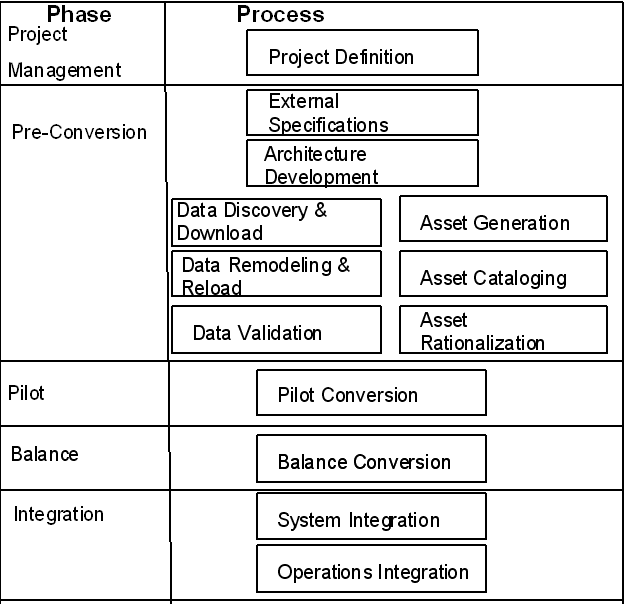
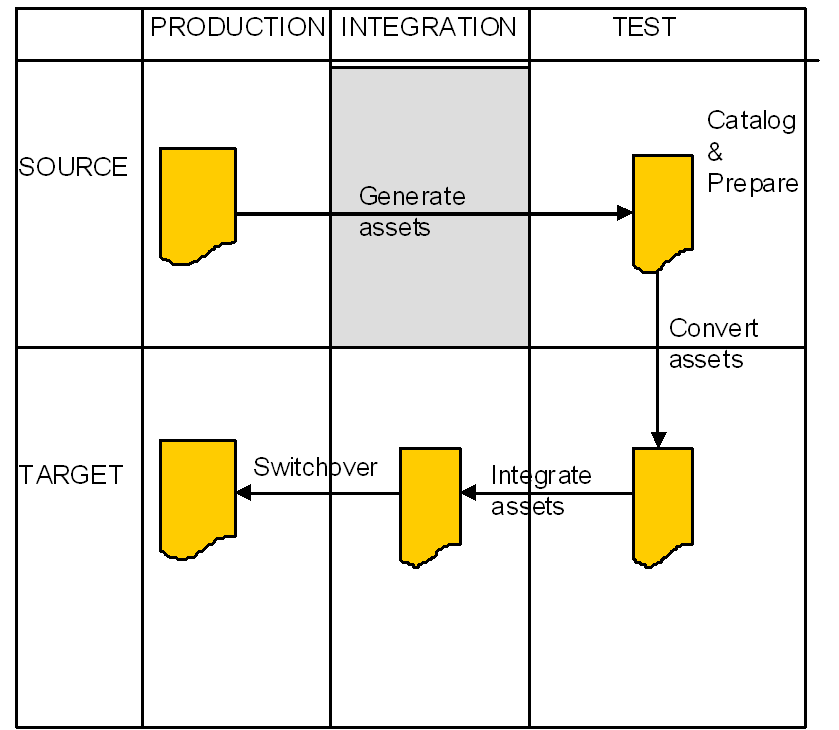
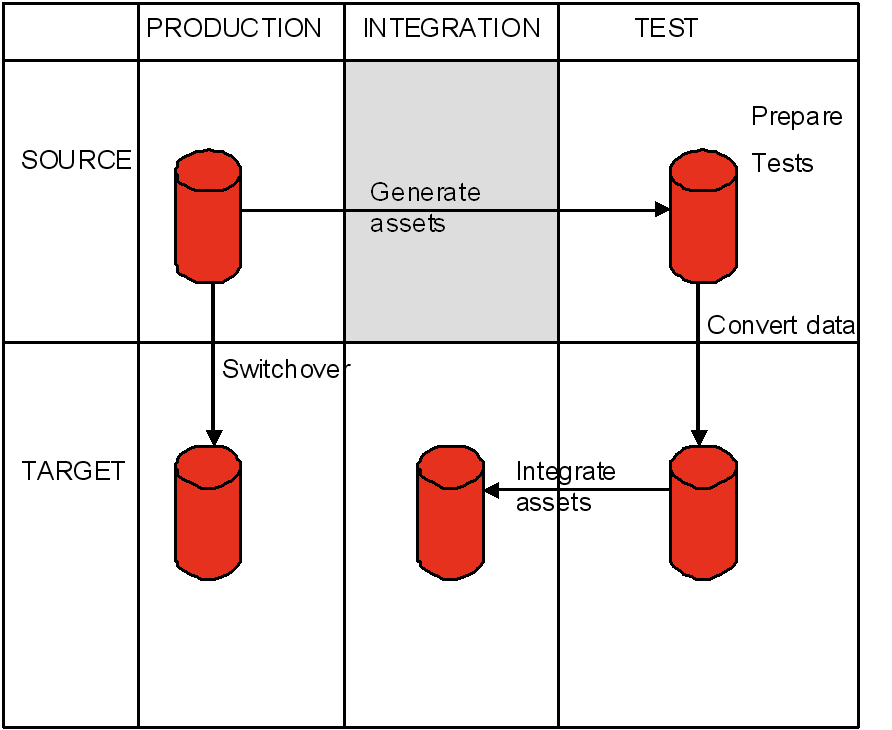
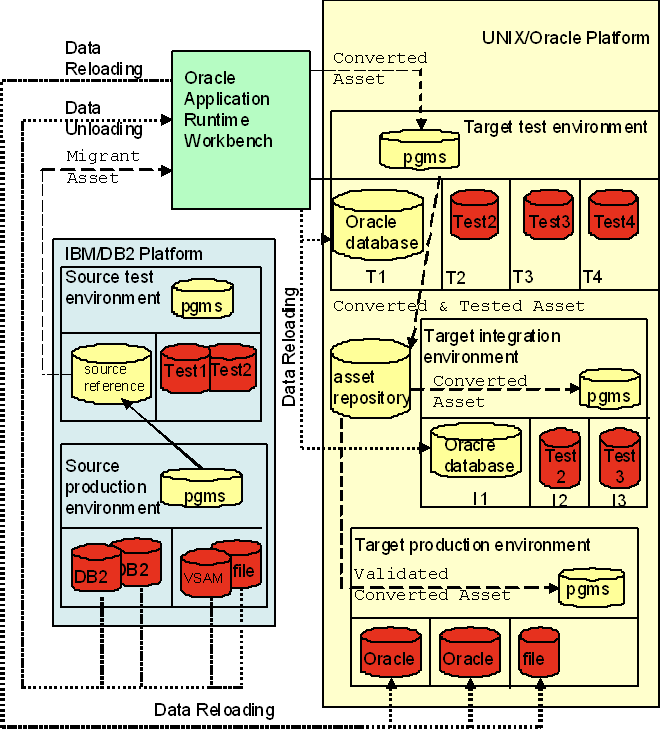
リホスティング・プロジェクトを実行するには5つの異なる環境が必要です。次に示す2つのソース環境(移行前)と3つのターゲット環境(移行後)です。
|
•
|
-cleanオプションを使用してEclipseを実行する。
|
プラグインをインストールするには、com.oracle.tuxedo.wbplugin_x.x.x.x.jarファイル(Tuxedo ART Workbenchインストール・ディレクトリの下の
