Desenvolver Aplicativos Oracle Cloud Infrastructure Data Flow Localmente, Implantar na Nuvem
O Oracle Cloud Infrastructure Data Flow é um serviço de nuvem Apache Spark totalmente gerenciado. Ele permite que você execute aplicativos Spark em qualquer escala e com o mínimo de trabalho de administração ou configuração. O serviço Data Flow é ideal para programar jobs confiáveis de processamento em batch de longa execução.
Você pode desenvolver aplicativos Spark sem estar conectado à nuvem. Desenvolva-os, teste-os e repita-os rapidamente em seu laptop. Quando eles estiverem prontos, você poderá implantá-los no Data Flow sem precisar reconfigurá-los, fazer alterações de código ou aplicar perfis de implantação.
- A maioria do código de origem e das bibliotecas usadas para executar o Data Flow está oculta. Você não precisa mais corresponder às versões do Data Flow SDK e não tem mais conflitos de dependência de terceiros com o Data Flow.
- Os SDKs são compatíveis com o Spark; portanto, você não precisa mais mover dependências de terceiros conflitantes, permitindo que você separe seu aplicativo de suas bibliotecas para builds mais rápidos, menos complicados, menores e mais flexíveis.
- O novo arquivo de modelo pom.xml faz download e cria uma cópia quase idêntica do serviço Data Flow na sua máquina local. Você pode executar o depurador de etapas na sua máquina local para detectar e resolver problemas antes de executar seu Aplicativo no serviço Data Flow. Você pode compilar e executar exatamente as mesmas versões da biblioteca que o serviço Data Flow executa. A Oracle pode decidir rapidamente se seu problema é um problema com o Data Flow ou com o código do seu aplicativo.
Antes de Começar
Antes de começar a desenvolver seus aplicativos, você precisa configurar e trabalhar o seguinte:
- Um log-in no Oracle Cloud com o recurso de Chave de API ativado. Carregue seu usuário em Identidade /Usuários e confirme se você consegue criar Chaves de API.
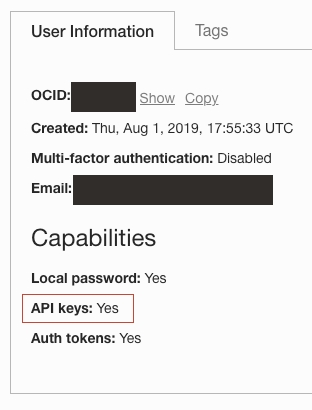
- Uma chave de API registrada e implantada no seu ambiente local. Consulte Registrar uma Chave de API para obter mais informações.
- Uma instalação local funcional do Apache Spark 2.4.4, 3.0.2, 3.2.1 ou 3.5.0. Você pode confirmar isso executando spark-shell na CLI.
- Apache Maven instalado. As instruções e os exemplos usam o Maven para fazer download das dependências necessárias.
Antes de começar, analise execute a segurança no serviço Data Flow. Ele usa um token de delegação que permite que ele faça operações na nuvem em seu nome. Tudo o que sua conta pode fazer na Console do Oracle Cloud Infrastructure, seu job do Spark pode fazer usando o serviço Data Flow. Ao executar no modo local, use uma chave de API que permita que seu aplicativo local faça solicitações autenticadas para vários serviços do Oracle Cloud Infrastructure.
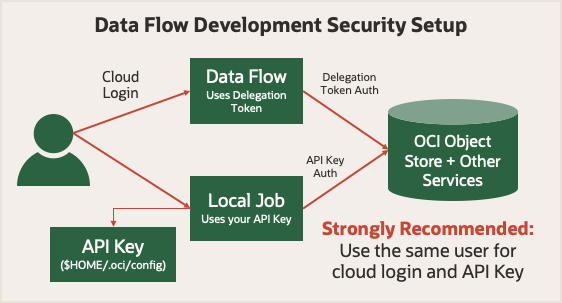
Para manter as coisas simples, use uma chave de API gerada para o mesmo usuário de quando você fez log-in na Console do Oracle Cloud Infrastructure. Isso significa que seus aplicativos têm os mesmos privilégios, independentemente de você executá-los localmente ou no serviço Data Flow.
