

|
|
|
|
|
|
Creating and Managing Content
The Content Manager provides content and document management capabilities for use in personalization services. The Content Manager works with files or with content managed by third-party vendor tools.
This topic includes the following sections:
What Is the Content Manager?
The Content Manager run-time subsystem provides access to content through tags and EJBs. The Content Management tags allow a JSP developer to receive an enumeration of Content objects by querying the content database directly using a search expression syntax. The Content Manager component works alongside the other components to deliver personalized content, but does not have a GUI-based tool for edit-time customization.
Choosing a Content Engine
The content engine behind the ContentManager can be set up to be the reference implementation that BEA provides out-of-the-box, or a third-party content engine.
For sites with limited content personalization needs and existing metatagged HTML, WebLogic Personalization Server includes a command-line utility called the BulkLoader. The BulkLoader can parse a directory of HTML files and store their URL address and metadata attributes in a JDBC store. The BulkLoader automatically creates the schema for these attributes.
For customers who have larger amounts of content and want more control over the publishing and tagging of content, BEA partners with third-party vendors to add flexibility to the WebLogic Personalization Server. Third-party content engines provide robust, content-creation management solutions while the Content Manager personalizes and serves the content to the end user.
Running Queries Against the Content Repository
The Content Management component supports querying that returns content from a content repository using several methods:
Note: All other attribute names in queries are considered implicit metadata properties.
Note: See Querying the Content for more information about queries.
Methods for Retrieving and Displaying Documents
WebLogic Personalization Server provides several methods for retrieving documents from a content management system and displaying them on your Web site.
A document is a graphic, a segment of HTML or plain text, or a file that must be viewed with a plug-in. We recommend that you store most of your web site's dynamic documents in a content management system because it offers an effective way to store and manage information.
Note: Campaigns cannot be used with anonymous users. Campaigns require a user ID that has two characteristics: the ID must be associated with a user profile, and that user profile must be saved (persisted). However, the anoymous profile for a user who is not logged in is a runtime profile (not saved), and not associated with a user ID.
Personalization features such as <pz:div> and <pz:contentSelector> JSP tags do work for anonymous users. This is because these features can use a runtime profile without a user ID,
Table 9-16 compares the methods of content retrieval that WebLogic Personalization Server provides.
Differences Between Content Management and Document Management
Content objects include metadata about the content. Metadata provides a means to query and match content with users by allowing the system to retrieve content based on the metadata that describes the content. In general, some kind of content management system provides services such as retrieval of content and content authoring services including creation, editing, versioning, and workflow.
Documents are a specialized type of Content that provide two methods for retrieval: a metadata-searching mechanism and retrieval of the pure bytes of the document's file. Documents should include additional explicit metadata properties related to the file and its versioning, including its size, name, path, author, and version. A document management system usually provides document-based services for documents that reside in the system's repository.
WebLogic Personalization Server provides the entire Content object model; however, it only provides the Document object as a concrete implementation (subclass) of the Content class.
Querying the Content
There are several way to query the document management system. To query the system, you construct a query expression, then pass the expression to any one of these:
For more information, see the Javadoc API documentation
Structuring a Query
WebLogic Personalization Server queries use a syntax similar to the SQL string syntax that supports basic Boolean-type comparison expressions, including nested parenthetical queries. In general, the template for use includes a metadata property name, a comparison operator, and a literal value. The basic query uses the following template:
attribute_name comparison_operator literal_value
Note: For more information about the query syntax, see the Javadoc API documentation
for com.bea.p13n.content.expression.ExpressionHelper.Several constraints apply to queries constructed using this syntax:
Note: The reference document management system ignores property scopes.
Note: The query syntax can only contain ASCII and extended ASCII characters (0-255).
Note: Use ExpressionHelper.toStringLiteral to convert an arbitrary string to a fully quoted and escaped string literal which can be put in a query.
