| Sun ONE Application Server 7, Enterprise Edition 管理者ガイド |
第 20 章
高可用性データベースの管理この章では、SunTM Open Net Environment (Sun ONE) Application Server 7, Enterprise Edition での高可用性データデース (High Availability Database: HADB) について概説し、その設定と管理の方法について説明しています。この章で説明するタスクは、HADB の設定に関する手順全体に該当します。その概要を次の表にまとめています。
注
rsh または ssh が設定されていない場合、この章で説明する hadbm コマンドが機能しません。rsh または ssh の設定の詳細は、『Sun ONE Application Server インストールガイド』および「管理プロトコルの設定」を参照してください。
この章には次の節があります。
高可用性データベースについてこの節では、高可用性データベース (High-Availability Database: HADB) について説明します。HADB を使って、持続的な HTTPSession の情報を保存できます。この節には次の項目があります。
HADB のアーキテクチャ
高可用性とは、システム内でアップグレードのための計画された停止や、一部のハードウェアやソフトウェアの問題で、計画にない停止が発生しても、システム全体では各種のサービス提供を継続できるだけの、高い可用性を持つことを意味します。HADB は、単純なデータモデルおよび Always On (常時配信) テクノロジに基づいています。HADB は、高パフォーマンスが要求される企業のアプリケーションサーバー環境において、あらゆる種類のセッション状態を持続的に配信するための理想的なプラットフォームを提供します。
次の図は、4 つのアクティブなノードと 2 つのスペアノードを持つデータベースのアーキテクチャを示しています。ノード 0 とノード 1 はミラーノードのペアであり、ノード 2 とノード 3 も同様です。
図 20-1 HADB のアーキテクチャ
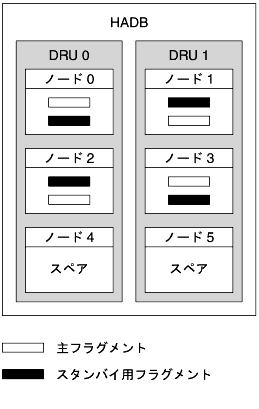
HADB では、データのフラグメント化とレプリケーションによって、高度なデータ可用性を実現します。データベース内のすべての表を分割することにより、フラグメントと呼ばれるほぼ同じサイズの複数のサブセットが作成されます。このフラグメント化のプロセスは、ハッシュ機能に基づいています。このハッシュ機能によって、データベースのノード間でデータがフラグメント化されて、均等に分散されます。各フラグメントは 2 回、つまりデータベースとミラーノードに保存されます。これにより、障害耐性が確立され、データをすばやく復旧することが可能になります。また、ノードに障害が発生した場合、またはノードが停止した場合には、そのノードが再びアクティブになるまでスペアノードが処理を引き継ぐことができます。
HADB ノードは 2 つのデータ冗長ユニット (Data Redundancy Units: DRU) で構成され、この 2 つの DRU は相互にミラーとして機能します。各 DRU は半分のアクティブなノード (2 つのノードのいずれか 1 つ) とスペアノードで構成され、各 DRU にはデータの完全なコピーが含まれます。障害耐性を確立するには、1 つの DRU をサポートする各コンピュータがそれぞれ独立して電源 (無停電電源装置の使用を推奨)、処理装置、およびストレージを完全にサポートしている必要があります。1 つの DRU で電源障害が発生した場合、電源が復旧するまでの間、ほかの DRU のノードで要求の処理を続行できます。
セッション持続のメカニズムを導入しないと、Web コンテナ間でフェイルオーバーが実行されたときに、HTTPSession の状態 (非活性化されたセッション状態を含む) が失われます。セッションの持続性を得るために HADB を使用すると、このような問題を解決できます。HADB では、個別の (ただし、密接に統合されている) 持続ストレージ層に状態の情報を保存して、取り出します。
HADB は、セッションデータが削除されたときに、不要になった領域を回収します。HADB では、セッションデータのレコードが固定サイズブロック内に格納されます。1 つのブロック内のすべてのレコードが削除されると、そのブロックは解放されます。ブロック内のレコードはランダムに削除できるので、ブロック内に「ホール」が発生します。新しいレコードがブロックに挿入されて、隣接する領域が必要になった場合に、このようなホールが削除され、結果としてブロックが圧縮されます。
ここでは、このアーキテクチャについて要約して説明しました。詳細は、『Sun ONE Application Server システム配備ガイド』を参照してください。
HADB ノード
データベースノードは、一連のプロセス、共有メモリの専用領域、および 1 つ以上の二次ストレージデバイスによって構成されます。セッションデータの保存と更新に使用されます。各ノードには 1 つのミラーノードが必要であるため、ノードはペアとして使用されます。また、可用性を最大化するために、各 DRU 内のノードに対して 2 つ以上のスペアノードを追加する必要があります。これにより、1 つのノードで障害が発生した場合、そのノードの修理中にスペアノードが処理を引き継ぐことができます。
ノードトポロジの選択肢の詳細は、『Sun ONE Application Server システム配備ガイド』を参照してください。ノードおよびその監視方法の詳細は、「ノードの状態」を参照してください。
hadbm コマンド
注
rsh または ssh が設定されていない場合、hadbm コマンドが機能しません。rsh または ssh の設定の詳細は、『Sun ONE Application Server インストールガイド』および「管理プロトコルの設定」を参照してください。
hadbm コマンドは、install_dir/SUNWhadb/4/bin ディレクトリに保存されています。HADB の管理に使うコマンドは、hadbm コマンドのサブコマンドです。一般的な構文は次のとおりです。
hadbm subcommand [-short-form [argument]]* [--long-form [argument]]* [dbname]
たとえば、hadbm status サブコマンドを次のように使うと、HADB の状態を確認できます。
hadbm status --nodes
サブコマンドによって、実行したい操作またはタスクが特定されます。サブコマンドでは、アルファベットの大文字と小文字が区別されます。
