Cloud-Links für schreibgeschützten Datenzugriff in einer autonomen KI-Datenbank verwenden
Cloud-Links bieten eine cloudbasierte Methode für den Remotezugriff auf schreibgeschützte Daten auf einer autonomen KI-Datenbankinstanz.
Informationen zu Cloud-Links auf einer autonomen KI-Datenbank
Bei Cloud-Links registriert ein Dateneigentümer eine Tabelle oder Ansicht für den Remotezugriff für eine ausgewählte Zielgruppe, wie vom Dateneigentümer definiert, und die Daten sind dann für diejenigen zugänglich, denen bei der Registrierung Zugriff gewährt wurde. Für die Einrichtung von Cloud-Links sind keine weiteren Maßnahmen erforderlich, und wer Ihre Daten sehen und darauf zugreifen soll, kann die Daten erkennen und mit ihnen arbeiten.
Die Cloud Links-Implementierung nutzt Oracle Cloud Infrastructure-Zugriffsmechanismen, um Daten innerhalb eines bestimmten Geltungsbereichs zugänglich zu machen. Der Geltungsbereich gibt an, wer remote auf die Daten zugreifen kann. Der Geltungsbereich kann auf verschiedene Ebenen festgelegt werden, einschließlich der Region, in der sich die Datenbank befindet, auf einzelne Mandanten oder auf Compartments. Außerdem können Sie angeben, dass die Autorisierung für den Zugriff auf ein Dataset auf mindestens eine autonome AI-Datenbankinstanz beschränkt ist.
Wenn Sie mindestens einen regionsübergreifenden aktualisierbaren Klon aus der autonomen KI-Datenbankinstanz der Quelle (Datenseteigentümer) erstellen, können Sie Daten über Cloud-Links regionsübergreifend freigeben.
Cloud-Links vereinfachen die gemeinsame Nutzung von Tabellen oder Ansichten über autonome KI-Datenbankinstanzen hinweg im Vergleich zu herkömmlichen Mechanismen zur Datenbankverknüpfung erheblich. Mit Cloud Links können Sie Daten erkennen, ohne dass ein komplexes Datenbanklinksetup erforderlich ist. Autonome KI-Datenbank bietet transparenten Zugriff mit SQL und implementiert die Durchsetzung von Berechtigungen mit dem Geltungsbereich "Cloud-Links" und durch Autorisierung einzelner Instanzen der autonomen KI-Datenbank.
Cloud Links stellen die Konzepte regionaler Namespaces und Namen für Daten vor, die remote zugänglich gemacht werden. Dies ähnelt vorhandenen Oracle-Tabellen, in denen eine Tabelle vorhanden ist. Beispiel: "EMP", das sich in einem Namespace (Schema) befindet. Beispiel: "LWARD". In Ihrer Datenbank kann nur ein LWARD.EMP vorhanden sein. Cloud-Links stellen einen ähnlichen Namespace und Namen auf regionaler Ebene bereit, der nicht an eine einzelne Datenbank gebunden ist, aber für viele autonome KI-Datenbankinstanzen gilt, wie mit dem Geltungsbereich und optional mit Datenbankautorisierung angegeben.
Beispiel: Sie können ein Dataset unter dem Namespace FOREST registrieren und aus Sicherheitsgründen oder zur Vereinfachung der Benennung einen Namespace und einen anderen Namen als das ursprüngliche Schema und die ursprünglichen Objektnamen angeben. In diesem Beispiel ist TREE_DATA der sichtbare Name des registrierten Datasets, und dieser Name muss nicht der Name der Quelltabelle sein. Neben dem Namespace und dem Namen gibt das Schlüsselwort cloud$link der Datenbank an, dass die Quelle als Cloud-Link aufgelöst werden muss.
Um auf ein registriertes Dataset zuzugreifen, nehmen Sie den Namespace, den Namen und das Schlüsselwort cloud$link in die FROM-Klausel einer SELECT-Anweisung auf:
SELECT county, species, height FROM FOREST.TREE_DATA@cloud$link;Optional können Sie angeben, dass der Zugriff auf ein Dataset von einer oder mehreren Datenbanken auf einen aktualisierbaren Klon ausgelagert wird. Wenn eine autonome KI-Consumer-Datenbank in der Auslagerungsliste eines Datasets aufgeführt wird, wird der Zugriff auf das Dataset an den aktualisierbaren Klon weitergeleitet. Darüber hinaus können Sie die Funktion "Einheitliche Abfrageauslagerung" verwenden, bei der Sie einen Elastic Pool Leader oder Member als Cloud-Link-Provider konfigurieren und die ProxySQL-Abfrageauslagerung aktivieren, um Abfragen (Lesevorgänge) auf eine beliebige Anzahl aktualisierbarer Klone auszulagern.
Hinweis
Hinweis: Cloud-Links bieten schreibgeschützten Zugriff auf Remoteobjekte in einer autonomen KI-Datenbankinstanz. Wenn Sie Datenbanklinks mit anderen Oracle-Datenbanken oder mit Nicht-Oracle-Datenbanken verwenden möchten oder Ihre Remote-Daten mit DML-Vorgängen verwenden möchten, müssen Sie Datenbanklinks verwenden. Weitere Informationen finden Sie unter Datenbanklinks mit autonomer KI-Datenbank verwenden.
Cloud-Links unterstützen private und öffentliche Synonyme. Beispiel: Sie können ein Synonym für FOREST.TREE_DATA@cloud$link definieren und verwenden:
CREATE SYNONYM S1 for FOREST.TREE_DATA@cloud$link;
SELECT county, species, height FROM S1;
CREATE PUBLIC SYNONYM S2 for FOREST.TREE_DATA@cloud$link;
SELECT * FROM S2;Weitere Informationen zu Synonymen finden Sie unter Überblick über Synonyme.
Begriffe zu Cloudlinks
Bei der Arbeit mit Cloud-Links müssen Sie mehrere Konzepte und Begriffe verwenden:
-
Registriertes Dataset (Dataset): Gibt eine Tabelle oder View an, die für den Remotezugriff in einer autonomen KI-Datenbank aktiviert wurde. Ein registriertes Dataset gibt auch an, wer auf das Dataset (den Geltungsbereich) zugreifen darf. Die Dataset-Registrierung definiert einen Namespace und einen Namen zur Verwendung mit Cloud-Links. Nach der Dataset-Registrierung geben diese Werte gemeinsam den vollqualifizierten Namen (FQN) für den Remotezugriff an, und Cloud-Links können die Barrierefreiheit für das Dataset verwalten.
-
Dataset-Eigentümer: Geben Sie einen Dataset-Eigentümer an, um einen Ansprechpartner für Fragen zu einem Dataset anzugeben.
-
Geltungsbereich: Gibt an, wer und von wo aus ein Benutzer auf ein registriertes Dataset zugreifen darf. Weitere Informationen zum Geltungsbereich finden Sie unter Dataset-Geltungsbereich, Zugriffskontrolle und Autorisierung.
-
OCID (Oracle Cloud-ID): Gibt einen bestimmten Mandanten, ein Compartment oder eine bestimmte Datenbank an. Der Geltungsbereich für ein registriertes Dataset kann als OCIDs ausgedrückt werden. Weitere Informationen finden Sie unter Ressourcen-IDs.
-
Datenregistrierung: Bei der Datenregistrierung stellt ein Benutzer eine Tabelle oder Ansicht für den Remotezugriff zur Verfügung, vorbehaltlich der Zugriffsbeschränkungen, die durch den Geltungsbereich festgelegt werden, und optional vorbehaltlich eines zusätzlichen Autorisierungsschritts. Sie können Remotezugriff mit Cloud-Links in einer Tabelle oder View zulassen, die in der Datenbank oder in Daten gespeichert sind, die im Objektspeicher gespeichert sind.
-
Daten-Discovery: Ein registriertes Dataset kann mit Textabfragen aus der Datenbank ermittelt werden. Die Discovery zeigt nur dann ein Dataset an, wenn eine Berechtigung zum Zugriff auf das Dataset vorhanden ist. Sie können nach einem registrierten Dataset nach Name oder Beschreibung suchen.
-
Datenbeschreibung: Ermöglicht einem Benutzer das Abrufen einer Beschreibung oder Metadaten für eine Tabelle oder Ansicht, die als registriertes Dataset verfügbar gemacht wird.
-
Offloadziele: Optional können Sie ein oder mehrere Offload-Ziele angeben. Offload-Ziele sind aktualisierbare Klone, die Cloud-Links-Datasets zu angegebenen autonomen KI-Datenbankinstanzen bereitstellen. Wenn Sie ein Offload-Ziel angeben, können Sie eine autonome KI-Datenbankinstanz dedizieren, um Datasets bereitzustellen, um die Produktion von der Entwicklung zu trennen, die Performance zu steigern, die Sicherheit zu gewährleisten oder aus anderen Gründen. Weitere Informationen finden Sie unter Aktualisierbare Klone mit einer autonomen KI-Datenbank verwenden.
Auditing von Cloud-Links
Jeder Zugriff auf ein registriertes Dataset mit Cloud-Links wird zu Auditzwecken protokolliert. Das Log enthält den Mandanten, das Compartment oder die Datenbank, die auf das Dataset zugegriffen hat, die Datenmenge, auf die zugegriffen wurde, sowie zusätzliche Informationen. In den Views V$CLOUD_LINK_ACCESS_STATS und GV$CLOUD_LINK_ACCESS_STATS werden Auditinformationen angezeigt.
Dataset-Metadaten und Auditansichten
Jede autonome KI-Datenbankinstanz bietet Ansichten, die Dataset-Metadaten bereitstellen und Ihnen die Überwachung und das Audit der Datennutzung ermöglichen. Weitere Informationen finden Sie unter Informationen zu Cloud-Links überwachen und anzeigen.
Umfang, Zugriffskontrolle und Autorisierung von Datasets
Cloud-Links nutzen Oracle Cloud Infrastructure-Zugriffsmechanismen, um registrierte Datasets zugänglich zu machen und Ihre Daten mit Zugriffsbeschränkungen zu schützen.
Die autonome KI-Datenbank bestimmt den Zugriff auf registrierte Datasets wie folgt:
-
Der ADMIN-Benutzer gibt einen Geltungsbereich für einen Benutzer an, mit dem der Benutzer Datasets basierend auf dem angegebenen Geltungsbereich registrieren kann.
-
Ein Benutzer, dem Berechtigungen zur Registrierung von Datasets erteilt wurden, gibt einen Geltungsbereich an, wenn er ein Dataset registriert.
-
Wenn Sie ein Dataset registrieren, kann ein Benutzer, dem Autorisierungsberechtigungen erteilt wurden, optional angeben, dass ein Autorisierungsschritt für den Zugriff auf ein Dataset erforderlich ist. Dieser Autorisierungsschritt wird zusätzlich zur Zugriffsberechtigung auf Umfangsebene ausgeführt.
Dataset-Geltungsbereich
Der ADMIN legt den Geltungsbereich eines Benutzers mit DBMS_CLOUD_LINK_ADMIN.GRANT_REGISTER als einen der folgenden Werte fest:
-
'MY$REGION' -
'MY$TENANCY' -
'MY$COMPARTMENT' -
'MY$POOL'
Der Geltungsbereich eines Benutzers ist hierarchisch, d.h. ein Benutzer, dem einer dieser Geltungsbereiche erteilt wurde, kann den Zugriff wie folgt zulassen:
-
MY$REGION: Ein Benutzer kann Remote-Datenzugriff auf andere Mandanten in der Region der autonomen KI-Datenbankinstanz erteilen, die das Dataset registriert. Dies ist der am wenigsten restriktive Geltungsbereich. -
MY$TENANCY: Ein Benutzer kann Remote-Datenzugriff auf jede Ressource, jeden Mandanten, jedes Compartment oder jede Datenbank im Mandanten der autonomen KI-Datenbankinstanz erteilen, die das Dataset registriert. Dieser Geltungsbereich ist restriktiver als der GeltungsbereichMY$REGION. -
MY$COMPARTMENT: Ein Benutzer kann Remote-Datenzugriff auf jede Ressource, jedes Compartment oder jede Datenbank im Compartment der autonomen KI-Datenbankinstanz erteilen, die das Dataset registriert. Dies ist der restriktivste Bereich, den Sie für einen Benutzer mitGRANT_REGISTERfestlegen können. -
MY$POOL: Ein Benutzer kann Remote-Datenzugriff auf jede autonome KI-Datenbank im selben Elastic Pool erteilen wie die Instanz der autonomen KI-Datenbank, die das Dataset registriert (einschließlich übergeordneter/untergeordneter Mandanten). Dieser Geltungsbereich ist restriktiver alsMY$TENANCY- undMY$REGION-Geltungsbereiche, ist jedoch umfassender alsMY$COMPARTMENTund ermöglicht eine sichere Freigabe ohne Datenkopie innerhalb des Pools, wobei Berechtigungsprüfungen in der Datenbank des Benutzers durchgeführt werden, bevor eine Remoteverbindung hergestellt wird.
