| Oracle Rdb SQLリファレンス・マニュアル リリース7.2 E06178-01 |
|


 戻る |
 次へ |
アウトラインの作成方法の詳細は、「CREATE OUTLINE文」を参照してください。
次の例は、この句の使用方法を示しています。
SQL> select * from employees where employee_id > '00200' cont> optimize with sampled selectivity; |
ROWIDキーワードは、DBKEYキーワードのシノニムです。
LIST OF BYTE VARYINGデータ型の列のセグメントへの値の割当てに使用されるINSERT文では、RETURNING DBKEY句は無効です。
これは、SQLでサポートされている、単一SQL文で2番目のデータベースの指定を可能にする唯一の状況です。
結果表の列の数は、列名のリストで指定されている列の数と一致している必要があります。列名のリストを指定しなかった場合、結果表の列数はターゲット表の列数と同じである必要があります。結果表の行ごとに最初の列の値がターゲット表の最初の列に割り当てられ、2番目の値が2番目の列に割り当てられます(以降同様)。
LIST OF BYTE VARYINGデータ型の列のセグメントへの値の割当てに使用されるINSERT文では、選択式を指定できません。
選択式の詳細は、第2.8.1項を参照してください。
パラメータ、修飾パラメータ、列選択式、値式およびデフォルト値の詳細は、第2章を参照してください。
VALUES引数でリストされた値は別の表から選択できますが、どちらの表も同じデータベースに配置されている必要があります。
リストの値の数は、列名のリストで指定されている列の数と一致している必要があります。列リストを指定しなかった場合、リストの値の数は表の列数と同じである必要があります。リストで指定されている最初の値が最初の列に割り当てられ、2番目の値が2番目の列に割り当てられます(以降同様)。
IDENTITY、COMPUTED BYおよびAUTOMATIC COLUMNSの値は挿入できないため、これらの列型はデフォルトの列リストでは考慮されません。
列選択式を指定したINSERT文の例は、SQLのオンライン・ヘルプのINSERT EXAMPLESのトピックを参照してください。
- INSERT文を使用してビューに行を追加すると、実際にはこのビューの元になる実表に行が追加されます。さらに、SQLではINSERT文を使用可能なビューのタイプが制限されます。ビューの値の挿入、更新および削除のルールは、「CREATE VIEW文」を参照してください。
- ビューに行を挿入しようとすると、次がどちらも該当する場合は、わかりにくいエラー・メッセージが表示される場合があります。
- ビューの元になる表にNOT NULL属性で定義された列が含まれている場合。
- ビュー定義にNOT NULL属性で定義された列が含まれていない場合。
次に例を示します。
SQL> -- Create a view that is not a read-only view: SQL> CREATE VIEW TEMP AS cont> SELECT SUPERVISOR_ID FROM JOB_HISTORY; SQL> SQL> -- However, the JOB_HISTORY table on which the view is based SQL> -- contains a column, EMPLOYEE_ID, that is defined with the SQL> -- NOT NULL attribute. Because the TEMP view does not include SQL> -- the EMPLOYEE_ID column, all attempts to insert rows into SQL> -- it will fail: SQL> INSERT INTO TEMP (SUPERVISOR_ID) VALUES ('99999'); 1 row inserted SQL> COMMIT; %RDB-E-INTEG_FAIL, violation of constraint JH_EMPLOYEE_ID_IN_EMP caused operation to fail SQL> ROLLBACK;
- データベース間でデータを移動するには、INSERT文のINTO句で指定されている、あるデータベースの表を参照し、次にそのINSERT文の選択式で指定されている別のデータベースの表を参照します。
これは、SQLでサポートされている、単一SQL文で2番目のデータベースの指定を可能にする唯一の状況です。- INSERT文のPLACEMENT ONLY RETURNING DBKEY(またはROWID)句は、指定した行のdbkeyを返します。この句を使用すると、アプリケーションは、指定されたすべての行の順序付けられていないdbkeyのリストを作成できます。次に、ソート・ユーティリティ(SORT)を使用してdbkeyのソート済リストを作成し、このソート済リストを使用して行を挿入できます。dbkeyでソートしたレコードを格納する場合、バッファ内のページに、そのページのすべての行を書き込むシーケンスでデータベース・ページに行を書き込みます。この方法でレコードを格納するとランダムI/Oが減少し、ロード・プロシージャ中のパフォーマンスが大幅に向上します。この句を使用すると、ハッシュ索引に対してPLACEMENT VIA INDEX句を指定するデータベース・ロード・プロシージャのパフォーマンスが大幅に向上する可能性があります。この句は、ハッシュ索引が定義されているレコードでのみ使用してください。
