Use Cloud Links for Read Only Data Access on Autonomous AI Database
Cloud Links provide a cloud-based method to remotely access read only data on an Autonomous AI Database instance.
About Cloud Links on Autonomous AI Database
With Cloud Links a data owner registers a table or view for remote access for a selected audience as defined by the data owner, and the data is then accessible to those with access granted at registration time. No further actions are required to set up Cloud Links and whoever is supposed to see and access your data is able to discover and work with the data.
The Cloud Links implementation leverages Oracle Cloud Infrastructure access mechanisms to make data accessible within a specific scope. Scope indicates who can remotely access the data. Scope can be set to various levels, including to the region where the database resides, to individual tenancies, or to compartments. In addition, you can specify that authorization to access a data set is limited to one or more Autonomous AI Database instances.
By creating one or more cross region refreshable clones from the source (data set owner’s) Autonomous AI Database instance, you can use Cloud Links to share data across multiple regions.
Cloud Links greatly simplify the sharing of tables or views across Autonomous AI Database instances, as compared to traditional database linking mechanisms. With Cloud Links you can discover data without requiring a complex database link setup. Autonomous AI Database provides transparent access using SQL, and implements privilege enforcement with the Cloud Links scope and by granting authorization to individual Autonomous AI Database instances.
Cloud Links introduce the concepts of regional namespaces and names for data that is made remotely accessible. This is similar to existing Oracle tables where there is a table, for example "EMP" that resides in a namespace (schema), for example "LWARD". There can only be one LWARD.EMP in your database. Cloud Links provide a similar namespace and name on a regional level, that is not tied to a single database but applies across many Autonomous AI Database instances as specified with the scope and optionally with database authorization.
For example, you can register a data set under the namespace FOREST and for security purposes or for naming convenience, you can provide a namespace and a name other than the original schema and object names. In this example, TREE_DATA is the visible name of the registered data set and this name is not required to be the name of the source table. In addition to the namespace and the name, the cloud$link keyword indicates to the database that it must resolve the source as a Cloud Link.
To access a registered data set, include the namespace, the name, and the cloud$link keyword in the FROM clause of a SELECT statement:
SELECT county, species, height FROM FOREST.TREE_DATA@cloud$link;Optionally, you can specify that access to a data set from one or more databases is offloaded to a refreshable clone. When a consumer Autonomous AI Database is listed in a data set’s offload list, access to the data set is directed to the refreshable clone. In addition, you can use the unified query offload feature where you configure an elastic pool leader or member as a cloud links provider and you enable ProxySQL query offload to offload queries (reads), to any number of refreshable clones.
Note: Cloud Links provide read only access to remote objects on an Autonomous AI Database instance. If you want to use database links with other Oracle databases or with non-Oracle databases, or if you want to use your remote data with DML operations, you need to use database links. See Use Database Links with Autonomous AI Database for more information.
Cloud Links support private and public synonyms. For example, you can define and use a synonym for FOREST.TREE_DATA@cloud$link:
CREATE SYNONYM S1 for FOREST.TREE_DATA@cloud$link;
SELECT county, species, height FROM S1;
CREATE PUBLIC SYNONYM S2 for FOREST.TREE_DATA@cloud$link;
SELECT * FROM S2;See Overview of Synonyms for more information on synonyms.
Cloud Links Terms
There are several concepts and terms to use when you work with Cloud Links:
-
Registered Data Set (Data Set): Identifies a table or view that has been enabled for remote access in an Autonomous AI Database. A registered data set also indicates who is allowed to access the data set (its scope). Data set registration defines a namespace and a name for use with Cloud Links. After data set registration, these values together specify the Fully Qualified Name (FQN) for remote access, and allow Cloud Links to manage accessibility for the data set.
-
Data Set Owner: Specify a data set owner to provide a point of contact for questions about a data set.
-
Scope: Specifies who and from where a user is allowed to access a registered data set. See Data Set Scope, Access Control, and Authorization for more details on scope.
-
OCID (Oracle Cloud Identifier): Identifies a specific Tenancy, Compartment, or Database. The scope for a registered data set can be expressed in terms of OCIDs. See Resource Identifiers for more information.
-
Data Registration: With data registration a user makes a table or view available for remote access, subject to the access restrictions imposed by scope, and optionally subject to an additional authorization step. You can allow remote access with Cloud Links on a table or view stored in the database or on data stored in Object Store.
-
Data Discovery: A registered data set can be discovered using textual queries from the database. The discovery only shows a data set if there is a privilege to access the data set. You can search to find a registered data set by name or by description.
-
Data Describe: Allows a user to retrieve a description or metadata for a table or view made available as a registered data set.
-
Offload Targets: Optionally, you can specify one or more offload targets. Offload targets are refreshable clones that provide Cloud Links data sets to specified Autonomous AI Database instances. By specifying an offload target, you can dedicate an Autonomous AI Database instance to provide data sets to separate production from development, for performance, to assure security, or for other reasons. See Use Refreshable Clones with Autonomous AI Database for more information.
Cloud Links Auditing
Any access to a registered data set using Cloud Links is logged for audit purposes. The log includes the tenancy, compartment, or database that accessed the data set, the amount of data accessed, and additional information. The V$CLOUD_LINK_ACCESS_STATS and GV$CLOUD_LINK_ACCESS_STATS Views show audit information.
Data Set Metadata and Audit Views
Each Autonomous AI Database instance provides views that expose data set metadata and that allow you to monitor and audit data usage. See Monitor and View Cloud Links Information for more information.
Data Set Scope, Access Control, and Authorization
Cloud Links leverage Oracle Cloud Infrastructure access mechanisms to make registered data sets accessible, and to protect your data with access restrictions.
Autonomous AI Database determines the accessibility of registered data sets as follows:
-
The ADMIN user specifies a scope for a user that allows the user to register data sets based on the scope provided.
-
A user who has been granted privileges to register data sets specifies a scope when they register a data set.
-
Optionally, when you register a data set, a user who has been granted authorization privileges can specify that an authorization step required to access a data set. This authorization step is in addition to scope level access authorization.
Data Set Scope
The ADMIN sets a user’s scope with DBMS_CLOUD_LINK_ADMIN.GRANT_REGISTER to be one of:
-
'MY$REGION' -
'MY$TENANCY' -
'MY$COMPARTMENT' -
'MY$POOL'
A user’s scope is hierarchical, meaning a user who is granted one of these scopes can allow access as follows:
-
MY$REGION: A user can grant remote data access to other tenancies in the region of the Autonomous AI Database instance that is registering the data set. This is the least restrictive scope. -
MY$TENANCY: A user can grant remote data access to any resource, tenancy, compartment, or database in the tenancy of the Autonomous AI Database instance that is registering the data set. This scope is more restrictive thanMY$REGIONscope. -
MY$COMPARTMENT: A user can grant remote data access to any resource, compartment, or database in the compartment of the Autonomous AI Database instance that is registering the data set. This is the most restrictive scope you can set for a user withGRANT_REGISTER. -
MY$POOL: A user can grant remote data access to any Autonomous AI Database in the same Elastic Pool as the Autonomous AI Database instance that is registering the data set (including parent/child tenancies). This scope is more restrictive thanMY$TENANCYandMY$REGIONscopes, but broader thanMY$COMPARTMENT, enabling secure, no-data-copy sharing within the pool, with permission checks done on the user's database before connecting remotely.
Next, the scope you set when you register a data set determines from where users are allowed to access the data set. The DBMS_CLOUD_LINK.REGISTER scope is a comma separated list consisting of one or more of the following:
-
Database OCID: Access to the data set is allowed for the specific Autonomous AI Database instances identified by OCID.
-
Compartment OCID: Access to the data set is allowed for databases in the compartments identified by compartment OCID.