Als Nächstes bestimmt der Geltungsbereich, den Sie beim Registrieren eines Datasets festlegen, von wo aus Benutzer auf das Dataset zugreifen dürfen. Die DBMS_CLOUD_LINK.REGISTER scope ist eine durch Komma getrennte Liste, die aus mindestens einer der folgenden Komponenten besteht:
-
Datenbank-OCID: Zugriff auf das Dataset ist für die spezifischen, per OCID identifizierten autonomen AI Database-Instanzen zulässig.
-
Compartment-OCID: Zugriff auf das Dataset ist für Datenbanken in den per Compartment-OCID identifizierten Compartments zulässig.
-
Mandanten-OCID: Zugriff auf das Dataset ist für Datenbanken in den per Mandanten-OCID identifizierten Mandanten zulässig.
-
Regionsname: Der Zugriff auf das Dataset ist für Datenbanken in der Region zulässig, die von der benannten Region identifiziert wird. In allen Fällen ist der Zugriff auf Cloud-Links auf eine einzelne Region beschränkt und nicht regionsübergreifend.
-
MY$COMPARTMENT: Zugriff auf das Dataset ist für Datenbanken in dem COMPARTMENT zulässig, in dem sich der Dataset-Eigentümer befindet.
-
MY$TENANCY: Zugriff auf das Dataset ist für Datenbanken in dem Mandanten zulässig, in dem sich der Dataset-Eigentümer befindet.
-
MY$REGION: Zugriff auf das Dataset ist für Datenbanken in der REGION zulässig, in der sich der Dataset-Eigentümer befindet.
-
MY$POOL: Zugriff auf das Dataset ist für Datenbanken in dem Elastic POOL zulässig, in dem sich der Dataset-Eigentümer befindet.
Die Geltungsbereichswerte MY$REGION, MY$TENANCY, MY$COMPARTMENT und MY$POOL sind Variablen, die als einfache Makros fungieren und als OCIDs aufgelöst werden.
Hinweis: Der Geltungsbereich, den Sie beim Registrieren eines Datasets festlegen, wird nur berücksichtigt, wenn er mit dem mit DBMS_CLOUD_LINK_ADMIN.GRANT_REGISTER festgelegten Wert übereinstimmt oder restriktiver ist. Beispiel: Der ADMIN hat den Geltungsbereich MY$TENANCY mit GRANT_REGISTER erteilt, und der Benutzer gibt MY$REGION an, wenn er ein Dataset mit DBMS_CLOUD_LINK.REGISTER registriert. In diesem Fall würde ein Fehler wie der Folgende angezeigt:
ORA-20001: Share privileges are not enabled for current user or it is enabled but not for scope MY$REGIONSie können auch einen zusätzlichen Zugriffskontrollmechanismus basierend auf einem SYS_CONTEXT-Wert verwenden. Dieser Mechanismus verwendet die Funktion DBMS_CLOUD_LINK.GET_DATABASE_ID, die eine ID zurückgibt, die als SYS_CONTEXT-Wert verfügbar ist.
Wenn Sie ein Dataset bei DBMS_CLOUD_LINK.REGISTER registrieren, können Sie den Wert SYS_CONTEXT in Oracle Virtual Private Database-(VPD-)Sicherheits-Policys verwenden, um den Datenbankzugriff weiter einzuschränken und zu kontrollieren, auf welche spezifischen Daten einzelne autonome KI-Datenbankinstanzen zugreifen können.
Weitere Informationen zur Verwendung von VPD-Policys finden Sie unter Policy für virtuelle private Datenbanken zum Sichern eines registrierten Datasets definieren.
Der Datenbank-ID-Wert ist auch in den Views V$CLOUD_LINK_ACCESS_STATS und GV$CLOUD_LINK_ACCESS_STATS verfügbar, die Zugriffsstatistiken und Auditinformationen verfolgen.
Weitere Informationen finden Sie unter Datenzugriff mit der Oracle Virtual Private Database steuern.
Dataset-Autorisierung
Wenn Sie ein Dataset registrieren und Ihnen Autorisierungsberechtigungen erteilt wurden, können Sie angeben, dass die Datenbank-OCID-Autorisierung für den Zugriff auf ein Dataset erforderlich ist. Um die Datenbank-OCID-Autorisierung für ein Dataset bereitzustellen, geben Sie mit der Prozedur DBMS_CLOUD_LINK.GRANT_AUTHORIZATION die Instanzen der autonomen KI-Datenbank an, die für den Zugriff auf das Dataset autorisiert sind. Bevor Sie DBMS_CLOUD_LINK.GRANT_AUTHORIZATION ausführen, muss der ADMIN Sie autorisieren, diese Prozedur mit DBMS_CLOUD_LINK_ADMIN.GRANT_AUTHORIZE auszuführen.
Die Dataset-Registrierung mit erforderlicher Autorisierung gibt den Zugriff auf Datenbankebene für ein Dataset sowie die für das Dataset angegebene Zugriffskontrolle auf Geltungsbereich wie folgt an:
-
Datenbanken, die sich innerhalb der angegebenen
SCOPEbefinden und mitDBMS_CLOUD_LINK.GRANT_AUTHORIZATIONautorisiert wurden, können Zeilen aus dem Dataset anzeigen. -
Alle Datenbanken, die sich innerhalb der angegebenen
SCOPEbefinden, aber nicht mitDBMS_CLOUD_LINK.GRANT_AUTHORIZATIONautorisiert wurden, können keine Dataset-Zeilen anzeigen. In diesem Fall sehen Verbraucher ohne Autorisierung den Datensatz als leer. -
Datenbanken, die nicht innerhalb der angegebenen
SCOPEliegen, sehen einen Fehler beim Versuch, auf das Dataset zuzugreifen.
Zugriff auf Cloud-Links für Datenbankbenutzer erteilen
Der ADMIN-Benutzer erteilt Datenbankbenutzern Berechtigungen zum Registrieren von Datasets. Der ADMIN-Benutzer erteilt Datenbankbenutzern außerdem Berechtigungen für den Zugriff auf registrierte Datasets.
Wenn der ADMIN-Benutzer Registrierungsberechtigungen erteilt, stellt er einen Geltungsbereich bereit, der den maximalen Geltungsbereich angibt, den ein Benutzer bei der Registrierung eines Datasets (innerhalb der Geltungsbereichshierarchie) angeben kann. Die gültigen scope-Werte zur Verwendung mit DBMS_CLOUD_LINK_ADMIN.GRANT_REGISTER sind:
-
'MY$REGION' -
'MY$TENANCY' -
'MY$COMPARTMENT' -
'MY$POOL'
Weitere Informationen finden Sie unter Dataset-Geltungsbereich, Zugriffskontrolle und Autorisierung.
-
Erlauben Sie als ADMIN-Benutzer einem Benutzer, Datensätze in einem bestimmten Geltungsbereich zu registrieren.
BEGIN DBMS_CLOUD_LINK_ADMIN.GRANT_REGISTER( username => 'DB_USER1', scope => 'MY$REGION'); END; /Gibt an, dass der Benutzer
DB_USER1über Berechtigungen zum Registrieren von Datasets in einem angegebenen Geltungsbereich verfügt,'MY$REGION'.Ein Benutzer kann
SYS_CONTEXT('USERENV', 'CLOUD_LINK_REGISTER_ENABLED')abfragen, um zu prüfen, ob sie für die Registrierung von Datasets aktiviert sind.Beispiel: Die folgende Abfrage:
SELECT SYS_CONTEXT('USERENV', 'CLOUD_LINK_REGISTER_ENABLED') FROM DUAL;Gibt '
YES' oder 'NO'' zurück.Weitere Informationen finden Sie unter Prozedur GRANT_REGISTER.
-
Erlauben Sie als ADMIN-Benutzer einem Benutzer den Zugriff auf registrierte Datasets.
EXEC DBMS_CLOUD_LINK_ADMIN.GRANT_READ('LWARD');Dadurch kann
LWARDauf registrierte Datasets zugreifen, die für die Instanz der autonomen KI-Datenbank verfügbar sind.Ein Benutzer kann
SYS_CONTEXT('USERENV', 'CLOUD_LINK_READ_ENABLED')abfragen, um zu prüfen, ob er für denREAD-Zugriff auf ein Dataset aktiviert ist.Beispiel: Die folgende Abfrage:
SELECT SYS_CONTEXT('USERENV', 'CLOUD_LINK_READ_ENABLED') FROM DUAL;Gibt '
YES' oder 'NO'' zurück.Weitere Informationen finden Sie unter Prozedur GRANT_READ.
-
Bei der Datenregistrierung können Sie den Parameter "Autorisierung erforderlich" auf
TRUEsetzen. Wenn die erforderliche AutorisierungTRUEist, muss der ADMIN-BenutzerDBMS_CLOUD_LINK_ADMIN.GRANT_AUTHORIZEausführen, um die Autorisierung zum Aufrufen vonDBMS_CLOUD_LINK.GRANT_AUTHORIZATIONbereitzustellen. Verwenden SieDBMS_CLOUD_LINK.GRANT_AUTHORIZATION, um Autorisierungsdetails anzugeben.Weitere Informationen finden Sie unter Dataset mit erforderlicher Autorisierung registrieren.
-
Wenn Database Vault für die autonome AI-Datenbankinstanz aktiviert ist und die Tabelle oder View, die bei Cloudlinks registriert werden soll, durch eine Realm geschützt ist, muss der Eigentümer der Tabelle oder View vor der Registrierung für die Realm als Realm-Eigentümer autorisiert werden.
BEGIN DBMS_MACADM.ADD_AUTH_TO_REALM( realm_name => 'myrealm', grantee => '*object_owner*', auth_option => dbms_macutl.g_realm_auth_owner); END; /Wenn die Realm, die die Tabelle oder View schützt, eine obligatorische Realm ist, muss das allgemeine Schema der autonomen KI-Datenbank mit dem Namen
C##DATA$SHARE, das intern als Verbindungsschema verwendet wird, für die Realm als Realm-Teilnehmer autorisiert werden.Beispiel:
BEGIN DBMS_MACADM.ADD_AUTH_TO_REALM( realm_name => 'myrealm', grantee => 'C##DATA$SHARE', auth_option => dbms_macutl.g_realm_auth_participant); END; /Weitere Informationen finden Sie unter Oracle AI Database Vault mit Autonomous AI Database verwenden.
Hinweise zum Erteilen von Berechtigungen für Datenbankbenutzer zum Registrieren von Datasets:
-
Um Datasets zu registrieren oder Remote-Datasets anzuzeigen und darauf zuzugreifen, müssen Sie die entsprechende Berechtigung für die Registrierung bei
DBMS_CLOUD_LINK_ADMIN.GRANT_REGISTERoder für das Lesen von Datasets mitDBMS_CLOUD_LINK_ADMIN.GRANT_READerteilt haben.Dies gilt auch für ADMIN-Benutzer. Der ADMIN-Benutzer kann sich jedoch Berechtigungen erteilen.
