| Oracle Rdb SQLリファレンス・マニュアル リリース7.2 E06178-01 |
|


 戻る |
 次へ |
SQL> CREATE TABLE COLOURS
cont> (ENGLISH MCS_DOM,
cont> FRENCH MCS_DOM,
cont> JAPANESE KANJI_DOM,
cont> ROMAJI DEC_KANJI_DOM,
cont> KATAKANA KATAKANA_DOM,
cont> HINDI HINDI_DOM,
cont> GREEK GREEK_DOM,
cont> ARABIC ARABIC_DOM,
cont> RUSSIAN RUSSIAN_DOM);
SQL> SHOW TABLE (COLUMNS) COLOURS;
Information for table COLOURS
Columns for table COLOURS:
Column Name Data Type Domain
----------- --------- ------
ENGLISH CHAR(8) MCS_DOM
DEC_MCS 8 Characters, 8 Octets
FRENCH CHAR(8) MCS_DOM
DEC_MCS 8 Characters, 8 Octets
JAPANESE CHAR(8) KANJI_DOM
KANJI 4 Characters, 8 Octets
ROMAJI CHAR(16) DEC_KANJI_DOM
KATAKANA CHAR(8) KATAKANA_DOM
KATAKANA 8 Characters, 8 Octets
HINDI CHAR(8) HINDI_DOM
DEVANAGARI 8 Characters, 8 Octets
GREEK CHAR(8) GREEK_DOM
ISOLATINGREEK 8 Characters, 8 Octets
ARABIC CHAR(8) ARABIC_DOM
ISOLATINARABIC 8 Characters, 8 Octets
RUSSIAN CHAR(8) RUSSIAN_DOM
ISOLATINCYRILLIC 8 Characters, 8 Octets
|
例13: グローバル一時表の作成および使用
データが移入されているPAYROLLと呼ばれる実表があり、今週の情報を抽出して会社の給与小切手を生成する必要があるとします。次の例は、PAYCHECKS_GLOBと呼ばれるグローバル一時表を生成し、この表にPAYROLL実表およびEMPLOYEES実表のデータを移入する方法を示しています。PAYCHECKS_GLOBのデータにより、各従業員の控除額と支給額が計算されます。これにより、実表に対する連続的な問合せが解消され、同時実行による競合が軽減されます。
SQL> CREATE GLOBAL TEMPORARY TABLE PAYCHECKS_GLOB cont> (EMPLOYEE_ID ID_DOM, cont> LAST_NAME CHAR(14), cont> HOURS_WORKED INTEGER, cont> HOURLY_SAL INTEGER(2), cont> WEEKLY_PAY INTEGER(2)) cont> ON COMMIT PRESERVE ROWS; SQL> -- SQL> -- Insert data into the temporary tables from other existing tables. SQL> INSERT INTO PAYCHECKS_GLOB cont> (EMPLOYEE_ID, LAST_NAME, HOURS_WORKED, HOURLY_SAL, WEEKLY_PAY) cont> SELECT P.EMPLOYEE_ID, E.LAST_NAME, P.HOURS_WORKED, P.HOURLY_SAL, cont> P.HOURS_WORKED * P.HOURLY_SAL cont> FROM EMPLOYEES E, PAYROLL P cont> WHERE E.EMPLOYEE_ID = P.EMPLOYEE_ID cont> AND P.WEEK_DATE = DATE '1995-08-01'; 100 rows inserted SQL> -- SQL> -- Display the data. SQL> SELECT * FROM PAYCHECKS_GLOB LIMIT TO 2 ROWS; EMPLOYEE_ID LAST_NAME HOURS_WORKED HOURLY_SAL WEEKLY_PAY 00165 Smith 40 30.50 1220.00 00166 Dietrich 40 36.00 1440.00 2 rows selected SQL> -- Commit the data. SQL> COMMIT; SQL> -- SQL> -- Because the global temporary table was created with PRESERVE ROWS, SQL> -- the data is preserved after you commit the transaction. SQL> SELECT * FROM PAYCHECKS_GLOB LIMIT TO 2 ROWS; EMPLOYEE_ID LAST_NAME HOURS_WORKED HOURLY_SAL WEEKLY_PAY 00165 Smith 40 30.50 1220.00 00166 Dietrich 40 36.00 1440.00 2 rows selected |
例14: 表の作成時における制約の有効化および無効化
PRIMARY KEY制約により、列Aの一意性はすでに有効にされています。この例では、別のUNIQUE制約を無効にし、制限の記述はそのまま残し、実行時の評価は行われないようにしています。
SQL> SET DIALECT 'SQL99'; SQL> CREATE TABLE TT cont> (A INTEGER CONSTRAINT A1 UNIQUE, cont> CONSTRAINT A2 UNIQUE (A), cont> CONSTRAINT A3 PRIMARY KEY (A)) cont> ENABLE CONSTRAINT A1 cont> DISABLE CONSTRAINT A2; |
例15: AUTOMATIC列の使用
この例では、AUTOMATIC列を使用してINSERTおよびUPDATE中に列値を入力します。
