| Oracle Rdb SQLリファレンス・マニュアル リリース7.2 E06178-01 |
|


 戻る |
 次へ |
この例では、EXPORT文とIMPORT文を使用して、オンラインのサンプル・データベース(人事データベース)を複数ファイルのデータベースに変換します。
SQL> export database
cont> filename PERSONNEL
cont> into PERS;
SQL>
SQL> import database
cont> from PERS
cont> filename MF_PERSONNEL
cont> default storage area MFP0
cont> create storage area MFP0
cont> filename MFP0_DEFAULT
cont> page format is UNIFORM
cont> create storage area MFP1
cont> filename MFP1
cont> create storage area MFP2
cont> filename MFP2
cont> create storage map EMPLOYEES_MAP
cont> for EMPLOYEES
cont> store randomly across (MFP1, MFP2);
SQL>
SQL> show storage area;
Storage Areas in database with filename MF_PERSONNEL
MFP0 Default storage area
MFP1
MFP2
RDB$SYSTEM List storage area.
|
この例では、記憶域RDB$SYSTEMが暗黙的に作成されています。データベース管理者は、このIMPORT文の例にCREATE STORAGE AREA RDB$SYSTEM句を追加して、RDB$SYSTEM領域の名前、場所および領域割当てを制御できます。
例2: ANSI/ISOスタイルの権限を使用して作成したデータベースのインポート
この例では、ACLSスタイルの保護を使用して最初に作成したデータベースをインポートし、ANSIスタイルの保護を設定した新規データベースを作成します。
SQL> import database
cont> from PERS
cont> alias NEW_PERS
cont> filename MF_PERSONNEL
cont> protection is ANSI
cont> ;
SQL> show protection on database NEW_PERS;
Protection on Alias NEW_PERS
[DEV,SMITH]:
With Grant Option: SELECT,INSERT,UPDATE,DELETE,SHOW,CREATE,ALTER,DROP,
DBCTRL,OPERATOR,DBADM,SECURITY,DISTRIBTRAN
Without Grant Option: NONE
[*,*]:
With Grant Option: NONE
Without Grant Option: NONE
SQL>
SQL> show protection on table NEW_PERS.EMPLOYEES;
Protection on Table NEW_PERS.EMPLOYEES
[DEV,SMITH]:
With Grant Option: SELECT,INSERT,UPDATE,DELETE,SHOW,CREATE,ALTER,DROP,
DBCTRL,REFERENCES
Without Grant Option: NONE
[*,*]:
With Grant Option: NONE
Without Grant Option: NONE
|
例3: データベースのインポートと統計の表示
この例ではデータベースをインポートし、TRACEオプションを使用してDIO統計、CPU統計およびPAGE FAULT統計を表示します。
SQL> IMPORT DATABASE FROM personnel.rbr cont> FILENAME personnel_new.rdb cont> TRACE cont> CREATE INDEX LOCAL_INDEX ON jobs (job_code); IMPORTing STORAGE AREA: RDB$SYSTEM IMPORTing table COLLEGES Completed COLLEGES. DIO = 103, CPU = 0:00:00.89, FAULTS = 169 Starting INDEX definition COLL_COLLEGE_CODE Completed COLL_COLLEGE_CODE. DIO = 25, CPU = 0:00:00.24, FAULTS = 26 IMPORTing table DEGREES Completed DEGREES. DIO = 96, CPU = 0:00:01.15, FAULTS = 9 Starting INDEX definition DEG_COLLEGE_CODE Completed DEG_COLLEGE_CODE. DIO = 27, CPU = 0:00:00.36, FAULTS = 1 Starting INDEX definition DEG_EMP_ID