-
Die Views
DBA_CLOUD_LINK_PRIVSundUSER_CLOUD_LINK_PRIVSenthalten Informationen zu Benutzerberechtigungen. Weitere Informationen finden Sie unter Informationen zu Cloud-Links überwachen und anzeigen. -
Ein Benutzer kann die folgende Abfrage ausführen, um zu prüfen, ob er für die Authentifizierung registrierter, geschützter Datasets aktiviert ist:
SELECT SYS_CONTEXT('USERENV', 'CLOUD_LINK_AUTH_ENABLED') FROM DUAL;
-
Zugriff auf Cloud-Links für Datenbankbenutzer entziehen
Der ADMIN-Benutzer kann die Registrierung widerrufen, damit ein Benutzer keine Datensätze für den Remotezugriff registrieren kann. Der ADMIN-Benutzer kann auch Berechtigungen oder Datenbankbenutzer für den Zugriff auf registrierte Datasets entziehen.
-
Entziehen Sie als ADMIN-Benutzer die Berechtigungen eines Benutzers zum Registrieren von Datasets.
Beispiel:
EXEC DBMS_CLOUD_LINK_ADMIN.REVOKE_REGISTER('DB_USER1');Dadurch werden die Berechtigungen zum Registrieren von Datasets für den Benutzer
DB_USER1entzogen.Die Ausführung von
DBMS_CLOUD_LINK_ADMIN.REVOKE_REGISTERwirkt sich nicht auf bereits registrierte Datasets aus. Verwenden SieDBMS_CLOUD_LINK.UNREGISTER, um den Zugriff für ein registriertes Dataset zu entfernen.Weitere Informationen finden Sie unter Prozedur REVOKE_REGISTER und UNREGISTER.
-
Entziehen Sie als ADMIN-Benutzer den Zugriff auf registrierte Datasets.
Beispiel:
EXEC DBMS_CLOUD_LINK_ADMIN.REVOKE_READ('LWARD');Dadurch wird der Zugriff auf Cloud-Links-Datasets für den Benutzer
LWARDentzogen.Weitere Informationen finden Sie unter Prozedur REVOKE_READ.
Dataset registrieren
Beschreibt die Optionen und Schritte zum Registrieren einer Tabelle oder Ansicht, deren Eigentümer Sie sind, als registriertes Dataset für die Freigabe mit Cloud-Links.
Dataset registrieren oder Registrierung aufheben
Sie können eine Tabelle registrieren oder anzeigen, deren Eigentümer Sie sind, als registriertes Dataset. Wenn Sie das Dataset entfernen oder ersetzen möchten, müssen Sie die Registrierung aufheben. Nachdem Sie ein Dataset registriert haben, können Sie die Werte der Attribute eines Datasets ändern.
Die Dataset-Registrierung definiert einen Namespace und einen Namen zur Verwendung mit Cloud-Links. Nach der Dataset-Registrierung geben diese Werte gemeinsam den vollqualifizierten Namen (FQN) für den Remotezugriff an, und Cloud-Links können die Barrierefreiheit für das Dataset verwalten.
So registrieren Sie ein Dataset:
-
Erteilen Sie dem ADMIN-Benutzer Registrierungsberechtigungen.
Weitere Informationen finden Sie unter Zugriff auf Cloud-Links für Datenbankbenutzer erteilen.
-
Registrieren Sie mindestens einen Datensatz.
Beispiel: Wenn die Instanz der autonomen KI-Datenbank ein Schema
CLOUDLINKenthält, können Sie zwei Objekte registrieren,SALES_VIEW_AGGundSALES_ALL. Außerdem können Sie verschiedenescope-Parameter angeben, um den Zugriff auf die Objekte zu bestimmen.BEGIN DBMS_CLOUD_LINK.REGISTER( schema_name => 'CLOUDLINK', schema_object => 'SALES_VIEW_AGG', namespace => 'REGIONAL_SALES', name => 'SALES_AGG', description => 'Aggregated regional sales information.', scope => 'MY$TENANCY', auth_required => FALSE, data_set_owner => 'amit@example.com' ); END; /BEGIN DBMS_CLOUD_LINK.REGISTER( schema_name => 'CLOUDLINK', schema_object => 'SALES_ALL', namespace => 'TRUSTED_COMPARTMENT', name => 'SALES', description => 'Trusted Compartment, only accessible within my compartment. Early sales data.', scope => 'MY$COMPARTMENT', auth_required => FALSE, data_set_owner => 'amit@example.com' ); END; /Die Parameter sind:
-
schema_name: ist der Schemaname (der Objekteigentümer). -
schema_object: ist der Name des Objekts. Gültige Objekte sind:-
Tabellen (einschließlich Heap, extern oder Hybrid)
-
Ansichten
-
Materialized Views
-
Cloud-Tabellen (Weitere Informationen finden Sie unter Logging- und Diagnoseinformationen mit Cloud-Tabellen speichern.)
Hinweis
Hinweis: Andere Objekte, wie Analyse-Views oder Synonyme, werden nicht unterstützt.
-
-
namespace: ist der Namespace, den Sie als Namen für den Zugriff mit Cloud-Links (ein Teil des Cloud-Link-FQN) angeben.Ein
NULL-Wert gibt einen systemgeneriertennamespace-Wert an, der für die Instanz der autonomen KI-Datenbank eindeutig ist. -
name: ist der Name, den Sie für den Zugriff mit Cloud-Links (ein Teil der Cloud-Link-FQN) angeben. -
description: Gibt Text zur Beschreibung der Daten an. -
scope: Gibt den Geltungsbereich an. Sie können eine der Variablen verwenden:MY$REGION,MY$TENANCY,MY$COMPARTMENToderMY$POOLoder eine oder mehrere OCIDs angeben.Weitere Informationen finden Sie unter Dataset-Geltungsbereich, Zugriffskontrolle und Autorisierung.
-
auth_required: Ein boolescher Wert, der angibt, ob neben der Zugriffskontrolle für den Geltungsbereich auch eine Autorisierung auf Datenbankebene für das Dataset erforderlich ist. Wenn dieser Wert aufTRUEgesetzt ist, erzwingt das Dataset einen zusätzlichen Autorisierungsschritt. Weitere Informationen finden Sie unter Dataset mit erforderlicher Autorisierung registrieren. -
data_set_owner: Der Textwert gibt Informationen über die Person an, die für das Dataset verantwortlich ist, oder einen Kontakt für Fragen zum Dataset. Beispiel: Sie können eine E-Mail-Adresse für den Dataset-Eigentümer angeben.
Weitere Informationen finden Sie unter Prozedur REGISTER.
In diesem Beispiel unterscheidet sich der Geltungsbereich für die beiden registrierten Objekte nach Abschluss der Registrierung je nach dem Geltungsbereichsparameter, den Sie mit
DBMS_CLOUD_LINK.REGISTERangegeben haben:-
MY$TENANCY: Gibt den Geltungsbereich auf Mandantenebene fürREGIONAL_SALES.SALES_AGGan. -
MY$COMPARTMENT: Gibt den restriktiveren Geltungsbereich auf Compartment-Ebene im Mandanten fürTRUSTED_COMPARTMENT.SALESan.
-
Sie können einige Werte für die Attribute eines Datasets aktualisieren, nachdem Sie ein Dataset registriert haben. Weitere Informationen finden Sie unter Dataset-Registrierungsattribute aktualisieren.
Wenn Sie den Remotezugriff auf ein registriertes Dataset entziehen möchten, heben Sie die Registrierung des Datasets auf.
Beispiel:
BEGIN
DBMS_CLOUD_LINK.UNREGISTER(
namespace => 'TRUSTED_COMPARTMENT',
name => 'SALES');
END;
/Weitere Informationen finden Sie unter UNREGISTER-Prozedur.
Hinweise zum Registrieren oder Aufheben der Registrierung eines Datasets
Enthält Hinweise zum Registrieren eines Datasets mit DBMS_CLOUD_LINK.REGISTER und zum Aufheben der Registrierung eines Datasets mit DBMS_CLOUD_LINK.UNREGISTER.
-
Nachdem Sie ein Objekt registriert haben, müssen Benutzer möglicherweise bis zu zehn (10) Minuten warten, um mit Cloud-Links auf das Objekt zuzugreifen.
-
Wenn Sie ein Dataset registrieren und möchten, dass Consumer in Remoteregionen auf das Dataset zugreifen können, müssen Sie zusätzliche Schritte ausführen, um das Dataset in einer Remoteregion verfügbar zu machen. Weitere Informationen finden Sie unter Datasets in einer anderen Region registrieren oder deren Registrierung aufheben.
-
Verwenden Sie die Prozedur
DBMS_CLOUD_LINK.UPDATE_REGISTRATION, um die Attribute für ein vorhandenes Dataset zu ändern.Die Wartezeit bis zum Abschluss des Updates kann bis zu 10 Minuten betragen, bis eine Registrierungsänderung über Cloud-Links propagiert und darauf zugegriffen werden kann. Diese Verzögerung kann sich auf die Genauigkeit der Daten in der
DBA_CLOUD_LINK_REGISTRATIONS- undDBA_CLOUD_LINK_ACCESS-Ansicht auswirken. -
Sie können eine Tabelle oder View registrieren, die sich im Schema eines anderen Benutzers befindet, wenn Sie über
READ WITH GRANT OPTION-Berechtigungen für die Tabelle oder View verfügen. -
Autonomous AI Database führt keine hierarchischen Validitätsprüfungen zum Zeitpunkt der Registrierung durch, und Registrierungen, die außerhalb des Geltungsbereichs liegen, werden nie sichtbar oder zugänglich sein.
Beispiel: Beachten Sie die folgende Sequenz:
-
Ein Benutzer mit dem Geltungsbereich
MY$COMPARTMENTregistriert ein Objekt mit einem Geltungsbereich, der eine einzelne Datenbank-OCID angibt. -
Wenn ein Benutzer Zugriff auf das registrierte Dataset anfordert, führt Autonomous AI Database die Prüfung aus, ob sich die Datenbank-OCID der Datenbank, von der die Anforderung stammt, in der OCID-Liste befindet, die mit
scopeangegeben wurde, als das Dataset registriert wurde. -
Danach kann das Objekt
namespace.namein der Datenbank, aus der die Anforderung stammt, erkannt, angezeigt und verwendet werden.
-
-
Die vollständige Propagierung von
DBMS_CLOUD_LINK.UNREGISTERkann bis zu zehn (10) Minuten dauern. Danach kann der Remotezugriff auf die Daten länger dauern.
Dataset in einer anderen Region registrieren oder deren Registrierung aufheben
Sie können Cloud-Links in mehreren Regionen verwenden, wobei die Quellregion die Quelldatenbank des Datasets enthält und mindestens eine Remoteregion aktualisierbare Klone der Quelldatenbank enthält.
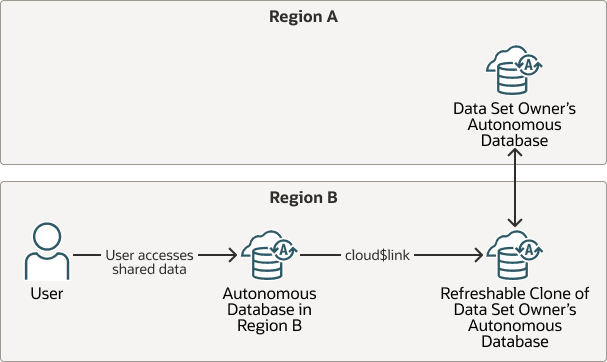
Beschreibung der Abbildung cloud-links-cross-region-refreshable-clone.png
So verwenden Sie Cloud-Links mit einem Dataset in einer anderen Region:
-
Erstellen Sie einen regionsübergreifenden aktualisierbaren Klon der Quelldatenbank in einer Remoteregion.
Informationen zum Hinzufügen eines regionsübergreifenden aktualisierbaren Klons finden Sie unter Mandantenübergreifenden oder regionsübergreifenden aktualisierbaren Klon erstellen.
-
Registrieren Sie das Dataset in der Quelldatenbank.
