Viewing deduplication rules
You can view the list of deduplication rules and the details for each rule from the Master entities page.
Viewing list of deduplication rules
To view the list of deduplication rules:
-
Click the Oracle icon
 in the bottom-right corner to open the navigation menu.
in the bottom-right corner to open the navigation menu.
- Select Master entities.
- Under Master entities, click the master entity you want to view.
- Click the Deduplication tab.
Tip: You can also view deduplication information by clicking Deduplication within the visual display of the ID resolution pipeline in the middle of the page.
Each deduplication rule displays the following information.
- Rule name: The name used to identify the deduplication rule in the application.
- Status: Indicates if the rule is currently Active or Inactive.
- Rule ID: The unique ID associated with the deduplication rule in the application.
- Attributes used: The attributes used in the deduplication rule. Click the More link to view the full list of attributes.
- Last updated: The date the rule was last updated and the name of the user that updated it.
Viewing deduplication rule details
To view details on an individual deduplication rule:
-
Click the Oracle icon in the bottom-right corner to open the navigation menu.
- Select Master entities.
- Under Master entities, click the master entity you want to view.
- Click the Deduplication tab.
- Under Rule name, click to select the deduplication you want to view.
Tip: You can also view deduplication information by clicking Deduplication within the visual display of the ID resolution pipeline in the middle of the page.
The page for the deduplication rule will display. You can review the following sections on the page.
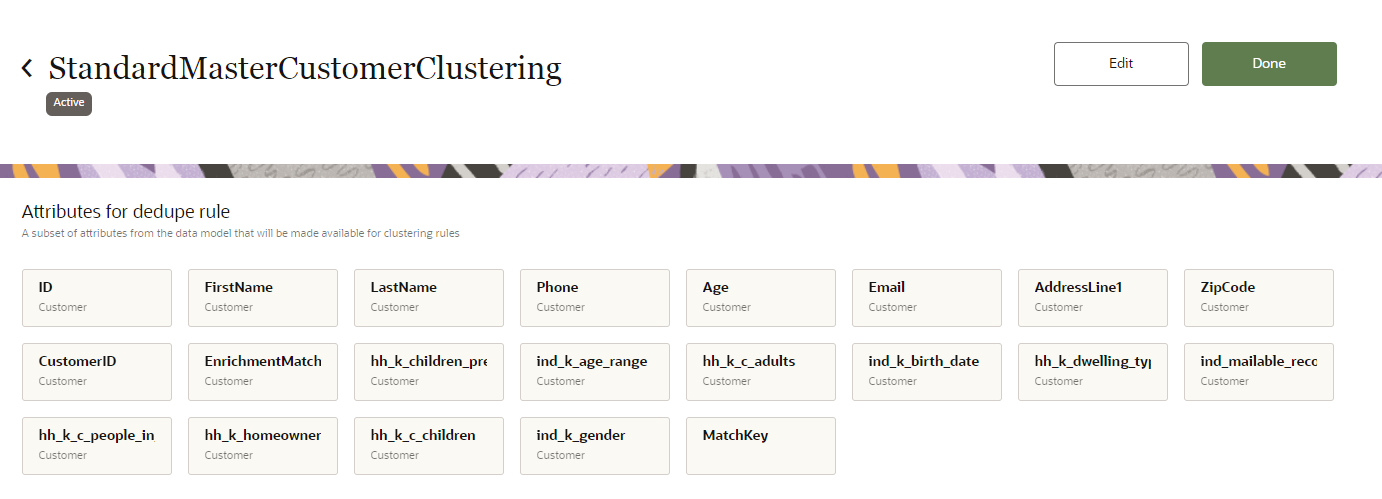
Attributes for dedupe rule
These are the attributes from the data model that will be processed for the deduplication rule.
Clustering rules
This section displays the individual clustering rules for the deduplication rule. It also indicates if each clustering rule is Active or Inactive.
Clustering rules are criteria to create smaller groups of customer records when comparing data. Rather than trying to find duplicate records by comparing every single customer record, clustering rules allow you to compare smaller sets of records more quickly and efficiently.
