Release 2 (v9.0.2)
Part Number A95949-01
Home |
Solution Area |
Contents |
Index |
| Oracle9i Warehouse Builder User's Guide Release 2 (v9.0.2) Part Number A95949-01 |
|
This chapter describes how to use Expression Builder to create expressions that operate on the data as it flows from a source to a target. This chapter also describes data flow operators and how to add them to a mapping.
This chapter includes the following topics:
Most of the data flow operators described in this chapter require that you create expressions. An expression is a statement or clause that transforms data. These expressions can be portions of SQL that are used inline as part of a bigger SQL statement. They can also be in other languages such as PL/SQL, SAP, or SQL*Loader. Each expression belongs to a type that is determined by the role of the data flow operator. You can create expressions using Expression Builder, or by typing them into the expression field located in the operator or attribute property inspectors.
You can open Expression Builder from the operator properties inspectors in the following operators:
You can open Expression Builder from the attribute properties inspectors in the following operators:

Expression Builder contains the following parts:
To use Expression Builder:
The Expression Builder displays.
You can create an expression by:
This verifies the accuracy of the expression syntax before you save the expression and close the editor.
See "About Mapping Operators" for more information on operators.
This section describes how to add flow operators to a mapping. Flow operators control the data that moves from sources to targets. They also enable you to change your data as appropriate once it reaches the data target.
To add a flow operator to a mapping:
Before you add data flow operators, you add data source and target operators to your mapping. See "Defining Mappings" for more information.
A Mapping Sequence operator generates sequential numbers that increment for each row. You can connect a Mapping Sequence operator to a target operator input or to the inputs of other types of operators. You can combine the sequence outputs with outputs from other operators.
This operator contains an attribute set named OUTGRP containing two output attributes: CURRVAL and NEXTVAL. NEXTVAL generates a row set of consecutively incremented numbers beginning with the next value and CURRVAL generates from the current value.
You must bind a Mapping Sequence to a repository sequence in one of the modules. You must also reconcile it to that object. The repository sequence must be generated and deployed before the map is deployed to avoid errors in the generated code package for the mapping. See "About Binding Mapping Operators" for more information.
You generate a mapping with a sequence in Row Based mode. Sequences are incremented even if rows are not selected. If you want a sequence to start from the last number, then do not run your SQL package in Set Based or in Set Based With Failover operating modes. See "Setting Runtime Parameters" for more information on configuring mode settings.
The Mapping Sequence operator contains the following property:
To add a mapping sequence operator to a mapping:
The Add Mapping Sequence dialog displays.
This selection contains a search text box and a tree for the sequences stored in the Warehouse Builder repository. Click the appropriate node to locate a sequence. Double-click a sequence to select it.
For more information on these options, see "Selecting Data Operators".
The Code Viewer displays generated code for the mapping. The sequence appears in the SELECT list for the insert DML.
Use a Data Generator operator to provide information such as record number, system date, and sequence values. It also provides a place to enter constant information. The Data Generator operator connects the mapping to SQL*Loader to generate the data stored in the database record. The following functions are available:
It is possible for Warehouse Builder to generate data by specifying only sequences, record numbers, system dates, and constants as field specifications. SQL*Loader inserts as many records as are specified by the LOAD keyword.
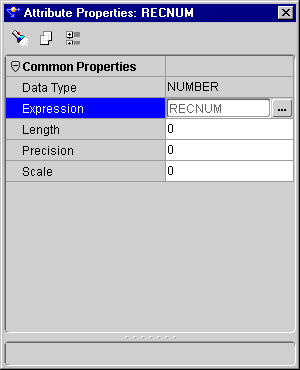
Use the RECNUM keyword to set an attribute to the number of the records that the record was loaded from. Records are counted sequentially from the beginning of the first data file, starting with record 1. Because RECNUM is incremented as each logical record is assembled, it increments for records that are discarded, skipped, rejected, or loaded. For example, if you use the option SKIP=10, the first record loaded has a RECNUM of 11.
A column specified with SYSDATE gets the current system date, as defined by the SQL language SYSDATE function.
The target column must be of type CHAR or DATE. If the column is of type CHAR, then the date is loaded in the format dd-mon-yy. After the load, it can be accessed only in that format. If the system date is loaded into a DATE column, then it can be accessed in a variety of formats that include the time and the date. A new system date/time is used for each array of records inserted in a conventional path load and for each block of records loaded during a direct path load.
The SEQUENCE keyword ensures a unique value for a column. SEQUENCE increments for each record that is loaded or rejected. It does not increment for records that are discarded or skipped.
The combination of column name and the SEQUENCE function is a complete column specification. Table 7-1 lists the options available for sequence values.
If a record is rejected because of a format error or an Oracle error, the generated sequence numbers are not reshuffled to mask this. For example, if four rows are assigned sequence numbers 10, 12, 14, and 16 in a column, and the row with 12 is rejected, the three rows inserted are numbered 10, 14, and 16, not 10, 12, 14. The sequence of inserts is preserved despite data errors. When you correct the rejected data and reinsert it, you can manually set the columns to match the sequence.
Although the Data Generator operator has only one output group, it has predefined attributes corresponding to Record Number, System Date, and a typical Sequence. Modification of these attributes is not recommended but you can create new attributes. The Data Generator operator is only valid for a SQL*Loader mapping. There can only be one Data Generator operator for a mapping.
