この項の内容:
パーティションは、データベース内にある他のデータベースと共有の領域です。Essbaseパーティション・アプリケーションは、複数のサーバー、プロセッサまたはコンピュータで使用できます。
表33は、Essbaseでサポートされているパーティション・タイプの一覧です:
表 33. パーティション・タイプ
|
パーティション・タイプ |
説明 |
適用先 |
|---|---|---|
|
データ・ターゲットに保管されているデータ・ソースの一部のコピー。 複製パーティションを参照。 |
ブロック・ストレージ・データベース 集約ストレージ・データベース | |
|
ユーザーは、データ・ソース内のデータに、まるでこのデータがデータ・ターゲット内に保管されているかのようにしてアクセスできる。しかし実際のデータは、データ・ソース(別のアプリケーションまたはEssbaseデータベース)、または別のEssbaseサーバー上に保管されている。 透過パーティションを参照。 |
ブロック・ストレージ・データベース 集約ストレージ・データベース | |
|
一方のデータベース内のセルからもう一方のデータベース内のセルにユーザーを送信する。リンク・パーティションを使用することで、データに対して異なる視点が提供される。 リンク・パーティションを参照。 |
ブロック・ストレージ・データベース 集約ストレージ・データベース |
表34は、使用するパーティションのタイプを選択するときに役立つ情報を示しています:
表 34. 各パーティション・タイプでサポートされている機能
|
機能 |
複製 |
透過 |
リンク |
|---|---|---|---|
|
最新データ |
x |
x | |
|
ネットワーク・トラフィックの軽減 |
x |
x | |
|
ディスク・スペースの削減 |
x |
x | |
|
計算速度の向上 |
x | ||
|
より小規模なデータベース |
x |
x | |
|
クエリー速度の向上 |
x |
x | |
|
エンド・ユーザーに表示しない |
x |
x | |
|
異なる次元を持つデータベースへのアクセス |
x | ||
|
リカバリの容易さ |
x | ||
|
同期化の必要性が小さい |
x | ||
|
属性に基づいてデータをクエリーする機能 |
x |
x | |
|
分散型OLAP対応以外のフロントエンド・ツールを使用する機能 |
x |
x | |
|
更新と計算を頻繁に実行することが容易かどうか |
x | ||
|
データ・ターゲット側でデータを更新する機能 |
x |
x | |
|
異なるコンテキストでのデータの表示 |
x | ||
|
バッチ更新や簡単な集約の実行 |
x |
図48と表35に示すように、パーティションには次の部分があります。
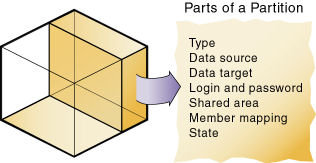
表 35. パーティションの各部分
|
部分 |
説明 |
|---|---|
|
パーティション・タイプが、複製、透過、リンクのどれであるかを示すフラグです。 | |
|
データ・ソースのサーバー、アプリケーションおよびデータベースの名前です。 | |
|
データ・ターゲットのサーバー、アプリケーションおよびデータベースの名前です。 | |
|
データ・ソースとデータ・ターゲットのログインおよびパスワード情報です。この情報は、2つのデータベース間の内部要求で、管理操作およびエンドユーザー操作を実行するために使用されます。 | |
|
データ・ソースとデータ・ターゲットによって共有されている複数の領域の定義です。データベース内の隣接しない複数の部分を共有させるには、単一のパーティション内に複数の領域を定義します。この情報により、データ・ソースとデータ・ターゲットのどの部分が共有されるかが決定します。Essbaseでは、データ・ターゲットに適切なデータを入力して、共有領域のアウトラインの同期を保持できます。 | |
|
データ・ソース内のメンバーをデータ・ターゲット内のメンバーにマッピングする方法の説明です。データ・ターゲットとデータ・ソースが、互いのメンバーや次元に異なる名前を使用している場合、Essbaseではこの情報を使用して、データ・ターゲットにデータを渡す方法が決定されます。 | |
|
パーティションが最新状態になっているかどうかを確認したり、パーティションが最後に更新された日時を確認するための情報です。 |
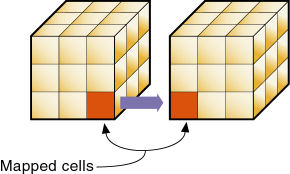
パーティション・データベースには、データ・ソース(データのプライマリ・サイト)とデータ・ターゲット(データのセカンダリ・サイト)が、それぞれ1つ以上含まれています。1つのデータベースが一方のパーティションのデータ・ソース、もう一方のパーティションのデータ・ターゲットとして機能します。パーティションを定義すると、データ・ソース内のセルがデータ・ターゲット内の対応するセルにマッピングされます。
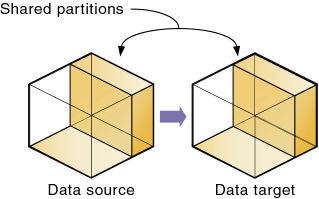
Essbaseデータベースには、複数のパーティションと、他のEssbaseデータベースとは共有されないデータが含まれます。パーティションは、次のデータベース間に定義できます:
同じ2つのデータベース間に各タイプのパーティションを1つずつのみ定義できます。たとえば、Sampeast.EastデータベースとSamppart.Companyデータベースの間には、複製パーティションを1つのみ作成できます。一方、EastデータベースやCompanyデータベースには、他のデータベースに接続する複製パーティションを多数含めることができます。
1つのデータベースが複数のパーティションのデータ・ソースまたはデータ・ターゲットとして機能します。多数のデータベース間でデータを共有させるには、複数のパーティションを作成します。図50に示すように、これらのパーティションのデータ・ソースは共通ですが、データ・ターゲットは異なります:
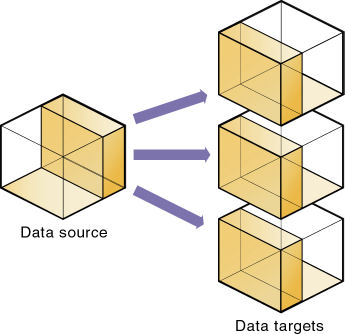
表36に、パーティション・タイプ別に、サポートされているデータ・ターゲットおよびデータ・ソースとして、ブロック・ストレージ・データベースと集約ストレージ・データベースの組合せを記載します:
複数のデータベース内の類似データが、単一パーティション内の単一データ・ターゲットのデータ・ソースになっている場合、このパーティションはオーバーラップ・パーティションになります。