- RETURNING DBKEY句を使用して、挿入専用の表カーソルに行を挿入することはできません。
次の例は、無効な構文を示しています。
SQL> ATTACH 'FILENAME MF_PERSONNEL'; SQL> DECLARE CURSOR1 INSERT ONLY TABLE CURSOR FOR SELECT * FROM COLLEGES; SQL> OPEN CURSOR1; SQL> INSERT INTO CURSOR CURSOR1 (COLLEGE_CODE, COLLEGE_NAME) cont> VALUES ('ASU','Arizona State University') RETURNING DBKEY; %SQL-F-NORETURN, Specifying a RETURNING clause is incompatible with a positioned insert statement SQL> CLOSE CURSOR1; SQL> SQL> DECLARE CURSOR2 INSERT ONLY TABLE CURSOR FOR cont> SELECT * FROM RESUMES; SQL> OPEN CURSOR2; SQL> INSERT INTO CURSOR CURSOR2 (EMPLOYEE_ID) cont> VALUES ('00169') RETURNING DBKEY; %SQL-F-NORETURN, Specifying a RETURNING clause is incompatible with a positioned insert statement SQL> CLOSE CURSOR2; SQL> DISCONNECT ALL;
この問題を回避するには、カーソルを使用せずにSQL INSERT文を指定します。INSERT INTO table-name ... RETURNING DBKEY INTO ...構文を使用します。- アウトラインが存在する場合は、OPTIMIZE USING句で指定されているアウトラインが使用されます。ただし、アウトラインのディレクティブを1つ以上順守できない場合は除きます。たとえば、アウトラインの準拠レベルが必須で、アウトラインのディレクティブで指定されている索引の1つが削除された場合、そのアウトラインは使用されません。既存のアウトラインを使用できない場合は、エラー・メッセージが発行されます。
存在しないアウトラインの名前を指定すると、問合せがコンパイルされ、そのアウトライン名は無視され、問合せと同じアウトラインIDを持つ既存のアウトラインが検索されます。同じアウトラインIDのアウトラインが検出されると、そのアウトラインのディレクティブを使用して問合せを実行しようとします。同じアウトラインIDを持つアウトラインが検出されない場合、問合せ実行のための計画がオプティマイザで選択されます。
問合せアウトラインの詳細は、『Oracle Rdb7 Guide to Database Performance and Tuning』を参照してください。
例1: リテラル値を使用した行の追加次の対話型SQLの例では、サンプルの人事データベースのDEPARTMENTS表に新規行を格納します。この例では、行の各列にリテラル値が明示的に割り当てられます。この文ではRETURNING DBKEY句が含まれているため、dbkeyの値として29:435:9が返されます。
SQL> INSERT INTO DEPARTMENTS cont> -- List of columns: cont> (DEPARTMENT_CODE, cont> DEPARTMENT_NAME, cont> MANAGER_ID, cont> BUDGET_PROJECTED, cont> BUDGET_ACTUAL) cont> VALUES cont> -- List of values: cont> ('RECR', cont> 'Recreation', cont> '00175', cont> 240000, cont> 128776) cont> RETURNING DBKEY; DBKEY 29:435:9 1 row inserted
例2: パラメータを使用した行の追加
この例は、パラメータの値を表の列に明示的に割り当てることにより、JOB_HISTORY表に行を追加するCOBOLプログラムの一部分を示しています。この例では、次の処理を実行します。
- 列値の入力を要求します。
- 読取り/書込みトランザクションを宣言します。JOB_HISTORY表を更新するため、この表のデータを読み取る他のユーザーとの競合を回避する必要があります。そのため、保護された共有モードおよび書込みロック・タイプを使用します。
- 表の列にパラメータを割り当てることにより、行を格納します。
