Contents
System administrators can configure High Availability (HA) in an API Gateway environment to ensure that there is no single of point of failure in the system. This helps to eliminate any potential system downtime in production environments. Typically, the API Gateway platform is deployed in the Demilitarized Zone (DMZ) to provide an additional layer of security for your backend systems.
This topic describes the recommended API Gateway architecture in an HA production environment. It includes recommendations on topics such as load balancing, commonly used transport protocols, caching, embedded persistence, and connections to external systems.
![[Tip]](../common_oracle/images/admon/tip.png) |
Tip |
|---|---|
| For details on how to configure and secure multiple Admin Node Managers in a domain, see Secure an API Gateway domain. |
The following diagram shows an overview of an API Gateway platform running in an HA production environment:
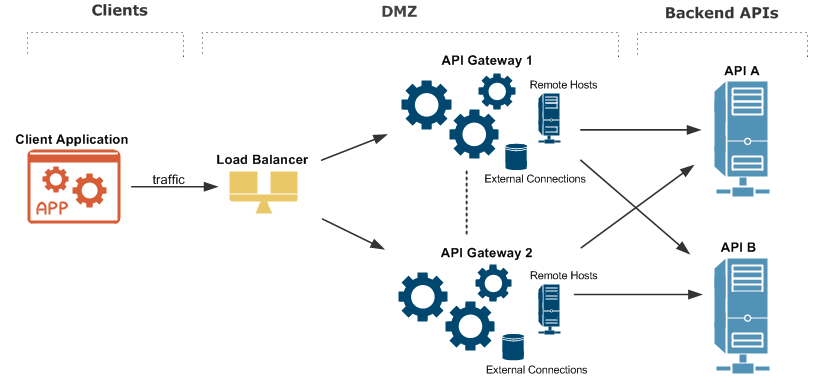
The architecture shown in the diagram is described as follows:
-
An external client application makes inbound calls sending business traffic over a specific message transport protocol (for example, HTTP, JMS, or FTP) to a load balancer.
-
A standard third-party load balancer performs a health check on each API Gateway instance, and distributes the message load to the listening port on each API Gateway instance (default is
8080). -
Each API Gateway instance has External Connections to third-party systems. For example, these include databases such as Oracle and MySQL, and Authentication Repositories such as CA SiteMinder, Oracle Access Manager, Local Directory Access Protocol (LDAP) servers, and so on.
-
Caching is replicated between each API Gateway instance using a distributed caching system based on Ehcache.
-
Each API Gateway instance has Remote Host interfaces that specify outbound connections to backend API systems, and which can balance the message load based on specified priorities for Remote Hosts.
-
Each API Gateway instance contains an embedded Apache Cassandra database used by certain features for persistent data storage, and which has its own HA capabilities.
-
Each API Gateway instance contains an embedded Apache ActiveMQ messaging system, which can be configured for HA in a shared filesystem.
-
Each backend API is also replicated to ensure there is no single point of failure at the server level.
-
Management traffic used by the Admin Node Manager, API Gateway Manager, and Policy Studio is handled separately on different port (default is
8090).
![[Important]](../common_oracle/images/admon/important.png) |
Important |
|---|---|
|
For simplicity, the diagram shows two API Gateway instances only. However, for a resilient HA system, a minimum of at least two active API Gateway instances at any time, with a third and fourth in passive mode, is recommended. |
In this HA production environment, the load balancer performs a health check and distributes message load between API Gateway instances. The API Gateway supports a wide range of standard third-party load balancing products (for example, F5) without any special requirements. Multiple API Gateway instances can be deployed active/active (hot standby) or active/passive (cold standby) modes as required.
The load balancer polls each API Gateway instance at regular intervals to perform a health
check on the message traffic port (default 8080). The load balancer calls the
API Gateway Health Check policy, available on the following default URL:
http://GATEWAY_HOST:8080/healthcheck
The health check returns a simple <status>ok</status> message
when successful. In this way, if one API Gateway instance becomes unavailable, the load
balancer can route traffic to an alternative API Gateway instance.