1. Os Conceitos de Desenvolvimento Local
- Personalize sua instalação local do Spark com arquivos de biblioteca do Oracle Cloud Infrastructure, de forma que ela se pareça com o ambiente de runtime do serviço Data Flow.
- Detecte onde seu código está sendo executado.
- Configure o cliente Oracle Cloud Infrastructure HDFS corretamente.
Para que você possa se mover perfeitamente entre o seu computador e o serviço Data Flow, use determinadas versões do Spark, Scala e Python em sua configuração local. Adicione o arquivo JAR do Oracle Cloud Infrastructure HDFS Connector. Adicione também dez bibliotecas de dependência à instalação do Spark que é instalada quando seu aplicativo é executado no serviço Data Flow. Estas etapas mostram como fazer download e instalar essas dez bibliotecas de dependência.
| Versão do Spark | Versão do Scala | Versão do Python |
|---|---|---|
| 3.5 | 2.12 | 3.11 |
| 3.2.1 | 2.12.15 | 3.8 |
| 3.0.2 | 2.12.10 | 3.6.8 |
| 2.4.4 | 2.11.12 | 3.6.8 |
CONNECTOR=com.oracle.oci.sdk:oci-hdfs-connector:3.3.4.1.4.2
mkdir -p deps
touch emptyfile
mvn install:install-file -DgroupId=org.projectlombok -DartifactId=lombok -Dversion=1.18.26 -Dpackaging=jar -Dfile=emptyfile
mvn org.apache.maven.plugins:maven-dependency-plugin:2.7:get -Dartifact=$CONNECTOR -Ddest=deps
mvn org.apache.maven.plugins:maven-dependency-plugin:2.7:get -Dartifact=$CONNECTOR -Ddest=deps -Dtransitive=true -Dpackaging=pom
mvn org.apache.maven.plugins:maven-dependency-plugin:2.7:copy-dependencies -f deps/*.pom -DoutputDirectory=.echo 'sc.getConf.get("spark.home")' | spark-shellscala> sc.getConf.get("spark.home")
res0: String = /usr/local/lib/python3.11/site-packages/pyspark/usr/local/lib/python3.11/site-packages/pyspark/jarsdeps contém muitos arquivos JAR, a maioria dos quais já está disponível na instalação do Spark. Você só precisa copiar um subconjunto desses arquivos JAR no ambiente Spark:bcpkix-jdk15to18-1.74.jar
bcprov-jdk15to18-1.74.jar
guava-32.0.1-jre.jar
jersey-media-json-jackson-2.35.jar
oci-hdfs-connector-3.3.4.1.4.2.jar
oci-java-sdk-addons-apache-configurator-jersey-3.34.0.jar
oci-java-sdk-common-*.jar
oci-java-sdk-objectstorage-extensions-3.34.0.jar
jersey-apache-connector-2.35.jar
oci-java-sdk-addons-apache-configurator-jersey-3.34.0.jar
jersey-media-json-jackson-2.35.jar
oci-java-sdk-objectstorage-generated-3.34.0.jar
oci-java-sdk-circuitbreaker-3.34.0.jar
resilience4j-circuitbreaker-1.7.1.jar
resilience4j-core-1.7.1.jar
vavr-match-0.10.2.jar
vavr-0.10.2.jardeps para o subdiretório jars encontrado na etapa 2.import com.oracle.bmc.hdfs.BmcFilesystemArquivos JAR Implantados Corretamente 
Se houver um erro, você terá colocado os arquivos no lugar errado. Neste exemplo, há um erro:
Arquivos JAR Implantados Incorretamente 
- Você pode usar o valor de
spark.masterno objetoSparkConfque está definido como k8s://https://kubernetes.default.svc:443 ao executar no serviço Data Flow. - A variável de ambiente
HOMEé definida como/home/dataflowdurante a execução no serviço Data Flow.
