| Oracle® Fail Safe概要および管理ガイド リリース4.1.1 for Microsoft Windows E61782-01 |
|



 前 |
 次 |
Oracle Fail Safeの高可用性ソリューションでは、Microsoft Windowsクラスタ・ハードウェアとMicrosoft Windowsフェイルオーバー・クラスタ・ソフトウェアを使用しています。
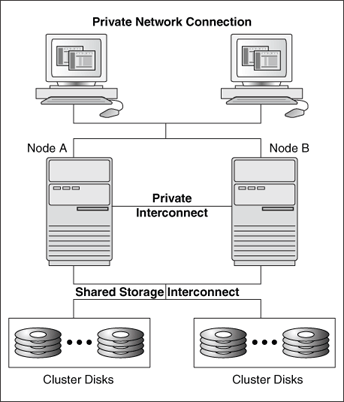
Microsoftクラスタは、2つ以上の独立したコンピューティング・システム(ノードと呼ばれる)が同じディスク・サブシステムに接続された構成になっています。
Microsoft Windowsソフトウェアに組み込まれているMicrosoft Windowsフェイルオーバー・クラスタ・ソフトウェアにより、Windowsクラスタにデプロイされたアプリケーションおよびハードウェア・コンポーネント(リソースと呼ばれる)を構成、監視および制御できます。
Oracle Fail Safeが提供する高可用性機能を利用するためには、Microsoft Windowsフェイルオーバー・クラスタの概念を理解することが重要になります。
この章では、次の項目について説明します。
クラスタのメンバーであるWindowsシステムをクラスタ・ノードと呼びます。クラスタ・ノードは、パブリックな共有ストレージ・インターコネクトおよびプライベート・ノード間ネットワーク接続によって結合されます。
ノード間ネットワーク接続(ハートビート接続とも呼ばれる)では、あるノードが使用可能かどうかを別のノードから検出できます。この通信には、(ユーザーおよびクライアント・アプリケーションのアクセスに使用されるパブリック・ネットワーク接続と区別される)プライベート・インターコネクトを使用することが一般的です。あるノードに障害が発生した場合、クラスタ・ソフトウェアは使用不可になったノードの作業負荷をただちに使用可能なノードにフェイルオーバーし、障害発生ノードが所有していたあらゆるクラスタ・リソースを使用可能なノードに再マウントします。クライアントは、何も変更することなく、クラスタ・リソースに継続してアクセスします。
図2-1に、2つのノードからなるMicrosoftクラスタ構成でのネットワーク接続を示します。
クラスタ・テクノロジが利用できるようになるまでは、PCシステムの信頼性はRAIDやミラー化ドライブ、および電源の二重化といったハードウェアの冗長性によって達成されていました。可用性の高いシステムを作成する上でディスク冗長性は重要ですが、この方法のみではシステムとアプリケーションの可用性を保証できません。
Microsoft Windowsフェイルオーバー・クラスタ・ソフトウェアを使用してWindowsクラスタ内のサーバーに接続すると、通常の操作中は各サーバー(ノード)がクラスタ・ディスクのサブセットに排他的アクセスすることになり、サーバーの冗長化を実現します。クラスタは、互いに依存しないスタンドアロン・システムよりはるかに効率的です。なぜなら、各ノードはそれぞれ有効な作業を実行できる上に、障害が発生したクラスタ・ノードのディスク・リソースおよび作業負荷を引き継ぐことができるためです。
クラスタは、その設計によって、コンポーネントの障害を管理し、コンポーネントの追加と削減をユーザーに認識させず、高い可用性を実現します。障害の検出、リカバリ、およびクラスタ・ノードを単一のシステムとして管理する能力などのサービスの提供を含む、付加的な利点があります。
クラスタ構成の設定と使用には、様々な方法があります。Oracle Fail Safeでは、次の構成がサポートされています。
アクティブ/パッシブ構成
アクティブ/アクティブ構成
これらの構成の詳細は、第3章を参照してください。
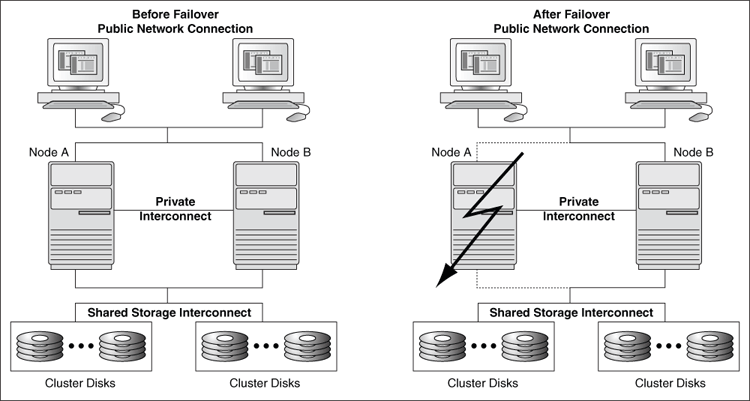
Windowsフェイルオーバー・クラスタが障害からリカバリする際には、正常に機能しているノードが、シェアード・ナッシング構成を介して障害発生ノードのディスク・データへのアクセスを獲得します。
シェアード・ナッシング構成では、すべてのノードが物理的に同一ディスクにケーブル接続されていますが、特定のディスクにアクセスできるのは一度につき1つのノードのみです。すべてのノードが物理的にディスクに接続されていても、そのディスクを所有しているノードしか、それらにアクセスできません。
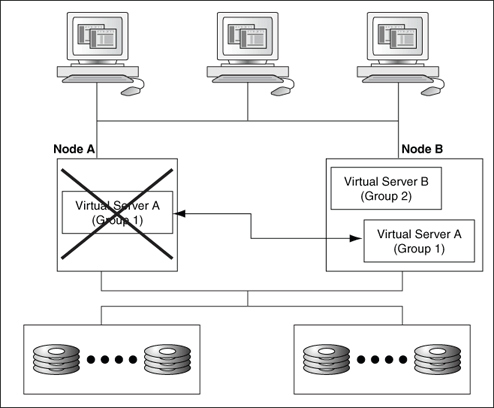
図2-2は、2つのノードからなるクラスタで1つのノードが使用不可になった場合に、障害発生ノードが所有していたディスクおよびアプリケーション作業負荷の所有権を、もう一方のクラスタ・ノードが引き受け、両方のノードに対する操作の処理を続行することを示しています。
あるサーバー・ノードが使用不可になった場合、可用性が高まるように構成されたクラスタ・リソース(ディスク、Oracle Databaseとアプリケーション、IPアドレスなど)は、グループと呼ばれる単位で使用可能なノードに移されます。グループは、サービスまたはアプリケーション、あるいはクラスタ化されたロールと呼ばれることもあります。次の各項でリソースおよびグループについて説明し、可用性が高まるようにそれらを構成する方法を説明します。
グループは、フェイルオーバーの最小単位を形成するクラスタ・リソースの論理的な集合です。グループは、サービスまたはアプリケーション、あるいはクラスタ化されたロールと呼ばれることもあります。フェイルオーバーの際には、グループ単位のリソースが別のノードに移されます。グループは、同時に1つのクラスタ・ノードにのみ所有されます。特定の作業負荷のために必要なリソース(データベース、ディスクおよび他のアプリケーション)はすべて、同じグループに常駐している必要があります。
