Datenflüsse
Ein Datenfluss ist ein visuelles Programm, das den Datenfluss von Quelldatenassets (z.B. eine Datenbank oder Flat File) zu Zieldatenassets (z.B. ein Data Lake oder Data Warehouse) darstellt.
Auf den folgenden Seiten wird beschrieben, wie Sie Datenflüsse in Data Integration auflisten, erstellen und verwalten:
- Datenflüsse auflisten
- Datenflüsse erstellen
- Datenflussoperatoren verwenden
- Datenflussparameter verwenden
- Datenflüsse bearbeiten
- Entitys in einem Datenfluss aktualisieren
- Datenfluss verschieben
- Datenfluss duplizieren
- Datenfluss löschen
- Funktionsreferenz (Data Flow)
Der intuitive UI-Designer von Data Integration wird geöffnet, wenn Sie einen Datenfluss erstellen, anzeigen oder bearbeiten.
Einen allgemeinen Überblick über die grundlegenden Konzepte hinter dem interaktiven Designer finden Sie unter Designkonzepte. Sie können sich auch das interaktive Video zum Datenflussdesigner von Data Integration ansehen, um eine praktische Einführung in Datenflüsse zu erhalten.
Auf den folgenden Seiten wird beschrieben, wie Sie einen Datenfluss exportieren und importieren:
Designkonzepte
Sie sollten mit den folgenden Grundkonzepten bei Verwendung des interaktiven Designers in Data Integration vertraut sein.
Ein Schema definiert die Ausprägung der Daten in einem Quell- oder Zielsystem. Wenn Sie an einem Datenfluss in Data Integration arbeiten, tritt beim Ändern der Datendefinitionen eine Schemaabweichung auf.
Beispiel: Ein Attribut kann in der Quelle hinzugefügt oder entfernt werden, oder ein Attribut im Ziel kann umbenannt werden. Wenn Sie die Schemadrift nicht berücksichtigen, werden die ETL-Prozesse möglicherweise nicht erfolgreich ausgeführt, oder die Datenqualität kann verringert werden.
Standardmäßig übernimmt Data Integration die Schemaabweichung für Sie. Wenn Sie einen Quelloperator im Datenflussdesigner konfigurieren, klicken Sie nach Auswahl einer Datenentity auf die Registerkarte "Erweiterte Optionen" im Bereich "Eigenschaften". Das ausgewählte Kontrollkästchen "Schemaabweichung zulassen" gibt an, dass die Schemaabweichung aktiviert ist.
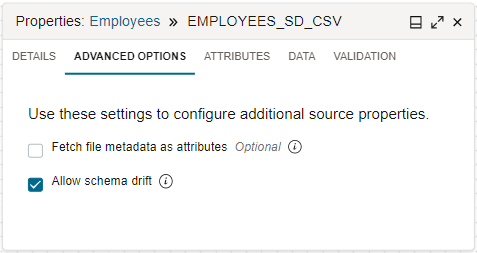
Wenn die Schemaabweichung aktiviert ist, kann Data Integration während der Entwurfszeit und Laufzeit des Datenflusses Schemadefinitionsänderungen in den angegebenen Datenentitys erkennen. Alle Änderungen werden automatisch übernommen, und das Schema wird angepasst, um neue Attribute, entfernte Attribute, unterschiedliche Attributnamen, geänderte Datentypen usw. aufzunehmen.
Wenn Sie das Kontrollkästchen {\b Allow Schema Drift} deaktivieren, werden die Schemadefinitionen bei der Definition des Datenflusses gesperrt. Wenn die Schemaabweichung deaktiviert ist, verwendet Data Integration eine feste Form der angegebenen Datenentity, auch wenn die zugrunde liegende Form geändert wurde.
Ohne Handling der Schemaabweichung können Datenflüsse anfällig für Upstream-Datenquellenänderungen werden. Mithilfe der Schemaabweichung werden Datenflüsse resilienter und können sich automatisch an Änderungen anpassen. Sie müssen die Datenflüsse nicht neu entwerfen, wenn Änderungen an der Schemadefinition auftreten.
Bei einer JSON-Datei ist die Schemaabweichung standardmäßig deaktiviert und kann nicht aktiviert werden, wenn ein benutzerdefiniertes Schema zum Inferenzieren der Entityausprägung verwendet wird. Wenn die Schemaabweichung verfügbar und aktiviert sein soll, bearbeiten Sie die JSON-Quelle in der Datenfluss- oder Data-Loader-Aufgabe, und deaktivieren Sie das Kontrollkästchen Benutzerdefiniertes Schema verwenden.
In Data Integration kann ein Datenvorgang in einem Datenfluss zur Verarbeitung an ein Quell- oder Zieldatensystem übergeben werden.