トランザクションの現在のタイムスタンプを格納し、順序番号に対して一意の数値を提供すると仮定します。さらに、行が更新(順序が変更)される場合は、LAST_UPDATED列に新規のタイムスタンプを書き込みます。この情報を提供するようにアプリケーションを記述できますが、目的の動作は保証されない可能性があります。たとえば、表にアクセスするユーザーが、対話型SQLによって表を更新しても、LAST_UPDATED列に新規のタイムスタンプの入力を忘れることも考えられます。このような場合、AUTOMATIC列をかわりに使用すると、挿入操作時に列にデータが自動的に入力されるよう定義できます。データは他の列と同じようにソートされますが、この列は読取り専用です。
SQL> CREATE TABLE ORDER_HEADER cont> (ORDER_NUMBER AUTOMATIC INSERT AS NEW_ORDER.NEXTVAL, cont> ORDER_DATE AUTOMATIC INSERT AS CURRENT_TIMESTAMP, cont> LAST_UPDATED AUTOMATIC UPDATE AS CURRENT_TIMESTAMP cont> DEFAULT NULL, cont> CUSTOMER_NUMBER INTEGER, cont> ORDER_TOTAL MONEY CHECK (ORDER_TOTAL >= 0.0)); |
例16: 新旧のUNIQUE制約のSHOW TABLE出力
SQL> -- This first example is a UNIQUE constraint created when
SQL> -- the default dialect is used (SQLV40). A new description
SQL> -- follows the "Unique constraint" text, explaining the
SQL> -- interpretation of null values.
SQL> SHOW TABLE (CONSTRAINT) T_UNIQUE
Information for table T_UNIQUE
Table constraints for T_UNIQUE:
T_UNIQUE_UNIQUE_B_A
Unique constraint
Null values are considered the same
Table constraint for T_UNIQUE
Evaluated on UPDATE, NOT DEFERRABLE
Source:
UNIQUE (b,a)
.
.
.
SQL> -- This second example is a UNIQUE constraint created
SQL> -- when the dialect was set to 'SQL92', and the description
SQL> -- here indicates that all null values are considered
SQL> -- distinct.
SQL> SHOW TABLE (CONSTRAINT) T_UNIQUE2;
Information for table T_UNIQUE2
Table constraints for T_UNIQUE2:
T_UNIQUE2_UNIQUE_B_A
Unique constraint
Null values are considered distinct
Table constraint for T_UNIQUE2
Evaluated on UPDATE, NOT DEFERRABLE
Source: UNIQUE (b,a)
.
.
.
|
例17: IDENTITY属性の使用
この簡易化された注文入力データベースでは、すべての表でIDENTITYを使用して表の主キー・フィールドに対して一意の値を生成しています。
SQL> set dialect 'SQL99';
SQL> create domain MONEY as INTEGER (2);
SQL> create domain CUSTOMER_ID as INTEGER;
SQL> create domain PRODUCT_ID as INTEGER;
SQL> create domain ORDER_ID as INTEGER;
SQL> create domain LINE_NUMBER as INTEGER
cont> check (VALUE > 0 and VALUE IS NOT NULL)
cont> not deferrable;
SQL>
SQL> create table PRODUCTS
cont> (product_id PRODUCT_ID identity primary key,
cont> product_name char (100),
cont> unit_price MONEY,
cont> unit_name char (10)
cont> );
SQL> create unique index PRODUCTS_IX on PRODUCTS (product_id);
SQL>
SQL> create table CUSTOMERS
cont> (customer_id CUSTOMER_ID identity (1,1) primary key,
cont> customer_name char (100)
cont> );
SQL> create unique index CUSTOMERS_IX on CUSTOMERS (customer_id);
SQL>
SQL> create table ORDERS
cont> (order_id ORDER_ID identity (1000) primary key,
cont> order_date timestamp,
cont> customer_id CUSTOMER_ID references CUSTOMERS
cont> );
SQL> create unique index ORDERS_IX on ORDERS (order_id);
SQL>
SQL> create table ORDER_LINES
cont> (order_id ORDER_ID references ORDERS,
cont> line_number LINE_NUMBER,
cont> product_id PRODUCT_ID references PRODUCTS,
cont> quantity integer,
cont> discount float
cont> );
SQL> create unique index ORDER_LINES_IX on ORDER_LINES (order_id, line_number);
SQL>
SQL> show sequences
Sequences in database with filename SAMPLE
CUSTOMERS An identity column sequence.
