



|
|
あるプロセスから別のプロセスにメッセージを送信する場合、メッセージ データ用のバッファを割り当てておく必要があります。Oracle Tuxedo システムのクライアントは、型付きバッファを使用してサーバにメッセージを送ります。型付きバッファとは、カテゴリ (タイプ) と、サブカテゴリ (サブタイプ) が定義されたメモリ領域です。サブカテゴリは必須ではありません。型付きバッファは、Oracle Tuxedo システムでサポートされる分散プログラミング環境の基本要素の 1 つです。
なぜ「型付き」レコードを使用するのでしょうか。分散環境では、アプリケーションが異機種システムにインストールされ、異なるプロトコルを使用して複数のネットワーク間で通信が行われます。バッファ タイプが異なると、初期化、メッセージの送受信、およびデータのエンコード/デコードにそれぞれ別のルーチンが必要になります。各バッファに特定のタイプが割り当てられていると、プログラマが介在しなくても、そのタイプに対応するルーチンを自動的に呼び出すことができます。
以下に示す表は、Oracle Tuxedo システムでサポートされる型付きバッファと、そのバッファが次の条件を満たしているかどうかを示しています。
ルーティング関数が必要な場合は、アプリケーション プログラマが用意します。
|
|
|||||
|
|
|||||
|
|
|||||
すべてのバッファ タイプは、$TUXDIR/lib ディレクトリの tmtypesw.c ファイルに定義されています。クライアント プログラムとサーバ プログラムで認識されるバッファ タイプは、tmtypesw.c に定義されているものだけです。tmtypesw.c ファイルを編集して、バッファ タイプを追加したり削除できます。また、UBBCONFIG の BUFTYPE パラメータを使用して、特定のサービスで処理できるタイプとサブタイプを制限できます。
tmtypesw.c ファイルは、共有オブジェクトや動的リンク ライブラリのビルドに使用されます。このオブジェクトは、Oracle Tuxedo 管理サーバ、およびアプリケーション クライアントとアプリケーション サーバによって動的にロードされます。
初期状態では、バッファはクライアント プロセスに対応付けられていません。クライアント プロセスでメッセージを送信する場合、サポートされているタイプのバッファを割り当てて、メッセージを格納できるようにします。型付きバッファを割り当てるには、次に示すように tpacall(3c) 関数を使用します。
char*
tpalloc(char *type, char *subtype, longsize)
CARRAY、X_OCTET、および XML を除くすべての型付きバッファに、自動的にデフォルトのバッファ サイズが割り当てられます。自動的にバッファ サイズが割り当てられないバッファ型には、バッファの終わりを識別できるようにサイズを指定する必要があります。
|
次の例で示すように、VIEW、VIEW32、X_C_TYPE、および X_COMMON 型バッファには subtype 引数が必要です。
struct aud *audv; /* VIEW 構造体 aud を指すポインタ */
. . .
audv = (struct aud *) tpalloc("VIEW", "aud", sizeof(struct aud));
. . .
次の例は、FML 型バッファの割り当て方法を示しています。subtype 引数に NULL 値が指定されていることに注目してください。
FBFR *fbfr; /* FML バッファ構造体を指すポインタ */
. . .
fbfr = (FBFR *)tpalloc("FML", NULL, Fneeded(f, v))
. . .
次の例は、CARRAY 型バッファの割り当て方法を示しています。このバッファ型では、size 値を指定する必要があります。
char *cptr;
long casize;
. . .
casize = 1024;
cptr = tpalloc("CARRAY", NULL, casize);
. . .
処理が正常に終了すると、tpalloc() 関数は char 型のポインタを返します。STRING と CARRAY 以外のタイプでは、ポインタを適切な C 構造体または FML ポインタにキャストする必要があります。
tpalloc() 関数は、エラーを検出すると NULL ポインタを返します。次は、エラー条件の例です。
全エラー コードとその説明については、『Oracle Tuxedo C リファレンス』の「tpalloc(3c)」を参照してください。
次のコード リストは、STRING 型バッファの割り当て方法を示しています。この例では、tpalloc() の size 引数の値として、デフォルト値が使用されています。
char *cptr;
. . .
cptr = tpalloc("STRING", NULL, 0);
. . .
バッファを割り当てると、そこにデータを格納できるようになります。
次の例では、3 つのメンバー (フィールド) を持つ VIEW 型バッファ aud を作成しています。3 つのメンバーは、コマンドラインがある場合はそこから取得される支店識別子の b_id、照会された残高を返す balance、およびステータス行にメッセージを返す ermsg です。audit を使用して特定の支店の残高が照会されると、b_id の値には要求の送信先の支店識別子、balance にはゼロ、ermsg には NULL 文字列がそれぞれ設定されます。
...
audv = (struct aud *)tpalloc("VIEW", "aud", sizeof(struct aud));
/* aud 構造体を用意する */
audv->b_id = q_branchid;
audv->balance = 0.0;
(void)strcpy(audv->ermsg, "");
...
audit を使用して銀行全体の残高が照会されると、BAL サーバが呼び出されてサイトごとの残高合計が取得されます。個々のサイトで照会を行うには、代表支店識別子を指定します。代表支店 ID は、配列 sitelist[] に格納されます。したがって、aud 構造体は、次の例のように設定されます。
...
/* aud 構造体を用意する */
audv->b_id = sitelist[i];/* このフィールドでルーティング */
audv->balance = 0.0;
(void)strcpy(audv->ermsg, "");
...
STRING バッファにデータを格納するプロセスについては、「バッファのサイズ変更」のコード リストを参照してください。
tpalloc() で割り当てられたバッファのサイズを変更するには、次のように tprealloc(3c) 関数を使用します。
char*
tprealloc(char *ptr, long size)
次の表は、tprealloc() 関数の引数を示しています。
tpalloc() の呼び出しで設定されます。それ以外の方法で設定されている場合、呼び出しは失敗し、tperrno(5) が TPEINVAL に設定されて、無効な引数がこの関数に渡されたことが示されます。
|
|
tprealloc() が返すポインタは、元のバッファと同じタイプのバッファを指します。バッファの場所が変わっている場合があるので、返されたポインタを使用してサイズが変更されたバッファを参照します。
バッファのサイズを増やすために tprealloc() 関数を呼び出すと、バッファに新しい領域が割り当てられます。バッファのサイズを減らすために tprealloc() 関数を呼び出すと、実際にバッファのサイズが変更されるのでなく、指定されたサイズを超える領域が使用不能になります。型付きバッファの内容には影響しません。未使用領域を解放するには、必要なサイズを持つ別のバッファにデータをコピーし、未使用領域を持つバッファを解放します。
tprealloc() 関数は、エラーが発生すると NULL ポインタを返し、tperrno に適切な値を設定します。エラー コードについては、『Oracle Tuxedo C リファレンス』の「tpalloc(3c)」を参照してください。
| 警告 : | tprealloc() 関数が NULL ポインタを返した場合、内容が変更されて有効ではなくなったバッファが渡された可能性があります。 |
次のコード リストは、STRING バッファの領域を再度割り当てる方法を示しています。
#include <stdio.h>
#include “atmi.h”
char instr[100]; /* 標準入力からの入力文字列を格納する文字列 */
long s1len, s2len; /* 文字列 1 と文字列 2 の長さ */
char *s1ptr, *s2ptr; /* 文字列 1 と文字列 2 のポインタ */
main()
{
(void)gets(instr); /* 標準入力から行を取得 */
s1len = (long)strlen(instr)+1; /* 長さを決定 */
join application
if ((s1ptr = tpalloc(“STRING”, NULL, s1len)) == NULL) {
fprintf(stderr, “tpalloc failed for echo of: %s\n”, instr);
leave application
exit(1);
}
(void)strcpy(s1ptr, instr);
make communication call with buffer pointed to by s1ptr
(void)gets(instr); /* 標準入力から別の行を取得 */
s2len = (long)strlen(instr)+1; /* その長さを決定 */
if ((s2ptr = tprealloc(s1ptr, s2len)) == NULL) {
fprintf(stderr, “tprealloc failed for echo of: %s\n”, instr);
free s1ptr's buffer
leave application
exit(1);
}
(void)strcpy(s2ptr, instr);
make communication call with buffer pointed to by s2ptr
. . .
