Sviluppa le applicazioni Oracle Cloud Infrastructure Data Flow localmente e implementale nel cloud
Oracle Cloud Infrastructure Data Flow è un servizio cloud Apache Spark completamente gestito. Ti consente di eseguire applicazioni Spark su qualsiasi scala e con un lavoro amministrativo o di impostazione minimo. Data Flow è la soluzione ideale per schedulare processi di elaborazione batch affidabili con tempi di esecuzione lunghi.
Puoi sviluppare applicazioni Spark senza essere connesso al cloud. È possibile sviluppare, testare e iterare rapidamente sul computer portatile. Quando sono pronti, puoi distribuirli in Data Flow senza doverli riconfigurare, apportare modifiche al codice o applicare profili di distribuzione.
- La maggior parte del codice di origine e delle librerie utilizzate per eseguire Data Flow sono nascosti. Non è più necessario abbinare le versioni del kit SDK di flusso dati e non sono più presenti conflitti di dipendenza di terze parti con il flusso dati.
- Gli SDK sono compatibili con Spark, quindi non è più necessario spostare dipendenze di terze parti in conflitto, consentendo di separare l'applicazione dalle librerie per build più veloci, meno complicate, più piccole e più flessibili.
- Il nuovo file pom.xml del modello scarica e crea una copia quasi identica del flusso di dati sul computer locale. È possibile eseguire il debugger dei passi sul computer locale per rilevare e risolvere i problemi prima di eseguire l'applicazione in Data Flow. È possibile compilare ed eseguire le stesse versioni esatte della libreria eseguite da Data Flow. Oracle può decidere rapidamente se il problema riguarda il flusso di dati o il codice dell'applicazione.
Informazioni preliminari
Prima di iniziare a sviluppare le applicazioni, è necessario impostare e lavorare come segue:
- Un login Oracle Cloud con la funzionalità Chiave API abilitata. Caricare l'utente in Identità /Utenti e confermare la possibilità di creare chiavi API.
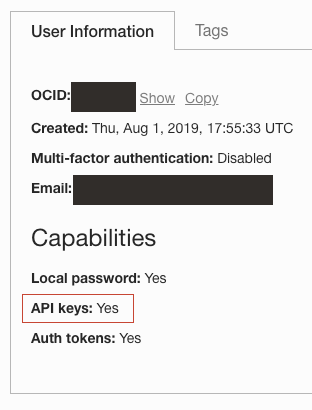
- Chiave API registrata e distribuita nell'ambiente locale. Per ulteriori informazioni, vedere Registrare una chiave API.
- Installazione locale di Apache Spark 2.4.4, 3.0.2, 3.2.1 o 3.5.0. Puoi confermarlo eseguendo spark-shell nell'interfaccia CLI.
- Apache Maven installato. Le istruzioni e gli esempi utilizzano Maven per scaricare le dipendenze necessarie.
Prima di iniziare, esaminare Esegui sicurezza in Flusso di dati. Utilizza un token di delega che consente di eseguire operazioni cloud per conto dell'utente. Qualsiasi cosa il tuo account possa fare nella console di Oracle Cloud Infrastructure, il tuo job Spark può fare utilizzando Data Flow. Quando viene eseguito in modalità locale, è necessario utilizzare una chiave API che consenta all'applicazione locale di effettuare richieste autenticate a vari servizi Oracle Cloud Infrastructure.
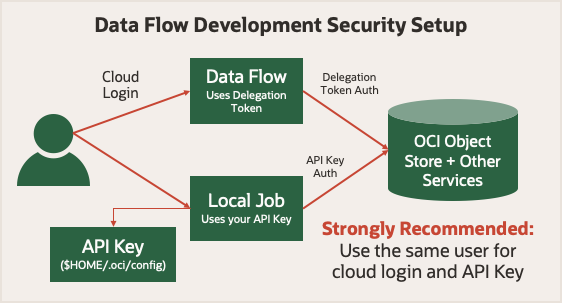
Per semplificare le cose, utilizza una chiave API generata per lo stesso utente quando esegui il login alla console di Oracle Cloud Infrastructure. Ciò significa che le applicazioni dispongono degli stessi privilegi, sia che vengano eseguite localmente che in Data Flow.