The following examples illustrate full expressions:
Example 1:
((color=`red' && size <=1024) || (keywords contains `red' && creationDate < now))
Example 2:
creationDate > toDate (`MM/dd/yyyy HH:mm:ss', `2/22/2000 14:51:00') && expireDate <= now && mimetype like `text/*'
Using Comparison Operators to Construct Queries
To support advanced searching, the system allows construction of nested Boolean queries incorporating comparison operators. Table 9-17 summarizes the comparison operators available for each metadata type. (For more information about the native types supported in WebLogic Personalization Server, see Support for Native Types.)
Note: The search parameters and expression objects support negation of expressions via a bit flag (!).
Note: The reference document management system has only single-value Text and Number properties. All implicit properties are single-value Text.
Constructing Queries Using Java
To construct queries using Java syntax instead of using the query language supplied with the Content Management component, see the Javadoc API documentation
for com.bea.p13n.content.expression.ExpressionHelper.The ContentManager session bean is the primary interface to the functionality of the Content Management component. Using a ContentManager instance, content is returned based on a com.bea.p13n.content.expression.Search object with an embedded com.bea.p13n.expression.Expression, which represents the expression tree.
In the expression tree, the following caveats apply for it to be valid for the ContentManager:
com.bea.p13n.expression.operator.logical.LogicalAnd, com.bea.p13n.expression.operator.logical.LogicalOr, com.bea.p13n.expression.operator.logical.LogicalMulitAnd, or com.bea.p13n.expression.operator.logical.LogicalMultiOr.
Any other branch node type is invalid.
com.bea.p13n.expression.operator.comparative.Equals, com.bea.p13n.expression.operator.comparative.GreaterOrEquals, com.bea.p13n.expression.operator.comparative.GreaterThan, com.bea.p13n.expression.operator.comparative.LessOrEquals, com.bea.p13n.expression.operator.comparative.LessThan, com.bea.p13n.expression.operator.comparative.NotEquals, com.bea.p13n.expression.operator.string.StringLike, com.bea.p13n.expression.operator.collection.CollectionContains, or com.bea.p13n.expression.operator.collection.CollectionsContainsAll
Any other branch node type is invalid.
JSP Tags
The Content Management component includes the following four JSP tags. These tags allow a JSP developer to include non-personalized content in a HTML-based page. Note that none of the tags support or use a body.
See Personalization Server JSP Tag Library Reference, for more information on any of these tags.
Using the Document Servlet
The Content Management component includes a servlet capable of outputting the contents of a Document object. This servlet is useful when streaming the contents of an image that resides in a content management system or to stream a document's contents that are stored in a content management system when an HTML link is selected. The servlet supports the following Request/URL parameters:
The servlet only supports Documents, not other subclasses of Content. It sets the Content-Type to the Document's mimeType and, the Content-Length to the Document's size, and correctly sets the Content-Disposition, which should present the correct filename when the file is saved from a browser.
Example 1: Usage in a JSP
This example searches for news items that are to be shown in the evening, and displays them in a bulleted list.
<cm:select sortBy="creationDate ASC, title ASC"
query=" type = `News' && timeOfDay = `Evening' && mimeType like `text/*' "id="newsList"/>
<ul>
<es:forEachInArray array="<%=newsList%>" id="newsItem" type="com.bea.p13n.content.Content">
<li><a href="ShowDoc/<cm:printProperty id="newsItem"
name="identifier" encode="url"/>"><cm:printProperty
id="newsItem" name="title" encode="html"/></a>
</es:forEachInArray>
</ul>
Example 2: Usage in a JSP
This example searches for image files that match keywords that contain bird and displays the image in a bulleted list.
