| Oracle TimesTen In-Memory Database C開発者およびリファレンス・ガイド
リリース7.0 E05164-03 |
|


 前へ |
 次へ |
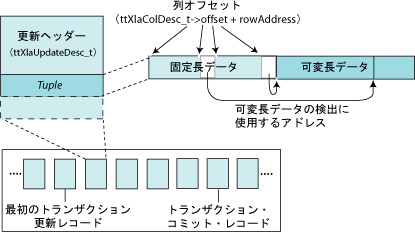
更新レコードでは、0(ゼロ)から2行の行がttXlaUpdateDesc_t構造体の後に返される場合があります(「レコード・ヘッダーの確認および行アドレスの検出」を参照)。図3.8に示すように、各行のデータの最初の部分は固定長で、その後に可変長データが続きます。
列データを確認する手順は次のとおりです。
返された行から列値を読み取るには、まず、その行の各列のオフセットを判別する必要があります。列オフセットおよびその他の列メタデータは、特定の表に対してttXlaGetColumnInfo 関数をコールすると取得できます。この関数は表の列ごとに個別のttXlaColDesc_t構造体を返します。ttXlaGetColumnInfo関数は、初期化プロシージャの一部としてコールする必要があります。このコールについては、この項で詳細を説明しているため、「XLAの初期化およびXLAハンドルの取得」での説明では省略されています。
ttXlaGetColumnInfoをコールする場合は、colinfoパラメータを指定して、返されるttXlaColDesc_t構造体のリストを保持するバッファへのポインタを作成します。バッファのサイズは、maxcolsパラメータを使用して定義します。
次に示すxlaSimple.cデモのコード例では、返される列の最大数(MAX_XLA_COLUMNS)を推測します。これは、返されるttXlaColDesc_t構造体を保持するバッファのサイズ(xla_column_defs)を設定します。maxcolsパラメータを設定する場合のもう1つのより正確な方法として、ttXlaGetTableInfo関数をコールした後で、ttXlaTblDesc_t→columnsに返された値を使用する方法があります(install_dir/demo/xla/xlaPersistent/subscriber.c.のinitialize関数を参照)。
#define MAX_XLA_COLUMNS 128
SQLINTEGER ncols;
ttXlaColDesc_t xla_column_defs[MAX_XLA_COLUMNS];
rc = ttXlaGetColumnInfo(xla_handle, SYSTEM_TABLE_ID, userID,
xla_column_defs, MAX_XLA_COLUMNS, &ncols);
if (rc != SQL_SUCCESS) {
/* 「XLAエラーの処理」を参照*/
}
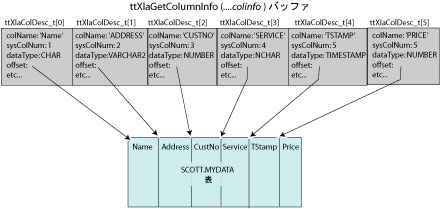
図3.9に示すように、ttXlaGetColumnInfo関数は次の情報を出力します。
ttXlaGetColumnInfo によって返される各ttXlaColDesc_t 構造体には、その列のオフセット位置を記述するoffset 値が含まれます。列データを読み込む際にこのoffset値をどのように使用するかは、列が固定長データ(CHAR、NCHAR、INTEGER、BINARY、DOUBLE、FLOAT、DATE、TIME、TIMESTAMPなど)を含んでいるか、可変長データ(VARCHAR、NVARCHAR、VARBINARYなど)を含んでいるかによって異なります。
固定長列データの場合、列のアドレスは、ttXlaColDesc_t構造体のoffset値に行のアドレスを追加したものです。
SCOTT.MYDATA表の最初の列はCHAR型です。HandleChange関数(例3.4)で前に取得したtup1行のアドレス、およびttXlaGetColumnInfo関数(例3.5を参照)によって返された最初のttXlaColDesc_t構造体のoffsetを使用する場合は、次のように計算して最初の列の値を取得します。
char * Column1;
Column1 = ((unsigned char*) tup1 + xla_column_defs[0].offset);
| 注意: | XLAによって返される文字列はヌル文字では終了されません。文字列をヌル文字で終了する方法については、「返された文字列のヌル文字での終了」を参照してください。 |
SCOTT.MYDATA表の3番目の列はINTEGER型です。3番目のttXlaColDesc_t構造体のoffsetを使用し、値を検出して整数として再キャストします(データが適切に配置されます)。
int Column3;
Column3 = *((int*) ((unsigned char*) tup +
xla_column_defs[2].offset));
SCOTT.MYDATA表の4番目の列はNCHAR型です。4番目のttXlaColDesc_t構造体のoffsetを使用し、値を検出してSQLWCHAR型として再キャストできます。
SQLWCHAR * Column4;
Column4 = (SQLWCHAR*) ((unsigned char*) tup +
xla_column_defs[3].offset);
前述の例で取得した列値とは異なり、Column4は2バイトのUnicode文字の配列を指します。文字列を取得するには、例3.16のSQL_WCHARの場合のように、この配列内の各要素に対して繰り返し実行する必要があります。
