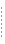

|
|
この章では、BEA AquaLogic Data Services Platform でデータ サービスのキャッシングを設定および管理する方法について説明します。
| 注意 : | キャッシングが使用できるのは、それが許可されているデータ サービス関数に対してのみです。 詳細については、『データ サービス開発者ガイド』の「データ サービスの設計」の「関数のキャッシング」を参照してください。 |
キャッシングは、アド ホック クエリまたは XQuery セキュリティ関数では使用できません。
データ サービス関数によって返されたデータをキャッシングすると、クライアントへの応答時間を短縮し、バックエンド システムに対する処理負荷を低減できます。
| 注意 : | 結果キャッシングを使用するには、AquaLogic Data Services Platform キャッシングのサポートが確認されているデータベースがインストールされており、実行中であることが必要です。 そのような DBMS システムは、AquaLogic Data Services Platform の『リリース ノート』の「サポート対象のコンフィグレーション」において特定されています。 |
初めてデータ サービス関数が実行された際にデザイン ビュー (『データ サービス開発者ガイド』の「データ サービスの設計」における「関数のキャッシング」を参照) を通じて関数のキャッシングが認可されると、AquaLogic Data Services Platform は結果をローカルのクエリ結果キャッシュに保存します。 次に同じ関数が同じパラメータで実行されると、AquaLogic Data Services Platform はキャッシュのコンフィグレーションをチェックし、結果が期限切れになっていなければ、結果を外部ソースからではなく、キャッシュから取得します。
キャッシュ エントリは、それぞれ異なったパラメータによる関数呼び出しの結果ごとに存在します。 キャッシュが有効になった関数が、2 つの異なったパラメータで 2 回、呼び出された場合は、2 つのキャッシュ エントリが作成されます。
デフォルトでは、キャッシングは無効になっています。 有効化されると、個々のデータ サービス関数について、キャッシュおよびそのキャッシュの生存時間 (TTL) をコンフィグレーションできます。 キャッシングと関連付けられたコンフィグレーション タスクには、次のものがあります。
各データ サービス関数について、TTL 設定は個別に指定されます。 一般に、基底のデータの変更頻度が高ければ高いほど、キャッシュの期限切れの頻度も高くする必要があります。 場合によっては、キャッシングをまったく使用すべきでないこともあります。 以下に、例を 2 つ挙げます。
Liquid Data Server が停止した場合でも、結果キャッシュの内容は保持されます。 サーバが再起動すると、Liquid Data Server はそれまでと同じようにキャッシングを再開します。 キャッシュの有効化された関数が最初に呼び出されると、Liquid Data Server は結果キャッシュをチェックして、その関数のキャッシュ結果が有効か期限切れかを調べ、それに応じて処理を続行します。
AquaLogic Data Services Platform では、クライアント アプリケーションが物理データ ソースを優先して任意の既存キャッシュ結果を回避することを可能とする API を提供しています。 この API により、影響を受けた関数について、クライアント サイドでキャッシュの更新が自動的に行われます。 詳細については、『アプリケーション開発者ガイド』における、キャッシュされたデータの回避に関する次の説明を参照してください。
| 注意 : | 大きなデータ セットに対して重大な処理が適用され、フィルタ処理された結果が生成される場合、キャッシングは特に効果的です。 最適なパフォーマンスを得るには、単にリレーショナル データベースのデータ ソースから直接大きなデータ セットを返すだけの関数に対しては、キャッシングを有効にしないことをお勧めします。 |