オプションについても、アルファベットの大文字と小文字が区別されます。各オプションには、長形式と短形式があります。短形式のオプションの前にはダッシュを 1 つ付けます (-)。長形式のオプションの前にはダッシュを 2 つ付けます (--)。オプションによって、hadbm コマンドによるサブコマンドの実行方法を変更できます。ほとんどのオプションでは、引数値が必要です。ただし、ブール型のオプションは機能のオンまたはオフを切り替えるために使用されるので、引数値を必要としません。コマンド行では、省略できるオプションをかっこ [ ] で囲んで表しています。
データベース名を使うサブコマンドでデータベースが指定されていない場合は、デフォルトのデータベースが使われます。デフォルトのデータベースは hadb です (すべて小文字)。
コマンド行でパスワードを入力する代わりに、サブコマンドのパスワードをファイルから設定できます。--dbpasswordfile オプションで、パスワードが記録されているファイルを指定します。このファイルの有効な形式は次のとおりです。
HADBM_DBPASSWORD=password
このファイル内の残りの部分は無視されます。--dbpassword オプションおよび --dbpasswordfile オプションの両方が指定されている場合は、--dbpassword が優先されます。パスワードが必要だが、コマンドで指定されていない場合は、パスワードの入力を求めるプロンプトが表示されます。
次の表に、hadbm の一般的なコマンドオプションを示します。これらのオプションはすべての hadbm サブコマンドで使うことができます。すべて、デフォルトでは使わないブール型オプションです。
HADB の設定この節では、次のような HADB の基本的な設定タスクについて説明します。
管理プロトコルの設定
データベースを作成する前に、HADB でリモート実行に rsh または ssh のどちらを使うかを決める必要があります。デフォルトは ssh なので、その代わりに rsh を使う必要がある場合にのみ、管理プロトコルの設定が必要になります。次の例のように、hadbm create コマンドの --set オプションを使います。
hadbm create --set managementProtocol=rsh --spares 2 --devicesize 1024 --dbpassword secret123 --hosts n1,n2,n3,n4,n5,n6
hadbm コマンドでは、データベースノードとの通信に rsh プロトコルまたは ssh プロトコルを使います。管理プロトコルは、データベースの操作には使われません。
データベースの作成
clsetup コマンドは、クラスタの初期化および設定の一部として HADB データベースを作成します。データベースの作成は、この方法で行うことをお勧めします。clsetup の詳細は、『Sun ONE Application Server インストールガイド』を参照してください。
ただし、clsetup 以外の方法でデータベースを作成することもできます。データベースを手動で作成するには、セッションデータを保存し、inetd を使わない場合にはデータベースを起動して、hadbm create コマンドを使います。構文は次のとおりです。
hadbm create [--installpath=path] [--historypath=path] [--devicepath=path] [--configpath=path] [--datadevices=devices-per-node] [--portbase=base-no] [--spares=sparecount] [--set=attr-name-value-list] [--inetd] [--inetdsetupdir=path] --devicesize=size --dbpassword=password | --dbpasswordfile=file --hosts=node-list [dbname]
次に例を示します。
hadbm create --spares 2 --devicesize 1024 --dbpassword secret123 --hosts n1,n2,n3,n4,n5,n6
データベースの作成で問題があった場合は、次の点を確認してください。
データベース作成のエラーは、Sun ONE Application Server のログファイルおよび HADB の履歴ファイルに書き込まれます。履歴ファイルの詳細は、「履歴ファイルのクリアとアーカイブ」を参照してください。データベースの作成で問題が残っている場合は、Sun のカスタマサポートにお問い合わせください。「HADB に関する Sun カスタマサポートへの問い合わせ」を参照してください。
次の表に、hadbm create コマンドのオプションを示します。
表 20-3 hadbm create のオプション
長形式
短形式
デフォルト値
説明
--installpath
-n
hadbm コマンドの場所
HADB システムのインストールパスを指定する。このパスは、既存のものである必要がある。このオプションは、HADB サーバーのインストールが管理クライアントのインストールとは異なる場所にある場合に使用する
--historypath
-t
/var/tmp
履歴ファイルへのパスを指定する。このパスは、既存のものである必要がある。履歴ファイルの詳細は、「履歴ファイルのクリアとアーカイブ」を参照
--devicepath
-d
/var/opt/SUNWhadb
データおよびログデバイスへのパスを指定する。このパスは、既存のものである必要がある
--configpath
-c
/etc/opt/SUNWhadb
HADB が内部で使用する設定ファイルへのパスを指定する。このパスは、既存のものである必要がある
--datadevices
-a
1
各ノードのデータデバイス数を 1 から 8 までで指定する
--portbase
-b
15200
ノード 0 で使うポートベース番号を指定する。ポートベース番号として、この番号から 20 ずつの連続するノードが自動的に割り当てられる。各ノードでは、それぞれのポートベース番号および後続の連続する 4 つの番号が付けられたポートを使う
同じマシンで複数のデータベースを実行する場合は、ポート番号の割り当ての計画を作成し、ポート番号を明示的に割り当てる必要がある
--spares
-s
0
スペアノード数を指定する。この数は偶数である必要があり、さらに --hosts オプションで指定したノード数より小さくする必要がある。スペアノードは省略可能だが、2 つ以上のスペアノードを使うと高可用性が得られる
--set
-S
なし
コンマで区切ったリストで、データベースの設定属性を指定する。データベースの有効な設定属性については、「設定属性の表示と修正」を参照
たとえば、ssh (デフォルト) の代わりに rsh を使うように指定するには、次のオプションを使用する
--set managementProtocol=rsh
--inetd
-I
指定なし
指定すると、データベースが inetd デーモンとともに実行され、作成後に自動的に起動しないように設定される。「inetd の追加手順」を参照