Completed DEG_EMP_ID. DIO = 39, CPU = 0:00:00.49, FAULTS = 2 IMPORTing table DEPARTMENTS Completed DEPARTMENTS. DIO = 99, CPU = 0:00:00.70, FAULTS = 3 IMPORTing table EMPLOYEES Completed EMPLOYEES. DIO = 182, CPU = 0:00:01.60, FAULTS = 21 . . . Starting CONSTRAINT definition SH_EMPLOYEE_ID_IN_EMP Completed SH_EMPLOYEE_ID_IN_EMP. DIO = 48, CPU = 0:00:00.56, FAULTS = 2 Starting CONSTRAINT definition WS_STATUS_CODE_DOM_NOT_NULL Completed WS_STATUS_CODE_DOM_NOT_NULL. DIO = 36, CPU = 0:00:00.23, FAULTS = 0 Completed import. DIO = 3530, CPU = 0:00:32.97, FAULTS = 2031 SQL> |
例4: インポート操作中の順序スロットの予約
SQL> IMPORT DATABASE FROM MF_PERSONNEL.RBR cont> FILENAME 'mf_personnel.rdb' BANNER cont> RESERVE 64 SEQUENCES; . . . Unused Sequences were 32 now are 64 IMPORTing STORAGE AREA: RDB$SYSTEM IMPORTing STORAGE AREA: DEPARTMENTS IMPORTing STORAGE AREA: EMPIDS_LOW |
例5: BANNERオプションの指定
SQL> import data from x file mf_personnel BANNER;
Exported by Oracle Rdb X7.1-201 Import/Export utility
A component of Oracle Rdb SQL X7.1-201
Previous name was mf_personnel
It was logically exported on 29-MAY-2003 12:32
Multischema mode is DISABLED
Database NUMBER OF USERS is 50
Database NUMBER OF CLUSTER NODES is 16
Database NUMBER OF DBR BUFFERS is 20
Database SNAPSHOT is ENABLED
Database SNAPSHOT is IMMEDIATE
Database JOURNAL ALLOCATION is 512
Database JOURNAL EXTENSION is 512
Database BUFFER SIZE is 6 blocks
Database NUMBER OF BUFFERS is 20
Adjustable Lock Granularity is Enabled Count is 3
Database global buffering is DISABLED
Database number of global buffers is 250
Number of global buffers per user is 5
Database global buffer page transfer is via DISK
Journal fast commit is DISABLED
Journal fast commit checkpoint interval is 0 blocks
Journal fast commit checkpoint time is 0 seconds
Commit to journal optimization is Disabled
Journal fast commit TRANSACTION INTERVAL is 256
LOCK TIMEOUT is 0 seconds
Statistics Collection is ENABLED
Unused Storage Areas are: 0
System Index Compression is DISABLED
Journal was Disabled
Unused Journals are: 1
Journal Backup Server was: Manual
Journal Log Server was: Manual
Journal Overwrite was: Disabled
Journal shutdown minutes was 60
Asynchronous Prefetch is ENABLED
Async prefetch depth buffers is 5
Asynchronous Batch Write is ENABLED
Async batch write clean buffers is 5
Async batch write max buffers is 4