- SQLCODE変数の値をチェックし、値がゼロ未満の場合はINSERT操作を繰り返します。
- COMMIT文を使用して更新を永続化します。
STORE-JOB-HISTORY. DISPLAY "Enter employee ID: " WITH NO ADVANCING. ACCEPT EMPL-ID. DISPLAY "Enter job code: " WITH NO ADVANCING. ACCEPT JOB-CODE. DISPLAY "Enter starting date: " WITH NO ADVANCING. ACCEPT START-DATE. DISPLAY "Enter ending date: " WITH NO ADVANCING. ACCEPT END-DATE. DISPLAY "Enter department code: " WITH NO ADVANCING. ACCEPT DEPT-CODE. DISPLAY "Enter supervisor's ID: " WITH NO ADVANCING. ACCEPT SUPER. EXEC SQL SET TRANSACTION READ WRITE RESERVING JOB_HISTORY FOR PROTECTED WRITE END-EXEC EXEC SQL INSERT INTO JOB_HISTORY (EMPLOYEE_ID, JOB_CODE, JOB_START, JOB_END, DEPARTMENT_CODE, SUPERVISOR_ID) VALUES (:EMPL-ID, :JOB-CODE, :START-DATE, :END-DATE, :DEPT-CODE, :SUPER) END-EXEC IF SQLCODE < 0 THEN EXEC SQL ROLLBACK END-EXEC DISPLAY "An error has occurred. Try again." GO TO STORE-JOB-HISTORY END-IF EXEC SQL COMMIT END-EXEC
例3: ある表から別の表へのコピー
この対話型SQLの例では、EMPLOYEES表から同一の中間結果表にデータのサブセットをコピーします。これを実行するため、この例では選択式を使用して、選択式の結果表の行をNew Hampshireに住む従業員のデータを含む行に制限します。
SQL> INSERT INTO TEMP cont> (EMPLOYEE_ID, cont> LAST_NAME, cont> FIRST_NAME, cont> MIDDLE_INITIAL, cont> ADDRESS_DATA_1, cont> ADDRESS_DATA_2, cont> CITY, cont> STATE, cont> POSTAL_CODE, cont> SEX, cont> BIRTHDAY, Cont> STATUS_CODE) cont> SELECT * FROM EMPLOYEES cont> WHERE STATE = 'NH'; 90 rows inserted SQL>
例4: INSERT文によるデータベース間の行のコピー
この例では、人事データベースのEMPLOYEES表の内容を別のデータベースのLOCALDATAにコピーします。
SQL> ATTACH 'ALIAS PERS FILENAME personnel'; SQL> ATTACH 'ALIAS LOCALDB FILENAME localdata'; SQL> SQL> DECLARE TRANSACTION cont> ON PERS USING (READ ONLY cont> RESERVING PERS.EMPLOYEES FOR SHARED READ) cont> AND cont> ON LOCALDB USING (READ WRITE cont> RESERVING LOCALDB.EMPLOYEES FOR SHARED WRITE); SQL> SQL> INSERT INTO LOCALDB.EMPLOYEES cont> SELECT * FROM PERS.EMPLOYEES; 100 rows inserted SQL>
例5: LIST OF BYTE VARYINGデータ型の列へのデータの追加
次の対話型SQLの例では、サンプルの人事データベースのRESUMES表に新規行を追加します。最初にEMPLOYEE_ID列に値が割り当てられ、次に同じ行のRESUME列に情報の3行が追加されます。このRESUME列はLIST OF BYTE VARYINGデータ型を持ちます。位置付け挿入で表カーソルを宣言するときは、表の列の他にリストの列(RESUME)の名前を指定する必要があります。