}
次の例は前述の例を拡張したもので、発生する可能性があるエラー コードを確認する方法を示しています。
. . .
if ((s2ptr=tprealloc(s1ptr, s2len)) == NULL)
switch(tperrno) {
case TPEINVAL:
fprintf(stderr, "given invalid arguments\n");
fprintf(stderr, "will do tpalloc instead\n");
tpfree(s1ptr);
if ((s2ptr=tpalloc("STRING", NULL, s2len)) == NULL) {
fprintf(stderr, "tpalloc failed for echo of: %s\n", instr);
leave application
exit(1);
}
break;
case TPEPROTO:
fprintf(stderr, "tried to tprealloc before tpinit;\n");
fprintf(stderr, "program error; contact product support\n");
leave application
exit(1);
case TPESYSTEM:
fprintf(stderr,
"BEA Tuxedo error occurred; consult today's userlog file\n");
leave application
exit(1);
case TPEOS:
fprintf(stderr, "Operating System error %d occurred\n",Uunixerr);
leave application
exit(1);
default:
fprintf(stderr,
"Error from tpalloc: %s\n", tpstrerror(tperrno));
break;
}
tptypes(3c) 関数は、バッファのタイプとサブタイプ (指定されている場合) を返します。次は tptypes() 関数の文法です。
long
tptypes(char *ptr, char *type, char *subtype)
tprealloc() の呼び出しで設定されます。NULL は指定できません。また、文字型にキャストする必要があります。この 2 つの条件が満たされていない場合、tptypes() 関数は引数が無効であることを示すエラーを返します。
|
|
処理が正常に終了した場合、tptypes() 関数は長精度型 (long) でバッファの長さを返します。
エラーが発生した場合、tptypes() 関数は -1 を返し、tperrno(5) に対応するエラー コードを設定します。エラー コードについては、『Oracle Tuxedo C リファレンス』の「C 言語アプリケーション トランザクション モニタ インタフェースについて」および「tpalloc(3c)」を参照してください。
処理の正常終了時に tptypes() 関数から返されたサイズ値を使用して、次の例に示すように、デフォルトのバッファ サイズがデータを格納するのに十分な大きさかどうかを確認できます。
. . .
iptr = (FBFR *)tpalloc("FML", NULL, 0);
ilen = tptypes(iptr, NULL, NULL);
.. .
if (ilen < mydatasize)
iptr=tprealloc(iptr, mydatasize);
tpfree(3c) 関数は、tpalloc() で割り当てられたバッファ、または tprealloc() で再度割り当てられたバッファを解放します。次は tpfree() 関数の文法です。
void
tpfree(char *ptr)
tpfree() 関数の引数は、次の表に示す ptr だけです。
tpfree() を使用して FML32 バッファを解放するとき、ルーチンは埋め込まれたバッファをすべて再帰的に解放して、メモリ リークの発生を防ぎます。埋め込みバッファが解放されないようにするには、対応するポインタに NULL を指定してから tpfree() ルーチンを発行します。ptr が NULL の場合、何も処理は行われません。
次のコード リストは、tpfree() 関数を使用してバッファを解放する方法を示しています。
struct aud *audv; /* VIEW 構造体 aud を指すポインタ */
. . .
audv = (struct aud *) tpalloc("VIEW", "aud", sizeof(struct aud));
. . .
tpfree((char *)audv);
VIEW 型バッファには 2 種類あります。1 つは FML VIEW で、FML バッファから生成される C 構造体です。もう 1 つは、単なる非依存型の C 構造体です。
FML バッファを C 構造体に変換して再び元に戻す (FML VIEW 型バッファを使用する) のは、FML 型バッファでの処理にはオーバーヘッドが生じるからです。つまり FML 型バッファには、データの独立性と操作の利便性がある一方で、FML 関数を呼び出すためのオーバーヘッドが発生します。C 構造体は、柔軟性の点では劣りますが、バッファ データの時間がかかる処理に適しています。大量のデータを操作する場合、フィールド化バッファのデータを C 構造体に転送し、通常の C 関数を使用してそのデータを処理し、格納やメッセージ転送を行うためにそのデータを FML 型バッファに戻すと、パフォーマンスを向上させることができます。
FML 型バッファと FML ファイルの変換の詳細については、『Oracle Tuxedo FML リファレンス』を参照してください。
#include 文に指定します。
アプリケーションで VIEW 型バッファを使用するには、次の環境変数を設定します。
VIEW 型バッファを使用するには、VIEW 記述ファイルに C 言語のレコードを定義する必要があります。VIEW 記述ファイルには、各エントリの VIEW、および C 構造体のマッピングと FML 変換パターンを記述した VIEW が定義されています。VIEW の名前は、C 言語の構造体の名前に対応します。
$ /* VIEW 構造体 */
VIEW viewname
type cname fbname count flag size null
次の表は、VIEW 記述ファイルに指定する必要がある各 C 構造体のフィールドを示しています。
|
|||
FML から VIEW、または VIEW から FML への変換関数を使用する場合、対応する FML 名をこのフィールドに指定する必要があります。このフィールド名は、FML フィールド テーブル ファイルにも必要です。FML に依存しない VIEW には必要ありません。
|
|||
|
|||
dec_t の場合は 0.0) になります。文字型の場合、デフォルトの NULL 値は \0 になります。STRING 型、CARRAY 型、および MBSTRING 型の場合、デフォルトの NULL 値は “ ” になります。
\ddd (d は 8 進数)、\0、\n、\t、\v、\r、\f、\\、\’、および \” です。
|
行頭に # または $ 文字を付けてコメント行を挿入できます。行頭に $ が挿入されたコード行は、.h ファイルに出力されます。
次のコード リストは、FML バッファに基づく VIEW 記述サンプル ファイルの一部です。このコード リストでは、fbname フィールドを指定する必要があり、この値は対応するフィールド テーブル ファイルの値と一致していなければなりません。CARRAY1 フィールドのオカレンス カウントが 2 に設定されていること、C フラグが設定されて追加のカウント要素の作成が定義されていることに注目してください。また、L フラグが設定され、アプリケーションが CARRAY1 フィールドを格納するときの文字数を示す長さ要素が定義されています。
$ /* VIEW 構造体 */
VIEW MYVIEW
#型 cname fbname カウント フラグ サイズ null
float float1 FLOAT1 1 - - 0.0
double double1 DOUBLE1 1 - - 0.0
long long1 LONG1 1 - - 0
short short1 SHORT1 1 - - 0
int int1 INT1 1 - - 0
dec_t dec1 DEC1 1 - 9,16 0
char char1 CHAR1 1 - - '\0'
string string1 STRING1 1 - 20 '\0'
carray carray1 CARRAY1 2 CL 20 '\0'
