| Oracle Rdb SQLリファレンス・マニュアル リリース7.2 E06178-01 |
|


 戻る |
 次へ |
2.3.3 DECIMALデータ型およびNUMERICデータ型
SQLでは、パック10進数データ型(DECIMAL)および符号付き数値データ型(NUMERIC)が限定的にサポートされています。
SQL> CREATE TABLE T (C DECIMAL(3)); %SQL-I-NO_DECIMAL, C is being converted from DECIMAL to SMALLINT. |
SQLで変換されるデータ型のリストを次に示します。
SQL> INSERT INTO T (C) VALUE (9999); %RDB-E-VALOUTRANGE, value outside the specified precision (3) for column "C" |
Oracle Rdbでは、Oracleサーバーとの互換性を維持するためにNUMBERデータ型がサポートされていますが、これらのデータ型には相違点があります。Oracleサーバーでは、最大38桁までの精度がサポートされ、スケールは-84〜127に制限されています。一方、Oracle Rdbリリース7.1でサポートされている精度は18桁、スケールは-128〜127です。
NUMBERデータ型には、次の特徴があります。
p <= 2の場合、TINYINTにマップされます。
2 < p <= 4の場合、SMALLINTにマップされます。
4 < p <= 9の場合、INTEGERにマップされます。
9 < p <= 18の場合、BIGINTにマップされます。
p > 18の場合、DOUBLE PRECISIONにマップされます。
SQLでは、TINYINT、SMALLINT、INTEGERおよびBIGINTの4種類の固定小数点数データ型が提供されています。この4種類すべてに対して、符号なし整数(n)を任意に指定できます。この整数は、小数部の桁数を示すスケール変更係数です。
スケール変更係数は、0〜127の範囲の整数である必要があります。nを指定しない場合は、0(小数部分なし)がデフォルトとして使用されます。
SQLでは、次の3種類の浮動小数点数データ型が提供されています。
2.3.7 LIST OF BYTE VARYINGデータ型
LIST OF BYTE VARYINGデータ型は、セグメント化された内部構造を使用したラージ・データ・オブジェクトの処理用に設計されています。LIST OF BYTE VARYINGデータ型は、次のデータ型と同等です。
通常、LIST OF BYTE VARYINGデータ型のオブジェクトは、リストとして参照されます。リストとは、データ・セグメントの連結リストのことであり、各セグメントは異なるページに格納されています。
リストの例は、サンプルの人事データベースのRESUMES表で確認できます。RESUMES表には、RESUMEというLIST列およびEMPLOYEE_IDというCHARACTER列の2つの列が含まれています。図2-2は、RESUMES表の概念図を示しています。
図2-2 LIST列を持つ表

リストには、大量のテキスト、データ収集デバイスからバイナリ入力された長い文字列、図形データなど、構造化されていないデータを格納できます。どのようなデータ型でも、リストに格納し、またリストから取得できます。データは、構造化されていないバイトで格納されます。たとえば、リストに文字データを格納し、これを16進数データとして解釈できます。Oracle Rdbでは、セグメントの長さを除き、リストに含まれているデータの型は認識されません。
リスト内のセグメント数に制限はありません。
ページに格納されている各セグメントは、ワード・オフセットおよびワードの長さを使用する、行索引構造によって参照されます。このページ構造により、セグメントのサイズが符号なしの65,535バイトに制限されます。
符号なし整数(n)を使用して、LIST OF BYTE VARYINGデータ型の列のオクテット数(バイト数)を指定します。nを省略すると、SQLでは1オクテットの列が作成されます。連鎖リスト形式におけるnの最大サイズは、最初のセグメントでは65,508、それ以降のセグメントではそれぞれ65,522です。索引リスト形式におけるnの最大サイズは、オーバーヘッドのための5バイトを残した65,530です。リストの連鎖形式および索引形式の詳細は、第2.3.7.1項を参照してください。
リスト・セグメントのユーザー・データ部分は、BYTE VARYINGデータ型のフィールドです。BYTE VARYINGデータ型は、符号なし8ビット・バイトの文字列です。BYTE VARYINGデータ型は、今後の使用のために予約されていますが、現時点では、リスト・セグメント内でのみ有効です。
リストは表の行内に格納されるため、リストを作成するにはCREATE TABLE文を使用する必要があります。実際には、セグメント化された文字列識別子がLIST OF BYTE VARYINGデータ型の列に格納されます。セグメント化された文字列識別子とは、プライマリ・リスト・セグメントの位置を指定する数値のことです。索引リスト形式では、セグメント化された文字列識別子は最初のポインタ・セグメントを指し示します。連鎖リスト形式では、セグメント化された文字列識別子は最初のリスト・セグメントを指し示します。リスト自体ではなくリスト表を指し示すポインタを格納するため、リストはOracle Rdbの表サイズの制限による制約を受けません。リストを含む表を作成する例は、「CREATE TABLE文」を参照してください。