--inetdsetupdir
-u
現在のディレクトリ
inetd 設定ファイルを保存するディレクトリを指定する。このディレクトリは同じマシン上に存在し、書き込み可能である必要がある
--devicesize
-z
なし
ノードごとにデバイスのサイズを M バイト単位で指定する。デバイスのサイズは、可能な限り大きくする必要がある。このときの最大サイズは、オペレーティングシステムの最大ファイルサイズと同じ。最小サイズは、デフォルトの LogbufferSize (48M バイト) を基準にして、次の数式で導き出される
4 x LogbufferSize + 16M バイト = 208M バイト
「既存のノードへのストレージスペースの追加」で説明しているとおり、後でデバイスのサイズを拡張できる
LogbufferSize の設定の詳細は、「設定属性の表示と修正」を参照
--dbpassword
-p
なし
HADB システムユーザーのパスワードを作成する。パスワードは 8 文字以上にする必要がある。このオプションの代わりに、--dbpasswordfile を使用できる。詳細は、「hadbm コマンド」を参照
--dbpasswordfile
-P
なし
HADB システムユーザー向けに作成されるパスワードを保存するファイルを指定する。詳細は、「hadbm コマンド」を参照
--hosts
-H
なし
コンマで区切られたリストで、データベース内のノードのホスト名または IP アドレスを指定する。DNS 検索には依存していないため、IP アドレスの使用を推奨。ホスト名は絶対名である必要がある。ホスト名として、localhost または 127.0.0.1 を使うことはできない
リスト内の各項目に対して 1 つのノードが作成される。ノード数は偶数である必要がある。重複するホスト名を使用すると、同じホストに異なるポート番号の複数のノードが作成される
各ノードには、このオプションで指定した順序で 0 から番号が付けられる。最初のミラーペアはノード 0 とノード 1 になり、次のミラーペアはノード 2 とノード 3 になり、以後同様に続く。1 つの DRU には奇数のノードがあり、それ以外には偶数のノードがある。--spares を使用する場合、番号が最も大きいノードがスペアノードになる
dbname
なし
hadb
データベースの名前を指定する。この名前は一意である必要がある。データベース名を確実に一意にするには、hadbm list コマンドを使って既存のデータベース名を一覧表示する
複数のデータベースを作成する必要がある場合以外は、デフォルトのデータベース名を使用する。たとえば、HADB マシンの同一セットで、独立したデータベースを持つ複数のクラスタを作成する場合は、各クラスタで別個のデータベース名を使用する
inetd の追加手順
データベースの作成時に --inetd を指定していない場合、データベースは初期化されて、--installpath の場所から起動されます。この場所は、hadbm status コマンドを使って確認できます。
--inetd を指定している場合、データベースは存在しますが (hadbm list コマンドで確認可能) 実行中ではありません (hadbm status コマンドで確認可能)。
本稼働環境では inetd の使用をお勧めしますが、開発環境やテスト環境では通常その必要はありません。--inetd オプションを使ってデータベースを作成すると、inetd を使って、マシンの再起動時にそのマシン上の HADB ノードが自動的に再起動されるように設定できます。これによって、より堅牢な配備が可能になりますが、管理の面では短所もあります。
特に、ノードを停止して何らかのメンテナンスを実行する場合などに、次のタスクを実行する必要があります。
また、ノードを追加する場合は、新しいノードを考慮に入れて inetd 設定ファイルを更新するための手順を別途実行する必要があります。
注
ノードとそのミラーで同時に障害が発生した場合は、「HADB のクリア」で説明しているとおり、データベースをクリアする必要があります。このような障害は二重ノード障害と呼ばれ、この場合には inetd は役立ちません。
新しいデータベース、または新しいノードが追加されたデータベース向けに inetd を設定するには、次の手順に従います。
- inetd サポートのスタブファイルは、--inetdsetupdir オプションで指定したディレクトリに作成され、次のように名前が付けられます。
dbname.hostname.inetd.conf
dbname.hostname.services
すべてのスタブファイルは、hadbm create コマンドを入力するマシンのローカルに保存されます。さらに、ホスト名は hostname に付加される番号によって識別されます。
これらのファイルの内容を各ノードに対応するマシンの /etc/inetd.conf ファイルおよび /etc/services ファイルに追加して、inetd を次のように再設定します。
kill -HUP inetd-process-id
- 各マシンで inetd の再設定が終了すると、hadbm clear コマンドを使ってデータベースを初期化できる状態になります。「HADB のクリア」を参照してください。
- ノードを停止し、そのノードが再起動することを確認することで、inetd が機能していることを検証できます。「ノードの停止」および「HADB の状態の取得」を参照してください。
JDBC 接続プールの設定
Sun ONE Application Server が HADB と通信するときは、データを保存するリレーショナルデータベースとの通信時と同じ方法で通信します。したがって、ほかのデータベースの場合と同じように、HADB にも JDBC 接続プールを設定する必要があります。
Sun ONE Application Server 内の HADB に JDBC 接続プールおよび JDBC リソースを設定するときには、clsetup コマンドの使用をお勧めします。このコマンドについては、『Sun ONE Application Server インストールガイド』を参照してください。
次の節では、HADB に JDBC 接続プールと JDBC リソースを手動で設定する方法について、簡潔に要約します。
接続プールおよび JDBC リソースの全般的な情報については、「JDBC リソースについて」を参照してください。
JDBC URL の取得
JDBC 接続プールを設定する前に、hadbm get コマンドを次のように使って、HADB の JDBC URL を確認する必要があります。
hadbm get jdbcURL [dbname]
次に例を示します。
hadbm get jdbcURL
JDBC URL が、次のような形式で標準出力デバイスに表示されます。
jdbc:sun:hadb:host:port,host:port,...