たとえば、データベース1のIDESC East, Salesとデータベース2のBoston, Salesは、データベース3内のIDESC East, SalesとBoston, Salesにマッピングされます。BostonはEast次元のメンバーなので、データベース1とデータベース2からデータベース3にマッピングされたBostonのデータがオーバーラップします。このオーバーラップの結果が、図51に示すようなオーバーラップ・パーティションになります:
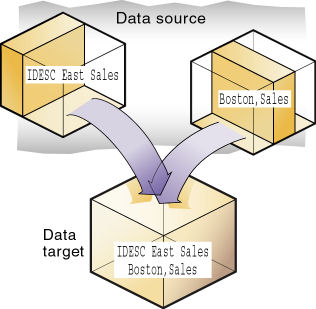
オーバーラップ・パーティションは、リンク・パーティション内では許可されますが、複製パーティションや透過パーティション内では許可されないため、検証中にエラー・メッセージが生成されます。
パーティション定義内で代替変数を使用することにより、そのときどきによって異なるメンバーに基づいたパーティション定義にできます。代替変数は、定期的に変更される情報のグローバル・プレースホルダとして機能します。データベース・マネージャは、各変数に割り当てられた値をいつでも変更できます。たとえば、Curmonthという名前の代替変数を定義して、この代替変数の値を年間の各月のメンバー名Jan、Feb、Marなどに変更できます。この例では、代替変数を使用することでパーティション・サイズが縮小されます。これは、ある月のデータにアクセスする場合、パーティション定義領域にすべての月を含める必要がないからです。
領域定義またはマッピング指定に代替変数を指定するには、「テキスト・エディタの使用」または「インライン編集の使用」オプションを使用します。&Monthのように、代替変数名の先頭に&を挿入します。Essbaseでは、パーティションの確認時に代替値が使用されます。パーティション・データを使用するプロセスを実行すると、Essbaseで代替変数名が値に解決されます。代替変数名を表示するには、パーティション定義を表示します。代替変数の使用を参照してください。
注: | パーティション定義内で代替変数を使用する場合、アプリケーションを再起動するまで変数値はパーティション定義内で固定されたままです。たとえば、&Curmonthの値がJanで、Febに値を変更する場合、パーティション定義内の値はアプリケーションを再起動するまでJanのままです。 |
ブロック・ストレージ・データベースでは、属性関数を使用して属性値によるパーティション化ができますが、属性次元のパーティション化はできません。各メンバーの特性に従って次元メンバーにアクセスするには、属性値を使用してデータベースをパーティション化します。
たとえば、Sample.Basicデータベースでは、Pkg Type属性次元をパーティション化できません。そのかわりに、Pkg Type次元のBottleメンバーとCanメンバー(またはそのどちらか一方)に関連付けられた製品次元のメンバーをすべて含むパーティションを作成できます。Canに関連付けられたメンバーを含むパーティションを作成した場合、缶で出荷される製品メンバー(100-10、100-20および300-30)のデータにのみアクセスできます。
注: | ブロック・ストレージ・データベースの属性メンバーのデータを取得しても、データが存在しないという結果になる場合があります。表18の「存在しない保管ブロックにおける、密の動的計算メンバー」のエントリを参照してください。 |
@ATTRIBUTEコマンドと@WITHATTRコマンドを使用してパーティションを定義できます。
たとえば、Caffeinated属性次元に関連付けられた製品次元のすべてのメンバーのデータを抽出するには、@ATTRIBUTE (Caffeinated)などのパーティションを作成できます。しかし、Caffeinated属性次元はパーティション化できません。
Source Target
@ATTRIBUTE(Caffeinated) @ATTRIBUTE(Caffeinated)
Source Target
Caffeinated Caffeinated
これらのコマンドの詳細は、『Oracle Essbaseテクニカル・リファレンス』を参照してください。
また、属性の操作。も参照してください。
この項の情報を利用して、慎重にパーティションを設計してから、パーティションを実装してください。
ユーザーの要件に基づいて、次の中からパーティション化の方法を選択します:
トップダウンのパーティション化を使用して、複数のプロセッサ、サーバーまたはコンピュータにデータベースを分割します。こうすることにより、データベースの拡張性、信頼性およびパフォーマンスを改善できます。トップダウンのパーティション化で最適な結果を得るためには、パーティション化されたデータベースごとに別々のアプリケーションを作成します。
ボトム・アップ方式によるアプリケーションのパーティション化。
ボトムアップのパーティション化を使用して、関連する複数のデータベース間のデータ・フローを管理します。こうすることにより、データベース内のデータの品質とアクセスを改善できます。
基本次元に関連付けられる属性値に従った、データベースのパーティション化(基本次元は、1つ以上の属性次元に関連付けられる標準の次元です)。
この方式では、次元の特性(種類、サイズなど)に基づいてデータを抽出できます。
注:
属性次元のパーティション化はできません。パーティションにおける属性を参照してください。
次の情報を利用して、データベースをパーティション化するかどうかを決定します。
すべてのデータベースを常時オンラインにしておく必要があります。
複数のタイム・ゾーンにデータベースがある場合、データベースを常にオンラインにしておくのが困難になることがあります。理由は、ユーザー負荷がピークになる時間帯がタイム・ゾーンによって異なる可能性があるからです。この問題は、リンク・パーティションや透過パーティションを使用すると悪化しますが、複製パーティションを使用すると軽減されます。
データベースによって、使用言語やUnicode関連モードが異なっています。
Essbaseでは、各データベースが同じ言語を使用している場合、または各データベースが同じUnicodeモードまたは非Unicodeモードを使用している場合にかぎり、データベースをパーティション化できます。
パーティション化されたデータベースを設計する際は、次の情報を利用して、各パーティションに含めるデータを決定します:
