11g リリース1(11.1)
E05777-03
 目次 |
 索引 |
| Oracle Database 2日でデータ・レプリケーションおよび統合ガイド 11g リリース1(11.1) E05777-03 |
|


この章では、Oracle Streamsレプリケーションに関する概念を示し、データベース間のデータの連続的なレプリケート方法を説明します。
この章は次の項で構成されています。
参照:
レプリケーションは、複数のデータベースでデータベース・オブジェクトとデータを共有するプロセスです。データベース・オブジェクトとデータを複数のデータベースでメンテナンスするために、あるデータベースでのこれらのデータベース・オブジェクトの1つに対する変更が他のデータベースと共有されます。このようにして、レプリケーション環境内のすべてのデータベースでデータベース・オブジェクトとデータの同期が維持されます。
一部のレプリケーション環境は、共有データベース・オブジェクトに対して行われた変更を絶えずレプリケートする必要があります。Oracle Streamsは、連続レプリケーションのためのOracle Database機能です。通常、このような環境では、共有データベース・オブジェクトを含むデータベースがほぼ常にネットワークに接続され、これらのネットワーク接続上でデータベース変更を絶えずプッシュします。
1つの共有データベース・オブジェクトに対して変更が行われると、Oracle Streamsは次のアクションを実行して、同じ変更が他の各データベースの対応する共有データベース・オブジェクトに対して行われるようにします。
図4-1に、Oracle Streams情報フローを示します。
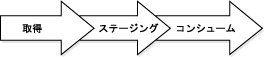
Oracle Streamsレプリケーションを使用して、複数のデータベースでデータを共有し、これらのデータベースでデータを効率よく最新に保つことができます。たとえば、全世界にいくつかのコール・センターを持つ会社は、顧客情報を各コール・センターのローカル・データベースに格納できます。このような環境では、Oracle Streamsでの連続レプリケーションにより、ある場所の顧客データに対して行った変更が、できるだけ早く他のすべての場所にプッシュされるようにすることができます。
Oracle Streamsを使用してデータベース・オブジェクトに対する変更を取得する場合、変更は論理変更レコード(LCR)に書式設定されます。LCRは、データベース変更を説明する特定の形式のメッセージです。変更がデータ操作言語(DML)操作だった場合は、行LCRにより、DML操作の結果として発生した行変更がそれぞれカプセル化されます。1つのDML操作によって複数の行変更が発生する場合があるため、1つのDML操作によって複数の行LCRが発生することがあります。変更がデータ定義言語(DDL)操作だった場合、1つのDDL LCRがDDL変更をカプセル化します。
次の各項で、Oracle Streamsレプリケーションを詳細に説明します。
Oracle Streamsは、データベース変更を自動的に取得する2つの方法を提供します。
単一の取得プロセスまたは単一の同期取得は、1つのデータベースのみに対して行われた変更を取得できます。変更が発生したデータベースは、変更のソース・データベースと呼ばれます。
取得プロセスは、REDOログに記録された変更を非同期に取得するOracle Databaseのオプションのバックグラウンド処理です。取得プロセスは、データベース変更を取得すると、それを論理変更レコード(LCR)に変換し、LCRをエンキューします。
取得プロセスは、単一のキューに常に関連付けられ、LCRをこのキューにのみエンキューします。パフォーマンスを向上させるために、取得されたLCRは常にバッファ・キューに格納されます。バッファ・キューは、キューに関連付けられているシステム・グローバル領域(SGA)メモリーです。
図4-2では、取得プロセスがどのように動作するかを示します。

取得プロセスは、ソース・データベースまたはリモート・データベース上で実行できます。ソース・データベース上で実行する場合、取得プロセスはローカル取得プロセスと呼ばれます。リモート・データベース上で実行する場合、取得プロセスはダウンストリーム取得プロセスと呼ばれます。
ダウンストリーム取得では、REDO転送サービスは、ソース・データベースのログ・ライター・プロセス(LGWR)を使用して、ダウンストリーム取得を実行するデータベースにREDOデータを送信します。異なるデータベースが変更を取得するため、ダウンストリーム取得プロセスではソース・データベースのリソースが少なくてすみます。一方、ローカル取得プロセスは、ダウンストリーム取得よりも構成と管理が簡単です。ローカル取得プロセスによって、プラットフォームまたはOracle Databaseのバージョンが異なるレプリケーション環境にも柔軟性が提供されます。
|
参照:
|
REDOログの非同期マイニングのかわりに、同期取得は内部メカニズムを使用して、データ操作言語(DML)の変更が表に対して行われたときにその変更を取得します。単一のDML変更によって、表の1つ以上の行が変更されることがあります。同期取得はそれぞれの行変更を取得し、それを行の論理変更レコード(LCR)に変換してエンキューします。
同期取得は常に単一のキューに関連付けられ、行LCRをこのキューにのみエンキューします。同期取得は常に行LCRを永続キューにエンキューします。永続キューは、メモリーではなくハード・ディスク上のキュー表にメッセージを格納するキューの部分です。
通常、同期取得は、比較的少数の表に対する変更を取得するレプリケーション環境で使用するのが最適です。多くの表、スキーマ全体またはデータベース全体に対する変更を取得する必要がある場合は、同期取得のかわりに取得プロセスを使用する必要があります。
図4-3では、同期取得がどのように動作するかを示します。

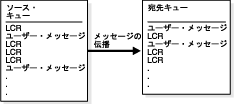
伝播は1つのキューから他のキューにメッセージを送信します。Oracle Streamsを使用して、同じデータベース内、または異なるデータベース内の2つのキュー間のメッセージ伝播を構成できます。Oracle Streamsは、データベース・リンクとOracle Schedulerジョブを使用してメッセージを送信します。伝播は常に「ソース・キュー」と「宛先キュー」の間で行われます。Oracle Streamsレプリケーション環境では、伝播は通常、ローカル・データベース内のソース・キューからリモート・データベース内の宛先キューにデータベース変更を記述するメッセージを(LCRの形式で)送信します。
図4-4では、伝播を示します。
|
参照:
|
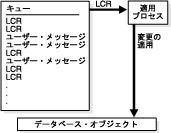
データベース変更が取得されて伝播された後、これらの変更はキューに存在し、レプリケーション・プロセスを完了するために適用する準備ができます。適用プロセスは、論理変更レコード(LCR)およびその他のタイプのメッセージを特定のキューからデキューするオプションのOracle Databaseバックグラウンド・プロセスです。単純なOracle Streamsレプリケーション環境では、通常、適用プロセスはデキューするLCR内の変更をローカル・データベースのデータベース・オブジェクトに直接適用します。
適用プロセスは、常に単一のキューに関連付けられ、このキューからのみメッセージをデキューします。単一の適用プロセスは、バッファ・キューまたは永続キューからメッセージをデキューできますが、両方からデキューすることはできません。したがって、適用プロセスが、取得プロセスによって取得された変更を適用する場合は、バッファ・キューからLCRをデキューするように適用プロセスを構成する必要があります。一方、適用プロセスが、同期取得によって取得された変更を適用する場合は、永続キューからLCRをデキューするように適用プロセスを構成する必要があります。
図4-5では、適用プロセスがどのように動作するかを示します。
適用プロセスは、LCRを正常に適用できない場合に、LCR、およびトランザクション内の他のすべてのLCRをエラー・キューという特別なキューに移動します。エラー・キューには、データベースの現在の適用エラーがすべて含まれます。データベースに複数の適用プロセスがある場合、エラー・キューには各適用プロセスの適用エラーが含まれます。エラーの原因となった条件を修正してから、エラー・キュー内の対応するトランザクションを再実行して変更を適用します。たとえば、表の行を変更してトランザクション・エラーの原因となった条件を修正し、トランザクションを再実行できます。
適用プロセスが変更をデータベース・オブジェクトに適用するためには、インスタンス化システム変更番号(SCN)をデータベース・オブジェクトに対して設定する必要があります。インスタンス化SCNは、ソース・データベースのSCNの後にコミットされた変更のみが適用プロセスによって適用されることを指定するデータベース・オブジェクトのSCNです。表のインスタンス化SCNでは、ソース・データベースと宛先データベースで指定されたSCNに一貫性があることを前提としています。通常、インスタンス化SCNは、Oracle Streamsレプリケーション環境を構成するときに自動的に設定されます。
Oracle Streamsレプリケーション構成では、レプリケート対象を指定する必要があります。取得プロセス、同期取得、伝播および適用プロセスは、Oracle Streamsクライアントと呼ばれます。Oracle Streamsクライアントがレプリケートする対象は、ルールによって決まります。ルールはOracle Streamsクライアントごとに個別に設定でき、異なるOracle Streamsクライアント間でルールが一致している必要はありません。
ルールはルール・セットに編成でき、各Oracle Streamsクライアントの動作は、Oracle Streamsクライアントに関連付けられているルール・セット内のルールによって決まります。ポジティブ・ルール・セットとネガティブ・ルール・セットを取得プロセス、伝播および適用プロセスに関連付けることができますが、同期取得に関連付けることができるのはポジティブ・ルール・セットのみです。
レプリケーション環境では、データベース変更がルール・セットを満たす場合にOracle Streamsクライアントがそのタスクを実行します。一般に、変更がOracle Streamsクライアントのルール・セットを満たすのは、変更についてネガティブ・ルール・セットのどのルールもTRUEと評価されず、ポジティブ・ルール・セットの1つ以上のルールが変更についてTRUEと評価される場合です。ネガティブ・ルール・セットが常に最初に評価されます。
Oracle Streamsレプリケーション環境でルール・セットを使用すると、具体的には次のことができます。
ルールベース変換は、複数のデータベースでデータベース・オブジェクトが同一でない場合に柔軟性を提供する追加の構成オプションです。ルールベース変換では、各データベースで正常に適用できるように、データベース・オブジェクトに対する変更を修正できます。ルールベース変換は、ポジティブ・ルール・セット内のルールがTRUEと評価された場合のメッセージに対する修正を示します。
たとえば、変更が発生したデータベースで表に5つの列があり、別のデータベースの共有表には5つの列のうちの4つしかないとします。データ操作言語(DML)操作がソース・データベースの表に対して実行されると、行変更が取得され、行LCRとして書式設定されます。ルールベース変換は、他のデータベースに正常に適用できるようにこれらの行LCR内の余分な列を削除できます。行LCRが変換されない場合、行LCRには余分な列があるため他のデータベースでの適用プロセスでエラーが発生します。
ルールベース変換には、宣言とカスタムの2種類があります。宣言ルールベース変換には、DML変更(行LCR)の結果として発生した行変更の一般的な変換シナリオのセットが含まれます。カスタム・ルールベース変換には、変換を実行するためのユーザー定義PL/SQLファンクションが必要です。このマニュアルでは、宣言ルールベース変換についてのみ説明します。
次の宣言ルールベース変換を使用できます。
これらの宣言ルールベース変換の1つを追加するときに、変換に関連付けるルールを指定します。指定したルールが行LCRについてTRUEと評価される場合、Oracle Streamsは行 LCRで宣言変換を内部的に実行します。通常、ルールとルール・セットはOracle Streamsレプリケーション環境を構成するときに自動的に作成されます。
1つのルールに対して複数の宣言ルールベース変換を構成できますが、カスタム・ルールベース変換は、1つのルールに対して1つのみ構成できます。また、1つのルールに対して宣言ルールベース変換とカスタム・ルールベース変換の両方を構成することもできます。
変換は、Oracle Streams情報フローの任意のステージ(取得中、伝播中または適用中)で発生します。変換がいつ発生するかは、変換が関連付けられているルールによって決まります。たとえば、伝播中に変換を実行するには、変換を伝播のポジティブ・ルール・セットのルールに関連付けます。
サプリメンタル・ロギングは、操作(行の更新など)が実行されるたびにREDOログに配置される追加の列データのプロセスです。取得プロセスは、この追加情報を取得し、論理変更レコード(LCR)に配置します。これらのLCRを適用する適用プロセスは、データベース変更を正しく適用するためにこの追加情報を必要とします。
競合は、表のデータを共有している2つの異なるデータベースが表の同じ行をほぼ同時に変更した場合に発生します。これらの変更がこれらのデータベースの一方で取得され、もう一方のデータベースに送信されると、適用プロセスは、行LCRを表に適用しようとしたときに競合を検出します。デフォルトでは、適用エラーがエラー・キューに入れられ、そこで手動で解消できます。適用エラーを回避するには、適用プロセスが環境に最適な方法で競合を処理するように競合解消を構成する必要があります。
Oracle Databaseには、行のUPDATEが原因で競合が発生した場合に競合を解消する競合ハンドラが組み込まれています。これらのハンドラは、組込み更新競合ハンドラと呼ばれています。
適用プロセスで、デキューされた行LCRに対する更新競合が発生した場合、2つのデータベースのデータの一貫性を維持するために行LCRを適用するか破棄する必要があります。更新競合を解消する最も一般的な方法は、最新のタイムスタンプを持つ変更を保持し、古い変更を破棄することです。表に最新の時刻競合解消を構成する方法については、「チュートリアル: 表の最新時刻競合解消の構成」を参照してください。
次の各項で、特定のタイプのレプリケーション環境で競合解消を構成する方法を説明します。
参照:
変更循環は、発生元のデータベースに変更を再び送信することを意味します。通常は、変更循環によって各データベース変更の結果が発生元のデータベースに無限にループするため、変更循環を回避する必要があります。このようなループによって、データベース内に意図しないデータが生成され、ネットワーキングと環境のコンピュータ・リソースに負荷がかかります。デフォルトでは、Oracle Streamsは変更循環を回避するように設計されています。