Both transparent load balancing and non-transparent load balancing are supported. For example, in transparent load balancing, the API Gateway can see that incoming messages are sent from specific client and load balancer IP addresses. The API Gateway can also extract specific client details from the HTTP header as required (for example, the SSL certificate, user credentials, or IP address for Mutual or 2-Way SSL Authentication). In non-transparent load balancing, the API Gateway sees only the virtual service address of the load balancer.
In addition, the API Gateway can also act as load balancer on the outbound connection to the backend APIs. For more details, see the section called “Remote Hosts”.
The API Gateway supports integration with a wide range of third-party Java Message System (JMS) products. For example, these include the following:
-
SonicMQ
-
Tibco Rendezvous
-
Fiorano
-
OpenJMS
-
JBoss Messaging
The API Gateway can act as a JMS client (for example, polling messages from third-party JMS products or sending message to them). For details on configuring API Gateway client connections to JMS systems, see the API Gateway User Guide. For details on configuring HA in supported third-party JMS systems, see the user documentation available from your JMS provider.
The API Gateway also provides an embedded Apached ActiveMQ server in each API Gateway instance. For more details, see the section called “Embedded Apache ActiveMQ”.
The API Gateway supports the following protocols:
-
File Transfer Protocol (FTP)
-
FTP over SSL (FTPS)
-
Secure Shell FTP (SFTP)
When using FTP protocols, the API Gateway writes to a specified directory in your filesystem. In HA environments, when the uploaded data is required for subsequent processing, you should ensure that the filesystem is shared across your API Gateway instances—for example, using Storage Area Network (SAN) or Network File System (NFSv4). For more details on configuring FTP connections, see the API Gateway User Guide.
You can use the Remote Host Settings in Policy Studio to configure how the API Gateway connects to a specific external server or routing destination. For example, typical use cases for configuring Remote Hosts with the API Gateway are as follows:
-
Mapping a hostname to a specific IP address or addresses (for example, if a DNS server is unreliable or unavailable), and ranking hosts in order of priority.
-
Specify load balancing settings (for example, whether load balancing is performed on a simple round-robin basis or weighted by response time).
-
Allowing the API Gateway to send HTTP 1.1 requests to a destination server when that server supports HTTP 1.1, or resolving inconsistencies in how the destination server supports HTTP.
-
Setting timeouts, session cache size, input/output buffer size, and other connection-specific settings for a destination server. For example, if the destination server is particularly slow, you can set a longer timeout.
For details on how to configure Remote Host Settings in Policy Studio, see API Gateway User Guide.
In an HA production environment, caching is replicated between each API Gateway instance using a distributed caching system. In this scenario, each API Gateway has its own local copy of the cache, but registers a cache event listener that replicates messages to the caches on other API Gateway instances. This enables the put, remove, expiry, and delete events on a single cache to be replicated across all other caches.
In the distributed cache, there is no master cache controlling all caches in the group. Instead, each cache is a peer in the group that needs to know where all the other peers in the group are located. Peer discovery and peer listeners are two essential parts of any distributed cache system.
For more details on configuring distributed cache settings, see the topic on Global Caches in the API Gateway User Guide. The API Gateway distributed caching system is based on Ehcache. For more details, see http://ehcache.org/.
You can use External Connections settings in Policy Studio to configure how the API Gateway connects to specific external third-party systems. For example, this includes connections such as the following:
-
Authentication Repositories (LDAP, CA SiteMinder, Oracle Access Manager, and so on)
-
Databases (Oracle, DB2, MySQL, and MS SQL Server)
-
JMS Services
-
SMTP Servers
-
ICAP Servers
-
Kerberos
-
Tibco
-
Tivoli
-
Radius Clients
For details on how to configure External Connections in Policy Studio, see API Gateway User Guide. For details on how to configure HA for any external third-party systems, see the product documentation provided by your third-party vendor.
|
Important |
|---|---|
|
When configuring connections to server hosts, it is recommended that you specify server hostnames instead of IP addresses, which are less stable and are subject to change in a Domain Name System (DNS) environment. |
The API Gateway provides an embedded Apache ActiveMQ broker in each API Gateway instance. In a HA production environment, multiple ActiveMQ broker can work together as a network of brokers in a group of API Gateways. This requires setting up a shared directory that is accessible from all API Gateway instances—for example, using Storage Area Network (SAN) or Network File System (NFSv4).
