この章の情報の一部は、ブロック・ストレージ・データベースのみに適用され、集約ストレージ・データベースとは関係がありません。集約ストレージとブロック・ストレージの比較。も参照してください。
多次元データベースを実装するには、Essbaseをインストールした後、アプリケーションとデータベースを設計して作成します。データ・ソースを分析し、慎重に要件を定義して、単一サーバーを使用する方法とパーティションに分割する方法のどちらがよりニーズに合っているかを判断します。アプリケーションをパーティションに分割するかどうかを判断する基準として、データベースのパーティション化のガイドラインを参照してください。
この章では、ケース・スタディを使用して、データベース・プランニング・プロセスの概要を説明します。また、組織向けに単一サーバーによる多次元データベース・ソリューションを設計する際の作業ルールについても説明します。アプリケーションとデータベースの作成。を参照してください。
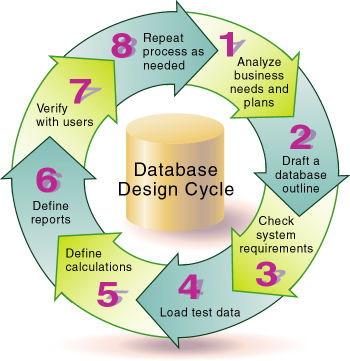
図26は、データベース設計のサイクルのプロセスを示しています。次の基本手順が含まれます:
ユーザーと組織の情報ニーズを満たすアプリケーションおよびデータベースを作成する必要があります。そのため、ソース・データを特定し、ユーザーの情報アクセスのニーズを定義し、セキュリティの考慮事項を確認して、データベース・モデルを設計します。分析とプランニングを参照してください。
アウトラインとは、データベースの構造を決めるものです。つまり、保管する情報と、異なる情報同士の相互関連付けを決定します。アウトラインのドラフト作成を参照してください。
データベースの効率とパフォーマンスは、システム要件を満たす方法およびシステム・パラメータの定義方法によって影響されます。システム要件のチェックを参照してください。
アウトラインの定義およびセキュリティ・プランの立案が完了したら、データベースにテスト・データをロードし、このプロセス以降の手順を処理できるようにします。テスト・データのロードを参照してください。
アウトラインの集計をテストし、専用の計算のための式および計算スクリプトを記述してテストします。計算の定義を参照してください。
ユーザーは、印刷やオンラインのレポートおよびスプレッドシート、またはWebを介してデータにアクセスします。ユーザーに事前定義済のレポートを提供する予定がある場合は、レポート・レイアウトを設計してレポートを実行します。レポートの定義を参照してください。
ユーザーのニーズを満たすデータベースを作成するには、ユーザーに意見を求め、その内容を慎重に検討します。設計の確認を参照してください。
この章では、The Beverage Company(TBC)という名前の架空の会社の要件に基づいてデータベース・プランニング・プロセスを開発し、このTBCを例として、Essbaseデータベースの構築方法を説明します。TBCはEssbaseのインストールに含まれるSample.Basicアプリケーションのバリエーションです。
TBCは、国内外で清涼飲料水の製造、販売、流通を行っています。TBCのアナリストは、予算予測を策定し、毎月の予算予測と実績を比較します。アナリストが追跡する財務尺度は、損益および在庫です。
TBCでは、スプレッドシート・パッケージを使用して予算データを準備し、差異レポートの作成を実行しています。複数の市場で様々な製品のプランニングと追跡を実施しているため、データの取得や分析に時間がかかります。先月、アナリストは勤務時間の大部分をデータの入力とレポートの準備に費やしていました。
TBCは、財務データの中央リポジトリを作成するには、Essbaseが最適のツールであると判断しています。データ・リポジトリは、アナリストが組織のどこにいてもアクセスできる1台のサーバー上に置かれます。ユーザーはこのサーバーにアクセスして、様々なソースからデータをロードしたり、必要なデータを取得したりできます。なお、TBCには様々なユーザーが存在するため、ユーザーごとにデータ・アクセスのセキュリティ・レベルを変更する必要があります。
システムを細かく調整して、ビジネス情報を効果的に分析できるようにするには、Essbase多次元データベースの設計と操作が鍵となります。多次元データベースのサイズおよびパフォーマンスの変動を考えると、最適化されたデータベースを開発することが重要です。データ・ソース、ユーザーの要件および予想されるデータベース要素をアウトライン化した詳細なプランを立案することで、開発および実装の所要時間を短縮できます。
多次元アプリケーションを設計する場合、次の要因を検討します:
会社が作成するレポートのタイプ: レポートに関するユーザーのニーズを満たすために、アウトラインにどのようなタイプのデータを含める必要があるか
アプリケーションごとにデータベースを1つのみ定義することで、メモリーの使用率を向上させ、データベース管理を簡易化できます。ただし、オプションのEssbase通貨換算モジュールを使用するアプリケーションは、この推奨要件に当てはまりません。通貨換算アプリケーションは、通常、メイン・データベースと独立した通貨データベースで構成されます(通貨換算アプリケーションの設計および作成を参照)。