たとえば、Oracle Fail Safeを使用して可用性の高いOracle Databaseを構成するために作成されたサービスまたはアプリケーションには、次のようなリソースが含まれる可能性があります。
Oracle Databaseのインスタンス
それぞれ次のもので構成される1つ以上のネットワーク名:
IPアドレス
グループ内のデータベースへの接続要求をリスニングするOracle Netネットワーク・リスナー
Oracle Enterprise Managerとサービスまたはアプリケーション内のデータベースの間の通信を管理するOracle Management Agent
リソースをグループに追加する場合、そこで使用されるディスクも同じグループに含まれる点に注意してください。そのため、同一のディスクを使用する2つのリソースを異なるグループに含めることはできません。両方のリソースをフェイルセーフにするには、同じグループに含めてください。
Microsoft Windowsフェイルオーバー・クラスタ・マネージャを使用して、グループを作成し、アプリケーションを実行するために必要なリソースを追加できます。
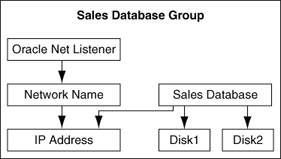
図2-3に、販売データベースの可用性が高まるように作成されたグループを示します。リソースをグループに追加すると、追加したリソースが依存しているリソースがOracle Fail Safe Managerによって自動的に追加されます。この関係はリソースの依存性と呼ばれます。たとえば、シングルインスタンス・データベースをグループに追加すると、Oracle Fail Safeにより、データベース・インスタンスで使用されるシェアード・ナッシング・ディスクが追加され、Oracle Netファイルがそれぞれのグループと連携するように構成されます。また、Oracle Fail Safeでは、各グループがそれぞれのノードにフェイルオーバーできるかどうかがテストされます。
クラスタ内のノードはそれぞれ1つ以上のグループを所有できます。各グループは、関連付けられたリソースの独立したセットで構成されます。グループ内のリソースの依存関係によって、クラスタ・ソフトウェアがリソースをオンライン化またはオフライン化する順序が定義されます。たとえば、障害が発生するとまずOracleアプリケーションまたはデータベース(およびOracle Netリスナー)がオフライン化され、続いて物理ディスク、ネットワーク名、IPアドレスがオフライン化されます。フェイルオーバー・ノードでは、順序が逆になり、Windowsフェイルオーバー・クラスタによって最初にIPアドレスがオンライン化され、次にネットワーク名、物理ディスク、最後にOracle DatabaseとOracle Netリスナー、またはアプリケーションがオンライン化されます。
各リソース・タイプ(汎用サービス、物理ディスク、Oracle Databaseなど)は、リソースのDynamic Link Library(DLL)と関連付けられており、クラスタ環境ではそのリソースDLLを使用して管理されます。標準のMicrosoft Windowsフェイルオーバー・クラスタのリソースDLLおよびカスタムOracleリソースDLLがあります。同じリソースDLLで異なるリソース・タイプをサポートできます。
Microsoft Windowsフェイルオーバー・クラスタは、IPアドレス、物理ディスク、汎用サービスなどのサポートされるリソース・タイプのリソースDLLを提供します。(汎用サービス・リソースは、Microsoft Windowsフェイルオーバー・クラスタが提供するリソースDLLによってサポートされるWindowsサービスです。)
Oracle Fail Safeでは、カスタム・サポートが提供されているリソース・タイプ(汎用サービスなど)を監視する際に、多数のWindowsフェイルオーバー・クラスタ・リソースDLLを使用します。
オラクル社では、Oracle Databaseリソース・タイプに対するカスタムDLLを提供しています。Windowsフェイルオーバー・クラスタは、OracleリソースDLLを使用してOracle Databaseリソースを管理(オンライン化およびオフライン化)し、リソースの可用性を監視します。
Oracle Fail SafeはDLLファイルを提供し、Microsoft Windowsフェイルオーバー・クラスタによるOracle Databaseリソースの通信および監視を有効化できます。FsResOdbs.dllが提供する機能によって、Microsoft Windowsフェイルオーバー・クラスタはOracle Databaseおよびそのリスナーをオンライン化またはオフライン化し、Is Aliveポーリングを介してデータベースの状態をチェックできます。
Oracle Fail Safe Managerを使用してOracle Databaseをグループに追加すると、Oracle Fail Safeによってデータベース・リソースとOracleリスナー・リソースが作成されます。
Oracle Fail Safeには、Oracleクラスタ・リソースに関する情報がMicrosoft Windowsフェイルオーバー・クラスタよりも多く含まれています。このため、Oracle Databaseおよびアプリケーションを構成し管理する場合はOracle Fail Safe Manager(またはOracle Fail Safe PowerShellコマンドレット)を使用することをお薦めします。
|
関連項目: Oracle Fail Safeによって提供されるカスタム・リソースDLLの詳細は『Oracle Fail Safeインストレーション・ガイドfor Microsoft Windows』を参照し、標準リソース・タイプおよびリソースDLLの詳細はMicrosoft Windowsフェイルオーバー・クラスタのドキュメント・セットを参照してください。 |