Beispiel: Ein Sortier- oder Filtervorgang kann im Quellsystem ausgeführt werden, während die Daten gelesen werden. Wenn sich eine der Quellen für einen Join-Vorgang in demselben System wie das Ziel befindet, kann der Datenvorgang an das Zielsystem übergeben werden.
Data Integration kann Pushdown in einem Datenfluss verwenden, wenn Sie relationale Datensysteme verwenden, die den Pushdown unterstützen. Die aktuelle Liste umfasst Oracle Databases, Oracle Autonomous AI Lakehouse, Oracle Autonomous AI Transaction Processing und MySQL.
Standardmäßig wird Data Integration Pushdown verwendet, wenn anwendbar. Wenn Sie einen Quelloperator im Datenflussdesigner konfigurieren, klicken Sie nach Auswahl einer Datenentity auf die Registerkarte "Erweiterte Optionen" im Bereich "Eigenschaften". Das ausgewählte Kontrollkästchen "Pushdown zulassen" gibt an, dass der Pushdown aktiviert ist.
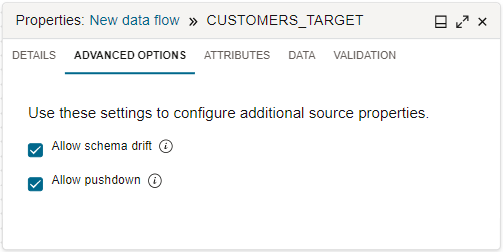
Wenn der Pushdown aktiviert ist, konvertiert Data Integration die anwendbare Datenvorgangslogik in SQL-Anweisungen, die dann direkt in der relationalen Datenbank ausgeführt werden. Durch das Übergeben der Datenverarbeitung an die Datenbank werden weniger Daten abgerufen und geladen.
Wenn Sie das Kontrollkästchen "Pushdown zulassen" deaktivieren, deaktivieren Sie den Pushdown. Wenn der Pushdown deaktiviert ist, ruft Data Integration alle Daten aus dem Quellsystem ab und verarbeitet die Daten in den Apache Spark-Clustern, die dem Workspace zugewiesen sind.
Da Data Integration Pushdown verwenden kann, wird die Performance aus folgenden Gründen verbessert:
- Die Verarbeitungsleistung der Datenbank wird genutzt.
- Weniger Daten werden zur Verarbeitung aufgenommen.
Je nach Optimierung kann Data Integration einen teilweisen oder vollständigen Pushdown in einem Datenfluss verwenden. Der Teil-Pushdown wird ausgeführt, wenn ein unterstütztes relationales Datensystem bei der Quelle oder dem Ziel verwendet wird. Der vollständige Pushdown wird ausgeführt, wenn folgende Bedingungen erfüllt sind:
- Im Datenfluss ist nur ein Ziel vorhanden.
- In einem Datenfluss mit einer einzelnen Quelle verwenden sowohl die Quelle als auch das Ziel dieselbe Verbindung zu einem unterstützten relationalen Datensystem.
- In einem Datenfluss mit mehreren Quellen müssen auch alle Quellen dieselbe Datenbank und Verbindung verwenden.
- Alle Transformationsoperatoren und -funktionen im Datenfluss können gültigen Pushdown-SQL-Code generieren.
Durch die Datenvorbereitung wird sichergestellt, dass Datenintegrationsprozesse genaue und sinnvolle Daten mit weniger Fehlern aufnehmen, um Qualitätsdaten für zuverlässigere Insights zu erzeugen.
Die Datenvorbereitung umfasst das Löschen und Validieren von Daten zur Fehlerreduzierung sowie das Transformieren und Anreichern von Daten, bevor die Daten in Zielsysteme geladen werden. Beispiel: Die Daten stammen aus verschiedenen Quellen mit verschiedenen Formaten und sogar doppelten Informationen. Bei der Datenvorbereitung können doppelte Attribute und Zeilen entfernt, ein Standardformat für alle Datumsattribute festgelegt und sensible Attributdaten wie Kreditkarten und Kennwörter maskiert werden.
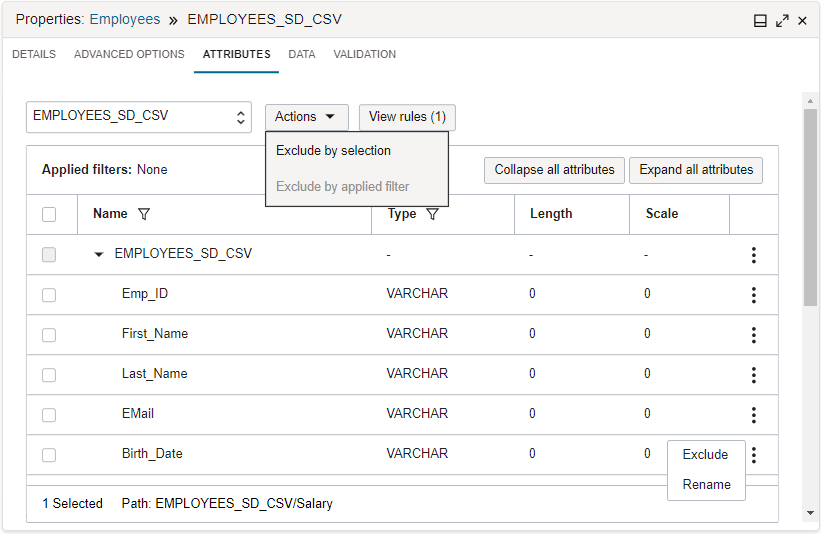
Data Integration bietet sofort einsatzbereite Modellierungsoperatoren und -funktionen sowie Transformationen, mit denen Sie Daten beim Entwerfen der Logik für die ETL-Prozesse in interaktiven Tools vorbereiten können. Beispiel: Auf der Registerkarte "Attribute" können Sie eingehende Attribute nach einem Muster durchsuchen und eine Ausschlussregel anwenden.
