

|
|
|
|
|
|
Designing and Developing BEA MessageQ Applications
Message queuing provides a flexible approach to distributed application development because applications share information through messages stored in queues. Because BEA MessageQ provides a set of portable API functions that support all industry-leading platforms, it frees applications from having to embed operating system or network-specific code in order to accomplish message exchange.
Read the following sections to learn more building BEA MessageQ applications:
Designing a BEA MessageQ Application
To design a distributed application using BEA MessageQ, application developers need to:
The first step in developing any application is to identify the business problem. As you research the current user environment and learn about their problems, you will soon determine whether the business need calls for a new application, or if the need is for existing applications to be integrated. Whether the solution requires the integration of new or existing applications, you can employ message queuing as the operating system- and network-independent "glue" that allows the application components to share information.
For example, let's break down the problem solved by our shop-floor monitoring example as shown in Figure 3-1.
Figure 3-1 Sample BEA MessageQ Application
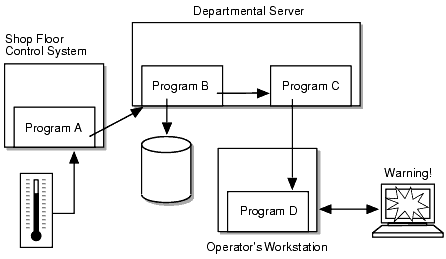
In this case, the user group needed to:
The design of the application to solve this problem calls for a number of separate application components as follows:
Message queuing was chosen as the integration approach because it provides a loosely-coupled asynchronous means to pass information between application components with high throughput and platform independence. Program A uses datagram-style messaging to quickly pass temperature readings to Program B at 30 second intervals. Program B reads the messages from its memory-based queue and writes them to a database from which they can be analyzed.
Program B also forwards the temperature readings to Program C which checks whether they are above or below an acceptable range. If an unacceptable temperature reading is received, Program C sends a message to Program D running on a shop-floor workstation to trigger a display that alerts a supervisor to the out-of-range condition.
Developing the Communications Model
After you have broken down the application problem into its program components, you are ready to decide the communication model that must be used for each set of interacting programs.
The simplest style of messaging is called datagram messaging. This is a one-way flow of information between two applications that does not follow a request/response paradigm. In our shop-floor monitoring application, for example, temperature readings are sent as datagram messages to the monitoring application. The application reading the temperatures does not require a response to each reading.
In addition to datagram style messaging, request/response messaging can be used to implement the client/server model of application integration. Using this model a client program sends a request to a server program. The server program reads the request, processes it, and returns the results to the client as shown in Figure 3-2.
Figure 3-2 Request/Response Messaging Paradigm
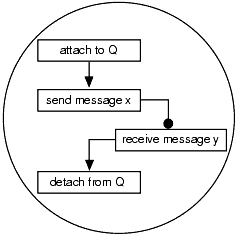
A more complex communication model that can be used for client/server or peer-to-peer messaging uses queues as service points. Using this model, sender programs direct requests or simply send information in the form of messages to a central queue. Several receiver programs may read the queue, obtain the request or information, process it, and then read the queue for another message as shown in Figure 3-3.
Figure 3-3 Service Point Messaging Paradigm
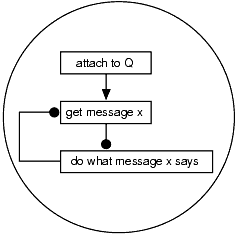
The communication model determines much of the system design, including the structure of the sender and receiver programs and the message queue configuration. The system designer uses the message queuing communication model that is most efficient for message exchange between each set of application components to be integrated.
Defining Major Application Needs
In addition to designing the most efficient communications model, the application developer must determine how to use BEA MessageQ features to implement the application design. The questions and answers in this topic can help the application developer to identify some of the major aspects of system design and development using BEA MessageQ such as:
Choosing the Style of Messaging
Message throughput depends on the style of messaging selected and the delivery mode of the message. For example, buffer-style messaging is faster than FML-based self-describing messaging, because of the extra steps of message encoding and decoding. In addition, limiting message size for buffer-style messages to 32K enables messages to be delivered faster over the distributed network. Though the selection of messaging style is based on the needs of the application, it is important for application developers to consider the performance implications of each messaging style when electing which style to use.