utils/eclipse_pluginサブディレクトリにあります)を
$ECLIPSE_HOME/pluginsディレクトリにコピーしてから、Eclipseを再起動する必要があります。
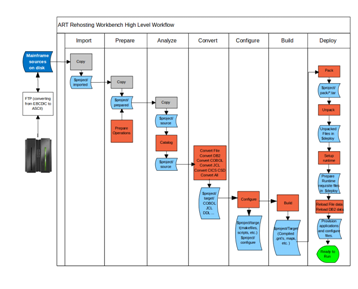
図1-7は、Tuxedo ART Workbenchのハイレベル・ワークフローの図です。
|
2.
|
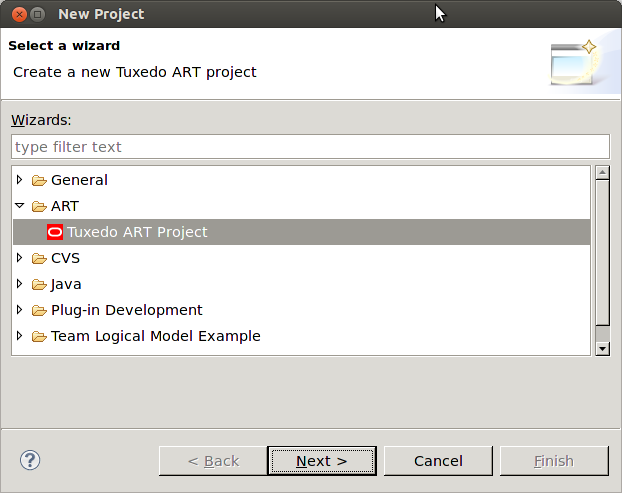
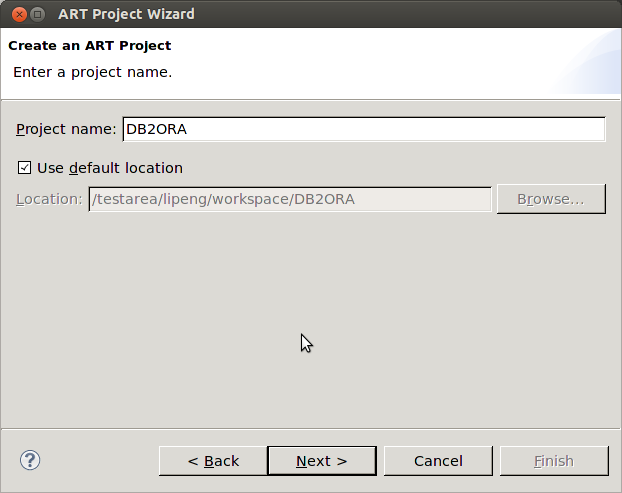
図1-9に示すように、プロジェクト名を指定します。
|
|
3.