次の節で説明するように、jdbc:sun:hadb: プレフィックスを削除し、serverList 接続プールのプロパティ値として host:port,host:port... の部分を使います。
接続プールの作成
次の表に、HADB に必要な接続プールの設定をまとめます。ノードを追加するときには、「Steady Pool Size (通常プールサイズ)」の設定のみを変更します。
次の表に、HADB に必要な接続プールのプロパティをまとめます。ノードを追加するときには「serverList」のプロパティのみを変更します。
表 20-5 HADB の接続プールのプロパティ
プロパティ
説明
username
asadmin create-session-store コマンドで指定される storeuser の名前を指定する。「アプリケーションサーバーインスタンスの可用性の有効化」を参照
password
asadmin create-session-store コマンドで指定される storepassword を指定する。「アプリケーションサーバーインスタンスの可用性の有効化」を参照
serverList
HADB の JDBC URL を指定する。この値の決定方法については、「JDBC URL の取得」を参照
データベースにノードを追加する場合は、この値を変更する必要がある。「HADB へのノードの追加」を参照
cacheDatabaseMetaData
必要に応じてこのプロパティを false に設定すると、Connection.getMetaData() の呼び出しによってデータベースが呼び出されるようになります。これにより、接続の有効性が確保されます。
eliminateRedundantEndTransaction
必要に応じてこのプロパティを true に設定すると、余計なコミットとロールバック要求を排除し、トランザクションが開いていない場合にはこのような要求を無視することにより、パフォーマンスが向上します。
接続プ―ルの例
ここでは、HADB JDBC 接続プールを作成する asadmin create-jdbc-connection-pool コマンドの例を示します。このコマンドの詳細は、『Sun ONE Application Server Developer's Guide to J2EE Services and APIs』を参照してください。
asadmin create-jdbc-connection-pool --user adminname --password secret --datasourceclassname com.sun.hadb.jdbc.ds.HadbDataSource --steadypoolsize=32 --isolationlevel=repeatable-read --isconnectvalidatereq=true --validationmethod=meta-data --property username=storename:password=secret456:serverList=host¥¥:port,host¥¥:port, host¥¥:port,host¥¥:port,host¥¥:port,host¥¥:port:cacheDatabaseMetaData=false:el iminateRedundantEndTransaction=true hadbpool
SolarisTM プラットフォームでは、プロパティ値の中にあるコロン (:) は二重の円記号 (¥¥) でエスケープする必要があります。そのようにしないと、プロパティの区切り記号として解釈されるためです。エスケープ文字の使用方法の詳細は、「エスケープ文字の使用」を参照してください。
JDBC リソースの作成
次の表に、HADB に必要な JDBC リソースの設定をまとめます。
表 20-6 HADB の JDBC リソースの設定
設定項目
説明
JNDI Name (JNDI 名)
次の JNDI 名が、セッション持続性の設定のデフォルトになる。jdbc/hastore。デフォルトの名前を使うことも、別の名前を使うことも可能
また、可用性サービスを有効化するときに、この JNDI 名を store-pool-jndi-name 持続性ストアのプロパティ値として指定する必要がある。「セッション持続性のデフォルト値」を参照
Pool Name (プール名)
この JDBC リソースで使用する HADB 接続プールの名前または ID をリストから選択する。詳細は、「接続プールの作成」を参照
Data Source Enabled (データソースを有効)
チェックマークを付ける/true
HADB の管理一般に、ネットワーク、ハードウェア、オペレーティングシステム、または HADB ソフトウェアの取り替えやアップグレードを行わない限り、管理操作は必要ありません。このような管理操作については、Sun のカスタマサポートにお問い合わせください。「HADB に関する Sun カスタマサポートへの問い合わせ」を参照してください。次の各節では、各種の管理操作について説明します。
ノードの起動
inetd を使ってノードを実行する場合には、ノードを起動する必要はありません。マシンが再起動すると、inetd によってノードが自動的に再起動するためです。
次のような場合に、ノードの起動が必要になることがあります。
ほとんどの場合、まず normal 起動レベルでノードの起動を試行する必要があります。次のような場合には、repair 起動レベルで試行する必要があります。
データベース内のノードを起動するには、hadbm startnode コマンドを使います。構文は次のとおりです。
hadbm startnode [--startlevel=level] node-number [dbname]
次に例を示します。
hadbm startnode 1
次の表に、hadbm startnode コマンドのオプションを示します。
ノードの停止
ホスト上でハードウェアやソフトウェアの交換が必要な場合には、ホストの停止が必要になり、同時に、ノードの停止が必要になる可能性があります。
注
目的のノードのミラーノードが実行中でない場合は、ノードを停止しないでください。そのようにすると、データベースが強制的に Non Operational (非運用) 状態に切り替えられる可能性があるためです。ノードの状態の詳細は、「HADB の状態の取得」を参照してください。
データベース内のノードを停止するには、hadbm stopnode コマンドを使います。構文は次のとおりです。
hadbm stopnode [--no-repair] node-number [dbname]
次に例を示します。
hadbm stopnode 1
注
inetd を設定している場合は、ノードが停止するとノードの監視プログラムが自動的に再起動します。この結果、ノードは再び実行状態に戻りますが、オフラインロールになります。
したがって、inetd を設定している場合は、ノードを停止するときに次のタスクを別途実行する必要があります。
1. 目的のノードの inetd エントリを inetd 設定ファイルから削除します。この削除を行わないと、ノードを停止してもただちに自動的に再起動します。
2. ノードを再起動した後、inetd ファイルにエントリを再び追加します。
詳細は、「inetd の追加手順」を参照してください。
次の表に、hadbm stopnode コマンドのオプションを示します。
ノードの再起動
ノードが通常以外の状態を示す(たとえば、CPU リソースが過大に消費されている)など、再起動によって問題が解決するか確認すべき場合には、ノードの再起動が必要になる可能性があります。
注
目的のノードのミラーノードが実行中でない場合は、ノードを再起動しないでください。そのようにすると、データベースが強制的に Non Operational (非運用) 状態に切り替えられる可能性があるためです。ノードの状態の詳細は、「HADB の状態の取得」を参照してください。
データが入っていないノードを補修しようとすると、その補修がハングアップすることがあります。このようなハングアップが発生する可能性があるのは、データベースを再フラグメント化する前、またはデータベースをクリアしてセッションストアを再作成する前に、repair レベルで新しいアクティブなノードの起動を試みた場合などです。