Lock Partitioning is DISABLED
Incremental Backup Scan Optim uses SPAM pages
Unused Cache Slots are: 1
Workload Collection is DISABLED
Cardinality Collection is ENABLED
Metadata Changes are ENABLED
Row Cache is DISABLED
Detected Asynchronous Prefetch is ENABLED
Detected Asynchronous Prefetch Depth Buffers is 4
Detected Asynchronous Prefetch Threshold Buffers is 4
Open is Automatic, Wait period is 0 minutes
Shared Memory is PROCESS
Unused Sequences are: 32
The Transaction Mode(s) Enabled are:
ALL
IMPORTing STORAGE AREA: RDB$SYSTEM
IMPORTing STORAGE AREA: DEPARTMENTS
IMPORTing STORAGE AREA: EMPIDS_LOW
IMPORTing STORAGE AREA: EMPIDS_MID
IMPORTing STORAGE AREA: EMPIDS_OVER
IMPORTing STORAGE AREA: EMP_INFO
IMPORTing STORAGE AREA: JOBS
IMPORTing STORAGE AREA: MF_PERS_SEGSTR
IMPORTing STORAGE AREA: SALARY_HISTORY
IMPORTing table CANDIDATES
IMPORTing table COLLEGES
IMPORTing table DEGREES
IMPORTing table DEPARTMENTS
IMPORTing table EMPLOYEES
IMPORTing table JOBS
IMPORTing table JOB_HISTORY
IMPORTing table RESUMES
IMPORTing table SALARY_HISTORY
IMPORTing table WORK_STATUS
IMPORTing view CURRENT_SALARY
IMPORTing view CURRENT_JOB
IMPORTing view CURRENT_INFO
|
例6: COMMIT EVERYオプションの使用
SQL> import database cont> from 'TEST$DB_SOURCE:MF_PERSONNEL' cont> filename 'MF_PERSONNEL' cont> cont> commit every 10 rows cont> cont> create storage area DEPARTMENTS cont> filename 'DEPARTMENTS' cont> page format is mixed cont> snapshot filename 'DEPARTMENTS' cont> create storage area EMPIDS_LOW cont> filename 'EMPIDS_LOW' cont> page format is mixed cont> snapshot filename 'EMPIDS_LOW' cont> create storage area EMPIDS_MID cont> filename 'EMPIDS_MID' cont> page format is mixed cont> snapshot filename 'EMPIDS_MID' cont> create storage area EMPIDS_OVER cont> filename 'EMPIDS_OVER' cont> page format is mixed cont> snapshot filename 'EMPIDS_OVER' . . . cont> ; ! end of import Definition of STORAGE AREA RDB$SYSTEM overridden Definition of STORAGE AREA MF_PERS_SEGSTR overridden Definition of STORAGE AREA EMPIDS_LOW overridden Definition of STORAGE AREA EMPIDS_MID overridden Definition of STORAGE AREA EMPIDS_OVER overridden Definition of STORAGE AREA DEPARTMENTS overridden Definition of STORAGE AREA SALARY_HISTORY overridden Definition of STORAGE AREA JOBS overridden Definition of STORAGE AREA EMP_INFO overridden COMMIT EVERY ignored for table EMPLOYEES due to PLACEMENT VIA INDEX processing COMMIT EVERY ignored for table JOB_HISTORY due to PLACEMENT VIA INDEX processing SQL> |
