この章の情報は、集約ストレージ・データベースのみに適用され、ブロック・ストレージ・データベースとは関係がありません。集約ストレージとブロック・ストレージの比較。も参照してください。
データベース情報の処理に関する最も一般的なプロセスには、アウトラインの管理、データベースへのデータ値のロード、値の計算およびデータベース情報の取得が含まれます。集約ストレージ・データベースでのこれらのタスクの実行は、ブロック・ストレージ・データベースでの実行とは異なります。
この章の例は、図163のアウトラインを引用しています。

図163の簡易化した集約ストレージ・アウトラインは、完全には展開されていません。メンバー名の左側にあるプラス記号(+)のノードは、そのメンバーが表示されていない子を持つことを示しています。
この項のトピックでは、集約ストレージ・データベースとブロック・ストレージ・データベース間の、次元構築およびデータ・ロード・プロセスに関する相違点について説明します。データ・ロード、次元構築およびルール・ファイルの概念と手順に精通している必要があります。
データ・ソースを使用してアウトラインの変更やデータ値のロードを行う方法は、データ・ロードおよび次元構築の理解およびデータ・ロードまたは次元構築の実行およびデバッグ。を参照してください。
構築可能な集約ストレージ・アウトラインの最大サイズの詳細は、アウトラインのページング制限を参照してください。
アウトラインに対する集約ストレージの次元構築の変更により、次元構築の終了時にすべての集約ビューまたはすべてのデータ値が、データベースから消去されることがあります。集約ストレージ・データベースの再構築で、アウトライン変更の結果について説明しています。
複数のデータ・ソースを使用して次元を構築する場合は、増分次元構築を実行することで処理時間を節約できます。増分次元構築により、すべてのデータ・ソースの処理が完了するまで再構築を延期させることができます。増分次元構築の詳細は、再構築が延期された次元構築の実行を参照してください。
ブロック・ストレージ・アウトラインと集約ストレージ・アウトラインの間でのアウトラインの特徴の相違点は、データ・ソースとルール・ファイルに影響します。たとえば、次元を疎として定義するか密として定義するかは、集約ストレージ・アウトラインには関係がありません。
集約ストレージ・アウトラインの構築用のルール・ファイルでは、集約ストレージ・アウトラインに適用されるアウトライン・プロパティとフィールド・タイプのみを定義する必要があります。表192を参照してください。
ブロック・ストレージ・アウトラインを集約ストレージに変換した後、それらを集約ストレージ版のアウトラインに関連付けることで、ルール・ファイルを更新します。Oracle Essbase Administration Services Online Helpの「エディタでのアウトラインの関連付け」を参照してください。
解決順フィールド・タイプは、集約ストレージ・データベースのみで使用できます。
フィールドには、アウトライン内でメンバーが評価される順序を指定する数値(0-127)が含まれます。0より小さい値、または127より大きい値は、それぞれ0と127にリセットされます。警告メッセージは表示されません。解決順プロパティの詳細は、計算順序を参照してください。
世代
レベル
親子参照
集約ストレージ・データベースのルール・ファイルを編集している間、ブロック・ストレージ・データベースのみに適用される次元構築ルール・ファイル・オプションのいくつかが、「データ準備エディタ」ダイアログ・ボックスに表示されます。表203に、集約ストレージ・アウトラインに適用されないブロック・ストレージのルール・ファイル設定をリストします。これらのオプションのルール・ファイルのエントリは、ルール・ファイルが処理されるときは無視されます。
Oracle Essbase Administration Services Online Helpを参照してください。
集約ストレージ・アウトラインを変更するためのデータ・ソースは、ブロック・ストレージ・アウトラインのみに適用されるフィールド値を含めることはできません。表204に、次元構築データ・ソースで集約ストレージ・データベース・アウトラインのメンバーのプロパティとして認識されるメンバー・コードをリストします。他のすべての集計コードは無視され、+ (加算)とみなされます。データ・ソースを使用したメンバー・プロパティの操作を参照してください。
集約ストレージ・アウトラインでは、通貨名および通貨カテゴリのフィールド・タイプはサポートされていません。
集約ストレージ・アウトラインでは、式はMDX数値式と同じフォーマットで指定する必要があります。集約ストレージ・アウトラインでの式の作成を参照してください。
集約ストレージ・アウトラインの共有メンバーを構築するには、「autoconfigure」設定をAdministration Servicesの「次元構築の設定」ダイアログ・ボックスで選択してから、Essbaseで共有を許可するよう設定されていることを確認します(「共有しない」をAdministration Servicesの「次元構築の設定」ダイアログ・ボックスで選択解除するか、「データ共有を許可しない」プロパティをルール・ファイル内で除外します)。autoconfigureが選択されていて、共有が使用可能な場合は、Essbaseによって、新しい親の下に重複メンバーが自動的に共有メンバーとして作成されます。ルール・ファイルを使用した共有メンバーの作成を参照してください。
重複する世代(DUPGEN)の方法を使用して集約ストレージ・アウトラインに代替階層を構築する場合は、制限があります。表195を参照してください。 |
集約ストレージ・データベースでは、複数の排他操作を同一データベース上で同時に行うことはできません。ある排他操作の実行中に別の排他操作を同時に実行しようとすると、最初の操作の進行中は別の操作を開始できないことを示すメッセージが表示され、2番目の操作は拒否されます。たとえば、集約ストレージ・データベースで部分データ消去の実行時に、そのデータベースで別の部分データ消去を同時に実行することは、その2つの操作がデータベースの別の領域を消去している場合であっても、できません。ほとんどの排他操作は相互に排他的ですが、例外がいくつかあります。
排他操作と例外:
エクスポート
エクスポートは読取り専用操作であるため、エクスポート操作は同時に複数実行できます。エクスポート操作は、いずれも排他操作である、構築集約およびバックアップとして実行できます; ただし、エクスポートは、他の排他操作とは互換性がありません。
集約の構築
バックアップ(データベースの読取り専用アーカイブ・モードへの設定)
データのロード(ロード・バッファのコンテンツのデータベースへのコミット)
集約ストレージ・ロード・バッファの作成と、ロード・バッファへのデータのロードは排他操作ではありません。これらの操作は他のいかなる操作とも同時に実行できます。ただし、ロード・バッファ内のデータのデータベースへのコミットは排他操作です。
スプレッドシート送信操作(セルの更新など)
送信操作が実行されているときに別の排他操作を試行すると、送信操作の終了を待機してから新しい操作が続行されます。送信操作は常に小さく、時間がかからない(5秒未満)ため、送信操作と互換性がない場合でも、新しい操作がエラーになることはありません。つまり、相互に互換性がないことが原因で操作が拒否されることがなく、スプレッドシート送信操作を同時に実行できます。
注:
送信操作の実行中に複数の排他操作を試行した場合、送信操作の完了後に新しい排他操作が実行される順序はランダムです; 順序は、新しい排他操作が試行された順番には基づきません。たとえば、送信操作の実行中に、タイプの異なる排他操作を試行すると、送信操作の終了を待機してから新しい排他操作が続行されます。一方、別のユーザーが他の送信操作を試行した場合、それらの送信操作が後から試行されたとしても、送信操作はその他の排他操作より前に実行されます。そのため、実行を待機している送信操作が1つでも存在すると、排他操作が無制限に待機する可能性があります。
スライスのマージ
データ消去操作(完全、集約のみ、部分)
クエリーは、すべての排他操作と並行して実行できます。ただし、操作によって、データベースのデータに追加、変更または削除が行われた場合、クエリーが変更を認識すると、操作の最後に次のシーケンスが実行されます:
新規クエリーが一時的に開始を阻止されます(クエリーが待機する)。
既存のクエリーが実行を終了します。
排他操作からのデータ変更が、データベースにコミットされます。
待機しているクエリーが開始します。
クエリーは、集約ストレージ・キューブ上のデータを変更する操作が原因で拒否または取り消されることはありません。
データのロードの概要は、データ・ロードまたは次元構築の実行およびデバッグ。を参照してください。
集約ストレージ・データベースにより、最大1000万を超えるのメンバーが含まれる非常に大きな次元の分析が容易になります。このような大きいデータベースへのデータ値のロードを効率的にサポートするため、Essbaseでは次のことが可能です:
一時的な集約ストレージのデータ・ロード・バッファによって、複数のデータ・ソースを処理できる
データ・ロード・バッファで使用されるリソースのパーセンテージを制御できる
集約ストレージ・データベースに、データの複数のスライスを含めることができる(データベースに対するクエリーが各スライスにアクセスして、データ・セルのすべてを収集する)
増分データのサイズに比例した時間の長さで完了する、増分データ・ロード・プロセスを指定する
 集約ストレージ・データベースに値をロードするには、次のツールを使用します:
集約ストレージ・データベースに値をロードするには、次のツールを使用します:
|
ツール |
トピック |
場所 |
|---|---|---|
|
Administration Services |
集約ストレージ・データベースのデータ・ロードまたは次元構築の実行 |
Oracle Essbase Administration Services Online Help |
|
MaxL |
alter database import data |
『Oracle Essbaseテクニカル・リファレンス』 |