In addition to the selection of messaging style, the delivery mode is the other critical factor in determining messaging throughput. If an application requires high messaging rates, the application developer selects a delivery mode which sends the message to the target queue in memory and requires no notification of whether the message is received (PDEL_MODE_NN_MEM). This kind of message is called a datagram because it requires the least processing overhead and provides the fastest messaging throughput. BEA MessageQ is capable of sending datagrams at rates of thousands of messages per second.
Datagram messaging, however, is only useful for applications that do not require a guarantee that every message is received. In our shop-floor monitoring example, the program that sends temperature readings uses datagram messages because, if one message is not received, the next will be sent in 30 seconds. It is not necessary for the receiver program to get every message in order to promptly report on out-of-range conditions.
Choosing Recoverable or Nonrecoverable Message Delivery
In contrast to datagram style messaging, some applications require a guarantee that the message be delivered, though the speed of delivery is not of great concern. For example, a developer could use message queuing to integrate the components of a manufacturing resource planning (MRP) system. In the just-in-time manufacturing environment, it is critically important that the order processing application notify the inventory application when goods are sold because manufacturing scheduling is based on inventory levels.
In this case, the developer could use recoverable messaging to exchange this kind of important information between applications to ensure that the inventory level is accurately maintained. Recoverable messaging reduces messaging throughput because of the additional system resources required to save messages on disk in case they cannot be delivered. However, the value of automatic recovery in the event of system, process, or network failures might outweigh the disadvantage of additional processing time.
Choosing Asynchronous or Synchronous Messaging
Interdependent applications use a blocking request/response paradigm. For example, when Program A sends a message to Program B, it halts processing until it receives a reply from Program B. BEA MessageQ offers delivery modes to support synchronous communication (PDEL_MODE_WF_xxx).
For example, let's look at a banking application. A bank teller may enter a request for a withdrawal of money from a customer's account. The banking application requires that the customer's account balance be checked and sufficient funds available before the withdrawal can be made. Therefore, the request message is sent using a blocking delivery mode. The request transaction cannot continue processing until the server application checks the account balance, verifies that the amount of money requested is available for withdrawal, and returns a response to the requesting application to proceed with the transaction.
Other applications share data but operate independently. These applications use asynchronous messaging; the sender program sends the message and continues processing. The receiver program receives and reads the message at a later time-independent of the operation of the sender program.
For example, in a manufacturing resource planning (MRP) system, it is not necessary for the order entry application to halt processing while it waits for the inventory application to receive the message because the data does not affect its own processing. So, for example, the order fulfillment application can send a message to the inventory system identifying how many items were sold using an asynchronous delivery mode (PDEL_MODE_AK_xxx). The order fulfillment application does not need to halt processing while the inventory application reads the messages and decrease the inventory count.
Using Message Broadcasting
Some applications require simultaneous distribution of information to many recipients at the same time. A stock brokerage program is a good example of this kind of application. As stock prices change, the updated values must be simultaneously displayed on all stock traders' monitors. BEA MessageQ offers a feature called message broadcasting which allows an application to send one message that is simultaneously delivered to all subscribers. This capability is also called publish and subscribe.
Using Message Selection
Applications can receive a variety of message types. For example, an application can receive responses to its requests, notification of successful delivery of asynchronous messages, broadcast messages, timer expiration messages, and so on. The BEA MessageQ API offers a feature called message selection that allows receiver programs to sort out the messages they receive by correlation identifier, sequence number, message source, class, type, priority, or a combination of message attributes. If your application will receive different kinds of messages, you need to include logic for sorting the messages as they are read using the appropriate pams_get_msg function.
Load Balancing with MRQs
Many applications would benefit greatly if multiple servers were allowed to process the data instead of a single server. The efficient and dynamic distribution of processing power is commonly referred to as load balancing. BEA MessageQ offers load balancing through its multireader queues (MRQs).
For example, let's look at an order processing system. Company A's sales people enter customer orders using laptop computers by dialing into a main order entry system. After the order information is entered, the transaction is transmitted as a message to the order processing server program. Normally, there are several server programs running to process customer orders.