AquaLogic Data Services Platform では、データ ソース内に自動的にキャッシュ テーブルを設定 (サーバが開発モードの場合) することも、以下の節で説明するように自分で作成することもできます。 AquaLogic Data Services Platform アプリケーションでは、キャッシュ テーブルの共有を行わないことをお勧めします。 各アプリケーションについて、別個のテーブルが必要です。
| 注意 : | AquaLogic Data Services Platform キャッシュには、機密性の高いデータが格納されている場合があるため、認可されたユーザのみがアクセスできるように、キャッシュ データベースに対しアクセス制御を維持することが重要です。 また、キャッシュに使用される JDBC データ ソースを、その他の目的には使用しないことをお勧めします。 |
キャッシュを設定する手順は、開発モードなのかプロダクション モードなのか、キャッシュ テーブル スキーマをカスタマイズする必要があるのかどうかなど、いくつかの要因によって変わります。図 7-1 に、キャッシングの設定手順を示します。
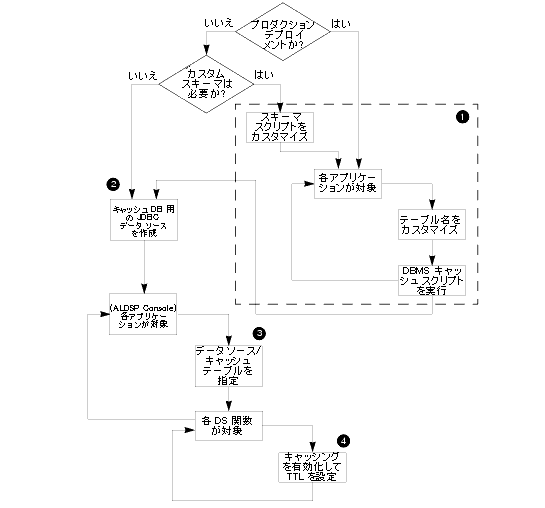
図 7-1 に示した手順については、以下の節で説明します。
開発モードの WebLogic サーバの場合、AquaLogic Data Services Platform では、任意に選択したデータ ソースを使用して AquaLogic Data Services Console から自動的にキャッシュ テーブルを設定できます。 プロダクション環境の場合、またはキャッシュ スキーマをカスタマイズする場合は、手動で SQL スクリプトを実行する必要があります。
次の場所にある、特定の DBMS に対応するサブディレクトリ内の SQL スクリプトを使用して、キャッシュ テーブルを作成できます。
<WebLogicHome>/liquiddata/dbscripts/
<WebLogicHome>/liquiddata/dbscripts/oracle/ld_cache.sql
各アプリケーションにおいて、キャッシュされたデータは独自のキャッシュ テーブルに保持することをお勧めします。 たとえば、テーブルを <appname>_CACHE という名前にできます。
カラム名、またはスキーマ テーブルの構造は、変更しないでください (「キャッシュ テーブルの構造を変更する」に示すような特別な場合を除く)。 キャッシュ テーブル スキーマについては、表 7-1 を参照してください。
テーブルが (「手順 3 : キャッシュ データ ソースとキャッシュ テーブルの指定」で説明するように) AquaLogic Data Services Platform によって自動的に作成されると、CHASH のインデックスが作成されます。 自動作成される名前は、テーブル名に「_INDEX」を付加したものとなります。
| 注意 : | DB2 では、この名前は最大 18 文字までで切り捨てられます。 |
AquaLogic Data Services Platform では、キャッシュ テーブルに特定のスキーマを必要とします。 したがって通常は、キャッシュ テーブルの構造は変更しないでください。 しかし場合によっては、デプロイメントに基づき、デフォルトのカラム サイズの調整が必要となることがあります。 これが必要となる状況としては、デフォルトのデータベース テーブルのコンテンツ カラムより大きい結果セットを頻繁に処理するデータ サービスがあり、DBMS として DB2 または Pointbase を使用しているという場合が考えられます。
DB2 および Pointbase の場合、表 7-1 に示すように、スクリプトは特定サイズの CINVKEY カラムおよび CCONTENT カラム (結果データを格納) を作成します。 シリアライズされたキーまたはコンテンツを、そのサイズより大きくする必要がある場合、スクリプトを実行する前に、それに応じてテーブル スキーマを調整する必要があります。