その他の固定長データ型は、対応するCの型にキャストできます。複合固定長データ型(DATE、TIME、DECIMAL値など)は、TimesTenの内部形式で格納されますが、アプリケーションでXLA変換関数を使用して、対応するODBC C値に変換できます(「複合データ型の変換」を参照)。
NOT INLINE可変長データ(VARCHAR、NVARCHARおよびVARBINARY)の場合、ttXlaColDesc_t→offsetにあるデータは、返された行の可変長部分でのデータの場所を指す4バイトのオフセット値です。オフセット値にオフセット・アドレスを追加して、行の可変長部分の列データのアドレスを取得できます。この場所の最初のnバイト(nは、32ビット・プラットフォームでは4、64ビット・プラットフォームでは8)はデータの長さです。この後に実際のデータが続きます。可変長データの場合、ttXlaColDesc_t→size の値は、列の許容最大サイズです。図3.11に、行内のNOT INLINE可変長データを検出する方法を示します。
SCOTT.MYDATA表の例で、返された行(tup1)の2番目の列はVARCHAR型です。行内の可変長データを検出するには、まず図3.11に示すように、行の固定長部分で列のttXlaColDesc_t→offsetの値を検出します。このアドレスの値は、行の可変長部分のデータの4バイトのオフセットです(VarOffset)。次に、VarOffsetのアドレスにVarOffsetオフセット値を追加して、可変長列データの先頭へのポインタを取得します(DataLength)。32ビット・プラットフォームで処理が行われると想定すると、DataLength位置の最初の4バイトがデータの長さです。DataLengthの後の次のバイトが、実際のデータの先頭です(Column2)。
| 注意: | この例では、32ビット・プラットフォームで処理が行われると想定しているため、DataLengthは32ビット・タイプとして初期化されます。64ビット・プラットフォームでは、DataLengthを64ビット・タイプとして初期化する必要があります。Column2データはオフセット・アドレスDataLengthの後に64ビット+ 1で書き込まれます。 |
void * VarOffset; /* offset of data */
long * DataLength; /* length of data */
char * Column2; /* pointer to data */
VarOffset = (void*) ((unsigned char*) tup1 +
xla_column_defs[1].offset);
/*
* If column is out-of-line, pColVal points to an offset
* else column is inline so pColVal points directly to the string length.
*/
if (xla_column_defs[1].flags & TT_COLOUTOFLINE)
DataLength = (long*)((char*)VarOffset + *((int*)VarOffset));
else
DataLength = (long*)VarOffset;
Column2 = (char*)(DataLength+1);
VARBINARY型は、VARCHAR型での方法とほぼ同じ方法で処理されます。Column2は、NVARCHAR型の場合、SQLWCHARとして初期化し、前述のVARCHARの場合と同様に値を取得し、次に例3.16のNCHAR値CharBufの場合と同様にColumn2配置に対して繰り返し実行できます。
レコードの行データから返される文字列はNULL文字では終了されません。文字列をバッファにコピーし、その文字列の最後の文字の後にNULL文字を追加すると、文字列をNULL文字で終了できます。
文字列をヌル文字で終了する手順は、文字列が固定長の場合と可変長の場合で少し異なります。例3.10に、固定長文字列をヌル文字で終了する手順を示します。例3.11にはサイズがわかっている可変長文字列をヌル文字で終了する場合の手順、例3.12にはサイズがわかっていない可変長文字列を終了する場合の手順を示します。
例3.6で返された固定長CHAR(10) Column1文字列をヌル文字で終了するには、文字列+ヌル文字を保持できる十分な大きさのバッファを設定します。次に、ttXlaColDesc_t→sizeから文字列のサイズを取得し、文字列をバッファにコピーして、文字列の末尾をヌル文字で終了します。これで、バッファの内容を使用できます。この例では、文字列を出力します。
char buffer[10+1];
int size;
size = xla_column_defs[0].size;
memcpy(buffer, Column1, size);
buffer[size] = (char)NULL;
printf(" Row %s is %s\n",
((unsigned char*) xla_column_defs[0].colName),
buffer);
可変長文字列をヌル文字で終了する手順は、固定長文字列の手順とほぼ同じです。可変長データのオフセットの先頭にある値は、文字列のサイズのみです(NOT INLINE可変長列データの読取りを参照)。