Each server reads a message from the MRQ that contains the customer order transaction information, processes the order information, and then reads the next available messages. As the number of messages in the MRQ grows, additional servers can be started to handle the load.
MRQs are generally used for load balancing when each message is a self-contained transaction. If an application requires multiple messages to be read and procesessed sequentially, the application uses a single-reader queue as the target queue to ensure proper processing. Optionally, an MRQ can be used to set up a session with a server application which then uses a single-reader queue for the remainder of the transaction. In this case:
When implementing this approach, it is important to note that the client application is temporarily stalled while waiting to receive the address of the server's single-reader queue.
Choosing Single Reader Queues for Sequential Processing
If sequential information processing is required, the application must send the messages to a target queue that is defined as a single reader queue. Single-reader queues are owned by a single process which reads messages from the queue in FIFO (first-in/first-out) order.
It is important to note that, by default, BEA MessageQ places the highest priority messages at the top of the queue. Priority ranges from 0 (lowest priority) to 99 (highest priority). For example, priority 1 messages are always placed before priority 0 messages. Messages are placed in first-in/first-out order by message priority.
Choosing Permanently Active Queues for Data Persistence
Some applications require information be available for only a short period of time. Or, applications may require that information be available only when a process is attached to a queue and, therefore, actively retrieving information. In the former case, the application developer would attach to a temporary queue. In the latter case, the application developer would send messages to a permanent queue that is configured to be active only when a process is attached.
For example, a client application that takes account inquiries from customers at an ATM machine only requires the use of a queue long enough to provide a particular customer with one time information about their account. The client application would attach to the message queuing bus using a temporary queue, request the account balance from the message server, and wait for the message server to return the account balance. After the balance inquiry is fulfilled, the client application detaches from the temporary queue and waits for the next account inquiry.
However, if an application requires message data to be captured regardless of whether an application is available to process it, the developer must define the queue as permanently active to enable it to store messages when no application is attached, or use a recoverable delivery mode for sending to this queue.
Using BEA MessageQ Naming
Another important aspect of application development is to decide whether applications should be insulated from changes in the underlying BEA MessageQ environment configuration. For very stable environments which infrequently change equipment configuration, this is not a great concern. However, for dynamic, multiplatform environments, it may be very important to ensure that applications continue to run without recoding despite underlying configuration changes. However, there is a performance loss when naming is used for each queue reference.
Application developers can insulate programs from configuration changes using the BEA MessageQ naming feature. To use naming, applications are designed to refer to queues by name and not by using their queue address. Applications use the pams_locate_q function to look up the queue address for a queue name at runtime and pass the value to the pams_put_msg function in order to send the message. Naming enhances the flexibility of applications and frees them from requiring maintenance each time the configuration of the BEA MessageQ environment changes.
In addition, BEA MessageQ offers the ability to assign a service point at runtime using the pams_bind_q function. So, for example, if applications are designed to read a queue called "parts_orders," the location of this queue can be determined at runtime by binding the queue name "parts_orders" to the queue address of the server that will be processing the parts orders at that time. The queue name can be unbound and the pams_bind_q function issued again to change the location from which parts orders will be obtained providing failover capability. Queue names are available on a group-wide and bus-wide basis providing a wide degree of flexibility to change the runtime environment.
Using FML for Self-Describing Messaging
For application environments subject to frequent change or that run on heterogeneous machine environments, FML-style self-describing messaging provides numerous capabilities to enhance the flexibility of applications. For example, using FML, you can add fields to a message that can be read by new applications without disrupting the way existing applications process the message. In addition, you can change the size of data fields in a message as your needs change without recoding applications because the size of the data field is encoded as part of the message itself.
In addition, messages can be planned with future considerations in mind because a single message can be designed for use by a variety of applications that use different data fields within the message and by future applications will use data fields not in use today. Also, FML marshals the data so that programmers need not be concerned with the different data formats from machine to machine.
Designing Message Flow and System Configuration
After you have broken down the application into its component programs, designed the communications model, and determined the BEA MessageQ features required by each component, you need to map out the messaging flow and determine how the component applications will be deployed in the distributed environment by answering the following questions:
A system designer answers these and many other detailed questions about the application in order to map the flow of information between sender and receiver programs in the distributed heterogeneous network.