|
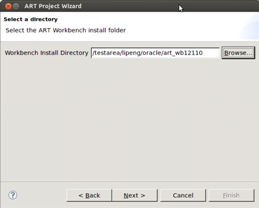
図1-10に示すように、Tuxedo ART Workbenchインストール・ディレクトリを指定します。
|
|
4.
|
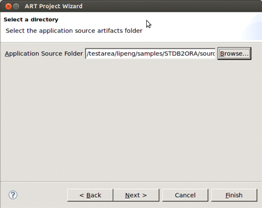
図1-11に示すように、ソース・ファイルを含むルート・ディレクトリを指定します。
|
|
5.
|
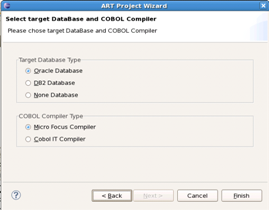
図1-12に示すように、ターゲット・データベースとCOBOLコンパイラを指定します。
|
|
ヒント:
|
uconv -lコマンドをシェルで入力すると、エンコーディング名がリストされます。
|
*.cbl - CICS、BatchおよびSubを含む、COBOLソース・プログラム
*.sql、
*.ddl、
*.db2 - SQLスクリプト
表1-12は、提案された変数の使用方法を説明しています。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tuxedo ART Workbenchにより使用される変数 |
|
|
|
|
|
|
|
|
|
4.
|
ファイル.projectを $PROJECTの下に作成し、 環境および作業変数の設定にリストした変数で初期化します。このファイルの変数はプロジェクトで作業するたびにエクスポートされます。
|
ディレクトリ$LOGS/catalogからコマンドを実行します。
makeはターゲット(ファイルまたはアクション)の構成を自動化および最適化することを目的としたUNIXユーティリティです。
makeを使用して移行プロセスを構成する様々な操作を実行することをお薦めする理由は次のとおりです。
次の2つの項でmake構成および
makeによるカタロガ機能の使用方法について説明します。
makefileの内容は実行するタスクの要約です。
$SOURCEディレクトリから次のコマンドを実行します。
たとえば、独自のスクリプト(report.sh)を作成して、基本のカタログ化レポートを基にしてカスタマイズしたレポートを生成する場合、そのスクリプトは
$TOOLSディレクトリに置きます。
|
2.
|
REAL_CMDをCOMMENTに変更してmakefile.debugを変更します
|
表1-14は、z/OSにより処理されるファイル編成をリストし、ターゲット・プラットフォームで提案される編成を示します。
|
注意:
|
populate.shユーティリティ( REFINEDIR/scripts/file/populate.shにある)を使用して、これら2つの構成ファイルを自動生成できます。詳細は、 REFINEDIR/scripts/file/README.txtを参照してください。
|
db-param.cfgファイルで、変更が必要となる可能性のあるパラメータは
target_osパラメータのみです
。
%% Lines beginning with "%%
" are ignored
|
|
|
|
|
|
|
|
|
|
|
|
|
|
include "#VAR:RECS-SOURCE#/BCOAC01E.cpy"
|
生成中に、文字列#VAR:RECS-SOURCE#はコピー・ファイルが置かれたディレクトリの名前 $PARAM/file/recs-sourceで置き換えられます
コピー・ファイルBCOAC01E.cpyの名前はファイルの作成時にユーザーが自由に選択します。
|
|
|
|
REC-ENTREEはコピー・ファイルのレベル01フィールド名に相当します。
|
|
|
|
|
|
|
|
|
%% Lines beginning with "%%
" are ignored
COBOL記述ファイルを準備したら、
mapper-<configuration name>.reファイルに記述したコピー・ファイルを
$PARAM/file/recs-sourceディレクトリに置く必要があります。
file.sh [ [-g] [-m] [-i <installation directory>] <
configuration name> | -s <
installation directory> (<
configuration name>,...) ]
file.shでは、Tuxedo ART Workbenchを使用して、z/OSファイルの移行に使用するコンポーネントを生成します。
attributes句がLOGICAL_MODULE_ONLYに設定されている場合を除き、ファイルからファイルへの移行には適用できません。
-i $HOME/trfオプションで生成されるアンロード・コンポーネントおよびロード・コンポーネントは、次の場所に配置されます。
$PARAMの
version.mk構成ファイルを使用して、makeユーティリティで必要な変数およびパラメータを設定します。
version.mkには、各種コンポーネントがインストールされる場所とその拡張機能、および使用される様々なツールのバージョンを指定します。このファイルにはログ・ファイルの構成方法も記述されます。
また、FILE_SCHEMAS変数はファイルの移行に固有で、処理する様々な構成を示します。
makefileおよび
version.mkファイルはTuxedo ART Workbench Simple Applicationとともに提供されます。
make FileConvertコマンドを使用して、Tuxedo ART Workbench
File-To-Fileコンバータを起動できます。これによりz/OSファイルのUNIX/Linuxターゲット・プラットフォームへの移行に必要なコンポーネントを生成できます。
makefileはFILE_SCHEMAS変数に含まれるすべての構成に対し、
-g、
-mおよび
-iオプションを指定して
file.shツールを起動できます。
VSAMファイルをソース・プラットフォームからOracle UNIXターゲット・プラットフォームに移行するとき、VSAMが関係する場合は、ファイルを保持するかデータをOracle表に移行するかをまず確認します。