データベース内のノードを再起動するには、hadbm restartnode コマンドを使います。構文は次のとおりです。
hadbm restartnode [--startlevel=level] node-number [dbname]
次に例を示します。
hadbm restartnode 1
次の表に、hadbm restartnode コマンドのオプションを示します。
HADB の起動
データベースを起動するには、hadbm start コマンドを使います。構文は次のとおりです。
hadbm start [dbname]
次に例を示します。
hadbm start
デフォルトの dbname は hadb です (すべて小文字)。
このコマンドにより、データベースを停止する前の時点で実行中だったすべてのノードが起動します。データベースの停止後に再び起動するとき、個別に停止させた (オフラインの) ノードは起動しません。
HADB の停止
HADB の停止と起動をそれぞれ別個の操作で実行する場合、HADB の停止中にはそのデータを利用できません。データを利用可能な状態に保つために、「HADB の再起動」で説明するように HADB を再起動することもあります。
次のような場合に、ノードの停止が必要になることがあります。
- HADB データベースを削除する場合
- すべての HADB ノードに影響を及ぼすシステムメンテナンスを実行する場合
- データベースを再初期化するために hadbm clear コマンドを実行する前。「HADB のクリア」を参照
HADB を停止する前に、Sun ONE Application Server の従属インスタンスを停止するか、これらのインスタンスが別の従属性メソッドを使うように設定する必要があります。詳細は、第 18 章「セッション持続性の設定」を参照してください。
データベースを停止するには、hadbm stop コマンドを使います。構文は次のとおりです。
hadbm stop [dbname]
次に例を示します。
hadbm stop
デフォルトの dbname は hadb です (すべて小文字)。停止しようとするデータベースは、その状態が HA Fault Tolerant (HA 障害耐性)、Fault Tolerant (障害耐性)、Operational (運用)、Non-Operational (非運用) のいずれかである必要があります。データベースの状態の詳細は、「HADB の状態の取得」を参照してください。
データベースを停止すると、そのデータベースで実行中のすべてのノードが停止し、データベースの状態は Stopped (停止) になります。
HADB が自動的に再起動するように inetd を設定している場合は、次の手順を実行して HADB を停止させる必要があります。
HADB の再起動
HADB 内で不審な動作 (タイムアウトの整合性の問題など) が見られる場合に、再起動によって問題が解決するかどうかを確認するために、HADB を再起動することがあります。
HADB を再起動すると、データは利用可能な状態に保たれます。HADB の停止と起動をそれぞれ別個の操作で実行する場合、HADB の停止中にはそのデータを利用できません。hadbm set コマンドの実行に失敗した場合、HADB の再起動によって以前の設定が復元されます。hadbm set の詳細は、「設定属性の表示と修正」を参照してください。
データベースを再起動するには、hadbm restart コマンドを使います。構文は次のとおりです。
hadbm restart [--no-rolling] [dbname]
次に例を示します。
hadbm restart
デフォルトの dbname は hadb です (すべて小文字)。デフォルトでは、このコマンドによって、データベース内の各ノードが元の状態またはより適切な状態で再起動します。--no-rolling オプションまたは -g オプションを指定している場合は、このコマンドによって、サービスを中断せずにすべてのノードが同時に再起動します。
データベースの一覧表示
作成済みのすべてのデータベースを一覧表示するには、hadbm list コマンドを使います。構文は次のとおりです。
hadbm list
HADB のクリア
次のような場合、ノードのクリアが必要になる可能性があります。
- inetd を使うデータベースに対し、新しいノードを作成または追加する場合。「inetd の追加手順」を参照
- hadbm status コマンドの実行の結果、データベースが Non Operational (非運用) の状態であるか、複数のノードが待機状態であることが判明した場合。「HADB の状態の取得」を参照
- セッションデータの破損から復旧する場合。「セッションデータの破損からの復旧」を参照
データベースをクリアする前に、目的のデータベースを停止する必要があります。「HADB の停止」を参照してください。
hadbm clear コマンドによって、データベースのノードが停止し、データベースデバイスがクリアされ、ノードが再び起動します。構文は次のとおりです。
hadbm clear [--fast] [--spares=sparecount] --dbpassword=password | --dbpasswordfile=file [dbname]
次に例を示します。
hadbm clear --fast --spares=2 --dbpassword secret123
次の表に、hadbm clear コマンドのオプションを示します。
表 20-10 hadbm clear のオプション
長形式
短形式
デフォルト値
説明
--fast
-F
指定されていない
指定されている場合、データベースの初期化の際にデバイスの初期化を省略する。ディスクストレージデバイスが破損している場合、またはそのデータベースで inetd を使う場合は、このオプションを使わないこと
--spares
-s
0
再初期化後のデータベースで使うスペアノード数を指定する。この数は偶数である必要があり、さらにデータベース内のノード数より小さくする必要がある。スペアノードは省略可能だが、2 つ以上のスペアノードを使うと高可用性が得られる
--dbpassword
-p
なし
HADB システムのユーザーパスワードを指定する。このオプションの代わりに、--dbpasswordfile を使用できる。詳細は、「hadbm コマンド」を参照
--dbpasswordfile
-P
なし
HADB システムユーザーのパスワードを保存するファイルを指定する。詳細は、「hadbm コマンド」を参照
dbname
なし
hadb
データベース名を指定する
データベースの削除
削除するデータベースは、停止状態の既存のデータベースである必要があります。「HADB の停止」を参照してください。HADB システムから既存のデータベースを削除するには、hadbm delete コマンドを使います。構文は次のとおりです。
hadbm delete [dbname]
次に例を示します。
hadbm delete
デフォルトのデータベース名は hadb です (すべて小文字)。このコマンドを実行すると、データベースの設定ファイル、デバイスファイル、ログファイル、および履歴ファイルが削除され、共有メモリリソースが解放されます。
HADB の拡張HADB が十分なパフォーマンスを発揮していないためにシステム全体のパフォーマンスが制約を受けていると判断した場合には、HADB を拡張することによって、Sun ONE Application Server のクラスタや HADB を停止することなくスループットを向上させることができます。次の各節では、HADB を拡張する方法について説明します。
既存のノードへのストレージスペースの追加
次のような場合に、HADB にストレージスペースの追加が必要になることがあります。
- 空き容量のサイズが不十分であることが hadbm deviceinfo コマンドから報告された場合。「デバイスの情報の取得」を参照