Though a system manager may perform the configuration tasks, the following BEA MessageQ entities must be set up in accordance with the general system design in order for applications to exchange messages:
The BEA MessageQ environment must be configured before applications are able to exchange information. For example, a system designer may designate queue 40 in group number 1 to receive temperature readings from a semiconductor furnace.
Once the bus, group, and queue address are defined, the sender program knows where to direct messages containing temperature readings. The receiver program also knows which queue to attach to in order to read and respond to temperature changes in the furnace.
Advanced Message Queuing Features
In addition to its ability to send and receive messages between applications in a distributed multivendor environment, BEA MessageQ has advanced features to provide developers with the following powerful capabilities:
Self-describing messaging using Field Manipulation Lauguage (FML) provides a flexible form of BEA MessageQ messaging. With buffer-style messaging, BEA MessageQ applications pass information using a message buffer whose format and structure were agreed upon by the sender and receiver programs. FML provides a mechanism for passing information as an opaque message buffer.
The pams_put_msg function now accepts a pointer to an FML32 buffer as the msg_area parameter. The resulting message contains the tags and values needed by the receiver program to decode the message. FML adds significant flexibility in message exchange because, in many cases, the contents of a message can be changed without requiring all related applications to be changed.
One example of the flexibility inherent in the FML messaging style is illustrated through the handling of a change in a message field size of an existing message. Applications that do not use FML must modify the application header files of each applicable sender and receiver program and then they must be recompiled, relinked and restarted. Using FML, however, the application developer need only change the tag associated with the value to indicate the new field size. When the message is received and decoded by the receiver program, the message contains the information on the new field size, therefore, the receiver program can properly interpret the data.
In addition to changing the size of data fields in a message, developers can add fields to FML messages. The new fields are available to be read by applications that have been programmed to read the additional field, however, all existing applications continue to run without a problem.
Another very powerful feature of FML is its ability to provide data transformation for applications exchanging information in heterogeneous multivendor environments. For a complete description of how to use the BEA MessageQ self-describing messaging feature, refer to the BEA MessageQ Programmer's Guide.
Recoverable Messaging
When an application sends a message, the final receipt of the message can be interrupted by various failure conditions including system, process, and network failures as shown in Figure 3-4.
Figure 3-4 Recoverable Messaging
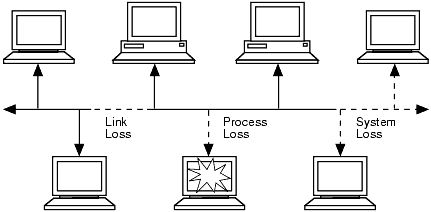
However, BEA MessageQ applications can choose to send a message using recoverable delivery modes to enable BEA MessageQ to store messages in a disk file and deliver them as soon as it is possible. Using recoverable messaging BEA MessageQ applications can recover from message delivery failures caused by any of the following:
When you send a BEA MessageQ message that is designated as recoverable, it is stored in one of two message recovery journals. The message recovery journal on the local system is called the store and forward (SAF) file. The message recovery journal on the remote system is called the destination queue file (DQF).
The selection of the recovery journal is determined by the delivery mode argument specified in the pams_put_msg function. If the delivery of a recoverable message is interrupted by a failure, it is automatically resent from the SAF or the DQF once communication with the target group is restored.
When an application receives and reads a recoverable message from a queue that is configured for explicit confirmation, it must use the pams_confirm_msg function to confirm message delivery. Confirming delivery of the recoverable message removes it from the message recovery journal. If the message is not confirmed, it will remain in the recovery journal and be redelivered if the application detaches and reattaches to the queue.
BEA MessageQ offers two types of message confirmation; implicit and explicit. The type of confirmation is set for each message queue as part of group configuration. Applications that receive recoverable messages in queues configured for implicit confirmation do not need to issue the pams_confirm_msg call. The message queuing system automatically issues the pams_confirm_msg call when the next sequential message is read from the message recovery journal. However, applications receiving recoverable messages in queues configured for explicit confirmation must issue the pams_confirm_msg call to delete the message from the message recovery journal.