z/OSで処理されるVSAM RRDS、
ESDSおよび
KSDSのファイル編成は、Tuxedo ART Workbenchを使用してOracleデータベースに移行できます。
|
注意:
|
populate.shユーティリティ( REFINEDIR/scripts/file/populate.shにある)を使用して、これら2つの構成ファイルを自動生成できます。詳細は、 REFINEDIR/scripts/file/README.txtを参照してください。
|
表1-18は、COBOL記述の形式の例を示しています。
前述の例では、2つのフィールド(FV15-ZNPCP3および
FV15-ZNB2T)の構造が異なります。最初のフィールドはEBCDIC英数字、次のフィールドはEBCDICデータおよびCOMP2、COMP3データから構成されます。
|
•
|
各表の名前は、table name句を使用して mapper-<configuration name>.reファイルに規定されます。
|
|
•
|
相対VSAMファイル( VSAM RRDS)の場合:
|
|
•
|
索引付きVSAMファイル( VSAM KSDS)の場合:
|
データをVSAMファイルからOracle表に移行するときに、次のルールがCOBOL Picture句に適用されます。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
注意:
|
パラメータfile:char_limit_until_varcharが db-param.cfgファイルに設定されている場合、前述のルールよりも優先されます。
|
|
次の例では、ODCSFOBに記述された索引付き
VSAMファイルは主キーとして
VS-CUSTIDENTフィールドを使用します。
VS_CUSTIDENT NUMBER(6) NOT NULL,
VS_SEQ_NUM NUMBER(8) NOT NULL,
VS_CUSTLNAME VARCHAR2(30),
VS_CUSTADDRS VARCHAR2(30),
VS_CUSTEMAIL VARCHAR2(40),
|
注意:
|
コピーブックODCSFOBにはフィールドの再定義 VS-CUSTBDATE-G PIC 9(008)が含まれ、これは技術フィールドのため、識別ルールは実装されません。この場合、再定義されたフィールドのみが生成された表 VS_CUSTBDATE NUMBER(8)に作成されます。
|
File-To-Oracle変換の場合、Datamap-<configuration name>.reおよび
mapper-<
configuration name>
.reファイルを自分で作成する必要があります。
db-param.cfgファイルの場合、ターゲットおよびファイル・パラメータのみが調整される必要があります。
PJ01AAA.SS.VSAM.CUSTOMERファイルは
VSAM KSDSファイルのため、編成は索引付きです。パラメータ
keys offset 1 bytes length 6 bytes primaryはキーを記述しています。この例では、キーは6バイトの長さでポジション1から開始します。
%% Lines beginning with "%%
" are ignored
|
|
|
|
|
|
|
|
|
|
|
|
|
|
include "COPY/ODCSF0B.cpy"
|
コピー・ファイルBCOAC01E.cpyの名前およびパスはファイルの作成時にユーザーが自由に選択します。
|
|
|
|
|
|
|
|
VS-ODCSF0-RECORDはコピー・ファイルのレベル01フィールド名に相当します。
|
|
|
|
|
|
|
|
|
|
注意:
|
使用される様々なパラメータの説明は、『Oracle Tuxedo Application Rehosting Workbench リファレンス・ガイド』のFile-To-Fileコンバータに関する項を参照してください。
|
%% Lines beginning with "%%
" are ignored
COBOL記述ファイルを準備したら、
mapper-<configuration name>.reファイルに記述したコピー・ファイルを
$PARAM/file/recs-sourceディレクトリに置く必要があります。
file.sh [ [-g] [-m] [-i <installation directory>] <
configuration name> | -s <
installation directory> (<
configuration name>,...) ]
file.shでは、Tuxedo ART Workbenchにより、VSAMファイルの移行に使用するコンポーネントを生成します。
$PARAMの
version.mk構成ファイルを使用して、makeユーティリティで必要な変数およびパラメータを設定します。
version.mkには、各種コンポーネントがインストールされる場所とその拡張機能、および使用される様々なツールのバージョンを指定します。このファイルにはログ・ファイルの構成方法も記述されます。
また、FILE_SCHEMAS変数はファイルの移行に固有で、処理する様々な構成を示します。
makefileおよび
version.mkファイルはTuxedo ART Workbench Simple Applicationとともに提供されます。
make FileConvertコマンドを使用して、Tuxedo ART Workbench
File-To-Fileコンバータを起動できます。これによりz/OSファイルのUNIX/Linuxターゲット・プラットフォームへの移行に必要なコンポーネントを生成できます。
makefileはFILE_SCHEMAS変数に含まれるすべての構成に対し、
-g、
-mおよび
-iオプションを指定して
file.shツールを起動できます。
-i $HOME/trfオプションで生成されるアンロード・コンポーネントおよびロード・コンポーネントは、次の場所に配置されます。
z/OSで処理されるVSAM RRDS、