次の hadbm set コマンドを使って、ノードごとにデバイスのサイズを M バイト単位で増加させることができます。
hadbm set TotalDatadeviceSizePerNode=size
次に例を示します。
hadbm set TotalDatadeviceSizePerNode=2048
オペレーティングシステムの最大ファイルサイズが、ここで許容される最大サイズになります。デバイスのサイズは、可能な限り大きくする必要があります。
FaultTolerant (障害耐性) 以上の状態のデータベースで TotalDatadeviceSizePerNode を変更すると、データが失われることなくシステムがアップグレードされ、再設定中はデータベースが Operational (運用) 状態に保たれます。FaultTolerant (障害耐性) より下位の状態のシステムでデバイスサイズを変更すると、データが失われます。データベースの状態の詳細は、「データベースの状態」を参照してください。
マシンの追加
HADB で処理や保存のための容量が不足した場合に、マシンの追加が必要になることがあります。ノードトポロジの選択肢の詳細は、『Sun ONE Application Server システム配備ガイド』を参照してください。
HADB を実行するための新しいマシンを追加するには、『Sun ONE Application Server インストールガイド』の説明に従って、Sun ONE Application Server とともに (または、これとは別個に) HADB パッケージをインストールします。
HADB へのノードの追加
新しいノードを作成して、これらをデータベースに追加すると、処理および保存のための容量が増加します。ノードを追加するには、hadbm addnodes コマンドを使います。構文は次のとおりです。
hadbm addnodes [--no-refragment] [--spares=sparecount] --dbpassword=password | --dbpasswordfile=file [--inetdsetupdir=path] --hosts=node-list [dbname]
次に例を示します。
hadbm addnodes --dbpassword secret123 --hosts n7,n8,n9,n10
ノードを追加した後、次のタスクを実行する必要があります。
詳細は、「JDBC 接続プールの設定」を参照してください。
注
--inetd を使ってデータベースを作成する場合は、次の操作を実行する必要があります。
- --no-refragment オプションを使い、hadbm refragment コマンドを使って独立した操作としてデータベースを再フラグメント化します。
- 追加する新しいノードを考慮に入れて inetd 設定ファイルを更新するための手順を別途実行します。詳細は、「inetd の追加手順」を参照してください。
次の表に、hadbm addnodes コマンドのオプションを示します。
表 20-11 hadbm addnodes のオプション
長形式
短形式
デフォルト値
説明
--no-refragment
-r
指定なし
指定されている場合、ノードの作成時にデータベースを再フラグメント化しない。データベースの再フラグメント化は、後で hadbm refragment コマンドを使って実行できる。再フラグメント化の詳細は、「HADB の再フラグメント化」を参照
--inetd を使うデータベースを作成する場合は、このオプションを使う必要がある。この場合、hadbm refragment を使って独立した手順としてデータベースを再フラグメント化する必要がある
データベースを再フラグメント化せずにノードを追加できる。「再フラグメント化を伴わないノードの追加」を参照
--spares
-s
0
新しいスペアノードの数を指定する。この数は偶数である必要があり、さらに追加されたノードの数より小さくする必要がある。スペアノードは省略可能だが、2 つ以上のスペアノードを使うと高可用性が得られる
--dbpassword
-p
なし
HADB システムのユーザーパスワードを指定する。このオプションの代わりに、--dbpasswordfile を使用できる。詳細は、「hadbm コマンド」を参照
--dbpasswordfile
-P
なし
HADB システムユーザーのパスワードを保存するファイルを指定する。詳細は、「hadbm コマンド」を参照
--inetdsetupdir
-u
現在のディレクトリ
inetd 設定ファイルを保存するディレクトリを指定する。このディレクトリは同じマシン上に存在し、書き込み可能である必要がある
--hosts
-H
なし
コンマで区切られたリストで、データベース内のノードの新しいホスト名を指定する。ホスト名の重複が許容されるため、重複するホスト名を使うと、同じホストに異なるポート番号の複数のノードが作成される。リスト内の各項目に対して 1 つのノードが作成される。ノード数は偶数である必要がある
dbname
なし
hadb
データベース名を指定する。データベースは、HA Fault Tolerant (HA 障害耐性) または Fault Tolerant (障害耐性) 状態である必要がある。データベースの状態の詳細は、「HADB の状態の取得」を参照してください。
HADB の再フラグメント化
新しいノードにデータを保存する前に、データベースを再フラグメント化する必要があります。再フラグメント化は、アクティブなすべてのノードに対してデータを均等に保存するために必要です。データベースを再フラグメント化するには、hadbm refragment コマンドを使います。構文は次のとおりです。
hadbm refragment --dbpassword=password | --dbpasswordfile=file [dbname]
次に例を示します。
hadbm refragment --dbpassword secret123
再フラグメント化を実行するには、ユーザーデータのサイズが、ユーザーデータに使用可能なディスク容量の 50% 未満である必要があります。詳細は、「デバイスの情報の取得」を参照してください。
このコマンドを何度か実行しても失敗する場合の対応については、「再フラグメント化を伴わないノードの追加」を参照してください。
次の表に、hadbm refragment コマンドのオプションを示します。
表 20-12 hadbm refragment のオプション
長形式
短形式
デフォルト値
説明
--dbpassword
-p
なし
HADB システムのユーザーパスワードを指定する。このオプションの代わりに、--dbpasswordfile を使用できる。詳細は、「hadbm コマンド」を参照
--dbpasswordfile
-P
なし
HADB システムユーザーのパスワードを保存するファイルを指定する。詳細は、「hadbm コマンド」を参照
dbname
なし
hadb
データベース名を指定する。データベースは、HA Fault Tolerant (HA 障害耐性) または Fault Tolerant (障害耐性) 状態である必要がある。データベースの状態の詳細は、「HADB の状態の取得」を参照
再フラグメント化を伴わないノードの追加
ノードの追加時にデータベースを再フラグメント化しない場合は、その代わりとしてデータベースをクリアし、セッションストアを再作成する必要があります。そのようにしないと、セッションストアが新しいノードを使えません。一般に、データベースを再フラグメント化せずにノードを追加することはお勧めできません。ただし、次の条件のすべてに該当する場合は、これが最適な選択肢になることもあります。
- 「既存のノードへのストレージスペースの追加」で説明しているように、各ノードを拡張できるだけの十分なディスク容量がない
- 「HADB の再フラグメント化」で説明しているように、ユーザーデータのサイズが、ユーザーデータに使用可能なディスク容量の 50% を超えている (この状態では再フラグメント化できない)
- セッション状態を非活性化していない
再フラグメント化せずにノードを追加するには、次のタスクを実行します。
