この章で示す情報は、集約ストレージ・アプリケーション、データベースおよびアウトラインに適用され、これらのプロセスとブロック・ストレージ・プロセスにどのような違いがあるかに関する情報も含まれています。
集約ストレージのアプリケーションおよびデータベースと、ブロック・ストレージのアプリケーションおよびデータベースには、概念と設計の点で違いがあります。一部のブロック・ストレージのアウトライン機能は、集約ストレージには適用されません。たとえば、密次元と疎次元の概念は適用されません。集約ストレージとブロック・ストレージの比較を参照してください。
新しいサンプル・アプリケーション(ASOsamp)、データ・ファイルおよびルール・ファイルを使用して、集約ストレージの機能を説明します。
このトピックでは、集約ストレージ・アプリケーションを作成するためのプロセスの概略を説明します。
集約ストレージ・アプリケーション、データベースおよびアウトラインを作成します。
集約ストレージ・アプリケーション、データベースおよびアウトラインの作成を参照してください。
テーブルスペースを使用して、データの格納および取得を最適化します。
集約ストレージ・アプリケーションのストレージ管理を参照してください。
集約ストレージ・キャッシュの管理を参照してください。
集約ストレージ・データベース内にデータをロードします。データ・ロードは次元構築と組み合せることができます。
集約ストレージ・データベースの準備を参照してください。データのサブセットはAdministration Servicesでプレビューできます。Oracle Essbase Administration Services Online Helpの「データのプレビュー」を参照してください。
集約ストレージ・データベースの計算を参照してください。
Oracle Essbase Administration Services Online Helpの「集約ストレージ統計の表示」を参照してください。
集約ストレージ・データベースを組み込むための、集約ストレージ・アプリケーションを作成する必要があります。集約ストレージ・アプリケーションに組み込めるのは、1つのデータベースのみです。集約ストレージのアプリケーション、データベースおよびアウトラインは、次の方法で作成できます:
ブロック・ストレージ・アウトラインを集約ストレージ・アウトラインに変換してから、変換したデータベースとアウトラインを含める新しい集約ストレージ・アプリケーションを作成します。
Essbaseでは、ブロック・ストレージ・アウトラインから集約ストレージ・アウトラインに変換する次のシナリオがサポートされています:
非Unicodeブロック・ストレージ・アウトラインから、非Unicode集約ストレージ・アウトライン
非Unicodeブロック・ストレージ・アウトラインから、Unicode集約ストレージ・アウトライン
Unicodeブロック・ストレージ・アウトラインから、Unicode集約ストレージ・アウトライン
次の変換シナリオはサポートされていません:
Unicodeブロック・ストレージ・アウトラインから、非Unicode集約ストレージ・アウトライン
集約ストレージ・アウトラインから、ブロック・ストレージ・アウトライン
集約ストレージ・アプリケーションおよびデータベースを作成します。集約ストレージ・アウトラインは、データベースを作成すると自動的に作成されます。
集約ストレージ・アウトラインへの次元とメンバーのロードの詳細は、集約ストレージ・データベースでの次元構築および集約ストレージ・データベースへのデータのロードを参照してください。
集約ストレージのアプリケーションとデータベースの情報は、ブロック・ストレージの情報とは異なり、集約ストレージのアプリケーションとデータベースには特有の命名規則が適用されます。表 191を参照してください。
集約ストレージ・アプリケーション、データベースおよびアウトラインを作成する際は、集約ストレージとブロック・ストレージの相違点と、集約ストレージに固有の問題について考慮してください。次の項と、集約ストレージの時間ベースの分析。も参照してください。
集約ストレージ・アウトラインとブロック・ストレージ・アウトラインでは、次元はレベル内の関連レベルおよびメンバーの1つ以上の階層が含まれるように構造化されます。たとえば、ASOsamp.Sampleデータベースの時間次元(図155を参照)には、階層MTD、QTDおよびYTDが含まれています。
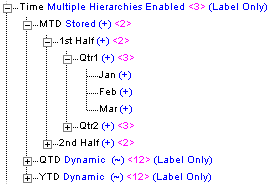
集約ストレージ・データベースでは、次の2つのタイプの階層を作成できます:
この2つのタイプの階層の利点と制限には違いがあります。次元には両方のタイプの階層を含まれることがあります。次元内で複数階層を使用するには(すべて保管階層の場合も)、その次元で複数階層を使用可能にする必要があります。
次元メンバーに「複合階層: 使用可能」タグを付けると、ラベルのみのタグが自動的に付けられます。
次元に「複合階層: 使用可能」タグを付けない場合は、Essbaseによって、次元に保管階層タグが自動的に付けられます(動的階層のタグが自動的に付けられる、勘定科目タグが付けられた次元を除く)。
保管階層のメンバーは、アウトライン構造に従って集約されます。集約ストレージ・データベースは集約のために最適化されているため、保管階層のデータ値の集約は非常に高速で行われます。この高速な集約を可能にするため、保管階層のメンバーには次のような制限があります:
保管階層には、ラベルのみメンバーに対する制限があります。表192を参照してください。
図156では、「All Merchandise」階層と「High End Merchandise」階層は保管階層です。「All Merchandise」メンバーと「High End Merchandise」メンバーは階層の最上位で、両方とも保管階層の最上位としてタグ付けされています。
保管階層の最上位のタグは、次のメンバーに付けることができます:
動的階層を評価する際、Essbaseでは、集約ではなく、メンバーと式が計算されます。メンバーと式が評価される順序は、解決順プロパティによって定義されます。計算順序を参照してください。