END
次のコード リストは、同じ VIEW 記述ファイルで非依存型 VIEW のものを示しています。
$ /* VIEW データ構造体 */
VIEW MYVIEW
#型 cname fbname カウント フラグ サイズ null
float float1 - 1 - - -
double double1 - 1 - - -
long long1 - 1 - - -
short short1 - 1 - - -
int int1 - 1 - - -
dec_t dec1 - 1 - 9,16 -
char char1 - 1 - - -
string string1 - 1 - 20 -
carray carray1 - 2 CL 20 -
END
この形式は FML 依存型 VIEW と同じです。ただし、fbname フィールドと null フィールドには意味がなく、viewc コンパイラで無視されます。これらのフィールドには、プレースホルダとしてダッシュ (-) などの値を挿入する必要があります。
VIEW 型バッファをコンパイルするには、引数として VIEW 記述ファイルの名前を指定して viewc コマンドを実行します。非依存型 VIEW を指定するには、-n オプションを使用します。生成される出力ファイルを書き込むディレクトリを指定することもできます (省略可能)。デフォルトでは、出力ファイルはカレント ディレクトリに書き込まれます。
たとえば、FML 依存型 VIEW をコンパイルするには、次のようにコンパイラを実行します。
viewc myview.v
| 注意 : | VIEW32 型バッファをコンパイルするには、viewc32 コマンドを実行します。 |
非依存型 VIEW の場合、コマンドラインで次のように -n オプションを指定します。
viewc -n myview.v
次のコード リストは、viewc によって生成されるヘッダ ファイルを示しています。
struct MYVIEW {
float float1;
double double1;
long long1;
short short1;
int int1;
dec_t dec1;
char char1;
char string1[20];
unsigned short L_carray1[2]; /* carray1 の長さを挿入する配列 */
short C_carray1; /* carray1 のカウント */
char carray1[2][20];
};
FML 依存型と FML 非依存型 VIEW にも、同じヘッダ ファイルが生成されます。
クライアント プログラムまたはサービス サブルーチンで VIEW 型バッファを使用するには、アプリケーションの #include 文にヘッダ ファイルを指定する必要があります。
FML ヘッダ ファイルを作成して、アプリケーションの #include 文に指定します。
FML 関数は、フィールド化バッファから C 構造体への変換、またその逆の変換など、型付きバッファを操作する場合に使用します。これらの関数を使用すると、データ構造やデータの格納状態がわからなくても、データ値にアクセスしたり更新できます。FML 関数の詳細については、『Oracle Tuxedo FML リファレンス』を参照してください。
アプリケーション プログラムで FML 型バッファを使用するには、次の環境変数を設定する必要があります。
FML 型バッファや FML 依存型 VIEW を使用する場合は、常にフィールド テーブル ファイルが必要です。フィールド テーブル ファイルは、FML 型バッファのフィールドの論理名をそのフィールドをユニークに識別する文字列にマッピングします。
FML フィールド テーブルの各フィールドは、次の形式で定義します。
$ /* FML 構造体 */
*basevaluename number type flags comments
次の表は、FML フィールド テーブルに指定する必要がある FML フィールドを示しています。
すべてのフィールドは省略可能です。また、複数個使用できます。
次のコード リストは、FML 依存型 VIEW の例で使用されるフィールド テーブル ファイルを示しています。
# 名前 番号 型 フラグ コメント
FLOAT1 110 float - -
DOUBLE1 111 double - -
LONG1 112 long - -
SHORT1 113 short - -
INT1 114 long - -
DEC1 115 string - -
CHAR1 116 char - -
STRING1 117 string - -
CARRAY1 118 carray - -
クライアント プログラムやサービス サブルーチンで FML 型バッファを使用するには、FML ヘッダ ファイルを作成して、アプリケーションの #include 文にそのヘッダ ファイルを指定する必要があります。
フィールド テーブル ファイルから FML ヘッダ ファイルを作成するには、mkfldhdr(1) コマンドを使用します。たとえば、myview.flds.h というファイルを作成するには、次のコマンドを入力します。
mkfldhdr myview.flds
FML32 型バッファの場合は、mkfldhdr32 コマンドを使用します。
次のコード リストは、mkfldhdr コマンドによって作成される myview.flds.h ヘッダ ファイルを示しています。
/* fname fldid */
/* ----- ----- */
#define FLOAT1 ((FLDID)24686) /* 番号 : 110 タイプ : float */
#define DOUBLE1 ((FLDID)32879) /* 番号 : 111 タイプ : double */
#define LONG1 ((FLDID)8304) /* 番号 : 112 タイプ : long */
#define SHORT1 ((FLDID)113) /* 番号 : 113 タイプ : short */
#define INT1 ((FLDID)8306) /* 番号 : 114 タイプ : long */
#define DEC1 ((FLDID)41075) /* 番号 : 115 タイプ : string */
#define CHAR1 ((FLDID)16500) /* 番号 : 116 タイプ : char */
#define STRING1 ((FLDID)41077) /* 番号 : 117 タイプ : string */
#define CARRAY1 ((FLDID)49270) /* 番号 : 118 タイプ : carray */
アプリケーションの #include 文に新しいヘッダ ファイルを指定します。ヘッダ ファイルがインクルードされると、シンボリック名でフィールドを参照できるようになります。
XML がデータ標準として受け入れられるに伴い、アプリケーションで XML 型付きバッファを使用する Oracle Tuxedo ユーザが増加しています。この動きを後押しするため、Oracle Tuxedo ソフトウェアでは Apache Xerces C++ バージョン 2.5 パーサが統合されました。
XML バッファを使用すると、Oracle Tuxedo アプリケーションで XML を使用して、アプリケーション内やアプリケーション間でデータを交換できるようになります。Oracle Tuxedo アプリケーションでは、単純 XML 型バッファの送受信や、それらのバッファを適切なサーバにルーティングできます。解析など、XML 文書のすべての処理ロジックはアプリケーション側にあります。
XML 型バッファのプログラミング モデルは、CARRAY 型バッファのモデルと類似しています。tpalloc() 関数を使用して、バッファの長さを指定する必要があります。最大 4 GB の XML 文書がサポートされます。
イベント処理で行われるフォーマット処理とフィルタ処理は、STRING 型バッファが使用されている場合はサポートされますが、XML 型バッファではサポートされません。そのため、XML 型バッファのバッファ タイプ スイッチ内の _tmfilter 関数と _tmformat 関数のポインタは、NULL に設定されます。
Oracle Tuxedo システムの XML パーサは、次の操作を行います。
XML 型バッファでは、データ依存型ルーティングがサポートされています。XML 文書のルーティングは、要素の内容、または要素タイプと属性値に基づいて行われます。使用される文字エンコードは XML パーサによって判別されます。エンコードが Oracle Tuxedo のコンフィグレーション ファイル (UBBCONFIG と DMCONFIG) で使用されているネイティブな文字セット (US-ASCII または EBCDIC) と異なる場合、要素と属性名は US-ASCII または EBCDIC に変換されます。