The Data Generator contains the following property:
To add a data generator to a mapping:
The RECNUM Attribute Properties inspector displays.
The Constant operator enables you to define constants. Constants are initialized at the beginning of the execution of the mapping. Constant values can be used as inputs to a pre-mapping process, a post-mapping process, a mapping output parameter, and other operators in the data flow.
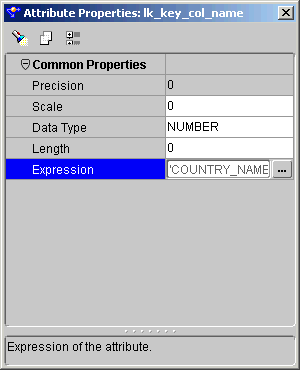
The Constant operator can have only one output attribute group. If the constant defined is of data type VARCHAR or VARCHAR2, the expression must be a valid SQL expression returning a value of data type VARCHAR or VARCHAR2. Constant string literals must be enclosed within single quotes, for example, `my_string'.
The Constant operator contains the following property:
To add a constant operator:
The Attributes Properties inspector displays.
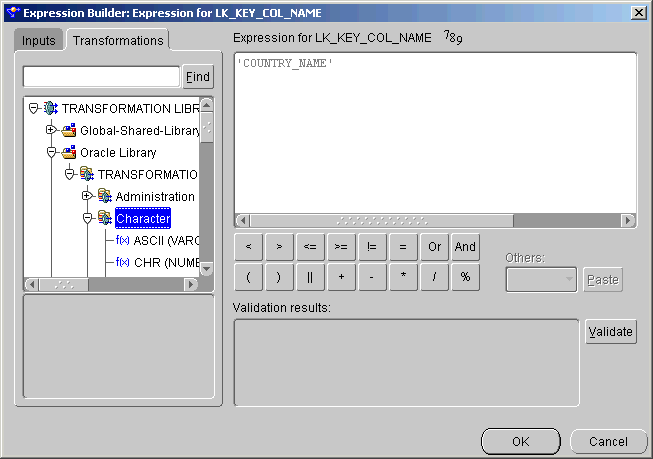
The Code Viewer displays generated code.
The Key Lookup operator enables you to perform a lookup of data from a lookup object such as a table, view, fact, or dimension. The lookup object is bound to the Key Lookup operator. Use the Key Lookup operator if you have defined surrogate keys on warehouse objects such as dimensions. You can have multiple Key Lookup operators in the same mapping.
The key that you look up can be any unique value. It does not need to be a primary or unique key, as defined in an RDBMS. The Key Lookup operator reads data from a lookup table using the key input you supply and finds the matching row. This operator returns a row for each input key.
The output of the Key Lookup operator corresponds to the columns in the lookup object. If multiple rows in the lookup table match the key inputs, the cardinality of the output differs from the input. This produces results inconsistent with the data flowing into the target operator. To ensure that only a single lookup row is found for each key input row, use keys in your match condition.
You can use Inbound reconciliation on Key Lookup outputs. Outbound reconciliation is disabled. See "Reconciling Mapping Operators with Repository Objects" beginning for more information on reconciliation.
Each output attribute for the key lookup has a property called DEFAULT VALUE. The DEFAULT VALUE property is used instead of NULL in the outgoing row set if no value is found in the lookup table for an input value. The generated code uses the NVL function.
When you validate this operator:
To add a Key Lookup operator:
The Add Mapping Key Lookup dialog displays.
This selection contains a search text box and a directory tree for the tables that can be Key Lookup entities. Click the appropriate node to locate a table. Double-click a table to select it.
A Key Lookup operator displays.
The Key Lookup Properties inspector displays.
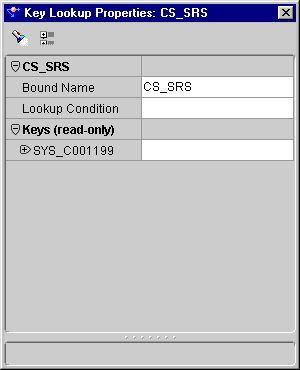
The Lookup Condition dialog displays.
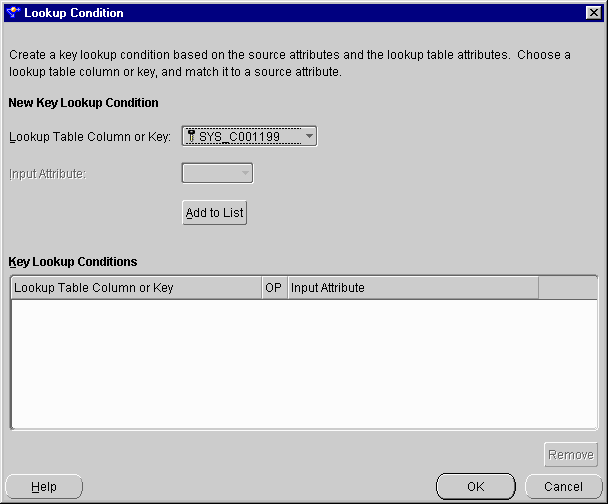
Choose attributes to compare to the selected lookup table column.