取得時に、Essbaseによって、必要なメンバーの組合せが計算されてから、任意の必要なアウトライン・メンバー式が計算されます。動的階層が計算されるため、保管階層からデータを取得する場合よりも、データの取得時間が長くなる場合があります。ただし、データベースを設計する場合、動的階層には次のような利点があります:
動的階層の最上位のタグは、次のメンバーに付けることができます:
勘定科目のタグが付けられた次元は、自動的に動的階層とみなされます。会計次元は、保管階層としては指定できません。
Essbaseでは、集約ビューの動的階層メンバーは選択できません。集約ストレージ・データベースの集約を参照してください。
属性次元として。属性を使用して、次元内のメンバーを論理的に分類します(たとえば、製品次元は、サイズや種類などの属性を持つことができます)。属性の操作。を参照してください。
共有メンバーの階層として。代替階層には、アウトライン内の以前の階層の非共有メンバーを参照する、共有メンバーが含まれます。共有メンバーは、それらが参照する非共有メンバーとは異なる階層に従ってロール・アップを行います。動的階層の共有メンバーは式を持つことができます。共有メンバーの理解を参照してください。表198は、ASOsamp.Sampleデータベースの階層を示しています。この「Products」次元は、図156に示されています。
表 198. ASOsamp.Sampleの「Product」次元の階層と代替階層の例
|
Products、All Merchandise、Personal Electronics、Home Entertainment、Televisions | ||
|
Products、All Merchandise、Personal Electronics、Home Entertainment、Televisions |

集約ストレージ・アウトラインに代替階層を作成するときには、次のような制限が適用されます:
メンバーの非共有インスタンスは、アウトライン内で、メンバーの共有インスタンスより前に存在する必要があります。たとえば、図156では、メンバー「HDTV」は、「High End Merchandise」の代替階層内の共有メンバーとして表示される前に、「All Merchandise」階層内に表示されます。
値が二重計算されないようにするため、保管階層に同じ共有メンバーの複数のコピーを含めることはできません。たとえば、保管階層に共有メンバーとその祖先のいずれかを含めることはできません。図156の場合、共有メンバー「Televisions」を「High End Merchandise」の子として追加はできません。このように追加すると、「Televisions」がその子である共有メンバー「Flat Panel」および「HDTV」の兄弟になり、「Flat Panel」と「HDTV」の値が2回追加されるためです。
メンバーの非共有インスタンスは、共有メンバーと同じ次元に存在している必要があります(ブロック・ストレージ・アウトラインと同じ)。
動的階層のメンバーが式を持たないレベル0メンバーの場合にのみ、動的階層のメンバーの共有インスタンスを保管階層に含めることができます。
集約ストレージ・データベースでは、共有メンバーはその非共有メンバーと関連付けられている属性を自動的に共有します。これは、暗黙の共有メンバー(たとえば、1つの子のみを持つメンバー)にも適用されます。暗黙的な共有の理解を参照してください。暗黙的な共有は、「共有しない」プロパティを設定することで防ぐことができます(メンバーによるデータ値の保管方法の決定を参照)。集約ストレージ・データベースでのこのような共有メンバーと属性の動作は、ブロック・ストレージ・データベースでの動作とは異なります。 |
このトピックでは、属性次元に関しての集約ストレージとブロック・ストレージのデータベースの相違点について説明します。このトピックの情報を利用するには、ブロック・ストレージ・データベースの属性次元の概念に精通している必要があります。属性の操作。を参照してください。
次の情報は、集約ストレージ・データベースで使用する属性次元に適用されます:
属性次元には階層タイプはありません。属性次元を動的階層または保管階層として指定できません。Essbaseでは、属性次元は基本次元の保管代替階層として扱われます。たとえば、Essbaseでは、ASOsamp.Sampleデータベースの「Store Manager」属性次元は、「Store Manager」次元が「Stores」次元の保管代替階層であるかのように扱われます。
クエリーの追跡の使用時には、Essbaseにより属性次元データに対するクエリーが考慮され、集約ビュー選択の属性次元メンバーが組み込まれる場合があります。使用状況に基づいたビューの選択および集約ストレージ・データベースの計算を参照してください。
属性のクエリー・データに基づいてビューを選択および構築する際には、属性データに対する一部のクエリーは取得時に常に動的に計算されるため、クエリー・パフォーマンスに影響を与える場合があります。
属性次元メンバーを含むすべてのクエリーには、基本次元のメンバーを少なくとも1つ含める必要もあります。クエリーに単一の属性次元と次元の合計メンバーが含まれている場合は、Essbaseによって、そのクエリー・データが集約されるため、クエリー・パフォーマンスが向上する可能性があります。その他の場合は、Essbaseによって取得時にクエリーが計算される必要があります。
表199で、属性クエリーのタイプと、Essbaseでのクエリーの計算方法について説明します:
図157で表示されているアウトラインでは、「RealDimension」はその子孫すべての合計です(ラベルのみのタグは付けられません)。クエリーに単一属性次元(たとえば、「AttributeDimension1」)の1つ以上のメンバーが含まれ、それが基本次元メンバー(「RealDimension」)と交差している場合は、Essbaseでそのデータの集約セルを構築できるため、クエリー・パフォーマンスが向上する可能性があります。