リストの使用方法の詳細は、「DECLARE CURSOR文」を参照してください。他の表情報に基づいた、異なる記憶域へのリストの格納の詳細は、「CREATE STORAGE MAP文」を参照してください。
LIST OF BYTE VARYINGデータ型では、サブタイプとしてBINARYおよびTEXTがサポートされています。これらのサブタイプを使用して、LIST OF BYTE VARYINGデータ型内に含まれるデータを指定します。サブタイプTEXTは、データ型に印刷可能文字が保持されることを示します。サブタイプBINARYは、データ型に16進数表記で表される、RAWバイナリ・データが保持されることを示します。
2.3.7.1 リストのディスク上の形式
Oracle Rdbでは、リストに対して次の3種類のディスク上の形式を使用できます。
最初の連鎖形式では、リストはセグメントの連鎖リストになっています。最初のセグメントには2番目のセグメントを指すポインタ、2番目のセグメントには3番目のセグメントを指すポインタ、というように順にポインタが格納されます。最後のセグメントにはNULLポインタが格納されます。
各セグメントには、ユーザー・データ用の65,522バイト以外に、次のセグメントを指す8バイトのデータベース・キー(dbkey)が格納されます。
最初のセグメントには、セグメント化された文字列を記述する、次のような14バイトのオーバーヘッドが含まれます。
このオーバーヘッドのため、最初のセグメントに保持できるユーザー・データは65,508バイトまでになります。
最初のセグメントに保持されるこれらの情報は、リスト・カーソルをオープンするときにSQLを使用すると、SQLCA構造体で返されます。図2-3は、連鎖リスト形式を示しています。
図2-3 連鎖リスト形式
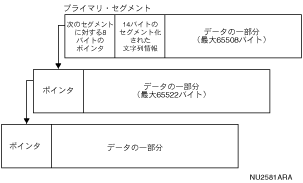
この連鎖リスト形式の最初のセグメントには、すべてのセグメントがディスクに書き込まれるまで有効にならない情報が保持されます。この形式は、その性質上更新が必要となります。この問題を解決するため、索引リスト形式が開発されました。
索引リスト形式では、次のセグメントを指し示すポインタはデータ・セグメントに含まれません。かわりに、ポインタはポインタ・セグメントと呼ばれる専用のセグメントに保持されます。ポインタ・セグメントには、データ・セグメントを指し示すポインタのみが格納されます。図2-4は、索引リスト形式の構造を示しています。
図2-4 索引リスト形式
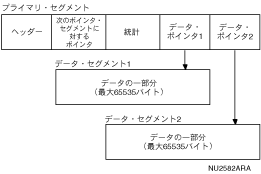
ポインタ・セグメントを使用すると、Oracle Rdbでデータ・セグメントへの書込みが可能になります。これは後で修正する必要はありません。ポインタ・セグメントのサイズは、記憶域のページ上の空き領域によって設定されます。ページにデータ・セグメントを格納する空き領域がなくなると、ポインタは新しいポインタ・セグメントに連鎖されます。この形式では、バッファ・サイズと大規模なページ・サイズを組み合せ、実質的なページ修正の必要性を削減できます。
索引リスト形式は、Oracle Rdbによって作成されるすべてのリストのデフォルトです。
デフォルトとして連鎖リスト形式を保持するには、論理名RDMS$USE_OLD_SEGMENTED_STRINGを定義する必要があります。
$ DEFINE RDMS$USE_OLD_SEGMENTED_STRING YES |
この論理名が定義されると、アプリケーションでは、すべての読取り/書込みメディアへの書込みは、連鎖リスト形式になります。
後で新しい索引リスト形式を使用する場合は、論理名RDMS$USE_OLD_SEGMENTED_STRINGの設定を解除する必要があります。
同一表内で連鎖リスト形式と索引リスト形式を混在させることができます。ただし、連鎖リスト形式を索引リスト形式に変換する必要がある場合があります。たとえば、スクロール可能リスト・カーソルでFETCH LAST文を実行する場合は、形式を変換することをお薦めします。連鎖リスト形式でFETCH LAST文を使用すると、Oracle Rdbでは、目的のセグメントに到達するまですべてのセグメントを読み取りますが、これは最適な方法ではありません。索引リスト形式でFETCH LAST文を使用すると、Oracle Rdbでは、ポインタ・セグメントおよび最後のデータ・セグメントのみを読み取ります。
連鎖リスト形式でFETCH LAST文が実行されないようにするには、論理名RDMS$SET_FLAGSを定義するか、またはSET FLAGSにNOSCROLL_EMULATIONを指定して使用します。この論理名を定義して、連鎖リスト形式でSCROLLリスト・カーソルをオープンしようとすると、OPEN CURSOR文が失敗します。
サンプル・ディレクトリにあるサンプル・プログラムsql_convert_lists.scで、連鎖リスト形式を索引リスト形式に変換するプロセスの実例を確認できます。
また、データ量がセグメント化された文字列のバッファに収まる場合、リストを単一セグメントに書式設定することもできます。単一セグメント・リストは、論理名RDMS$BIND_SEGMENTED_STRING_BUFFERで制御されます。