<cm:select max="5" sortBy="name" id="list"
query=" KeyWords like `*birds*' && mimeType like `image/*' "
contentHome="java:comp/env/ejb/MyDocumentManager"/>
<ul>
<es:forEachInArray array="<%=list%>" id="img" type="com.bea.p13n.content.Content">
<li><img src="/ShowDoc/<cm:printProperty id="img"
name="identifier"
encode="url"/>?contentHome=<es:convertSpecialChars
string="java:comp/env/ejb/MyDocumentManager"/>">
<es:forEachInArray>
</ul>
Configuring the Content Manager
The DocumentManager EJB deployment descriptor handles the EJB portion of the Content Management component configuration. The DocumentManager also needs to be integrated into the PropertySetManager EJB deployment descriptor so that content property sets are exposed to the system. The DocumentManager EJB accesses a document connection pool, which is defined in an application's META-INF/application-config.xml file. Optionally, the DocumentManager EJB can access a document connection pool configured via the WLS console.
For Web Applications to correctly access the Content Management Component, some additional configuration is required in the Web Application deployment descriptor.
For more information, see the Deployment Guide.
Configuring the DocumentManager EJB Deployment Descriptor
The DocumentManager EJB understands the following environment settings in its deployment descriptor:
If jdbc/docPool is specified in the deployment descriptor, then:
Use lower or upper depending upon the document connection pool implementation being used. For the document reference implemenation, do not specify the PropertyCase.
Configuring the PropertySetManager EJB Deployment Descriptor for Content Management
In the PropertySetManager EJB deployment descriptor, add the following environment settings:
To integrate a ContentManager or DocumentManager with the PropertySetManager, add an EJB reference here. For example, ejb/ContentManagers/Document is mapped to the standard DocumentManager.
Alternatively, you can set the JNDIName attribute the DocumentManager MBean to the JNDI Home name of the DocumentManager (see page22 for a definition of this attribute). The ${APPNAME} construct can be used in the value; it will be replaced by the current J2EE application name. The com.bea.p13n.content.PropertySetRepositoryImpl will automatically pick up those DocumentManagers and the J2EE EJB reference is not required.
Configuring DocumentManager MBeans
The DocumentManager implementation uses DocumentManager MBeans to maintain the configuration for the DocumentManager. A deployed DocumentManager finds which DocumentManager MBean to use from the DocumentManagerMBeanName EJB deployment descriptor setting. That value must correspond to the Name attribute of a DocumentManager MBean in the application.
To configure a DocumentManager MBean, you can modify the application's META-INF/application-config.xml file to add or change the following XML:
<DocumentManager
Name="default"
DocumentConnectionPoolName="default"
PropertyCase="none"
MetadataCaching="true"
MetadataCacheName="documentMetadataCache"
UserIdInCacheKey="false"
ContentCaching="true"
ContentCacheName="documentContentCache"
MaxCachedContentSize="32768"
>
</DocumentManager>
Attributes of the DocumentManager MBean
The attributes are as follows:
Use lower or upper depending upon the document connection pool implementation being used. For the document reference implementation, do not specify the PropertyCase.
Editing the DocumentManager MBean in the WebLogic Console
Once a DocumentManager MBean has been initially configured in the application-config.xml file, it can be edited via the WebLogic Server Administration Console, as show in Figure 9-1 below.
Figure 9-1 Using the WLS Console to Edit the Document Manager MBean
Setting Up Document Connection Pools The DocumentManager implementation uses connection pools to a specialized JDBC driver to handle searches. A deployed DocumentManager finds the document connection pool to use via either the DocumentConnectionPoolName attribute of its DocumentManager MBean or the DocumentConnectionPoolName EJB deployment descriptor setting. That value must correspond to a DocumentConnectionPool MBean. To configure a DocumentConnectionPool MBean, modify the application's META-INF/application-config.xml file to add or change the following XML: Attributes for the DocumentConnectionPool MBean The attributes are as follows: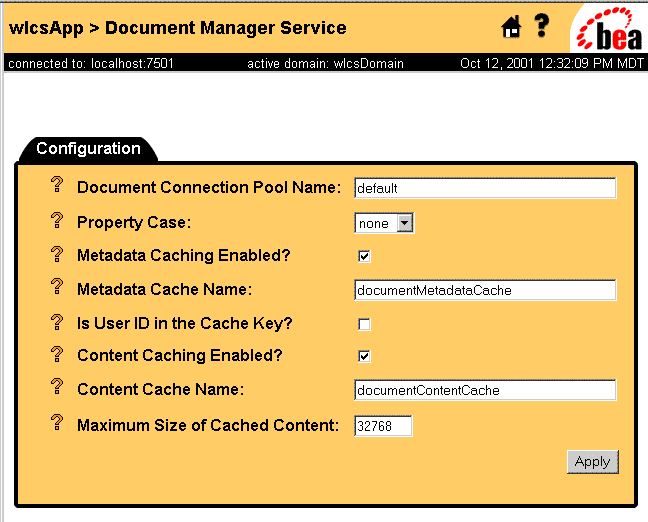
<DocumentConnectionPoolName="default"
DriverName="com.bea.p13n.content.document.jdbc.Driver"
URL="jdbc:beasys:docmgmt:com.bea.p13n.content.document.ref.