XML 文書には、ルーティング用にコンフィグレーションする属性を含めなければなりません。属性がルーティング基準としてコンフィグレーションされていても XML 文書に含まれていない場合、ルーティング処理は失敗します。
要素の内容と属性値は、ルーティング フィールド値の構文とセマンティクスに従っていることが必要です。また、ルーティング フィールド値のタイプも指定しなければなりません。XML でサポートされるのは文字データだけです。範囲フィールドが数値の場合、そのフィールドの内容や値はルーティング処理時に数値に変換されます。
Xerces-C++ 2.5.0 パーサは、移植可能な C++ サブセットで記述され、XML 文書を解析、生成、操作、および検証するための共有ライブラリを備えています。また、XML 1.0 勧告、および関連標準の DOM 1.0、DOM 2.0、SAX 1.0、SAX 2.0、Namespaces、および W3C の XML スキーマ勧告バージョン 1.0 に準拠しています。
Xerces-C++ 1.7 パーサは、検証が必要なときに文書型定義 (DTD) と XML スキーマ ファイルをキャッシュせず、DTD で使用される外部エンティティ ファイルもキャッシュしません。Oracle Tuxedo 8.1 では、Web で繰り返し取得される外部 DTD、スキーマ、およびエンティティ ファイルをキャッシュするオプションを追加することによって Xerces-C++ 1.7 パーサの性能が向上ました。この変更の継続的なサポートは、Tuxedo 9.x および Xerces C++ 2.5.0 で使用可能です。
Xerces-C++ パーサのキャッシュ機能を有効または無効にする方法は次の 2 通りです。
| 注意 : | 4 つのメソッドは、Apache Xerces-C++ パーサに加えられた Oracle Tuxedo の拡張機能です。以下の 2 つの Xerces オブジェクトと組み合わせて排他的に使用されます。 |
Oracle Tuxedo 配布キットには、さまざまなプラットフォーム上で 200 種類を超えるエンコード文字セット (エンコード形式) をサポートする C/C++ ライブラリ、International Components for Unicode (ICU) 3.0 ライブラリが付属しています。Xerces-C++ 2.5.0 パーサは、ICU 3.0 ライブラリと共に構築されます。
Xerces-C++ パーサ ATMI 関数を使用するためのサンプル アプリケーションは、Oracle Tuxedo ユーザ マニュアルに記載されています。このサンプルには、Xerces-C++ パーサのラッパーを記述して、C で記述された Tuxedo クライアントおよびサーバから Xerces-C++ ATMI 関数を呼び出せるようにするための方法が示されています。
Xerces パーサで XML スキーマを使用するためのサンプル アプリケーションは、Oracle Tuxedo ユーザ マニュアルに記載されています。『サンプルを使用した Oracle Tuxedo アプリケーションの開発方法』の「xmlfmlapp (完全な C XML/FML32 変換アプリケーション) のチュートリアル」
getURLEntityCacheDir(3c)、setURLEntityCacheDir(3c)、getURLEntityCaching(3c)、setURLEntityCaching(3c)、Xerces API パーサのオンライン マニュアル
入力/出力形式として、XML データは、現在のアプリケーション開発で幅広く使用されています。一方、ほとんどの Tuxedo カスタマは、望ましいデータ転送として Tuxedo FML/FML32 バッファを使用する既存の定義済みサービスに多額の投資を行っています。
Oracle Tuxedo は、XML と FML/FML32 バッファ間のデータ変換が可能な機能を追加して、この問題に対処します。この変換は、次のいずれかの方法で開始できます。
プログラマ用に、XML データと FML/FML32 バッファ間のオンデマンド変換では、手動変換用に新しい ATMI 関数が 4 つ用意されています。詳細については、「オンデマンド変換の使い方」を参照してください。
アプリケーション開発者用に、XML と FML/FML32 バッファ間の自動変換では、UBBCONFIG コンフィグレーション ファイルの SERVICES セクションに新しい BUFTYPECONV パラメータが用意されています。自動変換では、サーバの起動時に変換が開始されます。詳細については、「自動変換の使い方」を参照してください。
変換に使用されるメソッドに関係なく、FML/FML32 フィールド型は、特定の方法で XML にマッピングされます。変換マッピングの詳細については、「XML と FML/FML32 フィールド型のマッピング」を参照してください。
| 注意 : | XML と FML/FML32 間の変換では、サイズが大きくなる可能性があるサード パーティ ライブラリ (libticudata.so など) を使用します。 |
| 注意 : | 共有ライブラリのサイズが大きくなると、そのライブラリに直接または間接的に依存する、Tuxedo アプリケーションで実行中のプロセスが多くのメモリを消費し、その結果、パフォーマンスが低下する可能性があります。 |
| 注意 : | XML と FML/FML32 間の変換機能は、Tuxedo システム プロセスでは使用しないでください。 |
| 注意 : | Xerces パーサを使用した XML と FML/FML32 バッファ間の変換の制限に関するその他の既知の問題については、「変換の制限事項」を参照してください。 |
オンデマンド変換では、XML データから FML/FML32 バッファまたは FML/FML32 バッファから XML データへの変換を手動で実行できます。
次の 4 つの ATMI 関数では、オンデマンド変換を実行できます。
これらの関数と引数の詳細な説明については、『Oracle Tuxedo C リファレンス』を参照してください。
XML データと FML/FML32 バッファ間のオンデマンド変換を実行するには、次の手順に従います。
ATMI 関数を使用して XML と FML/FML32 バッファ間の変換を開始する場合は、次のいずれかの方法でパーサ検証が決定されます。
ATMI 関数とその Xerces パーサの flag 引数の詳細な説明については、『BEA Tuxedo C リファレンス』を参照してください。
自動変換では、最初の形式も最後の形式も XML になります。つまり、XML バッファが FML/FML32 バッファに入力、変換、および処理され、最後に XML に再変換されます。
XML と FML/FML32 バッファ間の変換を開始するには、UBBCONFIG ファイルの SERVICES セクションの BUFTYPECONV パラメータを指定する必要があります。このパラメータは、XML2FML または XML2FML32 のどちらかの値のオプションのみを受け付けます。
このパラメータを使用してサーバを起動した場合、クライアント tpcall()、tpacall()、tpconnect()、または tpsend() によって入力バッファが XML バッファから FML/FML32 バッファに変換されてからサービスに送られます。tpreturn() または tpsend() が呼び出されると、FML/FML32 バッファが XML バッファに変換されてから返されます。
BUFTYPECONV パラメータを使用しているサービスでは、クライアントまたはその他のサービスは、既存のサービスが FML/FML32 バッファを処理する方法を変更することなく、XML バッファを送受信できます。
| 注意 : | BUFTYPECONV パラメータを使用する場合は、以下の項目に注意してください。 |
BUFTYPECONV パラメータを使用している場合、出力されたすべての FML/FML32 バッファは XML に変換されます。BUFTYPECONV パラメータを使用して新しいサービス名を作成すると、XML を出力し、FML/FML32 バッファに対する元のサービス名を保持することができます。BUFTYPECONV で指定されている場合でも変換されません。server として動作する場合、つまりクライアントまたはその他のサービスが BUFTYPECONV パラメータを使用してサービスに要求を発行する場合にのみ変換されます。 BUFTYPECONV パラメータを使用しているサービスがクライアントとして動作している場合、変換は実行されません。たとえば、別のサービスに対して tpcall() を使用している BUFTYPECONV パラメータが指定されたサービスなどが挙げられます。/Q メッセージング モードでは、TMQFORWARD はサービスの呼び出しに tpcall() を使用します。呼び出されたサービスが BUFTYPECONV パラメータを使用している場合、自動変換が実行されます。