For a non-composite key:
The column or input pairs are added to the table at the bottom of the main dialog.
For a composite key:
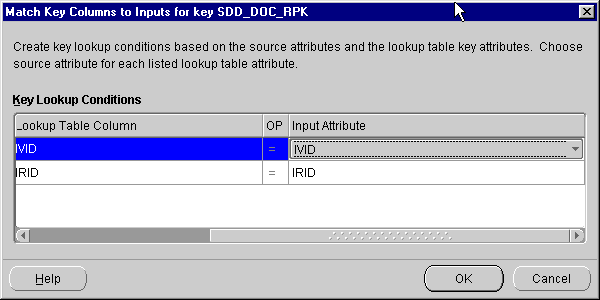
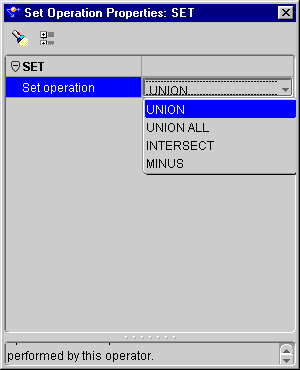
The Set Operation operator enables you to use set operations in a mapping. The operations are:
The Set Operation operator contains two input groups and one output group. You can add input groups by connecting source operator attributes to the Set Operation operator. Mapping attributes to a Set Operation operator input group creates corresponding attributes with the same name and data type in the Set Operation output group. The number of attributes in the output group matches the number of attributes in the input group containing the most attributes.
To execute the Set Operation operator:
Corresponding attributes are determined by the order of the attributes within an input group. For example, attribute 1 in input group 1 corresponds to attribute 1 in input group 2.
Apply the set operation in top-down order. The order of the input groups determines the execution order of the set operation. This order affects only the minus operation. For example, A minus B is not the same as B minus A. The order of the attributes within an input group determines the structure of a set. For example, {empno, ename} is not the same as {ename, empno}.
To create sets of data:
The Set Operation Properties inspector displays.
You can use the Joiner operator to join multiple row sets from different sources with different cardinalities, and produce a single output row set. The Joiner operator uses a boolean condition expression that relates column values in each source row set to at least one other row set.
If the input row sets are related through foreign keys, that relationship is used to form a default join condition. You can use this default condition or you can modify it. If the sources are not related through foreign keys, then you must define a join condition.
The following can help you generate queries with optimal performance:
LINES.PO_OR_ORDER_ID + 10 = ORD.ORDER_ID. All values from the source table must be read and transformed to find the joined rows for a given row.
The join condition expression cannot contain aggregation functions, such as SUM. Compile errors result when deploying the generated code for the map.
The Joiner can have an unlimited number of input groups and one output group.
The Joiner operator contains the following properties:
To add a Joiner to a mapping:
The output attributes are created with data types matching the corresponding input data types.
The Joiner Properties inspector displays.
The Code Viewer displays generated code. The join condition appears in the WHERE clause of the SELECT query for the insert DML.
In an equijoin, key values from the two tables must match. In a full outer join, key values are matched and nulls are created in the resulting table for key values that cannot be matched. A left or a right outer join retains all rows in the specified table.
In Oracle8i, you create an outer join in SQL using the join condition variable (+):
SELECT ...FROM A, BWHERE A.key = B.key (+);
This example is a left outer join. Rows from table A are included in the joined result even though no rows from table B match them. To create a full outer join in Oracle8i, you must use multiple SQL statements.
The Expression Builder allows the following syntax for a full outer join:
TABLE1.COL1 (+) = TABLE2.COL2 (+)
This structure is not supported by Oracle8i. Oracle9i is ANSI SQL 1999 compliant. The ANSI SQL 1999 standard includes a solution syntax for performing full outer joins. The code generator translates the above expression into an ANSI SQL 1999 full outer join statement, similar to:
SELECT ... FROM table1 FULL OUTER JOIN table2 ON (table1.col1 = table2.col2)
Because the full outer join statement complies to ANSI SQL 1999, it is only valid if the generated code is deployed to an Oracle9i database. Specifying a full outer join to an Oracle8i database results in a validation error.
A full outer join and a partial outer join cannot be used in one SQL statement. If a full outer join and partial outer join are used in the same SQL statement, a validation error occurs.
