この章の情報の一部は、ブロック・ストレージ・データベースのみに適用され、集約ストレージ・データベースとは関係がありません。集約ストレージとブロック・ストレージの比較。も参照してください。
オンライン分析処理(OLAP)は、企業データを分析する必要のあるユーザーのための多次元のマルチユーザー対応のクライアント・サーバー型計算環境です。財務部門では、予算設定、アクティビティベースの原価計算(割当て)、財務実績分析および財務モデリングなどの用途にOLAPを使用します。販売部門では、売上の分析と予測にOLAPを使用します。マーケティング部門では、市場調査分析、販売予測、プロモーション分析、顧客分析および市場/顧客の区分にOLAPを使用します。一般的な製造部門でのOLAPの用途には、製造のプランニングおよび不具合の分析が含まれます。
こうしたすべての用途で重要な点は、組織の戦略的方向に関する効果的な決定を下すために必要な情報を管理者に提供できるということです。適切にOLAPアプリケーションを使用することで、必要な情報が得られます。つまり、効果的な意思決定のために「ジャストインタイム」の情報が提供されます。
このような情報を提供するためには、基本レベル以上の詳細データが必要です。ジャストインタイムの情報は計算されたデータであり、通常は複雑な関係を反映し、たいていはすぐに計算されます。複雑な関係の分析とモデルングを行う場合は、応答時間が一貫して短くないと実用的であるとはいえません。また、データ関係の性質があらかじめわかっているとは限らないため、データ・モデルが柔軟である必要があります。真に柔軟なデータ・モデルでは、効果的な意思決定のために、OLAPシステムは、変化するビジネス要件の必要に応じて対応できます。
OLAPアプリケーションは、多岐にわたる職務分野で広く利用されていますが、すべての分野で次の主要機能が必要です:
OLAPシステムで鍵となるのは、多次元データベースです。これは、データを集計および計算するのみでなく、様々なデータ・サブセットの取得と計算も行います。多次元データベースでは、複数のデータ・カテゴリ間の関係を分析する必要があるユーザーのため、データ・セットを複数のビューで表示する機能がサポートされています。たとえば、マーケティング・アナリストは、次のような疑問を持ちます:
多次元データベースでは、データ表示の数は、データベース・アウトライン(データベースのすべての要素を定義する構造)によってのみ制限されます。ユーザーは、データをピボットして様々な視点から情報を表示したり、ドリル・ダウンしてより詳細な情報を探したり、ドリル・アップして概要を表示したりできます。
この項では、多次元データベース内のアウトライン、次元およびメンバーの概念を説明します。次元とメンバーについて理解することで、多次元データベースの機能について理解が深まります。
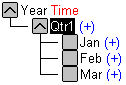
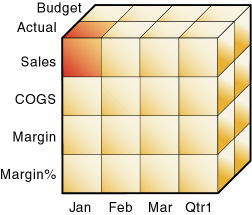
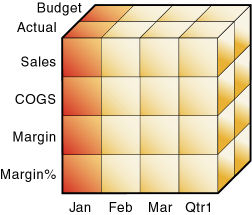
次元は、データベース・アウトライン内の最も高い集計レベルを表します。データベース・アウトラインでは、集計関係を示すツリー構造で次元とメンバーを表示します。たとえば、図2で、「Year」は次元(タイプ「Time」)であり、「Qtr1」はメンバーです。
標準次元は、ビジネス・プランのコア・コンポーネントを表し、たいていは部門機能と関連しています。一般的な標準次元は、時間、勘定科目、製品ライン、市場および部門です。次元はメンバーほどには変更されません。