パーティション・データベースの設計のケース・スタディを参照してください。
複製パーティション、透過パーティションまたはリンク・パーティションにアクセスするユーザーは、場合によって、複数のデータベースに保管されたデータを表示する必要があります。次の項では、ユーザーが不適切なデータを表示または変更するのを防止するセキュリティの設定方法について説明します。
正しいフィルタを使用して、必要なエンド・ユーザーを作成します。
Essbaseネイティブ・セキュリティ・モードでのユーザーおよびグループの管理を参照してください。
データ・ターゲット側で読取りフィルタと書込みフィルタを作成し、エンド・ユーザーが表示および更新可能な内容を決定します。
EPM Systemセキュリティ・モードでのユーザーの管理およびセキュリティ。を参照してください。
複製パーティションを作成する場合、データ・ターゲット側の複製パーティションの変更をユーザーに許可するかどうかを決定します。更新設定(更新を許可するまたは許可しない)は、ユーザーにデータの更新を許可するユーザー・フィルタを上書きします。
Oracle Essbase Administration Services Online Helpを参照してください。
create replicated partition MaxLステートメントを使用して複製パーティションを作成するときに、update allow構文を指定しない場合、複製パーティションをデフォルトで更新できません。『Oracle Essbaseテクニカル・リファレンス』を参照してください。
管理サービス・コンソールを使用して複製パーティションを作成すると、複製パーティションをデフォルトで更新できます。Oracle Essbase Administration Services Online Helpを参照してください。
リンク・パーティションを作成する場合、データ・ソース側でユーザー・アカウントを作成します。リンクされたデータベースにアクセスする際、ユーザーは、場合によって複数のデータベースに接続する必要があります。
ドリルとリンク・パーティションを参照してください。
管理アカウントは、データ・ターゲットによって要求されるデータ・ソースの読取りおよび書込み操作をすべて実行します。たとえば、エンド・ユーザーがデータ・ターゲットのデータを要求した場合、管理アカウントはこのデータを取得します。エンド・ユーザーがデータ・ターゲットのデータを更新した場合、管理アカウントはデータ・ソースにログインして、データ・ソースのデータを更新します。
管理アカウントおよびエンド・ユーザーのフィルタを作成できます。管理アカウントのフィルタを適用することにより、データ・ターゲット側のユーザーが不適切なデータを表示または更新するのを防止できます。たとえば、中央のデータベースの管理者が特定のセルへの書込みアクセスを制限した場合、各地域の管理者がエンド・ユーザーごとに正しくセキュリティを設定する手間が省けます。
データ・ソースとデータ・ターゲットの両方に管理アカウントを作成します。
ユーザー名とパスワードの設定を参照してください。
Essbaseでは、このアカウントを使用してデータ・ソースにログインし、データ取得やアウトラインの同期化操作を行います。
読取りフィルタおよび書込みフィルタを作成し、管理者が表示および更新可能なデータを決定します。
EPM Systemセキュリティ・モードでのユーザーの管理およびセキュリティを参照してください。
複製パーティションは、データ・ターゲットに保管されているデータ・ソースの一部のコピーです。一部のユーザーは、データ・ソース内のデータにアクセスできますが、他のユーザーはデータ・ターゲット内のデータにアクセスします。
たとえば、サンプル・アプリケーションSamppartとSampeastでは、The Beverage Company (TBC)のDBAが、EastデータベースとCompanyデータベース間の複製パーティションを作成しています。この複製パーティションには、Actual、Budget、VarianceおよびVariance%が含まれます。現在、東部のユーザーは予算データをローカルに保管しています。データを実際に本社から取得する必要がないので、応答時間が短縮され、ダウンタイムの制御やローカル・データの管理によりいっそう集中できます。ケース・スタディ1: 既存のデータベースのパーティション化を参照してください。
複製パーティション内のデータに対する変更は、データ・ソースからデータ・ターゲットに渡されます。データ・ターゲット内の複製されたデータに対する変更は、データ・ソースには戻されません。ユーザーがデータ・ターゲットでデータを変更した場合、この内容は、DBAが複製パーティションを更新する際、Essbaseによって上書きされます。
複製パーティションが定義されている場合、DBAは、データ・ターゲットの複製された部分のデータが更新されないように設定できます。更新設定(更新を許可するまたは許可しない)は、セキュリティ・フィルタによるアクセス設定より優先されます。また、この設定は、データのロードや計算などのバッチ操作によって履行されます。更新設定のデフォルトの動作は、MaxLまたは管理サービス・コンソールを使用して複製パーティションを作成するかによって異なります。エンドユーザー・セキュリティの設定を参照してください。
ネットワーク・アクティビティの低減
クエリー応答時間の短縮
計算時間の短縮
システム障害からのリカバリの簡便化
複製パーティションが従う必要のあるルールは、次のとおりです:
データ・ソースおよびデータ・ターゲットのアウトラインの共有複製領域をマッピングする必要があります。ただし、共有領域がまったく同じである必要はありません。データ・ソース内の各次元およびメンバーを、データ・ターゲット内の各次元およびメンバーにマッピングする方法をEssbaseに指定する必要があります。
共有でない領域のデータ・ソースのアウトラインとデータ・ターゲットのアウトラインは、マッピングできる必要はありません。
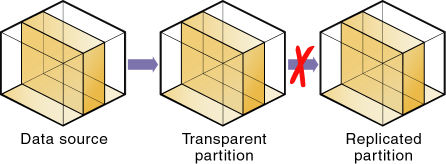
複製パーティションのターゲットとして使用する領域のうち、透過パーティションをソースに持つものはありません。このため、図52に示すように、透過パーティションの上に複製パーティションを作成できません:
複製パーティションのデータ・ターゲット内のセルが、2つのデータ・ソースを持つことはありません。同じパーティション内のセルは、単一のデータベースをソースにしている必要があります。複数のデータベースをソースとするセルを複製するには、データ・ソースごとに異なるパーティションを作成します。
データ・ターゲット内のセルを、別の複製パーティションのデータ・ソースにできます。たとえば、Samppart.CompanyデータベースにSampeast.Eastデータベースの複製パーティションが含まれている場合、Sampeast.East内のセルをSampwest.Westのような3番目のデータベースに複製できます。
属性メンバーを使用して複製パーティションを定義できません。たとえば、Urban、SuburbanおよびRuralは、市場次元に関連付けられたMarket Type属性次元のメンバーです。Urban、SuburbanまたはRuralにパーティションを定義できません。これは、複製パーティションに、保管済のデータではなく動的なデータが含まれるからです。このため、複製パーティション内の属性のマッピングを試行した場合、エラー・メッセージが返されます。ただし、WITHATTRコマンドを使用して、属性データを複製することは可能です。
データが比較的エンド・ユーザーの近くに保管されるので、データ・ターゲット内で、複製パーティションによりネットワーク・アクティビティを減少させることができます。結果として、ユーザーの取得時間が改善されます。
すべてのユーザーは、データにより容易にアクセスできます。一部のユーザーはデータ・ソースのデータにアクセスしますが、他のユーザーはデータ・ターゲットのデータにアクセスします。
障害が発生しても、大きな影響はありません。データが複数の場所にあるので、1つのデータベースで障害が発生しても、そのデータベースに接続しているユーザーが情報にアクセスできなくなるのみです。他のサイトからは、引き続きデータのアクセスおよび取得が可能です。
ローカルのDBAは、ローカルのデータベースのダウンタイムを制御できます。たとえば、東部のユーザーは、Companyデータベースではなく東部固有の複製データにアクセスするので、DBAは、東部のユーザーに影響を及ぼすことなくCompanyデータベースを停止できます。
各サイトには関連データのみが保持されるので、データベースのサイズを小さくできます。たとえば、東部のユーザーは、すべての地域の予算情報が含まれる会社全体の大規模なデータベースにアクセスしないで、東部の予算情報のみを複製できます。
複製パーティションのパフォーマンスを改善するには、次のガイドラインに従ってください:
Essbaseでは、動的に計算されるメンバーとそれらの子をアウトラインの検索により見つけ出して、計算の実行方法を決定する必要があるため、データ・ソース内で動的に計算されるメンバーを複製しないでください。
データ・ソースの計算結果データを複製しないでください。かわりに、各次元について最下位の実用レベルのデータを複製し、複製の完了後にデータ・ターゲット上で計算を実行します。
たとえば、市場次元に沿ってデータベースを複製する方法は、次のとおりです:
共有領域を市場次元の最下位メンバー(East、West、South、Centralなど)および他の次元のレベル0メンバーとして定義します。
複製が完了したら、データ・ターゲット側で市場の値と他の次元内の上位レベルの値を計算します。
データ・ターゲットで計算結果データを計算できない場合もあります。その場合は、データ・ソースからデータを複製します。たとえば、データが次のいずれかの基準を満たしている場合、データ・ソースで計算結果データを計算できません:
複製領域外のデータを計算するように要求する場合。
該当部分のみを抽出することができない計算スクリプトをデータ・ターゲット側で計算するように要求する場合。
ラップトップなどの処理能力の低いコンピュータ上に複製される場合。
集約ストレージ・データベースがターゲット、ブロック・ストレージ・データベースがソースになっていて、2つのアウトラインがまったく同じである場合、集約ストレージ・データベースの複製を最適化するには、次のいずれかの方法を使用します:
essbase.cfg内のREPLICATIONASSUMEIDENTICALOUTLINE構成設定。この設定は、サーバー、アプリケーションまたはデータベース・レベルで有効にできます。設定の構文は次のとおりです:
REPLICATIONASSUMEIDENTICALOUTLINE [appname [dbname]] TRUE | FALSEessbase.cfgファイルの更新の際、変更内容を有効にするには、Essbaseサーバーを停止して再起動する必要があります。
alter database MaxLステートメントとreplication_assume_identical_outline文法。このステートメントはデータベース・レベルでのみ使用可能です。ステートメントの構文は、次のとおりです:
alter database appname . dbname enable | disable replication_assume_identical_outline;alter databaseステートメントを使用する場合、集約ストレージ・アプリケーションを停止して再起動する必要はありません。
最適化の方法は両方とも、ターゲットの集約ストレージ・アプリケーションのみに影響します。ソースのブロック・ストレージ・アプリケーションには影響しません。これらの方法は、ブロック・ストレージの複製には適用されません。
密次元に沿ったパーティション化は、疎次元に沿ったパーティション化よりも時間がかかります。Essbaseでは、密次元に沿ってパーティション化されたデータを複製する場合、複製操作中にデータ・ソース内の各ブロックにアクセスし、これらの各ブロックをデータ・ターゲット内に作成する必要があります。
データ・ターゲットで動的に計算されるメンバーに、データを複製できません。Essbaseでは、動的計算メンバーと動的計算および保管メンバーへのデータのロードや複製は実行されません。実行時にユーザーが要求するまで、これらのメンバーにはデータが含まれないからです。複製データは、データ・ターゲットに保管されないので、Essbaseでは複製先の動的な密メンバーと動的な疎メンバーのどちらにも送信されません。
パーティション全体ではなく変更されたデータ値のみを複製する方法については、複製パーティションの取込みまたは更新を参照してください。