まずデータベースに含めるソース・データを評価します。データの場所とデータベースのデータを更新する頻度を考慮してください。この事前調査を行うことで、データベースのアウトラインを作成してEssbaseデータベースにデータをロードするときの時間を節約できます。
データベースのスコープを決定します。膨大な数の製品を含む製品ファミリが多数存在する場合、製品ファミリのデータ値のみを保管できます。各ユーザー部門のメンバーにインタビューを実施して、どのようなデータを処理しているのか、現在はどのような方法でデータを処理しているか、将来どのような方法でデータを処理していきたいかを確認します。
データをEssbaseにロードする準備ができていることを確認します。
Essbaseで使用できるフォーマットのデータですか。Essbaseにロード可能な有効なデータ・ソースのリストについては、データ・ソースを参照してください。
セキュリティ権限の設定方法をプランするときは、ユーザーの情報の要件を考慮します。分析の最後に、ユーザーと権限のリストを作成します。
次のチェックリストを使用して、セキュリティ・プランを立てます:
EPM Systemセキュリティ・モードでのユーザーの管理およびセキュリティを参照してください。
次に、データベースのモデルを紙に書き出します。モデルを構築するには、業務にとって重要なパースペクティブとビューを識別します。これらのビューが、データベース・モデルの次元になります。
業務情報の主要分野を明確にした後、Essbaseデータベース設計の次の手順は、データベースでどのようにデータを分析するかを決定することです。たとえば、次の内容を検討します:
業務の分野を問わず、分析に必要なパースペクティブと詳細を決定する必要があります。分析するビジネス領域ごとに、異なるデータ・ビューが提供されます。
各ビジネス・ビューをデータベース内の個々の標準次元として表現できます。分類や属性(製品のサイズや色など)によってビジネス領域を分析する必要がある場合、属性次元を使用して分類ビューを表現できます。
選択した次元によって、データに対して実行できる分析のタイプが決まります。Essbaseでは、分析のニーズに合わせて必要な数の次元を使用できます。一般的なEssbaseデータベースの場合、標準次元(非属性次元)が少なくとも7つと、さらに多数の属性次元が含まれます。
必要な次元とメンバーをほぼ把握できている場合は、次の項目を検討して、仮のデータベース設計を作成します:
データベース・モデルの次元を決定したら、各次元のパースペクティブ内の要素またはアイテムを選択します。これらの要素がそれぞれの次元のメンバーになります。たとえば、時間のパースペクティブには、分析対象の期間(四半期、四半期内の月など)が含まれます。各四半期と各月は、作成した時間を表す次元のメンバーになります。四半期と月は、メンバーとその子からなる2レベルの階層を表します。四半期内の月を集計すると、その四半期の合計が得られます。
次に、ビジネス領域間の関係について考えます。Essbaseデータベースは、ユーザーが多くのパースペクティブから情報を簡単に分析できるような構造になっています。たとえば財務アナリストが、次のような疑問を持つとします:
つまり、アナリストは、次の3つのパースペクティブから情報を調査する必要があります - 時間、勘定科目およびシナリオ。図27のサンプル・データベースでは、これら3つのパースペクティブが3つの次元として表されています。1つの次元が3つの軸に沿って表現されます:
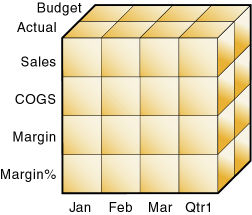
このキューブ内のセル(メンバーが交差している箇所)には、交差している3つのメンバーすべてに対応したデータが含まれています。たとえば、1月の販売実績などです。
表2は、プランナが次元として定義したTBCのビジネス領域の要約です。次元は、分析対象の主要なビジネス領域を表します。プランナは3つの列を作成しています。左端の列に次元、右の2列にメンバーが入ります。列3のメンバーは列2のメンバーのサブカテゴリです。列3のメンバーがさらにサブカテゴリ・レベルに分割される場合もあります。たとえばメジャー次元のMarginは、SalesとCOGSに分割されます。
表 2. TBCのサンプルの次元
初期の次元設計が準備段階の間に、一連のガイドラインに基づいて設計を見直す必要があります。ガイドラインを使用することで、データベースを調整して、多次元技術を活用できるようになります。ガイドラインは、効果的な設計を実現し、集計と計算の目標を達成するのに役立つプロセスまたは課題です。
潜在的データ・ポイントを記述するために必要なメンバーの数によって、次元の数が決まります。次元を削除すべきかどうかわからない場合は、削除を保留にして、その次元を削除すべきか保持すべきかの確信が得られるまで、さらに多くの分析ルールを適用します。
次のトピックの情報を使用して、データベース設計を分析し、改善します。
どの次元が疎で、どの密次元がパフォーマンスに影響するかについて考えます。初めに、疎次元および密次元を参照してください。パフォーマンスを最適化するためのアウトラインの設計を参照してください。