属性次元は標準次元に関連付けられています。属性次元を使用して、標準次元のメンバーをメンバー属性(特性)に基づいてグループ化して分析します。たとえば、パッケージがガラス瓶のカフェイン抜き製品の収益性と、パッケージが缶のカフェイン抜き製品の収益性を比較できます。
メンバーは、次元の個別のコンポーネントです。たとえば、製品A、製品Bおよび製品Cは製品次元のメンバーです。各メンバーには一意の名前があります。Essbaseでは、メンバー(この章では、保管済メンバーと呼びます)に関連付けられているデータを保管できます。または、ユーザーがデータを取得するときに、そのデータを動的に計算できます。
すべてのEssbaseデータベースの開発は、データベース・アウトラインを作成するところから始まります。この作業では、次のことを行います:
Essbaseでは、メンバーの概念を使用してデータ階層を表現しています。各次元は1つ以上のメンバーで構成されます。各メンバーは、さらに複数のメンバーで構成されている可能性があります。次元の作成時に、個々のメンバーの値の集計方法をEssbaseに指定します。データベース・アウトラインのツリー構造では、集計はツリーの分岐内の複数のメンバーを示します。
たとえば、多くの業界では、月ごとにデータを要約し、この月次データをロールアップして四半期の数値を取得します。さらに、四半期のデータをロールアップして年間の数値を取得します。データを郵便番号別、都市別、州別、国別に要約する場合もあります。レポートを作成する目的で、あらゆる次元を使用してデータを集計できます。
たとえば、Essbaseサーバーに付属しているSample.Basicデータベースの年次元は、四半期のデータを保管するQtr1、Qtr2、Qtr3、Qtr4の各メンバーと、1年の要約データを保管するYearメンバーの5つのメンバーで構成されています。Qtr1は、月ごとのデータを保管するJan、Feb、Marの各メンバーと、四半期の要約データを保管するQtr1メンバーで構成されています。同様に、Qtr2、Qtr3およびQtr4も、月ごとのデータを保管するメンバーと四半期の合計を保管するメンバーで構成されています。
図2のデータベース・アウトラインでは、前の段落で説明したように、階層構造を使用して四半期内のデータの集計とその関係を表現しています。
次元によって、比較的少数のメンバーで構成されるものと、非常に多くのメンバーで構成されるものがあります。Essbaseでは、次元内のメンバー数に制限がないので、必要に応じて新しいメンバーを追加できます。
Essbaseでは、階層を表す用語(世代とレベル、ルートとリーフ)と家系を表す用語(親、子、兄弟、子孫と祖先)を使用して、データベース・アウトライン内のメンバーの役割と関係を説明します。この項のサブトピックでは、図3に示すアウトラインを使用して、メンバーの位置を説明します。
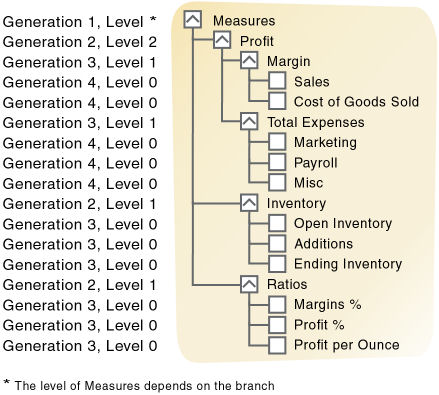
図3は、次のような親、子および兄弟関係を示しています:
図3は、次のような子孫と祖先の関係を示しています:
図3は、次のようなルート・メンバーとリーフ・メンバーの関係を示しています:
図3は、次の世代レベルを示しています:
世代とは、次元内の集計レベルのことです。ツリーのルート分岐は世代1です。世代番号はルートからカウントを開始し、リーフ・メンバーに向けて大きくなります。図3では、「Measures」は世代1、「Profit」は世代2、「Margin」は世代3です。各レベルの兄弟はすべて同じ世代に所属します。たとえば、「Inventory」と「Ratios」はどちらも世代2です。
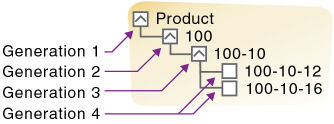
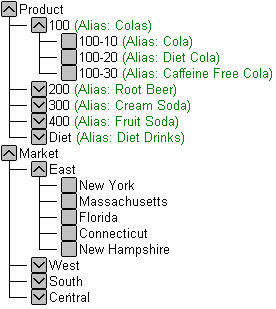