例3.9で取得したColumn2文字列がVARCHAR(32)の場合、文字列+ヌル文字を保持できる十分な大きさのバッファを設定します。DataLengthオフセットにある値を使用して文字列のサイズを設定します。
char buffer[32+1];
memcpy(buffer, Column2, *DataLength);
buffer[*DataLength] = (char)NULL;
printf(" Row %s is %s\n",
((unsigned char*) xla_column_defs[1].colName),
buffer);
すべてのデータ型を読み取るための汎用コードを記述する場合は、返される文字列のサイズを想定できません。サイズがわからない文字列に対しては、返された文字列の大部分を保持できる十分な大きさのバッファを静的に割り当てます。返された文字列がバッファより大きい場合は、例3.12に示すように、正しいサイズのバッファを動的に割り当てます。
例3.9で取得したColumn2文字列のサイズがわからない場合は、最大10000文字の文字列を保持できる十分な大きさのバッファを静的に割り当てます。その後、可変長データ・オフセットの先頭で取得したDataLength値が、バッファのサイズより小さいことを確認します。文字列がバッファより大きい場合は、mallocを使用してバッファを正しいサイズに動的に割り当てます。
#define STACKBUFSIZE 10000
char VarStackBuf[STACKBUFSIZE];
char * buffer;
buffer = (*DataLength+1 <= STACKBUFSIZE) ? VarStackBuf :
malloc(*DataLength+1);
memcpy(buffer,Column2,*DataLength);
buffer[*DataLength] = (char)NULL;
printf(" Row %s is %s\n",
((unsigned char*) xla_column_defs[1].colName),
buffer);
if (buffer != VarStackBuf) /* buffer was allocated */
free(buffer);
TT_DATE、TT_TIME、TT_DECIMAL値などの複合データ型は、TimesTenの内部形式で保存されます。これらはXLA変換関数を使用して、対応するODBC C値に変換できます。表3.2に、XLAデータ型変換関数の説明を示します。
これらの変換関数は、ttXlaUpdateDesc_t型(UPDATETUP、INSERTTUPおよびDELETETUP)に含まれる行データで使用できます。
HandleChange関数(例3.4を参照)で取得したtup1行のアドレス、およびttXlaGetColumnInfo 関数(例3.5を参照)によって返された5番目のttXlaColDesc_t構造体のoffsetを使用すると、TIMESTAMP型の列値を検出できます。ttXlaTimeStampToODBCCType関数を使用し、TimesTen形式から列データを変換し、変換されたTIME値をODBC TIMESTAMP_STRUCTに保存します。この例では、値を出力します。
void * Column5;
TIMESTAMP_STRUCT timestamp;
Column5 = (void*) ((unsigned char*) tup1 +
xla_column_defs[4].offset);
rc = ttXlaTimeStampToODBCCType(Column5, ×tamp);
if (rc != SQL_SUCCESS) {
/*「XLAエラーの処理」を参照*/
}
printf(" %s: %02d-%02d-%02d %02d:%02d:%02d.%06d\n",
((unsigned char*) xla_column_defs[i].colName),
timestamp.year,timestamp.month, timestamp.day,
timestamp.hour,timestamp.minute,timestamp.second,
timestamp.fraction);
HandleChange関数(例3.4を参照)で取得したtup1行のアドレス、およびttXlaGetColumnInfo 関数(例3.5を参照)によって返された6番目のttXlaColDesc_t 構造体のoffsetを使用すると、DECIMAL型の列値を検出できます。ttXlaDecimalToCString関数を使用して、TimesTenのDECIMAL形式から文字列に列データを変換します。この例では、値を出力します。
char decimalData[50];
Column6 = (float*) ((unsigned char*) tup +
xla_column_defs[5].offset);
precision = (short) (xla_column_defs[5].precision);
scale = (short) (xla_column_defs[5].scale);
rc = ttXlaDecimalToCString(Column6, (char*)&decimalData,
precision, scale);
if (rc != SQL_SUCCESS) {