- 各サーバーインスタンスについて、次のタスクを実行します。
- 「ロードバランサの設定ファイル」で説明しているとおり、ロードバランサでサーバーインスタンスを無効化します。
- 「アプリケーションサーバーインスタンスの可用性の有効化」で説明しているとおり、セッションの持続性を無効化します。
- サーバーインスタンスを再起動します。
- ロードバランサでサーバーインスタンスを再び有効化します。
可用性を保つ必要がない場合は、ロードバランサですべてのサーバーインスタンスを同時に無効化し、再び有効化できます。これによって時間を節約し、古いセッションデータがフェイルオーバーされることを防止します。
- 「HADB のクリア」で説明しているとおり、データベースをクリアします。
- 「JDBC 接続プールの設定」で説明しているとおり、JDBC 接続プールを再設定します。cladmin コマンドも使用できます。第 19 章「cladmin コマンドの使用」を参照してください。
- 「アプリケーションサーバーインスタンスの可用性の有効化」で説明しているとおり、セッションの持続性ストアを再読み込みします。cladmin コマンドも使用できます。
- 各サーバーインスタンスについて、次のタスクを実行します。
- ロードバランサでサーバーインスタンスを無効化します。
- 「アプリケーションサーバーインスタンスの可用性の有効化」で説明しているとおり、セッションの持続性を有効化します。
- サーバーインスタンスを再起動します。
- ロードバランサでサーバーインスタンスを再び有効化します。
可用性を保つ必要がない場合は、ロードバランサですべてのサーバーインスタンスを同時に無効化し、再び有効化できます。これによって時間を節約し、古いセッションデータがフェイルオーバーされることを防止します。
HADB の監視次のタスクを実行することにより、HADB 内のアクティビティを監視できます。
この節では、hadbm status コマンド、hadbm deviceinfo コマンド、および hadbm resourceinfo コマンドについて簡潔に説明します。HADB 情報の解釈の詳細は、『Sun ONE Application Server パフォーマンスおよびチューニングガイド』を参照してください。
HADB の状態の取得
データベースまたはそのノードの状態を表示するには、hadbm status コマンドを使います。構文は次のとおりです。
hadbm status [--nodes] [dbname]
次に例を示します。
hadbm status --nodes
次の表に、hadbm status コマンドのオプションを示します。
表 20-13 hadbm status のオプション
長形式
短形式
デフォルト値
説明
--nodes
-n
指定されていない
指定されている場合、ノードの状態情報を表示する。「ノードの状態」を参照
dbname
なし
hadb
データベース名を指定する
データベースの状態
データベースの状態は、次のとおりです。
- High-Availability Fault Tolerant (HAFT: 高可用性の障害耐性): データベースは障害耐性の状態にあり、各 DRU に少なくとも 1 つのスペアノードがある
- Fault Tolerant (FT: 障害耐性): すべてのミラーノードのペアが実行中
- Operational (O: 運用): 各ミラーノードのペアで少なくとも 1 つのノードが実行中
- Non Operational (NO: 非運用): 1 つ以上のミラーノードのペアで相手方のノードが見つからない
- Stopped (S: 停止): データベース内に実行中のノードがない
- Unknown (U: 不明): コマンドがデータベースの状態を判定できない
データベースの状態が Non Operational (非運用) の場合、「HADB のクリア」で説明しているとおり、hadbm clear を使ってデータベースをクリアします。
ノードの状態
--nodes オプションを指定している場合、データベース内の各ノードについて、次の情報が表示されます。
次の各節で説明するとおり、ノードのロールと状態は変更可能です。
ノードのロール
ノードはその作成時にロールに割り当てられます。ロールは、次のいずれかになります。
- Active (アクティブ): アクティブなノードではデータの保存とクライアントアクセスが可能。アクティブなノードは、ミラーペア内にある
- Spare (スペア): データデバイスが初期化された後、スペアノードはほかのデータノードを監視し、ほかのノードが利用できなくなった場合に補修を開始する。スペアノードではクライアントアクセスは可能だが、データの保存はできない
- Offline (オフライン): inetd による再起動を避けるために、ノードの停止前にノードはオフラインになる。オフラインのノードでは、そのロールが変更されるまでサービスを提供できない。オフラインのノードのロールは、元のロールに戻すことができる
- Shutdown (停止): アクティブとオフラインの中間段階で、スペアノードによって機能が引き継がれるまでノードが待機している状態。スペアノードが機能を引き継ぐと、ノードはオフラインになる
ノードの状態
ノードは、次のいずれかの状態になります。
- Starting (起動中): ノードが起動中
- Waiting (待機中): ノードが、その起動レベルを特定できず、オフラインになっている。1 つのノードで 2 分以上この状態が続く場合は、ノードを停止して、repair レベルで再び起動する。「ノードの停止」および「ノードの起動」を参照。複数のノードがこの状態である場合は、「HADB のクリア」で説明しているように、データベースをクリアする。
- Running (稼働中): ノードが完全に起動していて、そのロールに合ったサービスを提供している
- Stopping (停止中): ノードを停止中
- Stopped (停止): ノードが非アクティブ。停止しているノードの補修は禁止されている
- Recovering (復元中): ノードを復元中。ノードで障害が発生すると、そのノードの機能はミラーノードに引き継がれる。障害が発生したノードは、メインメモリまたはディスクから再起動することによって復旧を試みる。このとき、ミラーノードのログファイルを使って、失われたデータを復元する。復旧に成功すると、ノードがアクティブになる。復元に失敗すると、ノードの状態が Repairing (補修中) に変わる
- Repairing (補修中): ノードを補修中。この操作によって、ノードが再初期化され、ミラーノードからデータとログファイルがコピーされる。補修には、復元よりも多くの時間を要する
デバイスの情報の取得
HADB の監視の際に、データベースの増大に対応できる十分な空き容量があるかどうかも確認します。アクティブな各ノードのディスクストレージデバイスに関する情報を取得するには、hadbm deviceinfo コマンドを使います。構文は次のとおりです。
hadbm deviceinfo [--details] [dbname]
次に例を示します。
hadbm deviceinfo --details
デフォルトの dbname は hadb です。
データベースの各ノードの情報として、次のような項目などが表示されます。
ユーザーデータに使用可能な容量を特定するには、合計デバイスサイズを割り出し、そこから LogBufferSize の 4 倍の値を差し引きます。ログバッファのサイズが不明な場合は、hadbm get logbufferSize コマンドを使います。たとえば、合計デバイスサイズが 128M バイトで、LogBufferSize が 24M バイトの場合、ユーザーデータに使用可能な容量は 128 - (4 x 24) = 32M バイトになります。
合計デバイスサイズと空き容量のサイズとの差異が、ユーザーデータのサイズになります。将来、データを再フラグメント化する可能性がある場合は、ユーザーデータのサイズが、ユーザーデータに使用可能なディスク容量の 50% 未満である必要があります。再フラグメント化を実行しない場合には、ディスク容量のほぼ 100% を使用して構いません。システムがデバイススペース上で短時間実行された場合、リソース消費警告が履歴ファイルに書き込まれます。