ESDSおよび
KSDSのファイル編成は、Tuxedo ART Workbenchを使用してOracleデータベースに移行できます。
この項では、VSAMファイルのDB2/Luw(udb)表への移行の開始前に実行する手順について説明します。
|
注意:
|
populate.shユーティリティ( REFINEDIR/scripts/file/populate.shにある)を使用して、これら2つの構成ファイルを自動生成できます。詳細は、 REFINEDIR/scripts/file/README.txtを参照してください。
|
|
•
|
各表の名前は、table name句を使用して mapper-<configuration name>.reファイルに規定されます。
|
|
•
|
相対VSAMファイル( VSAM RRDS)の場合:
|
|
•
|
索引付きVSAMファイル( VSAM KSDS)の場合:
|
データをVSAMファイルからOracle表に移行するときに、次のルールがCOBOL Picture句に適用されます
|
|
|
|
|
|
|
|
|
|
|
PIC S9(4) BINARYは NUMERIC(5)として移行されます
|
|
|
|
|
|
|
|
|
|
注意:
|
パラメータfile:char_limit_until_varcharが db-param.cfgファイルに設定されている場合、前述のルールよりも優先されます。
|
|
次の例では、ODCSFOBに記述された索引付きVSAMファイルは主キーとして
VS-CUSTIDENTフィールドを使用します。
|
注意:
|
コピーブックODCSFOBにはフィールドの再定義 VS-CUSTBDATE-G PIC 9(008)が含まれ、これは技術フィールドのため、識別ルールは実装されません。この場合、再定義されたフィールドのみが生成された表 VS_CUSTBDATE NUMBER(8)に作成されます。
|
db-param.cfgファイルの場合、ターゲットおよびファイル・パラメータのみが調整される必要があります。
DB2/Luw(udb) VARCHARデータ型に変換される前のCOBOL英数字(PIC X)フィールドの最大フィールド長を示します。
移行するVSAMファイルをリストする必要があります。
|
|
|
|
|
|
|
|
|
|
|
カタロガのシステム記述ファイルによって決定されます。
|
|
|
|
|
|
|
|
|
%% Lines beginning with "%%
" are ignored
|
|
|
|
|
|
|
|
|
|
|
|
|
|
include "COPY/ODCSF0B.cpy"
|
コピー・ファイルBCOAC01E.cpyの名前およびパスはファイルの作成時にユーザーが自由に選択します。
|
|
|
|
作成されるDB2/Luw(udb)表の名前を指定します。
|
|
|
|
VS-ODCSF0-RECORDはコピー・ファイルのレベル01フィールド名に相当します。
|
|
|
|
|
|
|
|
|
|
注意:
|
使用される様々なパラメータの説明は、『Oracle Tuxedo Application Rehosting Workbench リファレンス・ガイド』のFile-To-Fileコンバータに関する項を参照してください。
|
%% Lines beginning with "%%
" are ignored
COBOL記述ファイルを準備したら、
mapper-<configuration name>.reファイルに記述したコピー・ファイルを
$PARAM/file/recs-sourceディレクトリに置く必要があります。
file.sh [ [-g] [-m] [-i <installation directory>] <
configuration name> | -s <
installation directory> (<
configuration name>,...) ]
file.shでは、Tuxedo ART Workbenchにより、
VSAMファイルの移行に使用するコンポーネントを生成します。
$PARAMの
version.mk構成ファイルを使用して、makeユーティリティで必要な変数およびパラメータを設定します。
version.mkには、各種コンポーネントがインストールされる場所とその拡張機能、および使用される様々なツールのバージョンを指定します。このファイルにはログ・ファイルの構成方法も記述されます。
また、FILE_SCHEMAS変数はファイルの移行に固有で、処理する様々な構成を示します。
makefileおよび
version.mkファイルはTuxedo ART Workbench Simple Applicationとともに提供されます。
make FileConvertコマンドを使用して、Tuxedo ART Workbench
File-To-Fileコンバータを起動できます。これによりz/OSファイルのUNIX/Linuxターゲット・プラットフォームへの移行に必要なコンポーネントを生成できます。
makefileはFILE_SCHEMAS変数に含まれるすべての構成に対し、
-g、
-mおよび
-iオプションを指定して
file.shツールを起動できます。
-i $HOME/trfオプションで生成されるアンロード・コンポーネントおよびロード・コンポーネントは、次の場所に配置されます。
|
|
|
|
|
|
|
|
例: loadtable-ODCSF0.ksh RELTABLE-ODCSF0.sqb
|
|
|
生成ログ・ファイルMapper-log-<configuration name>は問題の解決に使用できます。
|
|
|
|
|
|
|
DB2/luw (udb) CUSTOMER表にアクセスするための1つの埋込みSQLプログラムが生成されます。
名前の変更ルールは、rename-objects-<schema name>.txtという名前のファイルに配置する必要があります。このファイルは、
$PARAM/rdbmsパラメータで示されたディレクトリに配置する必要があります。