ORDERS An identity column sequence.
PRODUCTS An identity column sequence.
SQL> show sequences ORDERS
ORDERS
Sequence Id: 3
An identity column sequence.
Initial Value: 1000
Minimum Value: 1000
Maximum Value: (none)
Next Sequence Value: 1000
Increment by: 1
Cache Size: 20
No Order
No Cycle
No Randomize
Wait
Comment: column IDENTITY sequence
SQL> commit;
|
この例では、START WITH値は明示的に1000に設定されていますが、INCREMENT BY値は1にデフォルト設定されています。
例18: IDENTITY順序のすべての属性のデフォルト設定
SQL> set dialect 'sql99';
SQL> create table PRODUCTS
cont> (product_id PRODUCT_ID identity primary key,
cont> ...);
SQL> show sequence PRODUCTS;
PRODUCTS
Sequence Id: 1
An identity column sequence.
Initial Value: 1
Minimum Value: 1
Maximum Value: (none)
Next Sequence Value: 1
Increment by: 1
Cache Size: 20
No Order
No Cycle
No Randomize
Wait
Comment: column IDENTITY sequence
|
この例では、順序のSTART WITH値とINCREMENT BY値は両方とも1にデフォルト設定されています。
例19: 予約されているために削除できないIDENTITY順序
SQL> drop sequence ORDERS; %RDB-E-NO_META_UPDATE, metadata update failed -RDMS-E-NOMETSYSREL, operation illegal on system defined metadata -RDMS-E-SEQNOTDEL, sequence "ORDERS" has not been deleted |
例20: 既存の表へのIDENTITY列の追加
新規表を使用して、従業員が退職した後のEMPLOYEES詳細を記録します。退職日を記録するためにRETIRED_DATE列を別途追加し、従業員がEMPLOYEES表と新規RETIRED_EMPLOYEES表の両方にリストされないように新規CHECK制約を追加します。
SQL> set dialect 'sql99'; SQL> SQL> create table RETIRED_EMPLOYEES cont> like EMPLOYEES cont> (retired_date DATE_DOM cont> ,primary key (EMPLOYEE_ID) cont> ,check (not exists cont> (select * from EMPLOYEES e cont> where e.employee_id = RETIRED_EMPLOYEES.employee_id)) cont> initially deferred cont> ); SQL> SQL> show table RETIRED_EMPLOYEES; Information for table RETIRED_EMPLOYEES Columns for table RETIRED_EMPLOYEES: Column Name Data Type Domain ----------- --------- ------ EMPLOYEE_ID CHAR(5) ID_DOM LAST_NAME CHAR(14) LAST_NAME_DOM FIRST_NAME CHAR(10) FIRST_NAME_DOM MIDDLE_INITIAL CHAR(1) MIDDLE_INITIAL_DOM ADDRESS_DATA_1 CHAR(25) ADDRESS_DATA_1_DOM ADDRESS_DATA_2 CHAR(20) ADDRESS_DATA_2_DOM CITY CHAR(20) CITY_DOM STATE CHAR(2) STATE_DOM POSTAL_CODE CHAR(5) POSTAL_CODE_DOM SEX CHAR(1) SEX_DOM BIRTHDAY DATE VMS DATE_DOM STATUS_CODE