自動変換の際に、入力 XML ルート要素名を保存することはできないので、出力 XML ルート タグは、デフォルト ルート タグ <FML Type="FML"> または <FML Type="FML32"> を使用します。
XML データと FML/FML32 バッファ間の自動変換を実行するには、次の手順に従います。
Xerces パーサは、デフォルトの属性設定を使用して、自動変換時の XML 検証を制御します。ただし、Tuxedo では 14 個の固有の Xerces DOMParser クラス属性をサポートしており、これらを使用することで自動変換を多少柔軟にカスタマイズできます。
自動変換メソッドを使用している場合、パーサ検証は以下のいずれかの方法で決定されます。
TPXPARSFILE 環境変数で検証オプションを指定する
TPXPARSFILE 環境変数は、変更したい XercesDOMParser クラス属性設定を含むテキスト ファイルへの完全修飾パスを示します。
テキスト ファイルの各属性は、次の形式で別の行に記述されます。
<parser attribute>=<setting>
<parser attribute> には、次の表の 14 個のパーサ属性の一部または全部を指定できます。表内の属性に付けられた (D) はデフォルト設定を示します。
| 注意 : | これらの属性の詳細な説明については、Xerces パーサ 2.5.0 のドキュメントを参照してください。 |
以下のリストは、TPXPARSFILE 環境変数のサンプル入力プレーン テキスト ファイルです。
CacheGrammarFromParse=True
DoNameSpaces=True
DoSchema=True
ExternalSchemaLocation= http://www.xml.org/sch.xsd
ExitOnFirstFatalError=c:\xml\example.xsd
IncludeIgnorableWhiteSpace=True
LoadGrammar=
NoNamespaceSchemaLocation=
StandardUriConformant=True
UseCachedGrammarInParse=True
UseScanner=WF
ValidationConstraintFatal=True
ValidationScheme=Val_Auto
ValidationSchemaFullChecking=True
XML 形式と FML/FML32 フィールド間の関係では、XML 要素名は FML/FML32 フィールド名と同じですが、XML 値は対応するフィールド型をもとに解釈されます。
開始および終了タグは、フィールドの名前を使用します。属性は、必要に応じて FLD_FML32、FLD_MBSTRING と FLD_VIEW32 で提供されます。フィールド名と属性の大文字と小文字は区別されます。
フィールド値は文字列として読み取られ、以下のフィールド型に変換されます。
<FIELDNAME Attribute="Attribute Value"> FIELDVALUE </FIELDNAME>
FML/FML32 フィールド型は、次のように XML バッファ型にマッピングされます。
|
||||
FLD_FML32 フィールド名は、FML フィールド名に基づいて開始および終了タグでサポートされます。この XML 文書には、バッファに含まれるフィールドごとに <fieldname>value</fieldname> の複数の説明が含まれます。
|
||||
FLD_MBSTRING フィールド変換は、Encoding 属性、および FML32 フィールドを記述するためのフィールド データを使用します。この変換は、Fmbpack32 を使用した場合と同じです。次の条件に注意してください。
|
Tuxedo で提供されている Xerces 2.5.0 パーサを使用した XML データと FML/FML32 バッファ間の変換には、次の制限事項があります。
<FML Type="FML"> または <FML Type="FML32"> が使用されます。
中国語、日本語、韓国語、およびその他のアジア太平洋言語で必要とされるマルチバイトエンコード文字セットをサポートするために、Oracle Tuxedo には、マルチバイト文字のユーザ データを転送するための MBSTRING 型付きバッファが用意されています。中国語、日本語、韓国語、およびその他のアジア太平洋言語では、文字を表現するために複数バイトを使用するエンコード文字セットが使用されます。
MBSTRING 型付きバッファおよびマルチバイト文字エンコード機能を使用すると、Oracle Tuxedo システムは、プロセス間で MBSTRING バッファ (または FML32 バッファの FLD_MBSTRING フィールド) が転送されるときに、ユーザ データを別のエンコード表現に変換できます。次の図は、エンコード変換がどのように行われるかを例示しています。
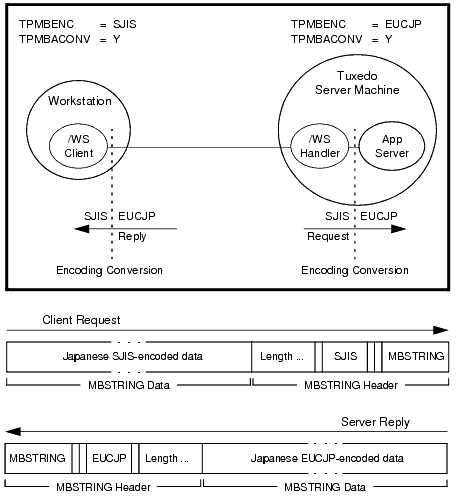
上図の例に示すように、MBSTRING 型付きバッファは、ユーザ データのコード セット文字エンコード (または単にエンコード) を識別する情報を保持できます。この例では、クライアントの要求の MBSTRING バッファは、Shift-JIS (SJIS) エンコードで表される日本語ユーザ データを保持し、サーバの応答の MBSTRING バッファは、Extended UNIX Code (EUC) エンコードで表される日本語ユーザ データを保持しています。マルチバイト文字エンコード機能では、環境変数 TPMBENC と TPMBACONV を読み込んで、ソースのエンコード、ターゲットのエンコード、および自動エンコード変換の状態 (有効または無効) を判別します。
エンコードの変換機能により、基底の Tuxedo システム ソフトウェアでは、着信メッセージのエンコード表現を、受信プロセスが実行されているマシンでサポートされているエンコード表現に変換できます。この変換は文字コード セット間の変換でも言語の翻訳でもなく、同じ言語の異なる文字エンコード間の変換です。
文字エンコード変換は、次の 2 とおりの方法で制御できます。
次の 2 つのフローチャートでは、MBSTRING バッファの割り当て、送信、受信、および変換時に環境変数および ATMI がどのように使用されるかを示します。
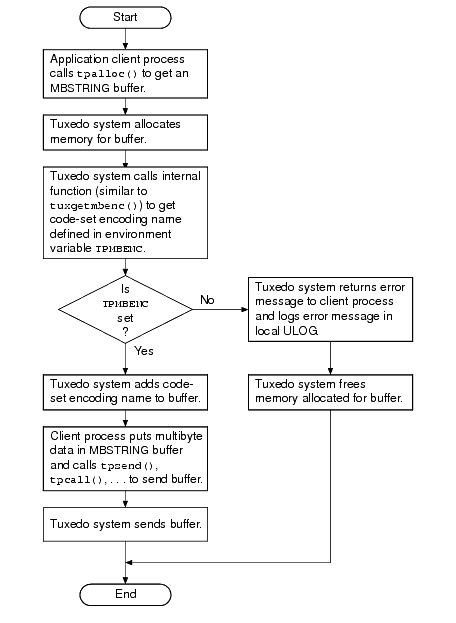
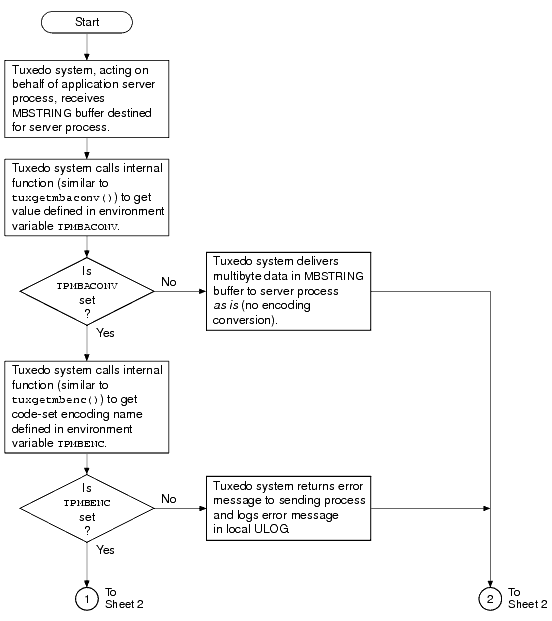
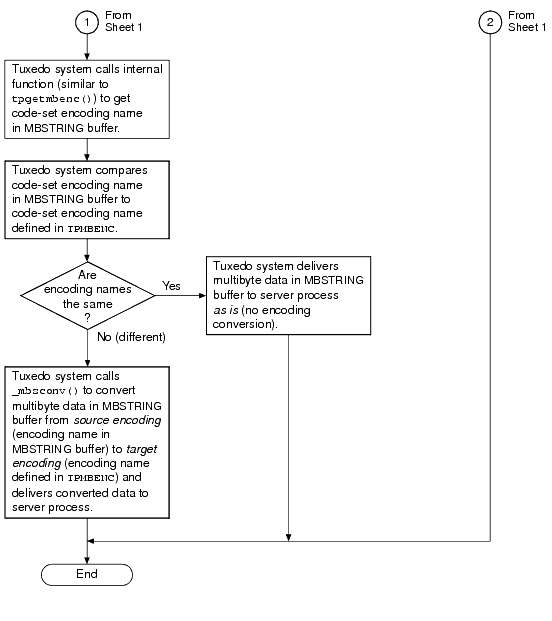
sendlen がゼロに設定されている場合、MBSTRING を自己記述型にすることができます。一部の Tuxedo バッファでは、ユーザがバッファの長さを指定していない場合、バッファが長さを自己決定できます。この自己記述型の動作は、アプリケーションが、Tuxedo 関数呼び出し (tpcall() など) の sendlen 引数をゼロに設定したときにトリガされます。
_mbspresend() を追加するには、Tuxedo バッファをカスタマイズするユーザがアプリケーションを再ビルドする必要があります。
TPMBENC で指定する安全または危険なエンコード名という考えは、これらのエンコードのマルチバイト文字データに NULL が埋め込まれているかどうかで決まります。_mbspresend() 関数は strlen() を使用してデータの長さを決めるので、NULL が埋め込まれていると、データの長さが不適切になり、誤ったデータ バイト数が送られてしまいます。
sendlen0_unsafe_tpmbenc のデフォルト リストには、NULL が埋め込まれている可能性がある (便宜上、大文字および小文字の) マルチバイト Unicode エンコード名があります。アプリケーション管理または性能が考慮すると、このリストを変更する必要があります。