ネットワーク名は、グループ内のリソースのホストになっているクラスタ・ノードとは無関係に、リソースにアクセスできるネットワーク・アドレスです。ネットワーク名によって、ノードに依存しない一定したネットワークの場所が提供されます。これにより、クライアントはリソースのホストになっている物理的クラスタ・ノードを認識することなく、容易にリソースにアクセスできます。
障害が起きている間にグループが使用不可ノードから使用可能ノードに移されるため、クライアントは、1つのノードによってしか識別されないアドレスを使用しているアプリケーションには接続できません。Oracle Fail Safe Manager内のグループのネットワーク名を識別するには、グループに一意のネットワーク名とIPアドレスを付加します。
ネットワーク名リソースをグループに追加するには、Microsoft Windowsフェイルオーバー・クラスタ・マネージャを使用します。
ネットワーク名をグループに追加すると、グループは仮想サーバーになります。クライアント・アクセスのために各グループには少なくとも1つのネットワーク名が必要ですが、グループに複数のネットワーク名を割り当てることができます。帯域幅を増やしたり、グループ内のリソースのセキュリティを区分化するために、複数のネットワーク名を割り当てることもできます。
ユーザーやクライアント・アプリケーションからは、各グループは特定のノードの物理的識別情報に依存しない、可用性の高い仮想サーバーのように見えます。グループ内のリソースにアクセスするために、クライアントは必ずグループのネットワーク名に接続します。クライアントにとって、仮想サーバーはクラスタ・リソースへのインタフェースであり、物理ノードのように見えます。
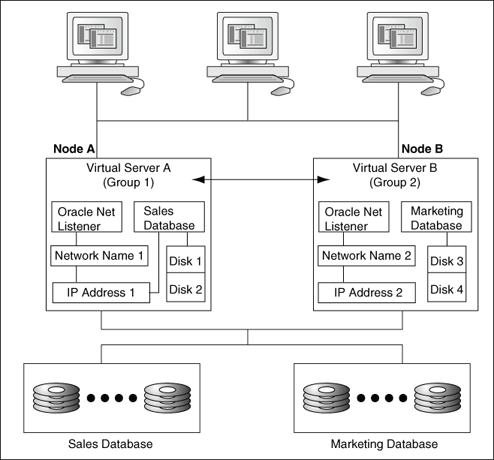
図2-4に、各ノードに1つのグループを構成した2ノード・クラスタを示します。クライアントは仮想サーバーAおよびBを通じてこれらのグループにアクセスします。各ノードの物理アドレスではなく、グループのネットワーク名を介してクラスタ・リソースにアクセスすることで、どのクラスタ・ノードがグループのホストになっているかにかかわらず、確実にリモート接続ができます。
クラスタをセットアップする際に、少なくとも次の数のIPアドレスを割り当てます。
各クラスタ・ノードに対して1つのIPアドレス
各クラスタ別名(2.5項を参照)に対して1つのIPアドレス
各グループに対して1つのIPアドレス
たとえば、図2-4の構成では、2つのクラスタ・ノードに1つずつ、クラスタ別名に1つ、そして2つのグループに1つずつで合計5つのIPアドレスが必要です。
|
関連項目: Oracle Fail Safe環境でのIPアドレス割当ての詳細は、『Oracle Fail Safeインストレーション・ガイドfor Microsoft Windows』を参照してください。 |
クラスタ別名とは、クラスタを特定し、クラスタ関連のシステム管理に使用される、ノードに依存しないネットワーク名です。Microsoft Windowsフェイルオーバー・クラスタはクラスタ・グループと呼ばれるグループを作成し、クラスタ別名はこのグループのネットワーク名です。Oracle Fail Safeはクラスタ・グループ内にあるリソースです。このためクラスタ・グループの可用性が高められると同時に、すべてのクラスタ・ノードのOracle Fail Safeの処理が常にOracle Fail Safeにより調整されます。
Oracle Fail Safe環境では、クラスタ別名はシステム管理の目的でしか使用されません。Oracle Fail Safe Managerは、クラスタ別名を使用してクラスタ・コンポーネントおよびMicrosoft Windowsフェイルオーバー・クラスタと対話します。
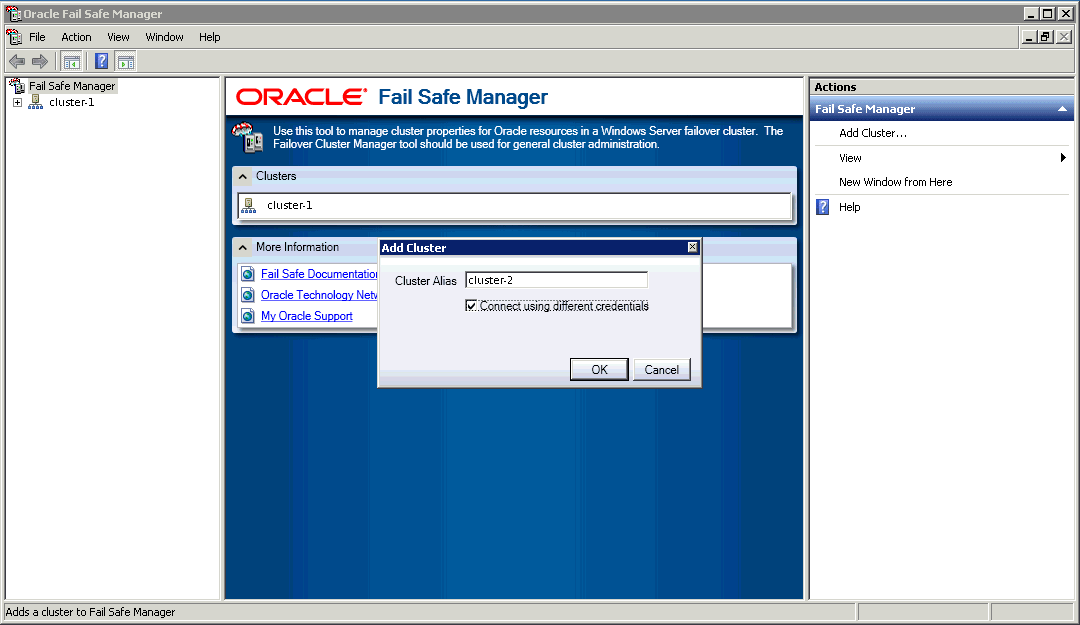
特定のクラスタでOracle Fail Safe Managerを使用するには、まずそのクラスタをOracle Fail Safe Managerクラスタ・リストに追加します。これを実行するには、「Oracle Fail Safe Manager」ページの右側のペインで「アクション」メニューから「クラスタの追加」を選択します。次に、図2-5に示すように、「クラスタ別名」フィールドにクラスタのネットワーク名を入力します。オプションで、「別の資格証明を使用して接続」を選択できます。
デフォルトでは、Oracle Fail Safe Managerは現在のWindowsログイン・セッションの資格証明を使用してクラスタに接続します。別のユーザーの資格証明を使用するには、「別の資格証明を使用して接続」オプションを選択します。Windowsセキュリティの「クラスタ資格証明」ダイアログ・ボックスが開き、クラスタを管理するための新たな資格証明を入力できるようになります。表示されたフィールドに、ユーザー名とパスワードを入力して続行します。資格証明を保存するには、資格証明を記憶するオプションを選択して、「OK」をクリックします。クラスタに接続する場合にOracle Fail Safe Managerでクラスタ用の保存された資格証明があるかどうかを確認してクラスタの接続に使用するために、資格証明がWindows資格証明キャッシュに保存されます。
クライアント・アプリケーションは、クラスタ・リソースとの通信の際にクラスタ別名を使用しません。かわりに、そのリソースを含むグループのネットワーク名を使用します。