CHAR(1) STATUS_CODE_DOM RETIRED_DATE DATE VMS DATE_DOM Table constraints for RETIRED_EMPLOYEES: RETIRED_EMPLOYEES_CHECK1 Check constraint Table constraint for RETIRED_EMPLOYEES Evaluated on COMMIT Source: CHECK (not exists (select * from EMPLOYEES e where e.employee_id = RETIRED_EMPLOYEES.employee_id)) RETIRED_EMPLOYEES_PRIMARY1 Primary Key constraint Table constraint for RETIRED_EMPLOYEES Evaluated on UPDATE, NOT DEFERRABLE Source: PRIMARY key (EMPLOYEE_ID) Constraints referencing table RETIRED_EMPLOYEES: No constraints found Indexes on table RETIRED_EMPLOYEES: No indexes found Storage Map for table RETIRED_EMPLOYEES: No Storage Map found Triggers on table RETIRED_EMPLOYEES: No triggers found SQL> |
指定した表のトリガーを作成します。トリガーにより、(INSERT文、DELETE文またはUPDATE文などの書込み操作による)表の更新の前後に行われるアクションを定義します。トリガーは、単一表に関連付けられ、特定のタイミングで特定タイプの更新に作用し、1つ以上のトリガー・アクションを実行します。トリガーに複数のアクションが指定されている場合、各アクションは、トリガー定義に記述されている順序で実行されます。トリガーを使用すると、次のような便利なアクションを定義できます。
- カスケード削除
1つの表内の行を削除すると、キー値によって最初の表に関連付けられている他の表の行も削除されます。- カスケード更新
1つの表内の行を更新すると、キー値によって最初の表に関連付けられている他の表の行も更新されます。通常、これらの更新はキー・フィールド自体に限定されています。- 加算更新
1つの表内の行を更新すると、別の表内の行の値が増減し、更新されます。- 非表示削除
表内の行をパラレル表に移動することによって削除します。このパラレル表は、これ以外にデータベースでは使用されません。
注意
表固有の制約と適切に定義されたトリガーの組合せのみでは、データベース更新時のデータベースの整合性の維持に十分ではありません。整合性を維持するには、表固有の制約とトリガーとともに、完全に再現可能で一貫した検索および更新計画を実現するための更新プロシージャの共通セットを使用する必要があります。
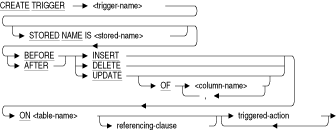
CREATE TRIGGER文により、物理データベースにトリガー定義が追加されます。
トリガー・アクションは、1つのオプション条件と複数のトリガー文で構成されます。指定された場合、アクションのトリガー文を実行するには、この条件がTRUEと評価される必要があります。各トリガー文は、トリガー・アクション句に記述されている順序で実行されます。
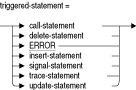
トリガー文には、次のタイプがあります。
CREATE TRIGGER文は次の環境で使用できます。
- 対話型SQL内
- プリコンパイル対象のホスト言語プログラムに埋め込まれる場合
- SQLモジュールのプロシージャの一部として
- 動的SQLで動的に実行される文として
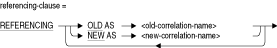
call-statement
起動するストアド・プロシージャを指定します。コールできるのは、INパラメータのあるプロシージャのみです。トリガー表に対する操作は、潜在的な副作用や再帰的コールのために許可されていません。column-name
指定した表内における削除、変更または挿入対象の列名です。この引数は、UPDATEトリガーでのみ使用します。delete-statement
削除する表の行を指定します。DELETE文のWHERE句でCURRENT OFカーソル名を指定すると、CREATE TRIGGER文ではカーソルが見えないため、エラー・メッセージが表示されます。ERROR
次のメッセージを表示します。
RDMS-E-TRIG_ERROR, Trigger 'trigger_name' forced an error.