Auf der Registerkarte "Daten" können Sie Transformationen auf ein einzelnes Attribut anwenden oder die Attribute nach einem Namensmuster oder Datentyp filtern und dann Transformationen auf eine Gruppe von Attributen anwenden. Sie können auch eine Vorschau der Ergebnisse von Datentransformationen auf der Registerkarte "Daten" anzeigen, ohne den gesamten Datenfluss ausführen zu müssen.

Auf der Registerkarte "Zuordnen" in Data Integration beschreiben Sie den Fluss der Daten von Quellattributen zu Zielattribute.
Ein Ziel kann eine vorhandene Datenentity oder eine neue Datenentity sein. In einem Datenfluss gilt die Registerkarte "Zuordnen" nur für einen Zieloperator für eine vorhandene Datenentity. Bei vorhandenen Zieldatenentitys werden die Quellattribute und alle benutzerdefinierten Attribute aus Upstreamvorgängen Attributen im Ziel zugeordnet.
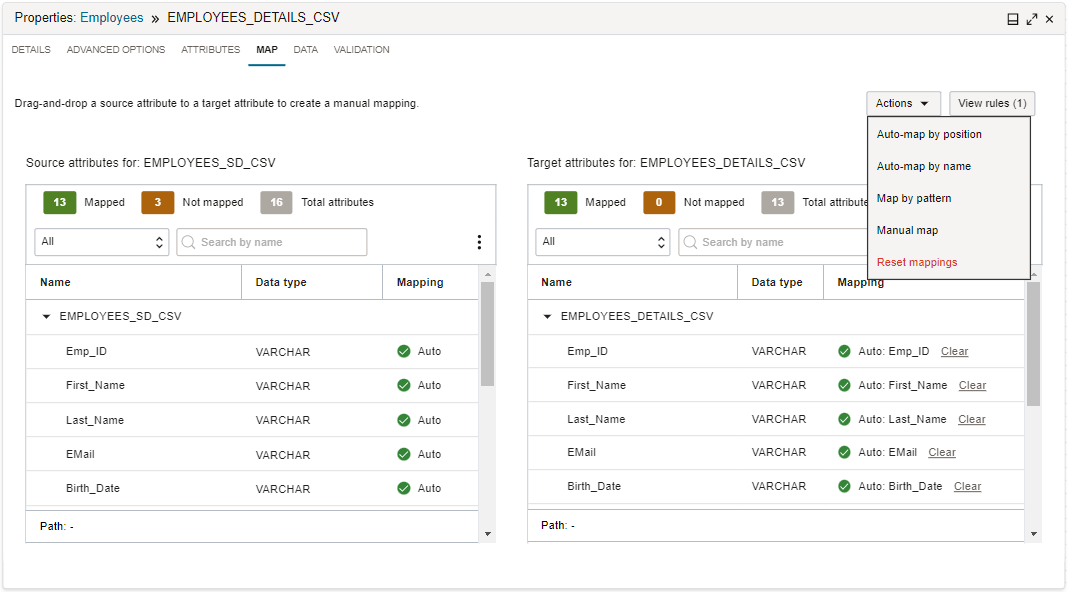
Sie können die automatische Zuordnung oder manuelle Zuordnung verwenden. Für die automatische Zuordnung kann Data Integration eingehende Attribute Zielattributen mit demselben Namen oder entsprechend ihrer Position in den Attributlisten zuordnen. Bei einer manuellen Zuordnung können Sie ein eingehendes Attribut aus der Quellliste in ein Attribut in der Zielliste ziehen, um eine Zuordnung zu erstellen. Alternativ können Sie im Dialogfeld "Attribut zuordnen" eine Zuordnung erstellen, indem Sie ein Quellattribut und ein Zielattribut auswählen. Sie können die Zuordnung auch mit einem Quellattributmuster und einem Zielattributmuster erstellen.