簡単にするため、このトピックの例では、2つの次元として最初に設計されたものとは別の配置を使用します。すべての次元の組合せに同じ論理を適用できます。
製品を複数の市場の複数の顧客に販売する会社における設計について考えてみます。この場合、市場は各顧客に対して一意です:
Cust A Cust B Cust C
New York 100 N/A N/A
Illinois N/A 150 N/A
California N/A N/A 30
Cust AはNew Yorkのみ、Cust BはIllinoisのみ、Cust CはCaliforniaのみに存在します。会社は、1つの標準次元でデータを定義できます:
Market
New York
Cust A
Illinois
Cust B
California
Cust C
しかし、データのサンプリング規模を大きくしたところ、多数の顧客が各市場に存在することがわかったとします。たとえば、Cust AとCust EがNew Yorkに、Cust B、Cust MおよびCust PがIllinoisに、Cust CとCust FがCaliforniaに存在するとします。この状況では、一般的に、大きい次元である顧客を標準次元として定義し、小さい次元である市場を属性次元として定義します。市場次元のメンバーを顧客次元のメンバーの属性として関連付けます。市場次元のメンバーは、顧客の場所を表します。
Customer (Standard dimension)
Cust A (Attribute:New York)
Cust B (Attribute:Illinois)
Cust C (Attribute:California)
Cust E (Attribute:New York)
Cust F (Attribute:California)
Cust M (Attribute:Illinois)
Cust P (Attribute:Illinois)
Market (Attribute dimension)
New York
Illinois
California
別の状況について考えます。同様に、製品を複数の市場の複数の顧客に販売する会社ですが、この会社は異なる複数の市場に存在する顧客に製品を発送することがあります:
Cust A Cust B Cust C
New York 100 75 N/A
Illinois N/A 150 N/A
California 150 N/A 30
Cust AはNew YorkとCaliforniaに存在します。Cust BはNew YorkとIllinoisに存在します。Cust CはCaliforniaのみに存在します。この状況で属性次元を使用しても機能しません。顧客のメンバーは、複数の属性メンバーを持つことができません。このため、次のように2つの標準次元を使用してデータを設計します:
Customer
Cust A
Cust B
Cust C
Market
New York
Illinois
California
2つの次元の各組合せを2次元マトリックスに配置します。たとえば、TBCの次元の候補(表2を参照)には、次の組合せがあります:
オンスとパッケージ・タイプは、属性次元として製品次元に関連付けられているので、製品次元と一緒に検討できます。
各次元を視覚的に表すために、マトリックスを作成し、最初の世代のメンバーのいくつかを配置します。図28は、3つの次元の簡単なマトリックスを示しています。
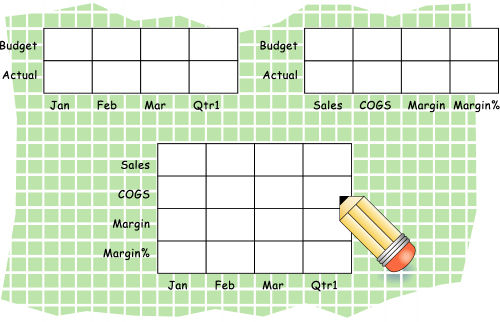
組合せごとにこの質問に答えることによって、その組合せがデータベースにとって有効であるかどうかを判断できます。すべての質問の答えが「はい」であるのが理想です。そうでない場合は、より有効な次元にデータを配置しなおすことを検討します。このプロセスで、必要な情報についてユーザーと話し合います。
アウトラインにある要素の繰返しは、ほとんどの場合、次元を分割する必要があることを示しています。次の例で、繰返しを避ける方法を説明します。
図29では、左側の列「Repetition」では、「Accounts」次元の「Budget」と「Actual」の下に、「Profit」、「Margin」、「Sales」、「COGS」および「Expenses」が繰り返し表示されています。右側の列「No Repetition」では、「Budget」と「Actual」を別の次元(「Scenario」)に分け、「Accounts」次元には「Profit」、「Margin」、「Sales」、「COGS」および「Expenses」メンバーが1セットのみ表示されています。この方法によって、アウトラインが単純になり、データベースの他の次元の予算と実績の数値の表示がわかりやすくなります。
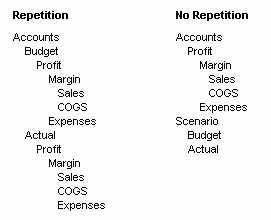
