| Oracle Rdb SQLリファレンス・マニュアル リリース7.2 E06178-01 |
|


 戻る |
 次へ |
条件では、SQLでTRUE、FALSEまたはUNKNOWNを評価するための条件が指定されます。条件は条件式とも呼ばれます。複数の異なるタイプの条件を様々な条件演算子を使用して指定できます。次のような条件タイプがあります。
文字値式を比較するときに、自動変換が有効になっていない場合は、これらの値式のキャラクタ・セットが同じである必要があります。
一部の条件は、DEC Multinational Character Set(MCS)とともに使用すると特定の動作をします。この動作については、後述の項で説明します。
次のリストは、条件に適用される各国語キャラクタ・セットの動作を示しています。
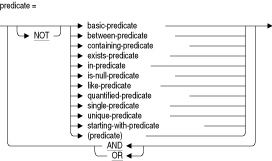
表2-29は、様々な条件演算子のSQLでの評価の概要を示しています。
| 比較 演算子 |
条件 |
|---|---|
| = | 2つの値式が等しい場合にTRUE。 |
| <> | 2つの値式が等しくない場合にTRUE。 |
| ^= | 2つの値式が等しくない場合にTRUE。 |
| != | 2つの値式が等しくない場合にTRUE。この基本条件は、ORACLE LEVEL1またはORACLE LEVEL2の言語を設定している場合にのみ使用可能。 |
| < | 最初の値式が2番目の値式よりも小さい場合にTRUE。 |
| <= | 最初の値式が2番目の値式よりも小さいか等しい場合にTRUE。 |
| > | 最初の値式が2番目の値式よりも大きい場合にTRUE。 |
| >= | 最初の値式が2番目の値式よりも大きいか等しい場合にTRUE。 |
| ALL | 指定した関係が、列選択式によって指定された結果表のすべての行(単一列幅のみである必要がある)に該当する場合にTRUE。結果表が空の場合もTRUE。ALLは限定条件タイプ。 |
| ANY (SOME) | 指定した関係が、列選択式によって指定された結果表の少なくとも1行(単一列幅のみである必要がある)に該当する場合にTRUE。ANYは限定条件タイプ。(SOMEはANYと同じ。これらのキーワードはシノニム。) |
| BETWEEN | 最初の値式が2番目の値式よりも大きく、3番目の値式よりも小さいか、2番目と3番目のいずれかの値式と等しい場合にTRUE。 |
| NOT BETWEEN | 最初の値式が2番目の値式よりも大きくなく、3番目の値式よりも小さくなく、2番目と3番目のいずれの値式とも等しくない場合にTRUE。 |
| CONTAINING | 2番目の値式によって指定された文字列が、最初の値式によって指定された文字列内にある場合にTRUE。大/小文字は区別されない。 |
| NOT CONTAINING | 2番目の値式によって指定された文字列が、最初の値式によって指定された文字列内にない場合にTRUE。大/小文字は区別されない。 |
| EXISTS | 列選択式によって指定された結果表内の行数がゼロでない場合にのみTRUE。 |
| NOT EXISTS | 列選択式によって指定された結果表内の行数がゼロの場合にTRUE。 |
| IN | 左側の値式が、右側の値式(列選択式を含む)のリストによって指定されたいずれかの値と等しい場合にTRUE。 |
| NOT IN | 左側の値式が、右側の値式または列選択式のリストによって指定されたいずれの値とも等しくない場合にTRUE。 |
| IS NULL | 値式がNULLの場合にTRUE。 |
| IS NOT NULL | 値式がNULLでない場合にTRUE。 |
| LIKE | 最初の式が2番目の値式のパターンと一致する場合にTRUE。LIKEでは次の特殊文字を使用する。
|
| NOT LIKE | 最初の式が2番目の値式のパターンと一致しない場合にTRUE。 |
| SINGLE | 列選択式によって指定された結果表に1行のみ含まれる場合にTRUE。 |
| NOT SINGLE | 列選択式によって指定された結果表に複数の行が含まれるか、行が含まれない場合にTRUE。 |
| STARTING WITH | 最初の値式の最初の文字が、2番目の値式で指定された文字と一致する場合にTRUE。大/小文字が区別される。 |
| NOT STARTING WITH | 最初の値式の最初の文字が、2番目の値式で指定された文字と一致しない場合にTRUE。大/小文字が区別される。 |
| UNIQUE | 列選択式の結果表内に重複行が存在しない場合にTRUE。 |