Wenn Sie das Kontrollkästchen Neue Datenentity erstellen für einen Zieloperator aktivieren, ist die Registerkarte "Zuordnen" nicht verfügbar. Data Integration verwendet die eingehenden Quellattribute, um die Tabelle oder Dateistruktur mit einer One-to-One-Zuordnung zu erstellen.
Designeroberfläche verwenden
Mit dem Datenintegrationsdesigner können Sie einen Datenintegrationsfluss in einer grafischen Benutzeroberfläche erstellen.
Sie verwenden einen ähnlichen Designer, um eine Pipeline zu erstellen.
Hauptbereiche des Designers:

Die folgenden Tools erleichtern die Navigation in einem Datenfluss oder einer Pipeline auf der Leinwand:
- Anzeigen: Wählen Sie dieses Menü, um die Fensterbereiche "Eigenschaften", "Operatoren", "Validierung" und "Parameter" zu öffnen bzw. zu schließen.
- Vergrößern: Mit dieser Option können Sie das Design vergrößern.
- Verkleinern: Ermöglicht das Verzoomen, um mehr vom Design anzuzeigen.
- Zoom zurücksetzen: Kehrt zur Standardansicht des Designs zurück.
- Grid Guide: Schaltet die Grid Guides ein und aus.
- Automatisches Layout: Ordnet die Operatoren auf der Leinwand an.
- Löschen: Der ausgewählte Operator wird von der Leinwand entfernt.
- Rückgängig: Löscht die zuletzt ausgeführte Aktion.
- Wiederholen: Führt die letzte Aktion durch, wenn Sie vorher auf Rückgängig geklickt haben.
Die folgenden Aktionstypen können Sie rückgängig machen und wiederholen:
- Operator hinzufügen und löschen
- Verbindungen zwischen Operatoren hinzufügen und löschen
- Position eines Operators auf der Leinwand ändern
Die Leinwand ist der Hauptarbeitsbereich, in dem Sie den Datenfluss oder die Pipeline entwerfen.
Ziehen Sie zunächst Objekte aus dem Bereich Operatoren auf die Leinwand.
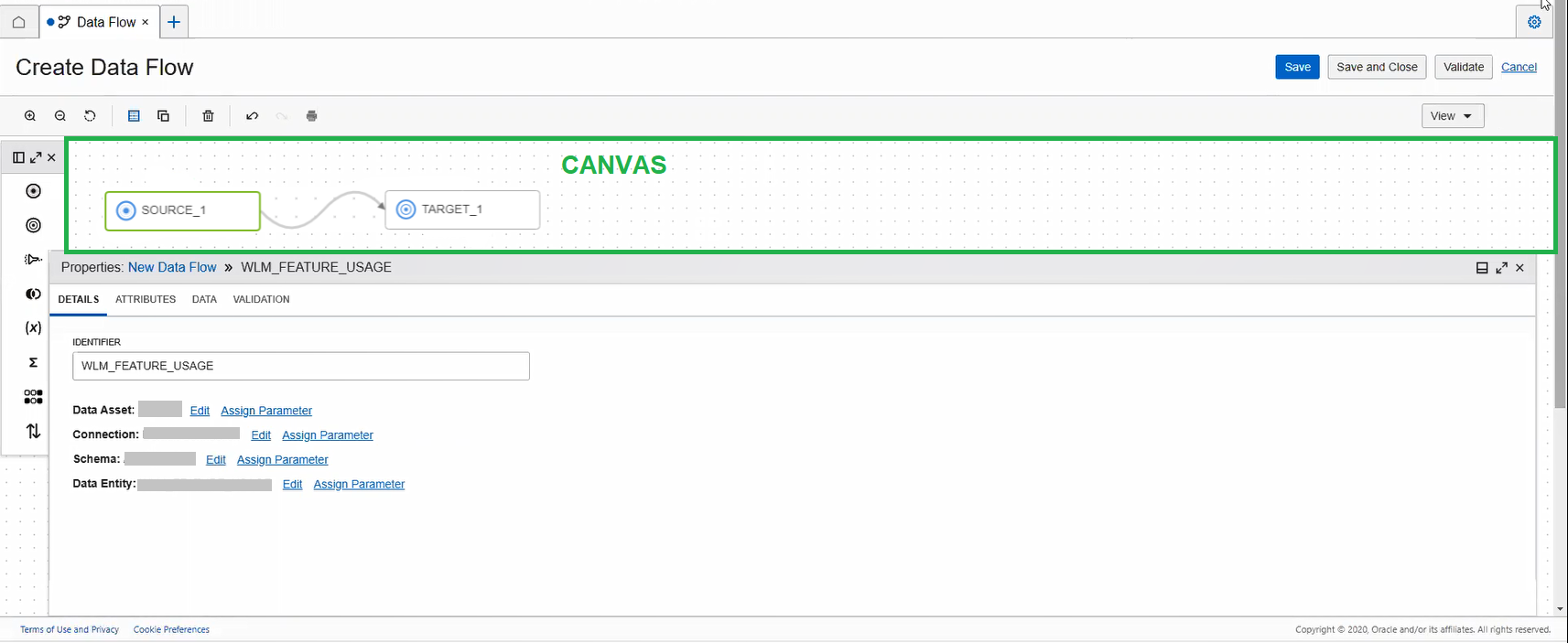
Sie beginnen mit einer leeren Leinwand für einen Datenfluss. Damit ein Datenfluss gültig ist, müssen Sie mindestens eine Quelle und ein Ziel definiert haben.
