| Oracle® Warehouse Builder概要 11gリリース2 (11.2) B61348-03 |
|


 前 |
 次 |
ここでは、データ品質管理およびデータ・プロファイリングについて説明します。データ品質管理を使用すると、Oracle Warehouse Builderによる一貫性のある信頼性が高いデータ品質が実現します。データ・プロファイリングは、組織が情報の品質を向上させ、より適切な決定を下すための最初のステップです。
この項は次のトピックで構成されています。
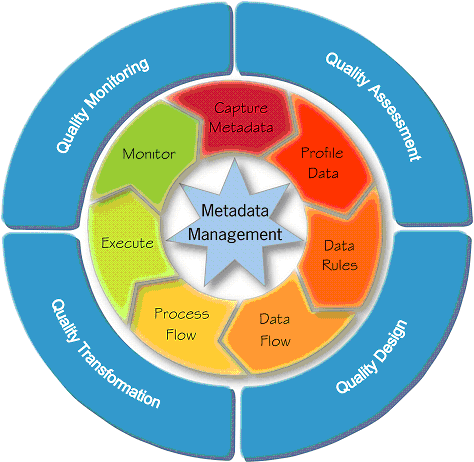
Oracle Warehouse Builderには、高品質な情報をビジネス・ユーザーに提供するデータ・システムの作成を支援する一連の機能が用意されています。Oracle Warehouse Builderを使用すると、データ品質を評価、設計、変換および監視するプロセスを実装できます。データ・ウェアハウスを構築する目的は、ビジネス上の意思決定を行うために必要な、統合かつ一元化されたデータを確保することです。通常、データは複数の異なるシステムから取得されるため、データ・ウェアハウスにロードされる前にデータが標準化およびクレンジングされていることが重要です。
Oracle Warehouse Builderを使用してデータを管理する利点は次のとおりです。
エンドツーエンドのデータ品質ソリューションを提供できます。
データ統合プロセスの構成部分として、データ品質およびデータ・プロファイリングを含めることができます。
データ定義とともにデータの品質に関するメタデータを格納できます。
データ修正に使用できるマッピングが自動生成されます。このマッピングは、データに適用するビジネス・ルール、およびデータの修正方法に関する決定に基づいています。
データ品質プロセスを実装および使用するフェーズを次に示します。
データ品質の確保には、次のフェーズが含まれます。
図8-1に、ビジネス・ユーザーへの高品質の情報の提供に関連するフェーズを示します。
品質評価フェーズでは、ソース・データの品質を判断します。このフェーズの最初のステップは、ソース・データ(複数の異なるソースに格納されている場合もあります)をOracle Warehouse Builderにインポートすることです。メタデータとデータは、OracleおよびOracle以外のソースからインポートできます。
ソース・データをロードした後に、データ・プロファイリングを使用してデータの品質を評価します。データ・プロファイリングとは、データ内の内容、構造および関係を分析して、データの変則、非一貫性および冗長性を検出するプロセスです。この分析とデータ検出の技術は、データ監視の基礎になります。データ・プロファイリングの概要は、「データ・プロファイリング: データ品質の評価」を参照してください。
品質設計フェーズは、品質プロセスの設計で構成されています。データ・ルールを使用してデータ・オブジェクト内に正当なデータを指定するか、またはデータ・オブジェクト間の正当な関係を指定できます。データ・ルールの詳細は、「データ・ルール: データ品質の適用」を参照してください。
品質設計フェーズの一部として、データ品質を確保するための変換も設計します。この変換は、データ・プロファイリングの結果としてOracle Warehouse Builderで生成されたマッピング、またはユーザーが作成したマッピングの場合があります。品質変換フェーズでは、ソース・データの修正用に設計した修正マッピングを実行します。
データ監視とは、ウェアハウスのデータを何時間にもわたって検証し、データ用のビジネス・ルール・セットにデータが違反する場合に警告するプロセスです。データ監視の詳細は、「データ監査: データ品質の監視」を参照してください。
データ統合シナリオおよびシステムに使用する前に、データ・プロファイリングを使用してソース・データの品質を評価できます。Oracle Warehouse Builderには、データ・プロファイルの作成をガイドするデータ・プロファイル・ウィザードと、データ・プロファイルを構成および管理するデータ・プロファイル・エディタがあります。データ・プロファイリングは、Oracle Warehouse BuilderのETL機能、および他のデータ品質機能(データ・ルール、組込みのクレンジング・アルゴリズムなど)と統合されているため、データ・クレンジング・マッピングおよびスキーマ修正スクリプトも生成できます。これによって、データおよびメタデータの非一貫性、冗長性および不正確さを自動的に修正できます。
データ・プロファイリングを使用すると、データに関する多くの重要な内容を検出できます。次に、一般的な検出内容を示します。
有効な製品コードのドメイン
製品割引の範囲
電子メール・アドレスのパターンを保持している列
列間の1対多関係
列内の変則および異常