タグは、変更レコード内の追加情報です。データベース変更を記録する各REDOエントリと、データベース変更をカプセル化する各論理変更レコード(LCR)には、タグが含まれます。タグのデータ型はRAWです。
デフォルトでは、変更レコードには次のタグ値があります。
NULLです。特定のデータベース・セッションに対してこのデフォルトを変更できます。
'00''(ゼロが2つ)と等価の16進数になります。特定の適用プロセスのデフォルトは変更可能です。
LCRのタグ値は、LCRがどのように取得されたかによって決まります。
Oracle Streamsクライアントのルールには、タグ値の条件を含めることができます。たとえば、取得プロセスのルールは、REDOレコードのタグ値に基づいてREDOログ内の変更が取得されるかどうかを決定できます。Oracle Streamsレプリケーション環境では、Oracle Streamsクライアントはタグとルールを使用して変更循環を回避します。
次の各項で、特定のタイプのレプリケーション環境で変更循環が回避される方法を説明します。
注意:
DBMS_STREAMS.SET_TAGプロシージャを使用します。例については、「データベース・オブジェクトでの適用エラーの修正」を参照してください。
Oracle Streamsにより、多くの異なるタイプのカスタム・レプリケーション環境を構成できます。ただし、最も一般的なのは、2データベース、ハブアンドスポークおよびn-wayの3つのタイプのレプリケーション環境です。
次の各項で、これらの一般的なレプリケーション環境タイプについて説明し、どのタイプを使用するのが最適かの決定を支援します。
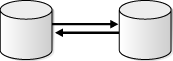
2データベース・レプリケーション環境は、レプリケートされたデータベース・オブジェクトを2つのデータベースのみで共有するレプリケーション環境です。一方のデータベースでレプリケートされたデータベース・オブジェクトに対して行われた変更は、取得された後、もう一方のデータベースに直接送信されて適用されます。2データベース・レプリケーション環境では、一方のデータベースのみでデータベース・オブジェクトに対する変更が許可される場合も、両方のデータベースでデータベース・オブジェクトに対する変更が許可される場合もあります。
レプリケートされたデータベース・オブジェクトに対する変更が一方のデータベースのみで許可されている場合、もう一方のデータベースには、これらのデータベース・オブジェクトの読取り専用レプリカが含まれます。これを単方向レプリケーション環境と呼び、通常は次の基本コンポーネントが含まれます。
図4-6に、単方向レプリケーション用に構成された2データベース・レプリケーション環境を示します。
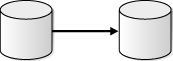
2データベース・レプリケーション環境では、両方のデータベースで、レプリケートされたデータベース・オブジェクトを変更できます。この場合、データベース・オブジェクトに対する変更は、両方のデータベースで取得され、他方のデータベースに送信されて取得されます。これを双方向レプリケーション環境と呼び、通常は次の基本コンポーネントが含まれます。
図4-7に、双方向レプリケーション用に構成された2データベース・レプリケーション環境を示します。
通常、双方向レプリケーション環境では、レプリケートされたデータベース・オブジェクトの同期化を維持するために競合解消を構成する必要があります。DBMS_STREAMS_ADMパッケージの構成プロシージャを使用して、2データベース・レプリケーション環境を構成できます。「Oracle Streamsレプリケーションの構成プロシージャの概要」を参照してください。
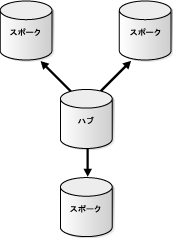
ハブアンドスポーク・レプリケーション環境は、集中データベース(ハブ)がセカンダリ・データベース(スポーク)と通信する環境です。スポークは相互に直接通信しません。ハブアンドスポーク・レプリケーション環境では、スポークはレプリケートされたデータベース・オブジェクトに対する変更を許可する場合と許可しない場合があります。
スポークが変更を許可しない場合、スポークにはハブのデータベース・オブジェクトの読取り専用レプリカが含まれます。このタイプのハブアンドスポーク・レプリケーション環境には、通常は次の基本コンポーネントがあります。
図4-8に、読取り専用スポークのあるハブアンドスポーク・レプリケーション環境を示します。
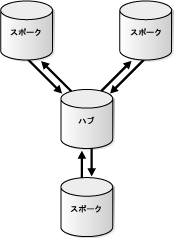
スポークがデータベース・オブジェクトに対する変更を許可する場合、通常は変更が取得されてハブに送信され、ハブが他のスポークに変更をレプリケートします。このタイプのハブアンドスポーク・レプリケーション環境には、通常は次の基本コンポーネントがあります。
図4-9に、読取り/書込みスポークのあるハブアンドスポーク・レプリケーション環境を示します。
通常、スポーク・データベースでの変更が許可されるハブアンドスポーク・レプリケーション環境では、レプリケートされたデータベース・オブジェクトの同期化を維持するために競合解消を構成する必要があります。ハブアンドスポーク・レプリケーション環境では、レプリケートされたデータベース・オブジェクトに対する変更が一部のスポークでは許可されますが、残りのスポークでは許可されない場合があります。
DBMS_STREAMS_ADMパッケージの構成プロシージャを使用して、ハブアンドスポーク・レプリケーション環境を構成できます。「Oracle Streamsレプリケーションの構成プロシージャの概要」を参照してください。
ハブアンドスポーク・レプリケーションが有効な場合については、「Oracle Streamsでのデータのレプリケート時期」を参照してください。
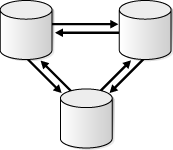
n-wayレプリケーション環境は、各データベースが環境内の他のデータベースと相互に直接通信する環境です。あるデータベースでのレプリケートされたデータベース・オブジェクトに対する変更は、取得されて環境内の他の各データベースに直接送信され、そこで適用されます。
n-wayレプリケーション環境には、通常は次の基本コンポーネントがあります。
図4-10に、n-wayレプリケーション環境を示します。
オラクル社が提供する次のパッケージを使用して、n-wayレプリケーション環境を構成できます。
DBMS_STREAMS_ADMを使用して、キューの設定、取得プロセスまたは同期取得の作成、伝播の作成、適用プロセスおよびレプリケーション環境でのルールおよびルール・セットの構成などの、ほとんどの構成アクションが実行できます。
DBMS_CAPTURE_ADMを使用して、レプリケーション環境で構成した取得プロセスを開始できます。
DBMS_APPLY_ADMを使用して競合解消を構成し、その他の構成タスクと同様に適用プロセスを開始できます。
n-wayレプリケーションが有効な場合については、「Oracle Streamsでのデータのレプリケート時期」を参照してください。
通常、n-wayレプリケーション環境では、レプリケートされたデータベース・オブジェクトの同期化を維持するために競合解消を構成する必要があります。
n-wayレプリケーション環境の構成は、このマニュアルの対象外です。n-wayレプリケーション環境を構成する例の詳細は、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。
Oracle Streamsレプリケーション環境を構成する最も簡単な方法は、DBMS_STREAMS_ADMパッケージにある次のいずれかの構成プロシージャを実行することです。
MAINTAIN_GLOBALプロシージャ: データベース・レベルでの変更を2つのデータベース間でレプリケートするOracle Streams環境を構成します。
MAINTAIN_SCHEMASプロシージャ: 指定したスキーマへの変更を2つのデータベース間でレプリケートするOracle Streams環境を構成します。
MAINTAIN_SIMPLE_TTSプロシージャ: ソース・データベースからの単純な表領域のクローンを宛先データベースに作成し、Oracle Streamsを使用してこの表領域を両方のデータベースで維持します。
MAINTAIN_TABLESプロシージャ: 指定した表への変更を2つのデータベース間でレプリケートするOracle Streams環境を構成します。
MAINTAIN_TTSプロシージャ: ソース・データベースからの表領域セットのクローンを宛先データベースに作成し、Oracle Streamsを使用してこれらの表領域を両方のデータベースで維持します。
これらのプロシージャは、同時に2つのデータベースを構成します。一方のデータベースをソース・データベースに、もう一方のデータベースを宛先データベースに指定する必要があります。これらのプロシージャを複数回実行することによって、2つ以上のデータベースを使用するレプリケーション環境を構成できます。
表4-1に、これらのプロシージャに必要なパラメータを示します。
また、各プロシージャには、オプションのパラメータもあります。bi_directionalパラメータは、重要なオプションのパラメータです。レプリケートされたデータベース・オブジェクトに対する変更を各データベースで取得して、他のデータベースに送信するには、bi_directionalパラメータをTRUEに設定する必要があります。このパラメータのデフォルトの設定はFALSEです。bi_directionalパラメータがFALSEに設定されていると、プロシージャは、宛先データベースでの変更が取得されない単方向レプリケーション環境を構成します。
これらのプロシージャは、Oracle Streamsレプリケーション環境を構成するために複数のタスクを実行します。次のタスクがあります。
bi_directionalパラメータがTRUEに設定されている場合に、宛先データベースで、レプリケートされたデータベース・オブジェクトに対するサプリメンタル・ロギングを構成します。
source_databaseパラメータで指定されたデータベースでプロシージャを実行すると、このデータベースでローカル取得プロセスが構成されます。source_databaseパラメータで指定されたデータベース以外のデータベースでプロシージャを実行すると、プロシージャを実行するデータベースでダウンストリーム取得プロセスが構成されます。「取得プロセスでの変更の取得の概要」を参照してください。
bi_directionalパラメータがTRUEに設定されている場合に、宛先データベースで、レプリケートされたデータベース・オブジェクトに対する変更を取得するための取得プロセスを構成します。この取得プロセスは、ローカル取得プロセスである必要があります。
bi_directionalパラメータがTRUEに設定されている場合に、宛先データベースでデータベース・オブジェクトに対して行われた変更をソース・データベースに送信するための伝播を構成します。
bi_directionalパラメータがTRUEに設定されている場合に、宛先データベースからの変更を適用する適用プロセスをソース・データベースで構成します。
bi_directionalパラメータがTRUEに設定されている場合に、ソース・データベースで、レプリケートされたデータベース・オブジェクトのインスタンス化SCNを設定します。これらのプロシージャでは、常にハブアンドスポーク・レプリケーション環境用のタグが構成されます。これらのプロシージャおよびタグに関する重要な考慮事項を次に示します。
タグおよび様々なタイプのレプリケーション環境については、「変更の循環を回避するためのタグの概要」および「Oracle Streamsレプリケーション環境の一般的なタイプの概要」を参照してください。
|
参照:
|
Oracle Enterprise Manager以外にも、Oracle Streamsレプリケーション環境を構成および管理するためのPL/SQLパッケージが提供されています。また、Oracle Streamsレプリケーション環境を監視するためのデータ・ディクショナリ・ビューも提供されています。
次の各項で、Oracle Streamsが提供する主要なPL/SQLパッケージおよびデータ・ディクショナリ・ビューについて説明します。
表4-2に、Oracle Streamsレプリケーション環境の構成および管理に重要なPL/SQLパッケージを示します。
|
参照:
|
表4-3に、Oracle Streamsレプリケーション環境の監視に重要なデータ・ディクショナリ・ビューを示します。
|
参照:
|
Oracle Streamsレプリケーションを構成する前に、レプリケーション環境に参加するデータベースを準備します。
GLOBAL_NAMES初期化パラメータをTRUEに設定します。「GLOBAL_NAMES初期化パラメータをTRUEに設定」を参照してください。
COMPATIBLE初期化パラメータをできるだけ高く設定することをお薦めします。可能な場合は、このパラメータを11.1.0以上に設定します。
MEMORY_TARGET初期化パラメータ(自動メモリー管理)、SGA_TARGET初期化パラメータ(自動共有メモリー管理)またはSTREAMS_POOL_SIZE初期化パラメータを設定することにより、Oracle Streamsを管理できます。Oracle Streamsプールの詳細は、『Oracle Streams概要および管理』を参照してください。Oracle Streamsコンポーネントのメモリー要件は次のとおりです。
parallelismで制御されます。取得プロセスのパフォーマンスは、取得プロセスの並行性を調整すると改善される場合があります。
parallelismで制御されます。適用プロセスのパフォーマンスは、適用プロセスの並行性を調整すると改善される場合があります。
PROCESSESおよびSESSIONS初期化パラメータの値を増やすことが必要な場合があります。
ベスト・プラクティスに従えば、パフォーマンスの最適な環境を構成して問題を回避することができます。DBMS_STREAMS_ADMパッケージの構成プロシージャを使用すれば自動的にベスト・プラクティスに従いますが、構成プロシージャを使用せずにOracle Streamsレプリケーション環境を構成する場合は、ベスト・プラクティスをよく確認し、できるだけそれに従ってください。
次に、Oracle Streamsの構成時に従う必要のある重要なベスト・プラクティスを示します。
Oracle Streams環境を構成した後は、Oracle Streams環境での操作時に次の重要なベスト・プラクティスに従う必要があります。
これらのベスト・プラクティスと、その他のOracle Streamsのベスト・プラクティスの詳細は、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。
|
参照:
|
この項では、Oracle Streamsレプリケーション環境の構成方法について、例を使用して説明します。例では、最も一般的なタイプのOracle Streamレプリケーション環境を構成します。
次に、例について説明します。