プリコンパイルされたホスト言語プログラムに宣言またはコードを挿入します。INCLUDE文を使用して、次の宣言またはコードを挿入できます。
- SQL通信領域(SQLCA)およびメッセージ・ベクターのホスト言語宣言
- SQL記述子領域(SQLDAおよびSQLDA2)のホスト言語宣言
- ホスト言語のソース・コード
- リポジトリ・レコード定義のホスト言語宣言
INCLUDE文は、プリコンパイルされたホスト言語プログラムでのみ使用できます。プログラムではINCLUDE SQLCA文を使用するか、SQLCODE変数を明示的に宣言する必要があります。INCLUDE文のその他の形式はオプションです(「使用方法」を参照)。
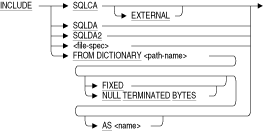
AS name
リポジトリのレコードの構造体名をオーバーライドする名前を指定します。デフォルトでは、SQLプリコンパイラはリポジトリ・レコード名から構造体名を取得します。EXTERNAL
SQLのプリコンパイルされたCプログラムのSQLCA構造体への外部参照を宣言します。複数のモジュールでINCLUDE SQLCA文を使用している場合は、1つを除くすべてのモジュールにEXTERNALキーワードを追加できます。複数のイメージでSQLCAを共有しているアプリケーションでは、1つのイメージでSQLCAを定義し、他のすべてのイメージでSQLCAを参照する必要があります。SQLCAの参照にはEXTERNALキーワードを使用します。
file-spec
プログラムに挿入されるソース・コードのファイル仕様です。このファイル仕様は、標準のOpenVMSテキスト・ファイルを参照する必要があります。SQLは、テキスト・ライブラリ(ファイル拡張子.tlb)のINCLUDE文をサポートしていません。次のいずれかの場合は、SQL INCLUDE文を使用してください。
- 組み込むソース・コードに埋込みSQL文が含まれる場合。
- 組み込むソース・コードに、プログラムの他の部分の埋込みSQL文が参照するホスト言語変数宣言が組み込まれる場合。
SQL文もSQL文が参照する変数もソース・コードに含まれない場合は、ファイルの組込みにSQL INCLUDE文とホスト言語文のいずれを使用しても同じです。
FIXED
FIXED句とNULL TERMINATED BYTES句は、C言語のCHARフィールドを解釈する方法をプリコンパイラに伝えます。FIXEDを指定すると、プリコンパイラは、リポジトリのCHARフィールドを固定文字列と解釈します。FROM DICTIONARY path-name
リポジトリ・レコード定義のパス名を指定します。SQLではパス名が文字列リテラルとして処理されるため、パス名を一重引用符で囲む必要があります。SQLではリポジトリ・レコード定義に従ってホスト構造体が宣言され、定義と同じ名前が指定されます。これにより、プログラムの埋込みSQL文はホスト構造体を参照できます。通常、リポジトリに格納されている表定義と対応するホスト構造体を宣言する便利な方法として、FROM DICTIONARY引数がプログラムで使用されます。
SQLでは、次の場合にのみ表定義がリポジトリに格納されます。
- 表が定義されたアタッチのCREATE DATABASE文とデータベース宣言の両方でPATHNAME引数が指定されている場合。
- INTEGRATE文によってデータベース定義がリポジトリにコピーされた場合。
ただし、データベースの一部として定義されたリポジトリ・オブジェクトを含むすべてのCDD$RECORDリポジトリ・オブジェクト型では、ホスト構造体を宣言するためにFROM DICTIONARY引数をプログラムで使用できます。
INCLUDE文を使用すると、プログラムにCDD$RECORDオブジェクトを挿入する同等のホスト言語文よりも多くの機能を利用できます。INCLUDE FROM DICTIONARY文では埋込みSQL文でリポジトリ・レコードを参照できますが、ホスト言語文ではできません。
NULL TERMINATED BYTES
リポジトリのCHARフィールドがヌル文字で終了するように指定します。モジュール・プロセッサは、リポジトリの長さフィールドを文字列のバイト数と解釈します。リポジトリの長さがnの場合、データ・バイト数はn--1、文字列の長さはnバイトです。つまり、プリコンパイラは文字列の最後の文字はヌル終端文字であると仮定します。したがって、リポジトリで10文字とされるフィールドは、Cプリコンパイラの9文字のSQLフィールドしか保持できません。
文字解釈オプションを指定しない場合は、NULL TERMINATED BYTESがデフォルトとなります。
詳細は、第3章の「NULL TERMINATED CHARACTERS引数」を参照してください。
SQLCA
サポートされているデータベース・システムに固有のSQLCA構造体およびメッセージ・ベクター(RDB$MESSAGE_VECTOR)構造体をSQLがプログラムに挿入するように指定します。SQLCAおよびメッセージ・ベクターはともにエラー条件の処理の方法を備えています。