SQL> DECLARE TBLCURSOR INSERT ONLY TABLE CURSOR FOR SELECT EMPLOYEE_ID, RESUME cont> FROM RESUMES; SQL> DECLARE LSTCURSOR INSERT ONLY LIST CURSOR FOR SELECT RESUME cont> WHERE CURRENT OF TBLCURSOR; SQL> OPEN TBLCURSOR; SQL> INSERT INTO CURSOR TBLCURSOR (EMPLOYEE_ID) VALUES ('00167'); 1 row inserted SQL> OPEN LSTCURSOR; SQL> INSERT INTO CURSOR LSTCURSOR VALUES ('This is the resume for 00167'); SQL> INSERT INTO CURSOR LSTCURSOR VALUES ('Boston, MA'); SQL> INSERT INTO CURSOR LSTCURSOR VALUES ('Oracle Corporation'); SQL> CLOSE LSTCURSOR; SQL> CLOSE TBLCURSOR; SQL> COMMIT;
例6: INSERT文のPLACEMENT ONLY RETURNING DBKEY句の使用
SQL> INSERT INTO EMPLOYEES cont> (EMPLOYEE_ID, LAST_NAME, FIRST_NAME) cont> VALUES cont> ('5000', 'Parsons', 'Diane') cont> PLACEMENT ONLY RETURNING DBKEY; DBKEY 56:34:-1 1 row allocated SQL>
例7: 選択した列のデフォルト値の挿入
SQL> INSERT INTO DEPARTMENTS cont> (DEPARTMENT_CODE, DEPARTMENT_NAME, BUDGET_ACTUAL) cont> VALUES cont> ('RECR','Recreation', DEFAULT); 1 row inserted SQL> SELECT * FROM DEPARTMENTS WHERE DEPARTMENT_CODE='RECR'; DEPARTMENT_CODE DEPARTMENT_NAME MANAGER_ID BUDGET_PROJECTED BUDGET_ACTUAL RECR Recreation NULL NULL NULL 1 row selected
例8: 表へのすべてのデフォルト値の行の挿入
SQL> INSERT INTO CANDIDATES cont> DEFAULT VALUES; 1 row inserted SQL> SELECT * FROM CANDIDATES cont> WHERE LAST_NAME IS NULL; LAST_NAME FIRST_NAME MIDDLE_INITIAL CANDIDATE_STATUS RESUME NULL NULL NULL NULL >> >> >> NULL 1 row selected
特別なアプリケーション・コードを必要とせずに、テキスト・ファイルまたはバイナリ・ファイルからLIST OF BYTE VARYINGデータ型の列をロードします。指定したファイルがオープンし、各行が読み取られて、リスト・カーソルで指定されたLIST OF BYTE VARYING列に格納されます。
INSERT文は、対話型SQLでのみ使用できます。

AS BINARY
AS CHARACTER VARYING
AS TEXT
FILENAME句で指定したファイルに次のデータ型を含めるかどうかを指定します。
- BINARY
イメージ・ファイルやオーディオ・ファイルなど、書式設定されていないデータのロードに使用します。データのコンテンツは、INSERTの実行中に512オクテットのセグメントに分割されます。- CHARACTER VARYING
テキストのロードに使用しますが、終端文字は含まれません。テキストのコンテンツの書込みは、1セグメントにつき1行で行われます。- TEXT
テキストのロードに使用され、ロードされる各セグメントに終端文字が追加されます。テキストのコンテンツの書込みは1セグメントにつき1行で行われ、末尾の終端文字の改行(CR、LF)が含まれます。
FILENAME filespec
LIST OF BYTE VARYING列にロードするファイルの仕様です。INSERT INTO CURSOR cursor-name
リスト・セグメントを追加するターゲット・リスト・カーソルの名前です。
- INSERT from FILENAME文を使用してリスト・セグメントに値を割り当てるときは、次の点に留意してください。
- 現在のトランザクションが読取り/書込みである必要があります。
- カーソルでは挿入専用のリスト・カーソルを指定する必要があります。
- 対話型SQLでは、挿入されたセグメントの数と最大長もレポートされます。この出力を無効にするには、SET DISPLAY NO ROW COUNT文を使用します。
- TEXTのソースおよびCHARACTER VARYINGのソースは、最大で65500バイト長のセグメントを含むことができます。以前のリリースでは、この上限は512オクテットでした。
例1: テキスト・ファイルのデータを使用した新規行の追加
