Daten mit einem Datenfluss aufnehmen und transformieren
Ein Datenfluss ist ein logisches Diagramm, das den Fluss der Daten von Quelldatenassets, wie einer Datenbank oder Flat File, zu Zieldatenassets darstellt, wie einem Data Lake oder Data Warehouse.
Der Datenfluss von Quelle zu Ziel kann eine Reihe von Transformationen durchlaufen, um die Daten zu aggregieren, zu bereinigen und zu modellieren. Data Engineers und ETL-Entwickler können dann Insights analysieren oder erfassen und diese Daten nutzen, um weitreichende Geschäftsentscheidungen zu treffen.
In diesem Tutorial führen Sie die folgenden Schritte aus:
- Erstellen Sie ein Projekt, in dem Sie den Datenfluss speichern können.
- Fügen Sie Quelloperatoren hinzu, und wählen Sie die Datenentitys aus, die im Datenfluss verwendet werden sollen.
- Verwenden Sie Modellierungsoperatoren, und wenden Sie Transformationen an.
- Identifizieren Sie das Zieldatenasset zum Laden der Daten.
Bevor Sie beginnen
Damit Sie Daten mit einem Datenfluss aufnehmen und transformieren können, müssen folgende Voraussetzungen erfüllt sein:
- Zugriff auf einen Data Integration-Workspace. Siehe Verbindung zu Data Integration herstellen.
- Quell- und Zieldatenassets wurden erstellt.
-
Die Berechtigung
PAR_MANAGEmuss für den Staging Bucket aktiviert sein.allow any-user to manage buckets in compartment <compartment-name> where ALL {request.principal.type = 'disworkspace', request.principal.id = '<workspace-ocid>', request.permission = 'PAR_MANAGE'}Autonome Datenbanken verwenden Object Storage für das Staging von Daten und benötigen vorab authentifizierte Anforderungen.
1. Projekt und Datenfluss erstellen
In Oracle Cloud Infrastructure Data Integration können Datenflüsse und Aufgaben nur in einem Projekt oder Ordner erstellt werden.
So erstellen Sie ein Projekt und einen Datenfluss:
2. Quelloperatoren hinzufügen
Sie fügen Quelloperatoren hinzu, um die Datenentitys zu identifizieren, die für den Datenfluss verwendet werden sollen. Eine Datenentity stellt eine Datenbanktabelle in diesem Tutorial dar.
3. Daten filtern und transformieren
Der Filteroperator erstellt basierend auf einer Bedingung eine Teilmenge von Daten aus einem Upstreamoperator.
-
Verbinden Sie REVENUE mit FILTER_1:
- Setzen Sie den Cursor auf REVENUE.
- Ziehen Sie den Connector-Kreis neben REVENUE.

- Löschen Sie den Connector-Kreis auf FILTER_1.

Mit Data Xplorer können Sie ein Datenbeispiel explorieren, Profilingmetadaten prüfen und Transformationen auf der Registerkarte "Daten" des Bereichs "Eigenschaften" anwenden. Für jede angewendete Transformation werden der Leinwand Ausdrucksoperatoren hinzugefügt.
-
Wählen Sie das Transformationsmenü (
 ) für
) für FILTER_2.CUSTOMERS_JSON.STATE_PROVINCE, und wählen Sie Groß-/Kleinschreibung ändern aus.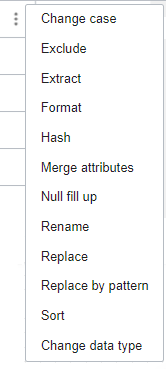
4. Daten verknüpfen
Nachdem Sie Filter und Transformationen angewendet haben, können Sie die Quelldatenentitys mit einer eindeutigen Kunden-ID verknüpfen und die Daten dann in eine Zieldatenentity laden.
5. Zieloperator hinzufügen
Zusätzlich Ressourcen
Weitere Informationen finden Sie unter
Weitere Schritte
Nachdem Sie Daten mit einem Datenfluss aufgenommen und transformiert wurden, erstellen Sie eine Integrationsaufgabe zur Konfiguration und Ausführung des Datenflusses.