- SQLCAは、SQL文の実行に関する情報をアプリケーション・プログラムに提供する際に使用する変数のコレクションです。SQLCAは、文が正常に終了したかどうかを示し、ある条件下では、文が正常に終了しなかったときの特定のエラーを示します。
- メッセージ・ベクターも、SQLが文の実行後に更新する変数のコレクションです。メッセージ・ベクターも、文が正常に終了したかどうかをプログラムでチェックしますが、文が正常に終了しなかった場合は、エラー条件のタイプについてSQLCAよりも詳細な情報を提供します。
SQLCAおよびメッセージ・ベクターの詳細は、付録Cを参照してください。
SQLDA
SQLがプログラムにSQLDAを挿入するように指定します。SQLDAは、動的SQLでのみ使用される変数のコレクションです。SQLDAでは、動的SQL文の情報をプログラムに、そのプログラムのホスト言語変数の情報をSQLに提供します。SQLDA2
SQLがプログラムにSQLDA2を挿入するように指定します。SQLDAと同様に、SQLDA2は、動的SQL文の情報をプログラムに、そのプログラムのホスト言語変数の情報をSQLに提供する変数のコレクションです。列名がパラメータ・マーカーで使用されている動的文や、選択リスト項目が日時データ型または期間データ型の1つである動的文ではSQLDA2を使用する必要があります。SQLDAおよびSQLDA2の詳細は、付録Dを参照してください。
- AdaプリコンパイラおよびPascalプリコンパイラは、INCLUDE FROM DICTIONARY文をサポートしていません。
- プログラムでINCLUDE SQLCA文を使用する必要はありません。ただし、使用しない場合は、SQLCODE変数を明示的に宣言してSQLから値を受け取る必要があります。
ANSI/ISO SQL規格に準拠するには、INCLUDE SQLCA文を使用するかわりにSQLCODE変数を明示的に宣言する必要があります。ただし、INCLUDE SQLCA文を使用しないプログラムには、プリコンパイラによって宣言されたRDB$MESSAGE_VECTORメッセージ・ベクター構造体がありません。そのようなプログラムでは、メッセージ・ベクターの明示的な宣言が必要になる場合があります。メッセージ・ベクターのサンプル宣言は、付録C.3節を参照してください。- INCLUDE SQLCA文を使用するプログラムは、この文による変数宣言が有効な場所にこの文を配置する必要があります。
- プリコンパイルされたプログラムに埋め込まれているSQL文はすべて、SQLCODE宣言またはSQLCA宣言の範囲内にある必要があります。SQLプリコンパイラは、Pascalプログラム、AdaプログラムおよびCプログラムのブロック構造体をサポートしていますが、COBOL、FORTRANまたはPL/Iのブロック構造体はサポートしていません。したがって、複数のモジュールを含むCOBOL、FORTRANおよびPL/Iプログラムでは、SQLで埋込みSQL文を使用できる場所がPascal、AdaおよびCよりも限定されます(モジュールは、個別にコンパイル可能な一連の文です)。
- COBOL、FORTRANおよびPL/Iのプログラムでは、1つのモジュールのみがSQLCAパラメータまたはSQLCODEパラメータを宣言できます。このような理由により、モジュールが複数あるプログラム・ソース・ファイルで埋込みSQL文を複数のモジュールに含めることはできません。
1つのモジュールに複数のルーチンがある場合は、SQL文がINCLUDE SQLCA文の範囲内にあるかぎり、そのSQL文をこれらのルーチンで使用できます。COBOLとPL/Iではこのネストされたルーチンを使用できますが、FORTRANでは使用できません。- Adaプログラム、CプログラムおよびPascalプログラムでは、すべてのSQL文がSQLCODE宣言またはSQLCA宣言の範囲内にある必要があります。ただし、プログラムの各モジュールには1つの宣言(またはモジュールのルーチンごとに1つなど、多数の宣言)を含むことができます。このように、Adaプログラム、CプログラムおよびPascalプログラムでは、複数のモジュールにSQL文を埋め込むことができます。
- SQLでは、別名を宣言するためにPATHNAME引数と一緒にINCLUDE FROM DICTIONARY文を使用するようにプログラムに要求することはありません。ただし、INCLUDE FROM DICTIONARY文を使用して表定義と対応するホスト構造体を宣言するプログラムでは、その表定義の完全なリポジトリ・パス名を指定する必要があります。
データベース・システムでは、データベース・パス名に従属しているパス名RDB$RELATIONSで表定義が格納されます。これらの定義の参照時には、INCLUDE FROM DICTIONARY文のパス名にパス名指定のRDB$RELATIONSの名前が含まれている必要があります。- SQL INCLUDE file-spec文で指定されたソース・コード・ファイルに、ネストされたINCLUDE file-spec文を含むことはできません。
- SQLプリコンパイラは、変数の宣言中にはINCLUDE文を処理しません。COBOLプログラムの次のセグメントは、処理されていないINCLUDE文を示しています。
01 dept_rec pic x(24). 01 commarea. EXEC SQL INCLUDE 'A.DAT' END-EXEC.