RefDocumentProvider"
Properties="jdbc.dataSource=weblogic.jdbc.pool.commercePool;
schemaXML=D:/bea/wlportal4.0/dmsBase/doc-schemas;
docBase=D:/bea/wlportal4.0/dmsBase"
InitialCapacity="20"
MaxCapacity="20"
CapacityIncrement="0"
/>
Properties
The WebLogic Personalization Server reference implementation DocumentProvider understands the following Properties:
READ_COMMITTED,
READ_UNCOMMITTED,
SERIALIZABLE,
REPEATABLE_READ, or
NONE.
If not specified, it defaults to SERIALIZABLE.
For further details, see the Javadoc API documentation for java.sql.Connection.
Editing a DocumentConnectionPool MBean in the WebLogic Console
Once a DocumentConnectionPool MBean has been initially configured in the application-config.xml, it can be edited via the WebLogic Server Administration Console, as shown in Figure 9-2.
Figure 9-2 Using the WLS Console to Edit a DocumentConnectionPool MBean
Setting up WebLogic Connection Pools If you map jdbc/docPool in your DocumentManager EJB deployment descriptor, you will need to configure the WebLogic JDBC connection pool and data source. Figure 9-3 shows how you can create a JDBC connection pool and configure the connection settings through the WebLogic Server Administration Console. The URL field is the same as the URL field in the DocumentConnectionPool MBean above. The Driver Classname is the same as the Driver field above. The Properties field is the same as the Properties field above. Figure 9-3 Creating and Configuring a JDBC Connection Pool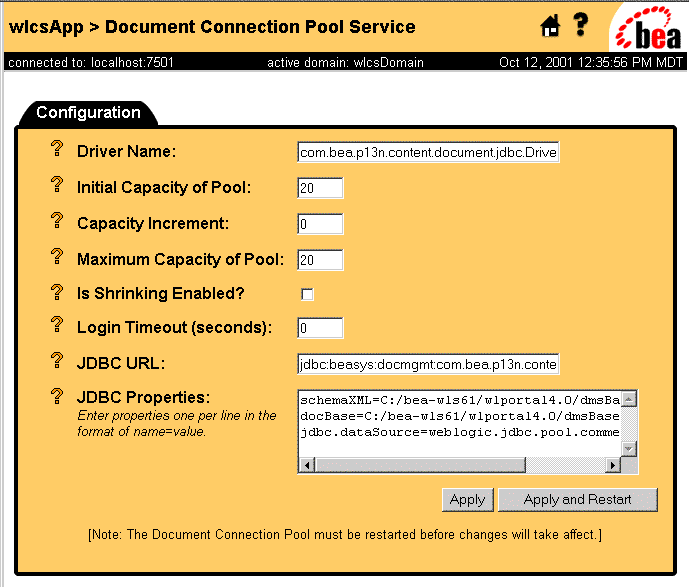
Then, you can configure the data source connected to the connection pool, as show in Figure 9-4. Figure 9-4 Configuring the Data Source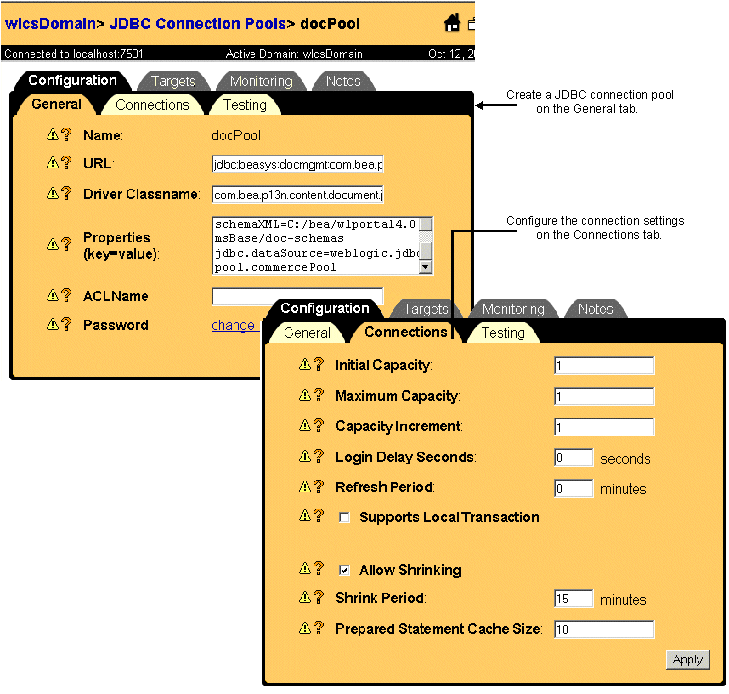