|
ESSCMD |
IMPORT LOADDB |
『Oracle Essbaseテクニカル・リファレンス』 |
注: | 値が集約によって値がすでに計算されて保管されている場合は、データ値が変更されると、Essbaseはより高いレベルの保管済の値を自動的に更新します。追加の計算手順は必要ありません。集約の存在とサイズは、データ・ロードの実行にかかる時間に影響する場合があります。集約を参照してください。 |
注: | データをデータベースにロードしているときは、データをエクスポートできません。 |
MaxLのimport database dataステートメントを使用して単一のデータ・ソースからデータ値をロードする場合には、集約ストレージ・データ・ロード・バッファは関係しません。
MaxLの複数のimport database dataステートメントを使用してデータ値を集約ストレージ・データベースにロードする場合は、最初に一時データ・ロード・バッファに値をロードし、すべてのデータ・ソースが読み取られた後でストレージに最終的な書込みを行うことで、パフォーマンスを大幅に向上させることができます。
集約ストレージのデータ・ロード・バッファでは、Essbaseによって、すべてのデータ・ソースが読み取られた後で値がソートされ、コミットされます。指定のデータ・セルに複数の(または重複する)レコードが検出される場合、それらの値は累計されます(セルの競合の解決を参照)。Essbaseでは、その後で、累計された値が格納され、データベース内の既存のデータ値の置換、加算または除算が行われます。集約ストレージのデータ・ロード・バッファの使用により、データ・ロードの全体的なパフォーマンスを大幅に向上させることができます。
集約ストレージのデータ・ロード・バッファを使用している場合は、データ・バッファのコンテンツをデータベースにロードする際に、データ・ソースのセット全体に対して値の置換、加算または除算の選択が指定されます。 |
集約の作成やスライスのマージはリソースを非常に多く使用するため、データ・ロード・バッファがメモリー内に存在している間、これらの操作はできません。ただし、他のデータ・ロード・バッファにデータをロードし、データベース上でクエリーやその他の操作を実行することは可能です。データ・セット全体がデータベースにコミットされて、集約が作成されるまで、クエリーが短時間待機する場合があります。
データ・ロード・バッファは、バッファのコンテンツがデータベースにコミットされるまで、またはバッファが破棄されたときにはアプリケーションが再起動されるまで、メモリー内に存在します。コミット操作が失敗した場合でも、バッファは破棄され、データはデータベースにロードされません。(データ・ロード・バッファは、MaxLのalter databaseステートメントを使用して手動で破棄できます。『Oracle Essbaseテクニカル・リファレンス』を参照してください。)
注: | バッファのコンテンツをコミットする前にアプリケーションを停止すると、バッファは破棄されます。このような場合は、アプリケーションを再起動した後、新しいバッファを初期化してそれにデータをロードできます。 |
データ・ロード・バッファを準備します。このデータ・ロード・バッファには、MaxLのalter databaseステートメントを使用して集約ストレージのデータ・ロード・バッファを初期化することで、データ値がソートされて累計されます。例:
alter database ASOsamp.Sample initialize load_buffer with buffer_id 1;MaxLのimport databaseステートメントを使用して、データ・ソースからデータ・ロード・バッファにデータをロードします。複数のステートメントを使用して、複数のデータ・ソースからデータをロードします。.xlsファイル、テキスト・ファイルおよびSQLリレーショナル・ソースなどのデータ・ソースの組合せを含めることができます。データ・ソースにルール・ファイルが必要な場合は、ルール・ファイルを指定します。
次の例では、3つのデータ・ソース(そのうちの1つはルール・ファイルを使用する)を同じデータ・ロード・バッファにロードします:
import database ASOsamp.Sample data from server data_file 'file_1.txt' to load_buffer with buffer_id 1 on error abort; import database ASOsamp.Sample data from server data_file 'file_2' using server rules_file ‘rule’ to load_buffer with buffer_id 1; on error abort; import database ASOsamp.Sample data from server excel data_file 'file_3.xls' to load_buffer with buffer_id 1 on error abort;データを同時に複数のロード・バッファにロードする方法は、複数のデータ・ロードの並行での実行を参照してください。
MaxLのimport databaseステートメントを使用して、データ・ロード・バッファのコンテンツをデータベースにコミットします。例:
import database ASOsamp.Sample data from load_buffer with buffer_id 1;1つのMaxLステートメントで複数のデータ・ロード・バッファのコンテンツをデータベースにコミットする方法は、複数のデータ・ロードの並行での実行を参照してください。
次の増分データ・ロードの例では、新しいデータ値が既存の値と交差しないときに最適なパフォーマンスが得られます:
ignore_missing_valuesおよびignore_zero_valuesプロパティを使用して、単一のデータ・ロード・バッファを作成します。例:
alter database ASOsamp.Sample initialize load_buffer with buffer_id 1 property ignore_missing_values, ignore_zero_values;データベースが更新されている間、そのデータベースでデータ送信要求を使用可能にする必要がある場合は、resource_usage文法で80%の設定でデータ・ロード・バッファを初期化します。例:
alter database ASOsamp.Sample initialize load_buffer with buffer_id 1 resource_usage 0.8 property ignore_missing_values, ignore_zero_values;データをバッファにロードします。例:
import database ASOsamp.Sample data from server data_file 'file_1.txt' to load_buffer with buffer_id 1 on error abort; import database ASOsamp.Sample data from server data_file 'file_2' to load_buffer with buffer_id 1; on error abort;スライスを作成し、値を追加することで、データ・ロード・バッファのコンテンツをデータベースにコミットします。例:
import database ASOsamp.Sample data from load_buffer with buffer_id 1 add values create slice;
増分データ・ロードの実行時、Essbaseでは、データのソートのために集約ストレージ・キャッシュが使用されます。データ・ロード・バッファで使用できるキャッシュの量は、パーセンテージを指定することで制御できます。パーセンテージは.01以上、1.0以下の数値で指定します。パーセンテージで意味があるのは、小数点以下の2桁のみです。たとえば、0.029は0.02と解釈されます。デフォルトでは、データ・ロード・バッファのリソース使用率は1.0に設定され、データベース上に作成されるすべてのデータ・ロード・バッファの合計使用率が1.0を超えることはできません。たとえば、サイズ0.9のバッファが存在する場合、サイズが0.1より大きい別のバッファを作成できません。
注: | 送信操作により、サイズ0.2のロード・バッファが内部的に作成されます。したがって、デフォルトのサイズ1.0のロード・バッファでは、データ・ロード・バッファのリソースが不十分なため、送信操作は失敗します。 |
バッファの使用が許可されるリソースの量を設定するには、resource_usage文法でMaxLのalter databaseステートメントを使用します。
たとえば、resource_usageを合計キャッシュの50%に設定するには、次のステートメントを使用します:
alter database ASOsamp.Sample
initialize load_buffer with buffer_id 1
resource_usage .5;
同時送信操作を実行することをプランしている場合は、ASOLOADBUFFERWAIT構成設定、およびwait_for_resources文法でMaxLのalter databaseステートメントを使用します。ASOLOADBUFFERWAITは、wait_for_resourcesオプションを使用して集約ストレージ・データ・ロード・バッファを作成する際や、割当て、カスタム計算、ロックおよび送信操作を行う際に適用されます。
データを増分的にロードするときには、データ・ロード・バッファにデータをロードするときに、ソース・データ内の欠落した値とゼロ値がどのように処理されるかを指定できます。
重複セルのセルの競合を解決するため、ロード・バッファに最後にロードされたセルを使用するかどうかを指定できます。
データ・ロード・バッファ・プロパティ:
ignore_missing_values: 入力データ・ストリーム内の#MI値は無視されます