例1: ホスト構造体の宣言の組込みこの単純なCOBOLプログラムでは、サンプルの人事データベースのEMPLOYEES表と対応するホスト構造体を宣言するためにINCLUDE FROM DICTIONARY文が使用されます。リポジトリ・パス名は、データベース・ディレクトリと表名の間のRDB$RELATIONSリポジトリ・ディレクトリを指定します。
IDENTIFICATION DIVISION. PROGRAM-ID. INCLUDE_FROM_CDD. * * Illustrate how to use the INCLUDE FROM DICTIONARY * statement to declare a host structure corresponding to * the EMPLOYEES table: * DATA DIVISION. WORKING-STORAGE SECTION. EXEC SQL WHENEVER SQLERROR GOTO ERR END-EXEC. * * Include the SQLCA: EXEC SQL INCLUDE SQLCA END-EXEC. * * Declare the schema: * (Notice that declaring the alias with the * FILENAME qualifier would not have precluded * using the INCLUDE FROM DICTIONARY statement later.) EXEC SQL DECLARE PERS ALIAS FOR PATHNAME 'CDD$DEFAULT.PERSONNEL' END-EXEC. * * Create a host structure that corresponds to the * EMPLOYEES table with the INCLUDE FROM DICTIONARY * statement. The path name in the INCLUDE statement * must specify the RDB$RELATIONS directory before * the table name: EXEC SQL INCLUDE FROM DICTIONARY 'CDD$DEFAULT.PERSONNEL.RDB$RELATIONS.EMPLOYEES' END-EXEC. * * Declare an indicator structure for the host * structure created by the INCLUDE FROM DICTIONARY statement: 01 EMPLOYEES-IND. 02 EMP-IND OCCURS 12 TIMES PIC S9(4) COMP. EXEC SQL DECLARE E_CURSOR CURSOR FOR SELECT * FROM EMPLOYEES END-EXEC. PROCEDURE DIVISION. 0. DISPLAY "Display rows from EMPLOYEES:". EXEC SQL OPEN E_CURSOR END-EXEC. EXEC SQL FETCH E_CURSOR INTO :EMPLOYEES:EMP-IND END-EXEC. PERFORM UNTIL SQLCODE NOT = 0 DISPLAY EMPLOYEE_ID, FIRST_NAME, LAST_NAME EXEC SQL FETCH E_CURSOR INTO :EMPLOYEES:EMP-IND END-EXEC END-PERFORM. EXEC SQL CLOSE E_CURSOR END-EXEC. EXEC SQL ROLLBACK END-EXEC. EXIT PROGRAM. ERR. DISPLAY "unexpected error ", sqlcode with conversion. CALL "SQL$SIGNAL".
