Release 2 (v9.0.2)
Part Number A95949-01
Home |
Solution Area |
Contents |
Index |
| Oracle9i Warehouse Builder User's Guide Release 2 (v9.0.2) Part Number A95949-01 |
|
This chapter describes how to load and refresh a data warehouse using scheduling and dependency management tools. After you generate and deploy scripts, register them as jobs with Oracle Enterprise Manager or another scheduling tool. You can use a dependency management tool such as Oracle Workflow to run multiple job processes with dependencies. Schedule these Workflow processes to load or update the warehouse. The Warehouse Builder Workflow Queue Listener monitors the processes and ensures that dependencies are handled in the correct order. After the processes have completed, view the results using the Warehouse Builder Runtime Audit Viewer.
For information about Oracle Workflow, see the Oracle Workflow Guide. For more information about Oracle Enterprise Manager, see the Oracle Enterprise Manager Administrator's Guide.
This chapter includes the following topics:
After the target warehouse module is deployed, the warehouse is created and the Tcl or mapping scripts are stored there. In order to run the Tcl scripts and load the warehouse, first register the scripts with Enterprise Manager or another scheduling tool.
To schedule jobs with Enterprise Manager, the following steps must be completed:
For more information, see the Oracle9i Warehouse Builder Installation Guide.
To register deployed scripts with Enterprise Manager:
The scripts must be saved before you register them.
Warehouse Builder connects with Enterprise Manager, registers the load scripts, and displays a confirmation list.
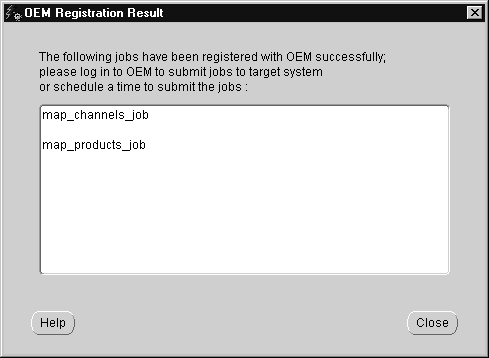
After the scripts have been registered with Enterprise Manager, you can either:
These processes can then also be scheduled with Enterprise Manager. Workflow processes are effective because they contain all the job dependencies and ensure that the warehouse is loaded and refreshed in the correct sequence.
When you load data or update existing data into a data warehouse, you must run the scripts in strict sequence to ensure that all foreign key references are satisfied. The referenced tables must be loaded before the tables making the reference.
For example, dimension tables must be loaded before the related fact table. A materialized view cannot be refreshed until the related fact table and referenced dimensions have been loaded.
You can create multiple job processes by defining a Workflow process in Oracle Workflow. When you schedule the processes, the Workflow server ensures that the jobs run in the proper sequence. If an exception occurs, the Workflow server terminates the process.
To define a Workflow process, the following steps must be completed:
If you plan to schedule the workflow process with Enterprise Manager, deploy the process to the Enterprise Manager Job Library.
After you register the Tcl scripts as jobs with Enterprise Manager, you can deploy the scripts to the Workflow server using the Workflow Deployment Wizard.
To deploy scripts to the Workflow server:
The Workflow Deployment Wizard Welcome page displays.
The Workflow Login page displays.
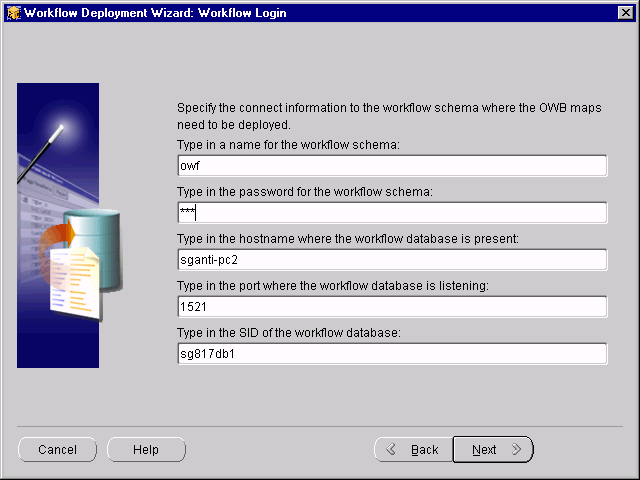
Warehouse Builder uses this information to establish a session with the Workflow server.