図4は、製品次元の一部に世代番号を付けたものです。Productは世代1、100は世代2、100-10は世代3、100-10-12および100-10-16は世代4です。
レベルも次元内の分岐を表しますが、世代とは使用する番号が逆になります。レベル番号はリーフ・メンバーからカウントし、ルートに向けて大きくなります。ルート・レベルの番号は、分岐の深さによって様々です。図3で、SalesとCost of Goods Soldはレベル0です。その他すべてのリーフ・メンバーもレベル0です。Marginはレベル1、Profitはレベル2です。Measuresのレベル番号は、分岐によって異なります。Ratios分岐の場合、Measuresはレベル2です。Total Expenses分岐の場合、Measuresはレベル3です。
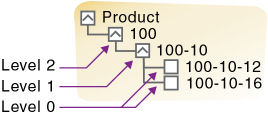
図5は、製品次元の一部にレベル番号を付けたものです。100はレベル2、100-10はレベル1、100-10-12および100-10-16はレベル0です。
Essbaseには、標準次元と属性次元があります。この章では、主に標準次元について説明します。なぜなら、Essbaseでは、属性次元のメンバーにはストレージが割り当てられないからです。属性次元の場合、ユーザーが関連データを要求すると、動的にメンバーの計算が行われます。
属性次元とは、標準次元に関連付けられた特殊なタイプの次元です。属性の操作。を参照してください。
多次元データベースのデータ・セットの多くは、次の2つの特性を備えています:
Essbaseでは、アプリケーションの標準次元を密次元と疎次元の2タイプに分割することで、パフォーマンスが最大化されます。Essbaseでは、この分割によりマトリックス方式のデータ・アクセスの長所を活かしながら、スムーズに分散されないデータに対応できます。また、Essbaseではメモリーとディスクの要件を最小限に抑えながら、データ取得時間を短縮できます。
大多数の多次元データベースは本質的に疎であり、大多数のメンバーの組合せにはデータ値がありません。疎次元とは、使用可能なデータ位置にデータが入っているパーセンテージが低い次元です。
たとえば、 図6内のSample.Basicデータベースのアウトラインには、年、製品、市場、メジャーおよびシナリオ次元が含まれます。製品は製品単位、市場は製品の販売地域、メジャーは勘定科目データを表します。すべての製品がすべての市場で販売されているわけではないので、市場と製品は疎次元になっています。
大多数の多次元データベースには、密次元も含まれます。密次元とは、あらゆる次元の組合せで1つ以上のセルに値が入っている可能性が高い次元です。たとえば、Sample.Basicデータベースでは、すべての市場のほとんどすべての製品に対して、勘定科目データが存在するので、メジャーは密次元になっています。年とシナリオも密次元です。年は各月、シナリオは勘定科目の値が実績値なのか予算値なのかを表します。
Caffeinated、Intro Date、Ounces、Pkg TypeおよびPopulationは属性次元です。属性の操作。を参照してください。

ほとんどのデータ・セットでは、既存のデータは予測可能な密と疎のパターンに従います。正確にパターン照合を行うと、非常に疎な多数のデータ・ブロックではなく、ある程度密な適切な数のデータ・ブロックに既存のデータを保管できます。
デフォルトでは、新規次元は疎に設定されています。密次元にするか疎次元にするかを決定するには、Essbaseの自動構成機能が役立ちます。
 密次元と疎次元の自動構成の方法については、