表間の関係(関係がデータベースに記述されていない場合も含む)
データ・プロファイリング・プロセスを開始するには、最初にデータ・プロファイル・ウィザードを使用してデザイン・センター内からデータ・プロファイルを作成します。次に、データ・プロファイル・エディタを使用して、データ・プロファイルに含まれるオブジェクトのデータ・プロファイリングを実行し、修正表およびマッピングを作成します。
|
関連項目: 『Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイド』の次のトピック:
|
データ・ルールは、表内の正当なデータ、または表間の正当な関係を判断する有効なデータ値と関係の定義です。データ・ルールは、表、ビュー、ディメンション、キューブ、マテリアライズド・ビューおよび外部表に適用できます。データ・ルールは、データ・プロファイリング、データやスキーマのクレンジング、データ監査など多くの場合に使用されます。
データ・ルールのメタデータは、ワークスペースに格納されます。データ・ルールを使用するには、データ・ルールをデータ・オブジェクトに適用します。たとえば、有効値が'm'と'f'であることを指定するgender_ruleというデータ・ルールを作成したとします。このデータ・ルールは、Employees表のemp_gender列に適用できます。データ・ルールを適用することによって、emp_gender列に格納される値が'M'または'F'のいずれかであることが保証されます。データ・ルール・バインディングの詳細は、Employees表のデータ・オブジェクト・エディタの「データ・ルール」タブで表示できます。
データ・ルールをデータ・プロファイリングの結果から導出できます。また、データ・ルール・ウィザードまたはOMB*Plusスクリプト・コマンドを使用してデータ・ルールを作成できます。
|
関連項目: 『Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイド』の次のトピック:
|
Oracle Warehouse Builderでは、カスタムのデータ監査(一連のデータ・ルールに対してデータを検証し、レコードがルールに準拠しているかどうかを判別するプロセス)を作成できます。データ監査では、監査データに対してエラーがいくつ発生しているかを監査し、マークすることで、システム内のデータがどの程度ルールに準拠しているかを示す統計メトリックを収集します。監視プロセスは、データ・プロファイリングとデータ品質の方針に基づきます。
ルールに準拠していないレコードの数が多すぎると、プロセス・フローがエラー・ストリームまたは通知ストリームに入ることがあるため、データ監査には、ロジックの作成を可能にするしきい値があります。プロセスでは、このしきい値に基づいてアクションを選択できます。また、監査結果を取得して、分析目的で保存できます。
データ監査は、デプロイして随時実行できますが、通常は、データ・ウェアハウスやERPシステムなどの運用環境において、データの品質を監視するために実行します。したがって、データ監査は、プロセス・フローに追加したりスケジュールすることができます。データ監査を実行すると、複数の出力値が設定されます。これらの出力値の1つが監査結果です。
また、データ監査には、エラー率やシックスシグマなどの実測値も設定されています。データ監査は、システムのユーザーが設定した標準以上のデータ品質レベルを確保するための非常に重要なツールです。また、データ監査は異常なデータの急激な増加を判断するのに役立ち、イベントを急激な増加に結び付けることができます。
|
関連項目: データ監査の使用手順は、『Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイド』の次のトピックを参照してください。
|
Oracle Warehouse Builderのデータ・プロファイリング機能を使用すると、次の作業を実行できます。
Oracle Warehouse Builderがアクセス可能なソースまたはソースの組合せからのデータをプロファイリングできます。
データ・プロファイリング結果を表形式またはグラフ形式で確認できます。
プロファイリング結果に関連する実際のデータにドリルダウンできます。
データ・プロファイリング結果に基づいて、データ・ルールを手動または自動で導出できます。
シックスシグマ評価などの品質指数を導出できます。
導入前に検証が必要なデータ・ルールをプロファイリングまたはテストできます。
|
関連項目: 詳細および手順は、『Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイド』のデータ・プロファイリングの実行に関する項を参照してください。 |
データ・オブジェクトを選択すると、プロファイリングおよび分析の対象とするデータの側面が決定されます。
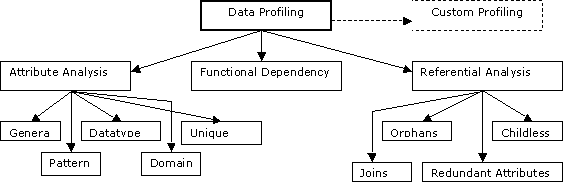