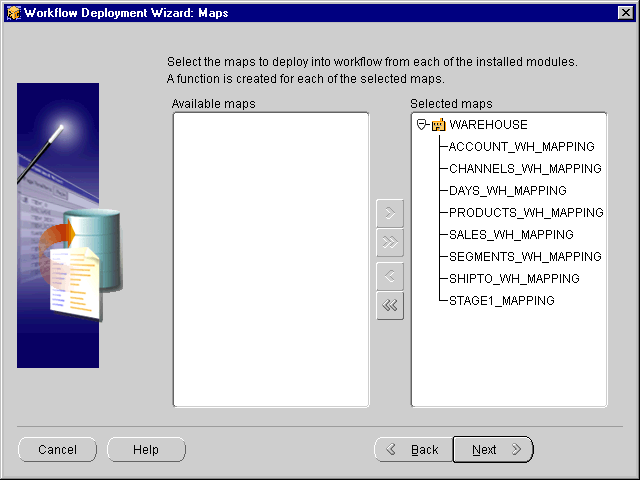
The Maps page displays a list of available mappings to be deployed.
The wizard displays the Functions page, which shows the function names assigned to the mappings.
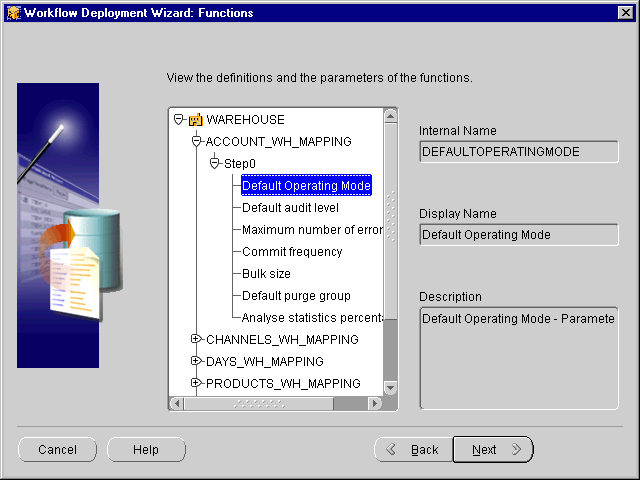
To display the internal function name for a mapping, select the mapping in the navigation tree.
You cannot modify names on this page.
The Item Type page displays.
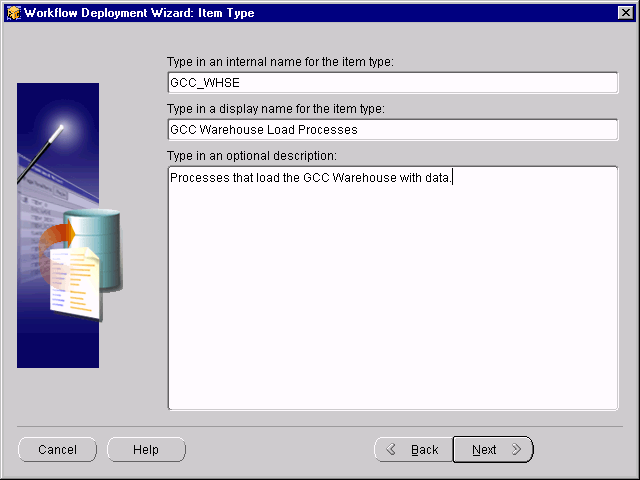
Specify the following:
The Process page displays.
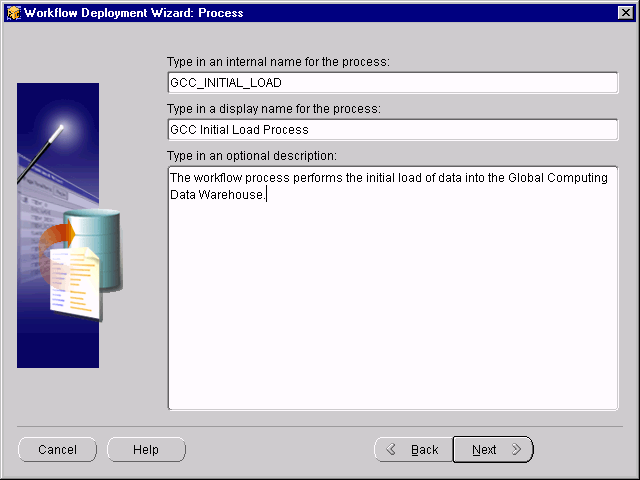
Specify the following information:
The Finish page displays. Verify the contents of this page. Use the Back button to make changes.