-
Tenancy OCID: Access to the data set is allowed for databases in the tenancies identified by tenancy OCID.
-
Region name: Access to the data set is allowed for databases in the region identified by the named region. In all cases, Cloud Links access is limited to within a single region and is not cross region.
-
MY$COMPARTMENT: Access to the data set is allowed for databases in the same compartment as the data set owner.
-
MY$TENANCY: Access to the data set is allowed for databases in the same tenancy as the data set owner.
-
MY$REGION: Access to the data set is allowed for databases in the same region as the data set owner.
-
MY$POOL: Access to the data set is allowed for databases in the same Elastic Pool as the data set owner.
The scope values, MY$REGION, MY$TENANCY, MY$COMPARTMENT, and MY$POOL are variables that act as convenience macros and resolve to OCIDs.
Note:
The scope you set when you register a data set is only honored when it matches or is more restrictive than the value set with DBMS_CLOUD_LINK_ADMIN.GRANT_REGISTER. For example, assume the ADMIN granted the scope MY$TENANCY with GRANT_REGISTER, and the user specifies MY$REGION when they register a data set with DBMS_CLOUD_LINK.REGISTER. In this case they would see an error such as the following:
ORA-20001: Share privileges are not enabled for current user or it is enabled but not for scope MY$REGIONYou can also use an additional access control mechanism based on a SYS_CONTEXT value. This mechanism uses the function DBMS_CLOUD_LINK.GET_DATABASE_ID that returns an identifier that is available as a SYS_CONTEXT value.
When you register a data set with DBMS_CLOUD_LINK.REGISTER you can use the SYS_CONTEXT value in Oracle Virtual Private Database (VPD) security policies to control database access to further restrict and control what specific data can be accessed by individual Autonomous AI Database instances.
See Define a Virtual Private Database Policy to Secure a Registered Data Set for more information on using VPD policies.
The database ID value is also available in the V$CLOUD_LINK_ACCESS_STATS and GV$CLOUD_LINK_ACCESS_STATS Views that tracks access statistics and audit information.
See Using Oracle Virtual Private Database to Control Data Access for more information.
Data Set Authorization
When you register a data set, if you have been granted authorization privileges you can specify that database OCID authorization is required to access a data set. To provide database OCID authorization for a data set, use the DBMS_CLOUD_LINK.GRANT_AUTHORIZATION procedure to specify the Autonomous AI Database instances that are authorized to access the data set. Before you run DBMS_CLOUD_LINK.GRANT_AUTHORIZATION, the ADMIN must authorize you to run this procedure with DBMS_CLOUD_LINK_ADMIN.GRANT_AUTHORIZE.
Data set registration with authorization required specifies database level access for a data set, in addition to the scope access control specified for the data set, as follows:
-
Databases that are within the
SCOPEspecified and have been authorized withDBMS_CLOUD_LINK.GRANT_AUTHORIZATIONcan view rows from the data set. -
Any databases that are within the specified
SCOPEbut have not been authorized withDBMS_CLOUD_LINK.GRANT_AUTHORIZATIONcannot view data set rows. In this case, consumers without authorization see the data set as empty. -
Databases that are not within the
SCOPEspecified see an error when attempting to access the data set.
Grant Cloud Links Access for Database Users
The ADMIN user grants privileges to database users to register data sets. The ADMIN user also grants privileges to database users to access registered data sets.
When the ADMIN user grants register privileges, they provide a scope that specifies the maximum scope that a user can provide when they register a data set (within the scope hierarchy). The valid scope values for use with DBMS_CLOUD_LINK_ADMIN.GRANT_REGISTER are:
-
'MY$REGION' -
'MY$TENANCY' -
'MY$COMPARTMENT' -
'MY$POOL'
See Data Set Scope, Access Control, and Authorization for more information.
-
As the ADMIN user, allow a user to register data sets within a specified scope.
BEGIN DBMS_CLOUD_LINK_ADMIN.GRANT_REGISTER( username => 'DB_USER1', scope => 'MY$REGION'); END; /This specifies that the user
DB_USER1, has privileges to register data sets within a specified scope,'MY$REGION'.A user can query
SYS_CONTEXT('USERENV', 'CLOUD_LINK_REGISTER_ENABLED')to check if they are enabled for registering data sets.For example, the following query:
SELECT SYS_CONTEXT('USERENV', 'CLOUD_LINK_REGISTER_ENABLED') FROM DUAL;Returns '
YES' or 'NO'.See GRANT_REGISTER Procedure for more information.
-
As the ADMIN user, allow a user to access registered data sets.
EXEC DBMS_CLOUD_LINK_ADMIN.GRANT_READ('LWARD');This allows
LWARDto access registered data sets that are available to the Autonomous AI Database instance.A user can query
SYS_CONTEXT('USERENV', 'CLOUD_LINK_READ_ENABLED')to check if they are enabled forREADaccess to a data set.For example, the following query:
SELECT SYS_CONTEXT('USERENV', 'CLOUD_LINK_READ_ENABLED') FROM DUAL;Returns '
YES' or 'NO'.See GRANT_READ Procedure for more information.
-
During data registration you can set the authorization required parameter to
TRUE. When authorization required isTRUE, the ADMIN user must runDBMS_CLOUD_LINK_ADMIN.GRANT_AUTHORIZEto provide authorization to invokeDBMS_CLOUD_LINK.GRANT_AUTHORIZATION. UseDBMS_CLOUD_LINK.GRANT_AUTHORIZATIONto specify authorization details.See Register a Data Set with Authorization Required for more information.
-
When the Autonomous AI Database instance has Database Vault enabled and the table or view to be registered with Cloud Links is protected by a realm, the owner of the table or view must be authorized to the realm as a realm-owner before registration.
BEGIN DBMS_MACADM.ADD_AUTH_TO_REALM( realm_name => 'myrealm', grantee => '*object_owner*', auth_option => dbms_macutl.g_realm_auth_owner); END; /If the realm protecting the table or view is a mandatory realm, the Autonomous AI Database common schema named
C##DATA$SHARE, which is used internally as the connecting schema, must be authorized to the realm as a realm-participant.For example:
BEGIN DBMS_MACADM.ADD_AUTH_TO_REALM( realm_name => 'myrealm', grantee => 'C##DATA$SHARE', auth_option => dbms_macutl.g_realm_auth_participant); END; /See Use Oracle AI Database Vault with Autonomous AI Database for more information.
Notes for granting privileges to database users to register data sets:
-
To register data sets or see and access remote data sets, you have to have granted the appropriate privilege for either registering with
DBMS_CLOUD_LINK_ADMIN.GRANT_REGISTERor for reading data sets withDBMS_CLOUD_LINK_ADMIN.GRANT_READ.This is true for ADMIN user as well; however the ADMIN user can grant privileges to themself.
-
The views
DBA_CLOUD_LINK_PRIVSandUSER_CLOUD_LINK_PRIVSprovide information on user privileges. See Monitor and View Cloud Links Information for more information. -
A user can run the following query to check if they are enabled for authenticating registered, protected data sets:
SELECT SYS_CONTEXT('USERENV', 'CLOUD_LINK_AUTH_ENABLED') FROM DUAL;
-
Revoke Cloud Links Access for Database Users
The ADMIN user can revoke registration to disallow a user from registering data sets for remote access. The ADMIN user can also revoke privileges or database users to access registered data sets.
-
As the ADMIN user, revoke a user's privileges to register data sets.
For example:
EXEC DBMS_CLOUD_LINK_ADMIN.REVOKE_REGISTER('DB_USER1');This revokes the privileges to register data sets for the user,
DB_USER1.Running
DBMS_CLOUD_LINK_ADMIN.REVOKE_REGISTERdoes not affect data sets that are already registered. UseDBMS_CLOUD_LINK.UNREGISTERto remove access for a registered data set.See REVOKE_REGISTER Procedure and UNREGISTER Procedure for more information.