密次元と疎次元の自動構成の方法については、Essbaseでは、次の要素に基づいて、疎と密の次元構成の推奨が行われます:
推奨構成を適用するか、自動構成機能をオフにして、次元ごとに手動で疎または密のプロパティを設定できます。属性次元は常に疎次元です。属性次元に関連付けられるのは疎な標準次元のみである点に注意してください。
The Beverage Company (TBC)のデータを表すSample.Basicデータベースについて考えます。
TBCはすべての製品をすべての市場で販売しているわけではないので、データ・セットは適度に疎です。製品次元と市場次元のメンバーの組合せの多くには、データ値が存在しません。たとえば、フロリダではカフェイン・フリー・コーラが販売されていない場合、カフェイン・フリー・コーラ(100-30) ->フロリダ(Florida)の組合せに対するデータ値は存在しません。よって、製品次元と市場次元は疎次元になります。このため、これらの次元内の特定のメンバーの組合せに対してデータ値が存在しない場合、Essbaseでは、その組合せに対するデータ・ブロックは作成されません。
次に、年次元、メジャー次元、シナリオ次元のメンバーの組合せについて考えます。これらの次元のメンバーの組合せには、ほとんどの場合、データ値が存在します。たとえば、一部の製品は1月に販売されるので、Sales->January->Actualのメンバーの組合せにはデータ値が存在します。このため、年次元、メジャー次元、シナリオ次元は密次元になります。
Sample.Basicデータベースの標準次元の疎と密の構成は、次のように要約できます:
Essbaseでは、製品次元と市場次元のメンバーの一意の組合せに対して、データ・ブロックが1つずつ作成されます(データ・ストレージを参照)。各データ・ブロックは、密次元のデータのみを表します。データ・ブロックには、多くの場合、空のセルがいくつか含まれます。
たとえば、図7は、疎メンバーであるカフェイン・フリー・コーラ(100-30)とニューヨーク(New York)の組合せについて説明しています:
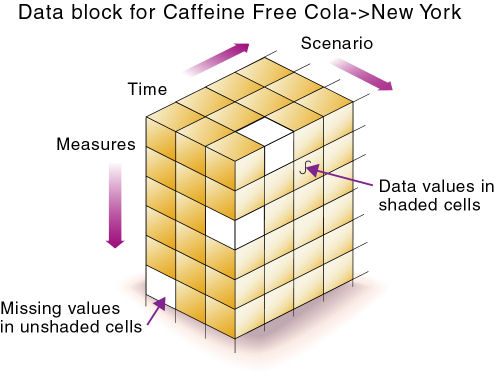
次のシナリオでは、異なる標準次元を選択したときのデータベースに対する影響を示します。これらのシナリオは、7つ以上の次元と数百個のメンバーを持つ一般的なデータベースを基にしています:
すべての次元を疎次元にした場合、Essbaseにより、データ値を1つのみ含むシングル・データ・セルで構成されるデータ・ブロックが作成されます。データ・ブロックごとにインデックス項目が作成されるので、このシナリオの場合は既存の各データ値に対してインデックス・エントリが作成されます。
この構成では、大量のメモリーを必要とするインデックスが生成されます。インデックス・エントリが多いほど、Essbaseによる特定ブロックの検索の所要時間が長くなります。
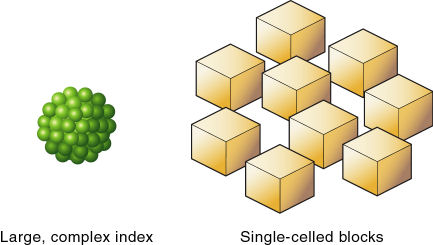
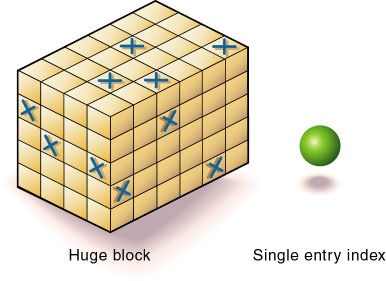
図9のようにすべての次元を密次元にした場合、Essbaseにより、インデックス項目とサイズの大きい疎なブロックが1つずつ作成されます。ほとんどのアプリケーションでは、この構成は、他の構成の何千倍ものストレージを必要とします。Essbaseでは、データ値を検索する際、メモリー全体をロードする必要があるので、膨大な量のメモリーが必要になります。
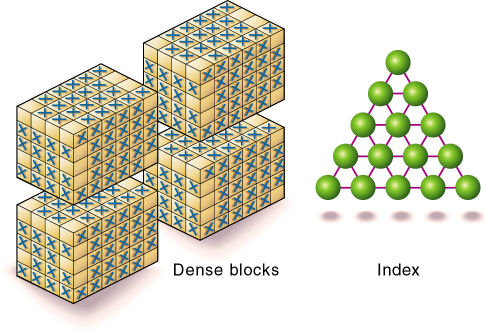