The wizard deploys the name of the process to the Enterprise Manager Job Library only if the warehouse module is configured for Enterprise Manager.
The wizard deploys the mappings as a set of Workflow functions defined with the specified item type to the Workflow server.
You can now start the Workflow Builder and define a process to load or update the warehouse.
To define a Workflow process:
The Workflow Builder navigator window displays.
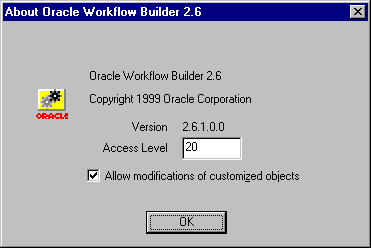
The Workflow Deployment Wizard assigns each function an access level of twenty during the deployment operation.
To edit these functions, you must set the access level of the Workflow Builder client to a value less than or equal to twenty.
The Open dialog displays.
The Show Item Types window displays a list of item types.
The Workflow Navigator window displays.
Workflow Builder displays tree entries for the mappings deployed from Warehouse Builder.
The process displays in a separate window with the functions overlapped.
Figure 10-11 shows the Workflow process that sequences the functions to load a data warehouse.
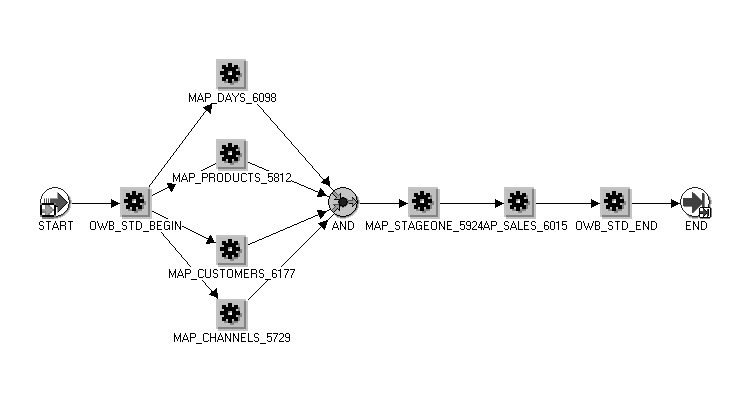
After the Workflow server executes this job, the functions are processed so that the execution of a function depends on the successful completion of all its predecessors. The dimension tables are loaded in parallel but the remaining two jobs run sequentially.
You can schedule a Workflow process using Enterprise Manager if the Workflow process has been deployed to the Enterprise Manager Job Library. Select the Deploy checkbox on the Finish page of the Workflow Wizard to deploy the process.
To schedule a Workflow process:
The Edit Job window displays.
If you are scheduling the process to begin immediately, select the Submit radio button.
You can view jobs in the Enterprise Manager Jobs window. You can track the status of a submitted job from the Active tab. After the job has completed, you can check its status in the History tab.
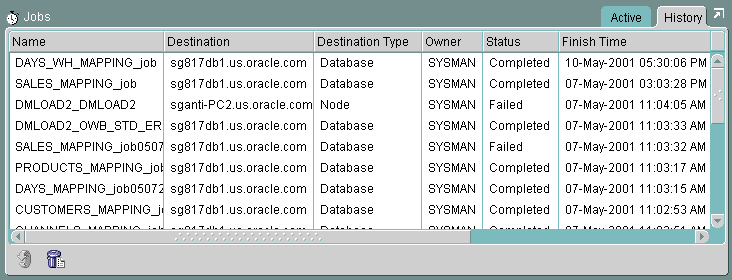
Right-click the job name on the History tab to display a pop-up list that enables you to view more details regarding the job, remove the job from the history log, or create another job like the selected job.
The Enterprise Manager log contains summary information about execution. For detailed information about the job, use the Warehouse Builder Runtime Audit Viewer. For more information on Enterprise Manager, see the Oracle Enterprise Manager Administrator's Guide.