スキーマ名は、system.descファイルのglobal-options句を使用して、Tuxedo ART Workbenchが決定することもできます。
パラメータtarget_<xxxxx>および
rdbms:<xxxxx>のみが調整される必要があります。
次のrdbmsパラメータは、z/OS DB2で使用され、DSNZPARMに格納される日付、タイムスタンプおよび時間形式を示します。
次のrdbmsパラメータはオプションで、DB2スキーマにCLOBまたはBLOBデータ型が含まれる場合にのみ必要です。
ターゲットMVSのデータセット名の長さがMIGR.SCH1.TAB1.COLUMN1と等しい場合(22文字)、JCLによって作成される文字列の最大長は32: 22 + 2 (カッコ文字) + 8 (メンバー名)になります。
ターゲットMVSのディレクトリ名の長さが/LOB/SCHEMA2/TABLE2/SECOND2と等しい場合(27文字)、JCLによって作成される文字列の最大長は36: 27 + 1 (スラッシュ文字) + 8 (ファイル名)になります。
|
注意:
|
rdbms:jcl_unload_utility_nameパラメータには、値 dsnutilbを設定する必要があります。
|
|
•
|
jcl_unload_utility_nameが dsnuprocに設定されている場合にのみ、2番目のパラメータを csvに設定できます。
|
rdbms.shでは、z/OS DB2データベースをUNIX Oracleデータベースに移行するために使用されるTuxedo ART Workbenchのコンポーネントを生成します。
次のコンポーネントが$TMPPROJECTに生成されます。DDL Oracle、
SQL*LOADERの
CTLファイル、COBOLコンバータで使用されるXMLファイル、構成ファイル(
mapper.reおよび
Datamap.re)。エラーまたは警告が発生してもプロセスは中断しません。
例: rdbms-conv.txt rdbms-conv-PJ01DB2.xml
$PARAMの
version.mk構成ファイルを使用して、makeユーティリティで必要な変数およびパラメータを設定します。
version.mkには、各種コンポーネントがインストールされる場所とその拡張機能、および使用される様々なツールのバージョンを指定します。このファイルにはログ・ファイルの構成方法も記述されます。
また、RDBMS_SCHEMAS変数はDB2の移行に固有で、処理する様々なスキーマを示します。
makefileおよび
version.mkファイルはTuxedo ART Workbench Simple Applicationとともに提供されます。
make RdbmsConvertコマンドを使用して、Tuxedo ART Workbench
File-To-Fileコンバータを起動できます。これによりDB2データベースからOracleへの移行に必要なコンポーネントを生成できます。
makefileはrdbms.shツールを、
-C、
-g、-
r、
-mおよび
-iオプションを使用して、
RDBMS_SCHEMAS変数に含まれるすべてのスキーマに対して起動できます。
-i $HOME/trfオプションで生成されるアンロード・コンポーネントおよびロード・コンポーネントは、次の場所に配置されます。
tr-hexa.mapファイルはEBCDIC (z/OSのコード・セット)とASCII (Linux/UNIXのコード・セット) 16進数値間のマッピング表です。
このスクリプトは、REFINEDIR/scripts/convert-hexa-copy-to-map.shに配置されます。
rename-call-map-fileは古いコール名と新しいコール名の間のマッピング・ファイルです。
これはTr-Rename-External-Callのような一部の変換ルールにより使用され、これによりユーザーは必要に応じて特定の変更を行うことができます。
この例ではMQGETへのすべてのコールは
MWMQGETに変更されます。
この例では、ログ・ファイルは$LOGS/trans-cbl/translate-cobol-datetimeに生成されます。ログ・ディレクトリはあらかじめ作成しておく必要があります。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
環境変数(PATH.LD_LIBRARY_PATH...)の初期化
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
詳細は、『Oracle Tuxedo Application Rehosting Workbench
リファレンス・ガイド』を参照してください。
プログラムBATCH/PGMMB00.cblをコンパイルするコマンドは次のとおりです。
|
•
|
カタロガにより生成されたPOBファイルに格納されているJCLの抽象構文ツリー。
|
カタロガにより生成された変換するJCLのASTに加え、Tuxedo ART Workbench JCLトランスレータは次のような様々な変換の要素を指定するメイン構成ファイルを入力として取得します。
2つのオプションtop-skeletonおよび
bottom-skeletonにより指定されたサブファイルは、それぞれ生成されたスクリプトのヘッダー・ファイルおよびフッター・ファイルを表します。これらのファイルはカスタマイズできます。
このサブファイルはFile-to-Fileコンバータにより生成されます。このファイルはJCLトランスレータにOracle表に変換されるファイルを示し、これらのファイルを含む手順を適切に変換できるようにします。例では、
PJ01AAA.SS.VSAM.CUSTOMERが変換されるファイルです。
一般オプションのroot-skeleton、
target-proc、
label-endなどは、『Oracle Tuxedo Application Rehosting Workbenchリファレンス・ガイド』のJCLトランスレータに関する項で説明しています。
|
1.