このトピックでは、集約ストレージ・データベース・アウトラインを作成する際の、設計に関する重要な考慮事項を記載ます。これらの設計の考慮事項の実施例については、ASOsamp.Sampleデータベースを参照してください。集約ストレージ・アウトラインを設計する際は、次の情報について考慮してください:
階層数を最小限にします(保管階層を追加するたびにビューの選択が遅くなり、集約データのサイズが大きくなる可能性があります)。
階層が最初の階層の小さいサブセットの場合は、その小さい階層を動的階層にすることを検討してください。考慮事項には、階層データがクエリーされる頻度と、その階層データが取得時に動的にクエリーされる際のクエリー・パフォーマンスの影響があります。
基本メンバーに対する属性の関連付けレベルが高いほど、クエリーの取得が速くなります(属性クエリーに関する設計時の考慮事項も参照)。
複数階層がある次元のデータをクエリーする場合は、次の方法でデータをクエリーするとクエリー・パフォーマンスが向上する場合があります:
動的階層のメンバーと保管階層のメンバーを同じクエリーに含めると、大量の内部メモリー・キャッシュが必要になって、クエリー・パフォーマンスが低下する可能性があります。
集約ストレージ・データベース・アウトラインは1つの次元について64ビットを超えることはできません。
ある次元に必要なビット数は、代替階層および関連付けられた属性次元のレベル0の子を含む、あらゆるレベル0の子で使用される中で最大のビット数になります。メンバーを番号付けする目的のため、属性次元はその基本次元の代替階層として扱われます。
通常、ある次元の任意のメンバーに必要なビット数を求める式は次のように表されます:
#_bits_member’s_parent + log(
x
)
ここで、xは親に属す子の数です。
たとえば、メンバーの親がメンバーAで、5ビットが必要であり、Aに10の子がいる場合、個々の子に必要なビット数は次のようになります:
5 +log(10) = 9 bits
次元または階層の最上位のメンバーは通常、0ビットを使用します。ただし、ラベルのみメンバーで構成されている最上位の世代が1つ以上あるとき、ラベルのみメンバーは、(保管済メンバーとみなされないため)メンバー番号を受け取りません。したがって、ラベルのみではない最初の世代にxメンバーがいる場合、このメンバーはlog(x)ビットを使用します。このメンバーの下の残りの子は正常に番号付けされます。
同様に、次元または階層が動的な場合、保管または共有されたレベル0メンバーのみがメンバー番号を受け取ります。このメンバーに必要なビット数はlog (x)で、xは保管または共有されたレベル0メンバーの数(つまり、式メンバーではないレベル0メンバーの数)を表します。
ただし、代替階層が(非共有の)レベル0メンバーを保管している場合、次元(関連付けられた属性次元を含む)内の全階層の各メンバーは追加のlog (x)ビットを使用します。ここでxは、この基本次元に対する階層および関連付けられた属性次元の合計数を表します。
次の例では、ASOsamp.SampleデータベースのProducts次元を使用します:

Products次元には次の2つの階層があります: All MerchandiseおよびHigh End Merchandise (High End Merchandiseは代替階層)。High End Merchandiseには次の1つの保管済レベル0メンバーがあります: Stored Member。Products次元には関連する属性次元はありません。
メンバーのAll MerchandiseおよびHigh End Merchandiseはlog(2) = 1ビットを使用します。
注: | 代替階層High End Merchandiseに保管済のレベル0メンバーがなかった場合、各階層(および関連付けられた属性次元)の最上位メンバーは、それぞれ0ビットを使用します。 |
それぞれのレベル0の子で必要なビット数の計算は次のようになります:
All Merchandise = 1 bit
Personal Electronics, Home Entertainment, Other = 1 + log(3) = 3 bits
Digital Cameras/Camcorders, Handhelds/PDAs, Portable Audio = 3 + log(3) = 5
Children of Digital Cameras/Camcorders = 5 + log(3) = 7
Children of Handhelds/PDAs = 5 + log(3) = 7
Children of Portable Audio = 5 + log(2) = 6
Televisions, Home Audio/Video = 3 + log(2) = 4
Children of Televisions = 4 + log(5) = 7
Children of Home Audio/Video = 4 + log(4) = 6
Computers and Peripherals = 3 + log(1) = 3 **
Systems, Displays, CD/DVD drives = 3 + log(3) = 5
Children of Systems = 5 + log(2) = 6
High End Merchandise = 1 bit
Flat Panel, HDTV, Stored Member = 1 + log(3) = 3 bits
メンバーのComputers and Peripheralsは、その親Otherと同じビット数(3)になります。
Products次元のレベル0の子で使用される最大のビット数は7 (Digital Camerasの子およびTelevisionsの子)です。したがって、Productsは7ビットを使用することになり、これは64ビットの次元サイズ制限を下回ります。
次元サイズが64ビットを超えると、次のようになります:
Essbaseで、アウトラインの保存時に次のエラーが発生します:
Hierarchy [DimensionName] is too complex. It exceeds the maximum member number width of 64 bits. See application log for details.