To use a full outer join in a mapping:
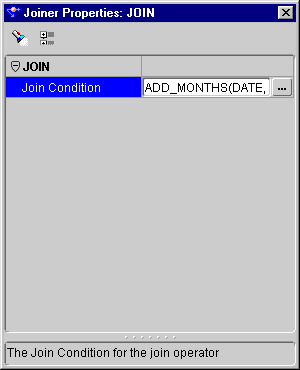
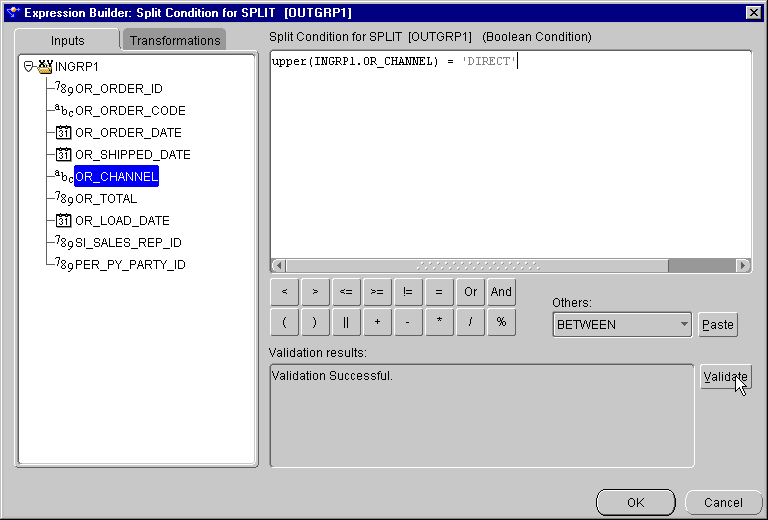
You can use the Splitter operator to split a single input row set into several output row sets using a boolean split condition. Each output row set has a cardinality less than or equal to the input cardinality.
The Splitter operator creates an output group called REMAINING_ROWS containing all input rows not included in any of the other output groups. You can delete this output group, but you cannot edit it.
The Splitter Operator contains the following properties:
To split data from one source to several targets:
The output attributes are created with data types matching the corresponding input data types.
The Splitter Properties inspector displays.
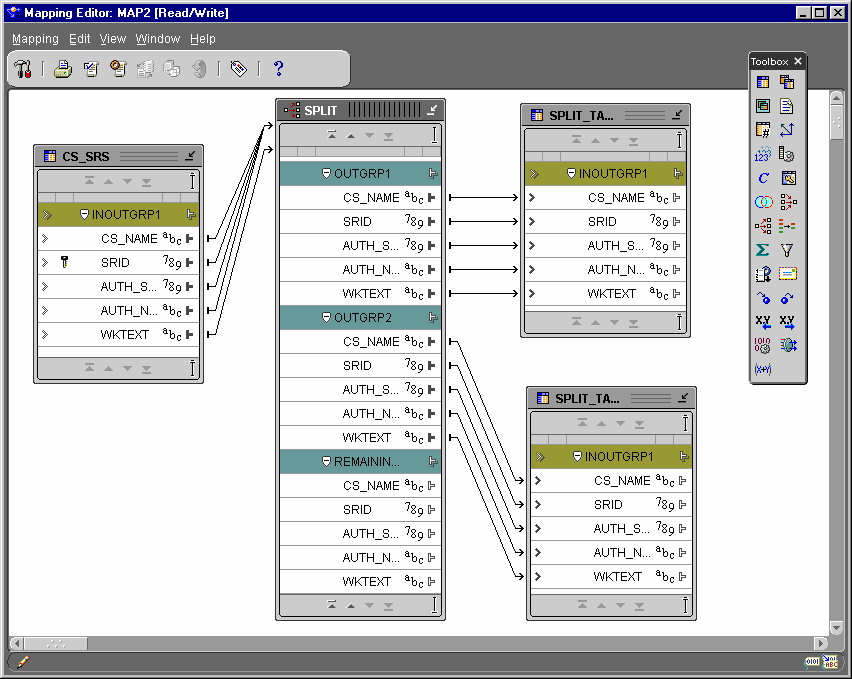
The Code Viewer displays generated code. The generated code displays the split conditions in the WHERE clauses of the SELECT queries for the insert DML. There is a separate select query for each target.
The Deduplicator enables you to remove duplicate data in a source by placing a DISTINCT clause in the select code represented by the mapping.
To remove redundant data:
The Code Viewer displays generated code with a DISTINCT clause in the select statement.
The Aggregator operator performs data aggregations, such as SUM and AVG, and provides an output row set with aggregated data. Because each Aggregator operator shares a GROUP BY and HAVING clause, each attribute in the output attribute group has the same cardinality. The number of rows in the output row set is less than or equal to the number of input rows.
The Aggregator operator has one input attribute group and one output attribute group. Connecting the source to the input attribute group produces the corresponding aggregated row set in the output attribute group.
The Aggregator operator contains the following properties:
To add an aggregator to a mapping:
See "Adding or Removing Operator Attribute Groups" for information.
The Attribute Properties inspector displays.
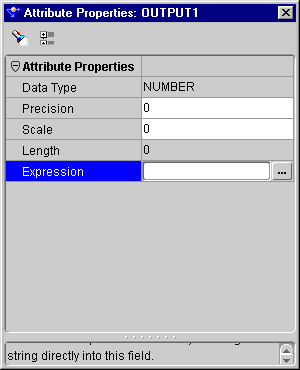
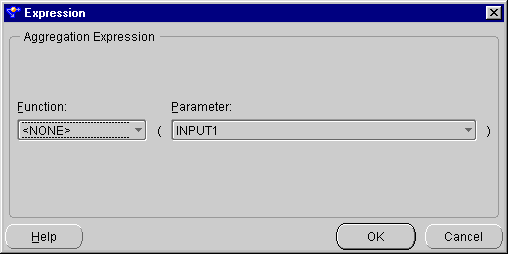
The Expression dialog displays.