データ・プロファイリングには、次の主要なタイプの分析が用意されています。
図8-2は、データ・プロファイリングのタイプおよび各タイプの実行方法を示しています。
属性分析では、特定の列または属性内に格納されたデータの構造と内容に関して、一般情報と詳細情報の両方を調べます。
属性分析は、次の分析で構成されます。
パターン分析では、属性内に格納されたデータの文字列を分析して、レコードのパターンと共通タイプを検出します。この分析では、属性内に存在する多くの値と一致する正規表現をいくつか生成し、候補となる各正規表現に準拠するデータの割合を報告します。Oracle Warehouse Builderでは、日付、電子メール・アドレス、電話番号および社会保障番号など、一般の正規表現に準拠するデータを検索できます。
表8-1に、パターン分析で使用できるサンプル属性「ジョブ・コード」を示します。
表8-2は、このパターン分析の結果を示しています。ここで、Dは数値を表し、Xは文字を表します。この結果から、すべてのジョブ・コードを999-A-99の形式にすることが会社の方針であることが判明し、この属性のすべての値がこのパターンに準拠することを要求するデータ・ルールを導出できます。
ドメイン分析では、最も頻繁に発生する値を調べることによって、ドメイン、つまり属性内で共通して使用されている値を識別します。たとえば、顧客表の「婚姻」列をプロファイリングした結果、90%の値が「MARRIED」、「SINGLE」または「DIVORCED」のいずれかであることが判明したとします。さらに分析を進めてデータにドリルダウンしたところ、残りの10%は、わずかな例外を除いて、これらの語のスペルの間違いであることが判明しました。プロファイリングの構成によってドメインとして適格となる対象が決まるため、ドメイン値を受け入れる前に、構成を確認してください。その後、Oracle Warehouse Builderで、この属性に格納されるデータがドメインとして適格とされた3つの値のいずれかであることを要求するルールを導出できます。
データ型分析では、属性内のデータ型に関する情報を検出できます。このタイプの分析では、文字長の最大値と最小値、スケール、精度などのメトリックが判明します。たとえば、データベース列のデータ型はVARCHAR2ですが、この列の値がすべて数値である場合があります。この場合、ロード対象が数値のみであることを確認する必要があるとします。データ型分析を使用すると、Oracle Warehouse Builderで、属性内に格納されたすべてのデータが同じデータ型であることを要求するルールを導出できます。
一意キー分析では、属性が一意キーであるかどうかを判断するための情報が提供されます。そのために、この分析では、属性内で発生する個別値のパーセントを調べます。70%以上の個別値を持つ属性を一意キー分析の対象としてフラグを付けることもできます。たとえば、一意キー分析を使用して、EMP_ID列の95%の値が一意であることが判明したとします。さらに分析を進めると、残り5%のほとんどの値は重複かNULL値であることが判明しました。このことから、EMP_ID列に入力するすべてのエントリは一意の値でNULL値でないことを要求するルールを導出できます。
関数従属性分析では、列の関係に関する情報を調べます。この分析によって、オブジェクト内のある属性によって別の属性が決定される関係などを検出できます。
表8-3に、部門所在地という属性が部門番号という属性に依存する従業員表の内容を示します。Locationは属性Dept.Numberに依存します。属性Dept.Numberは属性Dept.Locationに依存しません。
参照分析では、他のオブジェクトを参照するデータ・オブジェクトの状態を調べます。このタイプの分析の目的は、プロファイリング対象のオブジェクトが他のオブジェクトとどのように関連または結合しているかを調べることです。このタイプの分析では2つのオブジェクトを比較するため、多くの場合、1つのオブジェクトを親オブジェクト、もう1つを子オブジェクトと呼びます。検出される一般的な状態として、親なしの子、子なしオブジェクト、冗長なオブジェクト、および結合があります。親なしの子とは、子オブジェクトにあるが、親オブジェクトにない値です。子なしオブジェクトとは、親オブジェクトにあるが、子オブジェクトにない値です。冗長な属性とは、親オブジェクトと子オブジェクトの両方に存在する値です。
表8-4および表8-5に、参照分析の対象となる2つの表の内容を示します。表8-4「従業員表(子)」は子オブジェクトで、表8-5「部門表(親)」は親オブジェクトです。
この2つのオブジェクトの参照分析では、Employees表からのNumber 15が親なしで、Department表からのDept.Number 18、20および55が子なしであることが判明します。また、Dept.Number列の結合も判明します。
