Use Lakehouse with Autonomous AI Database
Learn the benefits of using Lakehouse with Autonomous AI Database.
About Lakehouse with Autonomous AI Database
Oracle Autonomous AI Database is a versatile solution for accommodating any type of data and workload.
Autonomous AI Database provides cost-efficient storage, with a cost per TB comparable to object stores, while supporting diverse data types like JSON, Graph, and Vector. With Autonomous AI Database, businesses can consolidate their data onto a single platform. They can leverage converged capabilities such as Oracle Machine Learning (OML), Graph, Spatial, Vector, and Blockchain to manage their data comprehensively.
For organizations that already have existing Lakehouses on other platforms, Oracle Autonomous AI Database integrates seamlessly, allowing businesses to benefit from Autonomous AI Database’s advanced features without disrupting their current setups.
To learn more, try the LiveLabs Title Build a Lakehouse with Autonomous AI Lakehouse.
What is a Lakehouse?
Lakehouses are centralized repositories designed to store vast amounts of raw data in their native format until the data is needed for analysis.
They are highly flexible and scalable, making them a powerful complement to traditional Lakehouses by enabling organizations to store and process various types of data, including structured, semi-structured, and unstructured.
Key attributes of a Lakehouse:
-
Open File and Table Formats
Lakehouses store data in open file formats, such as CSV, Parquet, and table formats like Iceberg. This ensures interoperability and flexibility in data processing by allowing multiple engines to write and read these datasets.
-
Support for Multiple Data Processing Engines
Lakehouses are compatible with various data processing engines, such as Apache Spark, Presto, and Hive, enabling diverse analytical workloads.
-
Schema-on-Read
Lakehouses often use a schema-on-read approach, meaning there is no need to define a schema upfront. This allows for rapid data ingestion, where data can be loaded without prior structuring, much like object stores that “capture data now, and ask questions later”.
-
Support for Unstructured Data
Beyond structured data, Lakehouses can store unstructured data such as images (JPG), documents (PDF, Word), and other binary data, offering a comprehensive storage solution.
Key Lakehouse Features of Autonomous AI Database
Oracle Autonomous AI Database is designed to seamlessly support Lakehouse workloads, eliminating the need for management or installation. It delivers robust capabilities to handle various data formats across different cloud environments, ensuring flexible and comprehensive data analysis.
Ready for Lakehouse Workloads
Oracle Autonomous AI Database is fully ready for Lakehouse workloads out-of-the-box, requiring no additional components. This readiness extends to key Lakehouse tasks such as data transformation, metadata management, and integration with popular Lakehouse tools-all available from day one without extra setup.
This comprehensive readiness is what makes Autonomous AI Database stand out, offering an integrated, hassle-free experience that accelerates time-to-insight for Lakehouse workloads. This means users can immediately start handling Lakehouse tasks without any setup or configuration, making it a true plug-and-play solution for Lakehouse environments. This built-in capability simplifies operations, reduces maintenance costs, and ensures higher reliability with fewer errors.
Autonomous AI Database provides a set of tools for all user types, from developers to business analysts, making the platform universal and accessible.
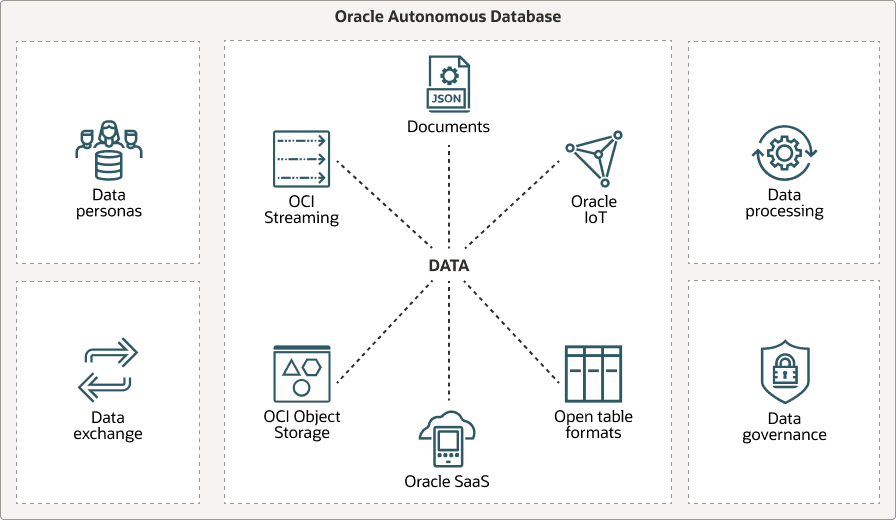
Description of the illustration data-lake-workloads.png
Developers can use tools such as the PL/SQL API for advanced operations, scripting, and automation, allowing seamless integration with existing tools and creating customized database solutions efficiently. See Autonomous AI Database Supplied Package Reference, for more information.