この例では、2つのデータベースでhrスキーマにあるすべての表にデータ操作言語(DML)変更をレプリケートするOracle Streamsレプリケーション環境を構成します。構成では、レプリケートされたデータベース・オブジェクトに対する変更を取得する取得プロセスを使用します。
例は、単方向レプリケーションまたは双方向レプリケーション用に環境を構成する方法を示しています。単方向レプリケーションでは、1つのデータベースのみがデータベース・オブジェクトを変更できます。双方向レプリケーションでは、両方のデータベースがデータベース・オブジェクトを変更できます。
この構成は、2つのデータベースのみを含む比較的単純なレプリケーション環境を構成する際に有効です。2つ目のデータベースをレポートまたはデータ分析に使用する場合は、単方向レプリケーション環境を構成します。両方のデータベースでデータの読取り/書込みが必要な場合は、双方向レプリケーション環境を構成します。たとえば、スケーラビリティやデータの可用性を向上させるには、双方向レプリケーションを使用します。
2データベース・レプリケーション環境の詳細は、「2データベース・レプリケーション環境の概要」を参照してください。
この例では、2つのデータベースでhrスキーマにあるすべての表にデータ操作言語(DML)の変更をレプリケートするOracle Streamsレプリケーション環境を構成します。例は、単方向レプリケーションの構成方法を示していて、レプリケートされたデータベース・オブジェクトに対する変更は、1つのソース・データベースでのみ許可されます。構成では、ソース・データベースでデータベース・オブジェクトに対して行った変更を取得するために、宛先データベースでダウンストリーム取得プロセスを使用しています。宛先データベースでは、データベース・オブジェクトは読取り専用です。
この構成は、プライマリ・データベースから別のデータベースにレポートまたはデータ分析をオフロードする際に使用します。この例では、2つ目のデータベースで取得プロセスを実行し、プライマリ・データベースの負荷を削減しています。
2データベース・レプリケーション環境の詳細は、「2データベース・レプリケーション環境の概要」を参照してください。
この例では、3つのデータベースでhrスキーマにあるすべての表にデータ操作言語(DML)をレプリケートするOracle Streamsレプリケーション環境を構成します。この例では、1つのハブと2つのスポークを持つハブアンドスポーク・レプリケーション環境を構成します。ハブアンドスポーク・レプリケーション環境は、1つの中央データベース(ハブ)がセカンダリ・データベース(スポーク)と通信する環境です。この例では、スポーク・データベースによって、レプリケートされたデータベース・オブジェクトに対する変更が可能になります。構成では、レプリケートされたデータベース・オブジェクトに対する変更を取得する取得プロセスを使用します。
この構成は、複数のセカンダリ・データベースにデータをレプリケートする必要のある中央データベースが存在する場合に使用します。たとえば、本社に中央データベースがあり、販売代理店に複数のセカンダリ・データベースがある企業にこの構成が有効です。
ハブアンドスポーク・レプリケーション環境の詳細は、「ハブアンドスポーク・レプリケーション環境の概要」を参照してください。
この例では、2つのデータベースでhrスキーマにあるemployees表およびdepartments表にデータ操作言語(DML)変更をレプリケートするOracle Streamsレプリケーション環境を構成します。この例では、2つのデータベース間での双方向レプリケーションを構成しています。このため、データベース・オブジェクトに対する変更は両方のデータベースで許可されています。構成では、レプリケートされたデータベース・オブジェクトに対する変更を取得する同期取得を使用します。
この構成は、2つのデータベースと少数の表のみを使用する比較的単純なレプリケーション環境を構成する際に使用します。Oracle Database 11g Standard Editionをインストールしている場合は、同期取得を使用することもできます。取得プロセスを使用するには、Oracle Database 11g Enterprise Editionをインストールする必要があります。
2データベース・レプリケーション環境の詳細は、「2データベース・レプリケーション環境の概要」を参照してください。
この項では、表の競合解消を構成する例も示します。「チュートリアル: 表の最新時刻競合解消の構成」を参照してください。競合解消は、レプリケートされた表に対するDML変更の実行を2つ以上のデータベースに対して許可するレプリケーション環境で使用します。この例は、最新時刻の競合解消を構成しています。このため、表に対する行変更によって競合が発生すると、最新の変更は保持され、古い変更は破棄されます。競合解消の詳細は、「競合と競合解消の概要」を参照してください。
この例では、hrスキーマにあるすべての表に、データ操作言語(DML)変更をレプリケートするOracle Streamsレプリケーション環境を構成します。この例では、変更を取得するローカル取得プロセスを使用して2データベース・レプリケーション環境を構成します。この例では、グローバル・データベース名db1.example.comおよびdb2.example.comを使用します。ただし、例を完了するために、ご使用の環境のデータベースに置き換えることもできます。2データベース・レプリケーション環境の詳細は、「2データベース・レプリケーション環境の概要」を参照してください。
この例では、DBMS_STREAMS_ADMパッケージのMAINTAIN_SCHEMASプロシージャを使用して2データベース・レプリケーション環境を構成します。このプロシージャは、1つ以上のスキーマをレプリケートするOracle Streams環境を構成する最速で最も単純な方法です。また、プロシージャはOracle Streamsレプリケーション環境に対して設定されたベスト・プラクティスに従います。
レプリケーション用に構成されているデータベース・オブジェクトは、MAINTAIN_SCHEMASプロシージャの実行時に、宛先データベースに存在する場合としない場合があります。宛先データベースにデータベース・オブジェクトが存在しない場合、MAINTAIN_SCHEMASプロシージャはデータ・ポンプ・エクスポート/インポートを使用して、宛先データベースでデータベース・オブジェクトをインスタンス化します。インスタンス化の際に、これらのデータベース・オブジェクトにインスタンス化SCNが設定されます。宛先データベースにデータベース・オブジェクトが存在する場合、MAINTAIN_SCHEMASプロシージャは既存のデータベース・オブジェクトを保持して、インスタンス化SCNを設定します。この例では、MAINTAIN_SCHEMASプロシージャを実行する前に、db1.example.comデータベースおよびdb2.example.comデータベースの両方にhrスキーマが存在しています。
この例では、単方向レプリケーションまたは双方向レプリケーションの構成方法を示しています。双方向レプリケーションを構成するには、追加の手順を実行して、構成プロシージャの実行時にbi_directionalパラメータをTRUEに設定する必要があります。
図4-11に、この例で作成した環境の概要を示します。双方向レプリケーションに必要な追加のコンポーネントはグレーで表示され、そのアクションは破線で示されています。
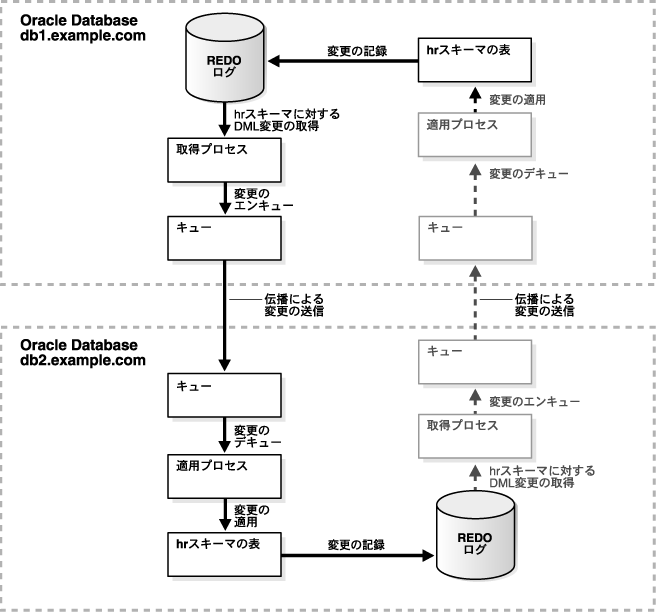
db1.example.comデータベースがdb2.example.comデータベースと通信できるように、ネットワーク接続を構成します。データベース間のネットワーク接続の構成の詳細は、『Oracle Database 2日でデータベース管理者』を参照してください。
strmadminであると想定します。
db1.example.comデータベースからdb2.example.comデータベースへのデータベース・リンクを作成します。データベース・リンクは、Oracle Streams管理者のスキーマに作成する必要があります。また、データベース・リンクは別のデータベースでOracle Streams管理者に接続する必要があります。データベース・リンクの名前およびサービス名は、どちらもdb2.example.comである必要があります。詳細は、「チュートリアル: データベース・リンクの作成」を参照してください。
ARCHIVELOGモードで実行するようにdb1.example.comデータベースを構成します。取得プロセスがソース・データベースで生成された変更を取得するには、ソース・データベースをARCHIVELOGモードで実行する必要があります。ARCHIVELOGモードで実行するためのデータベースの構成の詳細は、『Oracle Database管理者ガイド』を参照してください。
db2.example.comデータベースからdb1.example.comデータベースへのデータベース・リンクを作成します。データベース・リンクは、Oracle Streams管理者のスキーマに作成する必要があります。また、データベース・リンクは別のデータベースでOracle Streams管理者に接続する必要があります。データベース・リンクの名前およびサービス名は、どちらもdb1.example.comである必要があります。詳細は、「チュートリアル: データベース・リンクの作成」を参照してください。
ARCHIVELOGモードで実行するようにdb2.example.comデータベースを構成します。取得プロセスがソース・データベースで生成された変更を取得するには、ソース・データベースをARCHIVELOGモードで実行する必要があります。ARCHIVELOGモードで実行するためのデータベースの構成の詳細は、『Oracle Database管理者ガイド』を参照してください。
db2.example.comデータベースに接続します。SQL*Plusの起動の詳細は、『Oracle Database 2日でデータベース管理者』を参照してください。
MAINTAIN_SCHEMASプロシージャで生成されるファイル(インスタンス化に使用するデータ・ポンプ・エクスポート・ダンプ・ファイルを含む)を保持するディレクトリ・オブジェクトを作成します。ディレクトリ・オブジェクトは、コンピュータ・システム上の任意のアクセス可能ディレクトリを指すことができます。たとえば、次の文は、/usr/db2_log_filesディレクトリを指すdb2_dirという名前のディレクトリ・オブジェクトを作成します。
CREATE DIRECTORY db2_dir AS '/usr/db2_log_files';
db1.example.comデータベースにOracle Streams管理者として接続します。SQL*Plusでのデータベースへの接続の詳細は、『Oracle Database管理者ガイド』を参照してください。
MAINTAIN_SCHEMASプロシージャで生成されるファイル(インスタンス化に使用するデータ・ポンプ・エクスポート・ダンプ・ファイルを含む)を保持するディレクトリ・オブジェクトを作成します。ディレクトリ・オブジェクトは、コンピュータ・システム上の任意のアクセス可能ディレクトリを指すことができます。たとえば、次の文は、/usr/db1_log_filesディレクトリを指すdb1_dirという名前のディレクトリ・オブジェクトを作成します。
CREATE DIRECTORY db1_dir AS '/usr/db1_log_files';
MAINTAIN_SCHEMASプロシージャを実行して、db1.example.comデータベースとdb2.example.comデータベース間でhrスキーマのレプリケーションを構成します。bi_directionalパラメータが、構成するレプリケーション環境用に適切に設定されていることを確認します。このパラメータは、単方向レプリケーションを構成する場合はFALSEに、双方向レプリケーションを構成する場合はTRUEに設定します。
BEGIN DBMS_STREAMS_ADM.MAINTAIN_SCHEMAS( schema_names => 'hr', source_directory_object => 'db1_dir', destination_directory_object => 'db2_dir', source_database => 'db1.example.com', destination_database => 'db2.example.com', bi_directional => FALSE); -- Set to TRUE for bi-directional END; /
MAINTAIN_SCHEMASプロシージャは、多くの構成タスクを実行するため時間がかかることがあります。プロシージャの実行中は、宛先データベースのレプリケートされたデータベース・オブジェクトにデータ操作言語(DML)またはデータ定義言語(DLL)変更が行われないようにしてください。「Oracle Streamsレプリケーションの構成プロシージャの概要」を参照してください。
構成プロシージャを実行すると、進捗情報がDBA_RECOVERABLE_SCRIPT、DBA_RECOVERABLE_SCRIPT_PARAMS、DBA_RECOVERABLE_SCRIPT_BLOCKSおよびDBA_RECOVERABLE_SCRIPT_ERRORSデータ・ディクショナリ・ビューに記録されます。プロシージャがエラーによって停止した場合は、DBMS_STREAMS_ADMパッケージ内のRECOVER_OPERATIONプロシージャの使用方法について、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。
hrスキーマ内のすべての表に対して最新時刻の競合解消を構成します。このスキーマには、countries、departments、employees、jobs、job_history、locationsおよびregions表が含まれます。方法については、「チュートリアル: 表の最新時刻競合解消の構成」を参照してください。
例を完了すると、次の特性を持つ2データベース・レプリケーション環境が構成されます。
db1.example.comでは、サプリメンタル・ロギングがhrスキーマの表に対して構成されています。
db1.example.comデータベースには次のコンポーネントがあります。
db2.example.comデータベースには次のコンポーネントがあります。
db2.example.comでは、hrスキーマの表に対するサプリメンタル・ロギング。
db2.example.comでは、システムで生成された名前を持つ取得プロセス。取得プロセスはhrスキーマへのDML変更を取得します。
db2.example.comでは、システムで生成された名前を持つキュー。このキューは、データベースの取得プロセスに対するものです。
db1.example.comでは、システムで生成された名前を持つ、db2.example.comデータベースから送信された変更を受信するキュー。このキューは、ローカル・データベースの適用プロセスに対するものです。
db1.example.comでは、システムで生成された名前を持つ適用プロセス。適用プロセスはキューから変更をデキューし、それをhrスキーマに適用します。