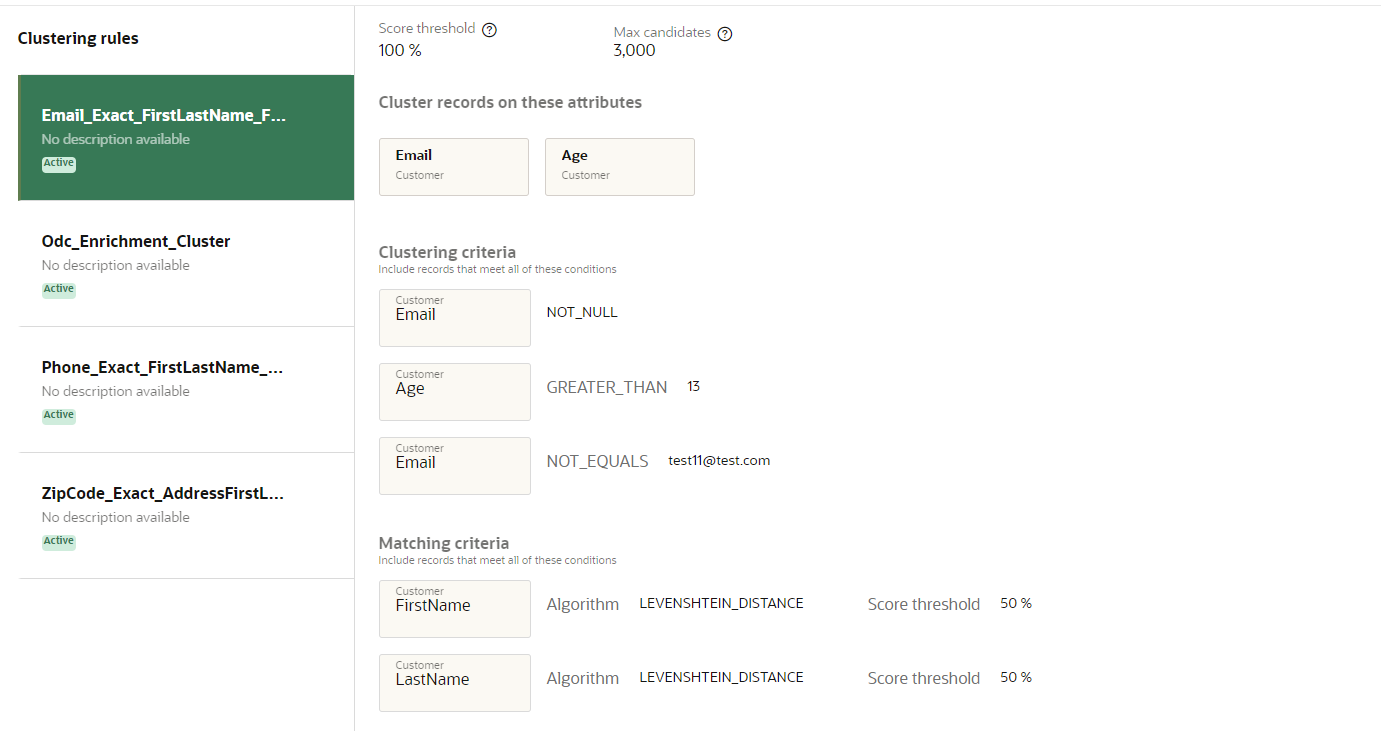
Each clustering rule has the following values:
Score threshold: Percentage that represents the possibility that two records are duplicates. For example, if the score threshold is 100%, Oracle Unity will then find two records that are an exact match.
Max candidates: Value that represents the maximum number of records that will be processed within that clustering rule.
Clustering criteria
This section displays the conditions for including records in the clustering rule.
Matching criteria
This section displays the conditions for matching duplicate records to individual customers. A score threshold will be used for each attribute along with one of two algorithms to calculate the possibility of records matching: Jaro-Winkler and Levenshtein.
Learn about the default data model