自律型AIデータベースによるレイクハウスの使用
自律型AIデータベースでレイクハウスを使用するメリットをご紹介します。
自律型AIデータベースを使用したレイクハウスについて
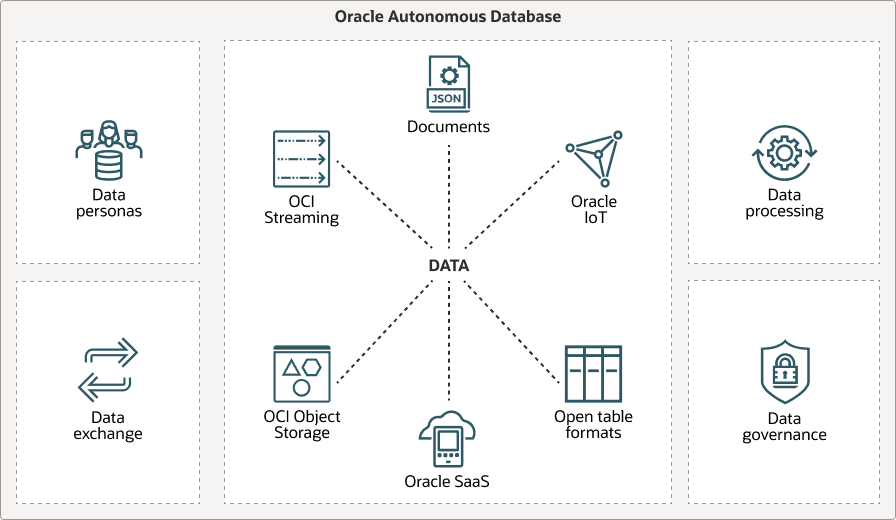
Oracle Autonomous AI Databaseは、あらゆるタイプのデータとワークロードに対応するための汎用性の高いソリューションです。
Autonomous AI Databaseは、JSON、Graph、Vectorなどの多様なデータ型をサポートしながら、オブジェクト・ストアに匹敵するTBあたりのコスト効率の高いストレージを提供します。自律型AIデータベースにより、企業はデータを単一のプラットフォームに統合できます。Oracle Machine Learning(OML)、Graph、Spatial、Vector、Blockchainなどのコンバージド機能を活用して、データを包括的に管理できます。
すでに他のプラットフォームにレイクハウスがある組織の場合、Oracle Autonomous AI Databaseはシームレスに統合されるため、企業は現在の設定を中断することなく、Autonomous AI Databaseの高度な機能の恩恵を受けることができます。
さらに学習するには、LiveLabsのAutonomous AI Lakehouseによるレイクハウスの構築をご覧ください。
Lakehouseとは?
レイクハウスは、分析にデータが必要になるまで、膨大な量のRAWデータをネイティブ形式で格納するように設計された一元化されたリポジトリです。
柔軟性と拡張性が高く、組織が構造化、半構造化、非構造化など、さまざまなタイプのデータを格納および処理できるようにすることで、従来のレイクハウスの強力な補完となります。
レイクハウスの主な属性:
-
ファイルおよび表の形式を開く
レイクハウスは、CSV、Parquet、Icebergなどのテーブル形式などのオープン・ファイル形式でデータを格納します。これにより、複数のエンジンがこれらのデータセットを書き込み、読み取ることができるようになり、データ処理の相互運用性と柔軟性が確保されます。
-
複数のデータ処理エンジンのサポート
レイクハウスは、Apache Spark、Presto、Hiveなどの様々なデータ処理エンジンと互換性があり、多様な分析ワークロードを可能にします。
-
読取り中のスキーマ
レイクハウスは、スキーマ・オン・リーディング・アプローチを使用することがよくあります。つまり、事前にスキーマを定義する必要はありません。これにより、データを迅速に取り込むことができ、データを事前に構造化せずにロードできます。これは、「データを今すぐ取得して、後で質問する」オブジェクト・ストアとよく似ています。
-
非構造化データのサポート
構造化データだけでなく、レイクハウスはイメージ(JPG)、ドキュメント(PDF、Word)、その他のバイナリ・データなどの非構造化データを格納し、包括的なストレージ・ソリューションを提供できます。
自律型AIデータベースの主要なレイクハウスの機能
Oracle Autonomous AI Databaseは、レイクハウスのワークロードをシームレスにサポートするように設計されており、管理やインストールが不要になります。様々なクラウド環境間で様々なデータ形式を処理する堅牢な機能を提供し、柔軟で包括的なデータ分析を実現します。
レイクハウスのワークロードに対応
Oracle Autonomous AI Databaseは、レイクハウスのワークロードにすぐに使用できる準備が整っており、追加のコンポーネントは不要です。この準備は、データ変換、メタデータ管理、一般的なレイクハウス・ツールとの統合など、レイクハウスの主要なタスクにまで及びます。これらはすべて、追加の設定なしで初日から利用できます。
この包括的な準備は、自律型AIデータベースを際立たせ、レイクハウスのワークロードのインサイト化を加速する、統合された手間のかからないエクスペリエンスを提供します。つまり、ユーザーは設定や構成を行わずにレイクハウスのタスクの処理をすぐに開始できるため、レイクハウス環境向けの真のプラグアンドプレイ・ソリューションとなります。この組込み機能により、運用が簡素化され、メンテナンス・コストが削減され、より少ないエラーで高い信頼性が保証されます。