MBSTRING 自己記述処理ですべてのエンコード名が安全なものと見なされます。MBSTRING 自己記述処理ですべてのエンコード名が危険なものと見なされます (tperrno は TPEINVAL になります)。_mbsinit() で) 一度読み取られ、Tuxedo の内部にリストが格納されます。mbsinit() の実行中に、格納されているリストと TPMBENC 名が比較され、バッファが安全または危険に設定されます。_mbspresend() が呼び出され (sendlen 引数がゼロに設定されている状態)、バッファが安全とマークされると、データの長さは Tuxedo の内部で設定されます。
Oracle Tuxedo のマルチバイト文字サポートには、以下の制限が存在します。
MBSTRING と FLD_MBSTRING をサポートする Tuxedo API に相当する COBOL API は存在しません。
Oracle Tuxedo 8.1 以降のソフトウェア配布キットには、多くのエンコード文字セットとエンコードをサポートするエンコード変換ライブラリ、GNU libiconv が付属しています。マルチバイト文字エンコードの機能では、このライブラリの文字変換関数を使用して、サポートされている任意の文字エンコードから別の文字エンコードに Unicode 変換を通じて変換できます。
マルチバイト文字エンコードの詳細については、次のマニュアルを参照してください。
Oracle Tuxedo システムで提供されるバッファ タイプでは、アプリケーションのニーズが満たされない場合があります。たとえば、アプリケーションがフラットではないデータ構造体、つまり SQL データベースの問い合わせのための解析ツリーなど、ほかのデータ構造体へのポインタを持つデータ構造を扱う場合があります。アプリケーション固有の要件に対応するために、Oracle Tuxedo システムではカスタム バッファがサポートされています。
バッファをカスタマイズするには、次の特性を理解しておきます。
次の表は、各バッファ タイプに指定する必要があるルーチンを示しています。特定のルーチンが必要ない場合は、NULL ポインタを指定します。必要に応じて、Oracle Tuxedo システムでデフォルトの処理が行われます。
領域の割り当てと解放、メッセージの送受信など、バッファを操作するコードを記述するのはアプリケーション プログラマです。デフォルトのバッファ タイプではアプリケーションのニーズを満たすことができない場合、ほかのバッファ タイプを定義し、新しいルーチンを記述してバッファ タイプ スイッチに組み込むことができます。
静的ライブラリが使用されるアプリケーションで、カスタム バッファ タイプ スイッチを使う場合は、カスタム サーバをビルドして、新しいタイプ スイッチにリンクする必要があります。詳細については、buildwsh(1)、TMQUEUE(5)、TMQFORWARD(5) を参照してください。
ここでは、前述の手順に従って、共有オブジェクトまたは DLL 環境で新しいバッファ タイプを定義します。その前に、Oracle Tuxedo システム ソフトウェアに提供されているバッファ スイッチを参照してみます。次のコード リストは、システムに提供されているスイッチです。
#include <stdio.h>
#include <tmtypes.h>
/*
* バッファ タイプ スイッチの初期化
*/
struct tmtype_sw_t tm_typesw[] = {
{
"CARRAY", /* type */
"*", /* subtype */
0 /* dfltsize */
NULL, /* initbuf */
NULL, /* reinitbuf */
NULL, /* uninitbuf */
NULL, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
NULL, /* encdec */
NULL, /* route */
NULL, /* filter */
NULL, /* format */
NULL, /* presend2 */
NULL /* マルチバイト コード セット エンコード変換 */
},
{
"STRING", /* type */
"*", /* subtype */
512, /* dfltsize */
NULL, /* initbuf */
NULL, /* reinitbuf */
NULL, /* uninitbuf */
_strpresend, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
_strencdec, /* encdec */
NULL, /* route */
_sfilter, /* filter */
_sformat, /* format */
NULL, /* presend2 */
NULL /* マルチバイト コード セット エンコード変換 */
},
{
"FML", /* type */
"*", /* subtype */
1024, /* dfltsize */
_finit, /* initbuf */
_freinit, /* reinitbuf */
_funinit, /* uninitbuf */
_fpresend, /* presend */
_fpostsend, /* postsend */
_fpostrecv, /* postrecv */
_fencdec, /* encdec */
_froute, /* route */
_ffilter, /* filter */
_fformat, /* format */
NULL, /* presend2 */
NULL /* マルチバイト コード セット エンコード変換 */
},
{
"VIEW", /* type */
"*", /* subtype */
1024, /* dfltsize */
_vinit, /* initbuf */
_vreinit, /* reinitbuf */
NULL, /* uninitbuf */
_vpresend, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
_vencdec, /* encdec */
_vroute, /* route */
_vfilter, /* filter */
_vformat, /* format */
NULL, /* presend2 */
NULL /* マルチバイト コード セット エンコード変換 */
},
{
/* XATMI - CARRAY と同じ */
"X_OCTET", /* type */
"*", /* subtype */
0 /* dfltsize */
},
{ /* XATMI - VIEW と同じ */
{'X','_','C','_','T','Y','P','E'}, /* type */
"*", /* subtype */
1024, /* dfltsize */
_vinit, /* initbuf */
_vreinit, /* reinitbuf */
NULL, /* uninitbuf */
_vpresend, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
_vencdec, /* encdec */
_vroute, /* route */
_vfilter, /* filter */
_vformat, /* format */
NULL, /* presend2 */
NULL /* マルチバイト コード セット エンコード変換 */
},
{
/* XATMI - VIEW と同じ */
{'X','_','C','O','M','M','O','N'}, /* type */
"*", /* subtype */
1024, /* dfltsize */
_vinit, /* initbuf */
_vreinit, /* reinitbuf */
NULL, /* uninitbuf */
_vpresend, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
_vencdec, /* encdec */
_vroute, /* route */
_vfilter, /* filter */
_vformat, /* format */
NULL, /* presend2 */
NULL /* マルチバイト コード セット エンコード変換 */
},
{
"FML32", /* type */
"*", /* subtype */
1024, /* dfltsize */
_finit32, /* initbuf */
_freinit32, /* reinitbuf */
_funinit32, /* uninitbuf */
_fpresend32, /* presend */