ignore_zero_values: 入力データ・ストリーム内のゼロ値は無視されます
aggregate_use_last: ロード・バッファに最後にロードされたセルの値を使用することで、重複するセルを組み合せます
注:
集約ストレージ・データベースにテキスト値と日付値をロードするときは、無効な集約を除去するため、aggregate_use_lastオプションを使用します。その他のガイドラインは、テキスト・メジャーと日付メジャーのロード、消去およびエクスポートを参照してください。
コマンドで複数のプロパティを使用し、競合がある場合は、最後にリストされたプロパティが優先されます。
データ・ロード・バッファ・プロパティを設定するには、property文法でMaxLのalter databaseステートメントを使用します。
例:
alter database ASOsamp.Sample
initialize load_buffer with buffer_id 1
property ignore_missing_values, ignore_zero_values;
管理サービス・コンソールの「データ・ロード」ダイアログ・ボックスで、最後にロードされたセルの値を使用することで、欠落した値とゼロ値を無視するオプションや、重複セルを集約するオプションを設定できます。Oracle Essbase Administration Services Online Helpの「「データ・ロード」ダイアログ・ボックス」を参照してください。
デフォルトでは、同一キーを持つセルが同じデータ・ロード・バッファにロードされると、Essbaseで、値をまとめて追加することによってセルの競合が解決されます。
ロード・バッファに最後にロードされたセルの値を受け入れることによって、重複するセルを組み合せるデータ・ロード・バッファを作成するには、aggregate_use_last文法でMaxLのalter databaseステートメントを使用します。
例:
alter database ASOsamp.Sample
initialize load_buffer with buffer_id 1
property aggregate_use_last;
注: | このaggregate_use_last文法でデータ・ロード・バッファを使用すると、重複キーが存在しない場合でも、データ・ロードにはきわめて時間がかかります。 |
集約ストレージ・データベースには、複数のデータ・ロード・バッファが存在できます。時間を節約するため、データを複数のデータ・ロード・バッファに同時にロードできます。
データベース上では、常に1つのデータ・ロード・コミット操作しか有効にできませんが、同じコミット操作の中で複数のデータ・ロード・バッファをコミットすると、バッファを個別にコミットするより処理が速くなります。
注: | 管理サービス・コンソールを使用してデータを集約ストレージ・データベースにロードするときは、1つのデータ・ロード・バッファのみ使用されます。 |
同時に複数のデータ・ロード・バッファにデータをロードするには、別々のMaxLシェル・セッションを使用します。たとえば、1つのMaxLシェル・セッションで、IDが1のバッファにデータをロードします:
alter database ASOsamp.Sample
initialize load_buffer with buffer_id 1 resource_usage 0.5;
import database ASOsamp.Sample data
from data_file "dataload1.txt"
to load_buffer with buffer_id 1
on error abort;
同時に、もう1つのMaxLシェル・セッションで、IDが2のバッファにデータをロードします:
alter database ASOsamp.Sample
initialize load_buffer with buffer_id 2 resource_usage 0.5;
import database ASOsamp.Sample data
from data_file "dataload2.txt"
to load_buffer with buffer_id 2
on error abort;
データがデータ・ロード・バッファに完全にロードされたら、バッファIDのカンマ区切りのリストを使用することで、1つのMaxLステートメントを使用して両方のバッファのコンテンツをデータベースにコミットします:
たとえば、次のステートメントでは、バッファ1および2のコンテンツがロードされます:
import database ASOsamp.Sample data
from load_buffer with buffer_id 1, 2;
注: | 集約ストレージ・データベースにSQLデータをロードするときは、データの並行ロードに、最大8つのルール・ファイルを使用できます。この機能は、ここで説明したプロセスとは異なります。複数のSQLデータのロードを並行して実行する場合は、using multiple rules_file文法でMaxLの1つのimport databaseステートメントを使用します。Essbaseによって、複数の一時集約ストレージのデータ・ロード・バッファ(ルール・ファイルごとに1つ)が初期化され、1回の操作ですべてのバッファのコンテンツがデータベースにコミットされます。『Oracle Essbase SQLインタフェース・ガイド』を参照してください。 |
集約ストレージ・データベースには、複数のデータ・ロード・バッファが存在できます。集約ストレージ・データベースに存在するデータ・ロード・バッファのリストと説明については、次のようにlist load_buffers文法でMaxLのquery databaseステートメントを使用してください:
query database
appname.dbname
list load_buffers;
このステートメントでは、既存の各データ・ロード・バッファに関する次の情報が戻されます:
表 205. データ・ロード・バッファ情報
|
フィールド |
説明 |
|---|---|
|
buffer_id |
データ・ロード・バッファのID (1から4,294,967,296の間の数)。 |
|
internal |
データ・ロード・バッファがEssbaseによって内部で作成された(TRUE)か、またはユーザーによって作成された(FALSE)かを指定するブール。 |
|
active |
データ・ロード・バッファがデータ・ロード操作によって現在使用中であるかどうかを指定するブール。 |
|
resource_usage |
データ・ロード・バッファによる使用が許可されている集約ストレージ・キャッシュのパーセンテージ(.01から1.0までの数値)。 |
|
aggregation method |
バッファ内の同じセルに対して複数の値を結合するために使用されるメソッドの1つ:
|
|
ignore_missings |
入力データ・ストリームで#MI値を無視するかどうかを指定するブール。 |
|
ignore_zeros |
入力データ・ストリームでゼロを無視するかどうかを指定するブール。 |
データ・ロード・バッファを集約ストレージ・データベースに増分的にコミットすれば、スライスを作成できます。新しいスライスをデータベースにロードした後、新しいデータがクエリーに表示される前に、Essbaseによって、スライス上の必要なすべてのビュー(集約ビューなど)が作成されます。
データ・スライスの作成は、増分データ・ロードのパフォーマンスを向上させるため、有用です。増分データ・ロードにかかる時間は、新規データの量に比例します。データベースのサイズは要因になりません。
データ・スライスを作成するには、create slice文法でMaxLのimport databaseステートメントを使用します。
たとえば、値(デフォルト)を上書きすることでスライスを作成するには、次のステートメントを使用します:
import database ASOsamp.Sample data
from load_buffer with buffer_id 1
override values create slice;
注: | スライスを作成するときに上書き値を使用すると、#MISSING値はゼロと置き換えられます。このオプションを使用すると、add valuesオプションやsubtract valuesオプションを使用するよりもかなり時間がかかります。 |
管理サービス・コンソールでは、「データ・ロード」ダイアログ・ボックスでスライスを作成するオプションを設定できます。Oracle Essbase Administration Services Online Helpの「「データ・ロード」ダイアログ・ボックス」を参照してください。
メインのデータベース・スライスを変更しないまま、すべての増分データ・スライスをメインのデータベース・スライスにマージしたり、すべての増分データ・スライスを単一のデータ・スライスにマージしたりできます。スライスをマージするには、データをロードするための権限と同じ権限(管理者権限またはデータベース・マネージャ権限)を持つ必要があります。
新しいデータ・スライスのデータがデータ・ロード・バッファ内に存在すると、Essbaseによって、増分データ・スライスがスキャンされ、それらのデータを新しいスライスと自動的にマージするかどうかが検討されます。自動マージの対象になるには、スライスが100,000セル未満か、新しいスライスのサイズの2倍より小さいものである必要があります。5,000,000セルより大きいスライスが自動的にマージされることはありません。たとえば、新しいスライスに300,000個のセルが含まれている場合、90,000個のセルと500,000個のセルが含まれている増分データ・スライスは、自動的に新しいセルとマージされます。700,000個のセルが含まれて入る増分データ・スライスは、自動的にはマージされません。
データベースに新しい入力ビューが書き込まれた後、Essbaseでスライスの集約ビューが作成されます。新しいスライス用に作成されるビューは、メインのデータベース・スライス上に存在するビューのサブセットです。
注: | マージの実行中にはデータをエクスポートできません。 |