SQL> -- Declare a table cursor. SQL> DECLARE TABLE_CURSOR cont> INSERT ONLY TABLE CURSOR cont> FOR SELECT * FROM RESUMES; SQL> -- Open table cursor and insert values. SQL> OPEN TABLE_CURSOR; cont> INSERT INTO CURSOR TABLE_CURSOR cont> VALUES ('10065', NULL); 1 row inserted SQL> -- Declare a list cursor. SQL> DECLARE LIST_CURSOR cont> INSERT ONLY LIST CURSOR cont> FOR SELECT RESUME WHERE CURRENT OF TABLE_CURSOR; SQL --Open list cursor. SQL> OPEN LIST_CURSOR; SQL> --Load text from file into LIST OF BYTE VARYING column. SQL> INSERT INTO CURSOR LIST_CURSOR cont> FILENAME 'resume_10065.sql' AS TEXT; SQL> CLOSE LIST_CURSOR; SQL> CLOSE TABLE_CURSOR; SQL> COMMIT;
データベースまたはリポジトリの定義変更に対応するデータベースおよびリポジトリを定義します。INTEGRATE文では、データベース・ファイルから指定したリポジトリにコピーして、リポジトリでデータベース定義を作成できます。
INTEGRATE文は、対話型SQLでのみ発行できます。
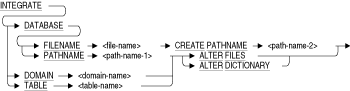

DATABASE FILENAME file-name CREATE PATHNAME path-name-2
既存のデータベース・システム・ファイルの定義を初めてリポジトリに格納します。例6-3を参照してください。PATHNAMEを指定しなかった場合や、データベースの作成時にリポジトリをインストールしなかった場合は、INTEGRATE DATABASE FILENAME句を使用します。INTEGRATE DATABASE FILENAME句を使用する場合は、パス名で指定されているリポジトリ・データベースのノードが存在しない必要があります。指定するパス名による古いリポジトリ定義が存在する場合は、別のリポジトリ・パス名を指定して、新しいデータベース定義を他の場所に置きます。
file-name句は、データベース定義のソースを指定する完全なファイル仕様または部分的なファイル仕様です。ファイル拡張子を指定する必要はありません。データベース・システムでは、.rdbファイル拡張子で終わるデータベース・ルート・ファイルが自動的に使用されます。
Path-name-2は、(ソースとしてデータベース・システム・ファイルを使用して)INTEGRATE文がデータベース定義を作成するリポジトリのリポジトリ・パス名です。リポジトリ・パス名としてフルパス名または相対パス名のいずれかを指定できます。データベース自体の名前ではなく、パス名を指定する必要があります。
DATABASE PATHNAME path-name-1 ALTER FILES
CREATE TABLE FROM文またはCREATE DOMAIN FROM文で作成した表定義およびドメイン定義を変更して、リポジトリのソースと一致するようにします。INTEGRATE...ALTER FILES文は、FROM句で作成されていない定義には影響を与えません。これは、データベース・ファイル定義がリポジトリの定義と一致しなくなった場合に便利です。例6-1を参照してください。Path-name-1は、データベースの定義変更のソースであるリポジトリ・データベースのリポジトリ・パス名です。リポジトリ・パス名としてフルパス名または相対パス名のいずれかを指定できます。
注意
データベース・ファイル定義がリポジトリで定義されていない場合、ALTER FILES句を使用すると、データベース・ファイル定義に関連付けられているデータが破壊される場合があります。その場合は、実際のデータを失います。このため、ALTER FILES句を使用するときは十分に注意してください。
DATABASE PATHNAME path-name-1 ALTER DICTIONARY
データベースのデータベース定義と一致するようにディクショナリのデータベース定義を変更します。これは、リポジトリの定義がデータベース・ファイル定義と一致しなくなった場合に便利です。例6-2を参照してください。ただし、リポジトリのデータベース定義を変更すると、その定義を参照している他のアプリケーションに影響する場合があるので注意してください。リポジトリはすでに存在している必要があり、定義が含まれている場合があります。
Path-name-1は、ソースとしてデータベース・ファイルの定義を使用してSQLによって変更される、リポジトリ・データベースのリポジトリ・パス名です。リポジトリ・パス名としてフルパス名または相対パス名のいずれかを指定できます。
DOMAIN domain-name ALTER FILES
データベースのドメイン定義を変更して、リポジトリのフィールド定義と一致させます。ドメイン定義がリポジトリで変更されると、ドメイン、およびドメインに基づく列、およびドメインを含む表により参照される照合順番も変更される場合があります。DOMAIN domain-name ALTER DICTIONARY
