Release 1 (9.0.1)
Part Number A89867-02
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Real Application Clusters Concepts Release 1 (9.0.1) Part Number A89867-02 |
|
![]()
![]()
This chapter describes the architectural components used in Oracle Real Application Clusters processing. These components are used in addition to the components for single instances. They are thus unique to Real Application Clusters. Some of these components are supplied with Oracle database software and others are vendor-specific.
Topics in this chapter include:
Oracle9i Database Concepts for more information about Oracle's single instance architectural components
See Also:
This section is an overview of Real Application Clusters, and how it uses Cache Fusion. Cache Fusion is a diskless cache coherency mechanism. Cache Fusion provides copies of blocks directly from the holding instance's memory cache to the requesting instance's memory cache.
Each hardware vendor implements cluster database processing by using Operating System-Dependent (OSD) Layers. These layers provide communication links between the Operating System and the Real Application Clusters software described in this chapter.
Clustered systems are composed of several components that synchronize operations among multiple nodes accessing a shared database. A high-level view of these components in the Cache Fusion architecture appears in Figure 2-1.
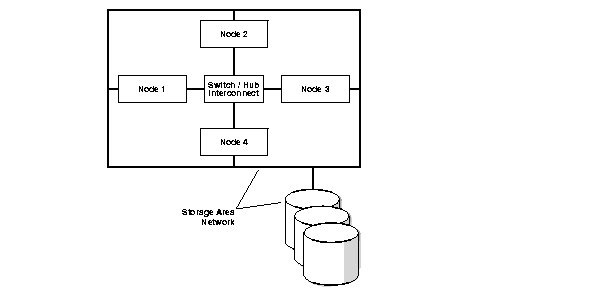
Real Application Clusters has these components:
The Cluster Manager (CM) oversees internode messaging that travels over the interconnect to coordinate internode operations. The Global Cache Service (GCS) oversees the operation of GCS resource and Global Enqueue Service (GES) enqueues. The cluster interconnect serves as a messaging pathway among the nodes, and the shared disk drivers control access to the shared disk subsystems. The following section describes these components in more detail.
The Cluster Manager provides a global view of the cluster and all nodes in it. It also controls cluster membership. Typically, the Cluster Manager is a vendor-supplied component. However, Oracle supplies the Cluster Manager for Windows NT environments.
Real Application Clusters also cooperates with the Cluster Manager to achieve high availability. Working in conjunction with the Cluster Manager is the Global Services Daemon (GSD). This daemon receives requests from the Real Application Clusters Control (SRVCTL) utility to execute administrative job tasks, such as Startup (START) or shutdown. The command is executed locally on each node, and the results are sent back to SRVCTL.
A Cluster Manager disconnect can occur for three reasons. The client:
This is true even if one or more nodes fail. If the Cluster Manager determines that a node is inactive or not functioning properly, the Cluster Manager terminates all processes on that node or instance.
If there is a failure, recovery is transparent to user applications. The Cluster Manager automatically reconfigures the system to isolate the failed node and then notifies the Global Cache Service of the status. Real Application Clusters then recovers the database to a valid state.
The Cluster Manager includes a subset of functionality known as a node monitor. The Node Monitor polls the status of various resources in a cluster including nodes, interconnect hardware and software, shared disks, and Oracle instances. The way that the Cluster Manager and its node monitor performs these operations is based on Oracle's implementation of the Operating System-Dependent (OSD) Layer.
The Cluster Manager informs clients and the Oracle server when the status of resources within a cluster change. For example, Real Application Clusters must know when another database instance registers with the Cluster Manager or when an instance disconnects from it.
As mentioned, the Cluster Manager monitors the status of various cluster resources, including nodes, networks and instances. The Node Monitor also serves the Cluster Manager by:
When you start Real Application Clusters instances, the alert log file shows the activity of various background processes. One of these is the diagnosability daemon. This daemon captures diagnostic data on instance process failures. No user control is required for this daemon. The diagnosability daemon should not be disabled or removed.