単一セグメント・リストは、プライマリ・セグメントおよびデータ・セグメントの区別に使用されるフィールドで構成されています。これにより、ポインタおよびその他のオーバーヘッドが省略されるため、ディスク・ストレージを節約できます。セグメントの読取りでは、I/Oは1回のみです。単一セグメント・リストを利用する場合は、論理名RDMS$USE_OLD_SEGMENTED_STRINGを定義しないでください。
2.3.8 データ型の変換
値をSQLからホスト言語パラメータに、またはホスト言語パラメータからSQLに代入する場合、2レベルのデータ型変換を実行できます。
サポートされているデータ型間のデータ変換規則の詳細は、第2.3.8.2項を参照してください。
Oracle Rdbでは、整数値およびテキスト値の比較の際に頻出する問題を回避するため、アプリケーション・プログラムでCASTファンクションを使用して、データを明示的に、一環した比較可能な形式に変換することをお薦めします。 |
SQLプリコンパイラまたはモジュール言語プロセッサでサポートされているデータベース、および様々なホスト言語では、必ずしも同じデータ型セットはサポートされていません。SQLでは、データベース間、および異なる言語間におけるこの非互換性に対して、次の方法のいずれかで対処します。
プリコンパイラのサポート対象の言語について、SQLで相互に変換されるホスト言語宣言の詳細は、第4.4節を参照してください。SQLモジュールで宣言されたパラメータと互換性のあるホスト言語宣言を示す表は、第3.5節を参照してください。このようなホスト言語パラメータ宣言は、SQLモジュール・ファイル内の対応する仮パラメータ宣言に正確に対応している必要があります。対応していない場合は、実行時に予期しない結果が生じる可能性があります。動的SQLにおけるプログラムおよびデータベースのデータ型の変換の詳細は、付録Dを参照してください。
SQLプリコンパイラを使用するホスト言語では、DATEデータ型はサポートされません。SQLでは、DATE、TIME、TIMESTAMPまたはINTERVALの値は、表4-3〜表4-10に示すホスト言語データ型の値には変換されません。かわりに、DATE、TIME、TIMESTAMPまたはINTERVALの列に格納されている64ビットの値が、これらの表に示す宣言済のパラメータに代入されます。 値がパラメータに格納されると、プログラムではLIB$FORMAT_DATE_TIMEランタイム・ライブラリ・ルーチンにより、この64ビット値がDATE、TIME、TIMESTAMPおよびINTERVALの各データ型に対するASCII文字列に変換されます。 |
通常、SQLでは、サポートされているデータ型間で値を代入できます。このような代入では、基底データベース・システムにより、ソース列またはソース・パラメータのデータ型から、ターゲット列またはターゲット・パラメータのデータ型に変換されます。
LIST OF BYTE VARYINGデータ型の変換はサポートされていません。ただし、使用している言語でCHARまたはVARCHARの各データ型がサポートされている場合は、LIST OF BYTE VARYINGデータ型の要素をCHARまたはVARCHARに変換できます。
データ型の異なるデータ間の変換は、次のルールに従います。
SQL> -- Oracle Rdb supports another internal format for
SQL> -- DATE VMS. This format is similar to the TIMESTAMP format
SQL> -- except that the punctuation is omitted. This example assigns
SQL> -- the CHAR column (A) to the DATE VMS (G) column and then
SQL> -- displays the result. In an application, the CHAR column could
SQL> -- be a CHAR host variable or module language parameter.
SQL> --
SQL> INSERT INTO DATE_TEST (G) VALUE ('1957020100000000');
1 row inserted
SQL> UPDATE DATE_TEST
cont> SET A=G
cont> WHERE G IS NOT NULL;
1 row updated
SQL> SELECT A, G
cont> FROM DATE_TEST
cont> WHERE G IS NOT NULL;
A G
1-FEB-1957 00:00:00.00 1957020100000000
1 row selected
SQL> ROLLBACK;
|
| 文字列 | 意味 |
|---|---|
| yyyy | 1857〜9999の間の4桁の年 |
| nn | 1月〜9月では先行ゼロを含む、01〜12の間の2桁の月 |
| dd | 右詰めで先行ゼロを含む、01〜31の間の2桁の日 |
| hh | 右詰めで先行ゼロを含む、00〜23の間の24時間表示の2桁の時間 |
| mm | 右詰めで先行ゼロを含む、00〜59の間の2桁の分 |
| ss | 右詰めで先行ゼロを含む、00〜59の間の2桁の秒 |
| cc | 右詰めで先行ゼロを含む、00〜99の間の2桁の秒の小数 |
