Table of Contents
Welcome to Oracle NoSQL Database. Oracle NoSQL Database provides multi-terabyte distributed key/value pair storage that offers scalable throughput and performance. That is, it services network requests to store and retrieve data which is accessed as tables of information or, optionally, as key-value pairs. Oracle NoSQL Database services these types of data requests with a latency, throughput, and data consistency that is predictable based on how the store is configured.
Oracle NoSQL Database offers full Create, Read, Update and Delete (CRUD) operations with adjustable durability guarantees. Oracle NoSQL Database is designed to be highly available, with excellent throughput and latency, while requiring minimal administrative interaction.
Oracle NoSQL Database provides performance scalability. If you require better performance, you use more hardware. If your performance requirements are not very steep, you can purchase and manage fewer hardware resources.
Oracle NoSQL Database is meant for any application that requires network-accessible data with user-definable read/write performance levels. The typical application is a web application which is servicing requests across the traditional three-tier architecture: web server, application server, and back-end database. In this configuration, Oracle NoSQL Database is meant to be installed behind the application server, causing it to either take the place of the back-end database, or work alongside it. To make use of Oracle NoSQL Database, code must be written (using Java or C) that runs on the application server.
An application makes use of Oracle NoSQL Database by performing network requests against Oracle NoSQL Database's data store, which is referred to as the KVStore. The requests are made using the Oracle NoSQL Database Driver, which is linked into your application as a Java library (.jar file), and then accessed using a series of Java APIs.
By using the Oracle NoSQL Database APIs, the developer is able to perform create, read, update and delete operations on the data contained in the KVStore. The usage of these APIs is introduced later in this manual.
Note
Oracle NoSQL Database is tested using Java 7, and so Oracle NoSQL Database should be used only with that version of Java.
The KVStore is a collection of Storage Nodes which host a set of Replication Nodes. Data is spread across the Replication Nodes. Given a traditional three-tier web architecture, the KVStore either takes the place of your back-end database, or runs alongside it.
The store contains multiple Storage Nodes. A Storage Node is a physical (or virtual) machine with its own local storage. The machine is intended to be commodity hardware. It should be, but is not required to be, identical to all other Storage Nodes within the store.
The following illustration depicts the typical architecture used by an application that makes use of Oracle NoSQL Database:
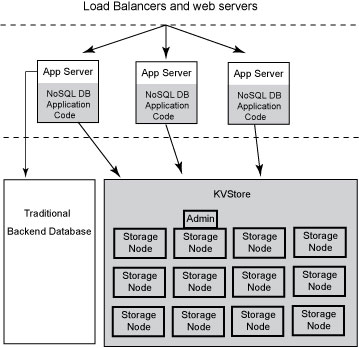
Every Storage Node hosts one or more Replication Nodes as determined by its capacity. The capacity of a Storage Node serves as a rough measure of the hardware resources associated with it. A store can consist of Storage Nodes of different capacities. Oracle NoSQL Database will ensure that a Storage Node is assigned a load that is proportional to its capacity. A Replication Node in turn contains at least one and typically many partitions. Also, each Storage Node contains monitoring software that ensures the Replication Nodes which it hosts are running and are otherwise healthy.
At a very high level, a Replication Node can be thought of as a single database which contains key-value pairs.
Replication Nodes are organized into shards. A shard contains a single Replication Node, called the master node, which is responsible for performing database writes, as well as one or more read-only replicas. The master node copies all writes to the replicas. These replicas are used to service read-only operations. Although there can be only one master node at any given time, any of the members of the shard (with the exception of nodes in a secondary zone as described below) are capable of becoming a master node. In other words, each shard uses a single master/multiple replica strategy to improve read throughput and availability.
The following illustration shows how the KVStore is divided up into shards:
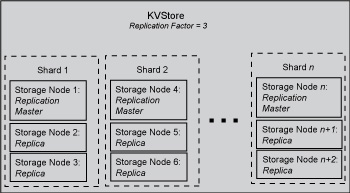
Note that if the machine hosting the master should fail in any way, then the master automatically fails over to one of the other nodes in the shard. That is, one of the replica nodes is automatically promoted to master.
Production KVStores should contain multiple shards. At installation time you provide information that allows Oracle NoSQL Database to automatically decide how many shards the store should contain. The more shards that your store contains, the better your write performance is because the store contains more nodes that are responsible for servicing write requests.
The number of nodes belonging to a shard is called its Replication Factor. The larger a shard's Replication Factor, the faster its read throughput (because there are more machines to service the read requests) but the slower its write performance (because there are more machines to which writes must be copied).
Once you set the Replication Factor for each zone in the store, Oracle NoSQL Database makes sure the appropriate number of Replication Nodes are created for each shard residing in each zone making up your store. The number of copies, or replicas, maintained in a zone is called the Zone Replication Factor. The total number of replicas in all Primary zones is called the Primary Replication Factor, and the total number in all Secondary zones is called the Secondary Replication Factor. For all zones in the store, the total number of replicas across the entire store is called the Store Replication Factor.
Each shard contains one or more partitions. Table rows (or key-value pairs) in the store are accessed by the data's key. Keys, in turn, are assigned to a partition. Once a key is placed in a partition, it cannot be moved to a different partition. Oracle NoSQL Database spreads records evenly across all available partitions by hashing each record's key.
As part of your planning activities, you must decide how many partitions your store should have. Note that this is not configurable after the store has been installed.
It is possible to expand and change the number of Storage Nodes in use by the store. When this happens, the store can be reconfigured to take advantage of the new resources by adding new shards. When this happens, partitions are balanced between new and old shards by redistributing partitions from one shard to another. For this reason, it is desirable to have enough partitions so as to allow fine-grained reconfiguration of the store. Note that there is a minimal performance cost for having a large number of partitions. As a rough rule of thumb, there should be at least 10 to 20 partitions per shard, and the number of partitions should be evenly divisible by the number of shards. Since the number of partitions cannot be changed after the initial deployment, you should consider the maximum future size of the store when specifying the number of partitions.
A zone is a physical location that supports good network connectivity among the Storage Nodes deployed in it and has some level of physical separation from other zones. A zone generally includes redundant or backup power supplies, redundant data communications connections, environmental controls (for example: air conditioning, fire suppression) and security devices. A zone may represent an actual physical data center building, but could also represent a floor, room, pod, or rack, depending on the particular deployment. Oracle recommends you install and configure your store across multiple zones to guard against systemic failures affecting an entire physical location, such as a large scale power or network outage.
Multiple zones provide fault isolation and increase the availability of your data in the event of a single zone failure.
Zones come in two types. Primary zones contain nodes which can serve as masters or replicas. Zones are created as primary zones by default. Secondary zones contain nodes which can only serve as replicas. Secondary zones can be used to make a copy of the data available at a distant location, or to maintain an extra copy of the data to increase redundancy or read capacity.
A topology is the collection of zones, storage nodes, replication nodes and administration services that make up a NoSQL DB store. A deployed store has one topology that describes its state at a given time.
After initial deployment, the topology is laid out so as to minimize the possibility of a single point of failure for any given shard. This means that while a Storage Node might host more than one Replication Node, those Replication Nodes will never be from the same shard. This improves the chances of the shard continuing to be available for reads and writes even in the face of a hardware failure that takes down the host machine.
Topologies can be changed to achieve different performance characteristics, or in reaction to changes in the number or characteristics of the Storage Nodes. Changing and deploying a topology is an iterative process.