図30では、左側の列「Repetition」で、ダイエット飲料を分析するために「Diet」次元の共有メンバーを使用しています。メンバー「100-20」、「200-20」および「300-20」は、「Diet」の下で1回、それぞれの親の下で1回表示されています。右側の列「No Repetition」では、ブール・タイプ(TrueまたはFalse)の「Diet」属性次元を作成して、アウトラインを単純にしています。すべてのメンバーはそれぞれの親の下に1回のみ表示され、該当する属性(「Diet: True」または「Diet: False」)でタグ付けされています。
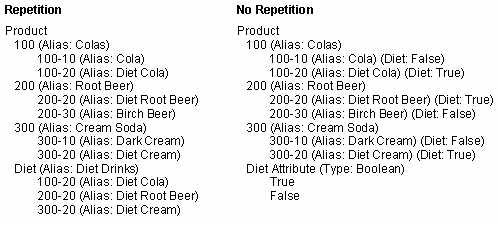
属性次元には、その他の分析機能もあります。属性次元の設計を参照してください。
次元間の無関係性は、ある次元の多数のメンバーが他の次元にとって無関係であるときに起こります。Essbaseでは、要約(次元)レベルでのみEssbaseによって保管されるデータとして、無関係データを定義します。このような場合、データベースから次元を削除して、そのメンバーを他の次元に追加するか、モデルを個別のデータベースに分けることができます。
たとえば、TBCは、メジャー次元のメンバーとして給与を分析することを考えました。ただし、給与情報は、ほとんどの場合、企業データベースのコンテキストで無関係であることがわかりました。ほとんどの給与は機密情報で、個人に適用されます。個人と給与は一般的に、1つのセルを表し、他の次元と交差する必要はありません。
TBCは、従業員を個別の次元に分けることを考えました。表4は、次元間の無関係性について、TBCが従業員次元の候補を分析した様子を示しています。候補の従業員次元のメンバー(表のヘッダー行)を、メジャー次元のメンバー(左端の列)と比較しています。メジャー次元のメンバー(Revenueなど)はAll Employeesに関係します。Salaryメジャーのみが個々の従業員に関係しています。
個別の従業員情報はデータベースの他の情報とは関係がなく、従業員次元を追加すると必要なデータベース・ストレージが大幅に増えるので、TBCでは人事部(HR)データベースを個別に作成しました。新しいHRデータベースには、関連する次元のグループが含まれ、給与、福利厚生、保険および401(k)プランの情報が保管されます。
データベースを分割する理由は様々です。たとえば、ある会社で、タイム・ゾーンの異なる複数の海外の子会社が含まれる組織データベースを運営しているとします。各子会社には、時間依存の財務計算が必要です。財務計算を適切なタイミングで提供できるように、タイム・ゾーンが同じ子会社のグループのデータベースを分割できます。また、パーティション化されたアプリケーションを使用して、子会社ごとに情報を分割できます。
Essbaseでアプリケーションとデータベースを作成して、アウトラインの最初のドラフトを構築できるようになりました。ドラフトでは、すべての次元、メンバーおよび集計を定義します。アウトラインを使用して、集計の要件を設計し、式と計算スクリプトが必要な場所を特定します。
TBCのプランナは、データベース・アウトラインに関して次のようなドラフトを発行しました。このプランでは、年、メジャー、製品、市場、シナリオ、パッケージ・タイプおよびオンスが次元名です。TBCが集計、計算、式およびレポートの要件をどのように予想したかについて説明します。プランナは、製品を説明するときに製品名ではなく製品コードを使用しています。
年。TBCでは、毎月データを収集して、その月次データを四半期または年ごとに集計する必要があります。1月、2月、3月などのメンバーに保管される月次データは、四半期に集計されます。第1四半期、第2四半期などのメンバーに保管される四半期ごとのデータは、年に集計されます。
メジャー。売上高、売上原価、マーケティング、給与計算、その他、期首在庫、追加および期末在庫が標準のメジャーです。Essbaseでは、マージン、合計支出、利益、合計在庫、利益%、マージン%および1オンス当たりの利益をこのメジャーから計算できます。TBCでは、月ごと、四半期ごと、年ごとにメジャーを計算する必要があります。
製品。製品コードは、100‑10、100‑20、100‑30、200‑10、200‑20、200‑30、200‑40、300‑10、300‑20、300‑30、400‑10、400‑20および400‑30です。各製品は、それぞれのファミリ(100、200、300および400)に集計されます。各製品はオンス属性次元とパッケージ・タイプ属性次元のメンバーに関連付けられているので、TBCでは各集計によってサイズ別およびパッケージ別の分析を行えます。
市場。複数の州で1つの地域が構成されます。4つの地域で1つの市場が構成されます。州は、コネチカット、フロリダ、マサチューセッツ、ニューハンプシャー、ニューヨーク、カリフォルニア、ネバダ、オレゴン、ユタ、ワシントン、ルイジアナ、ニューメキシコ、オクラホマ、テキサス、コロラド、イリノイ、アイオワ、ミズーリ、オハイオおよびウィスコンシンです。各州は、その地域(東部、西部、南部または中央)に集計されます。各地域は市場に集計されます。
シナリオ。TBCでは、予算と実績データを取り出して、追跡します。マネージャは、予算と実績、および予算と実績の差異と差異のパーセンテージを監視して追跡する必要があります。