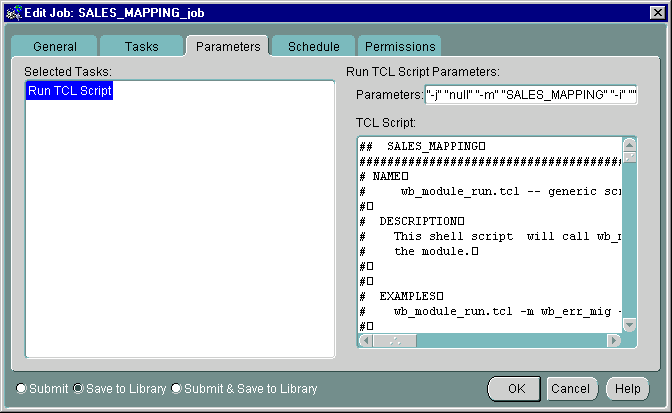
Parameters are set in the mapping configuration in Warehouse Builder. You can modify parameters in the Tcl script before you submit the job.
To modify a parameter value for a job:
The Job Editor window appears.
The Warehouse Builder Runtime Audit Viewer displays details of a job after it is run. This information can be useful when you are scheduling jobs. The Audit Viewer displays the contents of the Warehouse Builder Runtime Library for a load or refresh job. For example, you can display the number of records read, number of records inserted or updated, and detailed information about individual records when errors occur. This information helps you troubleshoot load errors.
The Runtime Audit Viewer window has two panes. The left pane contains a navigation tree with objects grouped by object type. The right pane displays information about the node that is currently selected in the navigation tree.
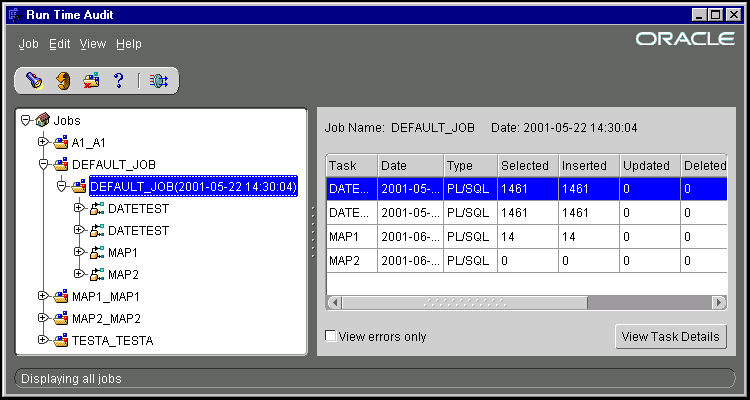
The nodes in the navigation tree below the top Jobs node each represent a job. Jobs are listed in alphabetical order. To set up a mapping job, register it as a Workflow Process. The corresponding node appears in the navigation tree after the first run of the Workflow process.
Select the Jobs node at the top of the navigation tree to display the list of jobs. This includes DEFAULT_JOB and any other named jobs that have been run.
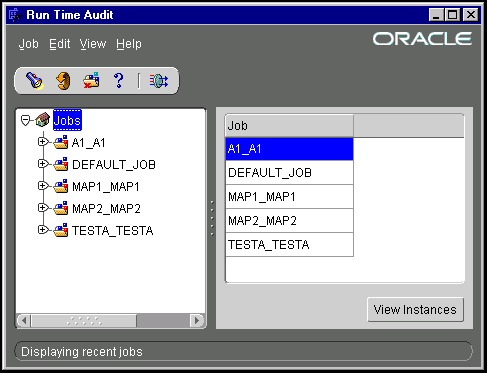
A mapping can be executed from either Warehouse Builder or Enterprise Manager, or it can be used as a component execution unit within a Workflow process.
When a mapping is executed from Warehouse Builder, the audit and error information is stored under the category Default Job. When a Workflow process is run, the audit and error information for the mappings is stored under the name of the Workflow process.
Expand a job node to display the job instance nodes in the navigation tree. Each time a job run starts, a new job instance is added. The text shows the name of the job and the time the run started.
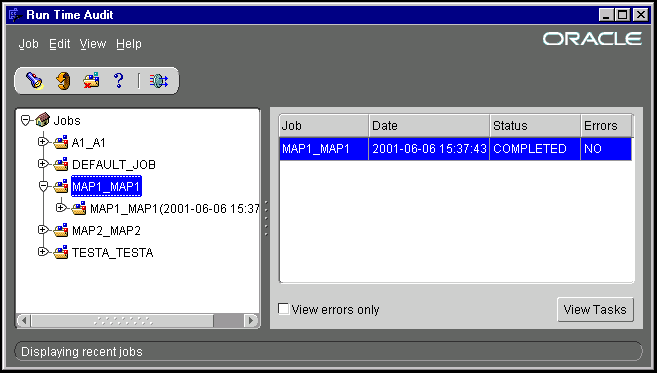
Selecting a job node in the tree or a job entry in the right hand pane and clicking the View Instances button displays details about job instances. A job instance represents a specific run of the job.