例2: SQLCAの組込み
PL/Iプログラムのこの断片はINCLUDE SQLCA文を示しており、エラー処理ルーチンがSQLCAを参照する方法を示しています。
このプログラムは中間結果表のTMPを作成し、人事データベースのEMPLOYEES表をこのTMPにコピーします。次に、プログラムはTMPのカーソルを宣言し、端末の画面にカーソルの行を表示します。
/* Include the SQLCA: */ EXEC SQL INCLUDE SQLCA; EXEC SQL WHENEVER SQLERROR GOTO ERROR_HANDLER; EXEC SQL DECLARE ALIAS FOR FILENAME personnel; DCL MANAGER_ID CHAR(5), LAST_NAME CHAR(20), DEPT_NAME CHAR(20); DCL COMMAND_STRING CHAR(256); EXEC SQL CREATE TABLE TMP (MANAGER_ID CHAR(5), LAST_NAME CHAR(20), DEPT_NAME CHAR(20)); COMMAND_STRING = 'INSERT INTO TMP SELECT E.LAST_NAME, E.FIRST_NAME, D.DEPARTMENT_NAME FROM EMPLOYEES E, DEPARTMENTS D WHERE E.EMPLOYEE_ID = D.MANAGER_ID'; EXEC SQL EXECUTE IMMEDIATE :COMMAND_STRING; EXEC SQL DECLARE X CURSOR FOR SELECT * FROM TMP; EXEC SQL OPEN X; EXEC SQL FETCH X INTO MANAGER_ID, LAST_NAME, DEPT_NAME; DO WHILE (SQLCODE = 0); PUT SKIP EDIT (MANAGER_ID, ' ', LAST_NAME, ' ', DEPT_NAME) (A,A,A,A,A); EXEC SQL FETCH X INTO MANAGER_ID, LAST_NAME, DEPT_NAME; END; EXEC SQL ROLLBACK; PUT SKIP EDIT (' ALL OK') (A); RETURN; ERROR_HANDLER: /* Display the value of the SQLCODE field in the SQLCA: */ PUT SKIP EDIT ('UNEXPECTED SQLCODE VALUE ', SQLCODE) (A, F(9)); EXEC SQL WHENEVER SQLERROR CONTINUE; EXEC SQL ROLLBACK;
1つ以上の新規行を表またはビューに追加します。INSERT文をカーソルで使用して、LIST OF BYTE VARYINGデータ型の列のセグメントに値を割り当てることもできます。LIST OF BYTE VARYINGデータ型の列のセグメントに値を割り当てるには、まず同じ行の1つ以上の他の列に値を割り当てる必要があります。これを実行するには、位置付け挿入を使用します。位置付け挿入は、挿入のみの表のカーソルを指定するINSERT文です。このタイプのINSERT文は、後続のリスト・カーソルの適切な行コンテキストを設定してリスト・セグメントに値を割り当てます。
位置付け挿入では、静的カーソル、動的カーソルまたは拡張動的カーソルの名前を指定できます。静的カーソルの名前を指定する場合、そのカーソル名は同じモジュール内のDECLARE CURSOR文でも指定されている必要があります。静的カーソル、動的カーソルおよび拡張動的カーソルの詳細は、「DECLARE CURSOR文」を参照してください。
INSERT文を使用してリスト・セグメントに値を割り当てるときは、次の点に留意してください。
- 現在のトランザクションは読取り専用にしないでください。
- 更新表のカーソルを参照しているカーソルの名前は指定できません。
- カーソルでは中間表を指定する必要があります。
- 割り当てる値はそのリストの最後に追加されます。
INSERT文は次の環境で使用できます。
- 対話型SQL内
- プリコンパイル対象のホスト言語プログラムに埋め込まれる場合
- SQLモジュールのプロシージャの一部として
- 動的SQLで動的に実行される文として
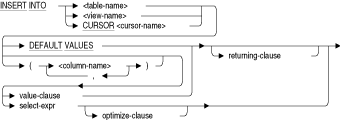



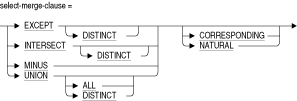