-
As the ADMIN user, revoke access to registered data sets.
For example:
EXEC DBMS_CLOUD_LINK_ADMIN.REVOKE_READ('LWARD');This revokes access to Cloud Links data sets for the user
LWARD.See REVOKE_READ Procedure for more information.
Register a Data Set
Describes the options and steps to register a table or view you own as a registered data set to share with Cloud Links.
Register or Unregister a Data Set
You can register a table or view you own as a registered data set. When you want to remove or replace the data set, you need to unregister it. After you register a data set you can changes the values of a data set’s attributes.
Data set registration defines a namespace and a name for use with Cloud Links. After data set registration, these values together specify the Fully Qualified Name (FQN) for remote access, and allow Cloud Links to manage accessibility for the data set.
To register a data set:
-
Obtain grant register privileges from the ADMIN user.
See Grant Cloud Links Access for Database Users for more information.
-
Register one ore more data sets.
For example, assuming there is a schema
CLOUDLINKon your Autonomous AI Database instance, you can register two objects,SALES_VIEW_AGGandSALES_ALLand provide differentscopeparameters to determine how the objects are accessed.BEGIN DBMS_CLOUD_LINK.REGISTER( schema_name => 'CLOUDLINK', schema_object => 'SALES_VIEW_AGG', namespace => 'REGIONAL_SALES', name => 'SALES_AGG', description => 'Aggregated regional sales information.', scope => 'MY$TENANCY', auth_required => FALSE, data_set_owner => 'amit@example.com' ); END; /BEGIN DBMS_CLOUD_LINK.REGISTER( schema_name => 'CLOUDLINK', schema_object => 'SALES_ALL', namespace => 'TRUSTED_COMPARTMENT', name => 'SALES', description => 'Trusted Compartment, only accessible within my compartment. Early sales data.', scope => 'MY$COMPARTMENT', auth_required => FALSE, data_set_owner => 'amit@example.com' ); END; /The parameters are:
-
schema_name: is the schema name (the object owner). -
schema_object: is the object's name. Valid objects are:-
Tables (including Heap, External or Hybrid)
-
Views
-
Materialized Views
-
Cloud Tables (See Use Cloud Tables to Store Logging and Diagnostic Information for more information.)
Note: Other objects such as analytic views or synonyms are not supported.
-
-
namespace: is the namespace you provide as a name for access with Cloud Links (one part of the Cloud Link FQN).A
NULLvalue specifies a system-generatednamespacevalue, unique to the Autonomous AI Database instance. -
name: is the name you provide for access with Cloud Links (one part of the Cloud Link FQN). -
description: Specifies text to describe the data. -
scope: Specifies the scope. You can use one of the variables:MY$REGION,MY$TENANCY,MY$COMPARTMENTorMY$POOLor specify one or more OCIDs.See Data Set Scope, Access Control, and Authorization for more information.
-
auth_required: A Boolean value that specifies if database level authorization is required for the data set, in addition to the scope access control. When this is set toTRUE, the data set enforces an additional authorization step. See Register a Data Set with Authorization Required for more information. -
data_set_owner: Text value specifies information about the individual responsible for the data set or a contact for questions about the data set. For example, you could supply an email address for the data set owner.
See REGISTER Procedure for more information.
For this example, after the registration completes the scope for the two registered objects are different, based on the scope parameter you supplied with
DBMS_CLOUD_LINK.REGISTER:-
MY$TENANCY: Specifies tenancy level scope forREGIONAL_SALES.SALES_AGG. -
MY$COMPARTMENT: Specifies the more restrictive compartment level scope within the tenancy forTRUSTED_COMPARTMENT.SALES.
-
You can update some of the values for a data set’s attributes after you register a data set. See Update Data Set Registration Attributes for more information.
If you want to revoke remote access to a registered data set, unregister the data set.
For example:
BEGIN
DBMS_CLOUD_LINK.UNREGISTER(
namespace => 'TRUSTED_COMPARTMENT',
name => 'SALES');
END;
/See UNREGISTER Procedure for more information.
Notes for Registering or Unregistering a Data Set
Provides notes for registering a data set with DBMS_CLOUD_LINK.REGISTER and unregistering a data set with DBMS_CLOUD_LINK.UNREGISTER.
-
After you register an object, users may need to wait up to ten (10) minutes to access the object with Cloud Links.
-
When you register a data set and you want consumers in a remote regions to access the data set, you must perform additional steps to make the data set available in a remote region. See Register or Unregister a Data Set in a Different Region for more information.
-
Use the procedure
DBMS_CLOUD_LINK.UPDATE_REGISTRATIONto change the attributes for an existing data set.The wait time for the update to complete can be up to 10 minutes for a registration change to be propagated and accessible through Cloud Links. This delay can impact the accuracy of the data in the both the
DBA_CLOUD_LINK_REGISTRATIONSandDBA_CLOUD_LINK_ACCESSviews. -
You can register a table or view that resides in another user's schema when the you have
READ WITH GRANT OPTIONprivileges for the table or view. -
Autonomous AI Database does not perform hierarchical validity checks at registration time and registrations that are outside the scope will never be visible or accessible.
For example, consider the following sequence:
-
A user with scope
MY$COMPARTMENTregisters an object with a scope that specifies an individual database OCID. -
When a user requests access to the registered data set, Autonomous AI Database performs the check to see that the database OCID of the database where the request originates is in the OCID list specified with the
scopewhen the data set was registered. -
After this, the
namespace.nameobject will be discoverable, visible, and usable in the database where the request originated.
-
-
DBMS_CLOUD_LINK.UNREGISTERmay take up to ten (10) minutes to fully propagate, after which the data can longer be accessed remotely.
Register or Unregister a Data Set in a Different Region
You can use Cloud Links in multiple regions, where the source region contains the data set’s source database and one or more remote regions contain refreshable clones of the source database.
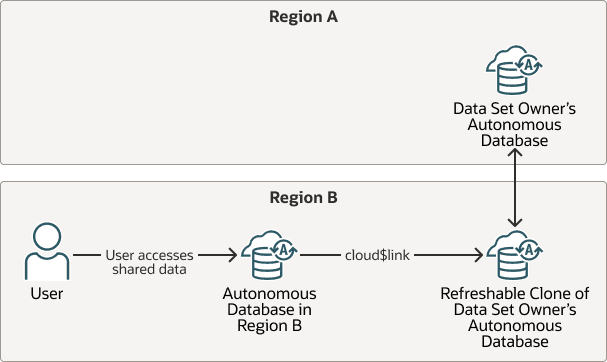
Description of the illustration cloud-links-cross-region-refreshable-clone.png
To use Cloud Links with a data set in a different region:
-
Create a cross region Refreshable Clone of the source database in a remote region.
See Create a Cross Tenancy or Cross Region Refreshable Clone for information on adding a cross region refreshable clone.
-
On the source database, register the data set.
See Register or Unregister a Data Set for more information.
-
Refresh the refreshable clone.
See Refresh a Refreshable Clone on Autonomous AI Database for more information.
-
On the remote Refreshable Clone register the data set using the same arguments you used to register the data set in the source region.
For example, assuming there is a schema
CLOUDLINKon your Autonomous AI Database instance, after you the registerSALES_ALLon the source database, registerSALES_ALLon the refreshable clone:BEGIN DBMS_CLOUD_LINK.REGISTER( schema_name => 'CLOUDLINK', schema_object => 'SALES_ALL', namespace => 'TRUSTED_COMPARTMENT', name => 'SALES', description => 'Trusted Compartment, only accessible within my compartment. Early sales data.', scope => 'MY$COMPARTMENT', auth_required => FALSE, data_set_owner => 'amit@example.com' ); END; /The parameters are:
-
schema_name: is the schema name (the object owner). -
schema_object: is the object's name. Valid objects are:-
Tables (including Heap, External or Hybrid)
-
Views
-
Materialized Views
Note: Other objects such as analytic views or synonyms are not supported.