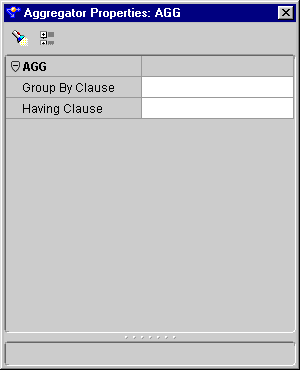
The Group By Clause dialog displays.
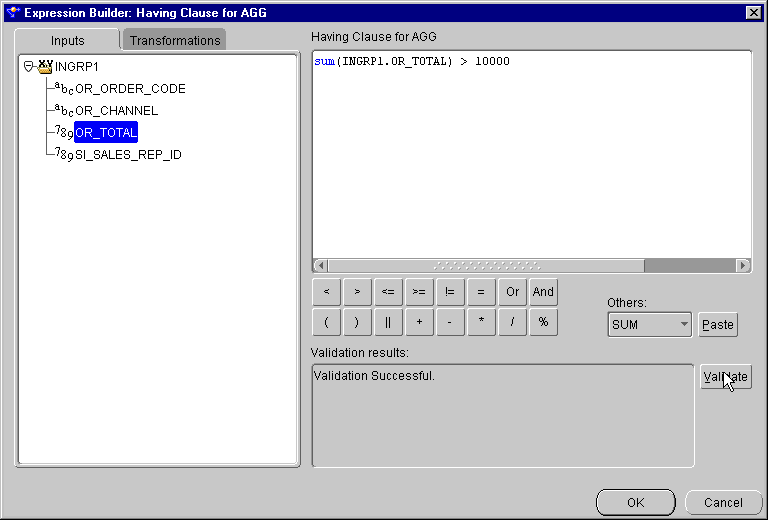
Create an expression, for example, sum(INGRP1.OR_TOTAL) > 10000.
The Code Viewer displays generated code.
You can conditionally filter out rows from a row set using the Filter operator. The Filter operator filters data from a source to a target by placing a WHERE clause in the code represented by the mapping. You connect a source operator to the Filter operator, apply a filter condition, and send a subset of rows to the next mapping operator.
A Filter operator has only one input/output attribute group that can be connected to both a source and target row set. The resulting row set is a filtered subset of the source row set based on a boolean filter condition expression.
The Filter operator contains the following property:
To filter data:
The Filter Properties inspector displays.

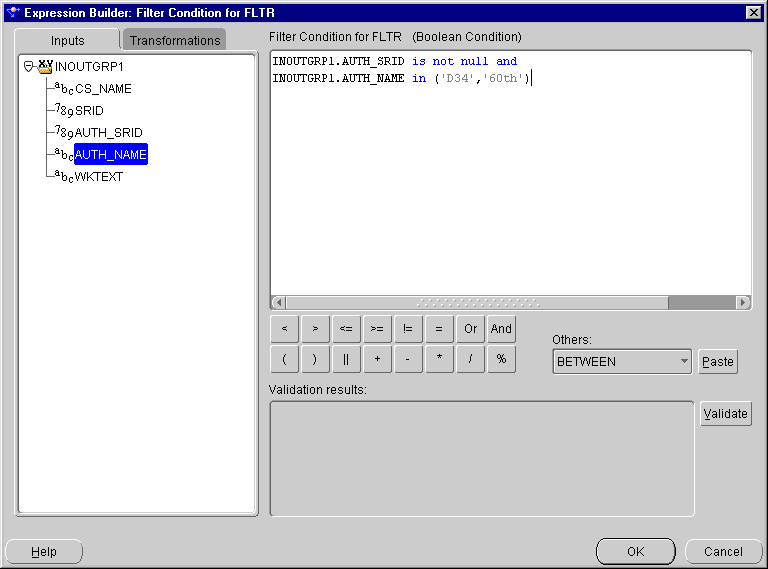
The Code Viewer displays generated code. The filter condition expressions generated as a WHERE clause for set-based view mode. The filter input names in the original filter condition are replaced by actual column names from the source table, qualified by the source table alias.
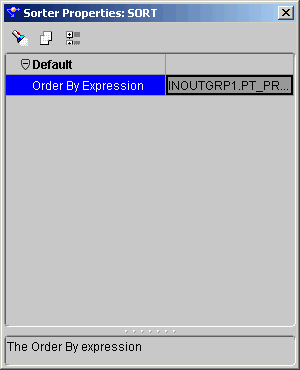
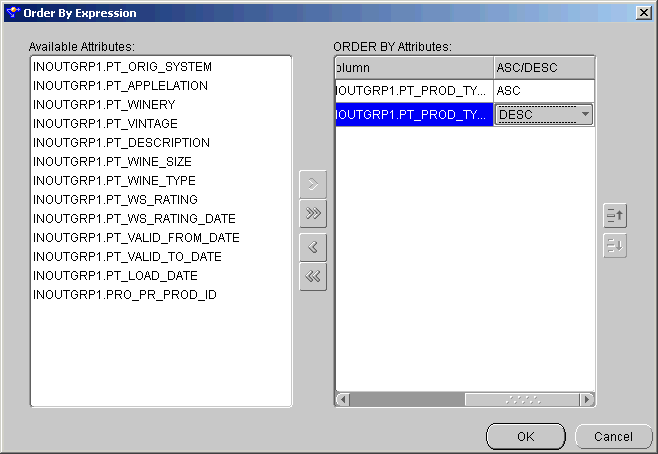
You can produce a sorted row set using the Sorter operator. The Sorter operator enables you to specify which input attributes are sorted and whether the sorting is performed in ascending or descending order.