会社のデータに関する知識に基づいて、疎な標準次元と密な標準次元をすべて識別しました。疎な標準次元と密な標準次元の数がほぼ同じになるのが理想です。そうでない場合は、おそらく非一般的なデータ・セットを使用することになり、次元を定義する際により細かい調整が必要になります。
図10に示すように、Essbaseにより、メモリーに収容しやすい密なブロックと比較的小さなインデックスが作成されます。データベースは、最小限のリソースを使用して、効果的に実行されます。
時間、勘定科目、領域および製品の4つの標準次元を持つデータベースがあるとします。次の例では、時間次元と会計次元は密次元、領域次元と製品次元は疎次元です。
図11の2次元データ・ブロックは、密次元(時間次元と会計次元)のデータ値を表しています。時間次元のメンバーは、J、F、MおよびQ1です。勘定科目次元のメンバーは、Rev、ExpおよびNetです。
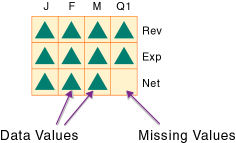
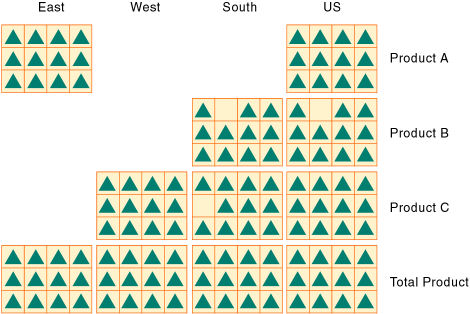
疎な標準次元のメンバーの組合せに対してEssbaseでデータ・ブロックが作成されます(メンバーの組合せに対して1つ以上のデータ値が存在する場合)。疎次元は領域次元と製品次元です。領域次元のメンバーは、East、West、SouthおよびTotal USです。製品次元のメンバーは、Product A、Product B、Product CおよびTotal Productです。
図12には、11個のデータ・ブロックが表示されています。WestとSouthのProduct A、EastとWestのProduct B、EastのProduct Cにはデータ値がありません。このため、Essbaseではこれらのメンバーの組合せに対してデータ・ブロックが作成されていません。Essbaseによって作成されたデータ・ブロックの中には、いくつかの空のセルが含まれます。この例では、すべての疎が効果的にインデックスに集められ、すべてのデータが完全に使用されているブロックに集められています。この構成では、データの格納と取得を効果的に実行できます。
次に、選択した密次元と疎次元の反転について考えます。次の例では、領域次元と製品次元は密次元、時間次元と会計次元は疎次元です。
図13では、2次元のデータ・ブロックは密次元である領域次元と製品次元のデータ値を表しています。West領域では、Product AおよびProduct Bに対するデータは使用できません。USのTotal Productに対するデータも使用できません。
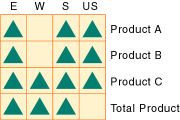
疎な標準次元のメンバーの組合せに対してEssbaseでデータ・ブロックが作成されます(メンバーの組合せに対して1つ以上のデータ値が存在する場合)。疎次元は時間次元と会計次元です。
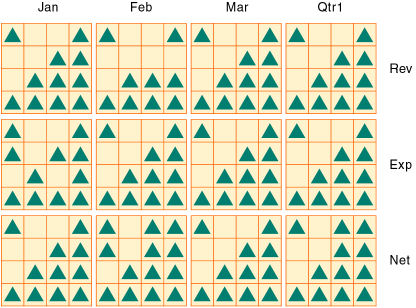
図14には、12個のデータ・ブロックが表示されています。時間次元と会計次元のメンバーのすべての組合せに対してデータ値が存在します。このため、Essbaseではすべてのメンバーの組合せに対してデータ・ブロックが作成されます。データ値は、すべての領域のすべての製品に対して存在するわけではないので、データ・ブロックには空のセルも多数含まれます。空のセルが多いデータ・ブロックには、データが効率的に保管されません。
多次元データベース内の各データ値は、単一のセルに保管されます。各標準次元に沿って座標を指定することにより、特定のデータ値を参照できます。
図15の単純なデータベースについて考えます。このデータベースには、会計、時間およびシナリオの3つの次元があります:
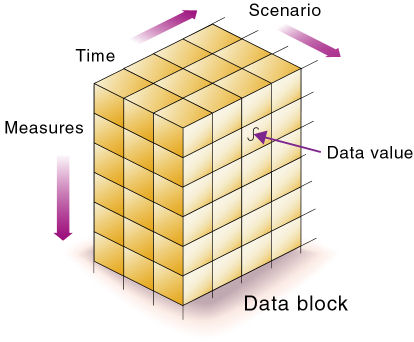