Bei einer Pipeline beginnen Sie mit einer Leinwand, die einen Startoperator und einen Endoperator aufweist. Das Pipeline-Design muss mindestens einen Aufgabenoperator enthalten, um gültig zu sein.

Um zwei Operatoren zu verbinden, zeigen Sie mit der Maus auf einen Operator, bis der Connector (kleiner Kreis) auf der rechten Seite des Operators angezeigt wird. Ziehen Sie dann den Connector auf den Operator, mit dem Sie eine Verbindung herstellen möchten. Eine Verbindung ist gültig, wenn die Operatoren mit einer Linie verbunden sind, nachdem Sie den Connector abgelegt haben.
Um einen Operator zwischen zwei verbundenen Operatoren hinzuzufügen, klicken Sie mit der rechten Maustaste auf die Verbindungslinie, und verwenden Sie das Menü Einfügen.
Um eine Verbindung zu löschen, können Sie mit der rechten Maustaste auf eine Linie klicken und Löschen auswählen.
Um eine Quelle, ein Ziel oder einen Ausdrucksoperator zu kopieren, klicken Sie mit der rechten Maustaste auf das Operatorsymbol, und wählen Sie Duplizieren aus.
Im Bereich "Operatoren" werden die Benutzer angezeigt, die Sie einem Datenfluss oder einer Pipeline hinzufügen können.
Ziehen Sie Operatoren aus dem Bereich Operatoren auf die Leinwand, um den Datenfluss oder die Pipeline zu entwerfen. Jeder Operator verfügt über ein anderes Set von Eigenschaften, die Sie im Bereich Eigenschaften konfigurieren.
Für einen Datenfluss können Sie verschiedene Operatoren hinzufügen: Eingabe-, Ausgabe- und Modellierungsoperatoren.

Für eine Pipeline können Sie folgende Operatoren hinzufügen, um eine Sequenz zu erstellen: Eingabe-, Ausgabe- und Aufgabenoperatoren.

Operatoren
Die folgenden Operatoren stehen Ihnen zur Verwendung in einem Datenfluss zur Verfügung:
- Eingaben/Ausgaben
-
- Quelle: Steht für eine Quelldatenentität, die als Eingabe in einen Datenfluss dient.
- Ziel: Steht für eine Zieldatenentity, die als Ausgabeentity zum Speichern der transformierten Daten dient.
- Modellierung
-
- Filter: Wählen Sie bestimmte Attribute aus dem eingehenden Port aus, die zum ausgehenden Port weitergeleitet werden sollen.
- Join: Verknüpft Daten aus mehreren Quellen. Die unterstützten Join-Typen sind "Inner", "Rechter Outer", "Linker Outer" und "Vollständiger Outer".
- Ausdruck: Führt eine Transformation für eine einzelne Datenzeile aus.
- Aggregieren: Führt Berechnungen wie Summe oder Anzahl für alle oder eine Gruppe von Zeilen aus.
- Eindeutig: Gibt verschiedene Zeilen zurück, deren Werte sich unterscheiden.
- Sortieren: Sortiert Daten in aufsteigend oder absteigend.
- Einheit: Führt einen Gewerkschaftsvorgang für bis zu 10 Quelloperatoren aus.
- Minus: Führt einen Minusvorgang für zwei Quellen aus und gibt die Zeilen zurück, die in einer Quelle vorhanden sind, in der anderen jedoch nicht.
- Schnittmenge: Führt einen Schnittmengenvorgang für zwei oder mehr Quellen aus und gibt die Zeilen zurück, die in den verbundenen Quellen vorhanden sind.
- Aufteilung: Führt einen Split-Vorgang aus, um eine Eingabedatenquelle basierend auf geteilten Bedingungen auf zwei oder mehr Ausgabeports zu teilen.
- Pivot: Führt eine Transformation mit Aggregatfunktionsausdrücken und Werten eines Attributs aus, das als Pivot-Schlüssel angegeben ist. Dadurch entstehen mehrere neue Attribute in der Ausgabe.
- Lookup: Führt eine Abfrage und dann eine Transformation mit einer primären Eingabequelle, einer Lookup-Eingabequelle und einer Lookup-Bedingung aus.
- Funktion: Ruft eine Oracle-Funktion aus einem Datenfluss in Data Integration in Oracle Cloud Infrastructure auf.