-
-
-
namespace: is the namespace you provide as a name for access with Cloud Links (one part of the Cloud Link FQN).A
NULLvalue specifies a system-generatednamespacevalue, unique to the Autonomous AI Database instance.-
name: is the name you provide for access with Cloud Links (one part of the Cloud Link FQN). -
description: Specifies text to describe the data. -
scope: Specifies the scope. You can use one of the variables:MY$REGION,MY$TENANCY, orMY$COMPARTMENTorMY$POOLor specify one or more OCIDs.See Data Set Scope, Access Control, and Authorization for more information.
-
auth_required: A Boolean value that specifies if database level authorization is required for the data set, in addition to the scope access control. When this is set toTRUE, the data set enforces an additional authorization step. See Register a Data Set with Authorization Required for more information. -
data_set_owner: Text value specifies information about the individual responsible for the data set or a contact for questions about the data set. For example, you could supply an email address for the data set owner.
See REGISTER Procedure for more information.
After the registration completes on the refreshable clone, the scope for the registered object is
MY$COMPARTMENT: Specifies the more restrictive compartment level scope for my compartment within my tenancy forTRUSTED_COMPARTMENT.SALES. -
You can unregister a remote data set only in the remote regions, or in both the remote regions and in the source region:
To unregister a data set in a remote region and disable remote access to the data set:
-
On the refreshable clone, unregister the data set.
For example:
BEGIN DBMS_CLOUD_LINK.UNREGISTER( namespace => 'TRUSTED_COMPARTMENT', name => 'SALES'); END; / -
Refresh the refreshable clone.
See Refresh a Refreshable Clone on Autonomous AI Database for more information.
To unregister a data set on the source database and unregister the data set on remote region refreshable clones:
-
On the remote refreshable clone if there is only one, or on multiple refreshable clones in remote regions if there are more than one, unregister the data set.
For example:
BEGIN DBMS_CLOUD_LINK.UNREGISTER( namespace => 'TRUSTED_COMPARTMENT', name => 'SALES'); END; / -
On the source database, unregister the data set.
See Register or Unregister a Data Set for more information.
-
Refresh the refreshable clones.
See Refresh a Refreshable Clone on Autonomous AI Database for more information.
Notes for Registering or Unregistering a Data Set in a Remote Region
Provides notes for registering a data set in a remote region.
-
When you register a data set on a refreshable clone in a remote region, the invocation of
DBMS_CLOUD_LINK.REGISTERon the remote region clone must use the same parameters with the same values as on the source database, with the exception of theoffload_targetsparameter.For example, when you run
DBMS_CLOUD_LINK.REGISTERwith scope set toMY$COMPARTMENTon the source Autonomous AI Database instance, run the procedure again on the cross region refreshable clone with the same scope parameter value (MY$COMPARTMENT). -
If you specify the
offload_targetsparameter withDBMS_CLOUD_LINK.REGISTERon source, you should omit this parameter when you register the data set on the refreshable clone. -
After you register an object, users may need to wait up to ten (10) minutes to access the object with Cloud Links.
-
The following actions require that you refresh the refreshable clone:
-
If you add a VPD policy to the data set in the source, you must refresh the refreshable clone.
-
If you perform a grant or a revoke for the data set on the source database, you must refresh the refreshable clone.
See Refresh a Refreshable Clone on Autonomous AI Database for more information.
-
Register a Data Set with Authorization Required
Optionally, when you register a data set, in addition to the scope you can specify that database level authorization is required to access a data set.
Compared to the previous example where you set auth_required to FALSE, in this example you set auth_required to TRUE. When auth_required is TRUE, additional steps are required to specify one or more databases from which access to the data set is authorized.
Note: You can only grant authorization, as shown in these steps, if you are authorized. The ADMIN grants authorization privileges with DBMS_CLOUD_LINK_ADMIN.GRANT_AUTHORIZE.
-
Use
DBMS_CLOUD_LINK.REGISTERto register a data with authorization required.Assuming there is a schema
CLOUDLINKon your Autonomous AI Database instance and you register the objectSALES_VIEW_AGGand setauth_requiredtoTRUE, then in addition to defining the scope, you must preform additional steps to determine how the object is accessed.BEGIN DBMS_CLOUD_LINK.REGISTER( schema_name => 'CLOUDLINK', schema_object => 'SALES_VIEW_AGG', namespace => 'REGIONAL_SALES', name => 'SALES_AGG', description => 'Aggregated regional sales information.', scope => 'MY$TENANCY', auth_required => TRUE, data_set_owner => 'amit@example.com' ); END; /The parameters are:
-
schema_name: is the schema name (the object owner). -
schema_object: is the object's name. Valid objects are:-
Tables (including Heap, External or Hybrid)
-
Views
-
Materialized Views
Note: Other objects such as analytic views or synonyms are not supported.
-
-
namespace: is the namespace you provide as a name for access with Cloud Links (one part of the Cloud Link FQN).A
NULLvalue specifies a system-generatednamespacevalue, unique to the Autonomous AI Database instance. -
name: is the name you provide for access with Cloud Links (one part of the Cloud Link FQN). -
scope: Specifies the scope. You can use one of the variables:MY$REGION,MY$TENANCY, orMY$COMPARTMENTorMY$POOLor specify one or more OCIDs.See Data Set Scope, Access Control, and Authorization for more information.
-
auth_required: A Boolean value that specifies if database level authorization is required for the data set, in addition to the scope access control. When this is set toTRUE, the data set enforces an additional authorization step. -
data_set_owner: Text value specifies information about the individual responsible for the data set or a contact for questions about the data set. For example, you could supply an email address for the data set owner.
-
-
Obtain the database ID for the database you want to grant authorization to (to allow the database to access to the data set).
On the system you want to grant access the data set:
SELECT DBMS_CLOUD_LINK.GET_DATABASE_ID FROM DUAL: -
Use the database ID you obtained to grant authorization to a specified data set.
You can only grant authorization, and run
DBMS_CLOUD_LINK.GRANT_AUTHORIZATION, as shown in this step, if you are authorized. The ADMIN grants authorization withDBMS_CLOUD_LINK_ADMIN.GRANT_AUTHORIZE.BEGIN DBMS_CLOUD_LINK.GRANT_AUTHORIZATION( database_id => '120xxxxxxx8506029999', namespace => 'TRUSTED_COMPARTMENT', name => 'SALES'); END; /Perform these steps multiple times if you want to authorize additional databases.
You can update the value of the auth_required parameter after you register a data set. See Update Data Set Registration Attributes for more information.
If you want to revoke authorization for a database:
BEGIN
DBMS_CLOUD_LINK.REVOKE_AUTHORIZATION(
database_id => '120xxxxxxx8506029999',
namespace => 'TRUSTED_COMPARTMENT',
name => 'SALES');
END;
/See the following for more information:
Register a Data Set with Offload Targets for Data Set Access
Optionally, when you register a data set you can offload access to the data set to one or more Autonomous AI Database instances that are refreshable clones.
Use the optional offload_targets parameter with DBMS_CLOUD_LINK.REGISTER to specify that access is offloaded to refreshable clones. The source database for each refreshable clone is the Autonomous AI Database instance where you register the data set (data publisher).