Nos aplicativos PySpark, um objeto SparkConf recém-criado está vazio. Para ver os valores corretos, use o método getConf de execução do SparkContext.
| Ambiente de Inicialização |
Definição spark.master |
|---|---|
| Serviço Data Flow |
|
| spark-submit local |
spark.master: local[*] $HOME: Variável |
| Eclipse |
Indefinido $HOME: Variável |
Quando você estiver executando no serviço Data Flow, não altere o valor de
spark.master. Se você fizer isso, seu job não usará todos os recursos provisionados. Quando seu aplicativo é executado no serviço Data Flow, o Oracle Cloud Infrastructure HDFS Connector é configurado automaticamente. Ao executar localmente, você mesmo precisa configurá-lo definindo as propriedades de configuração do HDFS Connector
No mínimo, você precisa atualizar seu objeto SparkConf para definir valores para fs.oci.client.auth.fingerprint, fs.oci.client.auth.pemfilepath, fs.oci.client.auth.tenantId, fs.oci.client.auth.userId e fs.oci.client.hostname.
Se a chave da API tiver uma frase-senha, você precisará definir fs.oci.client.auth.passphrase.
Essas variáveis podem ser definidas após a criação da sessão. No seu ambiente de programação, use os respectivos SDKs para carregar corretamente a configuração da Chave de API.
ConfigFileAuthenticationDetailsProvider conforme apropriado:import com.oracle.bmc.auth.ConfigFileAuthenticationDetailsProvider;
import com.oracle.bmc.ConfigFileReader;
//If your key is encrypted call setPassPhrase:
ConfigFileAuthenticationDetailsProvider authenticationDetailsProvider = new ConfigFileAuthenticationDetailsProvider(ConfigFileReader.DEFAULT_FILE_PATH, "<DEFAULT>");
configuration.put("fs.oci.client.auth.tenantId", authenticationDetailsProvider.getTenantId());
configuration.put("fs.oci.client.auth.userId", authenticationDetailsProvider.getUserId());
configuration.put("fs.oci.client.auth.fingerprint", authenticationDetailsProvider.getFingerprint());
String guessedPath = new File(configurationFilePath).getParent() + File.separator + "oci_api_key.pem";
configuration.put("fs.oci.client.auth.pemfilepath", guessedPath);
// Set the storage endpoint:
String region = authenticationDetailsProvider.getRegion().getRegionId();
String hostName = MessageFormat.format("https://objectstorage.{0}.oraclecloud.com", new Object[] { region });
configuration.put("fs.oci.client.hostname", hostName);oci.config.from_file conforme apropriado:import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
# Check to see if we're in Data Flow or not.
if os.environ.get("HOME") == "/home/dataflow":
spark_session = SparkSession.builder.appName("app").getOrCreate()
else:
conf = SparkConf()
oci_config = oci.config.from_file(oci.config.DEFAULT_LOCATION, "<DEFAULT>")
conf.set("fs.oci.client.auth.tenantId", oci_config["tenancy"])
conf.set("fs.oci.client.auth.userId", oci_config["user"])
conf.set("fs.oci.client.auth.fingerprint", oci_config["fingerprint"])
conf.set("fs.oci.client.auth.pemfilepath", oci_config["key_file"])
conf.set(
"fs.oci.client.hostname",
"https://objectstorage.{0}.oraclecloud.com".format(oci_config["region"]),
)
spark_builder = SparkSession.builder.appName("app")
spark_builder.config(conf=conf)
spark_session = spark_builder.getOrCreate()
spark_context = spark_session.sparkContext
No SparkSQL, a configuração é gerenciada de forma diferente. Essas definições são informadas usando a opção --hiveconf. Para executar consultas SQL do Spark, use um script wrapper semelhante ao exemplo. Quando você executa o script no serviço Data Flow, essas definições são feitas automaticamente para você.
#!/bin/sh
CONFIG=$HOME/.oci/config
USER=$(egrep ' user' $CONFIG | cut -f2 -d=)
FINGERPRINT=$(egrep ' fingerprint' $CONFIG | cut -f2 -d=)
KEYFILE=$(egrep ' key_file' $CONFIG | cut -f2 -d=)
TENANCY=$(egrep ' tenancy' $CONFIG | cut -f2 -d=)
REGION=$(egrep ' region' $CONFIG | cut -f2 -d=)
REMOTEHOST="https://objectstorage.$REGION.oraclecloud.com"
spark-sql \
--hiveconf fs.oci.client.auth.tenantId=$TENANCY \
--hiveconf fs.oci.client.auth.userId=$USER \
--hiveconf fs.oci.client.auth.fingerprint=$FINGERPRINT \
--hiveconf fs.oci.client.auth.pemfilepath=$KEYFILE \
--hiveconf fs.oci.client.hostname=$REMOTEHOST \
-f script.sql
Os exemplos anteriores alteram apenas a forma como você constrói seu Contexto do Spark. Nada mais no seu aplicativo Spark precisa mudar para que você possa desenvolver outros aspectos do seu aplicativo Spark como faria normalmente. Ao implantar seu aplicativo Spark no serviço Data Flow, você não precisa alterar qualquer código ou configuração.
