK du service de flux de données n'ont plus besoin d'être mises en correspondance et les conflits de dépendance de tierce partie avec le service de flux de données ne doivent plus se produire.
- Spark a été mis à niveau pour que les trousses SDK OCI soient désormais compatibles avec celles-ci. Cela signifie que les dépendances de tierce partie conflictuelles n'ont pas besoin d'être déplacées, de sorte que les bibliothèques d'applications et de bibliothèques peuvent être séparées pour des versions plus rapides, moins compliquées, plus petites et plus flexibles.
- Le nouveau fichier de modèle pom.xml est téléchargé et crée une copie presque identique du service de flux de données sur l'ordinateur local d'un développeur. Cela signifie que :
- Les développeurs peuvent exécuter le débogueur d'étapes sur leur machine locale pour détecter et résoudre rapidement les problèmes avant de les exécuter sur le service de flux de données.
- Les développeurs peuvent compiler et exécuter les mêmes versions de bibliothèque que le service de flux de données. Ainsi, l'équipe du service de flux de données peut rapidement décider si un problème est lié au service de flux de données ou au code d'application.
Méthode 1 : Exécution à partir de l'environnement de développement intégré
Si vous avez développé un environnement de développement intégré tel qu'Eclipse, vous n'avez pas à faire plus que cliquer sur Exécuter et sélectionner la classe principale appropriée. 
Lors de l'exécution, il est normal que Spark produise des messages d'avertissement dans la console. Vous pouvez ainsi voir que Spark est appelé. 
Méthode 2 : Exécution de PySpark à partir de la ligne de commande
python3 application.py$ python3 example.py
Warning: Ignoring non-Spark config property: fs.oci.client.hostname
Warning: Ignoring non-Spark config property: fs.oci.client.auth.fingerprint
Warning: Ignoring non-Spark config property: fs.oci.client.auth.tenantId
Warning: Ignoring non-Spark config property: fs.oci.client.auth.pemfilepath
Warning: Ignoring non-Spark config property: fs.oci.client.auth.userId
20/08/01 06:52:00 WARN Utils: Your hostname resolves to a loopback address: 127.0.0.1; using 192.168.1.41 instead (on interface en0)
20/08/01 06:52:00 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
20/08/01 06:52:01 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableMéthode 3: Utilisation de spark-submit
L'utilitaire spark-submit est inclus dans votre distribution de Spark. Utilisez cette méthode dans certaines situations, par exemple lorsqu'une application PySpark requiert des fichiers JAR supplémentaires.
spark-submit :spark-submit --class example.Example example.jarComme vous devez fournir le nom de la classe principale au service de flux de données, ce code est un bon moyen de vérifier que vous utilisez le nom de classe correct. Rappelez-vous que les noms de classe sont sensibles à la casse.
spark-submit pour exécuter une application PySpark qui requiert des fichiers JAR Oracle JDBC :
spark-submit \
--jars java/oraclepki-18.3.jar,java/ojdbc8-18.3.jar,java/osdt_cert-18.3.jar,java/ucp-18.3.jar,java/osdt_core-18.3.jar \
example.py4. Déployer l'application
- Copiez l'artefact de l'application (fichier
jar, script Python ou script SQL) vers Oracle Cloud Infrastructure Object Storage. - Si votre application Java comporte des dépendances non fournies par le service Flux de données, n'oubliez pas de copier le fichier
jard'assemblage. - Créez une application de flux de données qui référence cet artefact dans Oracle Cloud Infrastructure Object Storage.
Après l'étape 3, vous pouvez exécuter l'application autant de fois que vous le souhaitez. Pour plus d'informations, voir le tutoriel Introduction au service de flux de données pour Oracle Cloud Infrastructure, qui vous guide étape par étape au cours de ce processus.
Étape suivante
Vous savez comment développer vos applications localement et les déployer dans le service Flux de données.