Weitere Informationen finden Sie unter Dataset registrieren oder Registrierung aufheben.
-
Aktualisieren Sie den aktualisierbaren Klon.
Weitere Informationen finden Sie unter Aktualisierbaren Klon in einer autonomen KI-Datenbank aktualisieren.
-
Registrieren Sie das Dataset auf dem entfernten aktualisierbaren Klon mit denselben Argumenten, die Sie zum Registrieren des Datasets in der Quellregion verwendet haben.
Beispiel: Wenn die Instanz der autonomen KI-Datenbank ein Schema
CLOUDLINKenthält, registrieren Sie nach der RegistrierungSALES_ALLin der QuelldatenbankSALES_ALLauf dem aktualisierbaren Klon:BEGIN DBMS_CLOUD_LINK.REGISTER( schema_name => 'CLOUDLINK', schema_object => 'SALES_ALL', namespace => 'TRUSTED_COMPARTMENT', name => 'SALES', description => 'Trusted Compartment, only accessible within my compartment. Early sales data.', scope => 'MY$COMPARTMENT', auth_required => FALSE, data_set_owner => 'amit@example.com' ); END; /Die Parameter sind:
-
schema_name: ist der Schemaname (der Objekteigentümer). -
schema_object: ist der Name des Objekts. Gültige Objekte sind:-
Tabellen (einschließlich Heap, extern oder Hybrid)
-
Ansichten
-
Materialized Views
Hinweis
Hinweis: Andere Objekte, wie Analyse-Views oder Synonyme, werden nicht unterstützt.
-
-
-
namespace: ist der Namespace, den Sie als Namen für den Zugriff mit Cloud-Links (ein Teil des Cloud-Link-FQN) angeben.Ein
NULL-Wert gibt einen systemgeneriertennamespace-Wert an, der für die Instanz der autonomen KI-Datenbank eindeutig ist.-
name: ist der Name, den Sie für den Zugriff mit Cloud-Links (ein Teil der Cloud-Link-FQN) angeben. -
description: Gibt Text zur Beschreibung der Daten an. -
scope: Gibt den Geltungsbereich an. Sie können eine der Variablen verwenden:MY$REGION,MY$TENANCYoderMY$COMPARTMENToderMY$POOLoder eine oder mehrere OCIDs angeben.Weitere Informationen finden Sie unter Dataset-Geltungsbereich, Zugriffskontrolle und Autorisierung.
-
auth_required: Ein boolescher Wert, der angibt, ob neben der Zugriffskontrolle für den Geltungsbereich auch eine Autorisierung auf Datenbankebene für das Dataset erforderlich ist. Wenn dieser Wert aufTRUEgesetzt ist, erzwingt das Dataset einen zusätzlichen Autorisierungsschritt. Weitere Informationen finden Sie unter Dataset mit erforderlicher Autorisierung registrieren. -
data_set_owner: Der Textwert gibt Informationen über die Person an, die für das Dataset verantwortlich ist, oder einen Kontakt für Fragen zum Dataset. Beispiel: Sie können eine E-Mail-Adresse für den Dataset-Eigentümer angeben.
Weitere Informationen finden Sie unter Prozedur REGISTER.
Nachdem die Registrierung im aktualisierbaren Klon abgeschlossen ist, lautet der Geltungsbereich für das registrierte Objekt
MY$COMPARTMENT: Gibt den restriktiveren Geltungsbereich auf Compartment-Ebene für mein Compartment in meinem Mandanten fürTRUSTED_COMPARTMENT.SALESan. -
Sie können die Registrierung eines Remote-Datasets nur in den Remote-Regionen oder sowohl in den Remote-Regionen als auch in der Quellregion aufheben:
So heben Sie die Registrierung eines Datasets in einer Remoteregion auf und deaktivieren den Remotezugriff auf das Dataset:
-
Heben Sie auf dem aktualisierbaren Klon die Registrierung des Datasets auf.
Beispiel:
BEGIN DBMS_CLOUD_LINK.UNREGISTER( namespace => 'TRUSTED_COMPARTMENT', name => 'SALES'); END; / -
Aktualisieren Sie den aktualisierbaren Klon.
Weitere Informationen finden Sie unter Aktualisierbaren Klon in einer autonomen KI-Datenbank aktualisieren.
So heben Sie die Registrierung eines Datasets in der Quelldatenbank auf und heben die Registrierung des Datasets in aktualisierbaren Klonen der Remoteregion auf:
-
Heben Sie die Registrierung des Datasets auf dem aktualisierbaren Remoteklon auf, wenn nur ein Klon vorhanden ist, oder auf mehreren aktualisierbaren Klonen in Remote-Regionen, wenn mehrere Klone vorhanden sind.
Beispiel:
BEGIN DBMS_CLOUD_LINK.UNREGISTER( namespace => 'TRUSTED_COMPARTMENT', name => 'SALES'); END; / -
Heben Sie in der Quelldatenbank die Registrierung des Datasets auf.
Weitere Informationen finden Sie unter Dataset registrieren oder Registrierung aufheben.
-
Aktualisieren Sie die aktualisierbaren Klone.
Weitere Informationen finden Sie unter Aktualisierbaren Klon in einer autonomen KI-Datenbank aktualisieren.
Hinweise zum Registrieren oder Aufheben der Registrierung eines Datasets in einer Remoteregion
Enthält Hinweise zur Registrierung eines Datasets in einer Remoteregion.
-
Wenn Sie ein Dataset auf einem aktualisierbaren Klon in einer Remoteregion registrieren, muss der Aufruf von
DBMS_CLOUD_LINK.REGISTERauf dem Remoteregionsklon dieselben Parameter mit denselben Werten verwenden wie auf der Quelldatenbank, mit Ausnahme des Parametersoffload_targets.Beispiel: Wenn Sie
DBMS_CLOUD_LINK.REGISTERmit dem GeltungsbereichMY$COMPARTMENTin der autonomen KI-Quelldatenbankinstanz ausführen, führen Sie die Prozedur erneut auf dem regionsübergreifenden aktualisierbaren Klon mit demselben Geltungsbereichsparameterwert aus (MY$COMPARTMENT). -
Wenn Sie den Parameter
offload_targetsmitDBMS_CLOUD_LINK.REGISTERin der Quelle angeben, sollten Sie diesen Parameter weglassen, wenn Sie das Dataset im aktualisierbaren Klon registrieren. -
Nachdem Sie ein Objekt registriert haben, müssen Benutzer möglicherweise bis zu zehn (10) Minuten warten, um mit Cloud-Links auf das Objekt zuzugreifen.
-
Für die folgenden Aktionen müssen Sie den aktualisierbaren Klon aktualisieren:
-
Wenn Sie dem Dataset in der Quelle eine VPD-Policy hinzufügen, müssen Sie den aktualisierbaren Klon aktualisieren.
-
Wenn Sie eine Berechtigung oder einen Entzug für das Dataset in der Quelldatenbank ausführen, müssen Sie den aktualisierbaren Klon aktualisieren.
Weitere Informationen finden Sie unter Aktualisierbaren Klon in einer autonomen KI-Datenbank aktualisieren.
-
Dataset mit erforderlicher Autorisierung registrieren
Optional können Sie bei der Registrierung eines Datasets zusätzlich zu dem Geltungsbereich angeben, dass eine Autorisierung auf Datenbankebene für den Zugriff auf ein Dataset erforderlich ist.
Im Vergleich zum vorherigen Beispiel, bei dem Sie auth_required auf FALSE setzen, setzen Sie in diesem Beispiel auth_required auf TRUE. Wenn auth_required TRUE ist, sind zusätzliche Schritte erforderlich, um eine oder mehrere Datenbanken anzugeben, von denen aus der Zugriff auf das Dataset autorisiert wird.
Hinweis
Hinweis: Sie können die Autorisierung, wie in diesen Schritten gezeigt, nur erteilen, wenn Sie autorisiert sind. Der ADMIN erteilt Autorisierungsberechtigungen mit DBMS_CLOUD_LINK_ADMIN.GRANT_AUTHORIZE.
-
Verwenden Sie
DBMS_CLOUD_LINK.REGISTER, um Daten mit erforderlicher Autorisierung zu registrieren.Angenommen, die Instanz der autonomen KI-Datenbank enthält ein Schema
CLOUDLINK, und Sie registrieren das ObjektSALES_VIEW_AGGund setzenauth_requiredaufTRUE. Zusätzlich zur Definition des Geltungsbereichs müssen Sie zusätzliche Schritte vorgeben, um den Zugriff auf das Objekt zu bestimmen.BEGIN DBMS_CLOUD_LINK.REGISTER( schema_name => 'CLOUDLINK', schema_object => 'SALES_VIEW_AGG', namespace => 'REGIONAL_SALES', name => 'SALES_AGG', description => 'Aggregated regional sales information.', scope => 'MY$TENANCY', auth_required => TRUE, data_set_owner => 'amit@example.com' ); END; /Die Parameter sind:
-
schema_name: ist der Schemaname (der Objekteigentümer). -
schema_object: ist der Name des Objekts. Gültige Objekte sind:-
Tabellen (einschließlich Heap, extern oder Hybrid)
-
Ansichten
-
Materialized Views
Hinweis
Hinweis: Andere Objekte, wie Analyse-Views oder Synonyme, werden nicht unterstützt.
-
-
namespace: ist der Namespace, den Sie als Namen für den Zugriff mit Cloud-Links (ein Teil des Cloud-Link-FQN) angeben.Ein
NULL-Wert gibt einen systemgeneriertennamespace-Wert an, der für die Instanz der autonomen KI-Datenbank eindeutig ist. -
name: ist der Name, den Sie für den Zugriff mit Cloud-Links (ein Teil der Cloud-Link-FQN) angeben. -
scope: Gibt den Geltungsbereich an. Sie können eine der Variablen verwenden:MY$REGION,MY$TENANCYoderMY$COMPARTMENToderMY$POOLoder eine oder mehrere OCIDs angeben.Weitere Informationen finden Sie unter Dataset-Geltungsbereich, Zugriffskontrolle und Autorisierung.
-
auth_required: Ein boolescher Wert, der angibt, ob neben der Zugriffskontrolle für den Geltungsbereich auch eine Autorisierung auf Datenbankebene für das Dataset erforderlich ist. Wenn dieser Wert aufTRUEgesetzt ist, erzwingt das Dataset einen zusätzlichen Autorisierungsschritt. -
data_set_owner: Der Textwert gibt Informationen über die Person an, die für das Dataset verantwortlich ist, oder einen Kontakt für Fragen zum Dataset. Beispiel: Sie können eine E-Mail-Adresse für den Dataset-Eigentümer angeben.
-
-
Rufen Sie die Datenbank-ID für die Datenbank ab, für die Sie die Autorisierung erteilen möchten (um der Datenbank den Zugriff auf das Dataset zu ermöglichen).
Auf dem System, dem Sie Zugriff auf das Dataset gewähren möchten:
SELECT DBMS_CLOUD_LINK.GET_DATABASE_ID FROM DUAL: -
Verwenden Sie die Datenbank-ID, die Sie erhalten haben, um einem angegebenen Dataset eine Autorisierung zu erteilen.
Sie können die Autorisierung nur erteilen und
DBMS_CLOUD_LINK.GRANT_AUTHORIZATIONausführen, wie in diesem Schritt gezeigt, wenn Sie autorisiert sind. Der ADMIN erteilt die Autorisierung mitDBMS_CLOUD_LINK_ADMIN.GRANT_AUTHORIZE.BEGIN DBMS_CLOUD_LINK.GRANT_AUTHORIZATION( database_id => '120xxxxxxx8506029999', namespace => 'TRUSTED_COMPARTMENT', name => 'SALES'); END; /Führen Sie diese Schritte mehrmals aus, wenn Sie zusätzliche Datenbanken autorisieren möchten.
Sie können den Wert des Parameters auth_required aktualisieren, nachdem Sie ein Dataset registriert haben. Weitere Informationen finden Sie unter Dataset-Registrierungsattribute aktualisieren.