2. Criando "Fat JARs" para Aplicativos Java
Os aplicativos Java e Scala geralmente precisam incluir mais dependências em um arquivo JAR conhecido como "Fat JAR".
Se você usar o Maven, poderá fazer isso usando o plug-in Shade. Os exemplos a seguir são de arquivos pom.xml do Maven. Você pode utilizá-los como ponto de partida para seu projeto. Quando você cria seu aplicativo, as dependências são automaticamente baixadas e inseridas no ambiente de runtime.
Se estiver usando o Spark 3.5.0 ou o 3.2.1, este capítulo não se aplicará. Em vez disso, siga o capítulo 2. Gerenciando Dependências do Java para Aplicativos Apache Spark no Serviço Data Flow.
Esta parte pom.xml inclui as versões corretas das bibliotecas do Spark e do Oracle Cloud Infrastructure para o serviço Data Flow (Spark 3.0.2). Ela aponta para o Java 8 e oculta os arquivos de classe conflitantes comuns.
<properties>
<oci-java-sdk-version>1.25.2</oci-java-sdk-version>
</properties>
<dependencies>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-hdfs-connector</artifactId>
<version>3.2.1.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-core</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-objectstorage</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.2</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.0</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>example.Example</mainClass>
</transformer>
</transformers>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<relocations>
<relocation>
<pattern>com.oracle.bmc</pattern>
<shadedPattern>shaded.com.oracle.bmc</shadedPattern>
<includes>
<include>com.oracle.bmc.**</include>
</includes>
<excludes>
<exclude>com.oracle.bmc.hdfs.**</exclude>
</excludes>
</relocation>
</relocations>
<artifactSet>
<excludes>
<exclude>org.bouncycastle:bcpkix-jdk15on</exclude>
<exclude>org.bouncycastle:bcprov-jdk15on</exclude>
<!-- Including jsr305 in the shaded jar causes a SecurityException
due to signer mismatch for class "javax.annotation.Nonnull" -->
<exclude>com.google.code.findbugs:jsr305</exclude>
</excludes>
</artifactSet>
</configuration>
</plugin>
</plugins>
</build>Esta parte pom.xml inclui as versões corretas das bibliotecas do Spark e do Oracle Cloud Infrastructure para o serviço Data Flow (Spark 2.4.4). Ela aponta para o Java 8 e oculta os arquivos de classe conflitantes comuns.
<properties>
<oci-java-sdk-version>1.15.4</oci-java-sdk-version>
</properties>
<dependencies>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-hdfs-connector</artifactId>
<version>2.7.7.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-core</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-objectstorage</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.4</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>2.4.4</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.0</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>example.Example</mainClass>
</transformer>
</transformers>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<relocations>
<relocation>
<pattern>com.oracle.bmc</pattern>
<shadedPattern>shaded.com.oracle.bmc</shadedPattern>
<includes>
<include>com.oracle.bmc.**</include>
</includes>
<excludes>
<exclude>com.oracle.bmc.hdfs.**</exclude>
</excludes>
</relocation>
</relocations>
<artifactSet>
<excludes>
<exclude>org.bouncycastle:bcpkix-jdk15on</exclude>
<exclude>org.bouncycastle:bcprov-jdk15on</exclude>
<!-- Including jsr305 in the shaded jar causes a SecurityException
due to signer mismatch for class "javax.annotation.Nonnull" -->
<exclude>com.google.code.findbugs:jsr305</exclude>
</excludes>
</artifactSet>
</configuration>
</plugin>
</plugins>
</build>3. Testando o Seu Aplicativo Localmente
Antes de implantar seu aplicativo, você pode testá-lo localmente para ter certeza de que ele funciona. Há três técnicas que você pode usar; selecione a que funciona melhor para você. Estes exemplos assumem que o nome do artefato do aplicativo é application.jar (para Java) ou application.py (para Python).