|
renov-jcl.descに次のルールを書き込みます。
|
$SOURCEファイル・システムのすべてのJCLを変換する場合
$SOURCEディレクトリから次のコマンドを起動します。
アンロードに使用されるコンポーネント($HOME/trf/unload/fileに生成)は、ソースz/OSプラットフォームにインストールする必要があります。生成されたJCLは、JOBカード、ライブラリ・アクセス・パス、入力および出力ファイル(データ・セット名: DSN)へのアクセス・パスを含む、特定のサイトの制約への適合が必要な場合があります。
|
注意:
|
.jclunload拡張子は、z/OSで実行する場合には削除する必要があります。
|
実行ログは$MT_LOGで示されたディレクトリに作成されます。
このチェックでは、次のloadfile-<logical file name>.kshのオプションを使用します
|
•
|
Mapper-log-<configuration name>ファイルにエラーが含まれているか( 「共通の問題と解決策」を参照)。
|
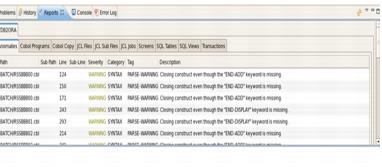
file.sh -gmi $HOME/trf STFILEORAの実行時に次のメッセージが表示されます。
Mapper-log-STFILEORAログ・ファイルの内容には次が含まれます。
移行するファイルがmapper-<configuration name>.reファイルに存在し、
Datamap.<configuration name>.reファイルには存在しません。
file.sh -gmi $HOME/trf STFILEORA1の実行時に次のメッセージが表示されます。
Mapper-log-STFILEORA1ログ・ファイルの内容には次が含まれます。
file.sh -gmi $HOME/trf STFILEORA2の実行時に次のメッセージが表示されます。
Mapper-log-STFILEORA2ログ・ファイルの内容には次が含まれます。
file.sh -gmi $HOME/trf STFILEORA3の実行時に次のメッセージが表示されます。
Mapper-log-STFILEORA3ログ・ファイルの内容には次が含まれます。
アンロードに使用されるコンポーネント($HOME/trf/unload/fileに生成)は、ソースz/OSプラットフォームにインストールする必要があります。生成されたJCLは、JOBカード、ライブラリ・アクセス・パス、入力および出力ファイル(データ・セット名: DSN)へのアクセス・パスを含む、特定のサイトの制約への適合が必要な場合があります。
表1-34は、ターゲット・プラットフォームに設定する必要がある環境変数を示しています。
|
注意:
|
.jclunload拡張子は、z/OSで実行する場合には削除する必要があります。
|
loadtable-<…>.kshスクリプトのオプション
-dにより、Oracleオブジェクトを作成できます。
実行ログは$MT_LOGで示されたディレクトリに作成されます。
この確認は次のloadtable-<logical file name>.kshのオプションを使用します
|
•
|
Mapper-log-<configuration name>ファイルにエラーが含まれているか( 「共通の問題と解決策」を参照)。
|
エラー・メッセージとその説明は、『Oracle Tuxedo Application Rehosting Workbench
リファレンス・ガイド』の付録に記載されています。
file.sh -gmi $HOME/trf STFILEORAの実行時に次のメッセージが表示されます。
file.sh -gmi $HOME/trf STFILEORA1の実行時に次のメッセージが表示されます。
file.sh -gmi $HOME/trf STFILEORA2の実行時に次のメッセージが表示されます。
Mapper-log-STFILEORA2ログ・ファイルの内容には次が含まれます。
file.sh -gmi $HOME/trf STFILEORAの実行時に次のメッセージが表示されます。
file.sh -gmi $HOME/trf STFILEORAの実行時に次のメッセージが表示されます。
アンロードに使用されるコンポーネント($HOME/trf/unload/fileに生成)は、ソースz/OSプラットフォームにインストールする必要があります。生成されたJCLは、JOBカード、ライブラリ・アクセス・パス、入力および出力ファイル(データ・セット名: DSN)へのアクセス・パスを含む、特定のサイトの制約への適合が必要な場合があります。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
このUNIX/Linux変数は、Oracle Tuxedo Application Runtime for Batchユーティリティのディレクトリを含む必要があります
|
|
注意:
|
.jclunload拡張子は、z/OSで実行する場合には削除する必要があります。
|
loadtable-<…>.kshスクリプトのオプション
-dにより、Oracleオブジェクトを作成できます。
実行ログは$MT_LOGで示されたディレクトリに作成されます。
この確認は次のloadtable-<logical file name>.kshのオプションを使用します
COBOLおよび埋込みSQLアクセス・ルーチンは、『Oracle Tuxedo Application Rehosting Workbench