1. I concetti di sviluppo locale
- Personalizza l'installazione Spark locale con i file della libreria di Oracle Cloud Infrastructure, in modo che sia simile all'ambiente runtime di Data Flow.
- Rileva dove è in esecuzione il codice,
- Configurare il client HDFS di Oracle Cloud Infrastructure in modo appropriato.
Per spostarsi senza problemi tra il computer e il flusso di dati, è necessario utilizzare alcune versioni di Spark, Scala e Python nell'impostazione locale. Aggiungere il file JAR del connettore HDFS di Oracle Cloud Infrastructure. Aggiungere inoltre dieci librerie di dipendenze all'installazione Spark installate quando l'applicazione viene eseguita in Data Flow. Questi passi mostrano come scaricare e installare queste librerie di dipendenze dieci.
| Versione Spark | Versione Scala | Versione Python |
|---|---|---|
| 3,5 | 2,12 | 3,11 |
| 3,2 | 2,12 | 3,8 |
| 3 | 2,12 | 3,6 |
| 2,4 | 2,11 | 3,6 |
CONNECTOR=com.oracle.oci.sdk:oci-hdfs-connector:3.3.4.1.4.2
mkdir -p deps
touch emptyfile
mvn install:install-file -DgroupId=org.projectlombok -DartifactId=lombok -Dversion=1.18.26 -Dpackaging=jar -Dfile=emptyfile
mvn org.apache.maven.plugins:maven-dependency-plugin:2.7:get -Dartifact=$CONNECTOR -Ddest=deps
mvn org.apache.maven.plugins:maven-dependency-plugin:2.7:get -Dartifact=$CONNECTOR -Ddest=deps -Dtransitive=true -Dpackaging=pom
mvn org.apache.maven.plugins:maven-dependency-plugin:2.7:copy-dependencies -f deps/*.pom -DoutputDirectory=.echo 'sc.getConf.get("spark.home")' | spark-shellscala> sc.getConf.get("spark.home")
res0: String = /usr/local/lib/python3.11/site-packages/pyspark/usr/local/lib/python3.11/site-packages/pyspark/jarsdeps contiene molti file JAR, la maggior parte dei quali sono già disponibili nell'installazione di Spark. È sufficiente copiare un subset di questi file JAR nell'ambiente Spark:bcpkix-jdk15to18-1.74.jar
bcprov-jdk15to18-1.74.jar
guava-32.0.1-jre.jar
jersey-media-json-jackson-2.35.jar
oci-hdfs-connector-3.3.4.1.4.2.jar
oci-java-sdk-addons-apache-configurator-jersey-3.34.0.jar
oci-java-sdk-common-*.jar
oci-java-sdk-objectstorage-extensions-3.34.0.jar
jersey-apache-connector-2.35.jar
oci-java-sdk-addons-apache-configurator-jersey-3.34.0.jar
jersey-media-json-jackson-2.35.jar
oci-java-sdk-objectstorage-generated-3.34.0.jar
oci-java-sdk-circuitbreaker-3.34.0.jar
resilience4j-circuitbreaker-1.7.1.jar
resilience4j-core-1.7.1.jar
vavr-match-0.10.2.jar
vavr-0.10.2.jardeps nella sottodirectory jars trovata nel passaggio 2.import com.oracle.bmc.hdfs.BmcFilesystemFile JAR distribuiti correttamente 
Se c'è un errore, allora hai messo i file nel posto sbagliato. In questo esempio si verifica un errore:
File JAR distribuiti in modo errato 
- È possibile utilizzare il valore
spark.masternell'oggettoSparkConfimpostato su k8s://https://kubernetes.default.svc:443 durante l'esecuzione in Data Flow. - La variabile di ambiente
HOMEviene impostata su/home/dataflowquando viene eseguita in Data Flow.