あるノード上のグループをオフライン化し、それを別のノード上でオンライン化するプロセスをフェイルオーバーと呼びます。フェイルオーバーの発生後、このグループ内のリソースを実行するように構成されたクラスタ・ノードのいずれかが使用可能であれば、そのリソースにアクセスできます。Windowsフェイルオーバー・クラスタは、クラスタ内のクラスタ・ノードおよびリソースの状態を継続的に監視します。
フェイルオーバーには、計画的なものと計画外のものがあります。
計画外フェイルオーバーは、クラスタ・ソフトウェアがノードまたはリソースの障害を検出した場合に、自動的に行われます。
次の各項で、これら2タイプのフェイルオーバーについて詳細に説明します。
計画外グループ・フェイルオーバーには2つのタイプがあり、それぞれ次のいずれかの原因によって実行されます。
可用性が高まるように構成されたリソースの障害
クラスタ・ノードの障害または使用不可状態
リソース障害による計画外フェイルオーバーは、次のように検出および実行されます。
クラスタ・ソフトウェアが、リソースに障害が発生したことを検出します。
リソース障害を検出するために、クラスタ・ソフトウェアはリソースが稼働状態であるかどうかを(リソースDLL経由で)定期的に問い合せます。詳細は、2.6.4項を参照してください。
クラスタ・ソフトウェアが、リソース再起動ポリシーを実装します。リソース再起動ポリシーでは、クラスタ・ソフトウェアが現在のノード上でリソース再起動を試行するかどうか、そして再起動を試行する場合には一定時間内に何回それを試行するかを指定します。たとえばOracle Fail Safeがリソースの再起動を900秒間に3回試行するなどと指定します。
リソースが再起動された場合、クラスタ・ソフトウェアがソフトウェアの監視を再開し(手順1)、フェイルオーバーは回避されます。
リソースが現在のノード上で再起動されない、またはできない場合、クラスタ・ソフトウェアはリソース・フェイルオーバー・ポリシーを適用します。
リソース・フェイルオーバー・ポリシーでは、リソース障害が起きた場合にグループをフェイルオーバーするかどうかを指定します。グループがフェイルオーバーしないというリソース・フェイルオーバー・ポリシーを指定した場合、リソースは障害発生の状態のままとなり、フェイルオーバーは発生しません。
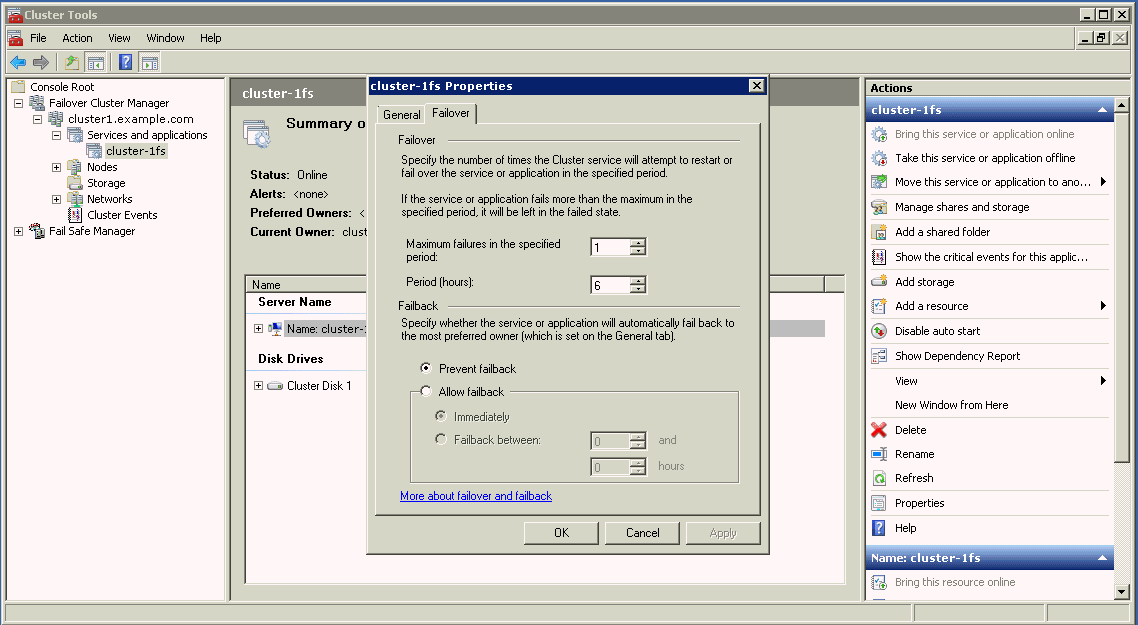
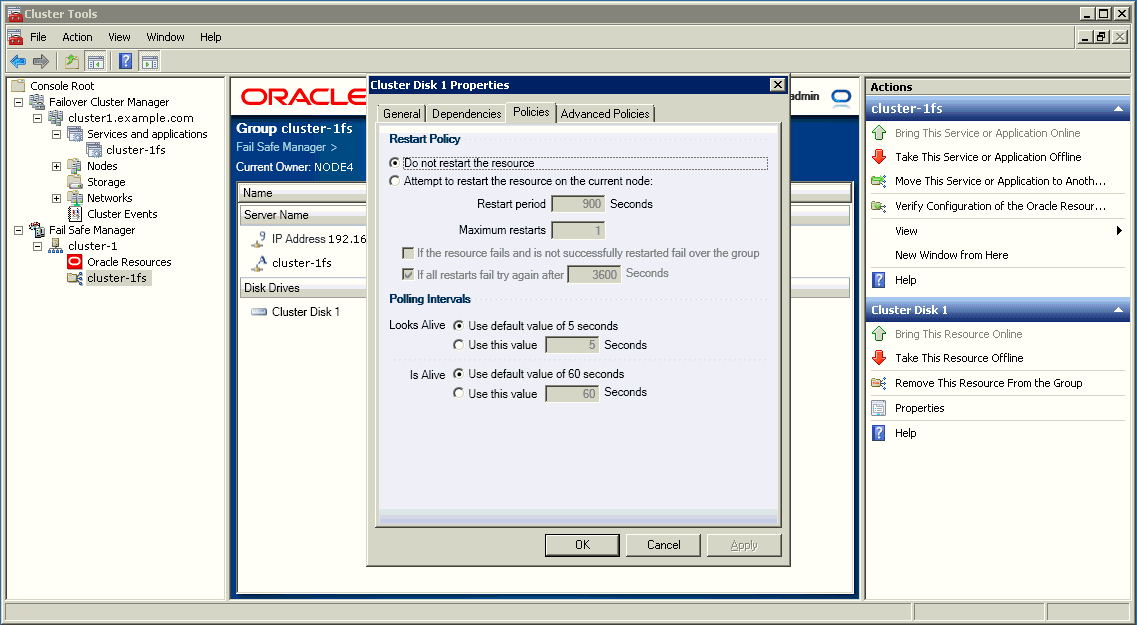
図2-9に示すプロパティ・ページで、リソースの再起動ポリシーおよびフェイルオーバー・ポリシーを表示または変更できます。
リソースが再起動しない(またはできない)場合には、グループがフェイルオーバーするというリソース・フェイルオーバー・ポリシーを指定すると、そのグループは別のノードにフェイルオーバーされます。グループのフェイルオーバー先となるノードは、稼働しているノード、そのリソースの「可能所有者ノード」リスト、およびグループの「優先所有者ノード」リストによって決定されます。リソースの「可能所有者ノード」リストの詳細は2.6.7項を、グループの「優先所有者ノード」リストの詳細は2.6.10項を、それぞれ参照してください。
グループがフェイルオーバーすると、そのグループのフェイルオーバー・ポリシーが適用されます。グループ・フェイルオーバー・ポリシーでは、そのグループがオフライン化されるまでに、クラスタ・ソフトウェアが一定時間内に何回のフェイルオーバーを許容するかを指定します。グループ・フェイルオーバー・ポリシーを使用すると、グループが何度もフェイルオーバーすることを防ぐことができます。グループ・フェイルオーバー・ポリシーの詳細は、2.6.8項を参照してください。
(障害または意図的な再起動のために)所定のノードがオフライン化され、その後再度オンライン化される場合に、リソースとそれが属するグループがそのノードに戻されるかどうかは、フェイルバック・ポリシーによって決定されます。フェイルバックの詳細は、2.7項を参照してください。
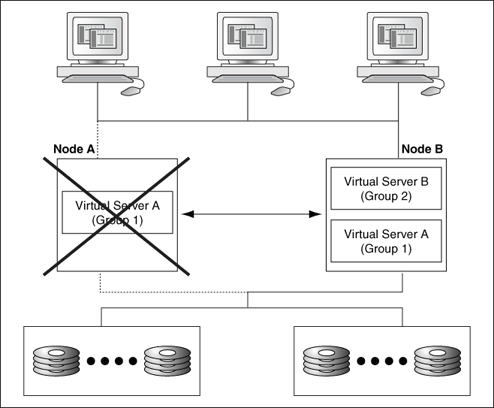
図2-6では、グループ1のリソースの1つに障害が発生したために、仮想サーバーAがノードBにフェイルオーバーしています。
クラスタ・ノードが使用不可になったことによる計画外フェイルオーバーは、次に説明する手順で検出および実行されます。
クラスタ・ソフトウェアによって、クラスタ・ノードが使用不可になったことが検出されます。
ノードの障害または使用不可状態を検出するために、クラスタ・ソフトウェアは(プライベート・インターコネクトを使用して)定期的にクラスタ内のノードに問合せを行います。
障害の発生した、または使用不可になったノード上のグループが、1つ以上の他のノードにフェイルオーバーされます。フェイルオーバー先のノードは、クラスタ内で使用可能なノード、各グループの「優先所有者ノード」リスト、および各グループ内のリソースの「可能所有者ノード」リストによって決定されます。リソースの「可能所有者ノード」リストの詳細は2.6.7項を、グループの「優先所有者ノード」リストの詳細は2.6.10項を、それぞれ参照してください。
グループがフェイルオーバーすると、そのグループのフェイルオーバー・ポリシーが適用されます。グループ・フェイルオーバー・ポリシーでは、そのグループがオフライン化されるまでに、クラスタ・ソフトウェアが一定時間内に何回のフェイルオーバーを許容するかを指定します。グループ・フェイルオーバー・ポリシーの詳細は、2.6.8項を参照してください。
リソースとそれが属するグループが、再度使用可能になったノードに移されるかどうかは、フェイルバック・ポリシーによって決定されます。フェイルバックの詳細は、2.7項を参照してください。