これらの結果に基づいて、2つの表の間のカーディナリティを判断する参照ルールを導出できます。
Oracle Warehouse Builderには、属性分析、関数従属性分析および参照分析に加えて、データ・ルール・プロファイリングが用意されています。データ・ルール・プロファイリングを使用すると、オブジェクト内またはオブジェクト間のプロファイル・パラメータを検出するルールを作成できます。
これは強力な機能で、ビジネス・ユーザーが定義した、明らかに存在するルールを検証できます。データ・ルールを作成し、このルールでプロファイリングすることによって、データが実際にルールに準拠しているかどうか、ルールの修正やデータのクレンジングが必要かどうかを確認できます。
たとえば、人事部が表8-6に示す従業員表に対して、「収入=給与+ボーナス」というルールを定義したとします。これによって、従業員Alisonに見られるようなエラーを検出できます。
表8-6 サンプルの従業員表
| ID | 名前 | 給与 | ボーナス | 収入 |
|---|---|---|---|---|
|
10 |
Alison |
1000 |
50 |
1075(エラー) |
|
20 |
Rochnik |
1000 |
75 |
1075 |
|
30 |
Meijer |
300 |
35 |
335 |
|
40 |
Jones |
1200 |
500 |
1700 |
|
関連項目: 『Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイド』のデータ・ルールを使用したデータのクレンジングと修正に関する項。 |
Oracle Warehouse Builderには、データ品質に対する標準化された手法として、別のデータ・プロファイリング結果内に埋め込まれたシックスシグマ結果およびメトリックが用意されています。
|
関連項目: シックスシグマ結果の詳細は、『Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイド』の「データ・プロファイリングの実行」のプロファイル結果の表示に関する項を参照してください。 |
シックスシグマとは、ビジネス・プロセスにおける品質の概念を標準化するための方法です。この方法では、ビジネス・プロセスのパフォーマンスを統計的に分析します。シックスシグマの目的は、欠陥を識別して把握し、欠陥の発生要因を排除することによって、ビジネス・プロセスのパフォーマンスを向上させることです。
シックスシグマ・メトリックによって、1,000,000機会当たりの欠陥数が量的な数値として示されます。「機会」という用語は、レコード数と解釈できます。満点のスコアは6.0です。6.0というスコアは、1,000,000機会当たりの欠陥数が3.4の場合のみ達成できます。スコアは、次の計算式を使用して計算されます。
1,000,000機会当たりの欠陥数(DPMO)= (合計欠陥数 / 合計機会数) * 1,000,000
欠陥率(%)= (合計欠陥数 / 合計機会数)* 100%
歩留まり(%)= 100 - 欠陥率
シグマの生成= NORMSINV(1-(合計欠陥数 / 合計機会数)) + 1.5
NORMSINVは、標準正規累積分布の逆数です。
データ・プロファイリングを実行すると、検出された欠陥および変則の数がシックスシグマ・メトリックとして示されます。たとえば、データ・プロファイリングを実行して、最初の表と2番目の表の間に行関係があることが検出されたとします。この場合、最初の表でこの行関係に準拠しないレコードの数をシックスシグマ・メトリックを使用して示すことができます。
シックスシグマ・メトリックは、データ・プロファイル・エディタで次の方法で計算されます。
集計: 各列について、表内の合計行数(機会)に対するNULL値(欠陥)の数。
ドメイン: 各列について、表内の合計行数(機会)に対する、文書化されたドメインに準拠しない値(欠陥)の数。
参照: 各行関係について、表内の合計行数に対するリモート・キーに準拠しない値の数。
関数従属性: 各列について、表内の合計行数(機会)に対する、冗長な値(欠陥)の数。
一意キー: 各一意キーについて、表内の合計行数(機会)に対する、文書化された一意キーに準拠しない値(欠陥)の数。
Oracle Warehouse Builderでは、データ・プロファイリングの結果に基づいて、修正されたデータ・オブジェクトおよび修正マッピングを自動的に作成できます。データ品質のためにOracle Warehouse Builderの基礎となるアーキテクチャを利用する自動化された修正に加えて、独自のデータ品質マッピングを作成し、ソース・データを修正およびクレンジングできます。
|
関連項目: 『Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイド』のデータ・ルールを使用した自動データ修正の概要に関する項 |