ユーザーは、透過パーティションを使用して、リモートに保管されたデータをローカル・データベース内のデータのように操作できます。リモート・データは、データ・ターゲットのユーザーから要求されるたびに、データ・ソースから取得されます。リモート・データはローカル・データベース内のデータと同様に扱えるので、ユーザーがデータの保管場所は把握する必要はありません。
データはデータ・ソースから直接取得されるので、ユーザーが表示するデータは常に最新のデータです。ユーザーがデータを更新すると、更新内容が再びデータ・ソースに書き込まれます。したがって、データ・ソースの他のユーザーとデータ・ターゲットは、これらの更新にただちにアクセスできます。
透過パーティションでは、ソース・データにアクセスするユーザーが多いほど、データ・ソース側とデータ・ターゲット側の両方でパフォーマンスが低減します。
たとえば、TBCのDBAは、透過パーティションを使用して、別のコンピュータ上にあるシナリオ次元の各メンバーを計算できます。このプロセスでは、ユーザーのデータ・ビューはそのままにして、計算時間を短縮できます。ケース・スタディ1: 既存のデータベースのパーティション化を参照してください。
透過パーティションは、次の目的で使用します:
ユーザーに最新バージョンのデータを提供する場合
データ・ターゲット側のユーザーにデータの更新を許可する場合
ディスク・スペースを削減する場合
透過パーティションが従う必要のあるルールは、次のとおりです:
データ・ソースおよびデータ・ターゲットのアウトラインの共有透過領域がまったく同じである必要はありませんが、これらに含まれる次元をマッピングする必要があります。データ・ソース内の各次元およびメンバーを、データ・ターゲット内の各次元およびメンバーにマッピングする方法をEssbaseに指定する必要があります。
共有でない領域のデータ・ソースおよびデータ・ターゲットのアウトラインは、マッピングする必要はありません。ただし、属性の関連付けは同じである必要があります。そうでない場合、一部の取得で正しい結果が得られない可能性があります。たとえば、製品100-10-1010がソースのGrape Flavor属性と関連付けられているのに、ターゲットのGrape Flavor属性に製品100-10-1010が関連付けられていない場合、New YorkのすべてのGrape Flavorの合計売上高として、正しい結果が得られません。
パーティション定義には、保管済メンバーのみを含める必要があります。属性次元やメンバーを使用して透過パーティションを定義できません。たとえば、市場次元に関連付けられているMarket Type属性次元のメンバーは、Urban、SuburbanおよびRuralです。Urban、SuburbanまたはRural上にパーティションを定義できません。
セルがデータ・ソースからターゲットの集約ストレージ・データベースにマッピングされている場合、このセルのすべての依存項目を同じパーティション定義にマッピングする必要があります。
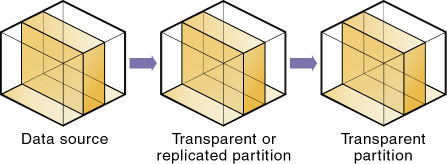
複製パーティションの上に透過パーティションを作成できます。つまり、図54のように、複製パーティションのソースを使用して透過パーティションのターゲットを作成できるということです。
図55に示すように、複数のパーティションの上に透過パーティションを作成できません。これは、複数のソースからは透過パーティションのターゲットを作成できないということです。理由は、データベース内の各セルを、ローカル・ディスクまたはリモート・ディスク上の1箇所から取得する必要があるからです。
データ・ソースとデータ・ターゲット内のメンバーに割り当てる式は、慎重に検討してください。
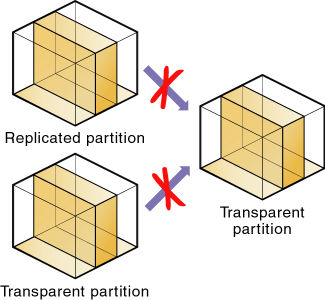
透過パーティションを使用すると、データベースの数多くの問題を解決できますが、透過パーティションが常に理想的なパーティションのタイプとは限りません。
ユーザーがデータ・ソースのデータを更新すると、Essbaseにより、その変更がデータ・ターゲットに対しても適用されます。
データは、エンド・ユーザーやエンド・ユーザーのツールからはわからないように配布されます。
ソースに指定した集約ストレージ・データベースと、ターゲットに指定したブロック・ストレージ・データベース間に透過パーティションを作成することで、集約ストレージ・データベースのライトバック機能を有効にできます。
これらの短所が無視できない場合は、かわりに複製パーティションやリンク・パーティションを使用することを検討してください。
透過パーティションでは、Essbaseによってデータ・ソースのデータがネットワークを通ってデータ・ターゲットに転送されるので、ネットワーク・アクティビティが増大します。ネットワーク・アクティビティが増大すると、ユーザーの取得時間が長くなります。
データ・ソースにアクセスするユーザーが増加するため、取得時間が長くなります。
データ・ソースの障害は、データ・ソースとデータ・ターゲットの両方のユーザーに影響を及ぼします。このため、ネットワークとデータ・ソースは、データ・ソースとデータ・ターゲットのどちらのユーザーが必要とするときでも使用できる必要があります。
一部の管理操作は、ローカル・データにしか実行できません。たとえば、データ・ターゲットをアーカイブする場合、Essbaseでは、データ・ソースではなくデータ・ターゲットのみがアーカイブされます。次の管理操作は、ブロック・ストレージ・データベース内のローカル・データのみに影響を及ぼします:
透過パーティション上で計算を実行すると、Essbaseではローカル・データと透過の依存項目の最新の値を使用して計算が行われます。データ・ソースとデータ・ターゲットのアウトラインの差異が大きすぎて正確な計算結果が得られないので、Essbaseでは透過の依存項目の値は再計算されません。すべてのパーティションを計算するには、個々のパーティションに対してCALC ALLコマンドを発行し、各パーティションの新しい値を使用して、最上位でCALC ALLコマンドを実行します。
次に例を示します:
データ・ターゲットのアウトラインには、East、West、SouthおよびCentralのメンバーからなる市場次元が含まれます。
データ・ソースのアウトラインには、New YorkとNew JerseyのメンバーからなるEast次元が含まれます。