Wenn Sie die Autorisierung für eine Datenbank entziehen möchten:
BEGIN
DBMS_CLOUD_LINK.REVOKE_AUTHORIZATION(
database_id => '120xxxxxxx8506029999',
namespace => 'TRUSTED_COMPARTMENT',
name => 'SALES');
END;
/In den folgenden Themen finden Sie weitere Informationen:
Dataset mit Offload-Zielen für Dataset-Zugriff registrieren
Wenn Sie ein Dataset registrieren, können Sie optional den Zugriff auf das Dataset auf mindestens eine Instanz der autonomen KI-Datenbank auslagern, bei der es sich um aktualisierbare Klone handelt.
Verwenden Sie den optionalen Parameter offload_targets mit DBMS_CLOUD_LINK.REGISTER, um anzugeben, dass der Zugriff auf aktualisierbare Klone ausgelagert wird. Die Quelldatenbank für jeden aktualisierbaren Klon ist die Instanz der autonomen KI-Datenbank, in der Sie das Dataset registrieren (Datenherausgeber).
Der Wert offload_targets ist ein JSON-Dokument, das mindestens ein Schlüsselwertpaar CLOUD_LINK_DATABASE_ID und OFFLOAD_TARGET definiert:
-
CLOUD_LINK_DATABASE_IDist einer der folgenden Werte:-
Eine Datenbank-ID: Gibt eine Datenbank-ID für den Dataset-Consumer an, dessen Anforderung an den entsprechenden aktualisierbaren Klon ausgelagert wird, der mit dem Wert
OFFLOAD_TARGETangegeben ist.Rufen Sie die Datenbank-ID ab, indem Sie
DBMS_CLOUD_LINK.GET_DATABASE_IDausführen. Weitere Informationen finden Sie unter GET_DATABASE_ID-Funktion. -
ANY: Gibt an, dass die Anforderung eines Dataset-Consumers an das entsprechende Offload-Ziel ausgelagert wird. Die Dataset-Anforderung eines Consumers wird an das entsprechende Auslagerungsziel weitergeleitet.Wenn Sie
ANYangeben, ohne Datenbank-IDs anzugeben, werden alle Dataset-Anforderungen von Consumern an den aktualisierbaren Klon ausgelagert, der mit dem WertOFFLOAD_TARGETangegeben ist.Wenn Sie sowohl Datenbank-IDs als auch
ANYangeben, werden Dataset-Anforderungen von Consumern, die nicht mit einer Datenbank-ID übereinstimmen, an den aktualisierbaren Klon ausgelagert, der mit dem WertOFFLOAD_TARGETangegeben ist.
-
-
OFFLOAD_TARGETist die OCID für eine autonome AI-Datenbankinstanz, die ein aktualisierbarer Klon ist.
Die folgende Abbildung zeigt die Verwendung von Offload-Zielen.
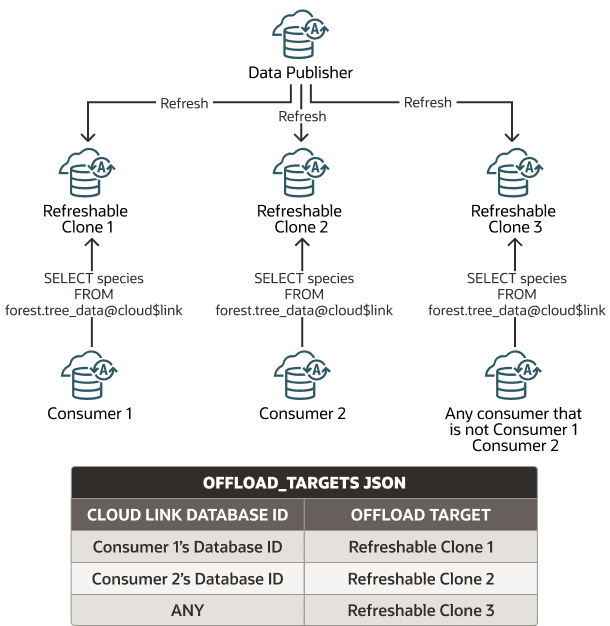
Beschreibung der Abbildung cloud-links-offload-targets-any-keyword.png
Wenn ein Dataset-Consumer Zugriff auf ein Dataset anfordert, das Sie bei offload_targets registrieren, und die Datenbank-ID der autonomen AI-Datenbankinstanz mit dem in CLOUD_LINK_DATABASE_ID angegebenen Wert übereinstimmt, wird der Zugriff auf den aktualisierbaren Klon ausgelagert, der mit OFFLOAD_TARGET in der angegebenen JSON identifiziert wird.
Beispiel: Im Folgenden wird ein JSON-Beispiel mit drei OFFLOAD_TARGET/CLOUD_LINK_DATABASE_ID-Wertpaaren dargestellt:
{
"OFFLOAD_TARGETS": [
{
"CLOUD_LINK_DATABASE_ID": "34xxxxx69708978",
"OFFLOAD_TARGET":
"ocid1.autonomousdatabase.oc1..xxxxx3pv6wkcr4jqae5f44n2b2m2yt2j6rx32uzr4h25vqstifsfabc"
},
{
"CLOUD_LINK_DATABASE_ID": "34xxxxx89898978",
"OFFLOAD_TARGET":
"ocid1.autonomousdatabase.oc1..xxxxx3pv6wkcr4jqae5f44n2b2m2yt2j6rx32uzr4h25vqstifsfdef"
},
{
"CLOUD_LINK_DATABASE_ID": "34xxxxx4755680",
"OFFLOAD_TARGET":
"ocid1.autonomousdatabase.oc1..xxxxx3pv6wkcr4jqae5f44n2b2m2yt2j6rx32uzr4h25vqstifsfghi"
}
]
}Wenn ein Dataset-Consumer Zugriff auf ein Dataset anfordert, das Sie mit offload_targets registrieren, das das Schlüsselwort ANY enthält, wird der Zugriff auf den aktualisierbaren Klon ausgelagert, der mit OFFLOAD_TARGET in der angegebenen JSON identifiziert wird (mit Ausnahme von Anforderungen von Consumern, die einen übereinstimmenden Datenbank-ID-Eintrag in der angegebenen JSON haben).
Beispiel: Im Folgenden wird ein JSON-Beispiel mit einem expliziten OFFLOAD_TARGET/CLOUD_LINK_DATABASE_ID-Wertpaar und ein ANY-Wert mit einem entsprechenden OFFLOAD_TARGET dargestellt:
{
"OFFLOAD_TARGETS": [
{
"CLOUD_LINK_DATABASE_ID": "ANY",
"OFFLOAD_TARGET":
"ocid1.autonomousdatabase.oc1..xxxxx3pv6wkcr4jqae5f44n2b2m2yt2j6rx32uzr4h25vqstifsfdef"
},
{
"CLOUD_LINK_DATABASE_ID": "34xxxxx4755680",
"OFFLOAD_TARGET":
"ocid1.autonomousdatabase.oc1..xxxxx3pv6wkcr4jqae5f44n2b2m2yt2j6rx32uzr4h25vqstifsfghi"
}
]
}So registrieren Sie ein Dataset und geben Offload-Ziele an:
-
Rufen Sie die OCID für mindestens einen aktualisierbaren Klon ab, in dem Sie den Dataset-Zugriff auslagern möchten. Aktualisierbare Klon-OCIDs sind in der Oracle Cloud Infrastructure-Konsole auf einem aktualisierbaren Klon verfügbar.
Hinweis
Hinweis: Es kann bis zu 10 Minuten dauern, nachdem Sie einen aktualisierbaren Klon erstellt haben, damit der aktualisierbare Klon als Auslagerungsziel angezeigt wird. Das bedeutet, dass Sie möglicherweise bis zu 10 Minuten warten müssen, nachdem Sie einen aktualisierbaren Klon erstellt haben, damit der aktualisierbare Klon für die Registrierung beim Auslagern von Cloud-Links verfügbar ist. -
Rufen Sie die Datenbank-ID für mindestens eine autonome KI-Datenbankinstanz ab, auf die Sie mit den vom aktualisierbaren Klon bereitgestellten Daten auf das Dataset zugreifen möchten.
Führen Sie auf dem System, auf das Sie über einen aktualisierbaren Klon auf das Dataset zugreifen möchten, den folgenden Befehl aus:
SELECT DBMS_CLOUD_LINK.GET_DATABASE_ID FROM DUAL: -
Registrieren Sie ein Dataset, und geben Sie den Parameter
offload_targetsan.Beispiel: Wenn die Instanz der autonomen KI-Datenbank ein Schema
CLOUDLINKenthält, können SieSALES_VIEW_AGGregistrieren und die aktualisierbaren Klone angeben, die Zugriff auf das Dataset ermöglichen:BEGIN DBMS_CLOUD_LINK.REGISTER( schema_name => 'CLOUDLINK', schema_object => 'SALES_VIEW_AGG', namespace => 'REGIONAL_SALES', name => 'SALES_AGG', description => 'Aggregated regional sales information.', scope => 'MY$TENANCY', auth_required => FALSE, data_set_owner => 'amit@example.com', offload_targets => '{ "OFFLOAD_TARGETS": [ { "CLOUD_LINK_DATABASE_ID": "34xxxx754755680", "OFFLOAD_TARGET": "ocid1.autonomousdatabase.oc1..xxxxxaaba3pv6wkcr4jqae5f44n2b2m2yt2j6rx32uzr4h25vqstifsfghi" } ] }'); END; /Die Parameter sind:
-
schema_name: ist der Schemaname (der Objekteigentümer). -
schema_object: ist der Name des Objekts. Gültige Objekte sind:-
Tabellen (einschließlich Heap, extern oder Hybrid)
-
Ansichten
-
Materialized Views
Hinweis
Hinweis: Andere Objekte, wie Analyse-Views oder Synonyme, werden nicht unterstützt.
-
-
namespace: ist der Namespace, den Sie als Namen für den Zugriff mit Cloud-Links (ein Teil des Cloud-Link-FQN) angeben.Ein
NULL-Wert gibt einen systemgeneriertennamespace-Wert an, der für die Instanz der autonomen KI-Datenbank eindeutig ist. -
name: ist der Name, den Sie für den Zugriff mit Cloud-Links (ein Teil der Cloud-Link-FQN) angeben. -
scope: Gibt den Geltungsbereich an. Sie können eine der Variablen verwenden:MY$REGION,MY$TENANCYoderMY$COMPARTMENToderMY$POOLoder eine oder mehrere OCIDs angeben.Weitere Informationen finden Sie unter Dataset-Geltungsbereich, Zugriffskontrolle und Autorisierung.
-
auth_required: Ein boolescher Wert, der angibt, ob neben der Zugriffskontrolle für den Geltungsbereich auch eine Autorisierung auf Datenbankebene für das Dataset erforderlich ist. Wenn dieser Wert aufTRUEgesetzt ist, erzwingt das Dataset einen zusätzlichen Autorisierungsschritt. Weitere Informationen finden Sie unter Dataset mit erforderlicher Autorisierung registrieren. -
data_set_owner: Der Textwert gibt Informationen über die Person an, die für das Dataset verantwortlich ist, oder einen Kontakt für Fragen zum Dataset. Beispiel: Sie können eine E-Mail-Adresse für den Dataset-Eigentümer angeben. -
offload_targets: Gibt eine oder mehrere OCIDs der autonomen KI-Datenbank von aktualisierbaren Klonen an, in denen der Zugriff auf Datasets aus der autonomen KI-Datenbank ausgelagert wird, in der das Dataset registriert ist.Für jeden Dataset-Consumer kann eine der folgenden Übereinstimmungen bestehen, um die Anforderung an einen aktualisierbaren Klon auszulagern:
-
Wenn der Wert der angegebenen
cloud_link_database_idübereinstimmt, d.h. die Werte mit der Datenbank-ID des Verbrauchers übereinstimmen, wird der Zugriff auf den aktualisierbaren Klon ausgelagert, der durch die inoffload_targetangegebene OCID identifiziert wird. -
Wenn das Schlüsselwort
ANYangegeben wird und der Wert eines angegebenencloud_link_database_idnicht übereinstimmt, wird der Zugriff auf den aktualisierbaren Klon ausgelagert, der mit dem Eintrag ANY durch die im entsprechendenoffload_targetangegebene OCID identifiziert wird.