レプリケーション環境における変更の循環の回避については、「変更の循環を回避するためのタグの概要」を参照してください。単方向レプリケーションを構成した場合は、変更は単一のロケーションでのみ取得されるため、変更の循環は発生しません。
db1.example.comデータベースで、取得プロセスが有効化され、取得タイプがローカルであることを確認します。確認には、「取得プロセスの情報の表示」の手順に従って、「取得」サブページで「ステータス」および「取得タイプ」フィールドを確認します。
db1.example.comデータベースで、伝播が有効化されていることを確認します。確認には、「伝播の情報の表示」の手順に従って、「伝播」サブページで「ステータス」フィールドを確認します。
db2.example.comデータベースで、適用プロセスが有効化されていることを確認します。確認には、「適用プロセスの情報の表示」の手順に従って、「適用」サブページで「ステータス」フィールドを確認します。
hrスキーマに対する変更を取得するデータベースで、DML変更をhrスキーマのすべての表に対して行います。この例では、db1.example.comデータベースがhrスキーマに対する変更を取得しています。双方向レプリケーションを構成した場合は、db2.example.comもhrスキーマに対する変更を取得します。
参照:
MAINTAIN_SCHEMASプロシージャの使用方法の詳細は、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。
MAINTAIN_SCHEMASプロシージャの詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。
この項の例では、hrスキーマにあるすべての表に、データ操作言語(DML)変更をレプリケートするOracle Streamsレプリケーション環境を構成します。この例では、宛先データベースでダウンストリーム取得プロセスを使用して2データベース・レプリケーション環境を構成します。この例では、グローバル・データベース名src.example.comおよびdest.example.comを使用します。ただし、例を完了するために、ご使用の環境のデータベースに置き換えることもできます。2データベース・レプリケーション環境の詳細は、「2データベース・レプリケーション環境の概要」を参照してください。
この例では、ダウンストリーム取得プロセスは宛先データベースdest.example.comで実行されます。したがって、変更の取得に必要なリソースはソース・データベースsrc.example.comで解放されます。この例では、アーカイブ・ログ・ダウンストリーム取得プロセスではなく、リアルタイム・ダウンストリーム取得プロセスを構成します。リアルタイム・ダウンストリーム取得は、ソース・データベースでの変更の取得に必要な時間を短縮できるという利点があります。時間を短縮できるのは、データを取得する前にREDOログ・ファイルがアーカイブされるまで待つ必要がないためです。
この例では、レプリケートされたデータベース・オブジェクトが宛先データベースでレポートおよび分析に使用されると想定しています。このため、これらのデータベース・オブジェクトは、dest.example.comデータベースでは読取り専用であると想定しています。
この例では、DBMS_STREAMS_ADMパッケージのMAINTAIN_SCHEMASプロシージャを使用して2データベース・レプリケーション環境を構成します。このプロシージャは、1つ以上のスキーマをレプリケートするOracle Streams環境を構成する最速で最も単純な方法です。また、プロシージャはOracle Streamsレプリケーション環境に対して設定されたベスト・プラクティスに従います。
レプリケーション用に構成されているデータベース・オブジェクトは、MAINTAIN_SCHEMASプロシージャの実行時に、宛先データベースに存在する場合としない場合があります。宛先データベースにデータベース・オブジェクトが存在しない場合、MAINTAIN_SCHEMASプロシージャはデータ・ポンプ・エクスポート/インポートを使用して、宛先データベースでデータベース・オブジェクトをインスタンス化します。インスタンス化の際に、これらのデータベース・オブジェクトにインスタンス化SCNが設定されます。宛先データベースにデータベース・オブジェクトが存在する場合、MAINTAIN_SCHEMASプロシージャは既存のデータベース・オブジェクトを保持して、インスタンス化SCNを設定します。この例では、MAINTAIN_SCHEMASプロシージャを実行する前に、src.example.comデータベースおよびdest.example.comデータベースの両方にhrスキーマが存在しています。
図4-12に、この例で作成する環境の概要を示します。
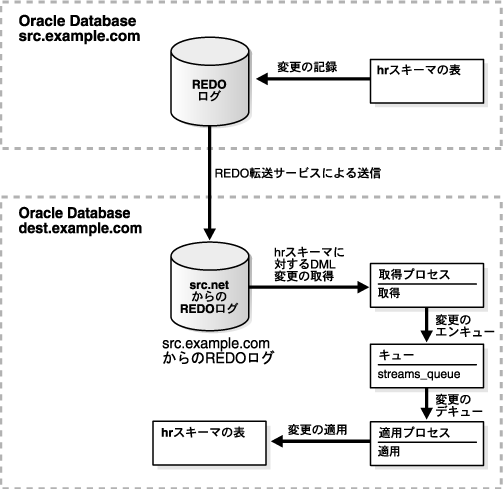
src.example.comデータベースとdest.example.comデータベースが相互に通信できるように、ネットワーク接続を構成します。データベース間のネットワーク接続の構成の詳細は、『Oracle Database 2日でデータベース管理者』を参照してください。
strmadminであると想定します。
src.example.comデータベースからdest.example.comデータベースへ。データベース・リンクの名前とサービス名は、どちらもdest.example.comである必要があります。
dest.example.comデータベースからsrc.example.comデータベースへ。データベース・リンクの名前とサービス名は、どちらもsrc.example.comである必要があります。
src.example.comは、dest.example.comデータベースにおけるダウンストリーム取得プロセスのソース・データベースなので、dest.example.comデータベースからsrc.example.comデータベースへのデータベース・リンクが必要となります。このデータベース・リンクは取得プロセスの作成および構成を簡略化します。
各データベース・リンクは、Oracle Streams管理者のスキーマに作成する必要があります。また、各データベース・リンクは、他のデータベースでOracle Streams管理者に接続する必要があります。方法については、「チュートリアル: データベース・リンクの作成」を参照してください。
ARCHIVELOGモードで実行するように両方のデータベースを構成します。ダウンストリーム取得プロセスがソース・データベースで生成された変更を取得するには、ソース・データベースとダウンストリーム取得データベースをARCHIVELOGモードで実行する必要があります。この例では、src.example.comおよびdest.example.comデータベースをARCHIVELOGモードで実行する必要があります。ARCHIVELOGモードで実行するためのデータベースの構成の詳細は、『Oracle Database管理者ガイド』を参照してください。
REDO転送セッションは、Secure Sockets Layer(SSL)プロトコルまたはリモート・ログイン・パスワード・ファイルのいずれかを使用して認証されます。ソース・データベースにリモート・ログイン・パスワード・ファイルがある場合は、それをダウンストリーム取得データベース・システムの適切なディレクトリにコピーします。パスワード・ファイルは、ソース・データベースおよびダウンストリーム取得データベースで同じである必要があります。
この例で、ソース・データベースはsrc.example.comで、ダウンストリーム取得データベースはdest.example.comです。REDO転送の認証要件の詳細は、『Oracle Data Guard概要および管理』を参照してください。
src.example.comで次の初期化パラメータを設定し、REDOデータがソース・データベースのオンラインREDOログからダウンストリーム・データベースdest.example.comのスタンバイREDOログに転送されるようにREDO転送サービスを構成します。
LOG_ARCHIVE_DEST_n初期化パラメータを1つ以上構成します。これを行うには、このパラメータに次の属性を設定します。
SERVICE: ダウンストリーム・データベースのネットワーク・サービス名を指定します。
ASYNCまたはSYNC: REDO転送モードを指定します。ASYNCを指定するメリットは、ソース・データベースのパフォーマンスにほとんど影響を与えないことです。ソース・データベースでOracle Database 10gリリース1以上が実行されていて、ダウンストリーム・データベースまたはネットワークのパフォーマンスが低いときは、ASYNCを使用してソース・データベースのパフォーマンスへの影響を回避することをお薦めします。
SYNCを指定するメリットは、ASYNCを指定する場合と比べて、ダウンストリーム・データベースにREDOデータが速く送信されることです。また、SYNC AFFIRMを指定すると、MAXIMUM AVAILABILITYスタンバイ保護モードの場合と同様に動作するようになります。SQL文ALTER DATABASE STANDBY DATABASE TO MAXIMIZE AVAILABILITYを指定しても、Oracle Streams取得プロセスには影響しないことに注意してください。
NOREGISTER: この属性は、アーカイブREDOログ・ファイルの場所がダウンストリーム・データベース制御ファイルに記録されないように指定します。
VALID_FOR: (ONLINE_LOGFILE,PRIMARY_ROLE)または(ONLINE_LOGFILE,ALL_ROLES)を指定します。
DB_UNIQUE_NAME: ダウンストリーム・データベースの一意の名前です。ダウンストリーム・データベースでDB_UNIQUE_NAME初期化パラメータに指定した名前を使用します。
次に、ダウンストリーム・データベースを指定するLOG_ARCHIVE_DEST_n設定の例を示します。
LOG_ARCHIVE_DEST_2='SERVICE=DEST.EXAMPLE.COM ASYNC NOREGISTER VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=dest'
LOG_ARCHIVE_DEST_STATE_n: ソース・データベースで、ダウンストリーム・データベースのLOG_ARCHIVE_DEST_nパラメータに対応する初期化パラメータをENABLEに設定します。たとえば、ダウンストリーム・データベースにLOG_ARCHIVE_DEST_2初期化パラメータが設定されている場合、LOG_ARCHIVE_DEST_STATE_2パラメータを次のように設定します。
LOG_ARCHIVE_DEST_STATE_2=ENABLE
LOG_ARCHIVE_CONFIG: この初期化パラメータのDB_CONFIG属性を設定して、ソース・データベースおよびダウンストリーム・データベースのDB_UNIQUE_NAMEを含めます。たとえば、ソース・データベースのDB_UNIQUE_NAMEがsrcで、ダウンストリーム・データベースのDB_UNIQUE_NAMEがdestの場合、次のパラメータを指定します。
LOG_ARCHIVE_CONFIG='DG_CONFIG=(src,dest)'
デフォルトでは、LOG_ARCHIVE_CONFIGパラメータによって、データベースでのREDOの送受信が可能になります。
dest.example.comで、次の初期化パラメータを設定し、ローカルに生成されるREDOデータのアーカイブを構成します。
LOG_ARCHIVE_DEST_n初期化パラメータで、少なくとも1つのアーカイブ・ログの保存先を、ダウンストリーム・データベースを実行しているコンピュータ・システム上のディレクトリまたはフラッシュ・リカバリ領域に設定します。これを設定するには、このパラメータの次の属性を設定します。
LOCATION: ディスク・ディレクトリへの有効なパス名またはUSE_DB_RECOVERY_FILE_DESTを指定します。LOCATION属性に指定する各宛先に、一意のディレクトリ・パス名またはUSE_DB_RECOVERY_FILE_DESTを指定する必要があります。これは、ローカル・データベースで生成されるアーカイブREDOログ・ファイルのローカルの宛先です。
VALID_FOR: (ONLINE_LOGFILE,PRIMARY_ROLE)または(ONLINE_LOGFILE,ALL_ROLES)を指定します。
次の例は、リアルタイム・ダウンストリーム取得データベースでローカルに生成されるREDOデータに対するLOG_ARCHIVE_DEST_n設定です。
LOG_ARCHIVE_DEST_1='LOCATION=/home/arc_dest/local_rl VALID_FOR=(ONLINE_LOGFILE,PRIMARY_ROLE)'
リアルタイム・ダウンストリーム取得構成では、アーカイブ・スタンバイREDOログ・ファイルをダウンストリーム・データベースからのアーカイブ・オンラインREDOログ・ファイルとは別に保持する必要があります。これを実現するには、VALID_FOR属性のREDOログ・タイプにALL_LOGFILESではなくてONLINE_LOGFILEを指定します。
必要に応じて、LOG_ARCHIVE_DEST_n初期化パラメータの他の属性も指定できます。
LOG_ARCHIVE_DEST_nパラメータに対応するLOG_ARCHIVE_DEST_STATE_n初期化パラメータをENABLEに設定します。たとえば、LOG_ARCHIVE_DEST_1初期化パラメータが設定されている場合、LOG_ARCHIVE_DEST_STATE_1パラメータを次のように設定します。
LOG_ARCHIVE_DEST_STATE_1=ENABLE
dest.example.comで、ダウンストリーム・データベースがソース・データベースからREDOデータを受信し、ダウンストリーム・データベースのスタンバイREDOログにそのREDOデータを書き込むように、次の初期化パラメータを設定します。
LOG_ARCHIVE_DEST_n初期化パラメータで、少なくとも1つのアーカイブ・ログの保存先を、ダウンストリーム・データベースを実行しているコンピュータ・システム上のディレクトリまたはフラッシュ・リカバリ領域に設定します。これを設定するには、このパラメータの次の属性を設定します。
LOCATION: ディスク・ディレクトリへの有効なパス名またはUSE_DB_RECOVERY_FILE_DESTを指定します。LOCATION属性に指定する各宛先に、一意のディレクトリ・パス名またはUSE_DB_RECOVERY_FILE_DESTを指定する必要があります。これは、スタンバイREDOログから書き込まれたアーカイブREDOログ・ファイルのローカルの宛先です。リモート・ソース・データベースからのログ・ファイルは、ローカル・データベースのログ・ファイルとは別に保持する必要があります。
VALID_FOR: (STANDBY_LOGFILE,PRIMARY_ROLE)または(STANDBY_LOGFILE,ALL_ROLES)を指定します。
次の例は、リアルタイム・ダウンストリーム取得データベースでのLOG_ARCHIVE_DEST_n設定です。