図2-7では、ノードAでの障害発生時にグループ1がフェイルオーバーされることを示しています。クライアント・アプリケーション(障害が発生したサーバーに接続されていたもの)は、フェイルオーバー後、再びサーバーに接続する必要があります。アプリケーションがOracle Databaseに対する更新処理を実行中で、障害発生時に未コミットのデータベース・トランザクションが進行している場合、そのトランザクションはロールバックされます。
グループの計画的フェイルオーバーは、あるノードのクライアント・アプリケーションおよびクラスタ・リソースをオフライン化し、別のノードでオンライン化する意図的なプロセスです。これによって、あるクラスタ・ノードで管理者が定期的なメンテナンス作業(ハードウェアおよびソフトウェアのアップグレードなど)を実行している間も、ユーザーは別のノードで作業を継続できます。メンテナンス作業以外にも、計画的フェイルオーバーによってクラスタ内のノード間でロード・バランスを行うことができます。つまり計画的フェイルオーバーは、ノード間でのグループの移動に使用します。実際、計画的フェイルオーバーを実装する際には、Oracle Fail Safe Manager内でグループ移動操作を実行します(説明はOracle Fail Safe Managerのオンライン・ヘルプを参照してください)。
計画的フェイルオーバーの際、Oracle Fail SafeはMicrosoft Windowsフェイルオーバー・クラスタとともに、グループをあるノードから別のノードに効率よく移します。クライアント接続は失われるので、透過的アプリケーション・フェイルオーバーを構成していない場合、クライアントはアプリケーションの仮想サーバー・アドレスに手動で再接続する必要があります(透過的アプリケーション・フェイルオーバーの詳細は、7.9項を参照してください)。また、元のノードがオフライン化された場合でも、Oracle Fail Safeによりクライアントは別のクラスタ・ノードで作業を続行できるため、ゆっくりアップグレードを実行します。(グループにOracle Databaseが含まれている場合、どの計画的フェイルオーバーよりも先にデータベースのチェックポイント取得が実行され、新しいノードでの高速データベース・リカバリが確実に行われます。)
リソースおよびグループの各フェイルオーバー・ポリシーの値は、Oracle Fail Safe ManagerおよびMicrosoft Windowsフェイルオーバー・クラスタ・マネージャを使用してグループを作成するか、グループにOracleリソースを追加すると、デフォルトに戻されます。ただし、Oracle Fail Safe ManagerのOracleリソース「プロパティ」ページおよびMicrosoft Windowsフェイルオーバー・クラスタ・マネージャのグループ・フェイルオーバーの「Properties」ページでこれらのポリシーの値をリセットできます。グループ・フェイルオーバーの「Properties」ページを使用して「Allow failback」オプションを選択し、グループ作成時またはそれ以降に、グループ・フェイルバック・ポリシーの値を設定できます。
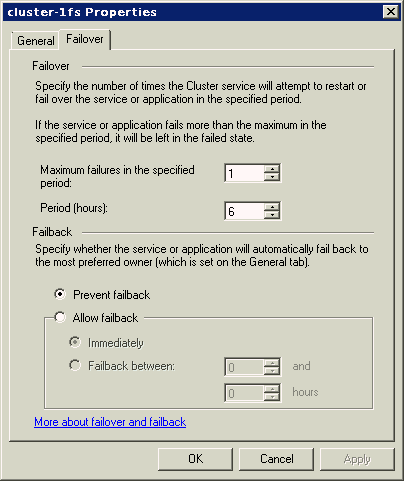
図2-8に、グループ・フェイルオーバー・ポリシーを設定するページを示します。このページにアクセスするには、Microsoft Windowsフェイルオーバー・クラスタ・マネージャのツリー・ビューで該当するグループを選択し、画面右側のペインの「Actions」メニューから「Properties」アクションを選択します。次に、「Properties」ページの「Failover」タブを選択します。
図2-9に、Oracleリソース・ポリシーを設定するページを示します。このページにアクセスするには、画面右側のペインの「プロパティ」アクション・メニューを選択するか、メニュー・バーの「操作」アイテムから「プロパティ」を選択します。次に、Oracleリソース「プロパティ」ページの「ポリシー」タブを選択します。
可用性が高まるように構成されたリソースは、すべてクラスタ・ソフトウェアによってその状態が監視されます。リソース障害は次の3つの値に基づいて検出されます。
保留タイムアウト値
保留タイムアウト値は、障害が発生したと判断する前に保留状態のリソースがオンライン化(またはオフライン化)されるまで、クラスタ・ソフトウェアが待機する時間の長さを指定します。デフォルト値は180秒です。
Is Aliveポーリング間隔
Is Aliveポーリング間隔は、クライアント・ソフトウェアがリソースの状態をチェックする頻度を指定します。リソース・タイプのデフォルト値を使用するか、数値(秒単位)を指定します。このチェックは、Looks Aliveポーリング間隔で行われるチェックよりも完全ですが、消費するシステム・リソースも多くなります。
Looks Aliveポーリング間隔
Looks Aliveポーリング間隔は、クライアント・ソフトウェアがリソースの登録済の状態をチェックし、リソースがアクティブかどうかを判断する頻度を指定します。リソース・タイプのデフォルト値を使用するか、数値(秒単位)を指定します。このチェックは、Is Aliveポーリング間隔で行われるチェックよりも不完全ですが、消費するシステム・リソースは少なくなります。
リソースで障害が発生したことが確定すると、クラスタ・ソフトウェアによってそのリソースの再起動ポリシーが適用されます。リソース再起動ポリシーには、図2-9で示すように2つのオプションがあります。
クラスタ・ソフトウェアが、現在のノードでリソースの再起動を試みない。そのかわりに、リソース・フェイルオーバー・ポリシーをただちに適用します。
クラスタ・ソフトウェアが、現在のノードでリソースの再起動を、一定時間内に指定した回数試みる。リソースが再起動できない場合、クラスタ・ソフトウェアはリソース・フェイルオーバー・ポリシーを適用します。