リポジトリのフィールド定義を変更して、データベースのドメイン定義と一致させます。フィールド定義がデータベースで変更されると、ドメイン、およびドメインに基づく列、およびドメインを含む表により参照される照合順番も変更される場合があります。TABLE table-name ALTER FILES
データベースの表定義を変更して、リポジトリのレコード定義と一致させます。表定義がレポジトリで変更されると、表を参照するまたは表により参照される他のオブジェクトも変更される場合があります。これらのオブジェクトには次のものがあります。
- ドメイン
- 照合順番
- 他の被参照表および被参照列
- 外部キー制約およびチェック制約
- 索引
- 表を参照するビュー
- 索引によって参照される記憶域マップと記憶域
TABLE table-name ALTER DICTIONARY
リポジトリのレコード定義を変更して、データベースの表定義と一致させます。レコード定義がデータベースで変更されると、表を参照するまたは表により参照される他のオブジェクトも変更される場合があります。これらのオブジェクトには次のものがあります。
- フィールド
- 照合順番
- 他の被参照レコードおよび被参照フィールド
- 外部キー制約およびチェック制約
- 索引
- INTEGRATE文の入力後にトランザクションをコミットする必要があります。
- INTEGRATE DATABASE文は、暗黙的なデータベースのアタッチを実行します。
- INTEGRATE DOMAIN文およびINTEGRATE TABLE文の使用時には、パス名によるアタッチを実行してドメインと表を統合する必要があります。
- INTEGRATE DOMAIN文またはINTEGRATE TABLE文で指定したドメインまたは表を統合するには、これらのドメインまたは表がリポジトリとデータベースの両方に存在している必要があります。指定したドメインまたは表が存在しない場合は、エラーが返されます。
- INTEGRATE DOMAIN ALTER DICTIONARY文またはINTEGRATE TABLE ALTER DICTIONARY文で指定したドメイン名または表名は、Oracle CDD/Repositoryのパス名ではなくOracle Rdbの有効なドメイン名と表名です。
例6-1は、ALTER FILES句を使用したINTEGRATE文の使用方法を示しています。この例では、フィールド(ドメイン)がリポジトリで定義されます。次に、SQLを使用して、このリポジトリ定義に基づく表を作成します。その後、リポジトリ定義が変更されて、データベース・ファイルとリポジトリで定義が一致しなくなります。INTEGRATE文は、ソースとしてリポジトリ定義を使用してデータベース定義を変更することにより、この状況を解決します。
例6-1 リポジトリ定義を使用したデータベース・ファイルの更新
$ ! $ ! Define CDD$DEFAULT $ ! $ DEFINE CDD$DEFAULT SYS$COMMON:[REPOSITORY]CATALOG $ ! $ ! Enter the CDO to create new field and record definitions: $ ! $ REPOSITORY CDO> ! CDO> ! Create two field (domain) definitions in the repository: CDO> ! CDO> DEFINE FIELD PART_NUMBER DATATYPE IS WORD. CDO> DEFINE FIELD PRICE DATATYPE IS WORD. CDO> ! CDO> ! Define a record called INVENTORY using the two CDO> ! fields previously defined: CDO> ! CDO> DEFINE RECORD INVENTORY. CDO> PART_NUMBER. CDO> PRICE. CDO> END RECORD INVENTORY. CDO> ! CDO> EXIT $ ! $ ! Enter SQL: $ ! $ SQL SQL> ! SQL> ! In SQL, create the database ORDERS: SQL> ! SQL> CREATE DATABASE ALIAS ORDERS PATHNAME ORDERS; SQL> ! SQL> ! Create a table in the database ORDERS using the SQL> ! INVENTORY record (table) just created in the repository: SQL> ! SQL> CREATE TABLE FROM SYS$COMMON:[REPOSITORY]CATALOG.INVENTORY cont> ALIAS ORDERS; SQL> ! SQL> ! Use the SHOW TABLE statement to see information about SQL> ! INVENTORY the table: SQL> ! SQL> SHOW TABLE ORDERS.INVENTORY Information for table