トリガーされたERROR文により、トリガーを起動したDELETE、UPDATEまたはINSERT文が取り消されます。
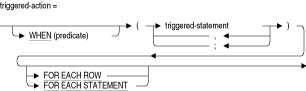
FOR EACH ROW
FOR EACH STATEMENT
トリガー・アクションをトリガー文ごとに1回評価するか、トリガー文の影響を受けるサブジェクト表の行ごとに評価するかを指定します。FOR EACH STATEMENTを指定する場合、トリガー・アクションは1回のみ評価され、トリガー・アクションでは行値を使用できません。
FOR EACH STATEMENT句はデフォルトで設定されます。
insert-statement
表に追加する1つ以上の新規行を指定します。old-correlation-name
UPDATE操作が行われる前に存在した行値を参照するために使用する一時名です。FOR EACH ROW句を指定しない場合、この相関名はトリガー文で参照できません。new-correlation-name
UPDATE操作によって適用される新規行値を参照するために使用する一時名です。FOR EACH ROW句を指定しない場合、この相関名はトリガー文で参照できません。referencing-clause
UPDATE操作が行われる前に存在した行値、またはUPDATE操作によって適用された後の新規行値のどちらを参照するかを指定できます。この句はINSERTまたはDELETE操作では使用しないでください。いずれのオプション(OLD AS old-correlation-nameまたはNEW AS new-correlation-name)とも参照句で1回のみ指定できます。
signal-statement
送信されたSQLSTATEステータス・パラメータをアプリケーションまたはSQLインタフェースに戻し、現行ルーチンおよびすべてのコール側ルーチンを終了するように指定します。これは、ERROR句よりも完全なエラー・メカニズムです。STORED NAME IS stored-name
マルチスキーマ・データベースに作成したトリガーへのアクセスに使用する名前を指定します。ストアド名を使用すると、Oracle Rdb管理ユーティリティであるOracle RMUなどのインタフェースを使用して、マルチスキーマ定義にアクセスできます。このユーティリティでは、1つのデータベース内で複数のスキーマを認識しません。マルチスキーマに対応しないデータベース内では、トリガーのストアド名は指定できません。ストアド名の詳細は、第2.2.18項を参照してください。table-name
このトリガーが定義されている表の名前です。trace-statement
トレース・ロギングがアクティブであるときに情報を記録するトリガーを追加できるようにします。triggered-action
1つのオプション条件、複数のトリガー文、およびオプションの頻度句で構成されています。指定し場合、トリガー・アクション句のトリガー文を実行するには、この条件がTRUEと評価される必要があります。各トリガー文は、トリガー・アクション句に記述されている順序で実行されます。triggered-statement
データベースを更新するか、エラーメッセージを生成します。update-statement
変更する表の行を指定します。UPDATE文のWHERE句でCURRENT OF cursor-nameを指定すると、CREATE TRIGGER文ではカーソルが見えないため、エラー・メッセージが表示されます。WHEN (predicate)
関連するトリガー文が実行される前に満たす必要のあるオプションの条件を記述します。この条件では、ホスト言語変数は参照できません。列と外部ファンクション・コールアウトの間のあいまいさを回避するために、WHEN句の条件は丸カッコで囲みます。詳細は、「使用方法」を参照してください。
- パス名でデータベースにアタッチしなかった場合、トリガー定義はリポジトリに格納されません。これにより、データベース内の定義とリポジトリ内の定義の間の整合性がなくなります。このため、INTEGRATE文を使用してリポジトリからデータベース・メタデータをリストアする場合は、常にトリガーを再定義する必要があります。
- トリガーを作成するには、サブジェクト表に対するSELECTおよびCREATEアクセスが必要です。また、トリガー文によっていずれかの形式の更新操作を指定する場合は、SELECT、DBCTRL以外に、トリガー・アクション文で指定する表に適したタイプの更新(DELETE、UPDATE、INSERT)アクセスも必要です。
- トリガー指定には、アクション時間、更新イベント(データベースに対するある種の書込み操作)、およびオプションの列リストが含まれます。これらの組合せにより、トリガーがいつ評価されるかが決まります。アクション時間は、更新イベント(INSERT文、DELETE文またはUPDATE文)の前後どちらに指定してもかまいません。UPDATE文で評価されるトリガーについては、(サブジェクト表から)オプションの列リストを指定することにより、リストされる列の1つがUPDATE文のSET列リストにも含まれる場合のみ、トリガーを評価するように指定することもできます。トリガーは、リストされる列内の値がUPDATE文の実行時に実際に変更されるかどうかとは関係なく評価されます。
- NEWコンテキスト値とOLDコンテキスト値の両方を使用してWHEN条件に適切な条件を設定すると、更新時に実際の列値が変更されなかった場合にトリガー・アクションが実行されないようにできます。
- 頻度句FOR EACH ROWにより、トリガー・アクションをトリガー文ごとに1回評価するか、トリガー文の影響を受けるサブジェクト表の行ごとに評価するかを決定します。FOR EACH ROWを指定しない場合、トリガー・アクションは1回のみ評価され、トリガー・アクションでは行値を使用できません。