For business users, Data Studio can be used-a web-based interface for simplifying data interaction, exploration, and visualization. Data Studio enables non-technical users to derive insights, create reports, and collaborate effectively, reducing complexity and supporting informed decision-making. See The Data Studio Overview Page, for more information.
Multi-Cloud Support
For organizations that already have existing Lakehouses on other platforms, Autonomous AI Database integrates seamlessly, allowing businesses to benefit from Autonomous AI Database advanced features without disrupting their current setups.
Provide Autonomous AI Database access to your Lakehouse by granting the necessary privileges and access for your Lakehouse to be connected to Autonomous AI Database. Once you’ve provided the necessary credentials, Autonomous AI Database can seamlessly connect to Lakehouses across various cloud environments, including AWS, Azure, Google Cloud, and Oracle OCI object store.
This capability allows you to securely access and manage your data, leveraging the native security features of each cloud provider. With this multi-cloud support, you gain the flexibility to deploy and scale your Lakehouse across different cloud platforms while maintaining a unified and secure environment.
Oracle Autonomous AI Database supports native security for other clouds, to learn more, see Use Amazon Resource Names (ARNs) to Access AWS Resources, Use Azure Service Principal to Access Azure Resources and Use Google Service Account to Access Google Cloud Platform Resources for your corresponding cloud platform.
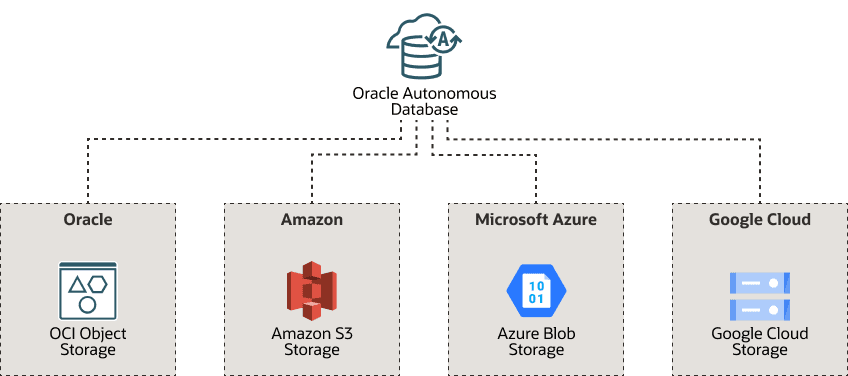
Description of the illustration data-lake-multicloud.png
End-To-End Data Format Support
Oracle Autonomous AI Database is designed with the flexibility to handle a broad spectrum of data formats, making it a universal solution for diverse data sources and workloads.
Whether your data resides in structured, semi-structured, or unstructured formats, Autonomous AI Database seamlessly supports them across various cloud environments. This allows businesses to ingest, store, and analyze data without worrying about format compatibility.
Autonomous AI Database provides native support for traditional formats like CSV and JSON, as well as advanced formats such as AVRO, Parquet, and ORC. See Query External Data with Autonomous AI Database, for more information. Autonomous AI Database supports the following file formats: CSV, JSON, XML, AVRO, ORC, Parquet, Delta Sharing, Iceberg, Word, PDF.
With the added support for the Iceberg Table format, Autonomous AI Database offers enhanced capabilities for large-scale Lakehouse environments. Iceberg allows for optimized, high-performance querying, better version control, and easier data management, making it a good fit for large, evolving datasets. See Query Apache Iceberg Tables, for more information.
Enhanced Capabilities: Autonomous AI Database for Unstructured Data Management
While Oracle AI Database is recognized for its powerful processing of structured and semi-structured data, Autonomous AI Database extends its capabilities to handle unstructured datasets as well.
These capabilities include managing and analyzing a wide range of formats like JPG, PDF, Word documents, and more. With these advancements, Autonomous AI Database brings a comprehensive solution for businesses dealing with unstructured data sources.
-
AI-Driven Insights with Retrieval Augmented Generation (RAG): Autonomous AI Database integrates advanced AI models, enabling Vector Search for unstructured data. This allows for efficient retrieval of relevant information across massive datasets using AI, enhancing search accuracy and speed. See Select AI with Retrieval Augmented Generation (RAG), for more information.