| NOT UNIQUE | 列選択式の結果表内に重複行が存在する場合にTRUE。 |
IS NULL演算子、EXISTS演算子およびSINGLE演算子を除き、条件内のいずれかのオペランドがNULLの場合、条件の値はUNKNOWNになります。 比較条件内のいずれのオペランドに対しても、LIST OF BYTE VARYINGデータ型の値は使用できません。詳細は、第2.3.7項を参照してください。 DEC_MCSまたはASCIIキャラクタ・セットを使用する場合、SQLではASCII照合順番に応じて文字列リテラルが比較されます。したがって、小文字が大文字よりも大きい値を持ち、アルファベットの先頭に近い文字は最後に近い文字よりも小さい値を持つとみなされます。
|
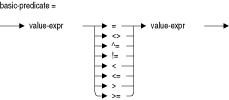
値式の詳細は、第2.6節を参照してください。
例: SELECT文での基本条件の使用
次のSELECT文では、列選択式を含む基本条件を使用して、平均よりも多い給与の従業員を検索します。
SQL> SELECT DISTINCT EMPLOYEE_ID FROM SALARY_HISTORY cont> WHERE SALARY_AMOUNT > cont> (SELECT AVG(SALARY_AMOUNT) cont> FROM SALARY_HISTORY); EMPLOYEE_ID 00164 00168 . . . |
この例では、条件は次の部分です。
SALARY AMOUNT > (SELECT AVG(SALARY_AMOUNT) FROM SALARY_HISTORY) |
不等比較では、<>基本条件のみでなく^=および!=も使用できます。ただし、!=は、ORACLE LEVEL1言語を設定している場合にのみ使用できます。1言語設定の詳細は、「SET DIALECT文」を参照してください。
2.7.2 BETWEEN条件
BETWEEN条件では、値の範囲を指定して値が比較されます。
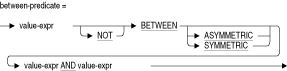
値式の詳細は、第2.6節を参照してください。
デフォルトはASYMMETRICです。
BETWEEN条件は、他の条件演算子を使用して表すことが可能な条件を、より簡単な方法で表す条件です。
value1 BETWEEN value2 AND value3 |
BETWEEN条件の使用は、次の複合条件の使用と同じです。
value1 >= value2 AND value1 <= value3 |
ASYMMETRIC
デフォルトでは、BETWEEN条件は値の順序によって異なります。つまり、最初の値式は2番目の値式よりも小さいか等しい必要があり、V0 => V1およびV0 <= V2と等しいと評価されます。次に例を示します。
SQL> select a from t where a between asymmetric 2 and 4;
A
2
3
4
3 rows selected
|
次の問合せでは、値式の順序が正しくないため、一致なしが返されます。
SQL> select a from t where a between asymmetric 4 and 2; 0 rows selected |
SYMMETRIC
これはBETWEENの代替形式であり、順序付けられていない値式の比較を簡単に行うことができます。次に示す例では同じ結果が返されます。この比較は、(V0 => V1 and V0 <= V2)または(V0 => V2 and V0 <= V1)に相当します。
次に例を示します。
SQL> select a from t where a between symmetric 2 and 4;
A
2
3
4
3 rows selected
SQL> select a from t where a between symmetric 4 and 2;
A
2
3
4
3 rows selected
|
NOT BETWEEN演算も、SYMMETRICを使用すると変更されます。
ASYMMETRICを使用する最初の問合せでは、指定範囲内にないすべての値が返されます。
SQL> select a from t where a not between asymmetric 2 and 4;
A
1
5
2 rows selected
|
次の問合せでは、範囲値の順序が正しくなく、BETWEEN条件では一致に関して空のセットが返されるため、NOT BETWEENでは例の表内のすべての行が返されます。
SQL> select a from t where a not between asymmetric 4 and 2;