The JNDI name selected here will be used in the jdbc/docPool resource reference in the DocumentManager EJB deployment descriptor. For more information about using the WebLogic Server Administration Console for configuring and managing JDBC connection pools, see the topic "JDBC Connection Pool" in the WebLogic Server documentation. You do not need to do this if you configure the DocumentConnectionPool MBean. If you choose to use a WLS connection pool, you will need be certain that your DocumentProvider implementation and all classes that it references are available in the system CLASSPATH of your server. Otherwise, you will most likely receive errors on startup. For more information about the CLASSPATH environment variable, see "Setting Environment Variables" under "Starting and Shutting Down the Server" in the Deployment Guide. Web Application Configuration To correctly access the various pieces of the Content Management component, you will need to configure EJB references to ejb/ContentManager and ejb/DocumentManager. Additionally, you need to have the com.bea.p13n.content.servlets.ShowDocServlet mapped into your Web Application. It is suggested to map it to the /ShowDoc/* URL in your Web Application. In your Web Application's WEB-INF/web.xml, you can add: This will allow the ShowDoc/ URI under your Web Application's context root (for example, /wlcs/ShowDoc) to be sent to the ShowDocServlet. The contentHome <init-param> will cause that ShowDocServlet to always use the ejb/DocumentManager EJB reference; you can take this out to allow ShowDocServlet to obey any contentHome request parameters. To access the Content Management tag libraries, you will need to: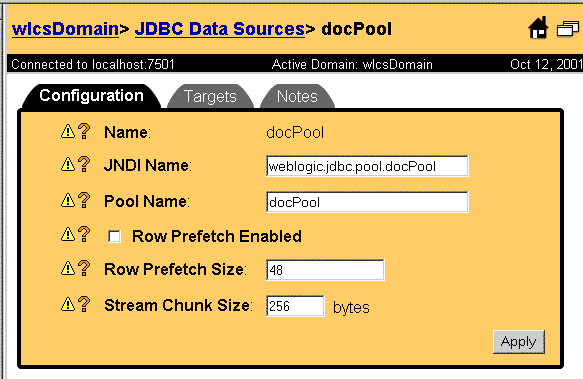
<servlet>
<servlet-name>ShowDocServlet</servlet-name>
<servlet-class> com.bea.p13n.content.servlets.ShowDocServlet
</servlet-class> <!-- Make showdoc always use the local ejb-ref DocumentMnager -->
<init-param>
<param-name>contentHome</param-name>
<param-value>java:comp/env/ejb/DocumentManager</param-value>
</init-param></servlet>
...