Autonomous AI Databaseは、開発者からビジネス・アナリストまで、すべてのユーザー・タイプに対応する一連のツールを提供し、プラットフォームを普遍的かつアクセスできるようにします。
開発者は、高度な操作、スクリプト作成、自動化のためにPL/SQL APIなどのツールを使用して、既存のツールとシームレスに統合し、カスタマイズされたデータベース・ソリューションを効率的に作成できます。詳細は、Autonomous AI Database提供パッケージ・リファレンスを参照してください。
ビジネス・ユーザーの場合、Data StudioをWebベースのインタフェースとして使用して、データの相互作用、探索および可視化を簡素化できます。Data Studioを使用すると、非技術ユーザーはインサイトを導き出し、レポートを作成し、効果的にコラボレーションできるため、複雑さを軽減し、情報に基づいた意思決定をサポートできます。詳細は、「Data Studioの概要ページ」を参照してください。
マルチCloud Support
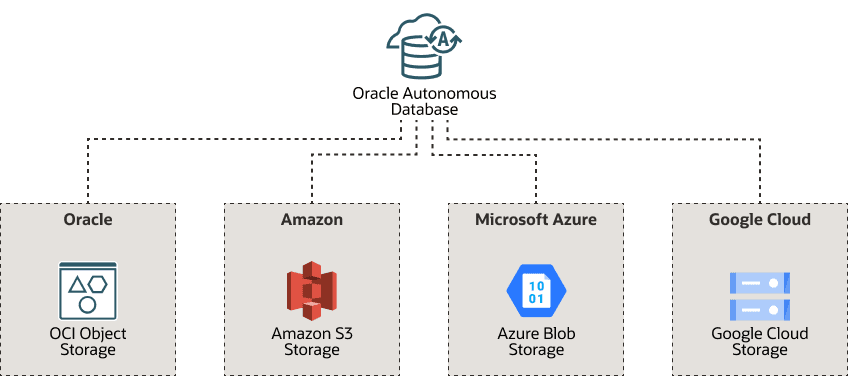
すでに他のプラットフォームに既存のレイクハウスがある組織の場合、自律型AIデータベースはシームレスに統合されるため、現在の設定を中断することなく、自律型AIデータベースの高度な機能を活用できます。
レイクハウスが自律型AIデータベースに接続するために必要な権限とアクセス権を付与することで、自律型AIデータベースへのアクセスをレイクハウスに提供します。必要な資格情報を提供すると、Autonomous AI Databaseは、AWS、Azure、Google Cloud、Oracle OCIオブジェクトストアなど、さまざまなクラウド環境のレイクハウスにシームレスに接続できます。
この機能により、各クラウド・プロバイダのネイティブ・セキュリティ機能を活用して、データに安全にアクセスし、管理できます。このマルチクラウド・サポートにより、統合された安全な環境を維持しながら、さまざまなクラウド・プラットフォームにまたがってレイクハウスをデプロイおよび拡張する柔軟性を得ることができます。
Oracle Autonomous AI Databaseは、他のクラウドのネイティブ・セキュリティをサポートしています。詳細は、「Amazonリソース名(ARN)を使用したAWSリソースへのアクセス」、「Azureサービス・プリンシパルを使用したAzureリソースへのアクセス」および「Googleサービス・アカウントを使用したGoogle Cloud Platformリソースへのアクセス」を参照してください。
エンドツーエンドのデータ形式のサポート
Oracle Autonomous AI Databaseは、幅広いデータ形式を処理できる柔軟性を備えて設計されており、多様なデータ・ソースおよびワークロードに対応するユニバーサル・ソリューションとなっています。
データが構造化形式、半構造化形式、非構造化形式のいずれであっても、Autonomous AI Databaseは様々なクラウド環境でシームレスにサポートします。これにより、フォーマットの互換性を心配することなく、データの取込み、格納および分析を行うことができます。
Autonomous AI Databaseは、CSVやJSONなどの従来のフォーマットや、AVRO、Parquet、ORCなどの高度なフォーマットをネイティブにサポートします。詳細は、Autonomous AI Databaseを使用した外部データの問合せを参照してください。Autonomous AI Databaseは、CSV、JSON、XML、AVRO、ORC、Parquet、Delta Sharing、Iceberg、Word、PDFのファイル形式をサポートしています。