A
1
2
3
4
5
5 rows selected
|
一方、SYMMETRICでは、次のようにいずれの順序の値に対しても同じ値セットが返されます。
SQL> select a from t where a not between symmetric 2 and 4;
A
1
5
2 rows selected
SQL> select a from t where a not between symmetric 4 and 2;
A
1
5
2 rows selected
|
例: 文字列を使用したBETWEEN条件の使用
次の例では、BETWEEN条件を使用して、名前が文字Bで始まる従業員の名前を検索します。
SQL> SELECT LAST_NAME cont> FROM EMPLOYEES cont> WHERE LAST_NAME cont> BETWEEN 'B' AND 'C'; LAST_NAME Babbin Bartlett Bartlett Belliveau Blount Boyd Boyd Brown Burton 9 rows selected |
この例では、姓が文字Bで始まる従業員以外の名前が取得される場合があります。姓がCで始まる従業員が、この結果に含まれる可能性があります。このような従業員を除外するには、次のBETWEEN条件を使用します。
BETWEEN 'B' AND 'Bzzzzzz'. |
複合条件を使用すると、ブール演算子AND、ORおよびNOTを使用して任意の数の条件を結合できます。ブール演算子は、論理演算子とも呼ばれます。

条件をネストする場合は、条件をカッコで囲む必要があります。SQLでは、複合条件の各条件が次の順序で評価されます。
表2-30、表2-31および表2-32は、ブール演算子で結合された条件のSQLでの評価の概要を示しています。このような表は、多くの場合、真理値表と呼ばれます。
| A | B | A AND B |
|---|---|---|
| TRUE | FALSE | FALSE |
| TRUE | TRUE | TRUE |
| FALSE | FALSE | FALSE |
| FALSE | TRUE | FALSE |
| TRUE | UNKNOWN | UNKNOWN |
| FALSE | UNKNOWN | FALSE |
| UNKNOWN | TRUE | UNKNOWN |
| UNKNOWN | FALSE | FALSE |
| UNKNOWN | UNKNOWN | UNKNOWN |
| A | B | A OR B |
|---|---|---|
| TRUE | FALSE | TRUE |
| TRUE | TRUE | TRUE |
| FALSE | FALSE | FALSE |
| FALSE | TRUE | TRUE |
| TRUE | UNKNOWN | TRUE |
| FALSE | UNKNOWN | UNKNOWN |
| UNKNOWN | TRUE | TRUE |
| UNKNOWN | FALSE | UNKNOWN |
| UNKNOWN | UNKNOWN | UNKNOWN |
| A | NOT A |
|---|---|
| TRUE | FALSE |
| FALSE | TRUE |
| UNKNOWN | UNKNOWN |
AがUNKNOWNの場合にNOT AがUNKNOWNと評価されると、NULL値を持つ表を参照する問合せでは混乱を招きます。これは、NOT条件は、NOTが付かない同じ条件がFALSEと評価される列のすべての行に対して、必ずしもTRUEと評価されないことを意味します。つまり、NOT Aを含む問合せの結果は、Aのみを含む同じ問合せの結果を必ずしも補完するわけではありません。 |
CONTAINING条件では、2番目の値式で指定された文字列式が、最初の値式で指定された文字列式内に含まれているかどうかがテストされます。
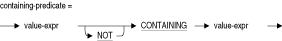
CONTAINING条件では、大/小文字は区別されません。
CONTAINING条件では、DEC Multinational Character Setで使用される発音区別符号が区別されます。したがって、aはAと一致しますが、á、à、ä、Á、À、Âなどとは一致しません。
スペイン語では、chとllは一意の単一の文字と同様に処理されます。
照合順番を使用している場合、CONTAINING条件では、DEC Multinational Character Setで使用される発音区別符号が区別されません。