LOG_ARCHIVE_DEST_2='LOCATION=/home/arc_dest/srl_src1 VALID_FOR=(STANDBY_LOGFILE,PRIMARY_ROLE)'
必要に応じて、LOG_ARCHIVE_DEST_n初期化パラメータの他の属性も指定できます。
LOG_ARCHIVE_DEST_nパラメータに対応するLOG_ARCHIVE_DEST_STATE_n初期化パラメータをENABLEに設定します。たとえば、ダウンストリーム・データベースにLOG_ARCHIVE_DEST_2初期化パラメータが設定されている場合、LOG_ARCHIVE_DEST_STATE_2パラメータを次のように設定します。
LOG_ARCHIVE_DEST_STATE_2=ENABLE
LOG_ARCHIVE_CONFIG: この初期化パラメータのDB_CONFIG属性を設定して、ソース・データベースおよびダウンストリーム・データベースのDB_UNIQUE_NAMEを含めます。たとえば、ソース・データベースのDB_UNIQUE_NAMEがsrcで、ダウンストリーム・データベースのDB_UNIQUE_NAMEがdestの場合、次のパラメータを指定します。
LOG_ARCHIVE_CONFIG='DG_CONFIG=(src,dest)'
デフォルトでは、LOG_ARCHIVE_CONFIGパラメータによって、データベースでのREDOの送受信が可能になります。
手順2、3または4で、インスタンスの実行中には初期化パラメータをリセットしなかったが、初期化パラメータ・ファイルでリセットした場合は、データベースを再起動します。ソース・データベースのグローバル名は、ソース・データベースがオープンな場合にのみダウンストリーム・データベースに送信されるため、ダウンストリーム・データベースにREDOデータを送信するときには、ソース・データベースがオープンである必要があります。
dest.example.comで、管理ユーザーとして接続してスタンバイREDOログ・ファイルを作成します。src.example.comに接続します。たとえば、管理ユーザーとしてsrc.example.comデータベースに接続するには、次のようにします。
sqlplus system@src.example.com Enter password: password
SQL*Plusの起動の詳細は、『Oracle Database 2日でデータベース管理者』を参照してください。
src.example.comで使用するログ・ファイルのサイズを決定します。スタンバイ・ログ・ファイルのサイズは、ソース・データベースのログ・ファイル・サイズと正確に同じかそれより大きくなるようにします。たとえば、ソース・データベースのログ・ファイル・サイズが500MBの場合、スタンバイ・ログ・ファイルのサイズも500MB以上にします。ソース・データベースにおけるREDOログ・ファイルのサイズ(バイト単位)は、ソース・データベースでV$LOGビューを問い合せて確認することができます。たとえば、次のようにV$LOGビューを問い合せます。
SELECT BYTES FROM V$LOG;
dest.example.comで必要なスタンバイ・ログ・ファイル・グループの数を決定します。スタンバイ・ログ・ファイル・グループの数は、ソース・データベースでのオンライン・ログ・ファイル・グループの数より1以上大きくする必要があります。たとえば、ソース・データベースに2つのオンライン・ログ・ファイル・グループがある場合、ダウンストリーム・データベースには少なくとも3つのスタンバイ・ログ・ファイル・グループが必要です。ソース・データベースのオンライン・ログ・ファイル・グループの数は、ソース・データベースでV$LOGビューを問い合せて確認することができます。たとえば、SQL*Plusで管理ユーザーとしてまだsrc.example.comに接続している状態で、次のようにV$LOGビューを問い合せます。
SELECT COUNT(GROUP#) FROM V$LOG;
dest.example.comに接続します。
CONNECT system@dest.example.com Enter password: password
ALTER DATABASE ADD STANDBY LOGFILEを使用して、ダウンストリーム・データベースdest.example.comにスタンバイ・ログ・ファイル・グループを追加します。たとえば、ソース・データベースに2つのオンラインREDOログ・ファイル・グループがあり、ログ・ファイルのサイズが500MBであるとします。この場合、次の文を使用して適切なスタンバイ・ログ・ファイル・グループを作成します。
ALTER DATABASE ADD STANDBY LOGFILE GROUP 3 ('/oracle/dbs/slog3a.rdo', '/oracle/dbs/slog3b.rdo') SIZE 500M; ALTER DATABASE ADD STANDBY LOGFILE GROUP 4 ('/oracle/dbs/slog4a.rdo', '/oracle/dbs/slog4b.rdo') SIZE 500M; ALTER DATABASE ADD STANDBY LOGFILE GROUP 5 ('/oracle/dbs/slog5a.rdo', '/oracle/dbs/slog5b.rdo') SIZE 500M;
dest.example.comで次の問合せを実行し、スタンバイ・ログ・ファイル・グループが正常に追加されたことを確認します。
SELECT GROUP#, THREAD#, SEQUENCE#, ARCHIVED, STATUS FROM V$STANDBY_LOG;
出力は次のようになります。
GROUP# THREAD# SEQUENCE# ARC STATUS ---------- ---------- ---------- --- ---------- 3 0 0 YES UNASSIGNED 4 0 0 YES UNASSIGNED 5 0 0 YES UNASSIGNED
LOCATION属性に指定したディレクトリに表示されることを確認します。ディレクトリ内のファイルを表示するために、ソース・データベースにあるログ・ファイルを切り替える必要がある場合があります。
src.example.comデータベースにOracle Streams管理者として接続します。SQL*Plusでのデータベースへの接続の詳細は、『Oracle Database管理者ガイド』を参照してください。
MAINTAIN_SCHEMASプロシージャで生成されるファイル(インスタンス化に使用するデータ・ポンプ・エクスポート・ダンプ・ファイルを含む)を保持するディレクトリ・オブジェクトを作成します。ディレクトリ・オブジェクトは、コンピュータ・システム上の任意のアクセス可能ディレクトリを指すことができます。たとえば、次の文は、/usr/src_log_filesディレクトリを指すsrc_dirという名前のディレクトリ・オブジェクトを作成します。
CREATE DIRECTORY src_dir AS '/usr/src_log_files';
dest.example.comデータベースにOracle Streams管理者として接続します。
MAINTAIN_SCHEMASプロシージャで生成されるファイル(インスタンス化に使用するデータ・ポンプ・エクスポート・ダンプ・ファイルを含む)を保持するディレクトリ・オブジェクトを作成します。ディレクトリ・オブジェクトは、コンピュータ・システム上の任意のアクセス可能ディレクトリを指すことができます。たとえば、次の文は、/usr/dest_log_filesディレクトリを指すdest_dirという名前のディレクトリ・オブジェクトを作成します。
CREATE DIRECTORY dest_dir AS '/usr/dest_log_files';
dest.example.comデータベースにまだOracle Streams管理者として接続しているときに、MAINTAIN_SCHEMASプロシージャを実行してsrc.example.comデータベースとdest.example.comデータベース間のレプリケーションを構成します。
BEGIN DBMS_STREAMS_ADM.MAINTAIN_SCHEMAS( schema_names => 'hr', source_directory_object => 'src_dir', destination_directory_object => 'dest_dir', source_database => 'src.example.com', destination_database => 'dest.example.com', capture_name => 'capture', capture_queue_table => 'streams_queue_qt', capture_queue_name => 'streams_queue', apply_name => 'apply', apply_queue_table => 'streams_queue_qt', apply_queue_name => 'streams_queue'); END; /
MAINTAIN_SCHEMASプロシージャは、多くの構成タスクを実行するため時間がかかることがあります。プロシージャの実行中は、宛先データベースのレプリケートされたデータベース・オブジェクトにデータ操作言語(DML)またはデータ定義言語(DLL)変更が行われないようにしてください。
MAINTAIN_SCHEMASプロシージャで必要なパラメータは、schema_names、source_directory_object、destination_directory_object、source_databaseおよびdestination_databaseです。「Oracle Streamsレプリケーションの構成プロシージャの概要」を参照してください。
この例では、取得プロセス、取得プロセスのキュー表、取得プロセスのキュー、適用プロセス、適用プロセスのキュー表および適用プロセスのキューの名前を選択できることを示すために他のパラメータを指定しています。これらのパラメータを指定しないと、システムで生成された名前が使用されます。
構成プロシージャを使用してダウンストリーム取得を構成する際は、キューおよびキュー表の名前を指定するパラメータは重要です。このような構成では、キュー間で変更が伝播されないようにするために、取得プロセスおよび適用プロセスがダウンストリーム取得プロセスで同じキューを使用するとより効率的です。このサンプル構成の効率を向上させるために、capture_queue_nameおよびapply_queue_nameパラメータの両方にstreams_queueが指定されていることに注意してください。また、capture_queue_tableおよびapply_queue_tableパラメータの両方にstreams_queue_qtが指定されています。
構成プロシージャを実行すると、進捗情報がDBA_RECOVERABLE_SCRIPT、DBA_RECOVERABLE_SCRIPT_PARAMS、DBA_RECOVERABLE_SCRIPT_BLOCKSおよびDBA_RECOVERABLE_SCRIPT_ERRORSデータ・ディクショナリ・ビューに記録されます。プロシージャがエラーによって停止した場合は、DBMS_STREAMS_ADMパッケージ内のRECOVER_OPERATIONプロシージャの使用方法について、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。
プロシージャが正常に完了してから、次の手順を実行します。
dest.example.comデータベースにまだOracle Streams管理者として接続しているときに、downstream_real_time_mine取得プロセスのパラメータをYに設定します。
BEGIN DBMS_CAPTURE_ADM.SET_PARAMETER( capture_name => 'capture', parameter => 'downstream_real_time_mine', value => 'Y'); END; /
取得プロセスのパラメータの設定にEnterprise Managerを使用する方法については、「取得プロセスのパラメータの設定」を参照してください。
src.example.comに接続します。
ALTER SYSTEM ARCHIVE LOG CURRENT;
ソース・データベースで現行のログ・ファイルをアーカイブすると、ソース・データベースのREDOログのリアルタイム・マイニングが開始されます。
例を完了すると、次の特性を持つ2データベース・レプリケーション環境が構成されます。
dest.example.comデータベースで、取得プロセスが有効化され、取得タイプがダウンストリームであることを確認します。確認には、「取得プロセスの情報の表示」の手順に従って、「取得」サブページで「ステータス」および「取得タイプ」フィールドを確認します。
dest.example.comデータベースで、適用プロセスが有効化されていることを確認します。確認には、「適用プロセスの情報の表示」の手順に従って、「適用」サブページで「ステータス」フィールドを確認します。
src.example.comデータベースで、hrスキーマの任意の表に対してDML変更を行った後、変更をコミットします。
dest.example.comデータベースで変更された表を問い合せてDML変更を表示します。
参照:
MAINTAIN_SCHEMASプロシージャの使用方法の詳細は、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。
MAINTAIN_SCHEMASプロシージャの詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。
この項の例では、hrスキーマにあるすべての表に、データ操作言語(DML)変更をレプリケートするOracle Streamsハブアンドスポーク・レプリケーション環境を構成します。この例では、各データベースで取得プロセスを使用してこれらの変更を取得します。ハブアンドスポーク・レプリケーションとは、中央のハブ・データベースが1つ以上のスポーク・データベースでの変更をレプリケートすることを意味します。スポーク・データベースは、相互に直接通信しません。このサンプル構成では、ハブ・データベースが、1つのスポーク・データベースで生成された変更を他のスポーク・データベースに送信します。ハブアンドスポーク・レプリケーション環境の詳細は、「ハブアンドスポーク・レプリケーション環境の概要」を参照してください。
この例では、DBMS_STREAMS_ADMパッケージのMAINTAIN_SCHEMASプロシージャを使用してハブアンドスポーク・レプリケーション環境を構成します。このプロシージャは、1つ以上のスキーマをレプリケートするOracle Streams環境を構成する最速で最も単純な方法です。また、プロシージャはOracle Streamsレプリケーション環境に対して設定されたベスト・プラクティスに従います。
この例では、ハブ・データベースのグローバル名はhub.example.com、スポーク・データベースのグローバル名はspoke1.example.comおよびspoke2.example.comです。ただし、使用している環境のデータベースをかわりに使用して例を完了することができます。