The Sorter operator has one input/output attribute group. This group can be connected from any output or input/output attribute group and to any target input or input/output attribute group. Warehouse Builder sorts data by placing an ORDER BY clause in the code generated by the mapping.
The Sorter operator contains the following property:
To order data:
The Sorter Properties inspector displays.
The Code Viewer displays generated code.
The Name and Address operator enables you to cleanse data from multiple sources in differing formats. Name cleansing includes both personal name and business name data. You can then map the clean data to a target or to another data flow operator.
By matching incoming data with data in the Warehouse Builder Name and Address data libraries, the Name and Address operator improves the accuracy and value of your name and address data. This operator enhances the quality of your data by:
The Name and Address operator parses the data from a source operator into data that can then be reassembled appropriately for your business case. Name and address data is parsed according to these methods:
After you choose a parsing method, you define Input Roles and Output Components from lists of predefined role types that vary depending on the selected parsing option. Warehouse Builder adjusts the list of available Input Roles and Output Components based on the selected parsing method. Figure 7-25 shows how the Name and Address operator appears on the Mapping Editor canvas.
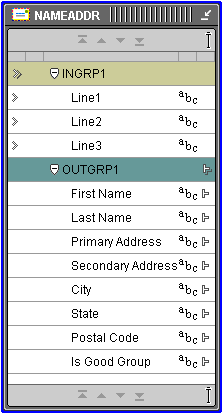
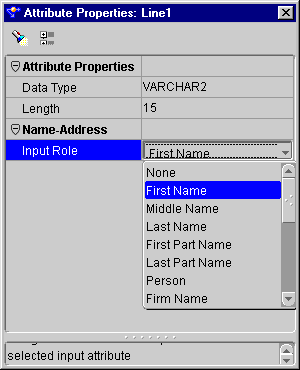
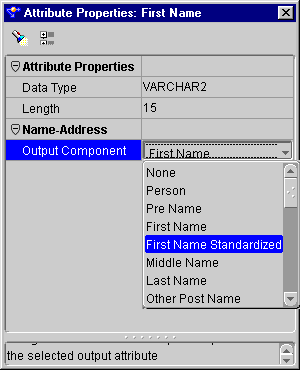
The Name and Address operator contains one input group and one output group, both of which are created automatically when you drop the operator on the mapping editor canvas. You configure the attributes in the input group as Input Roles. An input role represents the input data mapped from a mapping source operator. You configure the attributes in the output group as Output Components.
Table 7-2 lists the input roles.
Table 7-3 lists the output components.
After parsing and matching the data, you are ready to map from the output parameter group to a target operator.
To cleanse name and address data:
The Name and Address Properties inspector displays.
The Attribute Properties inspector displays.
The Code Viewer displays generated code.
The Pre-Mapping Process operator calls a function or procedure whose metadata is defined in Warehouse Builder prior to executing a mapping. The output parameter group provides the connection point for the returned value (if implemented with a function) and the output parameters of the function or procedure. There are no restrictions on the connections of these output attributes
When you drop a Pre-Mapping Process operator onto the Mapping Editor canvas, a dialog opens displaying the available libraries, categories, functions, and procedures. You select a function or procedure from the tree, and the operator displays with predefined input and output parameters.
The Pre-Mapping Process operator has attribute groups corresponding to the number and direction of the parameters associated with the selected PL/SQL procedure or function. You can modify this list by using reconciliation.
There can be only one Pre-Mapping Process operator for a mapping. Only constants, mapping input parameters, and output from a Pre-Mapping Process can be mapped into a Post-Mapping Process operator.
To add a pre-mapping process operator to a mapping:
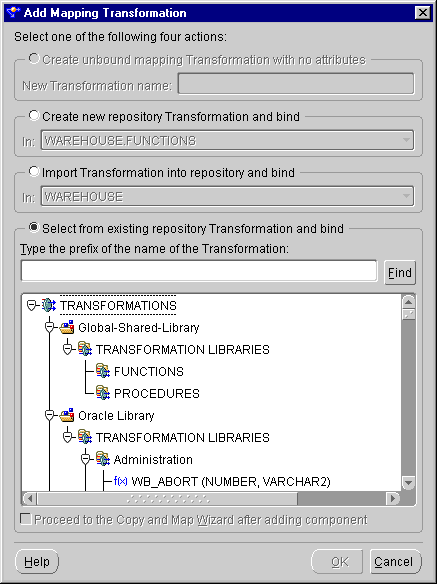
The Add Mapping Transformation dialog displays.
The Post-Mapping Process operator calls a function or procedure whose metadata is defined in Warehouse Builder after the map is executed. The output parameter group provides the connection point for the returned value (if implemented via a function) and the output parameters of the function or procedure. There are no restrictions on the connections of these output attributes
The Post-Mapping Process operator has attribute groups corresponding to the number and direction of the parameters associated with the selected PL/SQL procedure or function. This list of groups and attributes can only be modified through reconciliation.