例: CONTAINING条件の使用
SQL> -- Note that CONTAINING is not case sensitive. SQL> -- Although 'TOL' is typed in all uppercase letters, SQL> -- SQL still returns Toliver, which is SQL> -- in uppercase and lowercase letters. SQL> -- SQL> SELECT E.LAST_NAME FROM EMPLOYEES E WHERE cont> E.LAST_NAME CONTAINING 'TOL'; LAST_NAME Toliver 1 row selected |
EXISTS条件では、列選択式で指定された結果表が空であるかどうかがテストされます。
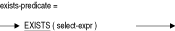
選択式で指定された結果表に1つ以上の行がある場合、SQLではEXISTS条件がTRUEに評価されます。行がない場合、EXISTS条件はFALSEになります。EXISTS条件がUNKNOWNになることはありません。
EXISTS条件では、行の存在のみが検証されるため、列選択式の結果表が単一列幅である必要はありません(列選択式の詳細は、第2.8.2項を参照)。EXISTS条件では、列選択式内のアスタリスク(*)・ワイルドカードによって複数列の表を参照できます(次の例を参照)。
例: EXISTS条件の使用
次の例は、EXISTS条件を示しています。この例は、= ANY条件を使用して大学の学位を持つ従業員を検索し、NOT (= ANY)条件を使用して大学の学位を持たない従業員の名前を検索する第2.7.9項の例2に類似しています。
SQL> SELECT E.LAST_NAME, E.EMPLOYEE_ID
cont> FROM EMPLOYEES E
cont> WHERE EXISTS
cont> -- Notice that the column select expression uses a wildcard,
cont> -- which is valid for multicolumn tables only in EXISTS
cont> -- predicates:
cont> (SELECT *
cont> FROM DEGREES D
cont> WHERE D.EMPLOYEE_ID =
cont> E.EMPLOYEE_ID);
LAST_NAME EMPLOYEE_ID
Toliver 00164
Smith 00165
Dietrich 00166
. .
. .
. .
Blount 00418
MacDonald 00435
Herbener 00471
99 rows selected
|
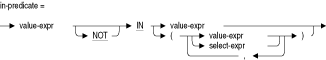
値式の詳細は、第2.6節を参照してください。列選択式の詳細は、第2.8.2項を参照してください。
IN条件のすべての形式は、他の条件演算子を使用して表すことができます。
value-expr IN (value-expr) |
これは、次の基本条件と同義です。
value-expr = value-expr |
(右側の値式が、複数のパラメータに拡張するホスト構造体でない場合)
value-expr = value-expr1 OR value-expr = value-expr2 OR value-expr = value-expr3 |
(この場合、右側の値式はいずれも、複数のパラメータに拡張するホスト構造体である可能性があります。)
value-expr = ANY (col-select-expr1) OR value-expr = val-expr2 OR value-expr = ANY (col-select-expr3) |
(この場合、右側の値式はいずれも、複数のパラメータに拡張するホスト構造体である可能性があります。)
例: 値式のリストを使用したIN条件の使用
次の例では、値式のリスト(この場合は文字列リテラル)とともにIN条件を使用して、New Englandに住む従業員の数を検索します。
SQL> SELECT COUNT(*)
cont> FROM EMPLOYEES
cont> WHERE STATE IN
cont> ('CT', 'RI', 'MA', 'VT', 'NH', 'ME');
100
1 row selected
|
1 他の言語では、!はコメント文字とみなされるためです。 |