データ・ターゲットのアウトラインの計算を試みる場合は、Eastをレベル0メンバーと想定します。しかし、データ・ソースでは、EastはNew YorkとNew Jerseyの合計によって計算されます。一方、データ・ターゲットでの計算では、この情報は認識されず、データ・ソース内のNew YorkおよびNew Jerseyに加えられた変更は反映されません。正確な計算を行うには、データ・ソース内でEastを計算した後、データ・ターゲットを計算します。
データ・ソースのメンバーに割り当てられた式は、データ・ターゲットで定義された式や集計と矛盾する計算結果を算出する場合があり、これは逆の場合も当てはまります。
透過パーティションのパフォーマンスを改善するには、パーティションの作成時に次のガイドラインについて検討してください:
透過パーティション内の密次元に沿ってパーティション化を行う場合、パフォーマンスがきわめて低くなる可能性があります。これは、密次元がデータ・ブロックの構造とコンテンツを特定するために使用されるからです。データベースをターゲットの密次元のみに沿ってパーティション化する場合、Essbaseでは、透過パーティション内およびブロックのローカル部分のディスクI/Oでリモート・データのネットワーク呼出しを実行して、データ・ブロックを作成する必要があります。
パフォーマンスを向上させるには、領域定義内に1つ以上の疎次元を含ませて、必要なブロック数を疎メンバーとの組合せに限定することを検討してください。
透過パーティションを次元の属性値に基づかせると、属性は疎次元に関連付けられているため、取得時間が長くなることがあります。この場合、属性のレベルより上位のレベルでパーティション化を実行すると、取得時間を短縮できます。たとえば、Sample.Basicデータベースの製品次元で、子100-10、200-10、300-10 (レベル0)が属性に関連付けられている場合、親100、200、300 (レベル1)をパーティション化すると、取得パフォーマンスが改善されます。
データ・ターゲットからデータ・ソースにデータをロードすると、パフォーマンスが大幅に低下します。可能であれば、ローカルでデータ・ソースにデータをロードします。
ユーザーはネットワークを使用してデータにアクセスするため、取得時間が長くなります。
透過パーティションがターゲットの場合、次の構成設定を使用することを検討してください:
データ・ソースから透過パーティション・ターゲット(ブロック・ストレージ・データベースまたは集約ストレージ・データベース)に送信される要求の場合、essbase.cfgファイル内のENABLE_DIAG_TRANSPARENT_PARTITION構成設定を使用して、トランザクションの応答時間をロギングできます。これらのメッセージのロギングは、応答時間がきわめて長くなりトラブルシューティングが必要になった場合に役立ちます。
透過パーティション・ターゲットが集約ストレージ・データベースの場合、MAX_REQUEST_GRID_SIZEおよびMAX_RESPONSE_GRID_SIZE構成設定を使用して、要求グリッドと応答グリッドの最大サイズを指定できます。
基本次元をパーティション化すると、パフォーマンスが大幅に低下します。
透過パーティション計算のパフォーマンス上の考慮事項を参照してください。
透過パーティション上で計算を実行すると、Essbaseではローカル・データと透過の依存項目の最新の値を使用して計算が実行されます。リモート・データに依存するローカル・データを計算するときは、Essbaseでボトムアップの計算が実行されます。ボトムアップの計算は、ターゲット・データベース上で計算機キャッシュが適切に使用されている場合にかぎり実行できます。ボトムアップ計算の使用を参照してください。
計算機キャッシュに割り当てるメモリーを増やすと、透過パーティションでの計算パフォーマンスが大幅に改善されます。計算が開始されると、アプリケーション・ログ・ファイルに、ターゲット・データベース上で計算機キャッシュが有効であるかどうかを示すメッセージが書き込まれます。ターゲット・データベース上で計算機キャッシュを使用すると、計算時にデータ・ソースから要求されるブロック数が減少します。要求されるブロック数が減少すると、ネットワーク経由でブロックを転送することにより発生するネットワーク・トラフィックが減少します。計算機キャッシュのサイズ設定を参照してください。
ネットワークを使用して、データ・ターゲットが個々の依存データ・ブロックを取得して計算を実行する必要がある場合、データ・ターゲット上のデータを計算すると、パフォーマンスが大幅に低下することがあります。
Essbaseで、トップダウンのメンバー式を含むデータ・ターゲットの一部に対してトップダウンの計算が実行される場合にも、透過計算のパフォーマンスは低下することがあります。データ・ターゲットにトップダウンのメンバー式が含まれない場合、Essbaseでは、より実行速度が速いボトムアップの計算がデータ・ターゲットに対して実行されます。
Essbaseでデータ・ソースに対する計算が実行される場合、常にボトムアップの計算を実行できます。トップダウンの計算とボトムアップの計算の比較については、ボトムアップ計算の使用を参照してください。
次の代替計算アプローチの使用を検討してください:
ターゲット・パーティションの計算スクリプトでリモート・データを使用しないことがわかっている場合は、計算スクリプト内でSET REMOTECALC OFF計算コマンドを使用して、ソース・パーティションからの取得を停止できます。『Oracle Essbaseテクニカル・リファレンス』を参照してください。
動的計算メンバーまたは動的計算および保管メンバーを透過データの親として使用し、取得時にただちにデータが計算されるようにします。このプロセスにより、バッチ処理時間が短縮されます。Essbaseでは、この計算はユーザーが要求した場合にかぎり実行されます。
下位レベルの透過データと上位のローカル・データ間に複製レイヤーを使用します。
次のパフォーマンス戦略を検討してください:
計算機キャッシュ領域内に、パーティションを完全に確保します(計算機キャッシュのサイズ設定を参照)。つまり、パーティション定義に含まれるすべての疎メンバーが計算機キャッシュ内に含まれるようにする必要があります。たとえば、Sample.Basicデータベース内で、パーティション定義に@IDESC(East)が含まれる場合、Eastのすべての子孫を計算機キャッシュに含める必要があります。