The offload_targets value is a JSON document that defines one or more CLOUD_LINK_DATABASE_ID and OFFLOAD_TARGET key value pairs:
-
CLOUD_LINK_DATABASE_IDis one of:-
A database ID: This specifies a database ID for the data set consumer whose request is offloaded to the corresponding refreshable clone specified with the
OFFLOAD_TARGETvalue.Obtain the database ID by running
DBMS_CLOUD_LINK.GET_DATABASE_ID. See GET_DATABASE_ID Function for more information. -
ANY: This specifies that any data set consumer's request is offloaded to the corresponding offload target. A consumer's data set request will be routed to the corresponding offload target.If you specify
ANYwithout specifying database IDs, all data set requests from consumers are offloaded to the refreshable clone specified with theOFFLOAD_TARGETvalue.If you specify both database IDs and
ANY, data set requests from consumers that do not match a database ID are offloaded to the refreshable clone specified with theOFFLOAD_TARGETvalue.
-
-
OFFLOAD_TARGETis the OCID for an Autonomous AI Database instance that is a refreshable clone.
The following figure illustrates using offload targets.
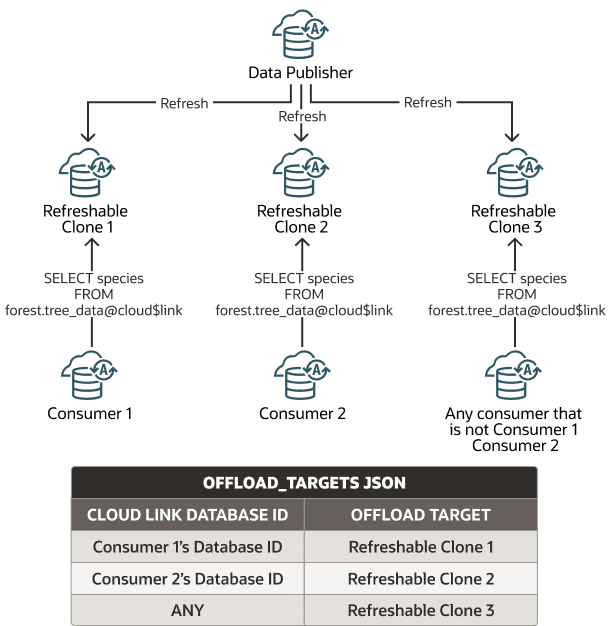
Description of the illustration cloud-links-offload-targets-any-keyword.png
When a data set consumer requests access to a data set that you register with offload_targets and the Autonomous AI Database instance’s database ID matches the value specified in CLOUD_LINK_DATABASE_ID, access is offloaded to the refreshable clone identified with OFFLOAD_TARGET in the supplied JSON.
For example, the following shows a JSON sample with three OFFLOAD_TARGET/CLOUD_LINK_DATABASE_ID value pairs:
{
"OFFLOAD_TARGETS": [
{
"CLOUD_LINK_DATABASE_ID": "34xxxxx69708978",
"OFFLOAD_TARGET":
"ocid1.autonomousdatabase.oc1..xxxxx3pv6wkcr4jqae5f44n2b2m2yt2j6rx32uzr4h25vqstifsfabc"
},
{
"CLOUD_LINK_DATABASE_ID": "34xxxxx89898978",
"OFFLOAD_TARGET":
"ocid1.autonomousdatabase.oc1..xxxxx3pv6wkcr4jqae5f44n2b2m2yt2j6rx32uzr4h25vqstifsfdef"
},
{
"CLOUD_LINK_DATABASE_ID": "34xxxxx4755680",
"OFFLOAD_TARGET":
"ocid1.autonomousdatabase.oc1..xxxxx3pv6wkcr4jqae5f44n2b2m2yt2j6rx32uzr4h25vqstifsfghi"
}
]
}When a data set consumer requests access to a data set that you register with offload_targets that includes the ANY keyword, access is offloaded to the refreshable clone identified with OFFLOAD_TARGET in the supplied JSON (except for requests from consumers that have a matching database ID entry in the supplied JSON).
For example, the following shows a JSON sample with one explicit OFFLOAD_TARGET/CLOUD_LINK_DATABASE_ID value pair, and one ANY value with a correspondingOFFLOAD_TARGET:
{
"OFFLOAD_TARGETS": [
{
"CLOUD_LINK_DATABASE_ID": "ANY",
"OFFLOAD_TARGET":
"ocid1.autonomousdatabase.oc1..xxxxx3pv6wkcr4jqae5f44n2b2m2yt2j6rx32uzr4h25vqstifsfdef"
},
{
"CLOUD_LINK_DATABASE_ID": "34xxxxx4755680",
"OFFLOAD_TARGET":
"ocid1.autonomousdatabase.oc1..xxxxx3pv6wkcr4jqae5f44n2b2m2yt2j6rx32uzr4h25vqstifsfghi"
}
]
}To register a data set and specify offload targets, do the following:
-
Obtain the OCID for one or more refreshable clones where you want to offload data set access. Refreshable clone OCIDs are available on the Oracle Cloud Infrastructure Console on a refreshable clone.
Note: It can take up to 10 minutes after you create a refreshable clone for the refreshable clone to be visible as an offload target. This means you may need to wait up to 10 minutes after you create a refreshable clone for the refreshable clone to be available for Cloud Links offload registration.
-
Obtain the database ID for one or more Autonomous AI Database instances that you want to access the data set using data provided by the refreshable clone.
On the system you want to access the data set from a refreshable clone, run the command:
SELECT DBMS_CLOUD_LINK.GET_DATABASE_ID FROM DUAL: -
Register a data set and specify the
offload_targetsparameter.For example, assuming there is a schema
CLOUDLINKon your Autonomous AI Database instance, you can registerSALES_VIEW_AGGand specify the refreshable clones that provide access to the data set:BEGIN DBMS_CLOUD_LINK.REGISTER( schema_name => 'CLOUDLINK', schema_object => 'SALES_VIEW_AGG', namespace => 'REGIONAL_SALES', name => 'SALES_AGG', description => 'Aggregated regional sales information.', scope => 'MY$TENANCY', auth_required => FALSE, data_set_owner => 'amit@example.com', offload_targets => '{ "OFFLOAD_TARGETS": [ { "CLOUD_LINK_DATABASE_ID": "34xxxx754755680", "OFFLOAD_TARGET": "ocid1.autonomousdatabase.oc1..xxxxxaaba3pv6wkcr4jqae5f44n2b2m2yt2j6rx32uzr4h25vqstifsfghi" } ] }'); END; /The parameters are:
-
schema_name: is the schema name (the object owner). -
schema_object: is the object's name. Valid objects are:-
Tables (including Heap, External or Hybrid)
-
Views
-
Materialized Views
Note: Other objects such as analytic views or synonyms are not supported.
-
-
namespace: is the namespace you provide as a name for access with Cloud Links (one part of the Cloud Link FQN).A
NULLvalue specifies a system-generatednamespacevalue, unique to the Autonomous AI Database instance. -
name: is the name you provide for access with Cloud Links (one part of the Cloud Link FQN). -
scope: Specifies the scope. You can use one of the variables:MY$REGION,MY$TENANCY, orMY$COMPARTMENTorMY$POOLor specify one or more OCIDs.See Data Set Scope, Access Control, and Authorization for more information.
-
auth_required: A Boolean value that specifies if database level authorization is required for the data set, in addition to the scope access control. When this is set toTRUE, the data set enforces an additional authorization step. See Register a Data Set with Authorization Required for more information. -
data_set_owner: Text value specifies information about the individual responsible for the data set or a contact for questions about the data set. For example, you could supply an email address for the data set owner. -
offload_targets: Specifies one or more Autonomous AI Database OCIDs of refreshable clones where access to data sets is offloaded, from the Autonomous AI Database where the data set is registered.For each data set consumer, one of the following can match to offload the request to a refreshable clone:
-
When there is matching the value of the specified
cloud_link_database_id, that is the values matches the consumer's database ID, access is offloaded to the refreshable clone identified by the OCID specified inoffload_target. -
When the
ANYkeyword is specified, if there is not a matching the value of a specifiedcloud_link_database_id, access is offloaded to the refreshable clone identified with the ANY entry by the OCID specified in the correspondingoffload_target.