There can be only one Post-Mapping Process operator for a mapping. Only constants, mapping input parameters, and output from a Pre-Mapping Process can be mapped into a Post-Mapping Process operator. The Post-Mapping Process operator is not valid for an SQL*Loader mapping.
To add a post-mapping process operator to a mapping:
The Add Mapping Transformation dialog displays.
A Mapping Input Parameter operator enables you to pass parameter values into a mapping. The Mapping Input Parameter operator has a cardinality of one and it creates a single row set that can be combined with another row set as input to the next operator.
The names of the input attributes become the names of the mapping output parameters. The parameters can be used by connecting the attributes of the Mapping Input Parameters operator within the mapping editor. You can have only one Mapping Input Parameter operator in a mapping.
The default value for the mapping input parameter appears in the DEFAULT clause following the function parameter declarations in the generated PL/SQL package. For example, if a mapping parameter named param1 with data type VARCHAR2 is defined with a default value of 'HELLO', the generated main function in the PL/SQL package appears as:
If a mapping parameter output named param1 has the data type VARCHAR2, the generated main function in the PL/SQL package appears as:
The Mapping Input Parameter operator contains the following properties:
To add a Mapping Input Parameter operator to a mapping:
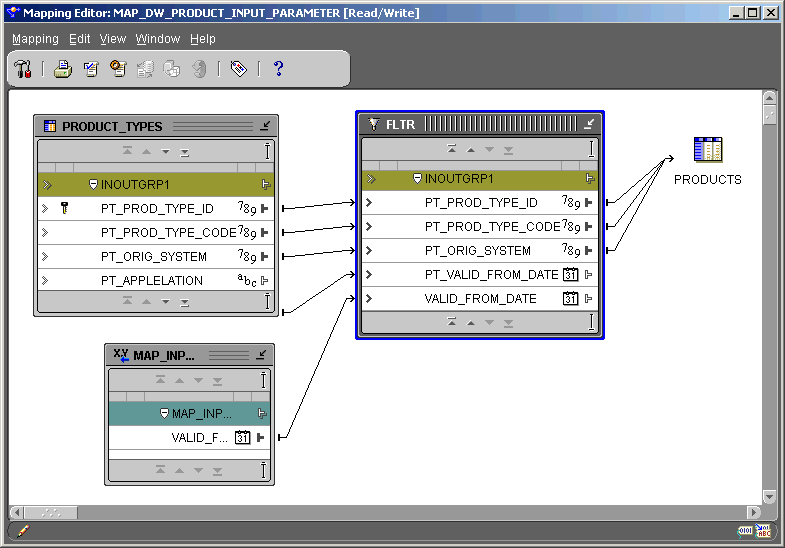
The Mapping Output Parameter operator enables you to send values out of a mapping. The Mapping Output Parameter operator must have only one input attribute group. You can have only one Mapping Output Parameter operator in a map. Attributes not associated with a row set can be mapped into a Mapping Output Parameter operator. For example, constant, input parameter, output from a pre-mapping process, or output from a post process can all contain attributes not associated with a row set. A Mapping Output Parameter operator is not valid for a SQL*Loader mapping.
The default value for the mapping output parameter appears in the DEFAULT clause following the function parameter declarations in the generated PL/SQL package. For example, if a mapping parameter named param1 with data type VARCHAR2 is defined with a default value of 'HELLO', the generated main function in the PL/SQL package appears as:
If a mapping parameter output named param1 has data type VARCHAR2, the generated main function in the PL/SQL package appears as:
The Mapping Output Parameter operator contains the following properties:
To add a mapping output parameter to a mapping:
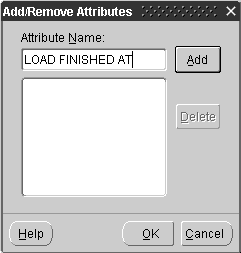
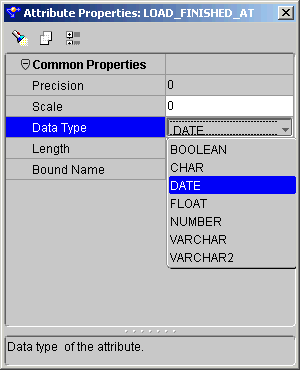
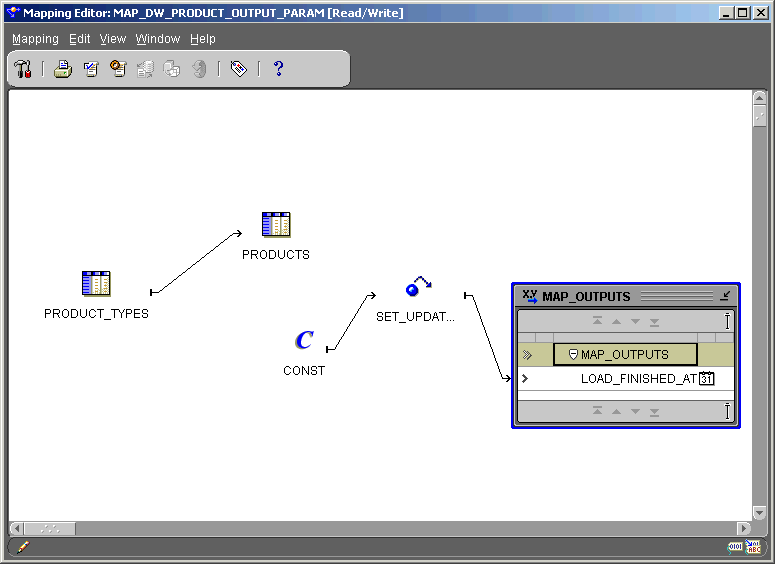
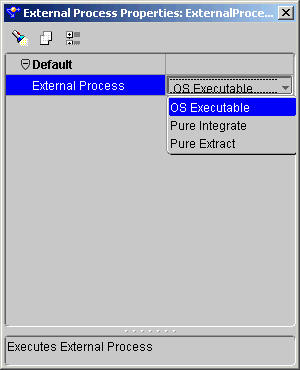
The External Process operator enables you to represent a process not defined by Warehouse Builder to incorporate it into a mapping. The External Process operator is a self-contained operation and requires no inputs or outputs. During code generation, Warehouse Builder generates a job control code (TCL script) for external process operators that can be deployed as part of the Warehouse Builder workflow.