In this shared network of ActiveMQ brokers, each API Gateway can start a local embedded
ActiveMQ broker, which listens on a configured TCP port (61616 by default).
This port is accessible from both the local API Gateway and remote clients using the load
balancer.
For details on how to configure and manage embedded Apache ActiveMQ, see the following:
For more details on Apache ActiveMQ, see http://activemq.apache.org/.
Each API Gateway instance contains an embedded Apache Cassandra database for default persistent data storage. This Cassandra database is used by the following API Gateway features:
-
OAuth tokens and codes
-
Client Application Registry
-
API Keys
-
KPS collections that you create
If your API Gateway system uses any of these features, you must configure the embedded Apache Cassandra database for HA. The embedded Cassandra database is API Gateway group-aware, which means that all API Gateways in a group can share the same Cassandra data source. In a production environment, you must configure the Cassandra data source to provide HA for the API Gateway group.
For more details on Apache Cassandra, see http://cassandra.apache.org/. For details on the KPS, see the Key Property Store User Guide, available from Oracle Support.
![[Note]](../common_oracle/images/admon/note.png) |
Note |
|---|---|
|
All nodes in a Cassandra cluster must run on the same operating system (for example, Windows, Linux, or Solaris). |
HA Cassandra configuration requires multiple API Gateway instances running on separate host nodes. This section describes how to configure a seed node and add additional nodes with a replication factor of two. For production environments, you should design your API Gateway topology and replication factors before you begin.
To configure a Cassandra seed node, perform the following steps:
-
Decide which API Gateway instance in the group is the seed node. Seed nodes must be running when adding new nodes to the system.
-
All Cassandra configuration is stored at the instance level in
cassandra.yaml, for example:<install-dir>/apigateway/groups/group-2/instance-1/conf/kps/cassandra/cassandra.yamlIn
cassandra.yaml, setlisten_addressandseed_providerto a network address on the host. This address must be accessible by other API Gateway instances in the group.Note rpc_addressshould remain aslocalhostfor this configuration. -
Start the API Gateway instance with Java Management Extensions (JMX) enabled using the
-DenableJMXflag. For example:startinstance -g "Group A" -n "API Gateway 1" -DenableJMX
-
Wait for the API Gateway instance to start.
|
Note |
|---|---|
|
This is the same as the default single node configuration except for the following:
|
On second and subsequent API Gateway nodes, perform the following steps:
-
In
cassandra.yaml, set the following:-
listen_addressto a network address on the host, which must be accessed by other API Gateway nodes in the group (change fromlocalhost) -
seed_providerto the address of the seed node (change fromlocalhost)
-
-
Start the API Gateway instance with JMX enabled, for example:
startinstance -g "Group A" -n "API Gateway 1" -DenableJMX
-
Wait for the API Gateway instance to start.
If you run the kpsdamin tool, and select Embedded Service
Administration > Show Configuration, you can view output
for the configured nodes in the cluster. For example, this includes details such as
the following for each node:
-
seeds: the seed node(s), which are common for each node in the cluster -
listen address: the node address, which is different for each node -
Cassandra clients connect to a
localhostaddress on port9160(server:rpc_address,rpc_port, client:hosts: localhost:9160)
|
Note |
|---|---|
|
You must ensure the Admin Node Manager is running on each node to retrieve this information. |
To display hidden KPS collection configuration in Policy Studio, perform the following steps:
-
Edit the following file:
<install-dir>\policystudio\policystudio.ini -
Add the following line, and save the update:
-Dshow.internal.kps.collection=true
-
Start Policy Studio using the
policystudiocommand.
