Chapter 1
Compass Server Concepts
What Is a Compass Server?
A Compass Server system is a group of software programs that enable users to locate resources on a network, much as they might consult a card catalog in a library or a catalog of merchandise in a store. The Compass system consists of three main parts:- The Compass Server itself--This is the part the users actually interact with. Users can either type in search queries using keywords or browse through a set of categories, and the Compass Server responds with a list of items that correspond to the specified keywords or category.
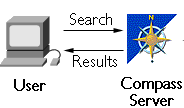 From the user perspective, the Compass Server is a stand-alone index
service, much like commercial web indexes they are probably familiar with,
but customized for your work environment both in content and
organization.
From the user perspective, the Compass Server is a stand-alone index
service, much like commercial web indexes they are probably familiar with,
but customized for your work environment both in content and
organization.
- The Compass database--The heart of the Compass Server is a database of information about resources available on the network, such as documents, text files, or spreadsheets. The administrator uses a program called a robot to find all the available resources on the network and generate information about them for the database. The robot works behind the scenes, invisible to end users.
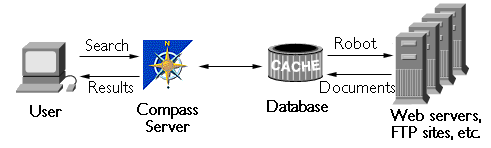 The administrator can also submit descriptions of resources manually. Most
of the work of the Compass Server administrator involves setting up and
customizing the robot and its settings.
The administrator can also submit descriptions of resources manually. Most
of the work of the Compass Server administrator involves setting up and
customizing the robot and its settings.
- The My Compass subscription system--Users who want to be notified when new material of interest comes into the Compass Server database can create subscriptions that describe what topics they want to hear about, using the Interest Profile Editor. The system can then notify them by email or by updating a web page.
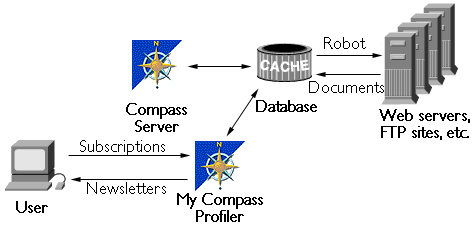 These My Compass newsletters provide both a customized notification of
updates and a way for users to rate new materials so that other users have
an idea of their relevance.
These My Compass newsletters provide both a customized notification of
updates and a way for users to rate new materials so that other users have
an idea of their relevance.
What Is a Compass Server For?
Networks contain vast amounts of information, spread out among multiple servers, stored in many formats, and maintained by different individuals. Even a carefully designed network can be confusing to those looking for specific information, and when the domain of the search extends to a company-wide collection of networks (an "intranet") or to the global Internet, where standards and coordination are nearly impossible, the search for the proper information can be nearly impossible. One way to bring some order to this chaotic jumble of networks, servers, documents, and resources is indexing. An index is a centralized, searchable database that brings together enough information about a set of resources so that users can pinpoint and retrieve the resources they want.Netscape Compass Server therefore addresses one of the most common issues network users face: finding information that might exist anywhere in a distributed environment. For example, a user might want to locate a specific report on a network that has dozens or even hundreds of servers. Network indexes have two general purposes:
In addition to these standard features of a network index, Netscape Compass Server can also alert network users to new resources of interest to them.Browsing for Information
In most cases, a user looking for information has no alternative except to browse (or "surf") through known locations and hyperlinks, hoping to find the desired resource.
Generating Navigational Aids
The solution is to create an index, which is a database at a specific location that contains information about network resources in a form that users can search in a number of ways.
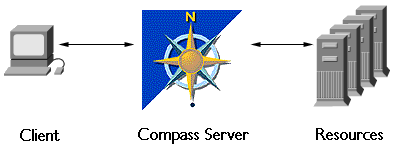
Using the Index
Instead of having to know about and visit a number of sites, the user now visits only a single site, using that site's tools to pinpoint and retrieve the desired resources.