Another queue characteristic that can be set during group configuration is the message confirmation order. Recoverable messages can be confirmed in order or out-of-order. The default confirmation order is to confirm messages sequentially as they are delivered from the message recovery journal and received by the target application.
In addition to the message recovery journals, BEA MessageQ offers two auxiliary journals to provide additional message recovery capabilities as follows:
For a complete description of how to use the BEA MessageQ recoverable messaging feature, refer to the BEA MessageQ Programmer's Guide.
Message Selection
When each BEA MessageQ message is sent, the sender program can assign a correlation identifier, message type, message class, and priority to distinguish it from other messages in the target queue. In addition, the message header contains the queue address of the sender program to allow the receiver program to identify the message source.
To selectively read messages, applications use sel_filter argument of the pams_get_msg, pams_get_msgw, or pams_get_msga functions. This argument allows developers to select messages by:
For a complete description of how to use the BEA MessageQ message selection feature, refer to the BEA MessageQ Programmer's Guide.
Broadcasting Messages
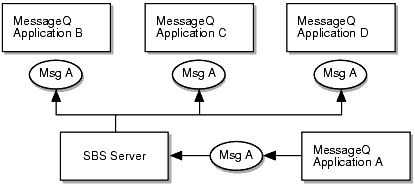
Message broadcasting is a style of messaging that enables one sender program to send a message simultaneously to many receiver programs. BEA MessageQ Selective Broadcast Services (SBS) manage the broadcasting of data between processes and groups of processes as shown in Figure 3-5.
Figure 3-5 Selective Broadcast Services
BEA MessageQ broadcast services provide applications with:
BEA MessageQ message broadcasting is similar to radio broadcasting. A sender program directs a message to a selected broadcast stream to be received by any interested application. Then, the receiver program "tunes in" just as a listener chooses a particular radio station by registering to receive messages sent to that broadcast stream. The sender program does not know which applications are receiving the messages it sends. Receiver programs register and deregister for message receipt from a particular broadcast stream without affecting the sender program.
Message broadcasting simplifies application development because sender programs do not need to be aware of the number, state, and location of the target queues. Message broadcasting increases efficiency by directing messages to many targets with a single call.
To send a message to multiple recipients simultaneously, the sender program uses the pams_put_msg function and specifies a Multipoint Outbound Target (MOT) as the queue address. A broadcast target, numbered between 4000 and 6000, is an identifier for a broadcast stream. A broadcast stream is the set of target queues registered to receive messages directed to a particular broadcast target. The SBS Server in each message queuing group distributes messages to registered receiver programs.
For a complete description of how to use the BEA MessageQ message broadcasting feature, refer to the BEA MessageQ Programmer's Guide.
Naming
Naming is a powerful BEA MessageQ capability that enables applications to refer to queues by name instead of by their queue address. Using naming separates applications from the details of the current BEA MessageQ environment configuration and enables system managers to make configuration changes without requiring developers to change their applications.
For example, an order processing application uses a multireader queue called ORDER_INBOX to store product order messages from client programs. Order fulfillment server programs read messages from ORDER_INBOX to process each order. Initially, ORDER_INBOX might be defined as queue 7 in group 1, an HP-UX system. However, after the company purchases a high performance, Compaq system running Tru64 UNIX, this queue may be redefined as queue 8 on group 2 to provide better performance for the application. In this example, no change is required to either the sender or receiver programs because they refer to the queue by name and not by its queue address.
To obtain the queue address for a queue name at runtime, application developers use the pams_locate_q function. Queue names can be defined in BEA MessageQ to have a local or global scope. A local name can be used as the target queue by applications running in the same message queuing group in which the name was defined. A global name can be used as the target queue by any application on the message queuing bus.
Names can be defined using a static or dynamic approach. The static approach means that the name-to-queue address translation is defined in the Queue Configuration Table (%QCT) or in the Global Name Table (%GNT) of the BEA MessageQ group initialization file. When the group starts up, the name-to-queue address translations are written to the BEA MessageQ name space. To change a name-to-queue address translation, you must stop the message queuing group, change the queue name definition in the group initialization file and restart the group and its applications. When an application performs a pams_locate_q function, it will obtain the new queue address for the queue name.