logical clear region操作を使用する領域からデータを消去し、結果として消去したセルの値がゼロになる場合は、マージ操作中にゼロ値のセルを削除するよう選択できます。集約ストレージ・データベースの特定の領域からのデータの消去を参照してください。
マージ操作を実行するには、merge構文でMaxLのalter databaseステートメントを使用します。
たとえば、すべての増分データ・スライスをメインのデータベース・スライスにマージするには、次のステートメントを使用します:
alter database ASOsamp.Sample
merge all data;
すべての増分データ・スライスをメインのデータベース・スライスにマージし、ゼロ値のセルを削除するには、次のステートメントを使用します:
alter database ASOsamp.Sample
merge all data remove_zero_cells;
すべての増分データ・スライスを単一のデータ・スライスにマージするには、次のステートメントを使用します:
alter database ASOsamp.Sample
merge incremental data;
管理サービス・コンソールでは、データ・スライスをマージできます。Oracle Essbase Administration Services Online Helpの「増分データ・スライスのマージ(集約ストレージ・データベース)」を参照してください。
注: | 集約ストレージ・アプリケーションをコピーする前に、すべての増分データ・スライスをメイン・データベース・スライスにマージする必要があります。マージされていない増分データ・スライスのデータはコピーされません。増分データ・スライスのマージを参照してください。 |
完全に再ロードするには十分に小さくて、データの待ち時間も短いデータ・セットの場合は、Essbaseで、現在のデータベースのコンテンツを削除し、データベースを指定したデータ・ロード・バッファのコンテンツと置き換えることができます。このアトミックな置換機能では、サービスを中断することなく、データベースの古いコンテンツのクエリーが新しいコンテンツに移行されます。新たにロードされたデータ・セットは、置換されたデータ・セット用に存在していたものと同じビューのセットを作成するために集約されます。
Essbaseでは、データベース内のすべての増分データ・スライスのコンテンツの微細な置換も可能です。データを、更新されることのない比較的大きい静的なデータ・セットと、個々の更新を識別するのは難しくても揮発性のデータ・セットに限定されている比較的小さい揮発性のデータ・セットに分けることができる状況を考えてみてください。たとえば、大きい静的なデータ・セットが直前の3年間の履歴トランザクション・データで構成されていても、過去2か月のトランザクション・データについては、ユーザーがソース・データベース内のトランザクションの特徴を変更できるとします。これらの変更の追跡は、途方もなく複雑になる可能性があります。この場合、静的データ・セットをデータベース内のメイン・スライスとしてロードし、揮発性のデータ・セットを1つ以上の増分スライスとしてロードできます。
Essbaseでは、すべての増分データ・スライスの現在のコンテンツが削除され、(add values文法を使用して)指定されたデータ・ロード・バッファを含む新しいスライスが作成されます。新たにロードされたデータ・セットは、メイン・スライス上に存在するビューのセットに基づいて、集約ビューで拡張されます。
注: | override文法を使用するには、最適なパフォーマンスを得るためにignore_missing_valuesプロパティでデータ・ロード・バッファを作成します。さらに、静的なデータ・セットと揮発性のデータ・セットの間に競合がないことを確認する必要があります(たとえば、同じセルに対して各データ・セット内に値が存在することはできません)。 |
データベース内のデータベースのコンテンツまたは増分データ・スライスを置換するには、override文法でMaxLのimport databaseステートメントを使用します。
たとえば、データベースのコンテンツを置換するには、次のステートメントを使用します:
import database ASOsamp.Sample data
from load_buffer with buffer_id 1
override all data;
すべての増分データ・スライスのコンテンツを新しいスライスと置き換えるには、次のステートメントを使用します:
import database ASOsamp.Sample data
from load_buffer with buffer_id 1
override incremental data;
注: | 上書き置換が失敗すると、Essbaseでは古いデータ・セットを引き続き使用します。 |
管理サービス・コンソールの「データ・ロード」ダイアログ・ボックスで、データベースまたはデータ・スライスのコンテンツを置換するオプションを設定できます。Oracle Essbase Administration Services Online Helpの「データベースまたはデータ・スライス・コンテンツの置換(集約ストレージ・データベース)」を参照してください。
Essbaseでは、増分データ・スライスのサイズと数、および増分データ・スライスのクエリーにかかるコストの統計を提供します。
すべての増分データ・スライスにアクセスするためのクエリーにかかる時間は、パーセンテージ(.01以上、1.0以下)で表されます。データベースにメインのスライスと複数の増分データ・スライスがある場合、クエリー統計0.66は、クエリー時間の3分の2が増分データ・スライスのクエリーに費やされ、3分の1がメインのデータ・スライスのクエリーに費やされたことを意味します。増分データ・スライスのクエリーのコストが高すぎる場合は、スライスをマージできます。
増分データ・スライス統計を表示する方法は、Oracle Essbase Administration Services Online Helpの「集約ストレージ統計の表示」を参照してください。
集約ストレージ・データベースでの増分データ・ロードには、現在のデータ・ファイルのサイズの最大2倍のディスク・スペースが使用される場合があります。データベースの大きさが2 GBを超える場合は、デフォルトのテーブルスペースの最大ファイル・サイズが2 GBを超えないように設定することで、ディスク・スペースの使用率を削減できます。テーブルスペースでの処理を参照してください。
Smart Viewでは、submitコマンドは、増分データ・ロード機能をoverride文法で使用することと同じです。
送信操作を実行している間、ロック、ロック解除および取得とロックの新しい要求は、送信操作が完了するまで待機します。
Oracle Hyperion Smart View for Office User's Guideを参照してください。
集約ストレージ・データベースに値をロードするためにデータ・ソース・レコードを処理する際、Essbaseではメンバーに式が存在しないレベル0の次元の交差のみを対象にしてソース・データ・レコードが処理されます。
次の例は、レベル0の交差のみのレコードを含むデータ・ソースを示しています。最後のフィールドにはデータ値が含まれていて、その他のフィールドは、それらの各次元のレベル0のメンバーです。
Jan, Curr Year, Digital Cameras, CO, Original Price, 10784
Jan, Prev Year, Camcorders, CO, Original Price, 13573
Essbaseは上位レベルのメンバーを指定するレコードを無視し、データ・ロードの完了時にスキップされたレコードの件数を表示します。
たとえば、メンバーMid Westはレベル1のメンバーであるため、次のレコードはスキップされます:
Jan, Curr Year, Digital Cameras, Mid West, Original Price, 121301
Essbaseサーバーでは、データベースに値をコミットする前にレコードの読取りとソートが内部的に行われるため、データ・ソースをソートする必要はありません。
集約ストレージ・データベースに値をロードするためのルール・ファイルの指定は、集約ストレージのデータ・ロード・プロセスに反映されます。
ブロック・ストレージのデータ・ロードでは、既存の値に上書きするか、既存の値にデータ・ソースの値を足すか、既存の値から差し引くかを、ルール・ファイルを使用してデータ・ソースごとに選択します。
集約ストレージ・データ・ロード・バッファを使用した集約ストレージのデータ・ロードでは、データ・ロード・バッファに収集されたすべてのデータ・ロード・ソースに対して選択した操作が行われてから、データベースにロードされます。
ブロック・ストレージ・アウトラインと集約ストレージ・アウトラインに定義されたルール・ファイルを使用するには、まずルール・ファイルを集約ストレージ・アウトラインに関連付けます。Oracle Essbase Administration Services Online Helpの「エディタでのアウトラインの関連付け」を参照してください。
集約ストレージ・データベースから、データを選択して消去するか、すべてのデータを消去できます。
集約の消去も参照してください。
集約ストレージ・データベース内の指定した領域からはデータを消去し、他の領域にあるデータを保持できます。この機能は、揮発性のデータ(過去1か月間に対応するデータなど)を削除しても、履歴データは保持したいときには便利です。データを消去するには、データ・マネージャ権限または管理者権限を持っている必要があります。
領域からのデータの消去方法:
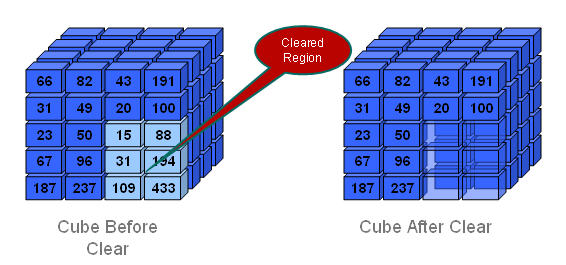
物理
指定した領域内の入力セルは、図164に示すように、集約ストレージ・データベースから物理的に削除されます。
データベース内に複数のデータ・スライスがある場合は、物理消去領域操作によって、すべてのデータ・スライスがメインのデータ・スライスに自動的にマージされます。指定した領域のデータが消去されると、Essbaseでは、消去領域操作が行われるまでメインのデータ・スライス内に存在していたすべての集約ビューが生成されます。