ある次元の1つのメンバーと他の各次元の1つのメンバーの交差は、特定のデータ値を表します。図16の例には3つの次元(勘定科目、時間およびシナリオ)があるため、次元とデータベース内のデータ値をキューブで表すことができます。
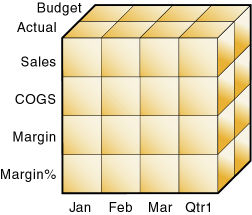
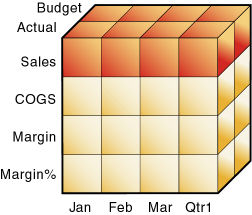
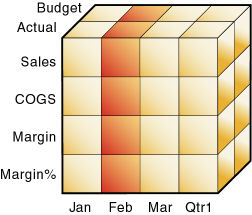
図17に示すように、Salesを指定すると、SalesがActualおよびBudgetと交差する8つのSales値を含む、データベースのスライスを指定することになります。
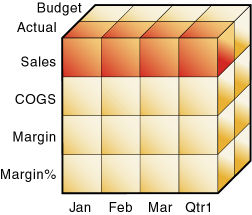
データベースをスライスするということは、1つ以上の次元をある定数値で固定するということです。その際、固定されていないその他の次元は可変です。
図18に示すように、Actual Salesを指定すると、ActualおよびSalesが交差する4つのSales値を含む、データベースのスライスを指定することになります。
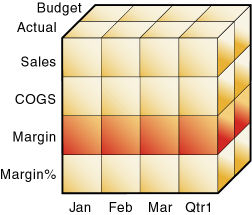
データベース内の1つのセルにデータ値が1つ保管されています。多次元データベース内の特定のデータ値を参照するには、各次元でそのメンバーを指定します。図19では、Sales、Jan、Actualのデータ値が含まれるセルが濃い色になっています。このデータ値は、次元間演算子(->)を使用して、Sales -> Actual -> Janと表現することもできます。
Essbaseでは、データ・ブロックとインデックス・システムという2つのタイプの内部構造を使用して、データの保管およびアクセスを行います。
Essbaseでは、疎な標準次元メンバーの一意な組合せごとに、データ・ブロックが1つ作成されます(その疎次元メンバーの組合せに1つ以上のデータ値が存在する場合)。データ・ブロックは、疎次元メンバーの組合せに対するすべての密次元メンバーを表します。
Essbaseでは、データ・ブロックごとにインデックス項目が1つ作成されます。インデックスは、疎な標準次元メンバーの組合せを表します。インデックスには、疎な標準次元のメンバーの一意な組合せ(データ値が1つ以上存在)ごとに、対応するエントリが1つずつ含まれます。
たとえば、図20に示すSample.Basicデータベースのアウトラインでは、「Product」次元と「Market」次元は疎次元です。
New YorkのCaffeine Free Colaのデータが存在する場合、Essbaseでは、Caffeine Free Cola (100-30) -> New Yorkという疎次元メンバーの組合せに対して、データ・ブロックとインデックス項目が作成されます。FloridaでCaffeine Free Colaが販売されていない場合、Caffeine Free Cola (100-30) -> Floridaという疎次元メンバーの組合せに対して、データ・ブロックやインデックス・エントリは作成されません。
Caffeine Free Cola (100-30) -> New Yorkというデータ・ブロックは、Caffeine Free Cola (100-30) -> New Yorkに対するすべての「Year」次元、「Measures」次元および「Scenario」次元を表します。