Essbaseで、次のメッセージに類似したメッセージがアプリケーション・ログに記録されます:
Member number for member [level0member] requires [65] bits to encode Member [level0member] contributes [5] bits to member number Member [level1parent] contributes [20] bits to member number Member [level2parent] contributes [20] bits to member number Member [level3parent] contributes [20] bits to member number
エラーを修正するには、次のいずれかの推奨操作を使用します:
可能な場合は、メッセージで参照されているいずれかのメンバーの兄弟をいくつか削除します。兄弟の数を2の累乗ずつ削除すると、1ビット節約できます。たとえば、メンバー番号に対して5ビットを占めているlevel0memberに、それ自身も含めて18の兄弟があると仮定します。兄弟の数を16以下に削除すると、log(16) = 4のため、1ビット節約できます。同様に、兄弟の数を8以下に削除すると、2ビット節約できます。
メッセージで参照されているメンバーの兄弟をいくつか再分類します。たとえば、level0memberの18の兄弟の半数を、それほど多くの子を持たない別の親に移動します。もしくは、level1parentの1兄弟として新規の親を作成し、level1parentの子の半数を新規メンバーの元に移動します。このアプローチでは1ビット節約できます。
中間レベルをいくつか結合します。たとえば、level0memberとその兄弟すべてをlevel2parentの子に移動してから、level1parentを削除します。このアプローチはさらに複雑ですが、多くのビットを節約できます。
デフォルトでは、集約ストレージ・データベース内の圧縮次元は会計次元です。圧縮次元を変更すると、データベース全体の再構築がトリガーされます。Essbaseでは、圧縮次元が単一の動的階層である必要があります。次元に複数階層のような別の階層設定がある場合、その次元は自動的に単一の動的階層に設定されます。元の設定は失われます(別の次元を圧縮と設定しても、下の階層設定は戻りません)。属性次元は、圧縮次元にすることはできず、属性が関連付けられている次元にすることもできません。
圧縮次元の選択は、パフォーマンスに大きな影響を与えることがあります。圧縮次元の適切な候補は、取得パフォーマンスを維持しながら、データ圧縮を最適化するものです。このトピックでは、最適な圧縮次元の選択に関する情報を説明します。
このトピックの情報は、ロード済データベースに適用されます。集約ストレージ・データベースへのデータのロードを参照してください。 |
圧縮次元は動的に計算されるため、圧縮次元を選択する際は、動的に計算される次元の設計に関する考慮事項を検討する必要があります。動的次元は取得時に計算されるため、データの取得時間は保管階層の場合よりも長くなります。
多数のレベル0のメンバーを持つ次元に圧縮のタグが付いている場合、上位レベルのクエリーには時間がかかります。これは、それらのクエリーで多数のレベル0のメンバーを取得する必要があるためです。ユーザーが大きな次元で多数の上位レベルの取得を行う予定の場合、これは圧縮次元として推奨される候補ではありません。
圧縮次元を選択する際のもう1つの考慮事項は、データベースがどの程度圧縮されるかです。圧縮されたデータベースのサイズは、どの次元に圧縮のタグを付けるかによって変わります。
Administration Servicesでは、圧縮の概算を表示してから、同じダイアログ・ボックスで圧縮次元を選択できます。Administration Servicesで新しい圧縮次元を選択すると、アウトラインが自動的に再構築されます。
Administration ServicesとMaxLでは、詳細な圧縮およびクエリー統計を表示できます。保管されるレベル0のメンバー(取得パフォーマンスに影響する)、バンドル量の平均値と値の長さの平均値(圧縮に影響する)およびレベル0のサイズを表示できます。
次の項では、圧縮およびクエリーに関連する各統計について説明します。
保管されるレベル0のメンバーが多数ある次元は、圧縮のタグが付いていると適切に実行されません。動的に計算される次元と同様、圧縮次元からの上位レベルの取得は、通常は時間がかかります。取得パフォーマンスの維持を参照してください。
圧縮の効果が高いのは、値の間に多数の#MISSINGデータがあるアウトライン全体ではなく、次元または階層の連続したメンバー内で値をグループ化する場合です。Essbaseでは、グループの場所とコンテンツをメンバーのそれぞれに個別に保存するのではなく、それらに関する情報を保管することによって、メモリーを節約します。バンドル量の平均値は、グループに保管される値の平均数です。この値は、1から16まで変わることがあり、16が最適です。バンドル量の平均値が高い圧縮次元を選択することは、データベースがより適切に圧縮されることを意味します。
一部のアウトラインでは、圧縮次元内の数値を、頻繁に取り込まれるメンバーがグループ化されるように順序付けることによって、圧縮を改善できます。取り込まれるメンバーがグループ化されていると、より多くのメンバーが各バンドルに組み込まれるため、バンドル量の平均値が大きくなり、圧縮が改善されます。
値の長さの平均値は、セルに保管された値に必要な、バイト単位の平均ストレージ・サイズです。この値は、2バイトから8バイトまでで変わることがあり、2バイトが最適です。圧縮していない場合、セル内の値を保管するには8バイト必要です。圧縮する場合は、必要なバイト数は値の長さに応じてさらに小さくなります。たとえば、10.050001では、圧縮されている場合でも保管するには8バイト必要ですが、10.05では、圧縮されている場合は保管するために2バイト-4バイトのみですみます。値の長さの平均値が小さい次元では、データベースはより適切に圧縮されます。