データを物理的に消去するプロセスが完了するには、消去されるデータのサイズではなく、入力データのサイズに比例した長さの時間がかかります。したがって、この方法は、データの大きいスライスを削除する場合のみ使用することをお薦めします。
データを物理的に消去するには、MaxLのalter databaseステートメントをclear data in region文法とphysicalキーワードを指定して使用します:
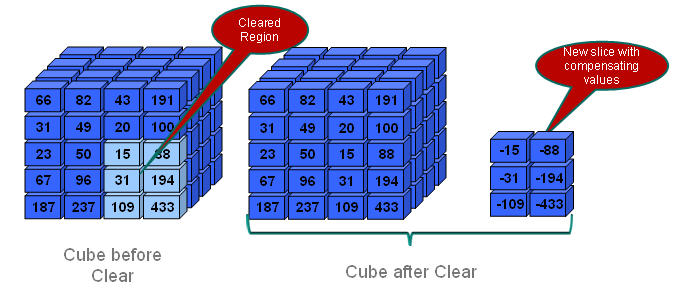
alter database appname . dbname clear data in region 'MDX set expression' physical;論理
指定した領域内の入力セルは、図165に示すように、負の補正値(消去するセルをゼロの値にする値)を含む新しいデータ・スライスに書き込まれます。
論理消去領域操作では、ゼロ値を持つデータのみ、自動的にメインのデータ・スライスにマージされます。データベース内の他のデータ・スライスはマージされません。指定した領域のデータが消去された後、Essbaseでは新しいデータ・スライスのみの集約ビューが生成されます。
データを論理的に消去するプロセスは、消去されるデータのサイズに比例する時間の長さで完了します。このオプションでは、相殺セルが作成されるので、データベースのサイズが増加します。
データを論理的に消去するには、MaxLのalter databaseステートメントをclear data in region文法で、physicalキーワードを指定せずに使用します:
alter database appname . dbname clear data in region 'MDX set expression';論理的に消去された領域に対するクエリーでは、#MISSING値ではなくゼロ値が戻されます。空のセルの#MISSING値に依存する式の更新が必要な場合があります。
値がゼロのセルを削除するには、alter database MaxLステートメントをmerge文法とremove_zero_cellsキーワードとともに使用します。『Oracle Essbaseテクニカル・リファレンス』を参照してください。
注:
同じ領域で2回目の論理消去領域操作を実行することはお薦めしません。これは、2回目の操作では、最初の操作で作成された補正セルが消去されず、新しい補正セルが作成されないためです。
消去する領域を指定するときは、次のガイドラインに従ってください:
領域は対称である必要があります。
{(Jan, Budget)}は、「Jan」のすべての「Budget」データを消去する有効な対称の領域です。
{(Jan, Forecast1),(Feb, Forecast2)}は、2つの非対称の領域(「Jan, Forecast1」と「Feb, Forecast2」)で構成されているため、無効な領域です。
領域指定内の次元の個々のメンバーは、保管済メンバーである必要があります。
領域内のメンバーは、次のものにすることはできません:
動的メンバー(暗黙的または明示的なMDX式を持つメンバー)
属性次元からのメンバー
セルを属性によって消去する必要がある場合は、Attribute MDX関数を使用します。
領域内のメンバーは、保管階層の上位レベルのメンバーにできます。これは、複数のレベル0のメンバーを指定する場合に便利な方法です。
たとえば、Qrt1を指定できます。これは、Jan、FebおよびMar(Qrt1のレベル0の子)を指定することと同じです:

次の2つのMaxLステートメントでは、同じ結果が生成されます:
alter database appname . dbname clear data in region '{Qtr1}'; alter database appname . dbname clear data in region '{Jan, Feb, Mar}';(物理的なデータの消去のみ)領域内のメンバーは、代替階層の上位レベル・メンバーにできます。
たとえば、High End Merchandiseを指定できます。これは、Flat Panel、HDTV、Digital RecordersおよびNotebooks (High End Merchandiseの共有のレベル0の子)を指定することと同じです:

次の2つのMaxLステートメントでは、同じ結果が生成されます:
alter database appname . dbname clear data in region '{High End Merchandise}'; alter database appname . dbname clear data in region '{[Flat Panel],[HDTV],[Digital Recorders],[Notebooks]}';データを論理的に消去するときに、代替階層のメンバーを指定するには、Descendants MDX関数を使用します。
注:
領域に代替階層の上位レベルのメンバーが含まれている場合は、パフォーマンスが低下する可能性があります。このような場合は、レベル0のメンバーのみを使用することを検討してください。
MDXのセット式は一重引用符で囲む必要があります。
たとえば、「Forecast1」および「Forecast2」のシナリオのすべての1月のデータを消去するには、次のステートメントを使用します:
alter database ASOsamp.Sample clear data in region 'CrossJoin({Jan},{Forecast1, Forecast2})';
消去領域操作の間は、データベースを更新する操作(データのロード、データ・スライスのマージ、または別の領域からのデータの消去など)は実行できず、データをエクスポートすることもできません。データベースのクエリーは可能ですが、クエリーの結果は、消去領域操作の前のデータ・セットに基づいたものになります。
clear data in region文法では、データベース全体からデータを消去できません。集約ストレージ・データベースからのすべてのデータの消去を参照してください。
集約ストレージ・アプリケーションですべてのデータをコピーするには、すべての増分データ・スライスをメインのデータベース・スライスにマージする必要があります。マージされていない増分データ・スライスのデータはコピーされません。
増分データ・スライスのマージを参照してください。
集約ストレージのデータ・ロード・バッファを使用するときは、データ・ソースとルール・ファイルを組み合せて、メンバーをアウトラインに追加したり、レベル0のセルにデータ値をロードしたりできます。ユーザーが指定するファイルの順序とは無関係に、Essbaseによってアウトラインに変更が加えられ、その後データ値がロードされます。
集約ストレージ・データベースの次元構築とデータ・ロードは、Administration Servicesでは1つの操作で結合できますが、次元構築操作とデータ・ロード操作は別々に行うことをお薦めします。これは、次元構築によってはデータが消去されることがあり、それによってデータが失われてしまう可能性があるためです。集約ストレージ・データベースでの次元構築を参照してください。 |
集約ストレージ・データベースの値は、アウトライン構造とMDX式によって計算されます。データ・ロードが完了すると、集約ストレージ・データベースの計算に必要なすべての情報が使用可能になります。取得要求が出されると、レベル0のメンバーにロードされた値を集計し、式を計算することによって、Essbaseサーバーで必要な値が計算されます。取得のために計算された値は格納されません。
取得パフォーマンスを向上させるため、Essbaseでは、値を集約し、それらの値を前もって格納できます。ただし、すべての値を集約して格納すると、ストレージ用のディスク・スペースを必要とするプロセスが長々と続く可能性があります。Essbaseには、時間とストレージのリソースのバランスをとる、高機能な集約プロセスがあります。集約ストレージ・データベースの集約を参照してください。
取得のために集約ストレージ・データベースを準備するには、アウトラインを作成し、レベル0の値をロードします。次に、追加の値を集約して格納することでデータベースを計算し、残りの値は取得時に計算されるようにします。
表193を参照してください。
集約ストレージ・アウトラインの階層構造により、値のロール・アップ方法が決定されます。レベル0のメンバーの値はレベル1のメンバーの値にロール・アップし、レベル1のメンバーの値はレベル2のメンバーの値にロール・アップする、などのようになります。
動的階層のメンバーに割り当てられた集計演算子では、ロールアップで使用される次の演算子が定義されます: 加算(+)、減算(-)、乗算(*)、除算(/)、パーセント(%)、非演算(~)および集計なし(^)。演算子の説明は、表16を参照してください。
より複雑な演算では、動的階層のメンバーにMDX式を指定できます。MDX式はMDX数値式と同じフォーマットで記述されます。集約ストレージ・アウトラインでの式の作成を参照してください。
集約ストレージの計算順序とブロック・ストレージの計算順序は異なります。集約ストレージ・データベースでは、Essbaseによりデータが次の順序で計算されます:
保管階層のメンバーと属性次元の集約。メンバーと次元が集約される順序は内部的に最適化され、データベース・アウトラインの性質と既存の集約に応じて変わります。集約は付加的であるため、Essbaseが次元とメンバーを集約する順序は結果には影響しません。
集約ストレージ・データベースの内部の集約順序は予測できないため、内在している丸め誤差も予測できません。これらの丸め誤差は、コンピュータ計算では予想される動作であり、関係しているデータ値についてはごくわずかです。
動的階層次元のメンバーと式の計算。メンバーと式が評価される順序は、各メンバーまたは次元に設定できる解決順プロパティによって定義されます。計算順序は計算結果に影響を及ぼす場合があります。