The user can
What Can You Index?
Netscape Compass Server stores and distributes information about resources in its database. A resource, in this context, is essentially anything that can be represented by a Uniform Resource Locator (URL). URLs are most often associated with individual files or documents, such as home pages, but they can also indicate World Wide Web (WWW) sites, File Transfer Protocol (FTP) directories, and other network resources.The general rule is: : If you can pinpoint it with a URL, you can index it. By default, the robot installed with the Compass Server handles the largest subset of the resources you can index: those that can appear in a web browser such as Netscape Navigator. Those common resources include
For a list of all the file formats supported in this version, see Filling the Database.
You can also add other kinds of resources to your database, either manually or by customizing your robot to handle them for you.
Choosing Compass Server Features
This section describes the available features of your Netscape Compass Server, primarily from the viewpoint of the users of the server. Depending on what your users will want to do with the server, you can choose different features or different configurations of hardware and software in the system.
Specifically, this section describes the following topics:
What Users Expect from an Index
The term index generally denotes a list of items, usually with pictures or summary information for each item. The index often groups related items together by categories. Physically, catalogs can range from a typed list of items to one or more printed volumes to extensive online databases. People use indexes to locate particular items based on their needs. Take several different examples:User Features in Compass Server
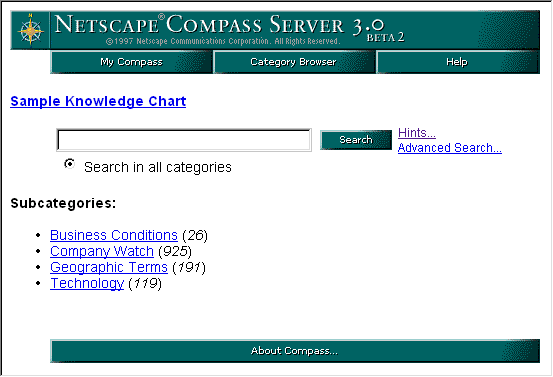
The Netscape Compass Server provides all the features that users expect of an index. These features are specifically designed for the task of locating resources on a computer network, and as the administrator you can further customize the user interface. But the key is that Compass Server provides the tools users expect when looking for a particular item. All of the features described in this section are explained in much more detail in the Netscape Compass Server User's Guide. Users of the Compass Server can access the appropriate pages in the User's Guide by pressing the Help button on each form. For your convenience, the User's Guide is also available in the Manuals section of the Server Manager for the Compass Server. Keyword Searches: The main Compass Server screen shown in the figure below provides a box in which users can type one or more keywords. When the user clicks the Search button, the Compass Server returns a list of items matching those keywords, with the best matches first. The user can then choose items from the list, which includes hypertext links to each item. The results list also provides links to similarly categorized items, if any.
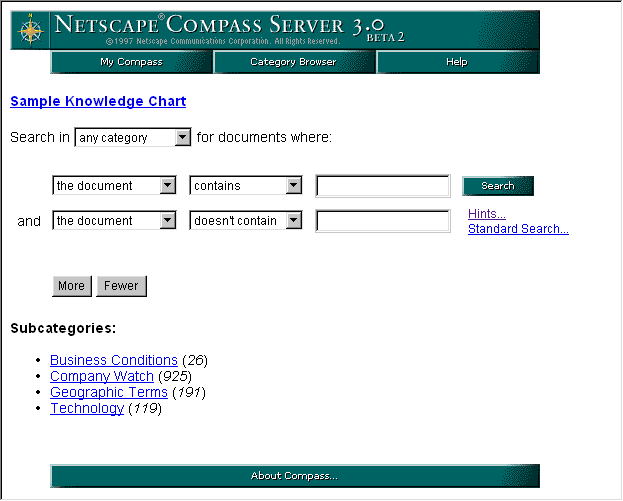
ANDs. This type of search is especially useful for locating specific items, rather than just a general type of item. The figure below shows the Advanced Search tool and highlights some of its main features.