データ値を小数点以下2桁に四捨五入すると、値の長さの平均値が小さくなり、圧縮の効率が高くなります。
集約ストレージ・アウトライン・ファイルは、ファイル拡張子(.otl)がブロック・ストレージ・アウトライン・ファイルと同じであり、同等のディレクトリ構造に格納されます。アウトラインを保存すると、Essbaseによりエラーが確認されます。アウトラインを保存する前に、その正確性を確認することもできます。ブロック・ストレージ・データベースの機能の一部は集約ストレージ・データベースには適用されず、確認プロセスでは集約ストレージ・データベースのルールが考慮されます。集約ストレージとブロック・ストレージの比較。を参照してください。
集約ストレージ・データベース・アウトラインはページング可能です。この機能により、非常に大きいデータベース・アウトラインのメモリー使用率が大幅に削減される場合があります。集約ストレージ・データベースでは、Essbaseによって、データベース・アウトラインの一部がメモリーにプレロードされます。その後、データの取得中に、Essbaseによって、必要に応じてアウトラインの他の部分がメモリーにページングされます。
集約ストレージ・データベースを作成すると、アウトラインはページング可能なフォーマットで作成されます。「集約ストレージ・アウトライン変換ウィザード」を使用して、既存のブロック・ストレージ・アウトラインを集約ストレージに変換すると、アウトラインは自動的にページング可能なフォーマットに変換されます。
アウトラインをメモリーにページングすることで、Essbaseで、非常に大きなアウトライン(たとえば、1,000万以上のメンバー)を処理できるようになりますが、データ取得時間が長くなる可能性があります。
構築可能なアウトラインの最大サイズ(メンバー数)は、次に示すいくつかの要因に依存します:
表200に、サポート対象の32ビット・オペレーティング・システムでEssbaseに使用できるアドレス可能なメモリー容量を示します:
表 200. 32ビット・オペレーティング・システムのアドレス可能なメモリー
|
次のコマンドを使用して、Essbaseサーバー・プロセスのESSSVRにアドレス可能なメモリーを設定する必要があります: | |
|
Redhat Linux |
デフォルトで3.9GB使用可能 |
Essbaseでは、起動時に約40 MBのメモリーが使用されます。さらに、各種キャッシュには次のようなメモリー割当てが必要です:
したがって、Essbaseの初期のメモリー・フットプリントは約90 MBです。さらに、着信クエリー要求を処理するためにメモリーを割り当てる必要があります。この目的のために予約する通常のメモリーは、約300 MBです。したがって、Essbaseに割り当てられる合計メモリーは390 MBです。
1.85 GBのアドレス可能メモリーがあるWindowsシステムでは、アウトラインの構築とロードに使用できるメモリーは約1.46 GB (1.85 GB - 390 MB = 1.46 GB)になります。
アウトラインの最大サイズは、アウトラインが次元構築を使用して構築されるか、Essbaseにすでにロードされているアウトラインから構築されるかによって異なります。
次元構築を使用してアウトラインを構築する際、Essbaseでは、約100バイトにメンバー名のサイズ、メンバーのすべての別名(最大10個の別名を許容)のサイズを加算した容量が、メンバーごとに割り当てられます。
サンプルのアウトライン(シングル・バイトのコード・ページを使用)では、メンバー名は平均15文字であり、メンバーごとに1つの別名(20文字)が存在しています。各メンバーに必要なメモリー要件は、次のように加算されます:
次元構築で追加できるメンバーの総数は、使用可能なメモリー(1.46 GBまたは153,092,060バイト)をメンバーごとのバイト数(135)で割った数、約1100万メンバーになります。
2 GB以上のアドレス可能メモリーがあるシステムでは、使用可能なメモリーの増分に比例して、アウトラインに可能なサイズが大きくなります。
次元構築が完了すると、dbname.otnファイルがデータベース・ディレクトリに保存されます。.otnファイルは、アウトライン再構築プロセスの入力として使用されます。このプロセスでは、古いアウトラインが新しいアウトラインと置き換えられます。再構築中に、古いアウトライン(空の可能性がある)と新しいアウトラインという、アウトラインの2つのコピーがメモリーにロードされるため、再構築できるアウトラインの最大サイズは、古いアウトラインのサイズによって変わります。
ランタイム時または再構築中にEssbaseにロードされるアウトラインに対するメモリー要件は、次元構築に対するメモリー要件とは異なります。Essbaseでは、メンバー当たり約60バイト、メンバー名のサイズにプラス5バイト、メンバーのすべての別名のサイズ(最大10個の別名が指定可能)にプラス5バイトが割り当てられます。平均のメンバー名が15文字で、メンバー当たり1つの別名(20文字)があるサンプルのアウトラインの場合、追加されるメンバーごとのメモリー要件は次のとおりです:
60 + 15 + 5 + 20 + 5バイト=メンバーごとに105バイト
1.46 GBのメモリーが使用可能であると想定すると、ロード可能なアウトラインの最大サイズは1400万個のメンバーを格納できるサイズ(1.46 GB / 105バイト)になります。
1400万個のメンバーは、再構築中にロードされる2つのアウトラインの合計です。たとえば、既存のアウトラインに500万個のメンバーがある場合、新しいアウトラインは最大900万個のメンバーを持つことができます。増分次元構築では、アウトラインの最大サイズを使用可能にするため、最初に小さいほうの次元を構築し、最後に大きいほうの次元を構築することをお薦めします。