解決順の概念は、クエリー実行に適用されます。セルが多次元クエリーで評価されるとき、計算が解決される順序はあいまいな場合があります。このあいまいさをなくすため、解決順のプロパティを使用して、必要な計算の優先度を指定できます。
各メンバーの解決順は、解決順のプロパティをメンバー・レベルまたは次元レベルで設定することによって指定することをお薦めします。解決順が指定されていない式を持たないメンバーは、その次元の解決順を継承します。解決順が指定されていない式を持つメンバーは、ゼロの解決順を持ちます。 |
解決順のプロパティの値により、Essbaseで式が計算される優先度が決まります。解決順が指定されているメンバーに対する式は、最も低い解決順から最も高い解決順の順序で計算されます(解決順のプロパティの使用例を参照)。0から127の範囲で解決順序を指定できます。デフォルトは0です。
解決順は、メンバー・レベルまたは次元レベルで指定できます。Essbaseでは、計算の優先順位は次の情報を使用して決定されます:
次元の解決順(メンバーの解決順を指定しない式を持たないメンバーは、その次元の解決順を継承します。メンバーの解決順を指定しない式を持つメンバーは、ゼロの解決順を持ちます。)
複数のメンバーが同じ解決順を持つ場合、メンバーは、その次元がデータベース・アウトライン内で出現する順序の逆順で評価されます。アウトライン内で後の方に出現するメンバーを優先します。
タイの状況の計算順序は、ブロック・ストレージ・データベースのMDXクエリーで定義された計算済メンバーとは異なります。『Oracle Essbaseテクニカル・リファレンス』を参照してください。
メンバー式が別のメンバーの値に依存する場合、その式を持つメンバーは、依存しているメンバーよりも高い解決順を持つ必要があります。たとえば、図167のASOsamp.Sampleデータベース・アウトラインでは、「Avg Units/Transaction」は「Units」および「Transactions」の値に依存します。「Avg Units/Transaction」は、「Units」および「Transactions」よりも高い解決順を持つ必要があります。
次の例は、ASOSamp.Sampleデータベースをベースにしています。クエリー結果のあいまいさをなくすため、この例では、解決順のプロパティを使用して必要な計算の優先度を指定しています。
図166のスプレッドシートのクエリーでは、今年の1月と去年の1月の売上数量と取引件数のデータが取得されます。「Variance」メンバーは、今年と去年の間の差異を示します。「Avg Units/Transaction」メンバーは、取引ごとの売上数量の比率を示します。
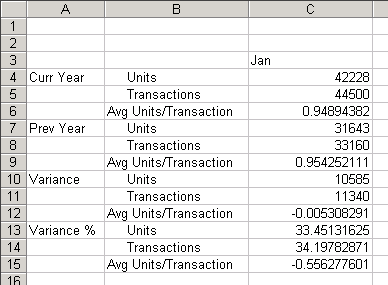
図167は、これらのメンバーのデータベース・アウトラインと、「Variance」メンバーと「Avg Units/Transaction」メンバーに適用される式を示しています。

取引ごとの平均数量の差異(図166のセルC12)を計算すると、結果は2つの比率の差異であることも、2つの差異の比率であることもあります。結果は、Essbaseで「Variance」に対する式か「Avg Units/Transaction」に対する式のどちらが優先されるかによって決まります。
解決順のプロパティの値は、データベース・アウトライン内のメンバーに添付され、Essbaseで式が評価される優先度を決定します。解決順の高いメンバーに対する式が優先されます。
この例では、「Variance」メンバーが「Avg Units/Transaction」メンバーより高い解決順を持つ場合、「Variance」メンバーに対する式が優先し、その結果は2つの比率の差異です。これはASOsamp.Sampleデータベースの場合であり、「Variance」メンバーの解決順が20で、「Avg Units/Transaction」メンバーの解決順が10のためです。「Variance」メンバーの方が解決順が高いため、「Variance」に対する式が優先されます。図166のクエリーのセルC12の結果は、表206に示されているように、2つの比率の差異です:
表 206. 2つの比率の差異を求めるように解決順のプロパティを指定
|
「Variance」と「Avg Units/Transaction」の交差の結果(図166のセルC12) | |||
|---|---|---|---|
|
今年の1取引当たりの平均数量- 去年の1取引当たりの平均数量 0.94894382 (セルC6) - 0.954252111 (セルC9) = -0.005308291 (セルC12) | |||
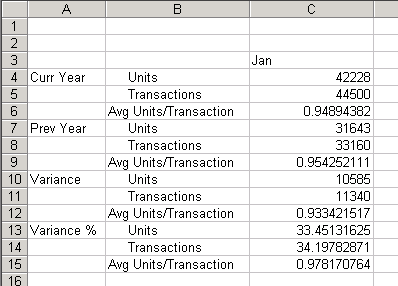
かわりに、ASOSamp.Sampleデータベースを変更し、「Avg Units/Transaction」メンバーに「Variance」メンバーよりも高い解決順を指定すると、「Avg Units/Transaction」メンバーが優先され、結果は、表207と図168に示されているように、2つの差異の比率になります:
集約ストレージ・データベースでは、データ値がアウトラインのレベル0のセルにロードされた後、別個の計算ステップは必要ありません。ユーザーは、データベース内の任意のポイントから、現在の取得のみについて、動的に集約される値を取得して表示できます。集約ストレージ・データベースはブロック・ストレージ・データベースより小さいため、データ値をすばやく取得できます。
データベースが増大するにつれて、取得では、クエリーの計算の要件を満たすためにより多くのデータ値を処理する必要があります。取得をより速くするため、Essbaseでは、データ値を事前計算し、それらの値を集約に格納できます。データベースのサイズが100万の集約セルに近づいた場合は、集約の実行を積極的に検討してください。データベース使用状況と使用環境によっては、小さいデータベースを同様に事前計算することによって、パフォーマンスを向上できます。集約ストレージ・データベースの計算には、管理サービス・コンソールまたはMaxLのいずれかを使用できます。
次のトピックでは、集約ストレージ・データベースの計算の説明に不可欠な用語について説明します。
次元全体のレベル0の交差のセルのうち、式を持たないセルを、入力セルといいます。データ値はそれらのセルにロードできます。会計次元または動的階層のメンバーが含まれている上位レベルのセルは、常に取得時に計算されます。次元全体の他のすべての上位レベルの交差は、集約セルです。たとえば、図163では、「Price Paid」>「Curr Year」>「1st Half」>「Portable Audio」>「CO」は集約セルです。「Original Price」>「Curr Year」>「Jan」>「Camcorders」>「CO」は、もう1つの集約セルです。集約セルの値は、下位レベルの値からロール・アップされる必要があります。
Essbaseがどの集約セルを事前計算して保管するかを定義するときは、集約ビューを操作します。集約ビューは集約セルの集合です。この集合は、各次元内のメンバーのレベルに基づきます。
たとえば、図163のアウトラインの1つの集約ビューについて考えてください。この集約ビューには、次の次元レベルの集約セルが含まれています:
この例の集約ビューは0, 0, 1/0, 2/0, 0と表されます。
それぞれの次元は、左から右に、アウトライン内でのその順序で表されます。次元に階層が含まれている場合、注釈によってその階層内でのメンバー・レベルが示されます。次元内の階層は、階層0からトップダウンで番号が付けられます。
0, 0, 1/0, 2/0, 0集約ビューには、次のメンバーの交差を含む集約セルが含まれています:
Original Price, Curr Year, Qtr1, Personal Electronics, CO
Original Price, Curr Year, Qtr1, Personal Electronics, KS
Original Price, Curr Year, Qtr1, Home Entertainment, CO
Original Price, Curr Year, Qtr1, Home Entertainment, KS
Original Price, Curr Year, Qtr2, Personal Electronics, CO
Original Price, Curr Year, Qtr2, Personal Electronics, KS
Original Price, Curr Year, Qtr2, Home Entertainment, CO
Original Price, Curr Year, Qtr2, Home Entertainment, KS
Original Price, Curr Year, Qtr3, Personal Electronics, CO
Original Price, Curr Year, Qtr3, Personal Electronics, KS
Original Price, Curr Year, Qtr3, Home Entertainment, CO
Original Price, Curr Year, Qtr3, Home Entertainment, KS
Original Price, Curr Year, Qtr4, Personal Electronics, CO
Original Price, Curr Year, Qtr4, Personal Electronics, KS
Original Price, Curr Year, Qtr4, Home Entertainment, CO
Original Price, Curr Year, Qtr4, Home Entertainment, KS
Original Price, Prev Year, Qtr1, Personal Electronics, CO
Original Price, Prev Year, Qtr1, Personal Electronics, KS
Original Price, Prev Year, Qtr1, Home Entertainment, CO
Original Price, Prev Year, Qtr1, Home Entertainment, KS
and so on...