Nelle applicazioni PySpark, un oggetto SparkConf appena creato è vuoto. Per visualizzare i valori corretti, utilizzare il metodo getConf per eseguire SparkContext.
| Avvia ambiente |
Impostazione spark.master |
|---|---|
| Data Flow |
|
| Invio sparkline locale |
spark.master: locale[*] $HOME: Variabile |
| Eclipse |
Annulla impostazione $HOME: Variabile |
Quando si esegue il flusso di dati, non modificare il valore di
spark.master. In tal caso, il job non utilizza tutte le risorse di cui è stato eseguito il provisioning. Quando l'applicazione viene eseguita nel flusso di dati, il connettore HDFS di Oracle Cloud Infrastructure viene configurato automaticamente. Quando si esegue in locale, è necessario configurarla personalmente impostando le proprietà di configurazione del connettore HDFS.
È necessario aggiornare almeno l'oggetto SparkConf in modo da impostare i valori per fs.oci.client.auth.fingerprint, fs.oci.client.auth.pemfilepath, fs.oci.client.auth.tenantId, fs.oci.client.auth.userId e fs.oci.client.hostname.
Se la chiave API contiene una passphrase, è necessario impostare fs.oci.client.auth.passphrase.
Queste variabili possono essere impostate dopo la creazione della sessione. Nel tuo ambiente di programmazione, utilizza i rispettivi SDK per caricare correttamente la configurazione della chiave API.
ConfigFileAuthenticationDetailsProvider come appropriato:import com.oracle.bmc.auth.ConfigFileAuthenticationDetailsProvider;
import com.oracle.bmc.ConfigFileReader;
//If your key is encrypted call setPassPhrase:
ConfigFileAuthenticationDetailsProvider authenticationDetailsProvider = new ConfigFileAuthenticationDetailsProvider(ConfigFileReader.DEFAULT_FILE_PATH, "<DEFAULT>");
configuration.put("fs.oci.client.auth.tenantId", authenticationDetailsProvider.getTenantId());
configuration.put("fs.oci.client.auth.userId", authenticationDetailsProvider.getUserId());
configuration.put("fs.oci.client.auth.fingerprint", authenticationDetailsProvider.getFingerprint());
String guessedPath = new File(configurationFilePath).getParent() + File.separator + "oci_api_key.pem";
configuration.put("fs.oci.client.auth.pemfilepath", guessedPath);
// Set the storage endpoint:
String region = authenticationDetailsProvider.getRegion().getRegionId();
String hostName = MessageFormat.format("https://objectstorage.{0}.oraclecloud.com", new Object[] { region });
configuration.put("fs.oci.client.hostname", hostName);oci.config.from_file come appropriato:import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
# Check to see if we're in Data Flow or not.
if os.environ.get("HOME") == "/home/dataflow":
spark_session = SparkSession.builder.appName("app").getOrCreate()
else:
conf = SparkConf()
oci_config = oci.config.from_file(oci.config.DEFAULT_LOCATION, "<DEFAULT>")
conf.set("fs.oci.client.auth.tenantId", oci_config["tenancy"])
conf.set("fs.oci.client.auth.userId", oci_config["user"])
conf.set("fs.oci.client.auth.fingerprint", oci_config["fingerprint"])
conf.set("fs.oci.client.auth.pemfilepath", oci_config["key_file"])
conf.set(
"fs.oci.client.hostname",
"https://objectstorage.{0}.oraclecloud.com".format(oci_config["region"]),
)
spark_builder = SparkSession.builder.appName("app")
spark_builder.config(conf=conf)
spark_session = spark_builder.getOrCreate()
spark_context = spark_session.sparkContext
In SparkSQL la configurazione viene gestita in modo diverso. Queste impostazioni vengono passate utilizzando lo switch --hiveconf. Per eseguire query SQL Spark, utilizzare uno script wrapper simile all'esempio. Quando si esegue lo script in Data Flow, queste impostazioni vengono impostate automaticamente.