自律型AIデータベースは、Iceberg Table形式のサポートを追加することで、大規模なレイクハウス環境向けに強化された機能を提供します。Icebergは、最適化され、高性能なクエリ、バージョン管理が向上し、データ管理が簡単になるため、大規模で進化するデータセットに適しています。詳細は、Apache Iceberg表の問合せを参照してください。
機能強化: 非構造化データ管理のための自律型AIデータベース
Oracle AI Databaseは、構造化データおよび半構造化データの強力な処理として認められていますが、Autonomous AI Databaseは、その機能を拡張して非構造化データセットも処理します。
これらの機能には、JPG、PDF、Wordドキュメントなどの幅広い形式の管理と分析が含まれます。これらの進歩により、自律型AIデータベースは、非構造化データ・ソースを処理する企業に包括的なソリューションをもたらします。
-
検索拡張生成(RAG)によるAIドリブン・インサイト: Autonomous AI Databaseは、高度なAIモデルを統合し、非構造化データのベクトル検索を可能にします。これにより、AIを使用して大量のデータセットにわたって関連情報を効率的に取得できるため、検索の精度と速度が向上します。詳細は、Select AI with Retrieval Augmented Generation (RAG)を参照してください。
-
全文索引付け: Autonomous AI Databaseは、非構造化ファイルに対する全文索引の作成をサポートし、PDF、Wordファイルなどのドキュメントに対して高度なテキスト検索を実行できます。この機能により、非構造化コンテンツの問合せ、索引付けおよび分析が大幅に向上します。オブジェクト・ストレージのファイルでの全文検索の使用を参照してください
-
非構造化データの解析とロード: Autonomous AI Databaseの強化された解析機能とデータ取り込み機能により、ユーザーは非構造化データをシームレスにロードし、自動的に表形式に変換して、すぐにデータベースにロードできます。詳細は、「イメージからの表抽出の実行」を参照してください。
-
AIをデータ・ソースとして(プロンプトから表へ): Autonomous AI Databaseは、AIを活用することで、迅速な対応が可能になり、ユーザーがAIモデルから直接データを生成して表にロードできるようになります。これにより、AIによって生成された出力から貴重なインサイトを抽出し、それらを構造化されたデータの新しいソースとして使用する可能性が生まれます。「AIソースからのデータのロード」を参照してください
これらの拡張された機能により、自律型AIデータベースは、構造化されていないデータの需要の高まりに対応するための強力なツールとして位置づけられ、AIを活用したソリューションを活用することで、最新のデータ課題に対応する汎用性と将来性に優れたプラットフォームとなっています。
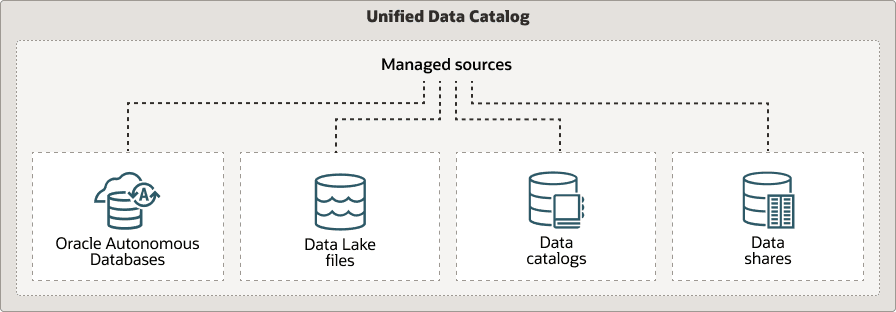
柔軟なメタデータ管理
Oracle Autonomous AI Databaseは、データセットのメタデータを定義するためのさまざまな方法を提供し、データ管理をより適応性と効率よくします。
-
カタログベースのメタデータ統合
ユーザーは、様々なカタログからメタデータを一元化されたビューに取り込むことができるため、組織全体でのデータの一貫性の制御と維持が容易になります。サポートされているカタログは次のとおりです。
-
OCI Data Catalog: Oracle Cloud Infrastructure (OCI)内のツールで、ユーザーがデータ・アセットを検出、整理、管理するのに役立ちます。すべてのデータ・アセットを明確に把握できるため、ユーザーはコンプライアンスを維持し、データ品質を確保し、チーム間のコラボレーションを促進できます。詳細は、例: MovieStreamシナリオを参照してください。
-
AWS Glue: メタデータを編成および管理するためのデータ・カタログを含む、Amazon Web Servicesの管理対象ETL (抽出、変換、ロード)サービス。詳細は、AWS Glueデータ・カタログを使用した外部データの問合せを参照してください。
-
-
手動メタデータ定義