一意のデータ値は、特定のデータ・ブロックの特定のセル内に存在すると考えられます。Essbaseでデータ値を検索するときは、インデックスによって適切なデータ・ブロックが検索されます。次に、データ・ブロック内で、目的のデータ値を含むセルが検索されます。インデックス項目は、データ・ブロックへのポインタを提供します。インデックスには既存のデータ・ブロックへのポインタのみが含まれるので、疎なデータを効率的に処理できます。
図21は、Sample.Basicデータベースのデータ・ブロックの一部を示しています。ブロックの各次元は、Sample.Basicデータベース内の密次元(「Time」次元、「Measures」次元および「Scenario」次元)を表します。疎次元である「Product」次元と「Market」次元のメンバーの一意な組合せごとに、データ・ブロックが存在します(この組合せに対してデータ値が1つ以上存在する場合)。
各データ・ブロックは多次元配列になっており、この配列には、密次元メンバーの可能な組合せ1つ1つに対する固定の順序付けられた位置の情報が含まれます。ブロック内のセルにアクセスする際、逐次検索やインデックス検索は行われません。検索はほぼ一瞬で行われ、取得および計算速度が最適化されます。
Essbaseでは、データベース・アウトラインにおける密次元内のメンバーの順序に従って、データ・ブロック中のセルが順序付けされます。
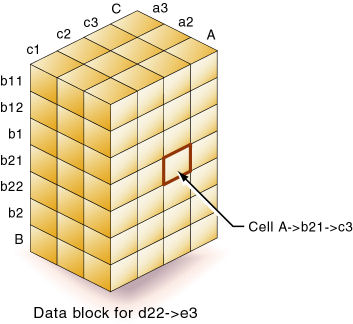
A (Dense)
a1
a2
B (Dense)
b1
b11
b12
b2
b21
b22
C (Dense)
c1
c2
c3
D (Sparse)
d1
d2
d21
d22
E (Sparse)
e1
e2
e3
図22のブロックは、前のデータベース・アウトライン内の疎なメンバーd22とe3の組合せに含まれる3つの密次元を表します。Essbaseでは、メンバーの組合せはクロス次元演算子で表されます。次元間演算子の記号は->です。したがって、d22 -> e3は、d22とe3のブロックを指します。A、b21およびc3の交差は、A -> b21 -> c3と記述します。
Essbaseでは、疎次元DおよびEのメンバーの一意な組合せごとに、データ・ブロックが作成されます(その組合せに対して1つ以上のデータ値が存在する場合のみ)。
図22のようなデータ・ブロックには、データ値がないセルが含まれる場合があります。データ・ブロックは、ブロック内に1つ以上データ値が存在する場合に作成されます。Essbaseでは、欠落した値があるデータ・ブロックはディスク上で圧縮され、各データ・ブロックはメモリーに読み込まれた時点で完全に展開されます。データの圧縮はオプションですが、デフォルトでは使用可能になっています。データ圧縮を参照してください。
密な標準次元と疎な標準次元を慎重に選択することで、データ・ブロックに多数の空のセルが含まれるのを防ぎ、ディスク・ストレージの要件を最小化するとともに、パフォーマンスを改善できます。Essbaseでは、空のセルは#MISSINGデータと呼ばれます。
最適化されたEssbaseデータベースを作成するには、次の点を確認します:
会社でデータを使用する方法
次元の構築と順序付けの方法
使用するデータ圧縮方式のタイプ
計算の作成と順序付けの方法
次のトピックを参照してください:
多次元データベースの開発プランニングの詳細は、ケース・スタディ: 単一サーバー、多次元データベースの設計。を参照してください。
密次元と疎次元の選択の詳細は、密次元と疎次元の選択を参照してください。
データのロードの詳細は、データ・ロードおよび次元構築の理解。を参照してください。
データの圧縮およびデータベースの最適化の詳細は、データ圧縮を参照してください。
データベースの計算の詳細は、Essbaseデータベースの計算。を参照してください。