計算機キャッシュを使用可能にし、十分なメモリー量を計算機キャッシュに割り当てます。
パーティションを定義するメンバーに対しては、複素数式を使用しないでください。たとえば、Sample.Basic内で、New YorkまたはNew Jersey (どちらもEastの子)に対して複素数式を割り当てた場合、Essbaseでは強制的にトップダウンの計算方式が採用されます。ボトムアップ計算とトップダウン計算を参照してください。
メンバー式が異なる点を除いて、データ・ターゲットとデータ・ソースのアウトラインがまったく同じである場合は、パーティション定義により意図したとおりの計算結果が出ることを確認してください。
たとえば、データ・ソースとデータ・ターゲットの両方のアウトラインに、North、South、Northの子、Southの子をメンバーとして持つ市場次元が含まれているとします。データ・ターゲット上で、市場は、データ・ソース上のNorth、Southおよびその子メンバーのデータから計算されます。データ・ソース上のこれらのメンバーのいずれかにメンバー式が含まれる場合、データ・ターゲット上の市場の計算結果に影響が及びます。この計算結果は、メンバー式が含まれない、データ・ターゲット上のNorthおよびSouthメンバーから計算された市場メンバーの値とは異なっている可能性があります。
データ・ソースとデータ・ターゲット内のメンバーに割り当てる式により、意図したとおりの結果が出ることを確認してください。
一意のユーザーとマシンの組合せに対して、ポート1つが使用されます。ユーザーが、同じユーザー名を使用して、1台のサーバー上に複数の透過パーティションを定義した場合、1つのポートのみが使用されます。
透過パーティション内で、ユーザー(user1)がターゲット内のソース・データにアクセスする領域をドリルする場合、user1はパーティション定義内に宣言したユーザー名(パーティション・ユーザー)を使用して、ソース・データベースからデータにアクセスします。このアクセスにより、追加のポートが使用されます。理由は、異なるユーザー(user1とパーティション・ユーザー)がアプリケーションに接続しているからです。
2番目のユーザー(user2)がターゲット・データベースに接続し、ドリル・ダウンしてソース・データにアクセスする場合、user2もパーティション定義内に宣言したユーザー名(パーティション・ユーザー)を使用します。パーティション・ユーザーはすでにソース・データベースに接続しているので、user2が同じソース・データベースにアクセスしているかぎり、パーティション・ユーザーの追加ポートは不要です。
リンク・パーティションは、データ・セルを使用して2つのデータベースに接続します。データ・ターゲット内のリンク・セルをクリックすると、2番目のデータベース(データ・ソース)のドリルが実行され、そのデータが表示されます。たとえば、Smart Viewを使用している場合、リンク・パーティションを起動すると、リンクされたデータベースの次元を表示する新しいスプレッドシートが開きます。ここから、リンクされたデータベースの次元にドリル・ダウンできます。
複製パーティションや透過パーティションの場合と異なり、リンク・パーティションでは、データ表示がターゲット・データベースと同じ次元に制限されていません。リンク先のデータベースには、接続元のデータベースとは異なる次元が含まれていてもかまいません。リンク・パーティションでは、ソースからターゲットへの物理的なデータ転送は行われません。そのかわり、ターゲットのデータ・セルまたはセル範囲により、ソースのセルまたはセル範囲へのリンク・ポイントが提供されます。
ユーザーが特権付きデータを表示するのを防ぐには、データ・ソースおよびデータ・ターゲット上にセキュリティ・フィルタを設置します。パーティション・データベースのセキュリティを参照してください。
各リンク・データベースのパフォーマンスを最適化する以外に、リンク・パーティションのパフォーマンスに関する考慮事項はありません。
たとえば、TBCが大企業に成長した場合、複数の事業所が設けられる可能性があります。一部のデータ(収益と販売など)は各事業所に存在します。全社の収益と販売を一目で把握できるように、TBCはこのデータを中央のデータベースに保管できます。DBAは事業所データベースを会社のデータベースにリンクできます。ケース・スタディ3: 2つのデータベースのリンクを参照してください。
このようなケースでは、ユーザーは次のようなタスクを実行できます:
データ・ターゲット側のスプレッドシートに全社レベルの全体的な収益と販売を表示します。
Eastなど、個々の事業所をドリルして、新しいスプレッドシートを開きます。
新しいスプレッドシートをドリル・ダウンし、詳細データを取得します。
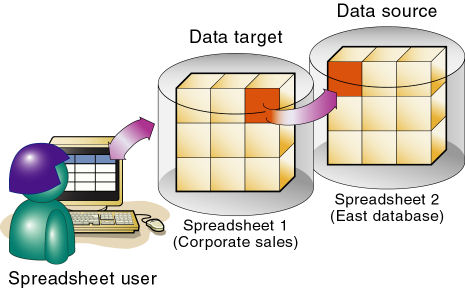
リンク・パーティションの場合、ユーザーが最初に表示するスプレッドシートはデータ・ターゲットに接続され、ユーザーがドリルすることによって開くスプレッドシートは、データ・ソースに接続されます。これは、データ・ターゲットからデータ・ソースに移動する複製データベースや透過データベースの設定とは正反対です。
データベースを異なる次元に接続するには、リンク・パーティションを使用します。
各データベース上でユーザー・アカウントを作成するか、目的のデータベースに対するデフォルトのアクセスを使用します(ゲスト・アカウントなどを使用)。ドリルとリンク・パーティションを参照してください。
ユーザーがリンク・パーティション内のリンク・セルをクリックすると、スプレッドシートが開き、リンク・データベースが表示されます。このプロセスをドリルと呼びます。次の方法により、ドリル・アクセスを容易化できます:
各データベース上に各ユーザーのアカウントを作成します。たとえば、MaryがCompanyデータベースとEastデータベースのデータにアクセスする場合、CompanyデータベースとEastデータベース上にMary用として同じログインとパスワードを持つアカウントを作成します。
Essbaseネイティブ・セキュリティ・モードでのユーザーおよびグループの管理を参照してください。