Subscribing to Information
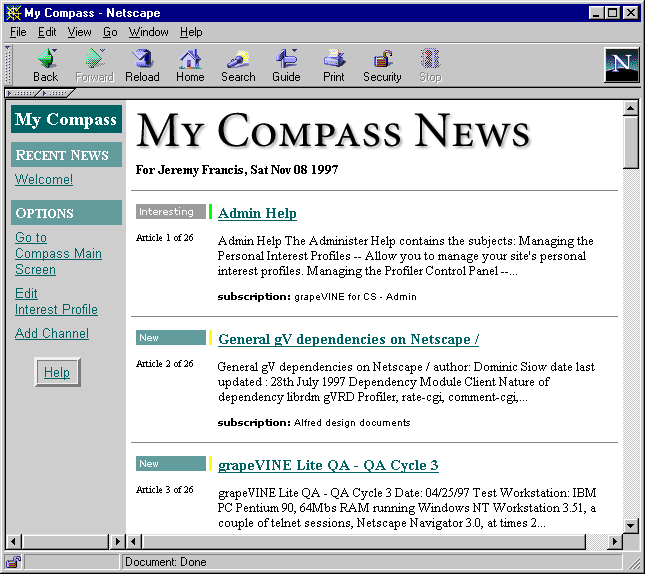
A new feature included with Netscape Compass Server is My Compass, a service that periodically checks the database for new or updated information and notifies users of items of interest to them. This "pushing" of information prevents users from having to repeatedly search for the same kinds of information. These My Compass notifications are based on subscriptions. Each user can specify a set of criteria that indicate what sorts of information the personal report should contain. My Compass then either sends electronic mail or updates a personal web page when new information arrives. In addition to receiving information about new and changed items, users can provide feedback on the usefulness of the items reported. The following figure shows a sample of a personal news page.
Advantages of the Compass Server
A computerized, networked resource database has several advantages over more traditional methods of indexing. Among these are- Multiple views of the same resources
- Easier reorganization of resources
- A variety of indexing methods that don't involve changing the data
What Administrators Need in an Index
Just as users have a set of expectations when using an online index, the administrator of that system brings certain expectations and requirements for setting up and maintaining the system.Administrator Features in Compass Server
With any server system, the administrator will have a number of requirements for features. This section describes both the more general server-administration features of Netscape Compass Server and those features particular to this kind of distributed indexing system. Access Control and Security: As with all Netscape server products, the Compass Server provides full access control and security. For description of these features, see the manual Managing Netscape Servers. Scheduling: Many administrators need to be able to schedule administrative and maintenance tasks to run at regular intervals, often when the system is physically unattended. Remote Administration: It is often useful to be able to perform routine tasks such as restarting the server from a remote location through the network. This enables the administrator to perform tasks without physical access to the server, either because the server is at another site or because it is in a computer room. Indexing control: For an online index, the administrator needs to be able to control what materials go into the index (and of course, which are excluded). The administrator also needs to be able to set up categories, assign documents to categories, rearrange the data, and maintain the database. Load balancing: There are several aspects of network and computer load balancing that affect all servers, and some specific to indexes. These include partitioning databases across physical devices, distributing workloads across different computers, and scheduling tasks based on network traffic and resource availability.Enabling Compass Server Features
Most of the features of Netscape Compass Server are active by default on installation. That is, you designate which site or sites on a network you want to index, and the Compass robot locates the resources at those sites, generates descriptions of them, and places them in the database, where they become immediately searchable. Of course, you have to allow enough time for the robot to find, describe, and register all the items on the network. Depending on the size of the network, that can take anywhere from a few minutes to several days. However, the database is usable all the time, even while being built initially or updated periodically.Indexing Documents
The most obvious need in starting and maintaining a Compass Server is making sure the database contains entries for all the appropriate items. That means you have to locate the items and generate descriptions of them. For the most part, this is the job of the Compass robot.The Compass Server robot is a process that runs continuously. Using a list of sites as starting points, the robot follows hypertext links to locate as many resources on the site and linked sites as possible (within parameters you set). For each resource it locates, it generates a resource description, which it then stores in its database. The Compass Server robot is described in much more detail in Filling the Database.