集約とは、アウトライン階層に基づいた、レベル0のデータ値の集計のことです。集約には1つ以上の集約ビューが含まれます。Essbaseには、ロール・アップされる集約ビューを選択し、それらを集約してから、選択したビューにセルの値を保管するという、高機能な集約プロセスがあります。集約に、データ・ロードによって変更されるレベル0の値に依存する集約セルが含まれる場合、上位レベルの値は、データ・ロード・プロセスの最後に自動的に更新されます。
集約スクリプトのそれぞれは、生成される集約ビューの特定の選択を定義するファイルです。Administration Servicesの集約設計ウィザードを使用して、集約スクリプトを作成し、それらのスクリプトを.csc拡張子を持つテキスト・ファイルとしてデータベース・ディレクトリに保管できます。集約スクリプトの操作を参照してください。
集約の実行には、Administration Servicesの集約設計ウィザードまたはMaxLステートメントのいずれかを使用できます。集約プロセスには2つの段階があります:
集約ビューの選択段階で、様々な組合せの集約ビューの計算と格納が、集約のクエリー応答時間にどのように影響するかがEssbaseで分析されます。分析に対する入力として、物理的ストレージとパフォーマンスの要件を定義できます。また、データの使用状況の追跡や分析プロセスに対する情報の入力も可能です。使用状況に基づいたビューの選択を参照してください。
集約ビューの有用性とリソース要件に基づいて、Essbaseで集約ビューのリストが作成されます。このリストには、各ビューとともに、その集約ビューとその上にリストされる他のすべての集約ビューの保管時に適用される、ストレージおよびパフォーマンス情報が含まれています。リストされたビューの集約、リストされたビューのサブセットの選択と集約、または別の入力基準による選択プロセスの再実行を選択できます。また、新しい選択基準に基づいた新しいビューの生成を、集約に追加することもできます。集約ビューの選択の調整を参照してください。
選択を生成するかどうかにかかわらず、集約ビューの選択は集約スクリプトとして保存できます。集約スクリプトには柔軟性があり、同じ選択が再度必要になった場合に選択プロセスをバイパスできるため、時間を節約できます。集約スクリプトの操作を参照してください。
選択プロセスが終了すると、選択された集約ビューは集約を生成するときに計算されます。
次のプロセスに従って集約を定義および生成することをお薦めします:
オプション: 格納停止ポイントを指定します。
クエリー時間や集約時間が長すぎる場合は、集約の微調整を検討してください。集約ビューの選択の調整を参照してください。
集約スクリプトの操作を参照してください。
データベース集約の選択または生成を実行するには、次のツールを使用します:
集約設計ウィザードを使用すれば、集約プロセスをバックグラウンドで実行できます。Administration Servicesのプロセスをバックグラウンドで実行するときは、バックグラウンド・プロセスを実行しながら、同時に他のアクティビティのために管理サービス・コンソールの使用を続けることができます。 |
集約のパフォーマンスの最適化も参照してください。
Essbaseで提案される集約ビューのデフォルトの選択では、非常に優れたパフォーマンスが得られます。ただし、選択リスト内のすべての集約ビューを受け入れると、最適なパフォーマンスは保証されません。デフォルトの選択では、Essbaseが保管階層を分析し、どの集約セルでも取得される可能性が等しいと仮定します。Essbaseでは、クエリーの時点で使用可能なメモリーの容量などの外的要因には対応できません。使用可能なメモリーは、取得時のキャッシュ・メモリーの定義や、他の同時プロセスで必要なメモリーなどの要因の影響を受ける可能性があります。
どのデータが最もクエリーされるかを追跡し、その結果と代替ビューを集約ビューの選択プロセスに組み込むことをお薦めします。使用状況に基づいたビューの選択を参照してください。
集約を調整してテストする場合は、次の点を考慮してください:
集約ビューのサイズを見積るには、essbase.cfgのASOSAMPLESIZEPERCENT構成設定を使用すると、Essbaseで使用されるサンプル・セルの数を指定できます。サンプル・サイズは、入力レベル・データのパーセンテージで指定します。デフォルト(最小)のサンプル・サイズは100万(1,000,000)セルです。『Oracle Essbaseテクニカル・リファレンス』を参照してください。
Essbaseでは、データベースに適したバランスの集約ビューを選択して保管する際に役立つ情報が提供されます。この情報を、データベースの取得要件と環境についてわかっている事柄と比較検討してください。次の情報は、集約のための集約ビューの選択に役立ちます:
集約ビュー選択時には、次の2通りの方法でストレージの上限を指定できます:
集約の選択を開始するときには、最大保管停止値を指定します。集約ビューは、指定されたストレージの上限に達するまで、または選択するビューがなくなるまで選択されます。
Administration Servicesでは、ユーザーが指定する数値はストレージの容量(MB)です。MaxLでは、この数値は、レベル0の保管される値のサイズの係数倍です。Oracle Essbase Administration Services Online Helpおよび『Oracle Essbaseテクニカル・リファレンス』を参照してください。
データベースの各分析の後、Essbaseはレベル0の入力セル・ビューに関する情報と、その後に提案された集約ビューのリストを表示します。集約ビューごとに、その集約ビューが含まれるストレージ番号と、その集約ビューが依存する他のすべての集約ビューが表示されます。集約に含める集約ビューを選択するときは、このストレージ番号を考慮に入れることができます。
集約ビューごとに表示されるクエリー・コスト番号により、関連する集約ビューから値を取得するための平均取得時間が推定されます。デフォルトのビュー選択では、可能なすべてのクエリーの平均としてのコストが見積られます。クエリーの追跡を使用する場合、見積られるコストは追跡されるすべてのクエリーの平均です。特定の集約ビューのコスト番号は、異なる選択リストでは異なることがあります。たとえば、集約ビュー0, 0, 1/0, 2/0, 0は、デフォルトの選択リストでは、分析で追跡したクエリーが含まれる選択に示されるものとは異なるクエリー・コストを示すことがあります。
改善率をパーセンテージで計算するには、集約ストレージのクエリー・コスト値をレベル0の入力セルのみを保存する場合のクエリー・コスト値で除算します。
集約ビューの選択を実行する前に、クエリーの追跡をオンにして、最も頻繁に取得されるデータを確認できます。一定期間のデータベースのアクティビティの後、Essbaseで集約分析プロセスに使用状況統計を組み込むことができます。使用状況に基づいたビューの選択を参照してください。
選択プロセスの完了後の集約実行にかかる時間は、集約ビューが生成されるたびに増加します。実際の集約時間を確認するには、集約を実行する必要があります。
データベースの集約の実行で説明しているデフォルトの集約を実行します。
集約スクリプトにデフォルトの選択を保存します。集約スクリプトの操作を参照してください。
クエリーの追跡をオンにします。使用状況に基づいたビューの選択を参照してください。
データベースに対して、ユーザーに通常のクエリーを実行してもらいます。または、集約が設定されているデータベースに対してバッチ・クエリーの操作を実行します。すべてのクエリー・ツールによるクエリーが追跡されます。
レポートの生成やユーザー・クエリーなど、異なるデータベース取得状況で最適な集約を選択するには、調整プロセスを繰り返し、それぞれの状況に応じた集約スクリプトを作成することが必要となる場合があります。集約スクリプトの操作を参照してください。 |
Essbaseでは、データベースに対する取得統計を捕捉できます。その後、それらの統計を使用して、自社の取得パターンに合った集約を構築できます。また、Essbaseでは、使用状況の情報が集約ビューの選択プロセスで使用されるときに、データベースの分析に代替階層も含めます。
定期的なレポートのためのデータベース使用状況は、進行中のユーザー取得の場合とは異なることがあります。様々な取得の状況を最適化するには、状況による使用パターンの追跡と状況ごとの集約スクリプトの作成を検討してください。
集約の選択プロセスを開始する前に、クエリーの追跡がオンになっていて、使用状況の捕捉に十分な時間が経過していることを確認してください。
クエリーの追跡では、クエリー使用状況の情報がメモリー内に保持されます。次のいずれかの操作を実行すると、クエリー使用状況の情報が消去されます。
デフォルトでは、Essbaseは、内部的なメカニズムを使用して集約の作成方法を決定します。ユーザー定義のビュー選択には、デフォルトのビュー選択とクエリー・データに基づいたビュー選択に影響を与える方法があります。使用状況に基づいたビューの選択を参照してください。
管理者は、保管階層にビュー選択プロパティを適用して、Essbaseに特定のレベルの集約が選択されないようにすることもできます。
注: | セカンダリ階層は、共有または属性階層のいずれかです。 |
|
プロパティ |
効果 |
|---|---|
|
デフォルト |
プライマリ階層については、Essbaseによってすべてのレベルが検討されます。代替ロールアップが使用可能な場合を除き、セカンダリ階層は集約されません。 |
|
すべてのレベルを検討 |
集約の可能性のある候補として、階層のすべてのレベルが検討されます。これはプライマリ階層ではデフォルトですが、セカンダリ階層ではデフォルトではありません。 |
|
集約しない |
この階層の集約は行われません。Essbaseで選択されるすべてのビューは、入力レベルです。 |
|
最下位レベルのみ検討 |
セカンダリ階層にのみ適用されます。Essbaseでは、この階層の最下位レベルのみの集約が検討されます。 |
|
上位レベルのみ検討 |
プライマリ階層にのみ適用されます。この階層の最上位レベルのみの集約が検討されます。 |
|
中間レベルに集約しない |
プライマリ階層に適用されます。最上位レベルと最下位レベルのみを選択します。 |
注: | 最下位レベルの属性次元は、ゼロレベルの属性メンバーで構成されます。セカンダリ階層が共有メンバーを使用して形成されている場合、最下位レベルは共有メンバーの直属の親を構成します。 |
Essbaseでは、選択されたビュー選択プロパティを満たすビューのみが検討されます。
デフォルトのプロパティを変更するには、データベースの主要なクエリー・パターンに精通している必要があります。特定のビューが選択されないようにすると、それらのビューに対するクエリーは遅くなりますが、他のクエリーの速度は上がります。同様に、セカンダリ階層で「すべてのレベルを検討」を有効にすると、その階層に対するクエリーは速くなり、他のクエリーは遅くなることがあります。