HADB のチューニングの詳細は、『Sun ONE Application Server パフォーマンスおよびチューニングガイド』を参照してください。
--details オプションを指定している場合は、次のような追加情報が表示されます。
次に例を示します。
NodeNO Totalsize Freesize Usage NReads NWrites DeviceName
0 128 120 6% 10000 5000 /var/opt/hadb.data.0
1 128 124 3% 10000 5000 /var/opt/hadb.data.1
2 128 126 2% 9500 4500 /var/opt/hadb.data.2
3 128 126 2% 9500 4500 /var/opt/hadb.data.3
さらに情報が必要な場合は、hadbm resourceinfo コマンドを使います。このコマンドによって、HADB 実行時のリソース情報が表示されます。この情報はリソースの競合の特定に役立ち、この結果を利用してパフォーマンス上のボトルネックを軽減できます。詳細は、『Sun ONE Application Server システム配備ガイド』および『Sun ONE Application Server パフォーマンスおよびチューニングガイド』参照してください。構文は次のとおりです。
hadbm resourceinfo [--databuf] [--locks] [--logbuf] [--nilogbuf] [dbname]
指定したオプションに応じて、次のようなデータベース情報が表示されます。
たとえば、データバッファプールの情報は次のように表示されます。
NodeNO Avail Free Access Misses Copy-on-Write
0 256 128 100000 50000 1000
1 256 128 110000 45000 950
ロックの情報として、次の項目が表示されます。
次に例を示します。
NodeNO Avail Free Waits
0 50000 20000 10
1 50000 20000 0
実際に使用するのは、使用可能なロック数の 50% 未満に抑える必要があります。NumberOfLocks の変更方法については、「設定属性の表示と修正」を参照してください。
ログバッファの情報として、次の項目が表示されます。
次に例を示します。
NodeNO Avail Free
0 16 2
1 16 3
ノードの内部ログバッファの情報として、次の項目が表示されます。
次に例を示します。
NodeNO Avail Free
0 16 2
1 16 3
設定属性の表示と修正データベースの設定変数は、変更可能です。この節では、次のタスクについて説明します。
設定属性値の取得
設定属性の値を取得するには (そのリストは「設定属性」を参照)、hadbm get コマンドを使います。構文は次のとおりです。
hadbm get attribute-list | --all [dbname]
次に例を示します。
hadbm get jdbcURL,NumberOfSessions
デフォルトの dbname は hadb です。attribute-list は、コンマで区切られた属性のリスト、または引用符で囲まれスペースで区切られた属性のリストです。--all オプションを指定すると、すべての属性の値が表示されます。
設定属性値の設定
設定属性の値を設定するには (そのリストは「設定属性」を参照)、hadbm set コマンドを使います。構文は次のとおりです。
hadbm set [dbname] attribute=value,attribute=value ...
デフォルトの dbname は hadb です。attribute-list は、コンマで区切られた属性のリスト、または引用符で囲まれスペースで区切られた属性のリストです。
このコマンドが正常に実行されると、データベースは以前の状態またはより適切な状態で再起動されます。データベースの状態の詳細は、「HADB の状態の取得」を参照してください。
このコマンドが正常に実行されない場合は、「HADB の再起動」で説明しているように、HADB を再起動します。
設定属性
次の表に、取得および設定が可能な設定属性を示します。特に指定されている場合を除き、サイズは M バイト単位、時間は秒単位です。
履歴ファイルのクリアとアーカイブHADB 履歴ファイルには、データベース操作とエラーメッセージのレコードが格納されます。HADB 履歴ファイルの場所は、hadbm create コマンドの --historypath オプションによって決定されます。デフォルトの場所は /var/tmp です。ファイル名は、dbname.out.nodenumber という形式になります。hadbm create の詳細は、「データベースの作成」を参照してください。
履歴ファイルのサイズは、時間の経過とともに増大します。ディスク容量を節約し、履歴ファイルが大きくなり過ぎないようにするには、古い履歴ファイルを定期的にクリアおよびアーカイブする必要があります。データベースの履歴ファイルをクリアするには、hadbm clearhistory コマンドを使います。構文は次のとおりです。
hadbm clearhistory [--saveto=path] [dbname]
デフォルトの dbname は hadb です。
古い履歴ファイルを保存したい場合に保存先のディレクトリを指定するには、--saveto オプションまたは -o オプションを使います。このとき、書き込み権が設定されているディレクトリを指定する必要があります。
履歴ファイル内の各メッセージには、次の情報が書き込まれています。
リソースの不足に関するメッセージには、HIGH LOAD という文字列が入ります。
履歴ファイル内にあるエントリのすべての種類を詳しく知っておく必要はありません。何らかの理由で履歴ファイルについて詳しく学習する必要がある場合は、Sun のカスタマサポートにお問い合わせください。「HADB に関する Sun カスタマサポートへの問い合わせ」を参照してください。
セッションデータの破損からの復旧次のような場合は、セッションデータが破損している可能性があります。
- セッション状態を保存しようとするたびに、Sun ONE Application Server のシステムログ (サーバーログ) にエラーメッセージが表示される
- セッションを活性化するときに、セッションが見つからない、またはセッションを読み込むことができないというエラーメッセージがサーバーログに書き込まれる
- 以前に非活性化して再び活性化したセッションに、空のセッションデータまたは正しくないセッションデータが含まれる
- インスタンスに障害が発生したときに、フェイルオーバーセッションに空のセッションデータまたは正しくないセッションデータが含まれる
- インスタンスに障害が発生したとき、インスタンスがフェイルオーバーセッションを読み込もうとすることが原因で、セッションが見つからない、またはセッションを読み込むことができないというエラーがサーバーログで発生する
データが破損していると判断した場合にセッションストアを整合性のある状態に戻すには、次の手順に従います。
- セッションストアをクリアします。詳細は、「セッションストアのクリア」を参照してください。
- セッションストアを正常にクリアできない場合、または引き続きサーバーログにエラーが発生する場合は、すべてのノードでデータスペースを再初期化して、データベース内のデータをクリアします。「HADB のクリア」を参照してください。
- データベースを正常にクリアできない場合は、データベースを削除して、その後に再作成します。「データベースの削除」および「データベースの作成」を参照してください。
HADB に関する Sun カスタマサポートへの問い合わせHADB の問題について Sun のカスタマサポートに問い合わせる前に、ご使用のシステムに関する次の情報を可能な限り確認してください。
環境変数次の表に、hadbm コマンドオプションに対応する環境変数を示します。