レプリケーション用に構成されているデータベース・オブジェクトは、MAINTAIN_SCHEMASプロシージャの実行時に、宛先データベースに存在する場合としない場合があります。宛先データベースにデータベース・オブジェクトが存在しない場合、MAINTAIN_SCHEMASプロシージャはデータ・ポンプ・エクスポート/インポートを使用して、宛先データベースでデータベース・オブジェクトをインスタンス化します。インスタンス化の際に、これらのデータベース・オブジェクトにインスタンス化SCNが設定されます。宛先データベースにデータベース・オブジェクトが存在する場合、MAINTAIN_SCHEMASプロシージャは既存のデータベース・オブジェクトを保持して、インスタンス化SCNを設定します。この例では、MAINTAIN_SCHEMASプロシージャを実行する前に、各データベースにhrスキーマが存在しています。
図4-13に、この例で作成する環境の概要を示します。
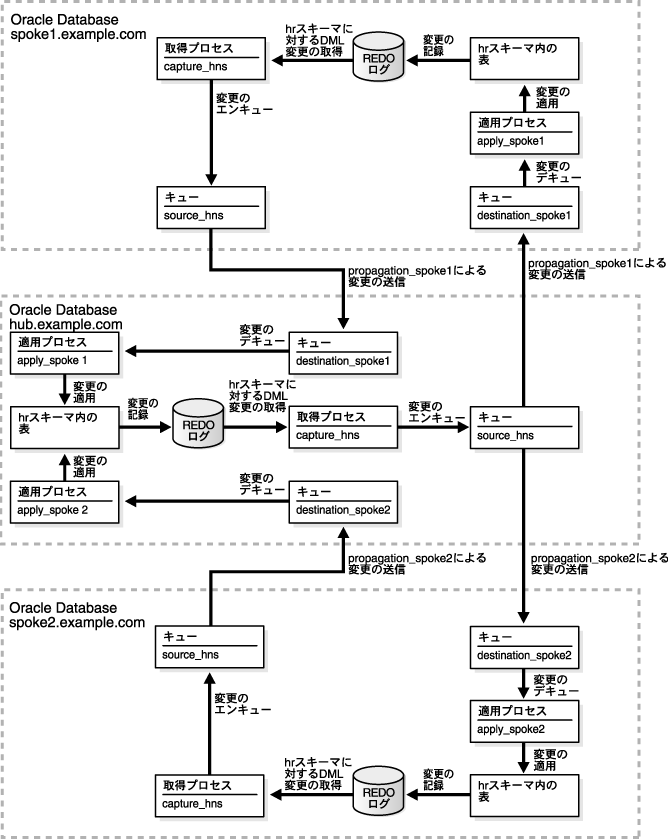
データベース間のネットワーク接続の構成の詳細は、『Oracle Database 2日でデータベース管理者』を参照してください。
strmadminであると想定します。
hub.example.comデータベースからspoke1.example.comデータベースへ。データベース・リンクの名前とサービス名は、どちらもspoke1.example.comである必要があります。
hub.example.comデータベースからspoke2.example.comデータベースへ。データベース・リンクの名前とサービス名は、どちらもspoke2.example.comである必要があります。
spoke1.example.comデータベースからhub.example.comデータベースへ。データベース・リンクの名前とサービス名は、どちらもhub.example.comである必要があります。
spoke2.example.comデータベースからhub.example.comデータベースへ。データベース・リンクの名前とサービス名は、どちらもhub.example.comである必要があります。
各データベース・リンクは、Oracle Streams管理者のスキーマに作成する必要があります。また、各データベース・リンクは宛先データベースでOracle Streams管理者に接続する必要があります。方法については、「チュートリアル: データベース・リンクの作成」を参照してください。
ARCHIVELOGモードで実行するように各ソース・データベースを構成します。取得プロセスがソース・データベースで生成された変更を取得するためには、ソース・データベースをARCHIVELOGモードで実行する必要があります。この例では、すべてのデータベースをARCHIVELOGモードで実行する必要があります。ARCHIVELOGモードで実行するためのデータベースの構成の詳細は、『Oracle Database管理者ガイド』を参照してください。
spoke1.example.comデータベースに接続します。SQL*Plusの起動の詳細は、『Oracle Database 2日でデータベース管理者』を参照してください。
MAINTAIN_SCHEMASプロシージャで生成されるファイル(インスタンス化に使用するデータ・ポンプ・エクスポート・ダンプ・ファイルを含む)を保持するディレクトリ・オブジェクトを作成します。ディレクトリ・オブジェクトは、コンピュータ・システム上の任意のアクセス可能ディレクトリを指すことができます。たとえば、次の文は、/usr/spoke1_log_filesディレクトリを指すspoke1_dirという名前のディレクトリ・オブジェクトを作成します。
CREATE DIRECTORY spoke1_dir AS '/usr/spoke1_log_files';
spoke2.example.comデータベースにOracle Streams管理者として接続します。SQL*Plusでのデータベースへの接続の詳細は、『Oracle Database管理者ガイド』を参照してください。
MAINTAIN_SCHEMASプロシージャで生成されるファイル(インスタンス化に使用するデータ・ポンプ・エクスポート・ダンプ・ファイルを含む)を保持するディレクトリ・オブジェクトを作成します。ディレクトリ・オブジェクトは、コンピュータ・システム上の任意のアクセス可能ディレクトリを指すことができます。たとえば、次の文は、/usr/spoke2_log_filesディレクトリを指すspoke2_dirという名前のディレクトリ・オブジェクトを作成します。
CREATE DIRECTORY spoke2_dir AS '/usr/spoke2_log_files';
hub.example.comデータベースにOracle Streams管理者として接続します。
MAINTAIN_SCHEMASプロシージャで生成されるファイル(インスタンス化に使用するデータ・ポンプ・エクスポート・ダンプ・ファイルを含む)を保持するディレクトリ・オブジェクトを作成します。ディレクトリ・オブジェクトは、コンピュータ・システム上の任意のアクセス可能ディレクトリを指すことができます。たとえば、次の文は、/usr/hub_log_filesディレクトリを指すhub_dirという名前のディレクトリ・オブジェクトを作成します。
CREATE DIRECTORY hub_dir AS '/usr/hub_log_files';
hub.example.comデータベースにまだStreams管理者として接続しているときに、MAINTAIN_SCHEMASプロシージャを実行してhub.example.comデータベースとspoke1.example.comデータベース間のレプリケーションを構成します。
BEGIN DBMS_STREAMS_ADM.MAINTAIN_SCHEMAS( schema_names => 'hr', source_directory_object => 'hub_dir', destination_directory_object => 'spoke1_dir', source_database => 'hub.example.com', destination_database => 'spoke1.example.com', capture_name => 'capture_hns', capture_queue_table => 'source_hns_qt', capture_queue_name => 'source_hns', propagation_name => 'propagation_spoke1', apply_name => 'apply_spoke1', apply_queue_table => 'destination_spoke1_qt', apply_queue_name => 'destination_spoke1', bi_directional => TRUE); END; /
MAINTAIN_SCHEMASプロシージャは、多くの構成タスクを実行するため時間がかかることがあります。プロシージャの実行中は、宛先データベースのレプリケートされたデータベース・オブジェクトにデータ操作言語(DML)またはデータ定義言語(DLL)変更が行われないようにしてください。
MAINTAIN_SCHEMASプロシージャで必要なパラメータは、schema_names、source_directory_object、destination_directory_object、source_databaseおよびdestination_databaseです。また、構成プロシージャを使用して双方向レプリケーションを構成する際は、bi_directionalパラメータをTRUEに設定する必要があります。「Oracle Streamsレプリケーションの構成プロシージャの概要」を参照してください。
この例では、取得プロセス、取得プロセスのキュー表、取得プロセスのキュー、伝播、適用プロセス、適用プロセスのキュー表および適用プロセスのキューの名前を選択できることを示すために他のパラメータを指定しています。これらのパラメータを指定しないと、システムで生成された名前が使用されます。
構成プロシージャを実行すると、進捗情報がDBA_RECOVERABLE_SCRIPT、DBA_RECOVERABLE_SCRIPT_PARAMS、DBA_RECOVERABLE_SCRIPT_BLOCKSおよびDBA_RECOVERABLE_SCRIPT_ERRORSデータ・ディクショナリ・ビューに記録されます。プロシージャがエラーによって停止した場合は、DBMS_STREAMS_ADMパッケージ内のRECOVER_OPERATIONプロシージャの使用方法について、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。
hub.example.comデータベースにまだStreams管理者として接続しているときに、MAINTAIN_SCHEMASプロシージャを実行してhub.example.comデータベースとspoke2.example.comデータベース間のレプリケーションを構成します。
BEGIN DBMS_STREAMS_ADM.MAINTAIN_SCHEMAS( schema_names => 'hr', source_directory_object => 'hub_dir', destination_directory_object => 'spoke2_dir', source_database => 'hub.example.com', destination_database => 'spoke2.example.com', capture_name => 'capture_hns', capture_queue_table => 'source_hns_qt', capture_queue_name => 'source_hns', propagation_name => 'propagation_spoke2', apply_name => 'apply_spoke2', apply_queue_table => 'destination_spoke2_qt', apply_queue_name => 'destination_spoke2', bi_directional => TRUE); END; /
hub.example.com、spoke1.example.com、spoke2.example.comの各データベースでhrスキーマ内のすべての表に対して最新時刻競合解消を構成します。このスキーマには、countries、departments、employees、jobs、job_history、locationsおよびregionsの各表が含まれます。方法については、「チュートリアル: 表の最新時刻競合解消の構成」を参照してください。
例を完了すると、次の特性を持つハブアンドスポーク・レプリケーション環境が構成されます。
hrスキーマの表に対して構成されています。
capture_hnsという名前の取得プロセスがあります。取得プロセスは、データベースのhrスキーマに対する変更を取得します。
source_hns_qtという名前のキュー表を使用するsource_hnsという名前のキューがあります。このキューは、データベースの取得プロセスに対するものです。
hub.example.comには、次の追加コンポーネントがあります。
apply_spoke1という名前の適用プロセス。この適用プロセスは、spoke1.example.comデータベースから送信されたhrスキーマに対する変更を適用します。
destination_spoke1_qtという名前のキュー表を使用するdestination_spoke1という名前のキュー。このキューは、データベースのapply_spoke1適用プロセスに対するものです。
apply_spoke2という名前の適用プロセス。この適用プロセスは、spoke2.example.comデータベースから送信されたhrスキーマに対する変更を適用します。
destination_spoke2_qtという名前のキュー表を使用するdestination_spoke2という名前のキュー。このキューは、データベースのapply_spoke2適用プロセスに対するものです。
propagation_spoke1という名前の伝播。この伝播は、hrスキーマに対する変更をsource_hnsキューからspoke1.example.comデータベースのdestination_spoke1キューに送信します。
propagation_spoke2という名前の伝播。この伝播は、hrスキーマに対する変更をsource_hnsキューからspoke2.example.comデータベースのdestination_spoke2キューに送信します。
spoke1.example.comには、次の追加コンポーネントがあります。
apply_spoke1という名前の適用プロセス。この適用プロセスは、hub.example.comデータベースから送信されたhrスキーマに対する変更を適用します。
destination_spoke1_qtという名前のキュー表を使用するdestination_spoke1という名前のキュー。このキューは、データベースのapply_spoke1適用プロセスに対するものです。
propagation_spoke1という名前の伝播。この伝播は、hrスキーマに対する変更をsource_hnsキューからhub.example.comデータベースのdestination_spoke1キューに送信します。
spoke2.example.comには、次の追加コンポーネントがあります。
apply_spoke2という名前の適用プロセス。この適用プロセスは、hub.example.comデータベースから送信されたhrスキーマに対する変更を適用します。
destination_spoke2_qtという名前のキュー表を使用するdestination_spoke2という名前のキュー。このキューは、データベースのapply_spoke2適用プロセスに対するものです。
propagation_spoke2という名前の伝播。この伝播は、hrスキーマに対する変更をsource_hnsキューからhub.example.comデータベースのdestination_spoke2キューに送信します。
レプリケーション環境で変更の循環を回避する方法の詳細は、「変更の循環を回避するためのタグの概要」および『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。
hrスキーマの任意の表に対して行います。
参照:
MAINTAIN_SCHEMASプロシージャの使用方法の詳細は、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。
MAINTAIN_SCHEMASプロシージャの詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。