-
Full-Text Indexing: Autonomous AI Database supports the creation of full-text indexes on unstructured files, making it possible to perform advanced text searches on documents such as PDFs, Word files, and more. This capability greatly improves how unstructured content can be queried, indexed, and analyzed. See Use Full-Text Search on Files in Object Storage
-
Parse and Load Unstructured Data: Autonomous AI Database enhanced parsing and data ingestion features allow users to load unstructured data seamlessly, automatically transforming it into a tabular format, ready to be load into database. See Perform Table Extraction from Image, for more information.
-
AI as a Source of Data (Prompt-to-Table): Leveraging AI, Autonomous AI Database enables prompt-to-table functionality, allowing users to generate data directly from AI models and load it into tables. This opens up possibilities for extracting valuable insights from AI-generated outputs and using them as a new source of structured data. See Loading Data from AI Source
These expanded capabilities position Autonomous AI Database as a powerful tool for handling the growing demands of unstructured data, while also tapping into AI-powered solutions, making it a versatile and future-proof platform for modern data challenges.
Flexible Metadata Management
Oracle Autonomous AI Database provides users with various ways to define metadata for their datasets, making data management more adaptable and efficient.
-
Catalog-Based Metadata Integration
Users can bring metadata from various catalogs into a centralized view, making it easier to control and maintain data consistency across the organization. Supported catalogs include:
-
OCI Data Catalog: A tool within Oracle Cloud Infrastructure (OCI) that helps users discover, organize, and manage data assets. It offers a clear view of all data assets, helping users maintain compliance, ensure data quality, and facilitate collaboration across teams. See Example: MovieStream Scenario, for more information.
-
AWS Glue: A managed ETL (extract, transform, load) service from Amazon Web Services that includes a data catalog for organizing and managing metadata. See Query External Data with AWS Glue Data Catalog, for more information.
-
-
Manual Metadata Definition
Users can also define metadata directly at the table level for datasets in object stores such as Oracle Cloud Infrastructure (OCI) Object Storage or Amazon S3. This allows for customized organization of data for individual files or groups of files, tailored to user requirements. Autonomous AI Database can also automatically infer metadata, such as column names and data types, to save time and reduce errors. For example, when uploading a CSV file, the system can automatically detect headers as column names and assign appropriate data types like number or varchar2 based on the content. This helps users quickly prepare their data for analysis without manual intervention, reducing setup time and minimizing the chance of errors.
Federated Metadata Support
Autonomous AI Database supports a federated metadata catalog, enabling users to unify metadata from different sources into a single view, providing a unified interface for metadata management.
This approach simplifies metadata management across various environments by connecting data sources across multiple clouds and platforms. Whether using catalog-based metadata or defining it manually, all information is available in a unified catalog for easy browsing. For example, an organization can use this federated view to manage data assets from both AWS and Oracle Cloud, ensuring consistent governance and discoverability across platforms.
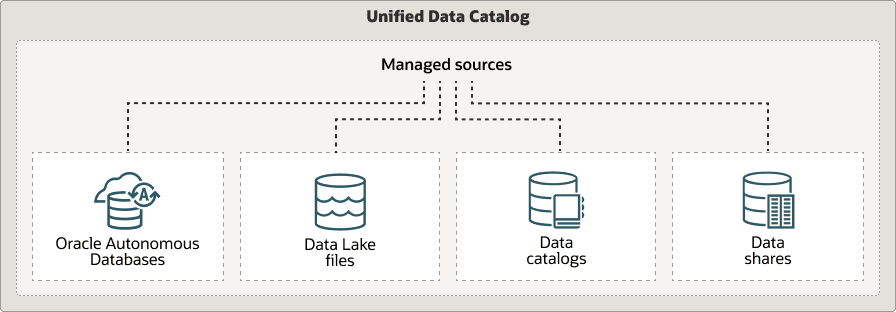
Description of the illustration data-lake-uni-dcat.png
Collaboration
After users finish their analysis, they often need to share their results with others. Oracle Autonomous AI Database makes sharing easy by offering several ways to collaborate, providing unique advantages over other databases, such as integrated security features, open protocols, and seamless cloud connectivity.
These options are made to be flexible and secure, so they fit different collaboration needs:
-
Delta Sharing Protocol: This lets you share data outside of Oracle using an open protocol called Delta Sharing. It supports secure data sharing with external partners, without needing complex integration, making it ideal for cross-cloud and cross-platform analytics. This way, data can be used smoothly in different analytics tools that are not part of Oracle. See Share Data Versions Using Object Storage, for more information.