リソース・フェイルオーバー・ポリシーは、現在のノードでリソースが再起動されない(または再起動できない)場合に、そのリソースを含むグループがフェイルオーバーするかどうかを決定します。障害リソースを含むグループがフェイルオーバーしないというポリシーが指定されている場合、リソースは現在のノードで障害発生状態のままとなります。(このグループが、最終的にはフェイルオーバーする可能性はあります。このグループ内の別のリソースが、障害リソースを含むグループはフェイルオーバーするというポリシーを指定されていれば、そこでフェイルオーバーするためです。)障害リソースを含むグループがフェイルオーバーするというポリシーが指定されている場合、障害リソースを含むグループは、「優先所有者ノード」リストによる指定に応じて別のクラスタ・ノードにフェイルオーバーします。「優先所有者ノード」リストについては、2.6.10項および2.7.1項を参照してください。
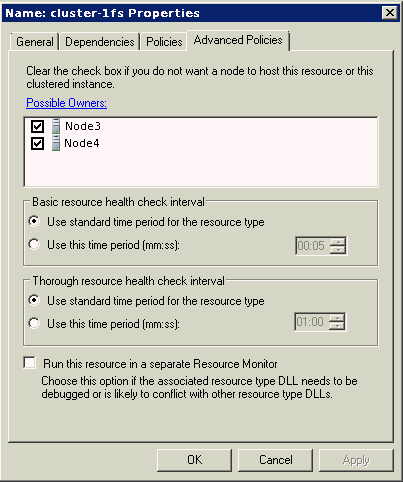
「可能所有者ノード」リストは、指定されたリソースの実行が許可されているすべてのノードで構成されています。
Oracle Fail Safe Managerは、リソースの「拡張ポリシー」の「プロパティ」タブの下に可能所有者ノードを表示します。ユーザーがノードを変更する場合、Microsoft Windowsフェイルオーバー・クラスタ・マネージャを使用する必要があります。可能所有者ノードを変更した後、「検証」グループ・アクションを実行する必要があります。
|
注意: 「検証」グループ・アクションを選択すると、指定されたグループ内のリソースが、そのグループの可能所有者となっている各ノードで実行するよう構成されているかどうかが、Oracle Fail Safeによってチェックされます。グループ内のリソースが実行するように構成されていない可能所有者ノードが検出されると、Oracle Fail Safeがそれを構成します。このため、新規のノードが可能所有者としてリストされた各グループについては、「検証」グループ・コマンドを選択することを強くお薦めします。6.1.2項に、「検証」グループ・アクションを示します。 |
リソースが現在のノード上で再起動できない場合には、そのリソースを含むグループがフェイルオーバーするというリソース・フェイルオーバー・ポリシーを指定すると、そのグループはフェイルオーバーし、グループ・フェイルオーバー・ポリシーが適用されます。同様に、ノードが使用不可になった場合にも、そのノード上のグループがフェイルオーバーし、グループ・フェイルオーバー・ポリシーが適用されます。
グループ・フェイルオーバー・ポリシーでは、そのグループがオフライン化されるまでに、クラスタ・ソフトウェアが一定時間内に何回のフェイルオーバーを許容するかを指定します。グループ・フェイルオーバー・ポリシーを使用すると、グループが何度もフェイルオーバーするのを防ぐことができます。
グループ・フェイルオーバー・ポリシーは、フェイルオーバーしきい値とフェイルオーバー期間とで構成されます。
フェイルオーバーしきい値では、クラスタ・ソフトウェアがグループ・フェイルオーバーの試行を停止するまでに(フェイルオーバー期間内で)発生するフェイルオーバーの最大回数を指定します。
フェイルオーバー期間は、クラスタ・ソフトウェアがフェイルオーバー発生回数をカウントする時間です。フェイルオーバーの頻度が、フェイルオーバー期間に指定した時間内に、フェイルオーバーしきい値に指定した回数を超えると、クラスタ・ソフトウェアはグループ・フェイルオーバーの試行を停止します。
たとえば、フェイルオーバーしきい値が3でフェイルオーバー期間が5の場合、クライアント・ソフトウェアがそのグループのフェイルオーバーを中止するまでに、5時間以内で3回のフェイルオーバーが許容されます。
最初のフェイルオーバーが発生すると、フェイルオーバー期間を測定するタイマーは0にリセットされ、フェイルオーバー回数を測定するカウンタは1に設定されます。フェイルオーバー期間を超過した時点では、タイマーは0にリセットされません。そのかわりに、フェイルオーバー期間を超過してから最初のフェイルオーバーが発生した時点で、タイマーは0にリセットされます。
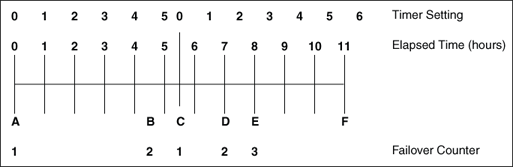
たとえば、前述の例と同様にフェイルオーバー期間が5時間で、フェイルオーバーしきい値が3であるとします。図2-13に示すように、Aの時点で最初のグループ・フェイルオーバーが発生すると、タイマーが0に設定されます。2度目のグループ・フェイルオーバーが4.5時間後のBの時点で発生し、3度目のグループ・フェイルオーバーはCの時点で発生すると仮定します。3度目のグループ・フェイルオーバー発生時点(Cの時点)ではフェイルオーバー期間を超過しているため、グループ・フェイルオーバーは続行可能で、タイマーは0にリセットされ、フェイルオーバーのカウンタは1にリセットされます。
Dの時点(Aの時点から7時間が経過し、Bの時点から2.5時間が経過した時点)でフェイルオーバーがもう1回発生すると仮定します。フェイルオーバーは停止するでしょうか。B、CおよびDの時点でのフェイルオーバーは、5時間以内に発生しています。しかし、フェイルオーバー期間を測定するタイマーはCの時点で0にリセットされており、フェイルオーバーしきい値は超えていないため、このグループのフェイルオーバーはクラスタ・ソフトウェアによって許可されます。
次のフェイルオーバーがEの時点で発生するとします。通常はフェイルオーバーになるような問題がFの時点で発生しても、クラスタ・ソフトウェアはこのグループをフェイルオーバーしません。これは、Cの時点でタイマーが0にリセットされて以降5時間以内に、3回のフェイルオーバーが発生したためです。このグループは、クラスタ・ソフトウェアによって障害発生状態のまま現在のノード上に残されます。