メンバーを集約ストレージ・アウトラインから削除すると、アウトライン・ファイル(.otlファイル)内のメンバーの対応するレコードには削除済とマークされますが、ファイル内には残されます。メンバーが削除されたり追加されたりしている間、アウトライン・ファイルは増大し続けます。アウトライン・ファイルのサイズは、ファイルをコンパクト化して削除されたメンバーのレコードを削除することで最小化できます。アウトライン・ファイルのコンパクト化により、Essbaseによって、アウトラインが再構築されます。また、アウトライン・ファイルのコンパクト化は、他のユーザーまたはプロセスによってデータベースがアクティブに使用されていない場合のみ行われます。Essbaseでは、アウトラインのコンパクト化ではデータは消去されません。
式により、データベース・アウトライン内のメンバー間の関係が計算されます。ブロック・ストレージ・アウトラインでの式の使用に精通している場合、集約ストレージ・アウトラインで式を使用する際は次の相違点について考慮してください:
この章では、集約ストレージ・データベースで式を記述する際のMDXの使用に焦点を当てて説明します。クエリーを記述する際のMDXの使用の詳細は、MDXクエリーの記述。を参照してください。ブロック・ストレージ・アウトラインでの式の記述の詳細は、ブロック・ストレージ・データベース用の式の作成。を参照してください。また、『Oracle Essbaseテクニカル・リファレンス』のMDXに関する項も参照してください。
MDX式は、常にMDX数値式である必要があります。MDXの数値式とは、次のアクションのいずれかを実行する関数、演算子およびメンバー名の、任意の組合せです:
数値式はセット式とは異なります。セット式はクエリー軸で使用され、メンバーおよびメンバーの組合せを記述します。数値式は値を指定します。
数値式は、計算済メンバーを構築するためのクエリーで使用されます。計算済メンバーはクエリーのWITHセクションに分析目的のために作成される論理メンバーです。ただし、アウトライン内には存在しません。
次のクエリーは、計算済メンバーを定義し、数値式を使用して値を設定しています:
WITH MEMBER
[Measures].[Prod Count]
AS
'Count (
Crossjoin (
{[Units]},
{[Products].children}
)
)', SOLVE_ORDER=1
SELECT
{[Geography].children}
ON COLUMNS,
{
Crossjoin (
{[Units]},
{[Products].children}
),
([Measures].[Prod Count], [Products])
}
ON ROWS
FROM
ASOsamp.Sample
サンプル・クエリーでは、次のようにWITH句で計算済メンバー「Product Count」を「Measures」次元に定義します:
数値式はWITH句の後に続き、一重引用符で囲まれています。サンプル・クエリーでは、数値式は次のように指定されています:
SOLVE_ORDERプロパティでは、メンバーと式が評価される順序を指定します。計算順序を参照してください。
例のような数値式を構築するための構文規則の説明は、『Oracle Essbaseテクニカル・リファレンス』のCount、CrossJoinおよびChildren関数に関するドキュメンテーションを参照してください。 |
数値式をMDX式として使用して、既存のアウトライン・メンバーの値を計算することもできます。
したがって、例のようなクエリーを作成するのではなく、サンプル・クエリーで仮想「Prod Count」を計算したのと同じ方法で、アウトラインで計算された「Prod Count」というアウトライン・メンバーを「Measures」次元に作成します。
 式を持つ計算済メンバーを作成するには:
式を持つ計算済メンバーを作成するには:
例のように「Prod Count」メンバーを作成したことを想定して、次の数式を使用します。これは、例のクエリーで計算済メンバーの作成に使用した数値式と同じです:
Count(Crossjoin ( {[Units]}, {[Products].children}))集約ストレージ・データベースからデータを取得するときに、メンバー値の計算に式が使用されます。
式の中では代替変数を使用できます。たとえば、「EstimatedPercent」という代替変数を定義し、代替変数値として様々なパーセンテージを入力できます。代替変数の使用を参照してください。
アウトライン内のメンバーに式を適用する前に、計算済メンバーを含むMDXクエリーを記述できます。求めている計算済メンバー結果を戻すMDXクエリーを記述できる場合は、数値式の論理をアウトライン・メンバーに適用して、式の検証とテストができる状態です。MDXクエリーの記述。を参照してください。MDXの構文情報は、『Oracle Essbaseテクニカル・リファレンス』を参照してください。
Essbaseで集約ストレージ・アウトライン内の式が計算されるのは、データが取得されるときのみです。計算順序は計算結果に影響を及ぼす場合があります。集約ストレージ・アウトライン内の複数次元でMDX式を使用するときは常に、各メンバーまたは次元に解決順を設定することをお薦めします。計算順序を参照してください。
集約ストレージ・アウトラインのメンバー式を作成する際は、次の規則に従ってください:
メンバー名が次のいずれかの条件に該当する場合は、そのメンバー名を大カッコ([])で囲みます:
注:
式では、$または&で始まるメンバー名を引用符と大カッコで囲む必要があります。たとえば、$testmemberは式では["$testmember"]/100と表されます
単一のelse条件を持つ条件付テストを記述するには、IIF関数を使用します。IIF関数の構文では、else条件を識別するためのELSEIFキーワードも、ステートメントを終了するためのENDIFキーワードも必要ありません。IIF関数をネストすることで、より複雑な式を作成できます。