この項の例では、hrスキーマにある2つの表に、データ操作言語(DML)変更をレプリケートするOracle Streamsレプリケーション環境を構成します。この例では、各データベースで同期取得を使用して変更を取得します。この例では、Oracle Streamsレプリケーション環境で、データベースのグローバル名にsync1.example.comおよびsync2.example.comを使用します。ただし、例を完了するために、ご使用の環境の2つのデータベースに置き換えることもできます。2データベース・レプリケーション環境の詳細は、「2データベース・レプリケーション環境の概要」を参照してください。
具体的に、この例では、sync1.example.comおよびsync2.example.comデータベースでhr.employeesおよびhr.departments表を共有するOracle Streamsの2データベース・レプリケーション環境を構成します。2つのデータベースは、すべてのDML変更をこれらの表にレプリケートします。hrサンプル・スキーマは、Oracle Databaseに付属してデフォルトでインストールされます。
図4-14に、この例で作成する環境の概要を示します。
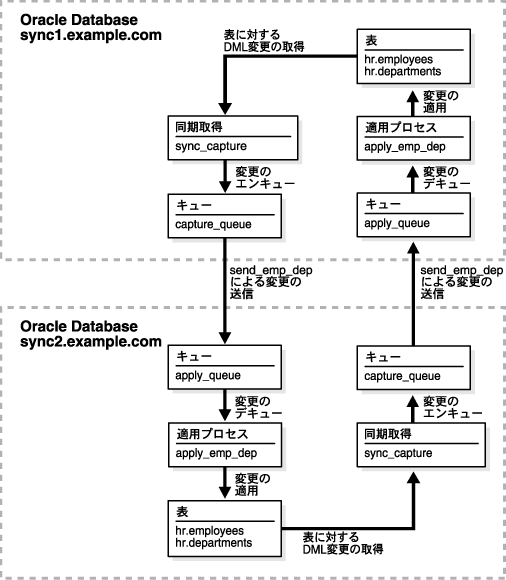
strmadminであると想定します。
hr.employeesおよびhr.departments表が2つのデータベースに存在し、これらのデータベースで一貫していることを確認します。データベース・オブジェクトが1つのデータベースにのみ存在する場合は、エクスポート/インポートを使用してこれらを他のデータベースで作成および移入できます。エクスポート/インポートの詳細は、『Oracle Databaseユーティリティ』を参照してください。
ANYDATAキューを作成します。この例では、各データベースに次の2つのキューを作成します。
strmadminが所有する、capture_queueという名前のキュー。このキューはデータベースでの同期取得によって使用されます。
strmadminが所有する、apply_queueという名前のキュー。このキューはデータベースでの適用プロセスによって使用されます。
方法については、「ANYDATAキューの作成」を参照してください。
sync1.example.comデータベースからsync2.example.comデータベースに、データベース・リンクを作成します。データベース・リンクは、Oracle Streams管理者のスキーマに作成する必要があります。また、データベース・リンクはsync2.example.comデータベースでOracle Streams管理者に接続する必要があります。データベース・リンクの名前およびサービス名は、どちらもsync2.example.comである必要があります。
sync2.example.comデータベースからsync1.example.comデータベースに、データベース・リンクを作成します。データベース・リンクは、Oracle Streams管理者のスキーマに作成する必要があります。また、データベース・リンクはsync1.example.comデータベースでOracle Streams管理者に接続する必要があります。データベース・リンクの名前およびサービス名は、どちらもsync1.example.comである必要があります。
方法については、「チュートリアル: データベース・リンクの作成」を参照してください。
sync1.example.comデータベースで適用プロセスを構成します。この適用プロセスは、sync2.example.comデータベースで取得され、sync1.example.comデータベースに伝播された共有表への変更を適用します。
sync1.example.comデータベースにOracle Streams管理者として接続します。SQL*Plusの起動の詳細は、『Oracle Database 2日でデータベース管理者』を参照してください。
BEGIN DBMS_APPLY_ADM.CREATE_APPLY( queue_name => 'strmadmin.apply_queue', apply_name => 'apply_emp_dep', apply_captured => FALSE); END; /
適用プロセスは永続キュー内の変更を適用するため、apply_capturedパラメータがFALSEに設定されます。これらは、同期取得によって取得された変更です。apply_capturedパラメータは、適用プロセスが取得プロセスによって取得された変更を適用する場合にのみTRUEに設定する必要があります。
適用プロセスは起動しないでください。
BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.employees', streams_type => 'apply', streams_name => 'apply_emp_dep', queue_name => 'strmadmin.apply_queue', source_database => 'sync2.example.com'); END; /
このルールは、apply_queueキューに出現するhr.employees表に対するすべてのDML変更を適用するよう適用プロセスapply_emp_depに指示します。ルールは、適用プロセスがsync2.example.comソース・データベースで取得された変更のみ適用することも指定します。
BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.departments', streams_type => 'apply', streams_name => 'apply_emp_dep', queue_name => 'strmadmin.apply_queue', source_database => 'sync2.example.com'); END; /
このルールは、apply_queueキューに出現するhr.departments表に対するすべてのDML変更を適用するよう適用プロセスapply_emp_depに指示します。ルールは、適用プロセスがsync2.example.comソース・データベースで取得された変更のみ適用することも指定します。
sync2.example.comデータベースで適用プロセスを構成します。この適用プロセスは、sync1.example.comデータベースで取得され、sync2.example.comデータベースに伝播された変更を適用します。
sync2.example.comデータベースにOracle Streams管理者として接続します。SQL*Plusでのデータベースへの接続の詳細は、『Oracle Database管理者ガイド』を参照してください。
BEGIN DBMS_APPLY_ADM.CREATE_APPLY( queue_name => 'strmadmin.apply_queue', apply_name => 'apply_emp_dep', apply_captured => FALSE); END; /
適用プロセスは永続キュー内の変更を適用するため、apply_capturedパラメータがFALSEに設定されます。これらの変更は、同期取得によって取得されました。apply_capturedパラメータは、適用プロセスが取得プロセスによって取得された変更を適用する場合にのみTRUEに設定する必要があります。
適用プロセスは起動しないでください。
BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.employees', streams_type => 'apply', streams_name => 'apply_emp_dep', queue_name => 'strmadmin.apply_queue', source_database => 'sync1.example.com'); END; /
このルールは、apply_queueキューに出現するすべてのDML変更をhr.employees表に適用するよう適用プロセスapply_emp_depに指示します。ルールは、適用プロセスがsync1.example.comソース・データベースで取得された変更のみ適用することも指定します。
BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.departments', streams_type => 'apply', streams_name => 'apply_emp_dep', queue_name => 'strmadmin.apply_queue', source_database => 'sync1.example.com'); END; /
このルールは、apply_queueキューに出現するすべてのDML変更をhr.departments表に適用するよう適用プロセスapply_emp_depに指示します。ルールは、適用プロセスがsync1.example.comソース・データベースで取得された変更のみ適用することも指定します。
sync1.example.comデータベースのキューからsync2.example.comデータベースのキューに変更を送信する伝播を作成します。
sync1.example.comデータベースにOracle Streams管理者として接続します。
sync2.example.comデータベースに対する変更を送信する伝播の作成を作成します。
BEGIN DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES( table_name => 'hr.employees', streams_name => 'send_emp_dep', source_queue_name => 'strmadmin.capture_queue', destination_queue_name => 'strmadmin.apply_queue@sync2.example.com', source_database => 'sync1.example.com', queue_to_queue => TRUE); END; /
ADD_TABLE_PROPAGATION_RULESプロシージャは、伝播およびポジティブ・ルール・セットを作成します。このプロシージャは、sync2.example.comデータベース内のapply_queueキューのhr.employees表にDML変更を送信するよう指示する伝播ルール・セットにルールの追加もします。
BEGIN DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES( table_name => 'hr.departments', streams_name => 'send_emp_dep', source_queue_name => 'strmadmin.capture_queue', destination_queue_name => 'strmadmin.apply_queue@sync2.example.com', source_database => 'sync1.example.com', queue_to_queue => TRUE); END; /
ADD_TABLE_PROPAGATION_RULESプロシージャは、sync2.example.comデータベース内のapply_queueキューのhr.departments表にDML変更を送信するよう指示する伝播ルール・セットにルールを追加します。
sync2.example.comデータベースのキューからsync1.example.comデータベースのキューに変更を送信する伝播を作成します。
sync2.example.comデータベースにOracle Streams管理者として接続します。
sync1.example.comデータベースに対する変更を送信する伝播の作成を作成します。
BEGIN DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES( table_name => 'hr.employees', streams_name => 'send_emp_dep', source_queue_name => 'strmadmin.capture_queue', destination_queue_name => 'strmadmin.apply_queue@sync1.example.com', source_database => 'sync2.example.com', queue_to_queue => TRUE); END; /
ADD_TABLE_PROPAGATION_RULESプロシージャは、伝播およびポジティブ・ルール・セットを作成します。このプロシージャでは、sync1.example.comデータベース内のapply_queueキューのhr.employees表にDML変更を送信するよう指示する伝播ルール・セットにルールを追加します。
BEGIN DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES( table_name => 'hr.departments', streams_name => 'send_emp_dep', source_queue_name => 'strmadmin.capture_queue', destination_queue_name => 'strmadmin.apply_queue@sync1.example.com', source_database => 'sync2.example.com', queue_to_queue => TRUE); END; /
ADD_TABLE_PROPAGATION_RULESプロシージャは、sync1.example.comデータベース内のapply_queueキューのhr.departments表にDML変更を送信するよう指示する伝播ルール・セットにルールを追加します。
sync1.example.comデータベースで同期取得を構成します。
sync1.example.comデータベースにOracle Streams管理者として接続します。
ADD_TABLE_RULESプロシージャを実行して、同期取得を作成し、hr.employees表に対する変更を取得するよう指示するルールを追加します。
BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.employees', streams_type => 'sync_capture', streams_name => 'sync_capture', queue_name => 'strmadmin.capture_queue'); END; /
BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.departments', streams_type => 'sync_capture', streams_name => 'sync_capture', queue_name => 'strmadmin.capture_queue'); END; /
これらのプロシージャを実行して次のアクションを実行します。
sync_captureという名前の同期取得を作成します。同じ名前の同期取得は存在できません。
strmadminが所有するcapture_queueという名前の既存のキューで同期取得を関連付けます。