You can use the Cassandra command-line interface (cassandra-cli) to set the
replication factor. Perform the following steps:
-
Enter
cassandra-cli [-h hostname]to connect the Cassandra command-line interface to the specified node. -
Enter
use kps;to use thekpskeyspace. -
Set
strategy_options = {replication_factor:2};. -
Enter
quit;. -
Run the following command against each API Gateway instance to synchronize the update:
nodetool -h server-address repair kps
Wait until the command completes before moving to the next API Gateway instance. The time depends on how much data you have, but on a new cluster this should happen quickly.
-
Run the following command against each API Gateway instance to display cluster information:
nodetool -h server-address ring kps
You should see an effective ownership of 100% on each node.
-
Start Policy Studio enabled to show the hidden Cassandra Data Sources. For more details, see the section called “View hidden KPS configuration in Policy Studio”).
-
In the Policy Studio tree, under Key Property Stores, select Data Sources > Embedded Storage at the API Gateway KPS collection and/or table level. You can edit the collection if all tables use the default data source in that collection.
For OAuth applications, you can select OAuth Token Stores in Cassandra under Libraries > OAuth2 Stores.
-
Set the read and write consistency level to at least ONE.
-
Deploy the configuration.
This section describes how to share a KPS collection across API Gateway groups.
|
Note |
|---|---|
|
Before performing the steps in this section, second and subsequent nodes
must be registered as hosts of the seed node using the |
Perform the following steps:
-
Set up a KPS collection for an initial group as described in the section called “Set the replication factor”. Ensure this is working before setting up HA for the group.
-
In the Policy Studio tree, right-click the KPS collection, and select Export to export the configuration in an
.xmlfile. -
On the new node, click Import in the Policy Studio toolbar, and browse to the previously exported
.xmlfile. -
Select the
.xmlfile, and click Open to import the selected configuration. -
Deploy the updated configuration.
The HA configuration can then be applied to the nodes in the second and subsequent groups in this way. The seed nodes are used across the groups. You can use the seed node from the initial group if this has been configured.
Cassandra uses Java Management Extensions (JMX) for administration tasks such as repairing and compacting data. JMX must be enabled for Cassandra HA configuration. Cassandra JMX configuration is stored in:
<install-dir>/groups/<group-id>/<instance-id>/conf/kps/cassandra/jvm.xml
To enable this configuration, you must specify enableJMX when starting
the API Gateway, for example:
startinstance -g "Group A" -n "API Gateway 2" -DenableJMX
The default JMX configuration is an insecure JMX configuration using port 7199.
This is the Cassandra JMX monitoring port. After the initial handshake, the JMX protocol
requires that the client reconnects on a randomly chosen port (1024+). The
following shows some example settings:
<?xml version="1.0" encoding="UTF-8"?>
<ConfigurationFragment>
<if property="enableJMX">
<VMArg name="-Dcom.sun.management.jmxremote"/>
<VMArg name="-Dcom.sun.management.jmxremote.port=7199"/>
<VMArg name="-Dcom.sun.management.jmxremote.authenticate=false"/>
<VMArg name="-Dcom.sun.management.jmxremote.ssl=false"/>
</if>
</ConfigurationFragment>
You should run the Cassandra nodetool repair and compact
commands at regular intervals against all Cassandra nodes in the cluster. Ideally,
these commands should be performed at different times on different nodes. For more
details, see http://wiki.apache.org/cassandra/Operations.
You can use the kpsadmin tool to issue these commands to Cassandra
nodes on a user-defined schedule. For example:
kpsadmin -housekeeping <nodelist> <commands> <cron schedule>
This syntax is described as follows:
-
nodelistis a comma-separated list of JMXhostname:portpairs -
commandsis a comma-separated list of of Cassandra commands (ring,repair, orcompact) -
cron scheduleis a cron expression that specifies when the command runs
For example, you can use the following command to run repair, compact, and ring
every day against localhost at 23:15:
kpsadmin -housekeeping "localhost:7199" "repair,compact,ring" "0 15 23 ? * *"
For more details on configuring Cassandra, see:
http://www.datastax.com/documentation/cassandra/1.2/webhelp/