_fpostsend32, /* postsend */
_fpostrecv32, /* postrecv */
_fencdec32, /* encdec */
_froute32, /* route */
_ffilter32, /* filter */
_fformat32, /* format */
_fpresend232, /* presend2 */
_fmbconv32 /* マルチバイト コード セット エンコード変換 */
},
{
"VIEW32", /* type */
"*", /* subtype */
1024, /* dfltsize */
_vinit32, /* initbuf */
_vreinit32, /* reinitbuf */
NULL, /* uninitbuf */
_vpresend32, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
_vencdec32, /* encdec */
_vroute32, /* route */
_vfilter32, /* filter */
_vformat32, /* format */
NULL, /* presend2 */
_vmbconv32, /* マルチバイト コード セット エンコード変換 */
},
{
"XML", /* type */
"*", /* subtype */
0, /* dfltsize */
NULL, /* initbuf */
NULL, /* reinitbuf */
NULL, /* uninitbuf */
NULL, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
NULL, /* encdec */
_xroute, /* route */
NULL, /* filter */
NULL, /* format */
NULL, /* presend2 */
NULL /* マルチバイト コード セット エンコード変換 */
},
{
"MBSTRING", /* type */
"*", /* subtype */
0, /* dfltsize */
_mbsinit, /* initbuf */
NULL, /* reinitbuf */
NULL, /* uninitbuf */
_mbspresend, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
NULL, /* encdec */
NULL, /* route */
NULL, /* filter */
NULL, /* format */
NULL, /* presend2 */
_mbsconv /* マルチバイト コード セット エンコード変換 */
},
{
""
}
};struct tmtype_sw_t _TM_FAR *
_TMDLLENTRY
_tmtypeswaddr(void)
{
return(tm_typesw);
}
この例をよく理解できるように、次の例に示すバッファ タイプ構造体の宣言を参照してください。
/*
* 以下の定義は、$TUXDIR/include/tmtypes.h にあります。
*/
#define TMTYPELEN ED_TYPELEN
#define TMSTYPELEN ED_STYPELEN
struct tmtype_sw_t {
char type[TMTYPELEN]; /* バッファのタイプ */
char subtype[TMSTYPELEN]; /* バッファのサブタイプ */
long dfltsize; /* バッファのデフォルト サイズ */
/* バッファ初期化関数へのポインタ */
int (_TMDLLENTRY *initbuf) _((char _TM_FAR *, long));/* バッファ再初期化関数へのポインタ */
int (_TMDLLENTRY *reinitbuf) _((char _TM_FAR *, long));
/* バッファ非初期化関数へのポインタ */
int (_TMDLLENTRY *uninitbuf) _((char _TM_FAR *, long));
/* バッファ送信前処理関数へのポインタ */
long (_TMDLLENTRY *presend) _((char _TM_FAR *, long, long));
/* バッファ送信後処理関数へのポインタ */
void (_TMDLLENTRY *postsend) _((char _TM_FAR *, long, long));
/* バッファ受信後処理関数へのポインタ */
long (_TMDLLENTRY *postrecv) _((char _TM_FAR *, long, long));
/* XDR エンコード/デコード関数へのポインタ */
long (_TMDLLENTRY *encdec) _((int, char _TM_FAR *, long, char _TM_FAR *, long));
/* ルーティング関数へのポインタ */
int (_TMDLLENTRY *route) _((char _TM_FAR *, char _TM_FAR *, char _TM_FAR *,
long, char _TM_FAR *));
/* バッファ フィルタ処理関数へのポインタ */
int (_TMDLLENTRY *filter) _((char _TM_FAR *, long, char _TM_FAR *, long));
/* バッファ フォーマット処理関数へのポインタ */
int (_TMDLLENTRY *format) _((char _TM_FAR *, long, char _TM_FAR *,
char _TM_FAR *, long));
/* 送信前、おそらくコピー生成前のバッファの処理 */
long (_TMDLLENTRY *presend2) _((char _TM_FAR *, long,
long, char _TM_FAR *, long, long _TM_FAR *));
/* マルチバイト コード セットのエンコードの変換関数へのポインタ */
long (_TMDLLENTRY *mbconv) _((char _TM_FAR *, long,
char _TM_FAR *, char _TM_FAR *, long, long _TM_FAR *));
/* この領域は将来の拡張のために予約されています。 */
void (_TMDLLENTRY *reserved[8]) _((void));
};
/*
* アプリケーション バッファ タイプのスイッチ ポインタ
* テーブルへのアクセス時には常にこのポインタを使用します。
*/
extern struct tmtype_sw_t *tm_typeswp;
前述のデフォルト バッファ タイプ スイッチの例は、バッファ タイプ スイッチの初期化を示しています。9 つのデフォルト バッファ タイプの後に、サブタイプの名前を指定するフィールドがあります。VIEW (X_C_TYPE と X_COMMON) 型を除き、サブタイプは NULL です。VIEW のサブタイプは ``*'' として指定されています。これは、デフォルトの VIEW 型のサブタイプに制約がないことを示します。つまり、VIEW 型のすべてのサブタイプは同じ方法で処理されます。
次のフィールドには、バッファのデフォルト (最小) サイズが指定されています。CARRAY (X_OCTET) 型の場合、このフィールドに 0 が指定されています。これは、CARRAY 型バッファを使用するルーチンでは、CARRAY 型に必要な領域を tpalloc() で割り当てなければならないことを示します。
それ以外のバッファ タイプの場合、tpalloc() が呼び出されて、dfltsize フィールドに指定されている領域が Oracle Tuxedo システムによって割り当てられます。ただし、tpalloc() のサイズを示す引数にこれより大きな値が設定されていない場合に限ります。
バッファ タイプ スイッチのエントリで、残りの 8 つのフィールドには、スイッチ要素ルーチンの名前が指定されています。これらのルーチンの詳細については、『Oracle Tuxedo C リファレンス』の buffer(3c) を参照してください。ルーチン名からそのルーチンの処理内容がわかります。たとえば、FML 型の _fpresend は、送信前にバッファを操作するルーチンを指すポインタです。送信前処理が必要ない場合は、NULL ポインタを指定します。NULL は、特に処理が必要ないことを示し、その結果デフォルトの処理が行われます。詳細については、buffer(3c) を参照してください。