パッケージ・タイプ。TBCでは、製品のパッケージングが売上高と利益に与える影響を確認したいと考えています。パッケージ・タイプ属性次元を作成することで、ユーザーは製品のパッケージ・タイプがビンであるのか缶であるのかに基づいて、製品情報を分析できます。
オンス。TBCでは、市場によって異なるサイズ(オンス単位)で製品を販売しています。オンス属性次元を作成することで、ユーザーは各市場の適切な販売サイズを監視できます。
次のトピックでは、次元とメンバー・プロパティの基本を概観し、パフォーマンスに影響を与えるアウトライン設計について説明します。
次元とメンバーのプロパティでは、多次元構造の設計での次元とメンバーの役割を定義します。そのプロパティは次のとおりです:
次元タイプと属性の関連付け。次元タイプを参照してください。
データ・ストレージ・プロパティ。メンバーのストレージ・プロパティを参照してください。
集計演算子。次元およびメンバーの集計を参照してください。
式。式および関数を参照してください。
次元とメンバーのプロパティの詳細なリストは、次元およびメンバーのプロパティの設定。を参照してください。
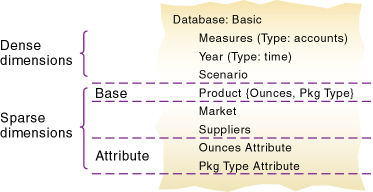
次元タイプは、Essbaseに用意されているプロパティの1つで、次元に特別な機能を追加します。最もよく使用される次元タイプは、時間、勘定科目および属性です。このトピックでは、TBCデータベースの次の次元を使用して、次元タイプを説明します。
Database:Design
Year (Type: time)
Measures (Type: accounts)
Product
Market
Scenario
Pkg Type (Type: attribute)
Ounces (Type: attribute)
表5で、各Essbase次元タイプを定義します。
|
データをレポートおよび更新する期間を定義します。「時間」というタグを付けることができる次元は1つのみです。時間次元によって、期首タイム・バランスや期末タイム・バランスなどの複数の会計次元の関数が使用可能になります。 | |
|
利益や在庫などの測定するアイテムを含み、Essbaseの組込み会計機能を使用可能にします。勘定科目として定義できる次元は1つのみです。 2つの形式の会計次元の計算については、会計次元の計算を参照してください。 | |
|
別の関連次元のメンバーを分類する際に使用するメンバーを含みます。 たとえば、Pkg Type属性次元には、Product次元のメンバーに適用される容器の各タイプ(ビンや缶など)に対応するメンバーが含まれます。 | |
|
ビジネス活動が行われる場所に関するデータを含みます。国次元では、各メンバーで使用される通貨を指定できます。 たとえば、カナダにはバンクーバー、トロント、モントリオールという3つの市場があり、すべての市場で同じ通貨(カナダ・ドル)を使用します。 | |
|
現地通貨メンバーをアプリケーションで定義されている基本通貨から分離します。この次元タイプは、メイン・データベースでのみ使用し、通貨換算アプリケーション専用です。分析用に基本通貨を米国ドルにすることができ、現地通貨メンバーには、各地域の通貨タイプに基づいた値を入れることができます。 |
メンバーにデータ・ストレージ・プロパティを指定できます。データ・ストレージ・プロパティでは、集計を格納する場所とタイミングを定義します。たとえば、デフォルトでは、メンバーは、「データの格納」としてタグ付けされます。Essbaseでは、データの保管メンバーの値を合計し、親レベルでその結果を格納します。
メンバーのデータ・ストレージ・プロパティ・タグを変更することで、各メンバーのデフォルトのロジックを変更できます。たとえば、データの保管メンバーをラベルのみメンバーに変更できます。ラベルのみタグが指定されたメンバーには、データが関連付けられません。
表6で、Essbaseデータ・ストレージ・プロパティがメンバーに与える影響について説明します。
表 6. Essbaseデータ・ストレージ・プロパティ
属性次元をアウトラインの最後に置きます。疎次元の前に密次元を置きます。
アウトライン内の次元の位置および次元のストレージ・プロパティは、パフォーマンスの2つの面に影響を及ぼす可能性があります。1つは計算の実行速度、もう1つはユーザーが情報取得に要する時間です。
次のトピックでは、パフォーマンスの最適化の基本について説明します。
計算のパフォーマンスを最適化するには、アウトライン内の疎次元をメンバー数の順に配列します。その際、最もメンバー数の少ない次元を先頭に配置します。
計算パフォーマンスの設計を参照してください。
図32のアウトラインは、最適な計算のパフォーマンスを実現します:

図31と図32のアウトライン例には、同じ次元が含まれていますが、この2つのアウトラインはそれぞれ異なります。状況に最適なアウトラインの順序を決定するには、データベースで計算を実行するために必要な時間に対するユーザーのデータ取得要件を優先させます。データベースの更新と再計算の頻度はどれくらいですか?ユーザー・クエリーの性質は?ユーザー・クエリーの予想量は?