リファレンス・ガイド』に記載されたターゲットのCOBOLコンパイル・オプションを使用してコンパイルされる必要があります。
|
•
|
Mapper-log-<configuration name>ファイルにエラーが含まれているか( 「共通の問題と解決策」を参照)。
|
file.sh -gmi $HOME/trf STFILEUDBの実行時に次のメッセージが表示されます。
file.sh -gmi $HOME/trf STFILEUDB1の実行時に次のメッセージが表示されます。
file.sh -gmi $HOME/trf STFILEUDB2の実行時に次のメッセージが表示されます。
Mapper-log-STFILEUDB2ログ・ファイルの内容には次が含まれます。
file.sh -gmi $HOME/trf STFILEUDBの実行時に次のメッセージが表示されます。
file.sh -gmi $HOME/trf STFILEORAの実行時に次のメッセージが表示されます。
アンロードに使用されるコンポーネント($HOME/trf/unload/rdbmsに生成)は、ソースz/OSプラットフォームにインストールする必要があります。生成されたJCLは、JOBカード、ライブラリ・アクセス・パス、入力および出力ファイル(データ・セット名: DSN)へのアクセス・パスを含む、特定のサイトの制約への適合が必要な場合があります。
表1-36は、ターゲット・プラットフォームに設定する必要がある環境変数を示しています。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SQL*LOADERで使用される<table name>. ctlファイルを含むディレクトリ( $HOME/trf/reload/rdbms/<schema name>/ctl)。
|
|
|
|
|
|
|
|
|
|
|
|
|
次の変数は『Oracle Tuxedo Application Rehosting Workbench
インストレーション・ガイド』の情報に従って設定する必要があります。
再ロード・スクリプトloadrdbms-<table name>.kshは、
SQL*LDR Oracleユーティリティを使用します。このユーティリティがアクセスできるのはORACLEサーバーに限られるため、このスクリプトはORACLEサーバーで使用する必要があり、クライアント接続では使用できません。特にこの再ロード手順では、この変数に
@<oracle_sid>文字列を含めることはできません。
パッケージは、REFINEDIR/convert-data/fixed-components/MWDB2ORA.plbおよび
REFINEDIR/convert-data/fixed-components/MWDB2ORA_CONST.plbに配置されます。
MWDB2ORA_CONST.plbパッケージを調整して、これらのパッケージを
DB2-To-Oracleコンバータに関する項で説明されているように、SQLPLUSの下にインストールする必要があります。
パラメータrdbms:jcl_unload_lob_file_systemがそれぞれ
pdsまたは
hfsに設定されている場合、これらのファイルは他のデータセットまたはディレクトリに書き込まれます。
<schema name>
.lstファイルには、すべての表の名前が階層順に含まれます(親表の次に子表)。
表1-37に、Tuxedo ART Workbenchで管理されるDB2オブジェクトとそれを作成するために使用するスクリプトの名前をリストします。
|
|
|
|
|
|
|
|
|
|
|
このファイルには、表<target_table_name>に関連付けられたすべてのCREATE INDEXが含まれます。このファイルは表 <target_table_name>>に索引が定義されてない場合には生成されません。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
このプログラムは出力時にRECORD SEQUENTIALファイルを生成し、それは次に
SQL*LOADERユーティリティに読み取られます。
loadrdbms-<table name>.ksh [-t | [-O|-T]] [-l] [-c: <
method>]
このチェックでは、loadrdbms-<table name>.kshの次のオプションを使用します
|
•
|
rdbms-converter-<schema name>.logファイルにエラーが含まれているか( 「共通の問題と解決策」を参照)。
|
エラー・メッセージとその説明は、『Oracle Tuxedo Application Rehosting Workbench
リファレンス・ガイド』の付録に記載されています。
$REFINEDIR/$VERS/rdbms.sh -Cgrmi $HOME/trf PJ01DB2 STFILEORAの実行時に、次のメッセージが表示されます。
$REFINEDIR/$VERS/rdbms.sh -Cgrmi $HOME/trf SCHEMAの実行時に、次のメッセージが表示されます。
$REFINEDIR/$VERS/rdbms.sh -Cgrmi $HOME/trf PJ01DB2の実行時に、次のメッセージが表示されます。
$REFINEDIR/$VERS/rdbms.sh -Cgrmi $HOME/bad-directory PJ01DB2の実行時に、次のメッセージが表示されます。
$REFINEDIR/$VERS/rdbms.sh -c WWARNの実行時に、次のメッセージが表示されます。