ユーザーは、Oracle Cloud Infrastructure (OCI) Object StorageやAmazon S3などのオブジェクト・ストア内のデータセットに対して、表レベルでメタデータを直接定義することもできます。これにより、ユーザー要件に合わせて、個々のファイルまたはファイル・グループのデータをカスタマイズして編成できます。自律型AIデータベースは、列名やデータ型などのメタデータを自動的に推測して、時間を節約し、エラーを削減することもできます。たとえば、CSVファイルのアップロード時に、ヘッダーを列名として自動的に検出し、コンテンツに基づいて数値やvarchar2などの適切なデータ型を割り当てることができます。これにより、ユーザーは手作業なしでデータを分析用に迅速に準備できるため、設定時間を短縮し、エラーの可能性を最小限に抑えることができます。
フェデレーテッド・メタデータのサポート
自律型AIデータベースでは、フェデレーテッド・メタデータ・カタログがサポートされるため、ユーザーは様々なソースから1つのビューにメタデータを統合でき、メタデータ管理のための統合インタフェースが提供されます。
このアプローチでは、複数のクラウドおよびプラットフォーム間でデータ・ソースを接続することで、様々な環境でのメタデータ管理を簡素化します。カタログベースのメタデータを使用するか、手動で定義するかに関係なく、すべての情報を統合カタログで使用して、簡単に参照できます。たとえば、組織はこのフェデレーテッド・ビューを使用して、AWSとOracle Cloudの両方のデータ・アセットを管理し、プラットフォーム全体で一貫したガバナンスと発見性を確保できます。
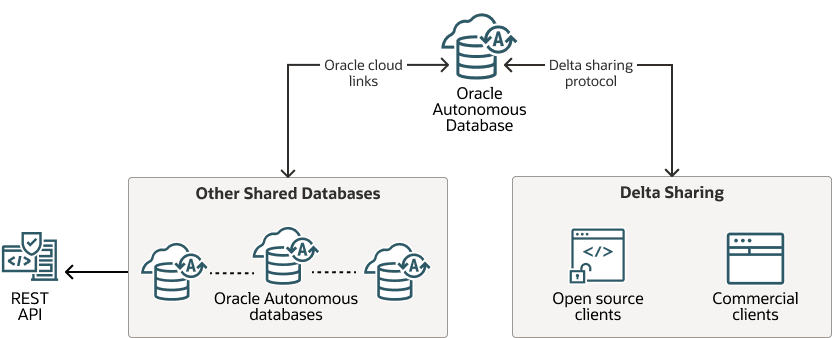
Collaboration
ユーザーは分析を終了した後、多くの場合、他のユーザーと結果を共有する必要があります。Oracle Autonomous AI Databaseは、いくつかのコラボレーション方法を提供することで、共有を容易にします。これにより、統合セキュリティ機能、オープン・プロトコル、シームレスなクラウド接続など、他のデータベースよりも独自のメリットが得られます。
これらのオプションは柔軟性と安全性を確保するため、異なるコラボレーション・ニーズに適合します。
-
Delta Sharing Protocol: これにより、Delta Sharingというオープン・プロトコルを使用して、Oracleの外部でデータを共有できます。複雑な統合を必要とせずに、外部パートナとの安全なデータ共有をサポートし、クロスクラウドおよびクロスプラットフォームの分析に最適です。このように、Oracleの一部ではない様々な分析ツールでデータをスムーズに使用できます。詳細は、「オブジェクト・ストレージを使用したデータ・バージョンの共有」を参照してください。
-
クラウド・リンク: セキュアなクラウド・リンクを使用して、異なるAutonomous AI Databaseインスタンス間でデータを共有できます。たとえば、クラウド・リンクは、様々なデータベースの接続に特に有効です。これにより、一貫したデータ可用性が確保され、コピーや複製を行う必要なく、複数のデータベースにまたがるデータへの迅速かつ信頼性の高いアクセスを必要とするアプリケーションのレイテンシが削減されます。コラボレーションをスムーズに維持し、チーム間の連携が必要になります。「直接接続を使用したライブ・データの共有」を参照してください
-
表ハイパーリンク: データを直接共有するには、別のログインを必要とせずにデータにアクセスできるようにする特別なURLを作成します。ユーザーは、これらのURLの権限を制御し、有効期限を設定できるため、セキュアで柔軟な共有オプションが確保されます。この機能は、RESTクライアント用に特別に構築されています。詳細は、表またはビューの表ハイパーリンクの作成を参照してください。
Oracle AI Databaseツールとの幅広い互換性
Autonomous AI Database環境は、さまざまなOracleデータベース・ツールと完全に互換性があります。