Once the robot places resource descriptions in the database, users can search for resources based on keywords or more complex criteria.
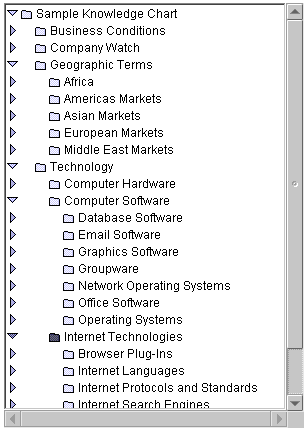
Defining Categories
In order for users to locate items in the database by browsing categories, the administrator must first set up the categories.
Most organizations will probably need to define their own categories, depending on the structure and needs of the organization. Compass Server comes with a number of sample category sets, however, that can serve as starting points for custom sets.
Creating and maintaining a set of categories is the subject of Setting Up Categories.
Maintaining the System
Once a Compass Server system has content, there are a few maintenance tasks needed to keep the database up-to-date and running smoothly. Most of these tasks can run on an automated schedule.
Refreshing Content:
Although the Compass robot is a continuous process that can always search for resources and generate descriptions of them for the database, you need to determine how often the robot should revisit all its sites to look for new items and update descriptions of changed ones.
How often this happens depends on how long the entire process takes, how often resources actually change, and how much load the Compass Server and network can handle. Filling the Database discusses these issues in greater detail.
Generating My Compass Newsletters: You should set up the My Compass profiler to generate timely newsletters for all users who subscribe to the service. There are at least two ways to handle this:
- Schedule the My Compass profiler to run at a specified day and time.
- Run a script at the completion of each robot run to run the profiler for the newly updated items.
System Maintenance: There are a few periodic tasks you can schedule to clean up unneeded files and improve system performance.
You also need to monitor and maintain the operating environment in general, to ensure that the Compass Server has enough disk space, memory, swap space, CPU cycles, and so on.About Resource Descriptions
The individual entries in the Compass database are called resource descriptions. A resource description is a specific set of information about a single resource. Users can search through this database to locate particular resources or kinds of resources. We often use the term document in a generic sense to describe any file on the network.The fields of each resource description are determined by the database schema. The database itself and the database schema are discussed in greater detail in Managing the Compass Database.
- Creating Resource Descriptions--This is by far the most common method, using a robot process to locate resources and generate their descriptions.
- Exchanging Resource Descriptions--This method is appropriate for large, distributed network indexes. A remote system generates resource descriptions, and the Compass Server imports those into its database.
NOTE: A special case of exchanging is migrating, which happens when you upgrade from Netscape Compass Server 1.0 to Netscape Compass Server. Migration is explained in Migrating from Catalog Server 1.0.The Compass Server's resource descriptions are based on open Internet standards, such as the Summary Object Interchange Format (SOIF) and resource description messages (RDM), ensuring that a Compass Server system can operate smoothly in a cross-platform enterprise environment.
Examples
One excellent way to visualize a resource index is to refer to some common, physical situations that are similar in function.
Scenario: Finding a book in the library:
In many ways, a computer network is like a library: information is stored in many separate physical locations (books) that can be inconvenient to locate and browse through. A book's contents might not be immediately obvious from the title.
The classic solution to locating particular books is to provide a card catalog (although most have been replaced by online indexes). The books in the library are the resources, and the individual cards are resource descriptions that contain summary information such as title, author, date, content summary, and shelving information. These resource description cards are generally organized alphabetically, but they are often dually indexed, by author and by title/subject.