column-name
表またはビューの列名のリストを指定します。列のリストは任意の順序で表示できますが、その名前は表またはビューの名前と対応している必要があります。リストに欠落している列名がある場合は、SQLではその指定されていない列名にNULL値が割り当てられます。ただし、次の列の場合は除きます。
- デフォルトで定義されている場合
- デフォルトが設定されているドメインに基づいている場合
- CREATE TABLE文のNOT NULL句で定義されている場合
NOT NULL句で定義されている列名をINSERT文から除外することはできません。除外すると、この文は失敗します。
列名のリスト全体を省略すると、表またはビューのすべての列のリストが定義された順序で表示されます。
INSERT文を使用してLIST OF BYTE VARYINGデータ型の列のセグメントに値を割り当てる場合、列名のリストを省略する必要があります。列名は、このコンテキストでは有効ではありません。
CURSOR cursor-name
カーソルの使用時に必要なキーワードです。カーソルを使用して、LIST OF BYTE VARYINGデータ型の列を含む行に値を挿入する必要があります。DEFAULT
指定した列にその列に対して定義されているデフォルト値が設定されるように強制します(デフォルト値が定義されていない場合はNULL)。INSERT文でDEFAULT句を使用すると、次のいずれかが適用されます。
- 列にDEFAULT属性がある場合は、INSERT実行中にその値が適用されます。
- または、列にAUTOMATIC属性がある場合は、INSERT実行中にその値が適用されます。これは、これらの列が通常の処理時には読取り専用であるためにSET FLAGS 'AUTO_OVERRIDE'が使用されている場合にのみ発生します。
- それ以外の場合は、INSERT実行中にNULLが適用されます。
DEFAULT VALUES
表内のすべての列にデフォルト値を割り当てるように指定します(列にデフォルト値が設定されていない場合はNULL)。INTO parameter
指定された値を指定されたパラメータに挿入します。INTOパラメータ句は、対話型SQLでは無効です。INTO table-name
INTO view-name
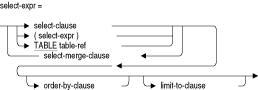
行を追加するターゲット表またはターゲット・ビューの名前です。指定された値を指定されたパラメータに挿入します。INTOパラメータ句は、対話型SQLでは無効です。limit-to-clause
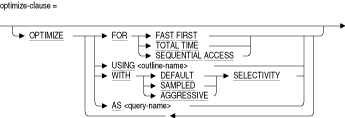
LIMIT TO式の詳細は、第2.8.1項を参照してください。OPTIMIZE AS query-name
OPTIMIZE AS句は、問合せに名前を割り当てます。この名前の表示を確認するには、SET FLAGS 'STRATEGY'を使用します。OPTIMIZE FOR
OPTIMIZE FOR句は、選択式を指定する文の優先オプティマイザ計画を指定します。次のオプションを使用できます。
- FAST FIRST
FAST FIRST用に最適化された問合せが、これにより全体のスループットが低下しても、できるかぎり速やかにデータをユーザーに返します。
問合せが早期に取り消されることがある場合は、FAST FIRSTの最適化を指定する必要があります。FAST FIRST最適化の有力な候補は、レコードのグループをユーザーに表示する対話型アプリケーションです。このようなアプリケーションでは、ユーザーは最初の数画面の確認後、問合せを中断することもできます。たとえば、シングルトンSELECT文では、FAST FIRST最適化がデフォルトで設定されます。
最適化計画を明示的に設定しない場合は、FAST FIRSTがデフォルトとなります。- TOTAL TIME
アプリケーションをバッチで実行し、問合せのすべてのレコードにアクセスして更新またはレポートの書込みを行う場合は、TOTAL TIME最適化を指定する必要があります。TOTAL TIME最適化は、ほとんどの問合せに効果があります。- SEQUENTIAL ACCESS
順次アクセスの使用を強制します。このオプションは、厳密なパーティション化機能を使用する表では特に有用です。
OPTIMIZE USING outline-name
OPTIMIZE USING句は、選択式で使用する問合せアウトラインを明示的に指定します。これには、選択式とアウトラインでアウトラインIDが異なる場合も含まれます。