The following types of processes are available in Warehouse Builder:
To add an External Process operator to a mapping:
The External Process Properties inspector displays.
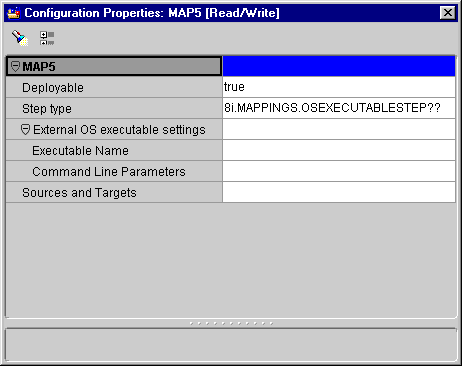
The Configuration Properties inspector displays.
The Code Viewer displays generated code.
You use the Mapping Transformation operator to transform the column value data of rows within a row set using a PL/SQL function, while preserving the cardinality of the input row set.
The Mapping Transformation operator must be bound to a function or procedure contained by one of the modules in the repository. The inputs and outputs of the Mapping Transformation operator correspond to the input and output parameters of the bound repository function or procedure. Also, if the Mapping Transformation operator is bound to a function, a result output is added to the operator that corresponds to the result of the function. The bound function or procedure must be generated and deployed before the mapping can be deployed, unless the function or procedure already exists in the repository.
Warehouse Builder provides pre-defined PL/SQL library functions in the runtime schema that can be selected as a bound function when dropping a Mapping Transformation operator onto a mapping. In addition, you can choose a function or procedure from the Global Shared Library.
The Mapping Transformation operator contains the following properties:
To add a mapping transformation operator:
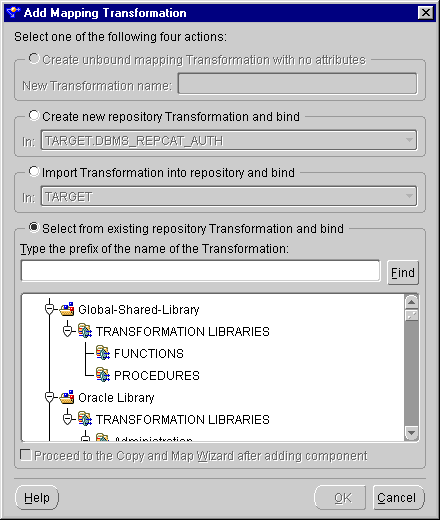
The Add Mapping Transformation dialog displays.
This selection contains a search text box and a directory tree for all the transformations stored in the Warehouse Builder repository. Click the appropriate node to locate a transformation. Double-click a transformation to select it.
For more information on these options, see "Selecting Data Operators" beginning.
The Mapping Transformation Properties inspector displays.
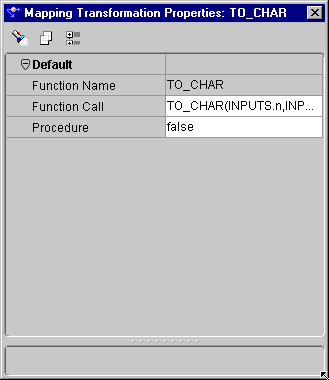
The Code Viewer displays generated code.
The Expression operator enables you to write SQL expressions that define non-procedural algorithms for one output parameter of the operator. The expression text can contain combinations of input parameter names, variable names, and library functions. Use the Expression operator to transform the column value data of rows within a row set using SQL-type expressions, while preserving the cardinality of the input row set. To create these expressions, open the Attribute Property inspector for the output attribute and open Expression Builder.
You can have only one input attribute group and one output attribute group in the Expression operator, both of which are created automatically when you drop the operator onto the Mapping Editor canvas.
The output expressions for this operator cannot contain any aggregation functions. To use aggregation functions, use the Aggregator operator.
The Expression operator contains the following properties:
To add an expression operator:
This automatically creates the input attributes.
The Code Viewer displays generated code.
The next chapter, Chapter 8, "Configuring and Generating Mappings" shows you how to configure your mapping for generating deployment code.
|
|
 Copyright © 1996, 2002 Oracle Corporation. All Rights Reserved. |
|