-
Note: If your data publisher is either an elastic pool leader or an elastic pool member, as an alternative to configuring the offload target details with
offload_targets, you can use the unified query offload feature. In this case, the publisher enables ProxySQL query offload to offload queries (reads) to any number of refreshable clones without the need to configure the targets. See Use Unified Query Offload with Cloud Links for more information.See the following for more information:
-
Update Data Set Registration Attributes
After you register a data set you can update some data set attributes. You cannot update the schema name, schema object, namespace, or name attributes.
To update data set attributes:
-
The user who registered a data set can update its attributes with
DBMS_CLOUD_LINK.UPDATE_REGISTRATION.If you do not have privileges to update data set attributes, you need to obtain grant register privileges from the ADMIN user.
See Grant Cloud Links Access for Database Users for more information.
-
Update one or more attributes for a data set.
For example, use
DBMS_CLOUD_LINK.UPDATE_REGISTRATIONto update thedescription,scope, andauth_requiredattributes for the data set in the namespaceREGIONAL_SALESwith the nameSALES_AGG:BEGIN DBMS_CLOUD_LINK.UPDATE_REGISTRATION( namespace => 'REGIONAL_SALES', name => 'SALES_AGG', description => 'Updated description for aggregated regional sales information.', scope => 'MY$COMPARTMENT', auth_required => TRUE ); END; /The required parameters are:
-
namespace: is the data set's namespace you provided when you registered the data set. -
name: is the data set's name you provided when you registered the data set.
Following is a list of the optional parameters. If
NULLis passed in for an optional parameter value, the attribute is not modified.-
description: Specifies the updated text to describe the data. -
scope: Specifies the scope. You can use one of the variables:MY$REGION,MY$TENANCY, orMY$COMPARTMENTorMY$POOLor specify one or more OCIDs.See Data Set Scope, Access Control, and Authorization for more information.
-
auth_required: A Boolean value that specifies if database level authorization is required for the data set, in addition to the scope access control. When this is set toTRUE, the data set enforces an additional authorization step. See Register a Data Set with Authorization Required for more information. -
data_set_owner: Text value specifies information about the individual responsible for the data set or a contact for questions about the data set. For example, you could supply an email address for the data set owner. -
offload_targets: Specifies one or more Autonomous AI Database OCIDs of refreshable clones where access to data sets is offloaded, from the Autonomous AI Database where the data set is registered. See Register a Data Set with Offload Targets for Data Set Access for more information.
You cannot update the
schema_nameorschema_objectattributes.See UPDATE_REGISTRATION Procedure for more information.
-
When a data set is registered in one or more cross region Refreshable Clones, any changes to the registration in the source database should be propagated to the remote regions.
Note the following to propagate changes to cross region Refreshable Clones:
-
If a Producer has N cross region Refreshable Clones in a region, for example in region A, run
DBMS_CLOUD_LINK.UPDATE_REGISTRATIONon exactly one Refreshable Clone in region A. -
If the same Producer has M cross region Refreshable Clones in a different remote region, for example in region B, run
DBMS_CLOUD_LINK.UPDATE_REGISTRATIONon exactly one Refreshable Clone in region B.
To update attributes when a data set is registered in one or more cross region Refreshable Clones:
-
On the source database, update the data set registration.
-
On a remote Refreshable Clone in the remote region if the there is only one remote region, or on a remote Refreshable Clone in each remote region if there are replicated Refreshable Clones in multiple regions, update the data set registration with the same values you used to update the source database, with the exception of the
offload_targetsparameter.In any given remote region, you only need to run
DBMS_CLOUD_LINK.UPDATE_REGISTRATIONon exactly one Refreshable Clone in that region (if the region has more than one Refreshable Clone associated with the same data set, you only need to run the procedure once to propagate the changes to all of the Refreshable Clones in an individual remote region). -
Refresh the refreshable clones.
See Refresh a Refreshable Clone on Autonomous AI Database for more information.
Find Data Sets and Use Cloud Links
A user who is granted access to read Cloud Links can search for data sets available to an Autonomous AI Database instance and can access and use registered data sets with their queries.
After the ADMIN user runs GRANT_READ, a user can search for and use Cloud Links.
-
Find the available data sets on your Autonomous AI Database instance.
For example, search for all data sets that contain the string, “TREE”:
DECLARE result CLOB DEFAULT NULL; BEGIN DBMS_CLOUD_LINK.FIND('TREE', result); DBMS_OUTPUT.PUT_LINE(result); END; / [{"name":"TREE_DATA","namespace":"FOREST","description":"Urban tree data including county, species and height"}]The parameters are:
-
search_string: The string to search for. The search string is not case sensitive. -
search_result: A JSON document that includes the namespace, name, and description values for the data set.
See FIND Procedure for more information.
The
DBMS_CLOUD_LINK.FINDprocedure provides the FQN you can use with Cloud Links. In this case,FOREST.TREE_DATA. -
-
Use the view
DBA_CLOUD_LINK_ACCESSto list available data sets:SELECT * FROM DBA_CLOUD_LINK_ACCESS;NAMESPACE NAME --------- -------------- FOREST TREE_DATA REGIONAL_SALES SALES_AGG TRUSTED_COMPARTMENT SALES -
Use the procedure
DBMS_CLOUD_LINK.DESCRIBEto find out more details about a registered data set.SELECT DBMS_CLOUD_LINK.DESCRIBE('FOREST','TREE_DATA') FROM DUAL;DBMS_CLOUD_LINK.DESCRIBE('FOREST','TREE_DATA') --------------------------------------------------- Urban tree data including county, species and height -
Use the registered data set in a query.
SELECT * FROM FOREST.TREE_DATA@cloud$link;
Note: It can take up to 10 minutes after you register a data set with DBMS_CLOUD_LINK.REGISTER for the data set to be visible and accessible.
Cloud Links support private and public synonyms. For example, you can define and use a synonym for FOREST.TREE_DATA@cloud$link:
CREATE SYNONYM S1 for FOREST.TREE_DATA@cloud$link;
CREATE PUBLIC SYNONYM S2 for FOREST.TREE_DATA@cloud$link;
SELECT * FROM S1;
SELECT * FROM S2;See CREATE SYNONYM for more information.
Use Cloud Links Consumer Options
You can set the service name mapping to use to access data from a consumer database and you can enable caching on a data set consumer for the results of a query or for a query fragment that accesses Cloud Link data.
Set Database Service Name Mapping for Cloud Links Consumers
You can set the service name mapping to use when Cloud Links consumers access data from a data set owner.
Cloud Links rely on database resources in the Autonomous AI Database instance that is the data set producer, or the resources of a refreshable clone, to access shared data. By default remote connectivity for consumers to access Cloud Links data uses the MEDIUM database service.
Use DBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPING to set the database service mapping for a consumer. In this procedure you supply either a database ID or the keyword ANY to specify the consumer service mapping. For example, the following figure shows a mapping for Consumer A to the HIGH service, Consumer B to the MEDIUM service, Consumer C to the LOW service, and a mapping for ANY to the TP service, meaning all other consumers access Cloud Links using the TP service.