The user can use the catalog to pinpoint which of the indexed resources are most likely to be useful.
Scenario: Ordering from a mail-order catalog:
Suppose you want to order new seat covers for your car from a mail-order company. To order the correct seat covers, you need to be able to specify the correct product number.
Mail-order companies generally provide catalogs of the products they sell. The products in this case are resources, and the resource descriptions are the entries in the catalog booklet, which might be as simple as single-line entries in a list or pictures with descriptions, but each contains a description of the resource: name, price, stock number, and so on. The products are generally grouped with similar products, often with an index for easy location.
By first locating the appropriate part of the catalog, then narrowing down choices until you find the seat covers you want, you can locate part numbers and other information needed to place your order.
Scenario: Finding out what's new:
Suppose you need to keep current on industry trends or the latest information on competing companies. Many people subscribe to news clipping services or specialized newsletters to keep them informed of the latest developments.
If your Compass Server is kept up-to-date, users will come to rely on it for such information, too. However, remembering to search for the same kinds of information every day is tedious and unreliable.
By creating customized subscriptions through the My Catalog Subscription Editor, users can have the system notify them of new or updated items in categories they choose, keyword searches they define, or documents others rate as important.
The Common Thread
In each of the preceding examples, the abstract situation is the same:
- There is a large number of resources to be represented.
- There is a common format for information describing each resource.
- A central repository holds all the resource descriptions.
- The resource descriptions are arranged, ordered, or grouped for easy access.
- The index provides direction on how to retrieve the desired resource.
Creating Resource Descriptions
A Compass Server most often relies on a robot to enumerate the resources it is responsible for. As the administrator, part of your job is to configure the robot to locate resources and have it generate resource descriptions for them. The most important part of that process is refining the robot's instructions to ensure that it finds all the resources you want included in the database without including extraneous resources or overburdening the network. Most of the material in this chapter deals with configuring and controlling the Compass Server robot.Exchanging Resource Descriptions
A very efficient way to get resource descriptions for your database is to import them from another Netscape Compass Server, a Netscape Enterprise Server, or a Harvest system. In cases where a number of systems all want to index the same material, it is much more efficient to generate the resource descriptions once and import them into other systems. Similarly, if network access is costly, you can minimize traffic by importing completed data, rather than making repeated robot inquiries.Much as a user requests certain kinds of information from the Compass Server, a Compass Server can make requests of other Compass Servers. This allows what is called distributed indexing, spreading the load for discovering and describing resources among different robots. A central Compass Server can gather resource descriptions from a number of different systems by importing the resource descriptions they generate. Importing and distributed indexing are explained in Managing the Compass Database.
The dialog between Compass Servers uses resource description messages (RDMs). RDM is an open protocol built on top of the standard HTTP protocol designed expressly for exchanging resource descriptions.
Filtering of resource descriptions in response to an RDM request is called scoping and is defined as part of the request. That is, a Compass Server need not import all the resource descriptions from another server's database. It can request only those that match certain criteria, just as a user does.
Deploying a Compass Server System
Once you have determined what you want your Compass Server system to do, you can proceed with deploying the system. This section focuses on what you have to do to set up an effective Compass Server system for the features you need.
Choosing User Features
As administrator, you have complete control over the user interface presented to your users. All the screens are controlled by JavaScript templates. The standard distribution provides a number of default screens you can use, but you can also modify those or create your own. Using templates, you can control both the layout and presentation of search screens and result lists as well as add or remove selected features from your system.
This section describes the following choices of default user interface features:
Searching and Browsing
There are two main ways for users to use the Compass Server: searching and browsing categories. As the administrator, you have a lot of control over the ease and usefulness of these features. The details of customizing the search and browse features appear elsewhere, but this section provides a brief overview of the issues you should consider when planning your Compass system so that you can maximize both its searchability and browsability.