1つの回避策として、最初に計算を最適化するために次元を配置します。計算の実行後、取得を最適化するために次元の順序を手動で変更できます。次元の順序を変更した後にアウトラインを保存する場合、データベースをインデックスのみで再構築することを選択します。再び計算を実行する間に、計算を最適化するためにアウトラインの次元の順序を変更します。
ディスク・スペース要件の決定を参照してください。
メモリー要件の決定を参照してください。
Essbaseキャッシュの最適化。を参照してください。
計算、集計およびレポートをテストするためには、データベースにデータを用意する必要があります。設計プロセス中に、ダミー・データまたは実際のデータのサブセットをロードすると、柔軟性が生まれ、テストと結果の分析に必要な時間を短縮できます。
予備テストを行い、データベース設計が適切であると判断した場合は、最終的なデータベースに読み込む実際のデータの完全なセットをテスト・ロードします。可能な場合は、テスト・ルール・ファイルを使用します。この最終テストによって、前の設計プロセス・フェーズで予測できなかった、ソース・データの問題が明らかになる可能性があります。
計算は、特定のタイプのデータを導き出すために必要です。計算から導き出されたデータを計算済データと呼び、基本の計算されていないデータを入力データと呼びます。
次のトピックでは、TBCアプリケーションの製品次元とメジャー次元を使用して、多くのEssbaseデータベースで見られる、一般的な計算のいくつかを紹介します。
ブロック・ストレージ計算の詳細は、次の章を参照してください:
標準次元のメンバーを定義すると、Essbaseによって自動的に、集計時にメンバーが加算されることを意味する+(加算を表すプラス符号)集計演算子がメンバーにタグ付けされます。メンバー集計プロパティは、必要に応じて、表7に示されている演算子のいずれかに変更できます。
集計は、Essbaseで最もよく使用される計算です。このトピックでは、製品次元を使用して集計について説明します。
TBCのアプリケーションには、次のようにいくつかの集計パスがあります:
集計演算子は、Essbaseで分岐の各メンバーのデータを親へロール・アップする方法を定義します。たとえば、デフォルトの加算(+)演算子を使用した場合、Essbaseでは、図33に示すように、100‑10、100‑20および100‑30を加算して、その結果を親100に保管します。

製品次元の大部分では、加算(+)演算子が使用されています。この演算子は、各メンバー・グループが加算され、親にロール・アップされることを示します。Dietにはチルダ(~)演算子が使用されています。この演算子は、Essbaseでは親である製品への集計にDietメンバーが入らないことを示します。Dietメンバーは、共有されるメンバーのみで構成されています。TBC製品管理グループは、レポートでダイエット飲料を分離することを望んでいるため、TBCは全体の集計に影響を与えないDietメンバーを個別に作成しました。
Essbaseでは、上から下の方向に分岐のデータを計算します。たとえば、加算(+)演算子がタグ付けされた2つのメンバーの次に、乗算(*)演算子がタグ付けされた3番目のメンバーがあるとします。Essbaseでは、最初の2つのメンバーを加算し、その合計に3番目のメンバーを乗算します。
Essbaseでは、必ず最上位メンバーから集計を始めるので、メンバーの順序とラベルが重要です。異なる演算子を持つ場合のメンバーの計算を参照してください。
表7に、Essbaseの集計演算子を定義します。
メジャー次元は、時間データと勘定科目データの両方を使用するので、TBCアウトラインで最も複雑な次元です。この次元には、Essbaseでのアウトラインの計算に役立つ式と特殊なタグも保管されています。このトピックでは、TBCがメジャー次元(勘定科目タグが付けられた次元)に保管した式とタグについて説明します。
(図34にある)TBCによって定義されたメジャー次元のタグをよく見てください。メジャー次元のほとんどのプロパティについては、この章の前のトピックで説明しています(加算(+)、減算(-)および集計なし(~)演算子、勘定科目タグとラベルのみタグ):
InventoryメンバーおよびRatiosメンバーは、ユーザーによるデータの操作を支援するためのものです。このメンバーにデータは含まれていません。したがって、ラベルのみタグが付いています。
メジャー次元自体にはラベルのみタグが付いています。メジャーの一部のメンバーには、動的計算タグが付いています。動的計算については、動的計算を参照してください。
メジャーの一部のメンバーにはタイム・バランス・タグ(TB FirstまたはTB Last)が付いています。タイム・バランス・タグについては、タイム・バランス・プロパティの設定を参照してください。

このトピックでは、勘定科目タグが付けられた次元を計算するための2つのフォーム(タイム・バランス・プロパティと差異レポート)について説明します。