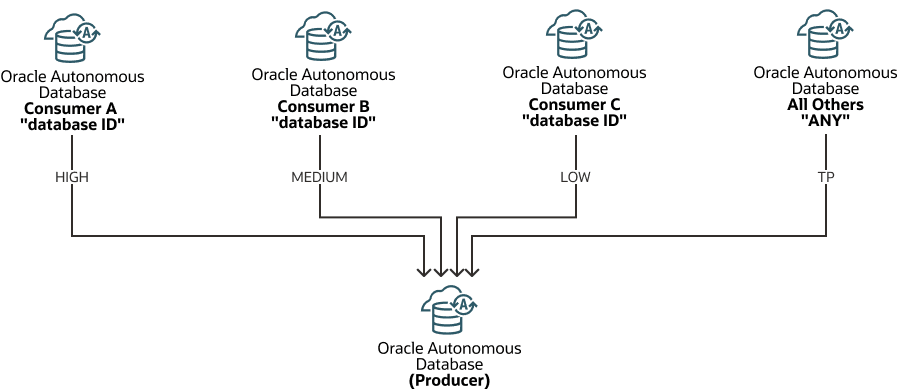
Description of the illustration autonomous-cloud-links-service-mapping.png
See Database Service Names for Autonomous AI Database for more information on the characteristics of database services.
Perform the following steps to set the database service to use for a Cloud Links consumer:
-
Obtain the database ID for the database that you want to set a service mapping.
On the consumer database run
GET_DATABASE_IDto obtain the consumer's database ID. For example:SELECT DBMS_CLOUD_LINK.GET_DATABASE_ID FROM DUAL:See GET_DATABASE_ID Function for more information.
-
On the data set owner's Autonomous AI Database instance, specify a service mapping.
Perform this step on the data set owner's Autonomous AI Database instance (that is, on the producer database).
BEGIN DBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPING( database_id => '*database_id*', service_name => 'HIGH'); END; /Where the
database_idparameter value is the database ID you obtained in step 1.Specify the value
ANYfor thedatabase_idto use the specifiedservice_namewith all consumer databases that do not have aservice_nameassociated with theirdatabase_id. That is, anydatabase_idwhoseservice_namehas not been set withDBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPING.See ADD_SERVICE_MAPPING Procedure for more information.
Only the ADMIN user and schemas with
PDB_DBArole can runDBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPING. -
Verify the database IDs and service mapping by listing the Cloud Links service mappings.
For example:
SELECT * FROM DBA_CLOUD_LINK_SERVICE_MAPPINGS;See DBA_CLOUD_LINK_SERVICE_MAPPINGS View for more information.
Notes for setting and changing service mappings:
-
Service mappings take effect at the time connections are established. If a particular consumer's service mappings are changed, the new mappings take effect only for new sessions from the consumer.
-
Any service mapping configured in a data set owner for a specific Consumer is honored even if access from the Consumer is offloaded to a Refreshable Clone. The Refreshable Clone must be refreshed to a point in time after the time when service mappings were configured in the data set owner. Note that offload to a Refreshable Clone is configured with the argument
offload_targetsduring data set registration.See Register a Data Set with Offload Targets for Data Set Access for more information.
-
Use the procedure
DBMS_CLOUD_LINK_ADMIN.REMOVE_SERVICE_MAPPINGto remove a service mapping for a specifieddatabase_id.After running
DBMS_CLOUD_LINK_ADMIN.REMOVE_SERVICE_MAPPINGa consumer either uses the defaultMEDIUMdatabase service or theservice_nameyou specify if you runDBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPINGwith thedatabase_idvalueANY. See REMOVE_SERVICE_MAPPING Procedure for more information. -
Set Database Service Name Mapping for Cloud Links Consumers in Remote Region
A data set that is registered in a source region can be accessed with Cloud Links from a remote region when you create cross region Refreshable Clone in the remote region.
Set Database Service Name Mapping for Cloud Links Consumers in Remote Region
A data set that is registered in a source region can be accessed with Cloud Links from a remote region when you create cross region Refreshable Clone in the remote region.
In this case, the service mappings for consumers in the remote region must be added twice, in the source database, and in the refreshable clone in the remote region.
Perform the following steps to set the service mappings for Cloud Links consumers in a remote region.
-
Create a cross region Refreshable Clone of the source database (the Refreshable Clone is a clone of the Cloud Links data set owner in the remote region).
See Create a Cross Tenancy or Cross Region Refreshable Clone for more information.
-
Register the data set.
See Register a Data Set for more information.
-
Add the service mappings on the data set owner.
See Set Database Service Name Mapping for Cloud Links Consumers for more information.
-
Refresh the Refreshable Clone.
See Refresh a Refreshable Clone on Autonomous AI Database for more information.
-
On the remote Refreshable Clone, register the data set using the same arguments you used to register the data set in the source region (that is, use the same arguments you used in Step 2).
-
On the remote Refreshable Clone, add the service mappings using the same arguments that you used in the source region (that is, use the same arguments you used in Step 3).
When a consumer in the remote region access Cloud Links data, the access will use the same service mappings as you added in source region’s data set owner database.
Enable Caching for a Cloud Link Consumer
You can enable caching on a data set consumer for the results of a query or for a query fragment that accesses Cloud Link data.
To enable caching on a data set consumer use the RESULT_CACHE hint with the SHELFLIFE option. With the SHELFLIFE option you supply a value that indicates the duration, in seconds, that a query result is cached. After the SHELFLIFE interval has passed, the cached result is marked as invalid. As long as the cached result is valid, a query retrieves the cached data from the cache on the consumer database, which avoids a round trip to the data set owner’s database.
Use the RESULT_CACHE hint with the SHELFLIFE option when the data set is static or when the consumer can tolerate stale results. The value of SHELFLIFE allows the Cloud Link data set consumer to control the time, in seconds, when the data in the cache is valid (the acceptable degree of staleness).
If the query result is large and does not fit in memory, you can use the RESULT_CACHE hint with the SHELFLIFE option and the TEMP option to indicate that the result should be written to disk in the temporary tablespace.
To cache Cloud Link data with the RESULT_CACHE hint:
-
In a query, specify the
RESULT_CACHEhint with theSHELFLIFEoption.For example:
SELECT /*+ RESULT_CACHE (SHELFLIFE=120) */ * FROM FOREST.TREE_DATA@cloud$link;This
RESULT_CACHEspecifies aSHELFLIFEvalue of 120. This indicates that the result should be cached in memory for 120 seconds. After 120 seconds, the cached result is marked as invalid.The
SHELFLIFEvalue must be a positive integer. The maximumSHELFLIFEvalue is 4294967295. -
If the query result is large and does not fit in memory, use both the
SHELFLIFEand theTEMPoptions to indicate that the result should be written to disk in the temporary tablespace.SELECT /*+ RESULT_CACHE (TEMP=true SHELFLIFE=360) */ * FROM FOREST.TREE_DATA@cloud$link;
See RESULT_CACHE_MODE for details on using the result cache with Autonomous AI Database.
See RESULT_CACHE Hint for more information on RESULT_CACHE with SHELFLIFE.
See DBMS_RESULT_CACHE for information on procedures to manage the result cache and to invalidate objects in the result cache.
Monitor and View Cloud Links Information
Autonomous AI Database provides views that allow you to monitor and audit Cloud Links.
| View | Description |
|---|---|
| V$CLOUD_LINK_ACCESS_STATS and GV$CLOUD_LINK_ACCESS_STATS Views | Use to track access to each registered data set on the Autonomous AI Database instance. These views track elapsed time, CPU time, the number of rows retrieved, and additional information about registered data sets. You can use the information in these views to audit Cloud Links data set access and usage. |
| DBA_CLOUD_LINK_REGISTRATIONS and ALL_CLOUD_LINK_REGISTRATIONS Views | Use to list details of the registered data sets on an Autonomous AI Database instance. |
| DBA_CLOUD_LINK_ACCESS and ALL_CLOUD_LINK_ACCESS Views | Use to retrieve details of registered data sets a database is allowed to access. |
| DBA_CLOUD_LINK_AUTHORIZATIONS View | Provides information about which databases are authorized to access which data sets. This applies to data sets where the auth_required parameter is TRUE. |
| DBA_CLOUD_LINK_PRIVS and USER_CLOUD_LINK_PRIVS Views | Provides information on the Cloud Link specific privileges, REGISTER, READ, or AUTHORIZE, granted to all users or to the current user. |
| DBA_CLOUD_LINK_SERVICE_MAPPINGS View | Displays details of all service mappings for Cloud Links consumer databases. Each service mapping consists of a Cloud Link database ID and a database service. |
Define a Virtual Private Database Policy to Secure a Registered Data Set
By defining Virtual Private Database (VPD) policies for a registered data set, you can provide fine-grained Cloud Link access control so that only a subset of data (rows) is visible for specific remote sites.