Dynamic naming means that the name-to-queue address translation is defined at runtime by an application using the pams_bind_q function. When the pams_bind_q function successfully completes, the name-to queue translation is written to the BEA MessageQ name space. To change the name-to-queue translation, the application must unbind the name from the queue address and use the pams_bind_q function to bind a new queue address to the queue name.
The BEA MessageQ process that supports the naming capability is called the Naming Agent. The Naming Agent is responsible for creating entries in the name space and for providing the look up capability for name-to-queue translations at runtime.
To use the BEA MessageQ naming feature, you must configure the message queuing environment as follows:
Refer to the installation and configuration guide for your platform for detailed information on how to configure the BEA MessageQ naming feature. For more detailed information on how to design your application to use naming, refer to the BEA MessageQ Programmer's Guide.
Using Message Based Services
BEA MessageQ applications may wish to perform certain standard tasks such as checking the status of a queue or the status of a cross-group connection before sending a message. To make these tasks easier, BEA MessageQ offers message-based services. These are predefined request, notification, and response messages exchanged between application processes and the BEA MessageQ servers that support each message queuing group.
BEA MessageQ offers message-based services for:
For example, an application may want to check whether a queue is available before it sends a message. BEA MessageQ offers built-in availability checking through its message-based services.
To register for availability notification, the application sends an AVAIL_REG message to the primary queue of the AVAIL Server running in its message queuing group. The AVAIL server responds by sending an AVAIL_REG_REPLY message to the sender program acknowledging that it is registered to receive availability notification.
Thereafter, as queues attach and detach from the message queuing bus, the sender program receives AVAIL and UNAVAIL notification messages identifying which queues have become available and which have become unavailable. When the sender program no longer requires availability notification, it sends a AVAIL_DEREG message to the AVAIL Server and notification is terminated.
For a complete description of how to use the BEA MessageQ message-based services feature, refer to the BEA MessageQ Programmer's Guide.
Exchanging Messages Between BEA MessageQ and BEA TUXEDO V6.4 or BEA M3 V2.1
BEA MessageQ V5.0 include a messaging bridge that allows the exchange of messages between BEA MessageQ V5.0 and BEA TUXEDO V6.4 or BEA M3 V2.1. BEA MessageQ applications can send a message using pams_put_msg that a TUXEDO application can retrieve through a call to tpdequeue. TUXEDO applications can send a message using tpenqueue that a BEA MessageQ application can retrieve through a call to pams_get_msg(w). In addition, a BEA MessageQ application can invoke a TUXEDO service using pams_put_msg. It is also possible for a TUXEDO application to use tpenqueue to put a message on a queue and tpdequeue to retrive a message from a queue.
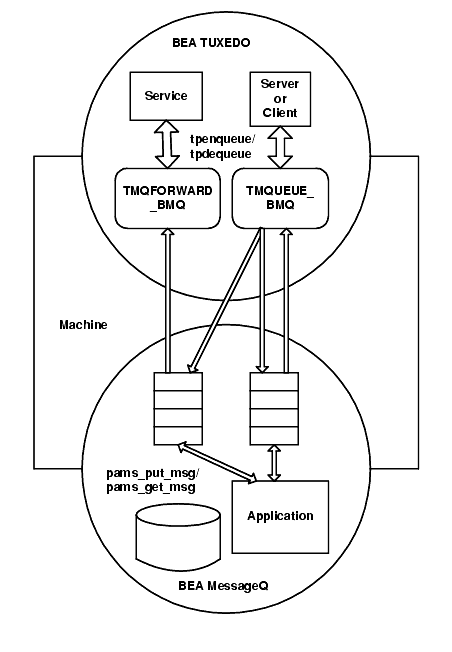
This exchange of messages is made possible by two TUXEDO servers that are included in the BEA MessageQ installation and that run on the same machine as BEA MessageQ: TMQUEUE_BMQ and TMQFORWARD_BMQ.
TMQUEUE_BMQ redirects TUXEDO tpenqueue requests to a BEA MessageQ queue where they can be retrieved with pams_get_msg(w). TMQUEUE_BMQ also redirects pams_put_msg requests to TUXEDO where they can be retrieved with tpdequeue.