リソース再起動ポリシーと、リソースを含むグループのフェイルオーバー・ポリシーは、どちらもグループのフェイルオーバー機能に影響します。
たとえば、CustomersというグループにNortheastデータベースがあり、次のように指定するとします。
Northeastデータベースの「ポリシー」プロパティ・ページで次のように指定します。
現在のノードで、600秒(10分)以内に3回データベースの再起動を試行
リソースに障害が発生し再起動が不可能な場合には、グループをフェイルオーバー
Customersグループの「フェイルオーバー」プロパティ・ページで次のように指定します。
リソースを含むグループのフェイルオーバーしきい値は20
リソースを含むグループのフェイルオーバー期間は1時間
データベース障害が発生したと仮定します。Oracle Fail Safeでは、現在のノードでデータベース・インスタンスの再起動が試行されます。データベース・インスタンス再起動の試行が、10分間で3回失敗したとします。この場合、Customersグループは別のノードにフェイルオーバーします。
そのノードで、Oracle Fail Safeはデータベース・インスタンスの再起動を試行しますが、10分間に3回失敗したため、Customersグループは再度フェイルオーバーします。Oracle Fail Safeによるデータベース・インスタンス再起動の試行とCustomersグループのフェイルオーバーは、データベース・インスタンスが再起動するか、あるいはグループのフェイルオーバーが1時間以内に20回を超えるまで続行されます。データベース・インスタンスが再起動できず、グループのフェイルオーバーが1時間以内に20回より少ない場合、Customersグループは何度もフェイルオーバーを続けます。このような場合には、フェイルオーバーが何度も続かないようにフェイルオーバーしきい値を低くすることを検討してください。
グループを作成する際に、グループ・フェイルオーバーおよびフェイルバック両方の「優先所有者ノード」リストを作成できます。(クラスタ内のノードが2つのみの場合、このリストをフェイルバックのみに指定します。)リスト中の各ノードがグループを所有する優先順位を示すために、順序付けられたノードのリストを作成します。
たとえば4つのノードからなるクラスタで、あるデータベースを含むグループについて次のような「優先所有者ノード」リストを指定するとします。
ノード1
ノード4
ノード3
このように指定すると、4つのノードすべてが稼働している場合にはグループが優先的にノード1で実行されます。ノード1が使用不可になると、グループは2番目に指定されているノード4で実行されます。ノード1もノード4も使用不可の場合、次に指定されているノード3でグループが実行されます。ノード2が優先所有者ノード・リストから省略されます。ただし、クラスタ・ソフトウェアで使用可能なノードが他にない(ノード1、ノード4およびノード3のすべてで障害が発生したため)場合、グループはノード2にフェイルオーバーします。(ノード2が、グループ内のすべてのリソースの可能所有者とはかぎらない場合でも同様です。このような場合、グループはフェイルオーバーしますが、障害発生状態のままになります。)
フェイルオーバーが発生すると、クラスタ・ソフトウェアは「優先所有者ノード」リストを使用して、グループのフェイルオーバー先となるノードを決定します。グループのフェイルオーバー先となるのは、リスト内のノードのうち、稼働しており、かつそのグループの可能所有者ノードである最上位のノードです。クラスタ・ソフトウェアがグループのフェイルオーバー先ノードを決定する方法の詳細は、2.6.11項で説明します。
グループの「優先所有者ノード」リストによるフェイルバックへの影響の詳細は、2.7.1項を参照してください。
グループのフェイルオーバー先となるノードは、次の3つのリストに基づいて決定されます。
使用可能なクラスタ・ノードのリスト
使用可能なクラスタ・ノードのリストは、グループ障害の発生時に稼働している全ノードで構成されます。たとえば、4つのノードからなるクラスタがあります。グループのフェイルオーバー時に1つのノードが停止している場合、使用可能なクラスタ・ノードのリスト内は3つになります。
グループ内の各リソースの「可能所有者ノード」リスト(2.6.7項を参照。)
リソースを含むグループの「優先所有者ノード」リスト(2.6.10項を参照。)
クラスタ・ソフトウェアでは、使用可能なクラスタ・ノードと、グループ内の全リソースに共通の可能所有者セットとの共通点を検出して、グループのフェイルオーバー先となる可能性があるノードを決定します。たとえば、4つのノードからなるクラスタで、ノード3にTest_Groupというグループがあるとします。Test_Group内のリソースには、表2-1に示すような可能所有者を指定してあります。
表2-1 Test_Groupグループ内のリソースの可能所有者の例
| リソース1の可能所有者 | リソース2の可能所有者 | リソース3の可能所有者 |
|---|---|---|
|
ノード1 - はい |
ノード1 - はい |
ノード1 - はい |
|
ノード2 - はい |
ノード2 - いいえ |
ノード2 - はい |
|
ノード3 - はい |
ノード3 - はい |
ノード3 - はい |
|
ノード4 - はい |
ノード4 - はい |
ノード4 - はい |
表2-1を見ると、3つのリソースすべてに共通な可能所有者は次のノードであることがわかります。
ノード1
ノード3
ノード4
ノード3(現在Test_Groupが常駐している)で障害が発生したと仮定します。使用可能なノードは次のようになります。
ノード1
ノード4
Test_Groupのフェイルオーバー先となるノードを決定するために、クラスタ・ソフトウェアはグループ内の全リソースに共通する可能所有者ノードのリストと、使用可能なノードのリストとの共通点を検出します。この例では、これら2つのリストで共通するのはノード1およびノード4です。