Oracle Virtual Private Database (VPD) is a security feature that lets you control data access dynamically at row level for users and applications by applying filters on the same data set.
Any user who is granted access to read Cloud Links can access and use registered data sets if they are within the scope specified when the data set is registered, and if the extra authorization required parameter is set for the data set, the access is from an authorized database. Each remote access is done in the context of the remote Autonomous AI Database instance accessing the registered data set (on the database where the data set was registered).
You use the function DBMS_CLOUD_LINK.GET_DATABASE_ID on the remote system to get the database’s unique ID. By defining a VPD policy on the database that registered a data set, you now can use the remote database’s identifier as SYS_CONTEXT rule to provide more fine-grained control. You can define rules for remote databases accessing your registered data set and limit access beyond what is possible by specifying a Cloud Link scope.
Consider an example where REGIONAL_SALES.SALES_AGG is made available at the tenancy level. If you want to restrict access to all databases except one specific database, only allowing full access to the specified database, you can add a VPD policy on the registered data set.
For example:
-
Obtain the unique Cloud Link database ID for the Autonomous AI Database instance where you want to provide full access.
DECLARE DB_ID NUMBER; BEGIN DB_ID := DBMS_CLOUD_LINK.GET_DATABASE_ID; DBMS_OUTPUT.PUT_LINE('Database ID:' || DB_ID); END; / -
Create VPD policy on the database that registered the data set by only allowing full access to the one specific database whose identifier you got on the database in question in Step 1.
CREATE OR REPLACE FUNCTION vpd_policy_sales( owner IN VARCHAR2, object IN VARCHAR2) RETURN VARCHAR2 IS BEGIN IF SYS_CONTEXT('USERENV', 'CLOUD_LINK_DATABASE_ID') <> '12121212163948244901' THEN RETURN 'time_id >= trunc(sysdate,''year'')'; ELSE RETURN ''; END IF; END; /See DBMS_RLS for more information.
-
Register the VPD policy for your registered data set to limit full access to only the database identified in step 1.
BEGIN DBMS_RLS.ADD_POLICY(object_schema => 'CLOUDLINK', object_name => 'SALES_VIEW_AGG', policy_name => 'THIS_YEAR', function_schema => 'ADMIN', policy_function => 'VPD_POLICY_SALES', statement_types => 'SELECT', policy_type => DBMS_RLS.SHARED_CONTEXT_SENSITIVE); END; /See DBMS_RLS for more information.
See Using Oracle Virtual Private Database to Control Data Access for more information.
Use Cloud Links from a Read Only Autonomous AI Database Instance
You can share Cloud Links when a data set resides on a Read-Only Autonomous AI Database instance.
To share Cloud Links from an Autonomous AI Database instance that is in Read-Only mode:
-
Change the database mode to Read/Write mode.
See Change Autonomous AI Database Operation Mode to Read/Write Read-Only or Restricted for more information.
-
With the database in Read/Write mode, perform the steps to register a data set.
-
After you register one or more data sets, change the database to read-only mode.
See Change Autonomous AI Database Operation Mode to Read/Write Read-Only or Restricted for more information.
Notes for Cloud Links
Provides notes and restrictions for using Cloud Links.
-
There is a limit of 4096 on the number of data sets you can register.
Each Autonomous AI Database instance can register no more than 4096 data sets. This limit applies to every Autonomous AI Database instance, regardless of the number of ECPUs (OCPUs if your database uses OCPUs) or the storage size of the instance. The limit is a fixed value and setting the ECPU count to a larger value does not allow you to register more data sets.
-
You can register an object in another schema if you have
READ WITH GRANT OPTIONprivilege on the object. -
To register data sets or see and access remote data sets, you have to have granted the appropriate privilege for either registering or reading data sets. This is true for ADMIN as well; however ADMIN can grant this privilege to themselves.
-
To use either
DBMS_CLOUD_LINK.REGISTERorDBMS_CLOUD_LINK.UPDATE_REGISTRATION, you must have execute privilege on theDBMS_CLOUD_LINKpackage, in addition to the register privilege assigned withDBMS_CLOUD_LINK_ADMIN.GRANT_REGISTER. Only the ADMIN user and schemas withPDB_DBAhave this privilege by default. -
If you drop and re-create a table that was registered, you need to re-register the table for remote access.
-
Only the ADMIN user and users with the role
PDB_DBAare privileged to access the following views:-
DBA_CLOUD_LINK_ACCESS -
DBA_CLOUD_LINK_REGISTRATIONS -
DBA_CLOUD_LINK_AUTHORIZATIONS -
DBA_CLOUD_LINK_PRIVS
See DBMS_CLOUD_LINK Views for more information.
-
-
Accessing registered, remote data requires the remote database to be open. If the remote database is closed or in restricted mode, you will not be able to access the data and an Oracle error will be returned.
-
There is a limit of a maximum of four open database links per session. Exceeding this limit can lead to
ORA-02020orORA-12545. -
If result cache is enabled, like the default behavior in Autonomous AI Database with Lakehouse workload, you need to ensure that result cache is not used when realtime data is required.
-
When you update your license type from Free to Paid, you must re-register Cloud Links data sets. See Update Always Free Instance to Paid with Autonomous AI Database for more information.
-
Cloud Links remote connectivity by default uses the
MEDIUMdatabase service. You can change the default withDBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPINGby usingANYas the value forDATABASE_ID. You can change the database service for a consumer withDBMS_CLOUD_LINK_ADMIN.ADD_SERVICE_MAPPINGby specifying the consumer'sDATABASE_ID. See Set Database Service Name Mapping for Cloud Links Consumers for more information.You can see the remote connections as user
C##DATA$SHAREinV$SESSIONand the Cloud Links viewsV$CLOUD_LINK_ACCESS_STATS and GV$CLOUD_LINK_ACCESS_STATS Views provide more details about remote connections. -
All interfaces are case-sensitive unless otherwise noted, as follows:
-
Anything you enter that exists in the database, for example user names and table names, case is significant and must be entered with uppercase letters.
-
Predefined variables, for example the predefined scope values must be entered in uppercase letters.
-
Anything that you specify for the setup of Cloud Links, for example namespaces or names of tables in a namespace, must be specified as entered. For example, if you define a namespace as
trees, you must enclose the namespace in double quotes, as"trees", when accessing it with SQL.
-
-
You can share Cloud Links when a data set resides on an Autonomous AI Database instance in Read-Only mode. See Use Cloud Links from a Read Only Autonomous AI Database Instance for more information.
-
It can take up to 10 minutes after you create a refreshable clone for the refreshable clone to be visible as an offload target. This means you may need to wait up to 10 minutes after you create a refreshable clone for the refreshable clone to be available for Cloud Links offload registration.
See Register a Data Set with Offload Targets for Data Set Access and Create a Refreshable Clone for an Autonomous AI Database Instance for more information.
-
Use Cloud Links from a Read Only Autonomous AI Database Instance
You can share Cloud Links when a data set resides on a Read-Only Autonomous AI Database instance.