タプルは必ず正確に指定します。タプルとは、同じメンバーからの2つのメンバーは存在できないという制限を持つメンバーの集合のことです。タプルは、たとえば(Actual, Sales)のように、カッコで囲みます。
セットは必ず正確に指定します。セットとは、1つ以上のタプルの順序付けられた集合のことです。セットに複数のタプルが含まれる場合は、次のルールが適用されます: セットの各タプルのメンバーは、セットの他のタプルのメンバーと同じ次元を表す必要があります。さらに、次元は同じ順序で表す必要があります。つまり、セットのすべてのタプルは同じ次元性を持つ必要があります。
セットの指定のルールを参照してください。
{ [Year].[Qtr1], [Year].[Qtr2], [Year].[Qtr3], [Year].[Qtr4] }
式を作成するには、式エディタを使用します。式エディタは、アウトライン・エディタの「メンバーのプロパティ」ダイアログ・ボックスのタブの1つです。式はプレーン・テキストです。式を式のテキスト領域に直接入力することも、事前定義された式テンプレートを使用することも、選択したテキスト・エディタで式を作成してから、それを式エディタに貼り付けることもできます。
次元構築データ・ソースに式を含めることもできます。フィールド・タイプ情報の設定を参照してください。
Essbaseには、式の構文エラーを通知する、MDXベースの構文検査機能が組み込まれています。たとえば、関数名を誤って入力したり、存在しないメンバーを指定した場合にEssbaseによって通知されます。不明な名前は関数名のリストで検証できます。Essbaseサーバーまたはアウトラインに関連付けられたアプリケーションに接続していない場合は、不明な名前を検証するためにEssbaseにより接続が行われる場合があります。
構文チェックは、式を保存するときに行われます。エラーは「メッセージ」パネルに表示されます。エラーが発生した場合は、式を保存するかしないかを選択します。エラーのある式を保存すると、アウトラインの確認または保存時に警告が出されます。エラーのある式を計算すると、その式は無視され、メンバーには$MISSINGの値が指定されます。
構文チェッカでは、式のセマンティク・エラーは通知できません。セマンティク・エラーは、式が期待どおりに動作しないときに発生します。式のセマンティク・エラーを検出する方法の1つは、クエリーに式を定義する数値式を配置し、そのクエリーを実行して、結果が期待どおりであることを確認することです。クエリーに式を配置する方法は、MDX式の使用を参照してください。
クエリーを作成するには、MDXスクリプト・エディタを使用できます。MDXスクリプト・エディタには、MDX構文のカラー・コーディングやオートコンプリートなどの機能があります。Oracle Essbase Administration Services Online Helpの「MDXスクリプト・エディタについて」を参照してください。
次の項では、集約ストレージ・アウトラインのメンバーに対する様々な式の記述方法について説明し、いくつかの例を示します。
式で算術演算を使用して、基本的な等式を作成できます。たとえば、次の式は、ASOsamp.Sampleデータベースの「Avg Units/Transaction」メンバーに適用されます:
[Units]/[Transactions]
「Avg Units/Transaction」内の式は、ユニットの数をトランザクション数で割って、トランザクション当たりのユニット数の平均を求めます。
集約ストレージ・アウトラインでは、メンバーに支出アイテムのタグは付けられません。したがって、Calcの@VARや@VARPERなどの関数は、支出タグを考慮することで2つのメンバー間の差異を決定しますが、集約ストレージ・アウトラインでは関係がありません。
MDXの減算演算子は、2つのメンバー間の差異を計算するために使用できます。たとえば、次の式をASOsamp.Sampleの「Price Diff」という新しいメンバーに適用して、支払価格と元値の差異を計算できます:
[Price Paid]-[Original Price]
ASOsamp.Sampleには、メンバーに対する「合計に占める割合%」という式が含まれています。このメンバー式では、「Transactions」によって生成されるメジャー合計のパーセンテージが識別されます。「合計に占める割合%」の式は次のとおりです:
Transactions/
(Transactions,Years,Months,[Transaction Type],[Payment Type],
Promotions,Age,[Income Level],Products,Stores,Geography)
この式では、タプル(「Transactions, Years, ...」)で除算したメンバー(「Transactions」)を指定します。この式では、すべての次元の最上位のメンバーをリストして、キューブ内のすべての「Transaction」データを計上しています。つまり、「Curr Year」メンバーの「Transaction」データではなく「Years」次元のすべてのメンバーの「Transaction」データ、最初の2つの四半期の中での月に対する「Transaction」データではなくすべての月に対する「Transaction」データ、などと続きます。このようにして、「合計に占める割合%」の値は、「Transactions」によって生成されるメジャーの合計のパーセンテージを表します。
1つまたは一連の条件付テストを使用する式を定義して、メンバーの値を特定できます。1つのelse条件を持つテストを実行するには、IIF関数を使用します。IIF関数をネストすれば、より複雑なクエリーを作成できます。
次の例では、会社がクレジット・カード取引に対して支払う必要がある価格(5%の手数料を含む)を表すメンバーの式を指定しています。次の例では、ASOsamp.Sampleデータベースのメジャー次元に「Credit Price」メンバーが追加されていると仮定しています。「Credit Price」には次の式が含まれ、支払タイプがクレジット・カードの場合、これにより「Price Paid」に5%加算されます。