表9のメジャー次元には、TB期首とTB期末という2つのタグがあります。これらのタグは、タイム・バランス・タグまたはプロパティと呼ばれ、勘定科目タグが付けられた次元でのデータの計算方法に関する指示をEssbaseに提供します。タグを使用するには、勘定科目タグが付けられた次元と時間タグが付けられた次元が必要です。期首、期末、平均および支出タグは、会計次元メンバーでのみ使用できます。
TBCメジャー次元では、期首在庫データは、各月の初めにTBCが持っている在庫を表します。期首在庫の四半期ごとの値は、四半期の期首の値に等しいです。期首在庫には、タイム・バランス・タグ「TB期首」が必要です。
期末在庫データは、各月の終わりにTBCが持っている在庫を表します。期末在庫の四半期ごとの値は、四半期の期末の値に等しいです。期末在庫には、タイム・バランス・タグ「TB期末」が必要です。表8では、会計次元のタイム・バランス・タグを定義しています。
表9で、第1四半期(右から2番目の列)と年(一番右側の列)は、会計次元のタイム・バランス・プロパティが時間次元の集計に与える影響を示しています。データは第1四半期分のみが表示されています。
通常、時間次元の親の計算は、その親の子の集計と式に基づきます。ただし、勘定科目の分岐のメンバーが「TB期首」とマークされている場合、時間次元のすべての親は、「TB期首」とマークされているメンバーに合わせます。
例については、タイム・バランス・プロパティの設定を参照してください。
TBCのEssbase要件の1つは、実績データと予算データの差異レポートを実行できることです。差異レポート計算では、会社の支出を表すすべてのアイテムに支出レポート・タグを付ける必要があります。在庫メンバー、合計支出メンバーおよびCOGSメンバーにそれぞれ、差異レポート用の支出レポート・タグを付けます。
Essbaseには、支出と支出外という2つの差異レポート・プロパティが用意されています。デフォルトは支出外です。差異レポート・プロパティでは、メンバーの実績データと予算データの差異を、そのメンバー式の@VAR関数または@VARPER関数を使用してEssbaseで計算する方法を定義します。
メンバーに「支出」のタグを付けた場合、@VAR関数では予算から実績を減算します。たとえば、予算額が$100で、実績の金額が$110の場合、その差異は-10です。
支出レポート・タグを付けなかった場合、@VAR関数では実績から予算を減算します。たとえば、予算額が$100で、実績の金額が$110の場合、その差異は10です。
式は、データベース・アウトラインのメンバー間の関係を計算します。式は、アウトラインのメンバーに適用するか、計算スクリプトに置くことができます。このトピックでは、式を使用してTBCがどのようにパフォーマンスを最適化したかについて説明します。
関数は、専用の計算を実行し、メンバーのセットまたはデータ値のセットを戻す、事前定義ルーチンです。式は、演算子、関数、次元名、メンバー名および数値定数で構成されます。
Essbaseの関数には、Essbaseの計算機能を拡張するための100を超える事前定義ルーチンが組み込まれています。Essbaseでは次の関数をサポートします:
Essbaseでは、集計演算子を使用して、Margin、Total ExpensesおよびProfitメンバーを計算します。Margin%式では、%演算子を使用しています。これは、「MarginをSalesのパーセンテージで表す」を意味します。Profit%式でも同じ%演算子を使用しています。Profit per Ounce式では、除算演算子(/)と関数(@ATTRIBUTEVAL)を使用して、オンス単位で作られた製品の1オンス当たりの収益性を計算します。
演算子、関数および構文の詳細なリストは、『Oracle Essbaseテクニカル・リファレンス』を参照してください。ブロック・ストレージ・データベース用の式の作成も参照してください。
データベース全体の計算を設計するときに、メンバーを動的計算メンバーとして定義できます。メンバーに動的計算タグを付けると、Essbaseでは、通常のデータベース計算時にメンバーの組合せを事前に計算するのではなく、データの取得時にメンバーの組合せを計算します。動的計算によって、通常のデータベース計算にかかる時間は短くなりますが、動的に計算されたデータ値を取得する時間が増える可能性があります。
図35で、TBCのメジャー次元のメンバーProfit、Margin、Total Expenses、Margin %およびProfit %に、動的計算タグが付けられています。
データベース全体の計算を実行すると、動的計算メンバーとそれに対応する式は、計算されません。これらのメンバーは、ユーザーが、たとえばSmart Viewから要求したときに計算されます。Essbaseでは計算された値は保管されません。値は、次の取得時に再計算されます。ただし、最初の取得後に動的に計算された値を保管することを選択できます。
データ値を動的に計算すべきか否かを決定する際、次の点に関する優先度を検討してください:
データ値の動的計算を参照してください。