#!/bin/sh
CONFIG=$HOME/.oci/config
USER=$(egrep ' user' $CONFIG | cut -f2 -d=)
FINGERPRINT=$(egrep ' fingerprint' $CONFIG | cut -f2 -d=)
KEYFILE=$(egrep ' key_file' $CONFIG | cut -f2 -d=)
TENANCY=$(egrep ' tenancy' $CONFIG | cut -f2 -d=)
REGION=$(egrep ' region' $CONFIG | cut -f2 -d=)
REMOTEHOST="https://objectstorage.$REGION.oraclecloud.com"
spark-sql \
--hiveconf fs.oci.client.auth.tenantId=$TENANCY \
--hiveconf fs.oci.client.auth.userId=$USER \
--hiveconf fs.oci.client.auth.fingerprint=$FINGERPRINT \
--hiveconf fs.oci.client.auth.pemfilepath=$KEYFILE \
--hiveconf fs.oci.client.hostname=$REMOTEHOST \
-f script.sql
Gli esempi precedenti modificano solo il modo in cui si crea il contesto Spark. Non è necessario modificare nient'altro nella tua applicazione Spark, in modo da poter sviluppare altri aspetti della tua applicazione Spark come faresti normalmente. Quando distribuisci l'applicazione Spark in Data Flow, non è necessario modificare alcun codice o configurazione.
2. Creazione di "JAR grassi" per le applicazioni Java
Le applicazioni Java e Scala in genere devono includere più dipendenze in un file JAR noto come "Fat JAR".
Se si utilizza Maven, è possibile farlo utilizzando il plugin Shade. Gli esempi seguenti provengono dai file pom.xml Maven. Puoi utilizzarli come punto di partenza per il tuo progetto. Quando si crea l'applicazione, le dipendenze vengono scaricate e inserite automaticamente nell'ambiente runtime.
Se si utilizza Spark 3.5.0 o 3.2.1, questo capitolo non si applica. In alternativa, seguire il capitolo 2. Gestione delle dipendenze Java per le applicazioni Apache Spark nel flusso di dati.
Questa parte pom.xml include le versioni appropriate della libreria Spark e Oracle Cloud Infrastructure per Data Flow (Spark 3.0.2). Si rivolge a Java 8 e oscura i file di classe in conflitto comuni.
<properties>
<oci-java-sdk-version>1.25.2</oci-java-sdk-version>
</properties>
<dependencies>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-hdfs-connector</artifactId>
<version>3.2.1.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-core</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-objectstorage</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.2</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.0</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>example.Example</mainClass>
</transformer>
</transformers>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<relocations>
<relocation>
<pattern>com.oracle.bmc</pattern>
<shadedPattern>shaded.com.oracle.bmc</shadedPattern>
<includes>
<include>com.oracle.bmc.**</include>
</includes>
<excludes>
<exclude>com.oracle.bmc.hdfs.**</exclude>
</excludes>
</relocation>
</relocations>
<artifactSet>
<excludes>
<exclude>org.bouncycastle:bcpkix-jdk15on</exclude>
<exclude>org.bouncycastle:bcprov-jdk15on</exclude>
<!-- Including jsr305 in the shaded jar causes a SecurityException
due to signer mismatch for class "javax.annotation.Nonnull" -->
<exclude>com.google.code.findbugs:jsr305</exclude>
</excludes>
</artifactSet>
</configuration>
</plugin>
</plugins>
</build>Questa parte pom.xml include le versioni appropriate della libreria Spark e Oracle Cloud Infrastructure per Data Flow (Spark 2.4.4). Si rivolge a Java 8 e oscura i file di classe in conflitto comuni.
<properties>
<oci-java-sdk-version>1.15.4</oci-java-sdk-version>
</properties>
<dependencies>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-hdfs-connector</artifactId>
<version>2.7.7.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-core</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-objectstorage</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.4</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>2.4.4</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.0</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>example.Example</mainClass>
</transformer>
</transformers>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<relocations>
<relocation>
<pattern>com.oracle.bmc</pattern>
<shadedPattern>shaded.com.oracle.bmc</shadedPattern>
<includes>
<include>com.oracle.bmc.**</include>
</includes>
<excludes>
<exclude>com.oracle.bmc.hdfs.**</exclude>
</excludes>
</relocation>
</relocations>
<artifactSet>
<excludes>
<exclude>org.bouncycastle:bcpkix-jdk15on</exclude>
<exclude>org.bouncycastle:bcprov-jdk15on</exclude>
<!-- Including jsr305 in the shaded jar causes a SecurityException
due to signer mismatch for class "javax.annotation.Nonnull" -->
<exclude>com.google.code.findbugs:jsr305</exclude>
</excludes>
</artifactSet>
</configuration>
</plugin>
</plugins>
</build>3. Test dell'applicazione a livello locale
Prima di distribuire l'applicazione, è possibile eseguirne il test in locale per assicurarsi che funzioni. Ci sono tre tecniche che puoi usare, seleziona quella che funziona meglio per te. Questi esempi presuppongono che l'artifact dell'applicazione sia denominato application.jar (per Java) o application.py (per Python).