IIF (
[Payment Type].CurrentMember=[Credit Card],
[Price Paid] * 1.05, [Price Paid]
)
複数のテストおよびelse条件が存在する式を作成するには、CASE、WHEN、THEN構造体を使用します。
Filter関数では、指定された検索条件の基準を満たす入力セットのタプルが戻されます。たとえば、すべての製品に基準線(100)を設定する場合は、基準線メンバーを追加し、そのメンバーに対する式を次のように作成します:
Count(Filter(Descendants([PersonalElectronics],
[Products].Levels(0)),[Qtr1] > 100.00))
UDAは、メンバーに対して作成する単語または語句です。たとえば、Sample.Basicの場合、「Market」次元の最上位レベルのメンバーには、「Small Market」というUDA、または「Major Market」というUDAが含まれます。
このトピックで使用する「Major Market」の例は、すべての主要市場メンバーの売上高合計を示すメンバーに対する式の作成方法を示しています。この例では、Sample.Basicに新しいメンバー(「Major Market Total」)が追加されていると仮定しています。
MDXには、IsUDAというブール関数があります。この関数では、メンバーに関連するUDAタグがある場合、TRUEが戻されます。次の構文では、「Market」次元の現在のメンバーにUDAの「Major Market」がある場合、TRUEが戻されます:
IsUda([Market].CurrentMember, "Major Market")次の構文で示すようにIsUDAとともにFilter関数を使用すると、「Market」次元のメンバーを循環して、「Major Market」というUDAを持つ各メンバーの値を戻します:
Filter([Market].Members, IsUda([Market].CurrentMember, "Major Market"))Sum関数では、Filter関数で戻された値が加算されます。「Major Market」の例では次の数式が作成されています:
Sum (Filter([Market].Members, IsUda([Market].CurrentMember, "Major Market")))
ライトバック・パーティションでは、ソース集約ストレージ・データベース内のデータを変更しないまま、ターゲット・ブロック・ストレージ・データベース内のデータをオンザフライで更新できます。ライトバック・パーティションを作成することで、計算時間が削減され、データベース・サイズが縮小される可能性があります。
ライトバック・パーティションを作成するときは、次のガイドラインに従ってください:
集約ストレージ・データベースが作成されているのとは別のアプリケーションにブロック・ストレージ・データベースを作成します。
通常、ブロック・ストレージ・データベースには、集約ストレージ・データベースの次元のサブセットが含まれています。
データの格納先にする場所に基づいて、透過パーティションを作成します。ブロック・ストレージ・データベースをターゲット、集約ストレージ・データベースをソースにします。
パーティション・アプリケーションの設計。を参照してください。
ユーザーは、ブロック・ストレージ・データベースに対するクエリーとライトバックを行います。クエリーは、ブロック・ストレージ・データベースによって、または透過的に集約ストレージ・データベースによって処理されます。
パーティション・アプリケーションの作成には、データベース・マネージャ権限が必要です。
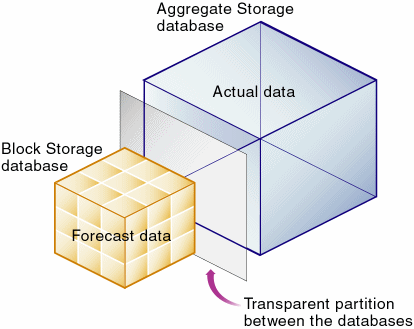
図158は、予測データと実績データの差異を分析するための透過パーティションの使用を示しています:
次の手順では、集約ストレージのサンプル・データベース(ASOsamp.Sample)を基にしていて、Administration Servicesの「集約ストレージ・パーティション・ウィザード」を使用します(Oracle Essbase Administration Services Online Helpを参照)。
ライトバック・パーティションを作成するには:
ASOsamp.Sampleデータベースを選択します。このデータベースには、現在の年と以前の年の実績データが含まれています。
図159を参照してください。
ASOsamp.Sampleの次元のサブセットであるメジャー、年、時間、製品、店舗、地域次元を含むブロック・ストレージ・データベースを作成します。
これらの式は、集約ストレージ・データベースからコピーされる、MDXで記述される式です。MDXの数式はブロック・ストレージ・データベースでは解釈されません。
データベースを、ターゲットがブロック・ストレージ・データベース(予測データ)、ソースが集約ストレージ・データベース(実績データ)として、年次元の透過パーティションとリンクさせます。
ライトバック・メンバー(「Forecast」および「Variance」)はパーティション領域に含めないでください。
Administration Servicesの「集約ストレージ・パーティション・ウィザード」を使用している場合、この手順は自動的に実行されます。手順3で年次元を選択したため、データベースは自動的に年次元でパーティション化されます。ライトバック・メンバーは、パーティション領域に含まれません。
ブロック・ストレージ・データベースのライトバック・メンバーに予測値を入力します。追加されたメンバーはパーティション化された領域の外側にあるため、それらに記述してから、更新済データに基づいてデータを計算してレポートを生成できます。透過パーティションにより、両方のデータベースをシームレスに表示できます。