ユーザーがターゲット・データベースにアクセスするときに使用できるデフォルト・アカウントを作成します。たとえばCompanyという名前のデータ・ソースとEastという名前のデータ・ターゲットからデータにアクセスする場合、適切な権限を持つEastのゲスト・アカウントを作成します。リンク・パーティションを作成するときは、このゲスト・アカウントのログインとパスワードをデフォルト・ログインとして使用します。
ユーザーが、データ・ターゲットのデータをドリルするとき、Essbaseでは、次の手順を使用して、データ・ターゲットにアクセスするユーザーのログを取ります:
ユーザーがデータ・ターゲット上に同じ名前とパスワードのアカウントを持っているかどうかを確認します。持っている場合、ユーザーはそのアカウントを使用してEssbaseにログインできます。
ユーザーがパーティションを作成したとき、データ・ターゲット上にデフォルト・アカウントを指定したかどうかを確認します。デフォルト・アカウントを指定している場合、ユーザーはそのアカウントを使用してEssbaseにログインできます。
新しいログインとパスワードの入力を求めるログイン・ウィンドウを開きます。ユーザーが有効なログインとパスワードを入力すると、そのアカウントを使用してEssbaseにログインできます。
Essbaseでは、リンク・パーティションにアクセスする際、エンド・ユーザー(user1)のログイン情報を使用してソース・データベースへの接続が試行されます。user1がソース・データベースにアクセスできない場合は、Essbaseによりリンク・パーティションのデフォルトのユーザー名とパスワードが検索されます。これらのデフォルトが指定されていない場合、user1はソース・データベースにアクセスするためのログイン情報を入力するように求められます。ポートの使用状況は、様々なソースおよびターゲット・データベースにアクセスするために使用されているユーザー名の数(とこれらのデータベースが同一サーバー上にあるか、別々のサーバー上にあるか)によって異なります。
次の項では、データベースをパーティション化する例について説明します:
Sample.Basicデータベースの基になっている架空の清涼飲料水製造会社TBCは、創業時から集中管理データベースを使用していました。ところが、東部地区での事業が成長したため、このソリューションでは対応できなくなりました。東部地区に対するネットワークは、大規模なデータ・フローを処理できませんでした。ユーザーは、常に意志決定に必要なデータを待機していました。ある日、ネットワークがダウンし、東部地区のユーザーはデータにアクセスできなくなりました。
このことが契機となり、会社全体のデータベースにアクセスするのではなく、東部地区固有のデータに直接アクセスできるようにする必要があるという合意が得られました。さらに、TBCは、予算設定情報の保管場所を変更することを決定しました。会社全体の予算設定情報は本社に残しますが、東部地区の予算設定方法は東部地区のデータベースに移動することになりました。
その結果、大規模な集中管理データベースを、2つの小規模なデータベース(CompanyおよびEast)にパーティション化する要求が出されました。
この例では、Companyデータベースを含むSamppartサンプル・アプリケーションと、Eastデータベースを含むSampeastサンプル・アプリケーションを基にしています。
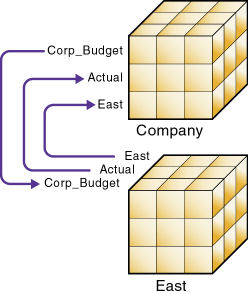
図58は、パーティション化されたデータベースのサブセットです。矢印は、データ・ソースからデータ・ターゲットへのフローを示します。Companyデータベースは、Corp_Budgetメンバーのデータ・ソースであると同時に、EastおよびEast Actualメンバーのデータ・ターゲットです。Eastデータベースは、EastおよびActualメンバーのデータ・ソースであると同時に、Corp_Budgetメンバーのデータ・ターゲットです。
TBCには、Inventory、Payroll、Marketing、Salesなどの複数のデータベースがあるとします。Sample.Basicデータベースを表示するユーザーは、複数のデータベースでの情報の共有と、他のデータベースへの移動機能を必要としています。この場合、DBAは関連データを同期化する必要があります。すべてのデータベースを1つのデータベースにまとめるのは実際的ではありません。次に、その理由を示します:
 複数のデータベースにアクセスするには:
複数のデータベースにアクセスするには:
TBCには、Sample.BasicとTBC.Demoの2つのメイン・データベースがあるとします。2つのデータベースのアウトラインはよく似ていますが、TBC.Demoには次の2つの次元が追加されています:
Channel (製品の販売地域を説明)
Package (製品の出荷形態を説明)
Sample.BasicのDBAは、その他のユーザーもSample.Basicに対するチャネル情報の追加を要求していることを認識します。ただし、チャネル情報に関するデータを所有していないため、対応が困難です。かわりに、すでにチャネル情報が含まれているTBC.Demoデータベースへのリンクを許可することにしました。
2つのデータベースをリンクするには:
DBAは、Sample.Basicの製品次元をTBC.Demoの製品次元にリンクすることを決定しました。
このため、ユーザーは、TBC.DemoをドリルしてChannelとPackageの情報を表示できるようになりました。
ユーザーはSample.Basicデータベースで開始しているため、データ・ターゲットとみなされます。ユーザーはTBC.Demoに移動するため、データ・ソースとみなされます。
Sample.Basicの製品メンバーからTBC.Demoの製品次元へのリンクを確立します。TBC.Demoの追加次元であるChannelとProductをSample.Basic内のVoidにマッピングする点に注意してください。次元数の異なるデータ・キューブのマッピングを参照してください。
TBC.Demo上に、Sample.Basicから接続するユーザーにChannel次元とPackage次元へのアクセスを提供するゲスト・アカウントを設定します。アカウントの作成に関する一般情報については、Essbaseネイティブ・セキュリティ・モードでのユーザーおよびグループへの権限の付与を参照してください。リンク・パーティションにアカウントを割り当てる方法については、パーティション・タイプの選択を参照してください。