-
Hinweis
Hinweis: Wenn Ihr Datenherausgeber entweder ein Elastic Pool Leader oder ein Elastic Pool Member ist, können Sie alternativ zur Konfiguration der Offload-Zieldetails mitoffload_targetsdie Funktion zum Auslagern einheitlicher Abfragen verwenden. In diesem Fall ermöglicht der Herausgeber die Auslagerung von ProxySQL-Abfragen, um Abfragen (Lesevorgänge) an eine beliebige Anzahl aktualisierbarer Klone auszulagern, ohne dass die Ziele konfiguriert werden müssen. Weitere Informationen finden Sie unter Einheitliche Abfrageauslagerung mit Cloud-Links verwenden.In den folgenden Themen finden Sie weitere Informationen:
-
Dataset-Registrierungsattribute aktualisieren
Nachdem Sie ein Dataset registriert haben, können Sie einige Dataset-Attribute aktualisieren. Sie können die Schemanamen-, Schemaobjekt-, Namespace- oder Namensattribute nicht aktualisieren.
So aktualisieren Sie Dataset-Attribute:
-
Der Benutzer, der ein Dataset registriert hat, kann seine Attribute mit
DBMS_CLOUD_LINK.UPDATE_REGISTRATIONaktualisieren.Wenn Sie keine Berechtigungen zum Aktualisieren von Dataset-Attributen haben, müssen Sie Registrierungsberechtigungen vom ADMIN-Benutzer erteilen.
Weitere Informationen finden Sie unter Zugriff auf Cloud-Links für Datenbankbenutzer erteilen.
-
Aktualisieren Sie mindestens ein Attribut für ein Dataset.
Beispiel: Verwenden Sie
DBMS_CLOUD_LINK.UPDATE_REGISTRATION, um die Attributedescription,scopeundauth_requiredfür das Dataset im NamespaceREGIONAL_SALESmit dem NamenSALES_AGGzu aktualisieren:BEGIN DBMS_CLOUD_LINK.UPDATE_REGISTRATION( namespace => 'REGIONAL_SALES', name => 'SALES_AGG', description => 'Updated description for aggregated regional sales information.', scope => 'MY$COMPARTMENT', auth_required => TRUE ); END; /Die erforderlichen Parameter sind:
-
namespace: ist der Namespace des Datasets, den Sie beim Registrieren des Datasets angegeben haben. -
name: Der Name des Datasets, den Sie beim Registrieren des Datasets angegeben haben.
Im Folgenden finden Sie eine Liste der optionalen Parameter. Wenn
NULLfür einen optionalen Parameterwert übergeben wird, wird das Attribut nicht geändert.-
description: Gibt den aktualisierten Text zur Beschreibung der Daten an. -
scope: Gibt den Geltungsbereich an. Sie können eine der Variablen verwenden:MY$REGION,MY$TENANCYoderMY$COMPARTMENToderMY$POOLoder eine oder mehrere OCIDs angeben.Weitere Informationen finden Sie unter Dataset-Geltungsbereich, Zugriffskontrolle und Autorisierung.
-
auth_required: Ein boolescher Wert, der angibt, ob neben der Zugriffskontrolle für den Geltungsbereich auch eine Autorisierung auf Datenbankebene für das Dataset erforderlich ist. Wenn dieser Wert aufTRUEgesetzt ist, erzwingt das Dataset einen zusätzlichen Autorisierungsschritt. Weitere Informationen finden Sie unter Dataset mit erforderlicher Autorisierung registrieren. -
data_set_owner: Der Textwert gibt Informationen über die Person an, die für das Dataset verantwortlich ist, oder einen Kontakt für Fragen zum Dataset. Beispiel: Sie können eine E-Mail-Adresse für den Dataset-Eigentümer angeben. -
offload_targets: Gibt eine oder mehrere OCIDs der autonomen KI-Datenbank von aktualisierbaren Klonen an, in denen der Zugriff auf Datasets aus der autonomen KI-Datenbank ausgelagert wird, in der das Dataset registriert ist. Weitere Informationen finden Sie unter Dataset mit Offload-Zielen für Dataset-Zugriff registrieren.
Sie können die Attribute
schema_nameoderschema_objectnicht aktualisieren.Weitere Informationen finden Sie unter Prozedur UPDATE_REGISTRATION.
-
Wenn ein Dataset in einem oder mehreren regionsübergreifenden aktualisierbaren Klonen registriert ist, müssen alle Änderungen an der Registrierung in der Quelldatenbank an die Remote-Regionen propagiert werden.
Beachten Sie Folgendes, um Änderungen an regionsübergreifenden aktualisierbaren Klonen zu propagieren:
-
Wenn ein Producer über N regionsübergreifende aktualisierbare Klone in einer Region verfügt, z.B. in Region A, führen Sie
DBMS_CLOUD_LINK.UPDATE_REGISTRATIONauf genau einem aktualisierbaren Klon in Region A aus. -
Wenn derselbe Producer regionsübergreifende aktualisierbare Klone in einer anderen Remoteregion hat, z.B. in Region B, führen Sie
DBMS_CLOUD_LINK.UPDATE_REGISTRATIONauf genau einem aktualisierbaren Klon in Region B aus.
So aktualisieren Sie Attribute, wenn ein Dataset in mindestens einem regionsübergreifenden aktualisierbaren Klon registriert ist:
-
Aktualisieren Sie in der Quelldatenbank die Dataset-Registrierung.
-
Aktualisieren Sie auf einem Remote-Klon für aktualisierbare Klone in der Remoteregion, wenn nur eine Remoteregion vorhanden ist, oder auf einem Remote-Klon für aktualisierbare Klone in jeder Remoteregion, wenn replizierte aktualisierbare Klone in mehreren Regionen vorhanden sind, die Dataset-Registrierung mit denselben Werten, die Sie zum Aktualisieren der Quelldatenbank verwendet haben, mit Ausnahme des Parameters
offload_targets.In einer bestimmten Remoteregion müssen Sie
DBMS_CLOUD_LINK.UPDATE_REGISTRATIONnur auf genau einem aktualisierbaren Klon in dieser Region ausführen (wenn in der Region mehrere aktualisierbare Klone mit demselben Dataset verknüpft sind, müssen Sie die Prozedur nur einmal ausführen, um die Änderungen an alle aktualisierbaren Klone in einer einzelnen Remoteregion zu propagieren). -
Aktualisieren Sie die aktualisierbaren Klone.
Weitere Informationen finden Sie unter Aktualisierbaren Klon in einer autonomen KI-Datenbank aktualisieren.
Datasets suchen und Cloud-Links verwenden
Ein Benutzer, dem Zugriff auf das Lesen von Cloud-Links erteilt wurde, kann nach Datasets suchen, die für eine autonome KI-Datenbankinstanz verfügbar sind, und kann auf registrierte Datasets mit ihren Abfragen zugreifen und sie verwenden.
Nachdem der ADMIN-Benutzer GRANT_READ ausgeführt hat, kann ein Benutzer nach Cloudlinks suchen und diese verwenden.
-
Suchen Sie die verfügbaren Datasets in Ihrer autonomen KI-Datenbankinstanz.
Beispiel: Suchen Sie nach allen Datasets, die den String "TREE" enthalten:
DECLARE result CLOB DEFAULT NULL; BEGIN DBMS_CLOUD_LINK.FIND('TREE', result); DBMS_OUTPUT.PUT_LINE(result); END; / [{"name":"TREE_DATA","namespace":"FOREST","description":"Urban tree data including county, species and height"}]Die Parameter sind:
-
search_string: Die Zeichenfolge, die gesucht werden soll. Bei der Suchfolge wird die Groß-/Kleinschreibung nicht beachtet. -
search_result: Ein JSON-Dokument, das Namespace-, Namens- und Beschreibungswerte für das Dataset enthält.
Weitere Informationen finden Sie unter FIND-Prozedur.
Die Prozedur
DBMS_CLOUD_LINK.FINDenthält den FQN, den Sie mit Cloud-Links verwenden können. in diesem FallFOREST.TREE_DATA. -
-
Verwenden Sie die Ansicht
DBA_CLOUD_LINK_ACCESS, um verfügbare Datasets aufzulisten:SELECT * FROM DBA_CLOUD_LINK_ACCESS;NAMESPACE NAME --------- -------------- FOREST TREE_DATA REGIONAL_SALES SALES_AGG TRUSTED_COMPARTMENT SALES -
Verwenden Sie die Prozedur
DBMS_CLOUD_LINK.DESCRIBE, um weitere Details zu einem registrierten Dataset anzuzeigen.SELECT DBMS_CLOUD_LINK.DESCRIBE('FOREST','TREE_DATA') FROM DUAL;DBMS_CLOUD_LINK.DESCRIBE('FOREST','TREE_DATA') --------------------------------------------------- Urban tree data including county, species and height -
Verwenden Sie das registrierte Dataset in einer Abfrage.
SELECT * FROM FOREST.TREE_DATA@cloud$link;
Hinweis
Hinweis: Es kann bis zu 10 Minuten dauern, nachdem Sie ein Dataset mit DBMS_CLOUD_LINK.REGISTER registriert haben, damit das Dataset sichtbar und zugänglich ist.
Cloud-Links unterstützen private und öffentliche Synonyme. Beispiel: Sie können ein Synonym für FOREST.TREE_DATA@cloud$link definieren und verwenden:
CREATE SYNONYM S1 for FOREST.TREE_DATA@cloud$link;
CREATE PUBLIC SYNONYM S2 for FOREST.TREE_DATA@cloud$link;
SELECT * FROM S1;
SELECT * FROM S2;Weitere Informationen finden Sie unter SYNONYM ERSTELLEN.
Consumer-Optionen für Cloudlinks verwenden
Sie können die Zuordnung des Servicenamens für den Zugriff auf Daten aus einer Consumer-Datenbank festlegen. Außerdem können Sie das Caching für einen Dataset-Consumer für die Ergebnisse einer Abfrage oder für ein Abfragefragment aktivieren, das auf Cloud Link-Daten zugreift.
Zuordnung von Datenbankservicenamen für Cloud-Link-Consumer festlegen
Sie können die Servicenamenszuordnung so festlegen, dass sie verwendet wird, wenn Cloudlinks-Consumer auf Daten von einem Dataset-Eigentümer zugreifen.
Cloud-Links verlassen sich auf Datenbankressourcen in der autonomen KI-Datenbankinstanz, die der Dataset-Producer oder die Ressourcen eines aktualisierbaren Klons ist, um auf gemeinsame Daten zuzugreifen. Standardmäßig verwendet die Remotekonnektivität für Consumer für den Zugriff auf Cloud-Links-Daten den Datenbankservice MEDIUM.
Verwenden Sie DBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPING, um die Datenbankservicezuordnung für einen Consumer festzulegen. In diesem Verfahren geben Sie entweder eine Datenbank-ID oder das Schlüsselwort ANY an, um die Consumer-Servicezuordnung anzugeben. Beispiel: Die folgende Abbildung zeigt eine Zuordnung für Consumer A zum HIGH-Service, Consumer B zum MEDIUM-Service, Consumer C zum LOW-Service und eine Zuordnung für ANY zum TP-Service. Das bedeutet, dass alle anderen Consumer über den TP-Service auf Cloud-Links zugreifen.