If the View errors only box is checked, a job instance is displayed only if it has errors.
A node representing a job instance can be expanded to display Tasks that are part of the run. For example, the execution of a PL/SQL mapping or an SQL*Loader run is represented as a Task. If a Workflow Process consists of several tasks, each running a PL/SQL mapping, a node representing a run of the Workflow Process has a Task node for each of those mappings.
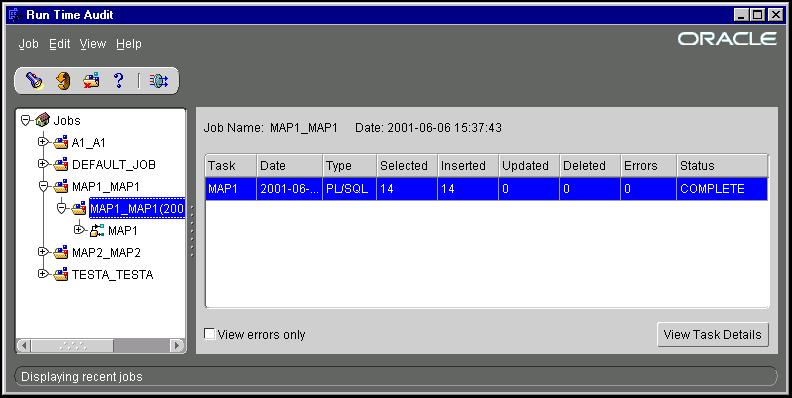
Table 10-1 lists the information displayed for each Task.
You can expand a task node to display a set of Detailed Mappings, which are also called target entries. In many cases there is only one Detailed Mapping for a task, but different scenarios can cause a task to have more than one Detailed Mapping.
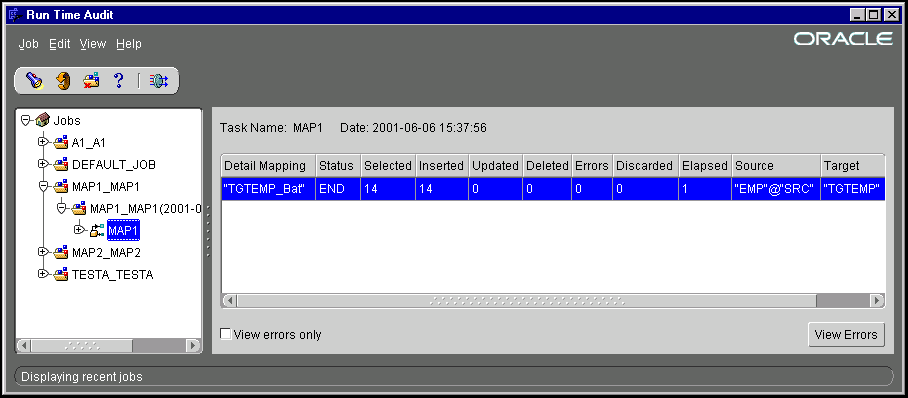
Selecting a task node in the tree, or the Targets node below it, or selecting a task entry in the right-hand pane and clicking View Task Details displays information about its Detailed Mappings. A Detailed Mapping entry represents a mapping to a specific target table. A task that affects multiple target tables has a Detailed Mapping entry for each target table. Also, if a PL/SQL mapping is run in set-based fail over mode, and the set-based run detects errors for a specific target table, there are two Detailed Mapping entries for the table. One is for the set-based run and one is for the row-based run.
If the relevant detailed mapping cannot be started when processing a task, there is no Detailed Mapping entry for it. For example, a set-based run cannot be started with certain Loading Types, such as DELETE. In this case, although a set-based fail over run immediately switches to row-based mode, a pure set-based run causes the mapping to be abandoned. The task itself is not marked as COMPLETE, and it has a reduced or empty list of Detailed Mappings.
If the View errors only box is checked, only those Detailed Mapping entries with errors are displayed.