TBCデータベースでは、Margin %とProfit %にラベル2パスが付いています。このデフォルトのラベルは、一部のメンバー式を2回計算して、目的の値を算出する必要があることを示します。2パス・プロパティは、勘定科目タグが付けられた次元のメンバー、動的計算タグまたは動的計算および保管タグが付けられたメンバーに対してのみ作用します。
次の例では、(式Profit % Salesに基づく) Profit %に2パス・タグが付いている理由を説明します。表には、5つの列(列ヘッダーは左から「次元」、「Jan」、「Feb」、「Mar」、「Qtr1」)と3つの行(「Profit」、「Sales」、「Profit %」)があります。Jan、Feb、MarおよびQtr1は、年次元のメンバーです。Profit、SalesおよびProfit %は、メジャー(勘定科目)次元のメンバーです。
表10では、Essbaseにロードする初期データを定義しています。Profit -> Jan、Profit -> FebおよびProfit -> Marのデータ値は100です。Sales -> Jan、Sales -> FebおよびSales -> Marのデータ値は1000です。
まず、Essbaseでは、メジャー次元を計算します。表11のProfit % -> Jan、Profit % -> FebおよびProfit % -> Marのデータ値は10%です。
次に、Essbaseでは、年次元を計算します。データは、次元全体でロール・アップされます。表12のProfit -> Qtr1 (300)およびSales -> Qtr1 (3000)のデータ値は正しいです。Profit %に2パス計算のタグが付けられているので、Profit % -> Qtr1 (30%)のデータ値は正しくありません。
Essbaseでは、メンバーProfit %の出現ごとに利益パーセンテージを再計算します。表13のProfit % -> Qtr1 (10%)は、2回目のパスが実行された後で正しくなります。
Essbaseのトリガー機能によって、データベース内のデータ変更の効率的な監視が可能になります。トリガー定義の理解を参照してください。 |
設計が確実にユーザー情報の要件を満たすようにするには、データをユーザーに表示されるとおりに表示する必要があります。ユーザーは通常、スプレッドシート、印刷されたレポートまたはWeb上で公開されたレポートを通してデータを表示します。オラクル社およびそのパートナーは、ユーザーが使用するレポート作成システムを生成するための多くのツールを提供しています。
いくつかのツールは、データの表示やフォーマットをすばやく行ったり、データベース設計がユーザーのニーズを満たしているかどうかをテストしたりするのに役立ちます。管理サービス・コンソールにあるレポート・スクリプト・エディタを使用すると、レポート・スクリプトをすばやく記述できます。スプレッドシートに精通しているユーザーは、Smart Viewを使用できます(この場合はProvider Servicesが必要です)。
事前に指定された使用レポートを作成したり、テスト・データに対してテストしたりする場合は、必ず適切なツールを使用するようにしてください。設計したレポートによって、元の目的を満たす情報が提供される必要があります。レポートを使いやすくして、データの適切な組合せと、適切なデータ量が提供されるようにしてください。多数の列や行が含まれているレポートは使用しにくいため、すべてを包含した1つのレポートではなく、複数のレポートを作成することが必要になる場合があります。
データを分析して予備の設計を作成した後、ユーザーとともに設計のすべての側面をチェックします。データベースがユーザーの分析やレポート作成のニーズを満たしていることはすでに確認しているはずです。データベースが、ユーザーのすべての目標を満たしていることを確認します。
計算は、ユーザーが必要としている情報を提供していますか?ユーザーはレポートをすばやく生成できますか?ユーザーは集計回数に満足していますか?つまり、データベースがユーザーのために機能しているかどうかをユーザーに尋ねます。
設計サイクルの終了近くになったら、実際のデータを使用してテストします。アウトラインは正常に構築されますか?すべてのデータがロードされますか?データベースがいずれかの領域で失敗した場合は、設計サイクルの手順を繰り返して問題の原因を識別します。
Essbaseによって、問題の分離に役立ついくつかの情報源が提供されます。これらの情報源には、アプリケーションやEssbaseサーバーのログ、例外ログ、Administration Servicesからアクセス可能なデータベース情報などが含まれます。問題に関連するドキュメントのトピック、たとえば、セキュリティ、計算、レポートまたは一般的なエラー・メッセージに関するトピックを参照してください。このガイドの索引を使用すると、問題の解決に役立ちます。トラブルシューティング、ログ、最適化、パフォーマンス、リカバリ、リソース、エラー、警告などの用語を探してください。