sync_captureのポジティブ・ルール・セットを作成します。ルール・セットにはシステムで作成された名前があります。
hr.employees表に対するDML変更を取得するルールを作成し、同期取得のポジティブ・ルール・セットにルールを追加します。ルールにはシステムで生成された名前があります。
DBMS_CAPTURE_ADM.PREPARE_SYNC_INSTANTIATIONファンクションを自動的に実行することで、インスタンス化用にhr.employees表を準備します。
hr.departments表に対するDML変更を取得するルールを取得するルールを作成し、同期取得のポジティブ・ルール・セットにルールを追加します。ルールにはシステムで生成された名前があります。
DBMS_CAPTURE_ADM.PREPARE_SYNC_INSTANTIATIONファンクションを自動的に実行することで、インスタンス化用にhr.departments表を準備します。
sync2.example.comデータベースで同期取得を構成します。
sync2.example.comデータベースにOracle Streams管理者として接続します。
ADD_TABLE_RULESプロシージャを実行して、同期取得を作成し、hr.employees表に対する変更を取得するよう指示するルールを追加します。
BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.employees', streams_type => 'sync_capture', streams_name => 'sync_capture', queue_name => 'strmadmin.capture_queue'); END; /
BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.departments', streams_type => 'sync_capture', streams_name => 'sync_capture', queue_name => 'strmadmin.capture_queue'); END; /
手順8では、これらのプロシージャによって現在のデータベースで実行されるアクションについて説明します。
sync2.example.comデータベースで表のインスタンス化SCNを設定します。
sync1.example.comデータベースにOracle Streams管理者として接続します。
sync2.example.comデータベースでhr.employees表のインスタンス化SCNを設定します。
DECLARE iscn NUMBER; -- Variable to hold instantiation SCN value BEGIN iscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER(); DBMS_APPLY_ADM.SET_TABLE_INSTANTIATION_SCN@sync2.example.com( source_object_name => 'hr.employees', source_database_name => 'sync1.example.com', instantiation_scn => iscn); END; /
sync2.example.comデータベースでhr.departments表のインスタンス化SCNを設定します。
DECLARE iscn NUMBER; -- Variable to hold instantiation SCN value BEGIN iscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER(); DBMS_APPLY_ADM.SET_TABLE_INSTANTIATION_SCN@sync2.example.com( source_object_name => 'hr.departments', source_database_name => 'sync1.example.com', instantiation_scn => iscn); END; /
インスタンス化SCNは、適用プロセスが表に変更を適用できる最小のSCNです。適用プロセスがsync2.example.comデータベースの共有表への変更を適用する前に、インスタンス化SCNを各表に対して設定する必要があります。
sync1.example.comデータベースで表のインスタンス化SCNを設定します。
sync2.example.comデータベースにOracle Streams管理者として接続します。
sync1.example.comデータベースでhr.employees表のインスタンス化SCNを設定します。
DECLARE iscn NUMBER; -- Variable to hold instantiation SCN value BEGIN iscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER(); DBMS_APPLY_ADM.SET_TABLE_INSTANTIATION_SCN@sync1.example.com( source_object_name => 'hr.employees', source_database_name => 'sync2.example.com', instantiation_scn => iscn); END; /
sync2.example.comデータベースでhr.departments表のインスタンス化SCNを設定します。
DECLARE iscn NUMBER; -- Variable to hold instantiation SCN value BEGIN iscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER(); DBMS_APPLY_ADM.SET_TABLE_INSTANTIATION_SCN@sync1.example.com( source_object_name => 'hr.departments', source_database_name => 'sync2.example.com', instantiation_scn => iscn); END; /
sync1.example.comデータベースにOracle Streams管理者として接続します。
BEGIN DBMS_APPLY_ADM.START_APPLY( apply_name => 'apply_emp_dep'); END; /
sync2.example.comデータベースにOracle Streams管理者として接続します。
BEGIN DBMS_APPLY_ADM.START_APPLY( apply_name => 'apply_emp_dep'); END; /
適用プロセスの開始にEnterprise Managerを使用する方法については、「適用プロセスの起動と停止」を参照してください。
sync1.example.comおよびsync2.example.comの各データベースのhr.departmentsおよびhr.employeesの各表に対して、最新時刻競合解消を構成します。方法については、「チュートリアル: 表の最新時刻競合解消の構成」を参照してください。
次のような特性を持つ2データベース・レプリケーション環境が構成されます。
sync_captureという名前の同期取得があります。この同期取得は、hr.employees表およびhr.departments表に対するすべてのDML変更を取得します。
capture_queueという名前のキューがあります。このキューは、データベースでの同期取得用です。
apply_emp_depという名前の適用プロセスがあります。この適用プロセスは、hr.employees表およびhr.departments表に対するすべてのDML変更を適用します。
apply_queueという名前のキューがあります。このキューは、データベースでの適用プロセス用です。
send_emp_depという名前の伝播があります。この伝播は、ローカル・データベース内のcapture_queueから、他のデータベース内のapply_queueに変更を送信します。この伝播では、hr.employees表およびhr.departments表に対するすべてのDML変更が送信されます。
'00'(ゼロが2つ)と等価の16進数になります。
NULLタグを含むセッションの変更のみを取得します。したがって、同期取得は、ローカル適用プロセスによって適用される変更は取得しません。同期取得のルールは、これらの変更を取得しないよう同期取得に指示します。
レプリケーション環境で変更の循環を回避する方法の詳細は、「変更の循環を回避するためのタグの概要」を参照してください。
hr.employees表またはhr.departments表に対してDML変更を行います。
hr.employees表またはhr.departments表を問い合せて変更を表示します。レプリケーション環境では、競合解消によって競合が自動的に解消されます。競合解消の詳細は、「競合と競合解消の概要」を参照してください。
更新競合を解消する最も一般的な方法は、最新のタイムスタンプを持つ変更を保持し、古い変更を破棄することです。この方法では、適用中に競合が検出された場合、適用プロセスは、変更のタイムスタンプ列が表の対応する行よりも新しい場合に変更を適用します。表のタイムスタンプ列が最新の場合、適用プロセスは変更を破棄します。
この項の例では、次のアクションを完了することにより、hr.departments表の最新時刻競合解消を構成します。
TIMESTAMP WITH TIME ZONEデータ型のtime列を表に追加する
DBMS_APPLY_ADMパッケージのSET_UPDATE_CONFLICT_HANDLERプロシージャを実行して、表の競合解消を構成する
この項の手順を使用して、任意の表の競合解消を構成できます。これを構成するには、hrをスキーマ名で置換し、departmentsを表名で置換します。また、SET_UPDATE_CONFLICT_HANDLERプロシージャを実行するときに、hr.departments表の列を、使用する表の列で置換します。
time列を追加します。
SYSTEMなどの管理ユーザーとしてデータベースに接続します。別の方法として、時間列が追加される表を所有しているユーザーとして接続することもできます。SQL*Plusの起動の詳細は、『Oracle Database 2日でデータベース管理者』を参照してください。
ALTER TABLEを使用して、表にtime列を追加します。この例では、次の文を実行してtime列をhr.departments表に追加します。
ALTER TABLE hr.departments ADD (time TIMESTAMP WITH TIME ZONE);
time列を更新します。SYSTEMまたはOracle Streams管理者などの管理者ユーザーとしてデータベースにログインします。
「トリガーの作成」ページが表示され、「一般」サブページが表示されます。

insert_departments_timeを入力します。
hrと入力します。
BEGIN -- Consider time synchronization problems. The previous update to this -- row might have originated from a site with a clock time ahead of -- the local clock time. IF :OLD.TIME IS NULL OR :OLD.TIME < SYSTIMESTAMP THEN :NEW.TIME := SYSTIMESTAMP; ELSE :NEW.TIME := :OLD.TIME + 1 / 86400; END IF; END;
schema.tableの形式で表名を入力するか、懐中電灯アイコンを使用してデータベース・オブジェクトを検索します。この例では、hr.departmentsを入力します。
表内の列が表示されます。
time列を除く表のすべての列を選択します。
SQL*Plusの起動の詳細は、『Oracle Database 2日でデータベース管理者』を参照してください。
ALTER TABLE hr.departments ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
サプリメンタル・ロギングは、適用中の競合解消に必要です。
SET_UPDATE_CONFLICT_HANDLERプロシージャを実行して、表の最新時刻競合解消を構成します。たとえば、次のプロシージャを実行して、hr.departments表の最新時刻競合解消を構成します。
DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'department_id'; cols(2) := 'department_name'; cols(3) := 'manager_id'; cols(4) := 'location_id'; cols(5) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.departments', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; /
cols列リストの表内のすべての列を含みます。
レプリケーション環境を構成または拡張する例を実行している場合は、適切な表に対して最新時刻競合解消を構成します。
db1.example.comおよびdb2.example.comデータベースでhrスキーマのすべての表に対して競合解消を構成します。このスキーマには、countries、departments、employees、jobs、 job_history、locationsおよびregions表が含まれます。
hub1.example.com、spoke1.example.com、spoke2.example.comの各データベースでhrスキーマ内のすべての表に対して競合解消を構成します。このスキーマには、countries、departments、employees、jobs、job_history、locationsおよびregions表が含まれます。
sync1.example.comおよびsync2.example.comデータベースでhr.departmentsおよびhr.employees表に対して競合解消を構成します。
hub.example.com、spoke1.example.comおよびspoke2.example.comデータベースでoe.ordersおよびoe.order_items表に対して競合解消を構成します。
spoke3.example.comデータベースでhrスキーマのすべての表に対して競合解消を構成します。このスキーマには、countries、departments、employees、jobs、 job_history、locationsおよびregions表が含まれます。
例からこの項に移動した場合は、ここでその例に戻ります。
|
 Copyright © 2007, 2008 Oracle Corporation. All Rights Reserved. |
|