TMQFORWARD_BMQ listens on specified BEA MessageQ queues and forwards pams_put_msg or tpenqueue requests to a TUXEDO service. It also puts the reply or failure message on the sender's response queue.
The target queue and service are defined when TMQUEUE_BMQ and TMQFORWARD_BMQ are configured. This ensures that message exchange between BEA MessageQ and TUXEDO is transparent to the application.
Figure 3-6 illustrates message exchange between BEA MessageQ and TUXEDO.
Figure 3-6 Message Exchange Between BEA MessageQ and TUXEDO
The TMQUEUE_BMQ and TMQFORWARD_BMQ servers are part of the BEA MessageQ installation and are installed when BEA MessageQ is installed. During the installation procedure, you are prompted to choose one of the following installation options for BEA MessageQ and TUXEDO integration:
install on top of BEA TUXEDO V6.4
install on top of BEA M3 V2.1
install without BEA TUXEDO
Note that if you are installing BEA MessageQ on OpenVMS, you do not have the option of installing over BEA M3 V2.1. Also, you must install BEA MessageQ for OpenVMS on an OpenVMS AXP 7.1 system to use the messaging bridge.
If you choose to install on top of BEA TUXEDO V6.4 or BEA M3 V2.1, the applicable files for the TMQUEUE_BMQ and TMQFORWARD_BMQ servers are installed on your system. If you install without BEA TUXEDO, the TMQUEUE_BMQ and TMQFORWARD_BMQ servers are not installed on your system. See the installation and configuration documentation for your system for detailed installation and configuration instructions.
Once the TMQUEUE_BMQ and TMQFORWARD_BMQ servers are installed, the system administrator enables message enqueuing and dequeuing for the application by specifying the servers as application servers in the *SERVERS section of the TUXEDO ubbconfig file. See the TMQUEUE_BMQ and TMQFORWARD_BMQ reference pages in the BEA MessageQ Reference Manual for detailed information on the server configuration syntax.
Additional API Functions
In addition to its API functions for sending and receiving messages, BEA MessageQ offers the following additional API functions to facilitate the development of distributed applications:
Defining a Name-to-Queue Translation at Runtime
The pams_bind_q function is designed to dynamically associate a queue name with a queue address at runtime. This function enables a server application to dynamically sign up to service a queue alias at runtime.
For example, an application may have client programs that submit orders for widgets by sending BEA MessageQ messages containing the appropriate information to a queue called "widget_orders." In addition, the application has a server program that processes widget orders. To maximize flexibility, the server program starts up and then binds the address of its primary queue to the queue name "widget_orders" which is defined in the group initialization file. The client programs are designed to perform the name-to-queue address translation at runtime using the pams_locate_q function and orders are sent to the primary queue of the server program.
If the server should fail, or if the server program is moved to a faster system, the pams_bind_q function can be used to unbind the queue name from the primary queue of one server program and bind it to the primary queue of another. The redefinition of the queue address of "widget_orders" is handled by BEA MessageQ and is invisible to the client programs which require no reprogramming to direct messages to a different queue. When the queue address for the name is redefined, the message from the client applications are automatically redirected to the new queue address.
Locating the Queue Address for a Queue
To send a message to a target queue, the application developer must supply a queue address as the target argument to the pams_put_msg function. Depending on the needs of the application, the queue address may be set when the program is compiled or may be supplied when the application is running.
To specify the queue address at compile time, the application developer supplies the queue number and group ID of the target queue to the pams_put_msg function. This information must match the group configuration information for the BEA MessageQ environment. If the group and queue number of the target queue do not exist in the group configuration information, the message cannot be delivered.
BEA MessageQ also allows the queue address of the target queue to be resolved at runtime. Using this approach, the application refers to queues only by name. To obtain their queue addresses, the application invokes the pams_locate_q function to obtain the queue address for a queue name. When the queue address is returned by the pams_locate_q function, the developer uses it to supply the queue address to the pams_put_msg function. Designing applications to refer to queues by name, adds some processing overhead at runtime, however, it increases flexibility over compile time resolution by insulating applications from changes in environment configuration.