One thing to remember is that the default configuration of the Netscape Compass Server provides for a reasonable, useful database for searching. Implementing browsing takes more planning. However, browsing is not a required element of a system. You can disable the browsing tools and use only the search capabilities of the Compass Server. It's a question of what your users need and want, and the usefulness of your browsing categories.
Factors Affecting Searching
The most common way for users to find resources in a Compass database is to type a query containing a few keywords that describe the desired documents. The Compass Server then provides a list of documents matching those keywords by searching its database of indexed resource descriptions. The search allows for simple matches as well as more complex searches that combine terms with AND or OR and other operators.
Generation of keywords for documents is provided by the Compass robot. By default, the robot generates keywords for each document based on words appearing in titles and headers. You can change the default keyword generation by customizing your robots through the robot application program interface (API), as described in the Netscape Compass Server Programmer's Guide.
Document authors can also provide specific keywords by embedding them with an editor such as Netscape Composer. Guidelines for authors appear in the Netscape Compass Server User's Guide.
In addition to keywords, the Compass Server can search for documents based on metainformation, such as author's name, creation date, or other attributes chosen by the administrator. The structure and content of the metainformation stored in the database is determined by the database schema. Managing the Compass Database describes how to adjust the schema for your particular needs.
Factors Affecting Browsing
With the Netscape Compass Server you can assign your indexed resources to categories. By designing your hierarchy of categories, you can make it very easy for users to find the types of information they want.
For example, suppose your Compass database covers a web site that contains only three kinds of documents: home pages, product announcements, and sales reports. You could create three categories within the global category of documents. Users looking only for sales reports could choose that category and then have the server display a list of only those documents.
Well-defined categories can make resources accessible in ways that ordinary searches might miss. For example, you could set up a category called "Competitors," containing information about companies that yours competes against. By directing your robot to categorize all items pertaining to competing companies in that category, you can ensure that users of your index don't have to search for each and every competitor individually.
The details of creating and maintaining a hierarchy of resource categories are explained in Setting Up Categories.
Deploying My Compass
The most important considerations in setting up the My Compass subscription system are setting up the user base and scheduling the profiler that generates newsletters informing users of new or updated materials that match their interest profiles.
These issues are discussed in greater detail in Administering My Compass.
The My Compass user and group definitions can either come from a local database or from an LDAP-based directory service, such as Netscape Directory Server. Keep in mind that once you choose your user database, you won't be able to easily change it later. That is, if you start out using a local database, you cannot easily change the configuration later to get the same information from a directory service.
For more about user and group management, see Managing Netscape Servers and the README file and release notes for Netscape Compass Server.
Scheduling the profiler is mostly a matter of balancing how often your users want updated newsletters with how often you update the information in the Compass Server database by running its robot. As you schedule the various parts of the system that can be automated, you will determine when best to include the My Compass profiler.
Providing Information About the Server
One of the most confusing things for users of a search system is knowing just what the system includes. Netscape Compass Server provides a standard way for you to provide that information through the About Compass button across the bottom of all the standard user screens.
For more on the About page, see Customizing the User Interface.
Choosing Sites to Index
The first step in planning a Compass Server system is to determine what sites your database will cover. This list of sites contains the starting points for the robot. Whenever you start the robot, it goes through its list of starting points to begin crawling sites, looking for documents to index.
The simplest case is a database that covers the resources of a single web server. In that case, the Compass Server need only direct its robot to the root of the web site. The robot will then traverse the links it finds on the home page. On the other hand, a Compass database could cover multiple web sites, portions of one or more web sites, and so on. The administrator controls the scope of the robot by choosing the starting points and refining its site definition.
It's also possible to have separate databases for, say, several groups of servers, and other databases that combine the contents of those. This is done by importing resource descriptions into the Compass database.