-
Cloud Links: You can share data between different Autonomous AI Database instances using secure cloud links. For example, Cloud Links are particularly effective for connecting different databases. This ensures consistent data availability and reduces latency for applications needing quick and reliable access to data across multiple databases, without the need to copy or duplicate. It keeps collaboration smooth for teams that are spread out and need to work together. See Share Live Data Using Direct Connection
-
Table Hyperlinks: You can share data directly by creating special URLs that give access to the data without needing a separate login. Users can control the permissions and set expiration times for these URLs, ensuring secure and flexible sharing options. This feature is built specifically for REST clients. See Create a Table Hyperlink for a Table or a View, for more information.
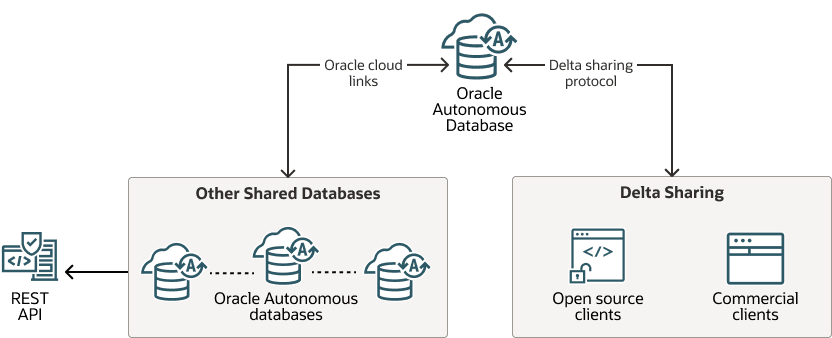
Description of the illustration data-lake-data-share.png
Broad Compatibility with Oracle AI Database Tools
The Autonomous AI Database environment is fully compatible with a wide array of Oracle database tools.
Any tool you already use to interact with Oracle databases-whether for data visualization, analytics, ETL, or administration-can also be leveraged seamlessly to analyze datasets within Autonomous AI Database . This compatibility ensures a frictionless experience, allowing users to integrate Autonomous AI Database into their existing workflows without needing to adopt new tools or processes, thereby maximizing efficiency and reducing the learning curve.
See The Data Studio Overview Page, for information on a few of the tools available to use with Oracle databases.
Performance
Autonomous AI Database includes numerous optimizations specifically designed for querying data stored in Object Store and utilizing open table formats, such as Apache Iceberg.
Data Lake Accelerator
The Data Lake Accelerator is a dynamic scale-out service that significantly enhances query performance by offloading intensive scan operations, including filtering, projection, and decompression from your Autonomous AI Database to a dedicated, pool of compute resources. This service dynamically provisions and adds ECPUs only for the duration of query execution, enabling large scans to finish faster by parallelizing data processing directly at the source, without requiring the data to be loaded into the database. Upon query completion, the allocated resources are automatically released, ensuring efficient consumption based utilization. See Data Lake Accelerator for more information.
Lake Cache
Lake Cache lets you store frequently accessed external data locally. When you use the cache, queries on external tables and on tables exposed through mounted catalogs can retrieve data directly from within the Autonomous AI Database, making them significantly faster. You can create Lake Cache for partitioned and non-partitioned external tables and for eligible mounted catalog tables, including data backed by Parquet, ORC, AVRO, CSV, and Iceberg tables. See Use Lake Cache to Improve Performance for External Tables for more information.
Implicit Partitioning
Implicit partitioning in Autonomous AI Database automatically recognizes common folder and file naming patterns in your Object Store paths, for example, '.../country=US/year=2024/month=01/'. The database treats these naming conventions as partition keys, enabling it to skip files and folders that are irrelevant to your query filters. This delivers partition pruning benefits without requiring you to manually define partitions in your table DDL or alter your existing directory structure. As a result, queries scan less data from Object Store and deliver faster results, especially when working with large datasets. See Query External Tables with Implicit Partitioning for more information.
Choosing the Right Feature
| Feature | Use Case | Data Volume |
| Lake Cache | Utilize for repeated, interactive, or scheduled dashboards. | Medium (GBs to low TBs) |
| Data Lake Accelerator | Utilize to scale out heavy or adhoc scans over extensive data. | Very Large (TBs to PBs) |
| Implicit Partitioning | Utilize to query or analyze large datasets organized by folder or file naming patterns, for example, by date, region, or other attributes, in Object Store. | Medium to Large (GBs to TBs) |
| Hybrid | Lake Cache to cache frequently accessed (hot) data subsets from external tables or mounted catalog tables, and Data Lake Accelerator to query against the full historical data. | All volumes |