スイッチの最後に NULL エントリがあることに注目してください。変更時には、配列の終わりに必ず NULL エントリを置いてください。
アプリケーションで新しいバッファ タイプを定義するのは、特別な処理を行うためです。たとえば、アプリケーションで、次のプロセスにバッファを送信する前に、データ圧縮を何度か行うとします。このようなアプリケーションでは、送信前処理ルーチンを記述します。次のコード リストは、送信前処理ルーチンの宣言を示しています。
long
presend(ptr, dlen, mdlen)
char *ptr;
long dlen, mdlen;
送信前処理ルーチンで行うデータ圧縮は、アプリケーションのシステム プログラマが行います。
ルーチンの処理が正常に終了した場合、同じバッファ内にある圧縮後の送信データの長さが返されます。処理が失敗した場合は、-1 が返されます。
プログラマが記述した送信前処理ルーチンには、C コンパイラが使用できる任意の識別子を付けることができます。たとえば、_mypresend という名前を付けます。
_mypresend 圧縮ルーチンを使用する場合、受信側にはそのデータの圧縮を解除する _mypostrecv ルーチンが必要です。『Oracle Tuxedo C リファレンス』の buffer(3c) に示すテンプレートを使用してください。
新しいスイッチ要素ルーチンを記述し、そのコンパイルに成功したら、そのバッファ タイプ スイッチに新しいバッファ タイプを追加する必要があります。その場合、$TUXDIR/lib/tmtypesw.c をコピーします。これはデフォルトのバッファ タイプ スイッチのソース コードです。コピーしたファイル名に、mytypesw.c など、拡張子として .c を付けます。コピーしたファイルに新しいタイプを追加します。タイプ名は 8 文字以内で指定します。サブタイプには、NULL ("") または 16 文字以内の文字列を指定できます。新しいスイッチ要素ルーチンの名前は、extern 宣言も含めて適切な場所に入力します。次の例は、バッファ スイッチに新しいタイプを追加しています。
#include <stdio.h>
#include <tmtypes.h>
/* カスタマイズしたバッファ タイプ スイッチ */
static struct tmtype_sw_t tm_typesw[] = {
{
"SOUND", /* type */
“", /* subtype */
50000, /* dfltsize */
snd_init, /* initbuf */
snd_init, /* reinitbuf */
NULL, /* uninitbuf */
snd_cmprs, /* presend */
snd_uncmprs, /* postsend */
snd_uncmprs /* postrecv */
},
{
"FML", /* type */
"", /* subtype */
1024, /* dfltsize */
_finit, /* initbuf */
_freinit, /* reinitbuf */
_funinit, /* uninitbuf */
_fpresend, /* presend */
_fpostsend, /* postsend */
_fpostrecv, /* postrecv */
_fencdec, /* encdec */
_froute, /* route */
_ffilter, /* filter */
_fformat /* format */
},
{
""
}
};
この例では、SOUND という新しいタイプを追加しています。また、VIEW、X_OCTET、X_COMMON、および X_C_TYPE のエントリを削除して、デフォルト スイッチで不要なエントリを削除できることを示しています。配列の最後に NULL があることに注目してください。
新しいバッファ タイプを定義する別の方法は、既存のタイプを再定義することです。バッファ タイプ MYTYPE に定義したデータ圧縮が文字列に対して実行されたとします。その場合、STRING 型の 2 つの _dfltblen の代わりに、新しいスイッチ要素ルーチン _mypresend と _mypostrecv を使用できます。
インストールを簡単に行うには、バッファ タイプ スイッチを共有オブジェクトに格納します。
| 注意 : | 一部のプラットフォームでは、「共有オブジェクト」ではなく「共有ライブラリ」という言葉が使用されています。Windows 2003 プラットフォームでは、「共有オブジェクト」ではなく「動的リンク ライブラリ」と呼ばれています。この 3 つの用語が示す機能は同じなので、ここでは「共有オブジェクト」を使用します。 |
ここでは、アプリケーション内のすべての Oracle Tuxedo プロセスに、変更後のバッファ タイプ スイッチを認識させる方法について説明します。これらのプロセスには、Oracle Tuxedo システムで提供されるサーバとユーティリティのほかに、アプリケーション サーバおよびアプリケーション クライアントも含まれています。
$TUXDIR/lib/tmtypesw.c をコピーして変更します。関数を追加する場合は、それらの関数を tmtypesw.c に記述するか、別の C ソース ファイルに記述します。tmtypesw.c をコンパイルします。libbuft.so.71 をカレント ディレクトリから別のディレクトリにコピーします。コピー先のディレクトリとしては、アプリケーションが libbuft.so.71 を認識でき、Oracle Tuxedo システムで提供されるデフォルトの共有オブジェクトより先に libbuft.so.71 が処理されるディレクトリを選択します。$APPDIR または $TUXDIR/lib ディレクトリ、または $TUXDIR/bin (Windows 2003 プラットフォームの場合) のいずれかを使用することをお勧めします。
オペレーティング システムの規則に従うために、プラットフォームが異なる場合は、バッファ タイプ スイッチ共有オブジェクトには異なる名前が使用されます。
共有オブジェクト ライブラリのビルド方法については、お使いのプラットフォームのソフトウェア開発マニュアルを参照してください。
別の方法として、すべてのクライアント プロセスとサーバ プロセスで新しいバッファ タイプ スイッチを静的にリンクすることもできます。ただし、この方法ではエラーが発生しやすくなり、効率も共有オブジェクト ライブラリをビルドするより劣ります。
「新しい tm_typesw のコンパイルとリンク」で説明したように、Windows プラットフォーム上で tmtypesw.c を変更した場合、次のコード リストに示すコマンドを使用して、変更後のバッファ タイプ スイッチをアプリケーションから使用できるようにします。
CL -AL -I..\e\|sysinclu -I..\e\|include -Aw -G2swx -Zp -D_TM_WIN
-D_TMDLL -Od -c TMTYPESW.C
LINK /CO /ALIGN:16 TMTYPESW.OBJ, WBUFT.DLL, NUL, WTUXWS /SE:250 /NOD
/NOE LIBW LDLLCEW, WBUFT.DEF
RC /30 /T /K WBUFT.DLL
コンフィグレーション ファイルの MACHINES セクションにある TYPE パラメータは、データ表現と使用するコンパイラが同じであるマシンをグループ化して、TYPE が異なるマシン間でやり取りされるメッセージのデータが変換されるようにします。デフォルトのバッファ タイプの場合、異なるマシン間でのデータ変換はユーザ、管理者、プログラマに対して透過的です。
アプリケーションで新しいバッファ タイプを定義して、データ表現スキーマが異なるマシン間でメッセージを交換する場合、新しいエンコード/デコード ルーチンを記述して、バッファ タイプ スイッチに組み込む必要があります。独自のデータ変換ルーチンを記述する場合は、次のガイドラインに従ってください。
_tmencdec ルーチンのセマンティクスを使用します。つまり、同じ引数を使用し、処理が成功した場合や失敗した場合に _tmencdec と同じ値が返されるようにルーチンをコーディングします。新しいバッファ タイプを定義する場合は、「独自のバッファ タイプの定義」の手順に従って、新しいバッファ タイプを使用するサービスを提供するサーバをビルドします。
エンコード/デコード ルーチンが呼び出されるのは、データをやり取りする 2 つのマシンの TYPE が異なることが Oracle Tuxedo システムによって検出された場合だけです。
 
|