The Global Cache Service and Global Enqueue Service are integrated components of Real Application Clusters that coordinate simultaneous access to the shared database and to shared resources within the database. They do this to maintain consistency and data integrity. This section describes the following features of the Global Cache Service and Global Enqueue Service:
The coordination of access to resources that is performed by the Global Cache Service and Global Enqueue Service are transparent to applications. Applications continue to use the same concurrency mechanisms used in single instance environments.
The Global Cache Service and Global Enqueue Service maintain a Global Resource Directory to record information about resources and enqueues held on these resources. The Global Resource Directory resides in memory and is distributed throughout the cluster to all nodes. In this distributed architecture, each node participates in managing global resources and manages a portion of the Global Resource Directory. This distributed resource management scheme provides fault tolerance and enhanced runtime performance.
The Global Cache Service and Global Enqueue Service have fault tolerance. They provide continual service and maintain the integrity of the Global Resource Directory even if multiple nodes fail. The shared database is accessible as long as at least one instance is active on that database after recovery is completed.
Fault tolerance also enables Real Application Clusters instances to start and stop at any time, in any order. However, instance reconfiguration can cause a brief delay.
The Global Cache Service and Global Enqueue Service maintain information about a resource on all nodes that need access to it. The Global Cache Service and Global Enqueue Service usually nominate one node to manage all information about a resource.
Real Application Clusters uses a resource mastering scheme in which a resource is assigned based on its resource name to one of the instances that acts as the master for the resource. This results in an even and arbitrary distribution of resources among all available nodes. Every resource is associated with a master node.
The Global Cache Service and Global Enqueue Service optimize the method of resource mastering to achieve better load distribution and to speed instance startup. The method of resource mastering affects system performance during normal runtime activity as well as during instance startup. Performance is optimized when a resource is mastered locally at the instance that most frequently accesses it.
The Global Cache Service and Global Enqueue Service employ resource affinity. Resource affinity is the use of dynamic resource remastering to move the location of the resource masters for a database file to the instance where resource operations are most frequently occurring. This optimizes the system in situations where update transactions are being executed on one instance. When activity shifts to another instance the resource affinity will correspondingly move to the new instance. If activity is not localized, the resource ownership is distributed to the instances equitably. Dynamic resource remastering is the ability to move the ownership of a resource between instances of Real Application Clusters during runtime and without affecting availability. It can be used to defer resource mastering when new instances enter the cluster. Resource remastering is deferred when instances enter or leave the cluster.
Assume that a node in a cluster needs to modify block number n in the database. At the same time, another node needs to update the same block to complete a transaction.
Without the Global Cache Service, both nodes would simultaneously update the same block. With the Global Cache Service, only one node can update the block; the other node must wait. The Global Cache Service ensures that only one instance has the right to update a block at any given time. This provides data integrity by ensuring that all changes made are saved in a consistent manner.
The Global Cache Service and Global Enqueue Service operate independently of the Cluster Manager. They rely on the Cluster Manager for timely and correct information about the status of other nodes. If the Global Cache Service and Global Enqueue Service cannot get the information they need from a particular instance in the cluster, then they will shut down the instance that is out of communication. This ensures the integrity of Real Application Clusters databases, as each instance must be aware of all other instances to coordinate disk access.
Real Application Clusters derives most of its functional benefits from its ability to run on multiple interconnected machines. Real Application Clusters relies heavily on the underlying high speed interprocess communication (IPC) component to facilitate this.
The IPC defines the protocols and interfaces required for the Real Application Clusters environment to transfer messages between instances. Messages are the fundamental units of communication in this interface. The core IPC functionality is built around an asynchronous, queued messaging model. IPC is designed to send and receive discrete messages as fast as the hardware allows. With an optimized communication layer, various services can be implemented above it. This is how the Global Cache Service and the Cluster Manager perform their communication duties.
In addition to the OSD layers, Real Application Clusters also requires that all nodes must have simultaneous access to the disks. This gives multiple instances concurrent access to the same database.
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|