For example, a large company might have a Compass database for each of its departments and a master Compass system for the entire company that covers all the departments by importing resource descriptions from each of the departmental Compass Servers. There are nearly as many different Compass Server configurations as there are network sites, and the considerations will be different for each. However, you can group the types of considerations into several categories:
Designing Sites for Indexing
If you use Netscape Compass Server to index sites over which you have some control, you can design the web sites to maximize the usefulness of the index. For example, if you index a corporate intranet, you can establish company-wide standards for metainformation that enables users to search more effectively, or you can have authors embed category information to ensure that browsing users can find the proper information.
A Compass Server that indexes remote sites over the global Internet, of course, does not have much control over what it finds, but you can still customize the way your system indexes those remote sites.
Controlling Robot Access
It is possible for web servers to control whether remote indexing processes, such as the Compass Server robot, can enter and index certain portions of their sites. The Internet standard for controlling such access is to use a file in the server's document root directory called robots.txt.
The format for
robots.txt is straightforward: it is a plain ANSI text file. The file consists of one or more groups of lines with name-value pairs that instruct the robots.
Each group of lines should describe the User-agent type, which is a name that robots call themselves. The Netscape Compass Server robot is called Netscape-Compass-Robot/3.0. After you specify which User-agents you want to configure, you include a Disallow line that lists the directories you want to restrict. You can include one or more groups in your robots.txt file.
Each line in the group has the format
The field:valuefield name is case insensitive, but value is case-sensitive. You can include comment lines by beginning the comment with the # character. The following example shows one group that configures all robots and tells them not to go into the directory called /usr:
# This is a sample robots.txt file
User-agent: *
Disallow: /usr Example Robots.txt Files
The following example robots.txt file specifies that no robots should visit any URL starting with /usr or /tmp:
# robots.txt for http://www.mysite.com/
The next example restricts all robots from your web site except the Compass Server robot:
User-agent: *
Disallow: /usr
Disallow: /tmp # robots.txt for http://www.site.com/
User-agent: *
Disallow: *# Netscape robot is a good robot
The following example tells all robots, including the Compass Server robot, not to traverse your web site.
User-agent: Netscape-Compass-Robot/3.0
Disallow: # No robots allowed!
User-agent: *
Disallow: / Using Document Metainformation
Another way to control the behavior of robots at the individual document level is to create metainformation in the document that indicates whether the robot should index that document and whether it should follow links found in the document.
This allows users who do not have access to the site's robots.txt file to define how their documents should be indexed. Note that, unlike robots.txt, users cannot specify permissions for any particular robot, just for robots in general.
In HTML documents, you use META tags to create this metainformation. In other kinds of documents, you can use whatever document information will be converted into the appropriate HTML META tags.
Using the ROBOTS Tag
The META tag that controls robot behavior uses the name ROBOTS. It's content tells a visiting robot whether it should include the document itself in its index and whether to follow hyperlinks found in the document to index the linked documents.
The general format for the ROBOTS tag is as follows:
<META NAME="ROBOTS" CONTENT="
The terms in the terms">CONTENT portion can be any of the following, separated by commas:
Using Other META Tags
In addition to the standard ROBOTS META tag, you can define other tags that have special meanings to your Compass Server robot. By default, the robot converts any user-defined META tags into corresponding fields in the document's resource description. You can then program the robot (as described in the Netscape Compass Server Programmer's Guide) to ignore documents containing certain tags, restrict its following of links, and so on.
For example, consider a document that includes the following META tag:
<META NAME="Importance" CONTENT="Trivial">
The Compass Server robot will automatically create a document field called "Importance" and assign it the value "Trivial" for this document. If you program the robot to ignore documents with an Importance of "Trivial," you can filter information for your index based on this self-rating.
[Contents] [Previous] [Next] [Index]
Last Updated: 02/12/98 13:30:51
Any sample code included above is provided for your use on an "AS IS" basis, under the Netscape License Agreement - Terms of Use