クエリー・ヒントは、実行される可能性のあるクエリーのタイプをEssbaseに指定します。たとえば、時間次元の最下位レベルのクエリーを指定するには、1月のように、最下位レベルの時間で1つのメンバーを指定できます。これにより、Essbaseに任意のメンバーが最下位レベルの時間でクエリーされる可能性があることが指定されます。Essbaseにより、ビューを選択する際のクエリー・ヒントの優先度で指定されたメンバーが指定され、共通のクエリーが最適化されます。
次元にメンバーが指定されていない場合は、その次元のメンバーがクエリーで使用される可能性があることを意味します。たとえば、Sample.Basicで(Sales, 100, East)のクエリー・ヒントを使用することは、レベル1の市場のレベル1の製品の利益率メジャーが、除外された年次元およびシナリオ次元とは無関係に、共通のタイプのクエリーであることを意味します。
使用状況に基づいたビューの選択は、クエリー・ヒントに優先します。使用状況に基づいたビューの選択を参照してください。ユーザー定義ビューの選択は、両者の間に競合がある場合は、クエリー・ヒントに優先します。ユーザー定義ビューの選択の理解を参照してください。
アスタリスク「*」は、次元にメンバーが選択されていないことを示します。
|
ヒント |
使用事例 |
|---|---|
|
(Jan, *, *, *, *,) |
最下位レベルの時間に対する頻繁なクエリー。 |
|
(Qtr1, *, *, *, Cola) |
大抵の場合、クエリーには、最下位レベルの製品と四半期レベルの時間のメンバーが含まれます。 |
|
(Jan, *, *, NY, *) (Qtr1, *, *, NY, *) |
「Market」の州レベルでの分析は、「Quarterly」レベル以下であり続ける傾向があります。 |
同じアウトライン内に多数のヒントが存在可能です。少なくとも1つのヒントに適合するビューは、適合するものがないビューよりも重要視されます。
クエリー・ヒントに、動的メンバー、ラベルのみメンバーまたは共有メンバーを含めることはできません。
各集約スクリプトは、データベースに対する特定の集約ビューの選択を表しています。
集約スクリプトによって時間を節約できます。たとえば、新しいデータ値をロードした後、別の集約ビューの選択を実行する必要はありません。集約スクリプトに保管されている選択を使用して集約を生成することで、集約プロセスの速度を上げることができます。
集約スクリプトによって柔軟性を得ることもできます。集約スクリプトには、異なる取得状況ごとに最適化された集約ビューの選択を保存できます。たとえば、月末レポートの取得を最適化するためのスクリプトや、日次レポートの取得を最適化するためのスクリプトを保存して使用できます。
データベースの集約スクリプトに含まれている選択がそのデータベースには無効な場合、そのスクリプトは無効になります。集約スクリプトは、集約の作成時に作成します。集約スクリプト・ファイルは手動で変更しないでください。手動で変更すると、予測できない結果が生じることがあります。集約および集約スクリプトを作成する必要があるタイミングの詳細は、集約の置換を参照してください。
保存されている集約スクリプトを使用すれば、全集約プロセスを分割できます。集約は、その集約の集約ビューが選択されているときとは異なる時点で生成できます。集約スクリプトには、集約ビューの選択段階で導出される情報が含まれます。
集約スクリプトは、拡張子が.cscのテキスト・ファイルとしてデータベース・ディレクトリに保管され、アウトライン内の次元レベルの構造が変更されていないかぎり有効です。集約の選択が有効なタイミングの詳細は、集約の置換を参照してください。無効な集約スクリプト・ファイルの潜在的なクラッタを回避するには、集約設計ウィザードを使用します。それらのファイルがもう有用ではない場合は、集約スクリプトを手動で削除します。
集約のパフォーマンス時間を可能なかぎり改善するため、CALCPARALLEL構成設定を使用してスレッド数を増やすことができます。各スレッドは集約ビューの構築タスクを取り扱うため、ユーザーが定義するスレッド数で、同時に構築できる集約ビューの数が設定されます。シングルCPUのコンピュータでも、CALCPARALLEL構成設定を大きくすると、データベースがメモリーには大きすぎるといった、構築する集約がI/Oバウンドである場合のパフォーマンスが向上することがあります。スレッドは集約ストレージ・キャッシュを共有する必要があるため、定義されたスレッド数をサポートするには、このキャッシュ・サイズを十分に大きくする必要があります。それ以外の場合は、スレッド数を大きくすると、集約のパフォーマンス時間が低下することがあります。
注: | 小規模なデータベースについては、Essbase9.3.1以降のバージョンにおける集約ビューの構築のパフォーマンスは、9.3.1より前のバージョンのEssbaseよりも遅くなる可能性があります。ただし、数億セルより大きいデータベースについては、Essbase 9.3.1は、複数のプロセッサを装備し、CALCPARALLEL構成の設定が適切に選択されているコンピュータ上で特に優れたパフォーマンスを発揮します。 |
ディスクからの集約の消去は、手動で行うほうがよい場合もあります。たとえば、ディスク・スペースをディスクの使用度が高い操作に使用できるようにする場合です。集約を消去すると、レベル0の値を除くすべてのデータがデータベースから消去され、他の用途で使用できるようにディスク領域が解放されます。集約が消去された後、クエリーにより、レベル0の値から動的に取得された値が計算されます。
Essbaseサーバーで集約されたデータが自動的に消去されるタイミングについては、表192の「データベースの再構築」を参照してください。
集約は、既存の集約を消去し、集約ビューの別の選択を生成することで置換できます。新しい集約ビューの選択および生成プロセスを実行することも、集約スクリプトを実行することもできます。次のような状況では、集約の置換を検討してください:
集約ビューの選択を微調整してパフォーマンスを向上させる場合。集約ビューの選択の調整を参照してください。
データベース・サイズが著しく増大した後で集約を最適化する場合。データベースのサイズが徐々に大きくなると、集約の効率が低くなることがあります。パフォーマンスの低下が顕著な場合や、データベース・サイズが元のサイズの約150%まで増加した場合は、集約の置換を検討してください。
次元内のレベル数が変更されたり、アウトラインに1つ以上の次元が追加または削除された場合には、集約および関連する集約スクリプトを置換する必要があります。データベースの集約の実行および集約スクリプトの操作を参照してください。
この項のトピックでは、集約ストレージ・データベースでのタイム・バランスおよびフロー・メトリック計算の実行方法について説明します。
集約ストレージの会計次元にタイム・バランス・プロパティを設定することで、時間次元に沿った組込みの計算を実行できます。これにより、タイムバランス機能を実行するためのメンバー式使用の時間とパフォーマンスのオーバーヘッドが削減されます。
保管済または式を持つ会計次元メンバーでは、次のタイムバランス・プロパティがサポートされています:
TB期首、TB期末、TB平均
スキップしない、#Missingのスキップ
人的資源アプリケーションの「Headcount」などの保管済メジャーについて考えてください。年-四半期-月階層では、「Headcount」のデータは月レベルでロードされます。

目的の年ごとまたは四半期ごとの「Headcount」の値は、その月の合計ではありません。そうではなく、期間内に記録された最後の値である必要があります。
SKIPMISSINGで「Headcount」にTB期末のタグを付けることは、「Year 2005」の場合は、その値がその月の従業員数の空でない最後の値であることを意味します。「Dec」に欠落していない「Headcount」値がある場合は、その値が戻されます。そうでない場合は、「Nov」の値がチェックされ、欠落していない場合はこの値が戻されます。
式を持つメンバーにタイム・バランス・タグがある場合、この式はレベル0の時間メンバーに対してのみ実行され、時間次元はタイム・バランス・タグに従って集約されます。
タイム・バランス・タグには、時間次元に沿った組込みの計算があります。期間累計やローリング平均など、式を使用するその他の時間ベースの計算を実行するには、TimeViewという次元を作成し、その次元にすべての時間ベースの式を記述できます。これを実行することで、他の時間ベースの計算が実行不可になることなく、タイム・バランス計算の機能を使用できます。
フロー・タグは、会計次元メンバーを持つ式に割り当てることができます。
次の例で、フロー・メトリックで解決される問題について説明します。12か月すべてに「売上」と「追加」のデータがあることが前提です。各月の初めの在庫を読み込むために集約を実行しようとしています。
期首在庫メンバーを計算するために、そのメンバーでMDX式を使用する場合もあります。フロー・メトリックを使用しないで各月の期首在庫を取得するには、計算機エンジンでMDX式を幾何学級数的に繰り返すことが必要な場合があります。
Inventory = SUM(MemberRange(Jan:Time.CurrentMember), (Additions - Sales)) + Beg_Inventory
図で示した例を最適化するには、在庫メンバーに式(Addition - Sales)を割り当ててから、メンバーにフローとタグ付けします。
代替階層が集約ストレージの時間次元で使用される場合は、会計次元でフロー・タグとTBタグを使用するときに、次の制限が適用されます:
代替時間階層間の共有レベルは、レベル0である必要があります。
代替時間階層間の共有レベルでのメンバーの順序は、すべての代替階層内で同じである必要があります。
MDXのAggregate関数は、タイム・バランス・タグが付けられたメジャーの集約に使用できます。『Oracle Essbaseテクニカル・リファレンス』を参照してください。
次のような場合、次の計算ロジックが適用されます
集約ストレージ・アウトラインに、1つ以上の属性を持つ日時次元またはリンク属性次元が含まれている。
タイム・バランス・タグが付いたメジャーでクエリーを実行する。
上のケースが両方とも当てはまる場合は、セルを評価するためにMDXのAggregate()セマンティクスが使用されます。
たとえば、次のようなシナリオを考えてみます:
「Year」は日レベルの階層を持つ日時次元である。
「Holiday」は「Year」の属性次元であり、それぞれの日付にHoliday_TRUEまたはHoliday_FALSEとタグ付けされている。
「Opening Inventory」にTBFirstとタグ付けされている。
(Year, Holiday_TRUE, [Opening Inventory])の値はMDXのロジックに従って評価されます:
Aggregate( {Set of dates that are holidays in Year}, [Opening Inventory])