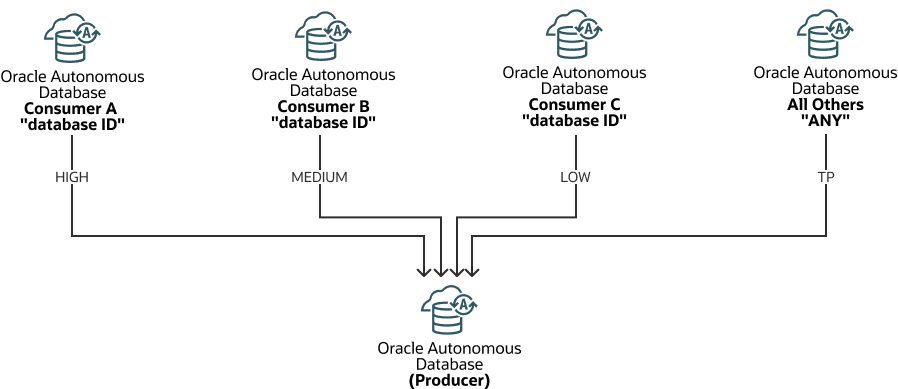
Beschreibung der Abbildung autonome-cloud-links-service-mapping.png
Weitere Informationen zu den Eigenschaften von Datenbankservices finden Sie unter Datenbankservicenamen für autonome KI-Datenbank.
Führen Sie die folgenden Schritte aus, um den Datenbankservice für einen Cloud-Links-Consumer festzulegen:
-
Rufen Sie die Datenbank-ID für die Datenbank ab, für die Sie eine Servicezuordnung festlegen möchten.
Führen Sie in der Consumer-Datenbank
GET_DATABASE_IDaus, um die Datenbank-ID des Consumers abzurufen. Beispiel:SELECT DBMS_CLOUD_LINK.GET_DATABASE_ID FROM DUAL:Weitere Informationen finden Sie unter GET_DATABASE_ID-Funktion.
-
Geben Sie in der Instanz der autonomen KI-Datenbank des Dataset-Eigentümers eine Servicezuordnung an.
Führen Sie diesen Schritt für die autonome KI-Datenbankinstanz des Dataset-Eigentümers aus (d.h. für die Producer-Datenbank).
BEGIN DBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPING( database_id => '*database_id*', service_name => 'HIGH'); END; /Dabei entspricht der Parameterwert
database_idder Datenbank-ID, die Sie in Schritt 1 abgerufen haben.Geben Sie den Wert
ANYfür diedatabase_idan, um die angegebeneservice_namemit allen Consumer-Datenbanken zu verwenden, denen keineservice_namemit derdatabase_idverknüpft ist. Das heißt, jededatabase_id, derenservice_namenicht mitDBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPINGfestgelegt wurde.Weitere Informationen finden Sie unter Prozedur ADD_SERVICE_MAPPING.
Nur der ADMIN-Benutzer und die Schemas mit der Rolle
PDB_DBAkönnenDBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPINGausführen. -
Prüfen Sie die Datenbank-IDs und die Servicezuordnung, indem Sie die Cloud Links-Servicezuordnungen auflisten.
Beispiel:
SELECT * FROM DBA_CLOUD_LINK_SERVICE_MAPPINGS;Weitere Informationen finden Sie unter Ansicht DBA_CLOUD_LINK_SERVICE_MAPPINGS.
Hinweise zum Festlegen und Ändern von Servicezuordnungen:
-
Service-Mappings treten zum Zeitpunkt der Verbindungsherstellung in Kraft. Wenn die Service-Mappings eines bestimmten Consumers geändert werden, werden die neuen Mappings nur für neue Sessions vom Consumer wirksam.
-
Jede Servicezuordnung, die in einem Dataset-Eigentümer für einen bestimmten Consumer konfiguriert ist, wird auch dann berücksichtigt, wenn der Zugriff vom Consumer auf einen aktualisierbaren Clone ausgelagert wird. Der aktualisierbare Klon muss bis zu einem Zeitpunkt nach der Konfiguration von Servicezuordnungen im Dataset-Eigentümer aktualisiert werden. Beachten Sie, dass die Auslagerung in einen aktualisierbaren Klon während der Dataset-Registrierung mit dem Argument
offload_targetskonfiguriert wird.Weitere Informationen finden Sie unter Dataset mit Offload-Zielen für Dataset-Zugriff registrieren.
-
Verwenden Sie die Prozedur
DBMS_CLOUD_LINK_ADMIN.REMOVE_SERVICE_MAPPING, um eine Servicezuordnung für eine angegebenedatabase_idzu entfernen.Nach der Ausführung von
DBMS_CLOUD_LINK_ADMIN.REMOVE_SERVICE_MAPPINGverwendet ein Consumer entweder den standardmäßigen DatenbankserviceMEDIUModer den angegebenenservice_name, wenn SieDBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPINGmit dem Wertdatabase_idANYausführen. Weitere Informationen finden Sie unter Prozedur REMOVE_SERVICE_MAPPING. -
Zuordnung von Datenbankservicenamen für Cloud-Links-Nutzer in Remoteregion festlegen
Auf ein Dataset, das in einer Quellregion registriert ist, kann über Cloud-Links aus einer Remoteregion zugegriffen werden, wenn Sie einen regionsübergreifenden aktualisierbaren Klon in der Remoteregion erstellen.
Zuordnung von Datenbankservicenamen für Cloud-Link-Nutzer in Remoteregion festlegen
Auf ein Dataset, das in einer Quellregion registriert ist, kann über Cloud-Links aus einer Remoteregion zugegriffen werden, wenn Sie einen regionsübergreifenden aktualisierbaren Klon in der Remoteregion erstellen.
In diesem Fall müssen die Servicezuordnungen für Consumer in der Remoteregion zweimal hinzugefügt werden, in der Quelldatenbank und im aktualisierbaren Klon in der Remoteregion.
Führen Sie die folgenden Schritte aus, um die Servicezuordnungen für Cloud-Links-Consumer in einer Remoteregion festzulegen.
-
Erstellen Sie einen regionsübergreifenden aktualisierbaren Klon der Quelldatenbank. (Der aktualisierbare Klon ist ein Klon des Eigentümers des Cloudlinks-Datasets in der Remoteregion.)
Weitere Informationen finden Sie unter Mandantenübergreifenden oder regionsübergreifenden aktualisierbaren Klon erstellen.
-
Registrieren Sie das Dataset.
Weitere Informationen finden Sie unter Dataset registrieren.
-
Fügen Sie die Servicezuordnungen zum Dataset-Eigentümer hinzu.
Weitere Informationen finden Sie unter Datenbankservice-Namenszuordnung für Cloud-Link-Nutzer festlegen.
-
Aktualisierbaren Klon aktualisieren.
Weitere Informationen finden Sie unter Aktualisierbaren Klon in einer autonomen KI-Datenbank aktualisieren.
-
Registrieren Sie auf dem Remote-Klon "Aktualisierbarer Klon" das Dataset mit denselben Argumenten, die Sie zum Registrieren des Datasets im Quellbereich verwendet haben (d.h. verwenden Sie dieselben Argumente, die Sie in Schritt 2 verwendet haben).
-
Fügen Sie auf dem entfernten aktualisierbaren Klon die Servicezuordnungen mit denselben Argumenten hinzu, die Sie in der Quellregion verwendet haben (d.h. verwenden Sie dieselben Argumente, die Sie in Schritt 3 verwendet haben).
Wenn ein Consumer in der Remoteregion auf Cloudlinks-Daten zugreift, verwendet der Zugriff dieselben Servicezuordnungen, die Sie in der Datenbank des Dataset-Eigentümers der Quellregion hinzugefügt haben.
Caching für einen Cloud Link Consumer aktivieren
Sie können das Caching für einen Dataset-Consumer für die Ergebnisse einer Abfrage oder für ein Abfragefragment aktivieren, das auf Cloud Link-Daten zugreift.
Um das Caching für einen Dataset-Consumer zu aktivieren, verwenden Sie den Hint RESULT_CACHE mit der Option SHELFLIFE. Mit der Option SHELFLIFE geben Sie einen Wert an, der angibt, wie lange ein Abfrageergebnis in Sekunden gecacht wird. Nach Ablauf des Intervalls SHELFLIFE wird das gecachte Ergebnis als ungültig markiert. Solange das gecachte Ergebnis gültig ist, ruft eine Abfrage die gecachten Daten aus dem Cache der Consumer-Datenbank ab, wodurch ein Roundtrip zur Datenbank des Dataset-Eigentümers vermieden wird.
Verwenden Sie den Hint RESULT_CACHE mit der Option SHELFLIFE, wenn das Dataset statisch ist oder wenn der Consumer veraltete Ergebnisse tolerieren kann. Mit dem Wert SHELFLIFE kann der Dataset-Consumer für den Cloud-Link die Zeit in Sekunden steuern, zu der die Daten im Cache gültig sind (der zulässige Grad der Veralterung).
Wenn das Abfrageergebnis groß ist und nicht in den Arbeitsspeicher passt, können Sie den Hint RESULT_CACHE mit der Option SHELFLIFE und der Option TEMP verwenden, um anzugeben, dass das Ergebnis auf den Datenträger im temporären Tablespace geschrieben werden soll.
So cachen Sie Cloud-Verknüpfungsdaten mit dem Hint RESULT_CACHE:
-
Geben Sie in einer Abfrage den Hint
RESULT_CACHEmit der OptionSHELFLIFEan.Beispiel:
SELECT /*+ RESULT_CACHE (SHELFLIFE=120) */ * FROM FOREST.TREE_DATA@cloud$link;Diese
RESULT_CACHEgibt einenSHELFLIFE-Wert von 120 an. Das bedeutet, dass das Ergebnis 120 Sekunden lang im Speicher gecacht werden muss. Nach 120 Sekunden wird das gecachte Ergebnis als ungültig markiert.Der
SHELFLIFE-Wert muss eine positive ganze Zahl sein. Der maximaleSHELFLIFE-Wert ist 4294967295. -
Wenn das Abfrageergebnis groß ist und nicht in den Speicher passt, geben Sie mit den Optionen
SHELFLIFEundTEMPan, dass das Ergebnis im temporären Tablespace auf den Datenträger geschrieben werden soll.SELECT /*+ RESULT_CACHE (TEMP=true SHELFLIFE=360) */ * FROM FOREST.TREE_DATA@cloud$link;
Weitere Informationen zur Verwendung des Ergebniscaches mit Autonomous AI Database finden Sie unter RESULT_CACHE_MODE.
Weitere Informationen zu RESULT_CACHE mit SHELFLIFE finden Sie unter RESULT_CACHE-Hinweis.
Informationen zu Prozeduren zur Verwaltung des Ergebniscaches und zur Invalidierung von Objekten im Ergebniscache finden Sie unter DBMS_RESULT_CACHE.
Cloud-Links überwachen und anzeigen - Informationen
Die autonome KI-Datenbank bietet Ansichten, mit denen Sie Cloud-Links überwachen und auditieren können.
| Anzeigen | Beschreibung |
|---|---|
| V$CLOUD_LINK_ACCESS_STATS- und GV$CLOUD_LINK_ACCESS_STATS-Views | Damit können Sie den Zugriff auf jedes registrierte Dataset in der autonomen KI-Datenbankinstanz verfolgen. In diesen Views werden die verstrichene Zeit, die CPU-Zeit, die Anzahl der abgerufenen Zeilen und zusätzliche Informationen zu registrierten Datasets erfasst. Sie können die Informationen in diesen Ansichten verwenden, um Zugriff und Nutzung von Cloud-Links-Datasets zu auditieren. |
| DBA_CLOUD_LINK_REGISTRATIONS und ALL_CLOUD_LINK_REGISTRATIONS Views | Hiermit werden Details der registrierten Datasets in einer autonomen KI-Datenbankinstanz aufgelistet. |
| DBA_CLOUD_LINK_ACCESS und ALL_CLOUD_LINK_ACCESS Views | Auf dieser Seite rufen Sie Details zu registrierten Datasets ab, auf die eine Datenbank zugreifen darf. |
| Ansicht - DBA_CLOUD_LINK_AUTHORIZATIONS | Liefert Informationen darüber, welche Datenbanken für den Zugriff auf welche Datasets autorisiert sind. Dies gilt für Datasets, bei denen der Parameter auth_required TRUE ist. |
| DBA_CLOUD_LINK_PRIVS und USER_CLOUD_LINK_PRIVS Views | Enthält Informationen zu den Cloud-Link-spezifischen Berechtigungen REGISTER, READ oder AUTHORIZE, die allen Benutzern oder dem aktuellen Benutzer erteilt wurden. |
| Ansicht - DBA_CLOUD_LINK_SERVICE_MAPPINGS | Zeigt Details aller Servicezuordnungen für Cloud-Links-Consumerdatenbanken an. Jede Servicezuordnung besteht aus einer Cloud Link-Datenbank-ID und einem Datenbankservice. |
Policy für eine virtuelle private Datenbank zum Sichern eines registrierten Datasets definieren
Durch die Definition von Virtual Private Database-(VPD-)Policys für ein registriertes Dataset können Sie eine feingranulierte Cloud Link-Zugriffskontrolle bereitstellen, sodass nur eine Teilmenge von Daten (Zeilen) für bestimmte Remote-Sites sichtbar ist.