- Verkleinern: Führt die Verschachtelung einer komplexen Dateistruktur von der Root in das von Ihnen ausgewählte hierarchische Datentypattribut aus.
Weitere Informationen finden Sie unter Datenflussoperatoren verwenden.
- Eingaben/Ausgaben
-
- Start: Steht für den Start einer Pipeline. In einer Pipeline ist nur ein Startoperator vorhanden. Der Startoperator kann Links zu mehreren Aufgaben haben.
- Ende: Steht für das Ende einer Pipeline. In einer Pipeline ist nur ein Endoperator vorhanden. Der Endoperator kann Links von mehreren Upstreamknoten aufweisen.
- Ausdruck: Ermöglicht das Erstellen neuer, derivativer Felder in einer Pipeline, ähnlich wie ein Ausdrucksoperator in einem Datenfluss.
- Merge: Führt mehrere Aufgaben zusammen, die parallel ausgeführt werden. Die angegebene Zusammenführungsbedingung bestimmt, wie mit nachfolgenden Downstreamvorgängen verfahren wird.
- Entscheidung: Ermöglicht die Angabe eines Pipelineverzweigungsablaufs mit einer Entscheidungsbedingung. Basierend auf Upstreamausgaben muss der angegebene Bedingungsausdruck einen booleschen Wert ergeben, der die nachfolgende Downstreamverzweigung bestimmt.
- Aufgaben
-
- Integration: Ist an eine Integrationsaufgabe gebunden.
- Data Loader: Ist an eine Data-Loader-Aufgabe gebunden.
- Pipeline: Ist an eine Pipelineaufgabe gebunden.
- SQL: Ist an eine SQL-Aufgabe gebunden.
- OCI Data Flow: Bindet an eine Anwendung in Oracle Cloud Infrastructure Data Flow.
- REST: Erstellt ein Binding an eine REST-Aufgabe.
Mit dem Bereich "Operatoren" arbeiten
Um effizienter zu arbeiten, können Sie den Bereich Operatoren links am Bildschirm andocken. Sie können den Bereich mit den Symbolen "Einblenden" oder "Minimieren" einblenden bzw. minimieren, um nur Symbole anzuzeigen. Sie können den Bereich auch schließen. Wenn der Bereich geschlossen ist, können Sie ihn über das Menü Anzeigen in der Designersymbolleiste öffnen.
Im Bereich "Eigenschaften" können Sie den Datenfluss oder die Pipeline und die zugehörigen Operatoren konfigurieren.
Auf der Registerkarte Validierung können Sie den gesamten Datenfluss oder die gesamte Pipeline validieren.
Auf der Registerkarte Parameter können Sie alle auf Datenfluss- oder Pipelineebene definierten Parameter anzeigen, einschließlich systemgenerierter Parameter. Bei benutzerdefinierten Parametern können Sie Parameter löschen und gegebenenfalls die Standardwerte von Parametern bearbeiten.
Nachdem Sie einen Operator für einen Datenfluss auf der Leinwand hinzugefügt haben, wählen Sie den Operator aus, und konfigurieren Sie ihn im Bereich "Eigenschaften". Sie können folgende Schritte ausführen:
- Geben Sie die Operatordetails an, z.B. die ID, und konfigurieren Sie benutzerspezifische Einstellungen auf der Registerkarte Details.
- Zeigen Sie die ein- und ausgehenden Attribute des Operators auf der Registerkarte Attribute an.
- Auf der Registerkarte Map eingehende Attribute Attributen in der Zieldatenentity für einen Zieloperator zuordnen.
- Eine Vorschau auf ein Sampling von Daten auf der Registerkarte Daten anzeigen.
- Validieren Sie die Konfiguration des Operators auf der Registerkarte Validierung.
Wählen Sie nach dem Hinzufügen eines Operators auf der Leinwand den Operator ähnlich für eine Pipeline aus, und konfigurieren Sie ihn im Bereich "Eigenschaften". Sie können folgende Schritte ausführen:
- Geben Sie auf der Registerkarte Details einen Namen für den Operator an. Für einen Zusammenführungsoperator geben Sie eine Zusammenführungsbedingung an. Für einen Ausdrucksoperator fügen Sie einen oder mehrere Ausdrücke hinzu. Für Aufgabenoperatoren wählen Sie eine Aufgabe, die an den Operator gebunden werden soll, und geben an, wann die Aufgabe basierend auf dem Ausführungsstatus des Upstreamoperators ausgeführt wird.
Für alle Aufgabenoperatoren können Sie Entwurfszeitaufgaben aus Projekten im aktuellen Workspace und veröffentlichte Aufgaben aus einer beliebigen Anwendung im aktuellen Workspace auswählen. Mit veröffentlichten REST-Aufgaben und OCI Data Flow-Aufgaben können Sie auch eine Aufgabe aus einer beliebigen Anwendung in einem anderen Workspace in demselben Compartment oder einem anderen Compartment auswählen.