- Data Flow nasconde la maggior parte del codice sorgente e delle librerie che utilizza per l'esecuzione, pertanto le versioni di Data Flow SDK non richiedono più la corrispondenza e non dovrebbero verificarsi conflitti di dipendenza di terze parti con Data Flow.
- Spark è stato aggiornato in modo che gli SDK OCI siano ora compatibili con esso. Ciò significa che le dipendenze di terze parti in conflitto non devono essere spostate, quindi le librerie di applicazioni e librerie possono essere separate per build più veloci, meno complicate, più piccole e più flessibili.
- Il nuovo file pom.xml del modello viene scaricato e creato una copia quasi identica di Data Flow sul computer locale di uno sviluppatore. Ciò significa quanto riportato di seguito.
- Gli sviluppatori possono eseguire il debugger dei passi sul proprio computer locale per rilevare e risolvere rapidamente i problemi prima di eseguire il flusso di dati.
- Gli sviluppatori possono compilare ed eseguire le stesse versioni esatte della libreria eseguite da Data Flow. Il team di Data Flow può quindi decidere rapidamente se un problema riguarda Data Flow o il codice dell'applicazione.
Metodo 1: Esegui dal tuo IDE
Se si è sviluppato in un ambiente IDE come Eclipse, non è necessario fare altro che fare clic su Esegui e selezionare la classe principale appropriata. 
Durante l'esecuzione, è normale che Spark produca messaggi di avvertenza nella console, che ti informano che Spark viene richiamato. 
Metodo 2: eseguire PySpark dalla riga di comando
python3 application.py$ python3 example.py
Warning: Ignoring non-Spark config property: fs.oci.client.hostname
Warning: Ignoring non-Spark config property: fs.oci.client.auth.fingerprint
Warning: Ignoring non-Spark config property: fs.oci.client.auth.tenantId
Warning: Ignoring non-Spark config property: fs.oci.client.auth.pemfilepath
Warning: Ignoring non-Spark config property: fs.oci.client.auth.userId
20/08/01 06:52:00 WARN Utils: Your hostname resolves to a loopback address: 127.0.0.1; using 192.168.1.41 instead (on interface en0)
20/08/01 06:52:00 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
20/08/01 06:52:01 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableMetodo 3: Usa Spark-Submit
La utility spark-submit è inclusa nella distribuzione Spark. Utilizzare questo metodo in alcune situazioni, ad esempio quando un'applicazione PySpark richiede file JAR aggiuntivi.
spark-submit:spark-submit --class example.Example example.jarPoiché è necessario fornire il nome della classe principale a Data Flow, questo codice è un buon modo per confermare che si sta utilizzando il nome della classe corretto. Tenere presente che i nomi delle classi fanno distinzione tra maiuscole e minuscole.
spark-submit per eseguire un'applicazione PySpark che richiede i file JAR JDBC Oracle:
spark-submit \
--jars java/oraclepki-18.3.jar,java/ojdbc8-18.3.jar,java/osdt_cert-18.3.jar,java/ucp-18.3.jar,java/osdt_core-18.3.jar \
example.py4. Distribuire l'applicazione
- Copiare l'artifact dell'applicazione (file
jar, script Python o script SQL) in Oracle Cloud Infrastructure Object Storage. - Se l'applicazione Java dispone di dipendenze non fornite da Data Flow, ricordarsi di copiare il file
jardell'assembly. - Creare un'applicazione di flusso dati che faccia riferimento a questo artifact all'interno di Oracle Cloud Infrastructure Object Storage.
Dopo il passo 3, è possibile eseguire l'applicazione tutte le volte che si desidera. Per ulteriori informazioni, l'esercitazione sulla Guida introduttiva a Oracle Cloud Infrastructure Data Flow descrive questo processo passo dopo passo.
Pagina successiva
Ora sai come sviluppare le tue applicazioni in locale e distribuirle in Data Flow.