<servlet-mapping>
<servlet-name>ShowDocServlet</servlet-name>
<url-pattern>/ShowDoc/*</url-pattern>
</servlet-mapping>
For more information, see the Deployment Guide
and the web.xml and weblogic.xml files in WL_PORTAL_HOME/applications.
Using the BulkLoader to Load File-based Content
WebLogic Personalization Server provides no run-time tools to load metadata information from a content database. However, the server provides a command-line utility, the BulkLoader, that descends a directory hierarchy, parses the HTML-style <meta> tags, reverses the metadata content contained within the <meta> tags into schema information, and loads the resulting documents into the reference implementation database.
The BulkLoader is a command-line application that is capable of loading document metadata into the reference implementation database from a directory and file structure. The BulkLoader parses the document base and loads all the document metadata so that the Content Management component can search for documents. The BulkLoader supports all document types, not just HTML documents.
Command-Line Usage
The BulkLoader class allows a number of command-line switches:
java com.bea.p13n.content.document.ref.loader.BulkLoader
[-/+verbose] [-/+recurse] [-/+delete] [-/+metaparse] [-/+cleanup]
[-/+hidden] [-/+inheritProps] [-/+truncate] [-/+ignoreErrors]
[-schemaName <name>] [-encoding <encoding>] [-commitAfter <num docs>]
[-properties <name>] -conPool <name> [-schema <name>] [+schema]
[-match <pattern>] [-ignore <pattern>] [-htmlPat <pattern>]
[-d <dir>] [-mdext <ext>] [--]
[files... directories...] [-filter <filter class>] [+filters]
[-columnMap <file.properties>]
[-column <columnName>=<propName,...>][+columns]
How the BulkLoader Finds Files
The following sequence describes how the BulkLoader locates files:
Note: If the file or directory is not an absolute path, then it is assumed to be relative to the docBase specified by the -d option.
Note: If it is a hidden file (or directory) and the +hidden option was not specified, then the file or directory is ignored.
Note: The -match and -ignore options only apply to files and directories not listed on the command line; in other words, they apply only to those found by recursing into a directory. The patterns specified with the -match and -ignore options (and the -htmlPat options, for that matter) should be DOS-style patterns: '*' matches any set of characters, '?' matches any one character. Sets of characters (for example, [aceg]) are not supported.
Note: Files with an extension matching the extension specified by -mdext (.md.properties by default) are always ignored.
How the BulkLoader Finds Metadata Properties
As the BulkLoader is finding files and directories, it will also attempt to load metadata property files. Whenever the BulkLoader encounters a directory that it will process, it looks for a file called dir.<mdext> where <mdext> is the extension specified by the -mdext option. Therefore, the default filename it looks for is dir.md.properties. If this file exists and is readable by the user, the BulkLoader loads it as a Java-style properties file of name=value properties. If the directory is actually a subdirectory entered because +recurse was not specified and the +inheritProps option is not specified, then the properties from dir.md.properties will be added to the properties from the parent directories. All files in the directory gain these metadata properties.
When the BulkLoader finds a file which is to be included and loaded, it looks for a file whose name is the original filename appended with the -mdext extension. So, by default, if the file is called image.gif, the BulkLoader looks for a file called image.gif.md.properties. If that file exists and is readable, the BulkLoader loads those properties into the directory's properties (and possibly the parent directories' as well).