/* 「XLAエラーの処理」を参照*/
}
printf(" %s: %s\n",
((unsigned char*) xla_column_defs[5].colName),
decimalData);
NULL値を指定可能な列では、ttXlaColDesc_t→nullOffset はレコードのNULLバイトを指します。nullOffsetは、列がNULLである場合は1、NULLでない場合は0(ゼロ)となります。
列値がNULLであるかどうかを判断するには、まずnullOffsetが0(ゼロ)かどうかを確認します。0の場合は、NULL値可能ではありません。nullOffsetがNULL値可能である場合は、nullOffsetの値が1か0かを確認します。
Column6がNULLであるかどうかを確認するには、次のように入力します。
if (xla_column_defs[5].nullOffset != 0) {
if (*((unsigned char*) tup +
xla_column_defs[5].nullOffset) == 1) {
printf("Column6 is NULL\n");
}
}
例3.16に示すように、前述のすべての列確認コードをPrintColValues関数にまとめてみます。この例では、各列のttXlaColDesc_t→dataType を確認し、データ型がCHAR、NCHAR、INTEGER、TIMESTAMP、DECIMAL、およびVARCHARである列を検出して、その値を出力します。これは、この例でのみ使用する方法です。読み取る列を識別する方法およびその結果への対応は、ユーザーが決定できます。たとえば、別の方法として、ttXlaColDesc_t→ColNameの値を確認して、名前で特定の列を検出する方法もあります。
まず、ttXlaColDesc_t→NullOffset を調べて列がNULLかどうかを確認します。次に、ttXlaColDesc_t→dataTypeのフィールドを調べて列のデータ型を確認します。単純な固定長データ(CHAR、NCHARおよびINTEGER)の場合は、ttXlaColDesc_t→offset にある値を適切なCの型にキャストします。複合データ型TIMESTAMPおよびDECIMALは、XLA変換関数ttXlaTimeStampToODBCCTypeおよびttXlaDecimalToCStringを使用して、TimesTen形式からODBC C値に変換されます。
可変長データ(VARCHAR)の場合は、行の可変長部分でデータを検出します(「NOT INLINE可変長列データの読取り」を参照)。
| 注意: | この関数は、長さが最大50バイトのCHARおよびVARCHARの文字列を処理します。NCHAR文字は、ASCIIキャラクタ・セットに属している必要があります。 |
void PrintColValues(void * tup)
{
SQLRETURN rc;
SQLINTEGER native_error;
void * pColVal;
char buffer[50+1]; /* No strings over 50 bytes */
int i, j, size;
for (i = 0; i < ncols; i++) /* ncols from ttXlaGetColumnInfo */
{
if (xla_column_defs[i].nullOffset != 0) { /* Is col NULL? */
if (*((unsigned char*) tup +
xla_column_defs[i].nullOffset) == 1) { /* If so... */
printf(" %s: NULL\n",
((unsigned char*) xla_column_defs[i].colName));
continue; /* Skip rest and re-loop */
}
}
固定長データ型を処理する場合:
/* For INTEGER, recast as int */
if (xla_column_defs[i].dataType == TTXLA_INTEGER) {
printf(" %s: %d\n",
((unsigned char*) xla_column_defs[i].colName),
*((int*) ((unsigned char*) tup +
xla_column_defs[i].offset)));
}
/* For CHAR, just get value and null-terminate string */
else if (xla_column_defs[i].dataType == TTXLA_CHAR) ||
xla_column_defs[i].dataType == TTXLA_CHAR_TT) {
pColVal = (void*) ((unsigned char*) tup +
xla_column_defs[i].offset);
memcpy(buffer, pColVal, xla_column_defs[i].size);
buffer[xla_column_defs[i].size] = (char)NULL;
printf(" %s: %s\n",
((unsigned char*) xla_column_defs[i].colName),
buffer);
}
/* For NCHAR, recast as SQLWCHAR.