ORDERS.INVENTORY CDD Pathname: SYS$COMMON:[REPOSITORY]CATALOG.INVENTORY;1 Columns for table ORDERS.INVENTORY: Column Name Data Type Domain ----------- --------- ------ PART_NUMBER SMALLINT ORDERS.PART_NUMBER PRICE SMALLINT ORDERS.PRICE . . . SQL> COMMIT; SQL> EXIT $ ! $ ! Enter CDO again: $ ! $ REPOSITORY CDO> ! CDO> ! Verify that the fields PART_NUMBER and PRICE are cdo> ! in the record INVENTORY: CDO> ! CDO> SHOW RECORD INVENTORY Definition of record INVENTORY | Contains field PART_NUMBER | Contains field PRICE CDO> ! CDO> ! Define the fields VENDOR_NAME and QUANTITY. Add them to CDO> ! the record INVENTORY using the CDO CHANGE RECORD command. Now, the CDO> ! definitions used by the database no longer match the definitions CDO> ! in the respository, as the CDO message indicates: CDO> ! CDO> DEFINE FIELD VENDOR_NAME DATATYPE IS TEXT 20. CDO> DEFINE FIELD QUANTITY DATATYPE IS WORD. CDO> ! CDO> CHANGE RECORD INVENTORY. CDO> DEFINE VENDOR_NAME. CDO> END. CDO> DEFINE QUANTITY. CDO> END. CDO> END INVENTORY RECORD. %CDO-I-DBMBR, database SQL_USER:[PRODUCTION]CATALOG.ORDERS(1) may need to be INTEGRATED CDO> ! CDO> ! Use the SHOW RECORD command to see if the fields VENDOR_NAME CDO> ! and QUANTITY are part of the INVENTORY record: CDO> ! CDO> SHOW RECORD INVENTORY Definition of record INVENTORY | Contains field PART_NUMBER | Contains field PRICE | Contains field VENDOR_NAME | Contains field QUANTITY CDO> ! CDO> EXIT $ ! $ ! Enter SQL again: $ ! $ SQL SQL> ! SQL> ! Use the INTEGRATE ... ALTER FILES statement to update SQL> ! the definitions in the database file, using the repository definitions SQL> ! as the source. Note the INTEGRATE statement implicitly attaches to SQL> ! the database. SQL> ! SQL> INTEGRATE DATABASE PATHNAME SYS$COMMON:[REPOSITORY]CATALOG.ORDERS cont> ALTER FILES; SQL> ! SQL> ! Use the SHOW TABLE statement to see if the table INVENTORY has SQL> ! changed. SQL has added the VENDOR_NAME and QUANTITY domains SQL> ! to the database file: SQL> ! SQL> SHOW TABLE INVENTORY Information for table INVENTORY CDD Pathname: SYS$COMMON:[REPOSITORY]CATALOG.INVENTORY;1 Columns for table INVENTORY: Column Name Data Type Domain ----------- --------- ------ PART_NUMBER SMALLINT PART_NUMBER PRICE SMALLINT PRICE VENDOR_NAME CHAR(20) VENDOR_NAME QUANTITY SMALLINT QUANTITY . . . SQL> COMMIT; SQL> EXIT