Next, if the file is an HTML file and the +metaparse option was not specified, then the BulkLoader will parse the HTML, looking for <meta> tags and <title> tags. The BulkLoader determines if a file is an HTML file by using the filename patterns specified by the -htmlPat options. If no -htmlPat patterns are specified, then *.htm and *.html are used. The BulkLoader will load into the file's properties any <meta> tags that contain name and content values found anywhere in the file (not just in the HTML head section). Additionally, it will pull the title from the <title></title> and set it as "title".
Finally, the BulkLoader will pass the file to the loadProperties method of each registered LoaderFilter (the -filter option). The LoaderFilter may assign additional metadata to the file. When the BulkLoader starts up, it looks for a com/bea/p13n/content/document/ref/loader/loader.properties file in the classpath. From that, it looks for a loader.defFilters property. This is the colon-separated list of LoaderFilter class names the BulkLoader should always load. Unless that file is modified, the BulkLoader will load an ImageLoaderFilter, which will pull the width and height from *.gif, *.jpg, *.png, and *.xbm image files.
In summary, the BulkLoader gathers metadata for a document from the following sources (in this order):
From there, the ID of the document in the database will be the file path, relative to the docBase specified by the -d option. If the file path is not relative to the docBase, then it will be relative to the path from the command line. The file size will be retrieved from the file. The mimeType will be determined by the file's extension. The modifiedDate in the database will become the current time (since that is when the document is being modified in the database).
Cleaning Up the Database
If the -cleanup option is specified, the BulkLoader will not actually load any documents. Instead, it will attempt to clean up and update the database tables. It will first query the database, looking for any metadata entries that do not have corresponding document entries. For each of those, it will create a document entry. It will then go over each document entry and update the size, modified date, and possibly the MIME type (if the MIME type is not in the database) based upon the files in the docBase specified with the -d option.
Loading Internationalized Documents
The BulkLoader accepts a -encoding <enc> option. When this is specified, the BulkLoader will use that encoding to open all HTML files to find <meta> tags.
For example, if the files under the Unicode files directory were saved in the Unicode encoding, you could do:
java com.bea.p13n.content.document.ref.loader.BulkLoader -verbose -properties loaddocs.properties -conPool commercePool -schema dmsBase\schemas\unicode-files.xml -d dmsBase unicode-files -encoding Unicode. When -encoding is specified, the generated schema XML file will be in the UTF-8 encoding (since some metadata property names might not be ASCII), which the run-time engine can read in. (Note: UTF-8 is a superset of ASCII and can be mostly read by common text editors.)
When -encoding is specified, all HTML files the BulkLoader encounters will be opened with the specified encoding. Therefore, either the encoding must be a superset of all the files' encodings (for example, ISO8859_1 is a superset of ASCII, where as Unicode is not) or the BulkLoader might not be able to correctly pull out the <meta> tag information. It is recommended to either save all documents in a single encoding or to run the BulkLoader against only certain directories at a time (for example, put all the Big5 files in one directory).
The list of available encoding names is contained in the documentation for your JDK, or the documentation for the tool which created the file. If you are not creating files containing non-ASCII characters, this should not affect you. If you want to check if the BulkLoader is correctly parsing your HTML file, you can use the com.bea.p13n.content.document.ref.loader.MetaParser class.
For example:
java com.bea.p13n.content.document.ref.loader.MetaParser unicode.htm unicode would print out the <meta> tags found in the unicode.htm file, assumed to be Unicode encoded. Of course, any non-ASCII character probably will not print correctly to your console window, but you can tell what it thinks it found.
Generating Schema Files
Additionally, the BulkLoader supports a -schemaName <name> argument which controls the name of the schema in the generated XML file; this in turn affects the name of the Content Property Sets which appear in the rules editor. If not specified, it defaults to "LoadedData."
After loading all the documents on the list, if the +schema option is not specified, the BulkLoader will output a XML file containing the schema information and following the doc-schemas DTD. The BulkLoader will output a single schema which contains entries for all the metadata attributes it finds over the entire load.
If +schema is specified, then no schema file will be created.

|

|

|
|
|
|
Copyright © 2001 BEA Systems, Inc. All rights reserved.
|