データ・プロファイリングを実行すると、Oracle Warehouse Builderはプロファイリングを実行したオブジェクトに対して修正を生成します。次に、データ・プロファイリングの結果に基づいて、修正されたオブジェクトを作成するかどうかを決定できます。修正は、修正されたオブジェクトにバインド可能なデータ・ルールの形式を取ります。
|
関連項目: 『Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイド』のデータ・プロファイリング結果に基づいた修正の生成に関する項。 |
ソース・データに対しては次のタイプの修正を実行できます。
スキーマ修正ではスクリプトが作成され、これを使用して、適用したデータ・ルールで修正されたソース・データ・オブジェクトのセットを作成できます。修正されたデータ・オブジェクトは、データ・プロファイリングの結果から導出されたデータ・ルールに準拠します。
修正表には、接頭辞TMP__を持つ名前があります。たとえば、EMPLOYEES表をプロファイリングすると、修正表はTMP__EMPLOYEESという名前になります。
データ修正は、ソース・データを修正済データ・オブジェクトにロードする前にソース・データの変則および不整合を削除するための修正マッピングを作成するプロセスです。修正マッピングは、データ・オブジェクトに定義されているデータ・ルールを遵守します。プロファイル・ソース表内の劣化した古い表からデータを移動する際に、これらのマッピングにより、データ・ルールに準拠しないレコードが修正されます。
修正マッピングの名前は、接頭辞M_を持つオブジェクト名です。たとえば、EMPLOYEE表の修正マッピングはM_EMPLOYEEになります。
ソース・データに対してデータ修正を実行するには、次の情報を指定します。
|
関連項目: すべての手順は、『Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイド』のデータ・ルールを使用したデータのクレンジングと修正に関する項を参照してください。 |
データ修正アクション
Oracle Warehouse Builderでは、データ・プロファイリングの結果に基づいて、ソース・データのクレンジングに使用できるデータ・ルールのセットが導出されます。データ修正アクションを実行すると、これらのデータ・ルールに基づいた修正を自動的に生成できます。
データ・プロファイリングの結果として導出された各データ・ルールに対して、データ・ルール規定のために許容されないデータ値の処理方法を指定する修正アクションを選択する必要があります。次の修正アクションを選択できます。
無視: データ・ルールは無視されるため、このデータ・ルールに基づいて拒否される値はありません。
レポート: データ・ルールは、レポート作成専用にデータがロードされた後にのみ実行されます。「無視」オプションと同様ですが、データ・ルールに違反していた値を含むレポートが作成されます。このアクションは、一部のルール・タイプに対してのみ使用できます。
整備: このデータ・ルールで拒否された値はエラー表に移動され、そこでクレンジング方針が適用されます。このオプションを選択した場合は、クレンジング方針を指定する必要があります。
データ修正のクレンジング方針
データ・プロファイリングの結果に基づいて修正オブジェクトの自動生成を決定する場合は、ソースの不整合データを修正済オブジェクトに格納する前のクレンジング方法を指定する必要があります。この場合、修正オブジェクトに適用するデータ・ルールごとにクレンジング方針を指定します。データ・ルールに準拠しないレコードの格納にはエラー表を使用します。
使用するクレンジング方針は、データ・ルールのタイプとルール構成によって異なります。
|
関連項目: 『Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイド』の次のトピック:
|
Oracle Warehouse Builderには、データ重複除外機能を含む、データ型に適用できる汎用のデータ一致およびマージ機能があります。照合により、同じ論理データを参照するレコードが判別されます。Oracle Warehouse Builderでは、レコードを比較するための様々な一致ルールが用意されています。一致ルールの範囲は、完全一致から、共通のデータ入力エラーを検出して修正できる高度なアルゴリズムまでおよびます。マージは、各列のマージした値を作成するために選択または定義されるマージ・ルールという存続ルールに基づいて、一致した複数のレコードを単一の標準レコードに一元化します。
|
関連項目: すべての手順は、『Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイド』の一致、マージおよび重複除外に関する項を参照してください。 |