- 表相関名(現行相関名)、旧相関名および新規相関名は、トリガー文のサブジェクト表コンテキストの様々な状態に使用します。旧相関名はAFTER UPDATEトリガーでのみ使用可能(有効)であり、新規相関名はBEFORE UPDATEトリガーでのみ使用可能(有効)です。
- 定義されているトリガーにより、更新時間およびタイプに指定されているトリガーとの競合や、変更する列のリストに記載されている列名の1つとの競合がチェックされます。トリガー文は、トリガーを再帰的に起動するよう定義されている表には作用しません。
- 表6-6は、使用可能な6つの更新アクションのタイプを示しています。1つの表に対しては、更新文のアクション時間とタイプの6つの組合せのうち1つを指定するトリガーを1つのみ定義できます。更新タイプUPDATEについては、指定された列名によってこの一意性がさらに限定されます。トリガー文は、トリガーを再帰的に起動するよう定義されている表には作用しません。
表6-6に示すように、トリガー文が作用する行の値はトリガー・アクションで使用可能です。
表6-6 トリガー・アクションでの行データの可用性 更新のアクション時間/タイプ 行データの可用性 BEFORE INSERT 行データは使用不可能 AFTER INSERT 表相関名によって参照される行データは使用可能 BEFORE DELETE 表相関名によって参照される行データは使用可能 AFTER DELETE 行データは使用不可能 BEFORE UPDATE 表相関名によって参照される行データの旧値は使用可能 新規相関名によって参照される行データの新規の値は使用可能 AFTER UPDATE 表相関名によって参照される行データの新規の値は使用可能 旧相関名によって参照される行データの旧値は使用可能
たとえば、EMPLOYEES表に対するBEFORE INSERTトリガー・アクションでは、格納するEMPLOYEE_ID列のIDについてJOB_HISTORY表に行を作成できません。これは、格納する行の情報がまだ使用できないためです。ただし、AFTER INSERTトリガー・アクションでは、格納されている行のEMPLOYEE_IDを使用してJOB_HISTORY表に行を作成できます。
EMPLOYEES表のBEFORE DELETEトリガー・アクションでは、削除する行のEMPLOYEE_ID列を使用してJOB_HISTORYの行を削除できます。しかし、AFTER DELETEトリガー・アクションでは、このEMPLOYEE_ID列を使用してJOB_HISTORYの行を削除できません。これは、削除された行の情報は使用できないためです。- 評価対象としてトリガーが選択された後、関連する各トリガー・アクションが連続して評価されます。トリガー・アクション文の実行により、他のトリガーが起動対象として選択される場合があります。ただし、トリガーがそのアクションの1回の直接または間接的実行によって再帰的に選択された場合、例外が発生します。すべてのトリガー・アクションが実行されると、関連する別のトリガーが評価対象として選択される場合があります(BEFORE UPDATEおよびAFTER UPDATEトリガーのみ)。
- 既存のトリガーは変更できません。既存のトリガーを変更するには、これを削除してから新規トリガーを作成する必要があります。
- SQLERRD配列の3番目の要素SQLERRD[2]の数値と、対話型SQLの文の最後に表示される数値には、トリガーによって挿入、更新および削除された行は含まれません。
- CREATE TRIGGER文は、読取り/書込みトランザクションで実行する必要があります。アクティブなトランザクションがない場合にこの文を発行すると、SQLでは、読取り/書込みトランザクションが暗黙的に開始されます。
- トリガーを作成しようとし、そのトリガーまたはその対象となる表が同時に問合せに含まれている場合は、トリガー作成に失敗します。トリガーを作成する前に、ユーザーはDISCONNECT文でデータベースからデタッチする必要があります。Oracle Rdbが最初に表などのオブジェクトにアクセスすると、そのオブジェクトにロックがかけられ、ユーザーがそのデータベースを終了するまで解除されません。このオブジェクトを更新しようとすると、もう1人のユーザーがこのオブジェクトにアクセスしているため、LOCK CONFLICT ON CLIENTメッセージが表示されます。
- RDB$SYSTEM記憶域が読取り専用に設定されている場合、CREATE TRIGGER文を実行できません。最初にRDB$SYSTEMを読取り/書込みに設定する必要があります。RDB$SYSTEM記憶域の詳細は、『Oracle Rdb7 Guide to Database Performance and Tuning』を参照してください。
- CREATE TRIGGER文を発行すると、他のユーザーがデータベースにアタッチできるようになります。
- SET TRANSACTION文のRESERVING句に指定されていない表がトリガーによって参照されると、この表はSHARED WRITEとして予約されます。トリガーによって参照される表が互換性のないモードですでに予約されている場合、この表をアクティブ化する文は失敗します。
- 複数のアクションを実行するトリガーが起動され、これらのアクションのいずれかによって別のトリガーが起動される場合、2番目のトリガーで実行されるアクションは、最初のトリガーの後続アクションの実行前に完了する必要があります。次に例を示します。

Action-1a
Action-2a
Action-2b
Action-1b

Action-1b
Action-1a
Action-2a
Action-2b