- O serviço Data Flow oculta a maioria do código-fonte e das bibliotecas que ele usa para execução, portanto, as versões do SDK do serviço Data Flow não precisam mais de correspondência e conflitos de dependência de terceiros com o serviço Data Flow não devem ocorrer.
- O upgrade do Spark foi feito para que os SDKs do OCI agora sejam compatíveis com ele. Isso significa que dependências conflitantes de terceiros não precisam se mover, portanto, as bibliotecas de aplicativos e bibliotecas podem ser separadas para compilações mais rápidas, menos complicadas, menores e mais flexíveis.
- O novo arquivo de modelo pom.xml é baixado e cria uma cópia quase idêntica do Data Flow na máquina local de um desenvolvedor. Isto significa que:
- Os desenvolvedores podem executar o depurador de etapas em sua máquina local para detectar e resolver problemas rapidamente antes de executar o serviço Data Flow.
- Os desenvolvedores podem compilar e executar exatamente as mesmas versões da biblioteca que o serviço Data Flow executa. Portanto, a equipe do serviço Data Flow pode decidir rapidamente se um problema é um problema com o serviço Data Flow ou com o código do aplicativo.
Método 1: Executar no IDE
Se você desenvolveu em um IDE como o Eclipse, não precisará fazer nada além de clicar em Executar e selecionar a classe principal apropriada. 
Quando você executa, é normal ver o Spark produzir mensagens de advertência na Console, que informam que o Spark está sendo chamado. 
Método 2: Executar o PySpark na Linha de Comando
python3 application.py$ python3 example.py
Warning: Ignoring non-Spark config property: fs.oci.client.hostname
Warning: Ignoring non-Spark config property: fs.oci.client.auth.fingerprint
Warning: Ignoring non-Spark config property: fs.oci.client.auth.tenantId
Warning: Ignoring non-Spark config property: fs.oci.client.auth.pemfilepath
Warning: Ignoring non-Spark config property: fs.oci.client.auth.userId
20/08/01 06:52:00 WARN Utils: Your hostname resolves to a loopback address: 127.0.0.1; using 192.168.1.41 instead (on interface en0)
20/08/01 06:52:00 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
20/08/01 06:52:01 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableMétodo 3: Usar o Spark-Submit
O utilitário spark-submit é incluído na distribuição do Spark. Use esse método em algumas situações, por exemplo, quando um aplicativo PySpark exigir arquivos JAR extras.
spark-submit:spark-submit --class example.Example example.jarComo você precisa fornecer o nome de classe principal ao serviço Data Flow, esse código é uma boa maneira de confirmar se você está usando o nome de classe correto. Lembre-se de que nomes de classe fazem distinção entre maiúsculas e minúsculas.
spark-submit para executar um aplicativo PySpark que exige arquivos JAR JDBC Oracle:
spark-submit \
--jars java/oraclepki-18.3.jar,java/ojdbc8-18.3.jar,java/osdt_cert-18.3.jar,java/ucp-18.3.jar,java/osdt_core-18.3.jar \
example.py4. Implantar o Aplicativo
- Copie o artefato do aplicativo (arquivo
jar, script Python ou script SQL) para o Oracle Cloud Infrastructure Object Storage. - Se seu aplicativo Java tiver dependências não fornecidas pelo Fluxo de Dados, lembre-se de copiar o arquivo
jarda montagem. - Crie um Aplicativo Data Flow que mencione esse artefato no Oracle Cloud Infrastructure Object Storage.
Após a etapa 3, você poderá executar o Aplicativo quantas vezes desejar. Para obter mais informações, o tutorial Conceitos Básicos do Oracle Cloud Infrastructure Data Flow o conduzirá por cada etapa do processo.
O Que Vem a Seguir
Agora você sabe como desenvolver seus aplicativos localmente e implantá-los no serviço Data Flow.