Oracle Virtual Private Database (VPD) ist ein Sicherheitsfeature, mit dem Sie den Datenzugriff für Benutzer und Anwendungen dynamisch auf Zeilenebene steuern können, indem Sie Filter für dasselbe Dataset anwenden.
Jeder Benutzer, dem der Zugriff auf das Lesen von Cloud-Links gewährt wird, kann auf registrierte Datasets zugreifen und diese verwenden, wenn sie innerhalb des bei der Registrierung des Datasets angegebenen Geltungsbereichs liegen und wenn der Parameter "Zusätzliche Autorisierung erforderlich" für das Dataset festgelegt ist, stammt der Zugriff aus einer autorisierten Datenbank. Jeder Remotezugriff erfolgt im Kontext der autonomen Remote-AI-Datenbankinstanz, die auf das registrierte Dataset zugreift (in der Datenbank, in der das Dataset registriert wurde).
Mit der Funktion DBMS_CLOUD_LINK.GET_DATABASE_ID auf dem Remote-System rufen Sie die eindeutige ID der Datenbank ab. Indem Sie eine VPD-Policy für die Datenbank definieren, die ein Dataset registriert hat, können Sie jetzt die ID der Remotedatenbank als SYS_CONTEXT-Regel verwenden, um eine fein granuliertere Kontrolle bereitzustellen. Sie können Regeln für Remote-Datenbanken definieren, die auf Ihr registriertes Dataset zugreifen, und den Zugriff über das Mögliche hinaus einschränken, indem Sie einen Cloud-Link-Geltungsbereich angeben.
Beispiel: REGIONAL_SALES.SALES_AGG wird auf Mandantenebene verfügbar gemacht. Wenn Sie den Zugriff auf alle Datenbanken mit Ausnahme einer bestimmten Datenbank einschränken möchten und nur den vollständigen Zugriff auf die angegebene Datenbank zulassen möchten, können Sie eine VPD-Policy für das registrierte Dataset hinzufügen.
Beispiel:
-
Rufen Sie die eindeutige Cloud Link-Datenbank-ID für die autonome KI-Datenbankinstanz ab, auf die Sie vollständigen Zugriff gewähren möchten.
DECLARE DB_ID NUMBER; BEGIN DB_ID := DBMS_CLOUD_LINK.GET_DATABASE_ID; DBMS_OUTPUT.PUT_LINE('Database ID:' || DB_ID); END; / -
Erstellen Sie eine VPD-Policy für die Datenbank, die das Dataset registriert hat, indem Sie nur den vollständigen Zugriff auf die eine bestimmte Datenbank zulassen, deren ID Sie in der betreffenden Datenbank in Schritt 1 erhalten haben.
CREATE OR REPLACE FUNCTION vpd_policy_sales( owner IN VARCHAR2, object IN VARCHAR2) RETURN VARCHAR2 IS BEGIN IF SYS_CONTEXT('USERENV', 'CLOUD_LINK_DATABASE_ID') <> '12121212163948244901' THEN RETURN 'time_id >= trunc(sysdate,''year'')'; ELSE RETURN ''; END IF; END; /Weitere Informationen finden Sie unter DBMS_RLS.
-
Registrieren Sie die VPD-Policy für das registrierte Dataset, um den vollständigen Zugriff nur auf die in Schritt 1 angegebene Datenbank zu begrenzen.
BEGIN DBMS_RLS.ADD_POLICY(object_schema => 'CLOUDLINK', object_name => 'SALES_VIEW_AGG', policy_name => 'THIS_YEAR', function_schema => 'ADMIN', policy_function => 'VPD_POLICY_SALES', statement_types => 'SELECT', policy_type => DBMS_RLS.SHARED_CONTEXT_SENSITIVE); END; /Weitere Informationen finden Sie unter DBMS_RLS.
Weitere Informationen finden Sie unter Datenzugriff mit der Oracle Virtual Private Database steuern.
Cloudlinks aus einer autonomen KI-Datenbankinstanz mit Schreibschutz verwenden
Sie können Cloud-Links freigeben, wenn sich ein Dataset auf einer autonomen KI-Datenbankinstanz mit Schreibschutz befindet.
So teilen Sie Cloud-Links von einer autonomen KI-Datenbankinstanz im schreibgeschützten Modus:
-
Ändern Sie den Datenbankmodus in den Lese-/Schreibmodus.
Weitere Informationen finden Sie unter Betriebsmodus für autonome KI-Datenbanken in "Lesen/Schreiben" oder "Eingeschränkt" ändern.
-
Wenn sich die Datenbank im Lese-/Schreibmodus befindet, führen Sie die Schritte zum Registrieren eines Datasets aus.
-
Nachdem Sie ein oder mehrere Datasets registriert haben, ändern Sie die Datenbank in den schreibgeschützten Modus.
Weitere Informationen finden Sie unter Betriebsmodus für autonome KI-Datenbanken in "Lesen/Schreiben" oder "Eingeschränkt" ändern.
Hinweise zu Cloud-Links
Enthält Hinweise und Einschränkungen zur Verwendung von Cloud-Links.
-
Die Anzahl der Datensätze, die Sie registrieren können, ist auf 4096 begrenzt.
Jede autonome AI-Datenbankinstanz kann maximal 4096 Datasets registrieren. Dieses Limit gilt für jede Instanz der autonomen KI-Datenbank, unabhängig von der Anzahl der ECPUs (OCPUs, wenn Ihre Datenbank OCPUs verwendet) oder der Speichergröße der Instanz. Das Limit ist ein fester Wert. Wenn Sie die ECPU-Anzahl auf einen größeren Wert setzen, können Sie keine weiteren Datasets registrieren.
-
Sie können ein Objekt in einem anderen Schema registrieren, wenn Sie über die Berechtigung
READ WITH GRANT OPTIONfür das Objekt verfügen. -
Um Datasets zu registrieren oder Remote-Datasets anzuzeigen und darauf zuzugreifen, müssen Sie die entsprechende Berechtigung zum Registrieren oder Lesen von Datasets erteilt haben. Dies gilt auch für ADMIN. ADMIN kann diese Berechtigung jedoch selbst erteilen.
-
Um
DBMS_CLOUD_LINK.REGISTERoderDBMS_CLOUD_LINK.UPDATE_REGISTRATIONverwenden zu können, benötigen Sie neben der Registrierungsberechtigung, dieDBMS_CLOUD_LINK_ADMIN.GRANT_REGISTERzugewiesen ist, Ausführungsberechtigung für das PackageDBMS_CLOUD_LINK. Nur der ADMIN-Benutzer und die Schemas mitPDB_DBAverfügen standardmäßig über diese Berechtigung. -
Wenn Sie eine registrierte Tabelle löschen und neu erstellen, müssen Sie die Tabelle für den Remotezugriff neu registrieren.
-
Nur der ADMIN-Benutzer und Benutzer mit der Rolle
PDB_DBAsind berechtigt, auf die folgenden Ansichten zuzugreifen:-
DBA_CLOUD_LINK_ACCESS -
DBA_CLOUD_LINK_REGISTRATIONS -
DBA_CLOUD_LINK_AUTHORIZATIONS -
DBA_CLOUD_LINK_PRIVS
Weitere Informationen finden Sie unter DBMS_CLOUD_LINK Views.
-
-
Für den Zugriff auf registrierte Remote-Daten muss die Remotedatenbank geöffnet sein. Wenn die Remotedatenbank geschlossen oder im eingeschränkten Modus ist, können Sie nicht auf die Daten zugreifen, und ein Oracle-Fehler wird zurückgegeben.
-
Pro Session sind maximal vier offene Datenbanklinks zulässig. Wenn Sie dieses Limit überschreiten, kann dies zu
ORA-02020oderORA-12545führen. -
Wenn der Ergebniscache aktiviert ist, wie das Standardverhalten in der autonomen KI-Datenbank mit Lakehouse-Workload, müssen Sie sicherstellen, dass der Ergebniscache nicht verwendet wird, wenn Echtzeitdaten erforderlich sind.
-
Wenn Sie Ihren Lizenztyp von "Kostenlos" auf "Kostenpflichtig" aktualisieren, müssen Sie Cloud-Links-Datasets erneut registrieren. Weitere Informationen finden Sie unter Instanz vom Typ "Immer kostenlos" mit Autonomous AI Database auf kostenpflichtig aktualisieren.
-
Die Remotekonnektivität von Cloud-Links verwendet standardmäßig den Datenbankservice
MEDIUM. Sie können den Standardwert mitDBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPINGändern, indem SieANYals Wert fürDATABASE_IDverwenden. Sie können den Datenbankservice für einen Consumer mitDBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPINGändern, indem Sie dieDATABASE_IDdes Consumers angeben. Weitere Informationen finden Sie unter Datenbankservice-Namenszuordnung für Cloud-Link-Nutzer festlegen.Sie können die Remoteverbindungen als Benutzer
C##DATA$SHAREinV$SESSIONanzeigen. Die Cloud-Links-Views V$CLOUD_LINK_ACCESS_STATS und GV$CLOUD_LINK_ACCESS_STATS-Views enthalten weitere Details zu Remoteverbindungen. -
Bei allen Schnittstellen wird die Groß-/Kleinschreibung beachtet, sofern nicht anders angegeben:
-
Alles, was Sie in die Datenbank eingeben, z.B. Benutzernamen und Tabellennamen, ist wichtig und muss in Großbuchstaben eingegeben werden.
-
Vordefinierte Variablen, z.B. die vordefinierten Geltungsbereichswerte, müssen in Großbuchstaben eingegeben werden.
-
Alles, was Sie für das Setup von Cloud-Links angeben, z.B. Namespaces oder Namen von Tabellen in einem Namespace, muss wie eingegeben angegeben angegeben werden. Beispiel: Wenn Sie einen Namespace als
treesdefinieren, müssen Sie den Namespace beim Zugriff mit SQL in doppelte Anführungszeichen ("trees") setzen.
-
-
Sie können Cloud-Links freigeben, wenn sich ein Dataset auf einer autonomen KI-Datenbankinstanz im schreibgeschützten Modus befindet. Weitere Informationen finden Sie unter Cloudlinks aus einer autonomen KI-Datenbankinstanz mit Schreibschutz verwenden.
-
Der Vorgang kann bis zu 10 Minuten dauern, nachdem Sie einen aktualisierbaren Klon erstellt haben, damit der aktualisierbare Klon als Auslagerungsziel angezeigt wird. Das bedeutet, dass Sie möglicherweise bis zu 10 Minuten warten müssen, nachdem Sie einen aktualisierbaren Klon erstellt haben, damit der aktualisierbare Klon für die Registrierung beim Auslagern von Cloud-Links verfügbar ist.
Weitere Informationen finden Sie unter Dataset mit Offload-Zielen für Dataset-Zugriff registrieren und Aktualisierbaren Klon für eine autonome KI-Datenbankinstanz erstellen.
-
Cloudlinks aus einer autonomen KI-Datenbankinstanz mit Schreibschutz verwenden
Sie können Cloud-Links freigeben, wenn sich ein Dataset auf einer autonomen KI-Datenbankinstanz mit Schreibschutz befindet.