For PL/SQL mappings, the values of the statistics reported depend on the mode in which the mapping is run. For example, in:
The Runtime Audit Viewer can only report on audit information that has been stored during the relevant mapping runs. The default Audit Level for a mapping is defined in the mapping configuration parameters. You can change this value when you configure the mappings. This value can be overridden in the runtime Tcl parameters.
For PL/SQL mappings, the audit levels are:
To use the Runtime Audit Viewer:
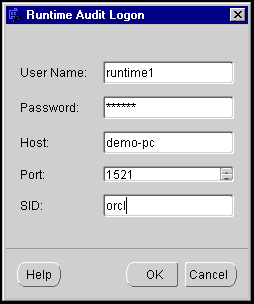
The Runtime Audit Logon dialog displays.
The Runtime Audit Viewer displays. The left pane contains a navigation tree. The right pane contains a list of details for the currently selected node.
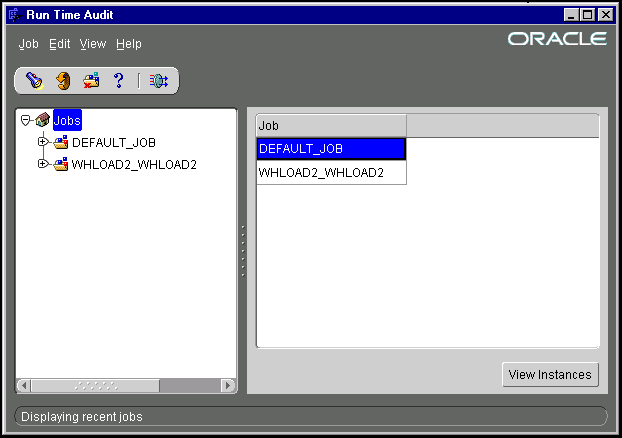
When the Audit Viewer first opens, all of the objects are rolled up under the Jobs node. As you expand the nodes, you see the following layers of objects:
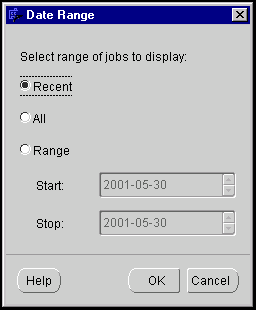
You can specify the results you can view by defining date range, or by performing a search. By default, the most recent job instance is displayed in the tree.
To select a date range:
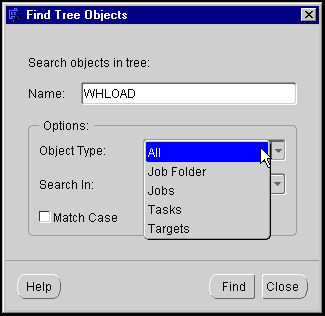
To search for objects by name:
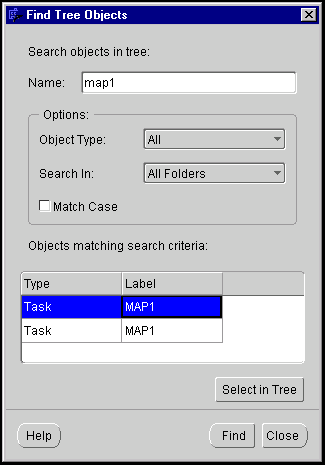
A list of objects matching the search criteria displays. You can click one of these entries and then click Select in Tree to select the relevant object in the navigation tree.
You can refresh the data displayed in the Audit Viewer by selecting Refresh from the View menu. This is useful if you are checking for errors or troubleshooting a job.
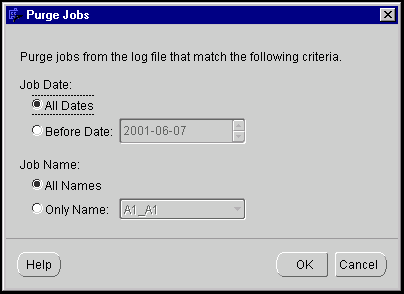
You can purge jobs from the runtime tables using the Runtime Audit Viewer. To purge runtime entries, select Purge from the Job menu or the toolbar. The Audit Viewer displays the Purge Jobs dialog. You can purge jobs according to Job Date or Job Name.
|
|
 Copyright © 1996, 2002 Oracle Corporation. All Rights Reserved. |
|