NCHAR strings must be parsed one character at a time */
else if (xla_column_defs[i].dataType == TTXLA_NCHAR) ||
xla_column_defs[i].dataType == TTXLA_NCHAR_TT) {
SQLWCHAR * CharBuf;
CharBuf = (SQLWCHAR*) ((unsigned char*) tup +
xla_column_defs[i].offset);
printf(" %s: ",
((unsigned char*) xla_column_defs[i].colName));
for (j = 0; j < xla_column_defs[i].size / 2; j++)
{
printf("%c", CharBuf[j]);
}
printf("\n");
}
可変長データ型を処理する場合:
/* For VARCHAR, locate value at its variable-length offset
and null-terminate.*/
/* VARBINARY types are handled in a similar manner. */
/* For NVARCHAR2, initialize 'var_data' as a SQLWCHAR, get
the value as shown below, then iterate through 'var_len'
as shown for NCHAR above */
else if (xla_column_defs[i].dataType == TTXLA_VARCHAR) {
long * var_len;
char * var_data;
pColVal = (void*) ((unsigned char*) tup + xla_column_defs[i].offset);
/* If column is out-of-line, pColVal points to an offset
* else column is inline so pColVal points directly to the string length. */
if (xla_column_defs[i].flags & TT_COLOUTOFLINE)
var_len = (long*)((char*)pColVal + *((int*)pColVal));
else
var_len = (long*)pColVal;
var_data = (char*)(var_len+1);
memcpy(buffer,var_data,*var_len);
buffer[*var_len] = '\0';
printf(" %s: %s\n",
((unsigned char*) xla_column_defs[i].colName),
buffer);
}
XLA変換メソッドを使用して複合データ型を変換する場合:
/* Read and convert a TTXLA_TIMESTAMP_TT value
* to an ODBC C value. */
else if (xla_column_defs[i].dataType == TTXLA_TIMESTAMP_TT) {
TIMESTAMP_STRUCT timestamp;
pColVal = (void*) ((unsigned char*) tup +
xla_column_defs[i].offset);
rc = ttXlaTimeStampToODBCCType(pColVal, ×tamp);
if (rc != SQL_SUCCESS) {
/* 「XLAエラーの処理」を参照*/
}
printf(" %s: %02d-%02d-%02d %02d:%02d:%02d.%06d\n",
((unsigned char*) xla_column_defs[i].colName),
timestamp.year,timestamp.month, timestamp.day,
timestamp.hour,timestamp.minute,
timestamp.second,timestamp.fraction);
}
/* Read and convert a TTXLA_TIMESTAMP value to an ODBC
* timestamp. */
else if (xla_column_defs[i].dataType == TTXLA_TIMESTAMP) {
TIMESTAMP_STRUCT timestamp;
pColVal = (void*) ((unsigned char*) tup +
xla_column_defs[i].offset);
rc = ttXlaOraTimeStampToODBCTimeStamp(pColVal, ×tamp);
if (rc != SQL_SUCCESS) {
}
printf(" %s: %02d-%02d-%02d %02d:%02d:%02d.%09d\n",
((unsigned char*) xla_column_defs[i].colName),
timestamp.year,timestamp.month, timestamp.day,
timestamp.hour,timestamp.minute,
timestamp.second,timestamp.fraction);
}
/* Read and convert a TTXLA_DATE value to an ODBC timestamp */
else if (xla_column_defs[i].dataType == TTXLA_DATE) {
TIMESTAMP_STRUCT timestamp;
pColVal = (void*) ((unsigned char*) tup +
xla_column_defs[i].offset);
rc = ttXlaOraDateToODBCTimeStamp(pColVal, ×tamp);
if (rc != SQL_SUCCESS) {
}
printf(" %s: %02d-%02d-%02d %02d:%02d:%02d\n",
((unsigned char*) xla_column_defs[i].colName),
timestamp.year,timestamp.month, timestamp.day,
timestamp.hour,timestamp.minute);
}
/* Read and convert a TTXLA_NUMBER value to a string. */
else if (xla_column_defs[i].dataType == TTXLA_NUMBER) {
/* 65 is max buffer size needed for number-to-char conversion */
char buf[65];
int outlen;
pColVal = (void*) ((unsigned char*) tup +
xla_column_defs[i].offset);
rc = ttXlaNumberToCString(pColVal, buf, sizeof(buf), &outlen);
if (rc != SQL_SUCCESS) {
}
printf("%s: %s\n",
((unsigned char*) xla_column_defs[i].colName),
buf);
}
/* Read and convert a TTXLA_DECIMAL_TT value to a string. */
else if (xla_column_defs[i].dataType == TTXLA_DECIMAL_TT) {
char decimalData[50];
short precision, scale;
pColVal = (float*) ((unsigned char*) tup +
xla_column_defs[i].offset);
precision = (short) (xla_column_defs[i].precision);
scale = (short) (xla_column_defs[i].scale);
rc = ttXlaDecimalToCString(pColVal,
(char*)&decimalData,
precision, scale);
if (rc != SQL_SUCCESS) {
}
printf(" %s: %s\n",
((unsigned char*) xla_column_defs[i].colName),
decimalData);
}
} /* End FOR loop */
}