- Geben Sie gegebenenfalls Ausführungsoptionen für Aufgaben auf der Registerkarte Konfiguration an.
- Konfigurieren Sie gegebenenfalls eingehende Parameter auf der Registerkarte Konfiguration.
- Zeigen Sie die Ausgaben auf der Registerkarte Ausgabe an, die als Eingaben für den nächsten Operator in der Pipeline verwendet werden kann.
- Validieren Sie gegebenenfalls die Konfiguration des Operators auf der Registerkarte Validierung .
Mit dem Bereich "Eigenschaften" arbeiten
Um effizienter zu arbeiten, können Sie den Bereich Eigenschaften unten am Bildschirm andocken. Sie können den Bereich mit den Symbolen "Einblenden" oder "Minimieren" einblenden bzw. minimieren. Sie können den Bereich auch schließen. Wenn der Bereich geschlossen ist, können Sie ihn über das Menü Anzeigen in der Designersymbolleiste öffnen.
Weitere Informationen zu Registerkarten im Bereich "Eigenschaften"
Wenn Sie auf die Leinwand klicken und kein Operator ausgewählt ist, werden im Bereich "Properties" die Details des Datenflusses oder der Pipeline angezeigt.
Wenn Sie verschiedene Operatoren auf der Leinwand auswählen, werden im Bereich "Eigenschaften" die Eigenschaften des fokussierten Operators angezeigt. Mit den folgenden Registerkarten im Bereich "Eigenschaften" können Sie Daten beim Durchlaufen des Operators anzeigen, konfigurieren und transformieren:
- Details
-
Sie können einen Operator über das Feld "ID" auf der Registerkarte "Details" benennen. Für Quell- und Zieloperatoren können Sie auch das Datenasset, die Verbindung, das Schema und die Datenentity auswählen. Wenn Sie "Autonomes KI-Lakehouse" oder "Autonome KI-Transaktionsverarbeitung" als Datenasset auswählen, ist die Option zum Auswählen der Staging Area aktiviert. In dem Staging Area können Sie den Object Storage-Bucket auswählen, in den die Daten zwischengespeichert wird, bevor sie in das Ziel verschoben wird.
Sie können das Datenasset, die Verbindung, das Schema und die Datenentity nur in der auf der Registerkarte "Details" angezeigten Reihenfolge auswählen. Beispiel: Sie können die Verbindung erst auswählen, nachdem Sie das Datenasset ausgewählt haben. Die Auswahloption für das Schema ist erst aktiviert, nachdem Sie die Verbindung ausgewählt haben usw. Eine Auswahl kann nur basierend auf der hierarchischen Beziehung erfolgen, die von der vorherigen Auswahl übernommen wurde. Nach der Auswahl ist die Bearbeitungsoption aktiviert.
Sie können verschiedenen Details jedes Operators Parameter zuweisen, damit diese Details nicht an den kompilierten Code gebunden sind, wenn Sie den Datenintegrationsfluss veröffentlichen. Siehe Parameter in Datenflüssen verwenden und Parameter in Pipelines verwenden.
Für Modellierungsoperatoren können Sie die Bedingungen oder Ausdrücke erstellen, die beim Durchlaufen des Operators auf die Daten angewendet werden.
Für eine Pipeline verwenden Sie die Registerkarte "Details", um einen Namen für die Pipeline oder den ausgewählten Operator anzugeben. Für Aufgabenoperatoren geben Sie auch die zu verwendende Aufgabe an.
- Attribute
-
Die Registerkarte "Attribute" wird nur für einen Datenfluss angezeigt.
Zeigen Sie über das Menü die eingehenden Attribute, die mit dem Operator verknüpft sind, links auf der Leinwand oder die Ausgabeattribute, die an den nächsten damit verknüpften Operator geleitet werden, auf der rechten Seite an.
Wenn das Filtersymbol in der Spalte "Name" ausgewählt wird, wird das Filterfeld angezeigt. Geben Sie ein einfaches reguläres Ausdrucksmuster oder Platzhalter (wie
?und*) im Filterfeld ein, um die Attribute nach Namensmuster zu filtern. Bei diesem Feld wird Groß-/Kleinschreibung nicht beachtet. Wenn das Filtersymbol in der Spalte "Typ" ausgewählt wird, wird das Typmenü angezeigt. Wählen Sie den Typfilter über das Menü aus. Sie können jeweils nur einen Namensmusterfilter, jedoch mehrere Typfilter gleichzeitig anwenden. Beispiel: Um nach dem Namensmuster "*_CODE" und nach dem Typ "Numerisch" oder "varchar" zu filtern, wenden Sie einen Namensmusterfilter (*_CODE) und zwei Typfilter (numerisch, varchar) an.Anschließend können Sie auszuschließende Attribute auswählen oder die auszuschließenden Attribute mit angewendetem Filter auswählen. Über das Menü Aktionen können Sie auswählen, ob Sie Elemente nach Auswahl oder nach angewendeten Filtern ausschließen möchten. Die ausgewählten Ausschlussregeln werden dem Bereich "Regeln" hinzugefügt. Die angewendeten Filter werden oben in der Attributliste angezeigt. Mit der Option Alle löschen können Sie die angewendeten Filter zurücksetzen.