Oracleデータベースとの対話にすでに使用しているツール(データの可視化、分析、ETL、管理など)は、自律型AIデータベース内のデータセットをシームレスに分析することもできます。この互換性により、スムーズなエクスペリエンスが実現します。これにより、ユーザーは新しいツールやプロセスを採用することなく、自律型AIデータベースを既存のワークフローに統合できるため、効率を最大化し、学習曲線を削減できます。
Oracleデータベースで使用できるいくつかのツールの詳細は、「Data Studioの概要ページ」を参照してください。
パフォーマンス
自律型AIデータベースには、オブジェクト・ストアに格納されているデータのクエリや、Apache Icebergなどのオープン・テーブル・フォーマットの利用に特化した多数の最適化が含まれています。
データ・レイク・アクセラレータ
Data Lake Acceleratorは、Autonomous AI Databaseから専用のコンピュート・リソース・プールへのフィルタリング、プロジェクション、解凍など、集中的なスキャン操作をオフロードすることで、クエリ・パフォーマンスを大幅に向上させる動的なスケールアウト・サービスです。このサービスでは、問合せの実行中にのみECPUが動的にプロビジョニングおよび追加されるため、データベースにデータをロードすることなく、ソースで直接データ処理をパラレル化することで、大規模なスキャンをより迅速に終了できます。問合せが完了すると、割り当てられたリソースが自動的に解放され、効率的な消費ベースの使用率が保証されます。詳細は、Data Lake Acceleratorを参照してください。
レイク・キャッシュ
レイク・キャッシュを使用すると、アクセス頻度の高い外部データをローカルに格納できます。キャッシュを使用すると、マウントされたカタログを介して公開される外部表および表に対する問合せで、Autonomous AI Database内から直接データを取得できるため、非常に高速になります。パーティション表と非パーティション外部表、およびParquet表、ORC表、AVRO表、CSV表およびIceberg表でバックアップされたデータを含む適格なマウント済カタログ表に対して、レイク・キャッシュを作成できます。詳細は、レイク・キャッシュを使用した外部表のパフォーマンスの向上を参照してください。
暗黙的なパーティション化
Autonomous AI Databaseでの暗黙的なパーティション化では、オブジェクト・ストア・パス内の共通のフォルダおよびファイル・ネーミング・パターン('.../country=US/year=2024/month=01/'など)が自動的に認識されます。データベースでは、これらの命名規則がパーティション・キーとして扱われ、問合せフィルタに関連しないファイルおよびフォルダをスキップできます。これにより、表のDDLにパーティションを手動で定義したり、既存のディレクトリ構造を変更することなく、パーティション・プルーニングの利点が得られます。その結果、問合せはオブジェクト・ストアからスキャンするデータが少なくなり、特に大規模なデータセットを操作する場合、より高速な結果を提供します。詳細は、暗黙的パーティション化による外部表の問合せを参照してください。
適切な機能の選択
| 機能 | ユースケース | データ容量 |
| レイク・キャッシュ | 繰返しダッシュボード、対話型ダッシュボードまたはスケジュール済ダッシュボードを利用します。 | 中(GBから低TB) |
| データ・レイク・アクセラレータ | 大規模なデータに対する大量スキャンまたはアドホック・スキャンを活用します。 | 非常に大きい(TBからPB) |
| 暗黙的なパーティション化 | オブジェクト・ストア内のフォルダまたはファイル・ネーミング・パターン(日付、リージョン、その他の属性など)別に編成された大規模なデータセットを問合せまたは分析する場合に利用します。 | 中から大(GBからTB) |
| ハイブリッド | レイク・キャッシュは、外部表またはマウントされたカタログ表から頻繁にアクセスされる(ホットな)データ・サブセットをキャッシュし、データレイク・アクセラレータは完全な履歴データに対して問い合せます。 | 全ボリューム |