Test_Groupのフェイルオーバー先となるノードの決定には、そのグループの「優先所有者ノード」リストがクラスタ・ソフトウェアで使用されます。Test_Groupの「優先所有者ノード」リストを次のように設定してあるとします。
ノード3
ノード4
ノード1
ノード3は障害が発生しているため、クラスタ・ソフトウェアはTest_Groupをノード4にフェイルオーバーします。ノード3およびノード4がいずれも使用不可の場合、Test_Groupはノード1にフェイルオーバーされます。もしノード1、3および4がすべて使用不可であれば、Test_Groupはノード2にフェイルオーバーされます。ただし、ノード2はTest_Group内のすべてのリソースの可能所有者ではないので、Test_Groupはノード2で障害発生状態のままになります。
フェイルバックは、優先所有者ノードが動作可能状態に復帰した後で、クラスタ・リソースのグループがフェイルオーバー・ノードから優先所有者ノードに自動的に戻るプロセスです。優先所有者ノードは、可能な場合(そのノードが使用可能である場合)にグループを常駐させるノードです。
グループをフェイルオーバー・ノードから優先所有者ノードへフェイルバックする必要があるか、およびいつフェイルバックするかを決定するフェイルバック・ポリシーを設定できます。たとえば、あるグループがただちにフェイルバックする、または選択した特定の時間内にフェイルバックするように設定が可能です。あるいは、グループがフェイルバックせずに現在常駐しているノードで稼働し続けるようなフェイルバック・ポリシーも設定できます。図2-14に、グループのフェイルバック・ポリシーを設定するプロパティ・ページを示します。
クラスタ上にグループを作成する際に、グループ・フェイルオーバーおよびフェイルバックの「優先所有者ノード」リストを作成します。クラスタ内のノードが2つの場合、このリストをフェイルバックのみに指定します。順序付けられたノードのリストを作成して、グループを優先的に実行するノードを指定します。以前に使用不可だったノードが再度オンライン化されると、クラスタ・ソフトウェアはクラスタ上の各グループの「優先所有者ノード」リストを読み込み、オンライン化されたこのノードがいずれかのグループの優先所有者ノードであるかどうかを判断します。「優先所有者ノード」リスト中で、再オンライン化されたノードの順位が、現在グループが常駐しているノードよりも上位である場合、グループは再オンライン化されたこのノードにフェイルバックされます。
たとえば4つのノードからなるクラスタで、My_Groupというグループについて次のような「優先所有者ノード」リストを指定するとします。
ノード1
ノード4
ノード3
ノード1がオフライン化されたため、My_Groupはノード4にフェイルオーバーし、現在そこで稼働中であると仮定します。ここでノード1が再オンライン化されます。クラスタ・ソフトウェアがMy_Group(およびクラスタ上の他の全グループ)の「優先所有者ノード」リストを読み込み、My_Groupの優先所有者ノードがノード1であることが検出されます。フェイルバックが有効であれば、My_Groupはノード1にフェイルバックされます。
My_Groupが現在ノード3で稼働中(ノード1もノード4も使用不可なため)であり、ノード4が再オンライン化された場合、フェイルバックが有効であればMy_Groupはノード4にフェイルバックします。この後でノード1が使用可能になった場合、My_Groupは再び、今度はノード1にフェイルバックします。「優先所有者ノード」リストを指定する際には、フェイルバックが不必要に何度も発生しないように注意してください。ほとんどのアプリケーションで、「優先所有者ノード」リストのノードは2つあれば十分です。
グループが、あるノードに手動で移動された場合、予期しない結果になります。すべてのノードが使用可能で、My_Groupは現在ノード3で稼働しているとします(これは、グループの移動操作でMy_Groupをノード3に移動したためです)。ノード4が再起動されると、ノード1(My_Groupの「優先所有者ノード」リストで最上位のノード)が稼働中であっても、My_Groupはノード4にフェイルバックします。
ノードが再オンライン化されると、オンライン化されたそのノードが、「優先所有者ノード」リストの中で、現在各グループが常駐しているノードよりも上位であるかどうかがクラスタ・ソフトウェアによってチェックされます。上位である場合、そのようなグループはすべて、再オンライン化されたノードに移動されます。
グループの「優先所有者ノード」リストによるフェイルオーバーへの影響の詳細は、2.6.10項を参照してください。
ノードの障害は、次のユーザーおよびアプリケーションにのみ影響します。
障害発生ノードがホストになっているアプリケーションに、直接接続しているもの
ノードの障害発生時にトランザクション処理中であったもの
多くの場合、障害発生ノードに接続していたユーザーおよびアプリケーションは接続を失うことになり、処理を継続するためにはフェイルオーバー・ノードに(ノードに依存しないネットワーク名を通じて)再接続する必要があります。データベースの場合、障害発生時に処理中だった未コミット・トランザクションは、ロールバックされます。透過的アプリケーション・フェイルオーバーが構成されているクライアント・アプリケーションではサービスが短時間中断され、クライアント・アプリケーションからはノードが即時に再起動されたように見えます。サービスはフェイルオーバー・ノードで自動的に再起動されます。オペレータの介入は必要ありません。
透過的アプリケーション・フェイルオーバーの詳細は、7.9項を参照してください。