キャッシュ テーブルに対するカスタマイズの実施を試みる前に、表 7-1 に示すスキーマをよく理解しておくことが必要です。
キャッシュ テーブル作成後、WebLogic Administration Console を使用して、AquaLogic Data Services Platform キャッシュ用に設定したデータベースを参照する JDBC データ ソースを WebLogic Server 上で作成できます。
| 注意 : | キャッシュ データベースとして Oracle を使用する場合、[グローバル トランザクションを受け付ける] を FALSE に設定する必要があります (デフォルトは TRUE)。 WebLogic Administration Console で Oracle JDBC データ ソースを作成する場合、[グローバル トランザクションを受け付ける] ボックスのチェックをはずす必要があります。 |
作成が済んだら、次の節の説明に従って結果キャッシュを有効化します。
WebLogic Administration Console で JDBC データ ソースとしてキャッシングに使用するテーブルをコンフィグレーション後は、AquaLogic Data Services Console を使用してキャッシュ テーブルを設定できます。
キャッシュ データベースを指定してキャッシングを有効化するには、次の手順に従います。
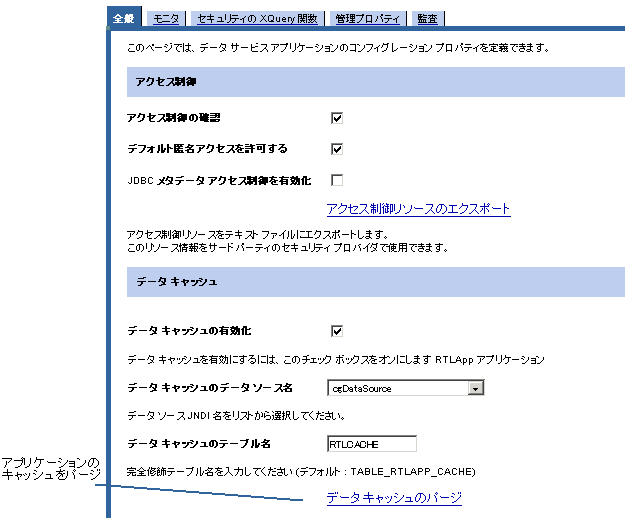
図 7-2 に示すように、[全般] タブが表示されます。
キャッシュ テーブルを作成しなかった場合は、AquaLogic Data Services Platform でキャッシュ テーブルを作成するデータ ソースを選択します。
別の手順としては、AquaLogic Data Services Platform で、テーブル作成時に使用する別の名前を入力するか、またはフィールドを空白のままにしておきます。空白にした場合は、デフォルト名 <appName>_CACHE が使用されます。
キャッシングが有効化されたら、各関数に関する結果キャッシングのコンフィグレーションを行う必要があります。
アプリケーションのためのキャッシュ設定を有効化したら、データ サービス関数のキャッシングをコンフィグレーションできます。 各関数について、キャッシングを有効にするかどうかを指定し、キャッシュ エントリの生存時間 (秒) を設定できます。
関数によりキャッシングを有効化するには、次の手順に従います。
図 7-3 に示すように、[データ キャッシュ] ページが表示されます。
基底のデータの変更頻度が高ければ高いほど、キャッシュの期限切れの頻度も高くする必要があります。
キャッシュのパージを行うと、キャッシュ データベースからキャッシュされたエントリが削除されます。 キャッシュがパージされると、そのデータ ソースに対する各関数が実行され、再びキャッシュされます。 AquaLogic Data Services Platform は、以下のいずれかのイベントが発生した場合、指定されたストアド クエリの結果キャッシュをフラッシュします。
AquaLogic Data Services Platform は、以下のいずれかのイベントが発生した場合、次の呼び出し時に関数の結果キャッシュをフラッシュします。
手動で、アプリケーション全体に対して一度に、または個々の関数について、キャッシュをパージすることもできます。 この節の内容は以下のとおりです。
[全般] アプリケーション設定ページを使用して、アプリケーションのキャッシュをパージできます。 アプリケーションのキャッシュをパージするには、次の手順に従います。
図 7-4 に示すように、[全般] アプリケーション設定ページが表示されます。
キャッシュをパージする前に、コンソールから確認を求められます。
図 7-5 に示すように、[データ キャッシュ] ページを使用して個々の関数のキャッシュをパージできます。
 
|