Wählen Sie Regeln anzeigen, um den Bereich Regeln zu öffnen und alle Regeln anzuzeigen, die auf die Datenentity angewendet werden. Die Regeln werden auch in der Erfolgsmeldung rechts oben in der Ecke angezeigt, nachdem Sie die Regeln angewendet haben. Standardmäßig schließt die erste Regel im Bereich "Regeln" alles ein. Sie können weitere Aktionen auf jede Regel anwenden, wie z.B. ihre Position in der Liste ändern oder sie löschen.
- Map
-
Die Registerkarte "Map" wird nur für einen Datenfluss angezeigt.
Diese Registerkarte wird nur für Zieloperatoren angezeigt. Sie können die eingehenden Attribute den Attributen der Zieldatenentity nach Position, nach Name, nach Muster oder direkt zuordnen. Sie können auch die automatische Zuordnung nach Name verwenden oder die Zuordnungen entfernen.
- Daten
-
Die Registerkarte "Daten" wird nur für einen Datenfluss angezeigt.
Auf der Registerkarte "Daten" können Sie eine Vorschau auf ein Sampling von Daten anzeigen, um festzustellen, wie sich eine Transformationsregel auf die Daten beim Durchlaufen des Operators auswirkt.
Hinweis
Stellen Sie sicher, dass das Datenasset, die Verbindung, das Schema und die Datenentity konfiguriert sind, bevor Sie auf die Registerkarte "Daten" zugreifen.Sie können Daten nach einem Namensmuster oder einem Datentyp filtern und eine Ausschlussregel auf die gefilterten Daten anwenden oder Über das Menü Aktionen im Bulkverfahren Transformationen ausführen. Um Daten nach einem Namensmuster zu filtern, geben Sie ein einfaches reguläres Ausdrucksmuster mit Platzhalterzeichen (wie
?und*) in das Feld Nach Muster suchen ein. Um Daten nach einem Datentyp zu filtern, wählen Sie den Typ im Menü aus. Transformationen können nicht für einen Zieloperator angewendet werden, da die Daten schreibgeschützt sind.Beim Hinzufügen und Entfernen von Regeln und Transformationen wird das Datensampling aktualisiert, um diese Änderungen widerzuspiegeln. Weitere Informationen zu Datentransformationen.
- Konfiguration
-
Die Registerkarte "Konfiguration" wird nur für eine Pipeline angezeigt. Wenn für eine Aufgabe verfügbar, können Sie gegebenenfalls die Parameterwerte neu konfigurieren, die mit der Aufgabe oder dem zugrunde liegenden Datenfluss verknüpft sind.
- Ausgabe
-
Die Registerkarte "Ausgabe" wird nur für eine Pipeline angezeigt.
Sie können die Liste der Ausgaben anzeigen, die als Eingaben für verbundene Operatoren in der Pipeline verwendet werden können.
- Validierung
- Auf der Registerkarte "Validierung" können Sie prüfen, ob der Operator korrekt konfiguriert ist, um später Fehler zu vermeiden, wenn Sie den Datenfluss oder die Pipeline ausführen. Beispiel: Wenn Sie vergessen, eingehende oder ausgehende Operatoren zuzuweisen, werden im Bereich "Validierung" Warnmeldungen angezeigt. Wenn Sie eine Meldung im Bereich "Validierung" auswählen, wird dieser Operator fokussiert, damit Sie die Ursache für den Fehler oder die Warnung beheben können.
Im Bereich "Parameter" werden die Parameter angezeigt, die in einem Datenfluss oder einer Pipeline verwendet werden.
Sie können auch einen Parameter im Bereich "Parameter" löschen.
Im Bereich Globale Validierung können Sie alle Fehler- und Warnmeldungen für einen Datenfluss oder eine Pipeline anzeigen.
Wählen Sie in der Symbolleiste "Leinwand" die Option Validieren aus, um den Datenfluss zu prüfen und zu debuggen, bevor Sie den Datenfluss in einer Integrationsaufgabe verwenden. Prüfen und debuggen Sie die Pipeline, bevor sie in einer Pipelineaufgabe verwendet wird. Der Bereich Globale Validierung wird geöffnet und zeigt Fehler- und Warnmeldungen an, die Sie beheben müssen. Wenn Sie eine Meldung auswählen, werden Sie zum Operator weitergeleitet, der die Fehler- oder Warnmeldung verursacht hat.