Using Timers
BEA MessageQ offers a timer API function that eliminates the need to write application-specific timer code. The PAMS timer function sends a timer expiration message to an application when:
The application sets a timer using the pams_set_timer function by supplying a timer_id, the type of timer and the value to be set. An application can set multiple timers by supplying each with a unique timer_id.
When the specified time has elapsed or the time of day has arrived, BEA MessageQ sends a priority 1 message with a message type of MSG_TYPE_TIMER_EXPIRED to the application's source queue. The data structure of the TIMER_EXPIRED message contains the timer_id to enable the application to discern which timer-related event to trigger.
The application cancels timers using the pams_cancel_timer function by supplying the timer_id of the timer to cancel. All pending timer expiration messages with the timer_id of the timer being canceled are purged from the queue.
Obtaining Detailed Status Information
Application developers can use the pams_status_text function to obtain a descriptive text string and a severity level for each API return value. This API function receives the status value and returns a text description in the following format:
PAMS__SUCCESS, normal successful completion
The text description contains the text name of the return code (as it appears in the documentation and development include files) followed by a comma, a space, and then a status description. If the user buffer is large enough, the string is zero terminated.
In addition to the text description, this function returns a code indicating the severity level for both success and error messages. Severity levels are designed to provide more information about the message being returned.
Obtaining the Number of Pending Messages in a Queue
The putil_show_pending function provides the number of pending messages for a single queue or a list of queues. The value returned by this function contains the total number of messages in each memory queue as well as the number of messages in the local and remote recovery journals targeted for delivery to the selected queue. This function can be used to monitor for bottlenecks in application processing and message flow design.
Testing and Debugging BEA MessageQ Applications
BEA MessageQ provides the following powerful tools that assist application developers testing and debugging distributed applications:
The BEA MessageQ Script facility provides a productivity tool for application developers to use in simulating message exchange between programs. Instead of writing a test program, you create a script file containing instructions for capturing messages sent or received by an application, replay captured messages, or simulate messages sent from an application that is still under development.
Message simulation offers a shortcut for sending messages to an application. Instead of writing a program to send a message, you can use a text editor to create a script file. The script file contains the message information and other instructions such as whether to log the message exchange.
The message information and other instructions are entered to the script file using the BEA MessageQ scripting language. When script processing is enabled, BEA MessageQ processes the contents of the script file and delivers the message to the target queue where it can be read by the receiver program.
Message capture provides a mechanism for viewing the messages sent or received by an application. To capture messages, you use the scripting language to create a script file that identifies the messages to be captured. Captured messages can be displayed on the screen, written to a log file, or both. When script processing is enabled, BEA MessageQ captures the messages and displays or logs them as specified in the script file.
Message replay uses the messages captured in a log file as input to an application in exactly the same way as messages entered to a script file. The script replay feature lets developers capture messages sent or received by an application and supply them as input to another program. By tracking the program's response to the captured messages, the developer can debug message exchange between programs that share information using BEA MessageQ.
Note: The BEA MessageQ script facility is available on UNIX and OpenVMS systems only.
For a complete description of how to use the BEA MessageQ script utility, refer to the BEA MessageQ Programmer's Guide.
BEA MessageQ Test Utility
The BEA MessageQ Test utility is a productivity tool that allows software developers to test message exchange with an existing application. A developer interacts with the graphical user interface or character-cell interface of the Test utility to:
To run the Test utility, the developer must begin by setting environment variables to specify the bus and group in which the test application is running. Then the developers uses the pulldown options to build the attach, send, or receive function entering the same information required as arguments to these API function calls.
The Test utility provides a quick and easy means for application developers to:
To view a sample run of the Test Utility, refer to the installation and configuration guide for your environment.
Message Tracing
The BEA MessageQ message tracing feature logs internal messaging events to a file as they happen. You can use this file to diagnose application failures as you debug your application.
It is important to note that message tracing generates a high volume of output; therefore, you should only enable tracing for diagnostic purposes in the event of a problem. For more information on how to set up message tracing, refer to the BEA MessageQ Programmer's Guide.

|
|
|
Copyright © 2000 BEA Systems, Inc. All rights reserved.
|