Release 2 (v9.0.2)
Part Number A95949-01
Home |
Solution Area |
Contents |
Index |
| Oracle9i Warehouse Builder User's Guide Release 2 (v9.0.2) Part Number A95949-01 |
|
This chapter describes how to configure operator properties of a mapping, and how to manage code generation. It also describes how to reconcile mapping operators with repository objects, mapping validation, and techniques for improving deployment performance.
This chapter includes the following topics:
Once you have selected the source and target objects, configured their properties, and linked the operators, you may need to reconcile the mapping operators with their corresponding repository objects.
Coordinating mapping operators with the status of repository objects is called reconciliation. You can reconcile operators with repository objects (inbound) or you can reconcile repository objects with operators (outbound).
Do not confuse reconciliation with synchronization. While synchronization ensures that you are up-to-date with changes made by other users in a multi-user environment, reconciliation updates mapping operators with changes made to the physical repository objects.
Inbound reconciliation updates the target mapping operator with its repository object. You can also use Inbound Reconcile to bind a mapping operator to a repository object. You can Inbound Reconcile an operator by name, position, object identifier match, or any combination of these methods.
You can use inbound reconciliation for any of the following reasons:
Inbound reconciliation has no impact on the linking of other mapping operators in the mapping to repository objects; Warehouse Builder preserves these links. Table 8-1 describes the operator types supported by reconciliation.
To reconcile inbound mapping operators:
The Inbound Reconcile Operator dialog displays.
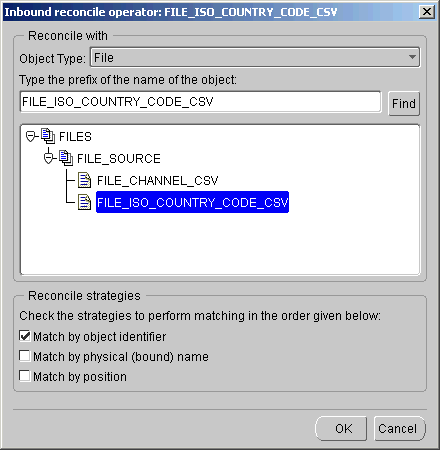
If you do not select a strategy, then the reconcile process replaces the attributes of the operator with an exact copy of the columns or fields of the selected repository object.
If you select more than one strategy, then matching occurs in the following order:
Reconciliation also updates additional logical properties of an operator. For example, for a Mapping Flat File operator, information about the character set and filename are refreshed.
Outbound reconciliation updates a selected repository object to reflect changes in the mapping operator. You can use outbound reconciliation for any of the following reasons:
You cannot create a repository object of a different type using outbound reconciliation. Outbound reconciliation has no impact on the linking of other mapping operators in the mapping to repository objects.
Table 8-2 lists the eligible Mapping Operators for Outbound Reconcile:
To reconcile outbound mapping operators:
The Outbound Reconcile dialog displays.
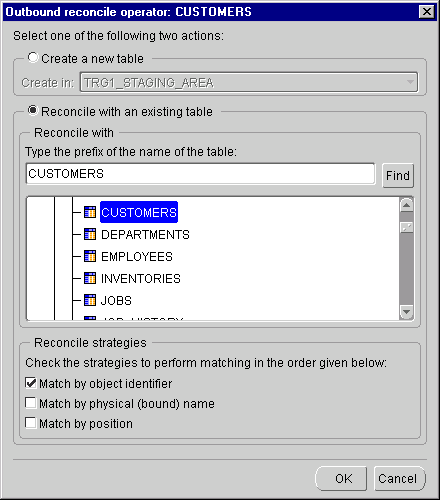
You can use the outbound reconcile feature to create new objects or update existing objects in the repository that are derived from a mapping operator. After you have created a mapping operator, you can copy and map its attributes into a new operator. You can then create a new corresponding repository object that inherits the same properties.
To create a new table in the repository associated with a Mapping Table:
The Reconcile Outbound dialog displays.
A table with identical properties and attributes as the Mapping Table is created in the repository.
You use the properties inspectors to configure how the operators behave in an ETL process. The properties that you configure vary according to the processes you defined when you created the mapping. You can configure the following sets of properties using properties inspectors:
The following sections describe the settings on the Operator Properties inspectors for mapping relational table, flat file, and materialized view operators. See Chapter 7, "Using Mapping Operators and Transformations" for information on settings unique to data flow operators.
This section describes how to configure a Mapping Table operator using the Operator Properties inspector. The Operator Properties inspector described in this section contains the same settings for Mapping Facts, Mapping Dimensions, Mapping Views, and Materialized Views.
You configure settings in the following categories:
Mapping Dimension and Mapping Fact operators contain a read-only category for keys.
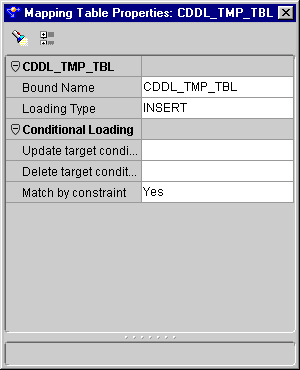
To configure a Mapping Table operator:
The Mapping Table Properties inspector displays.
If evaluated to true, the row is included in the update loading operation.
These settings define your operator name if it is unbound, and the loading type.
INSERT-The incoming row sets are inserted into the data target. Insert fails if a row already exists with the same primary or unique key.
UPDATE-The incoming row sets are used to update existing rows in the data target. Update fails if no row exists for the specified match conditions.
INSERT/UPDATE-For each incoming row, an insert operation is performed first. If the insert fails, an update operation occurs.
UPDATE/INSERT-For each incoming row, an update operation is performed first.
DELETE-The incoming row sets are used to determine which of the rows at the target get deleted.
TRUNCATE/INSERT-The data target is truncated before the incoming row set is inserted into the data target.
DELETE/INSERT-The rows in the data target are deleted before the incoming row set is inserted into the data target.
CHECK/INSERT-The data target is checked to see if it contains any rows. If not, the incoming row sets are inserted into the data target.
NONE-No operation is performed on the data target. This setting is useful for testing. Extraction and transformations run but have no effect on the target.
These settings define:
The following read-only settings are available in the mapping fact and mapping dimension operator properties.
You can configure a Flat File operator as either a source or target. You can configure the Loading type and the first row naming for this operator. All other settings are read-only.
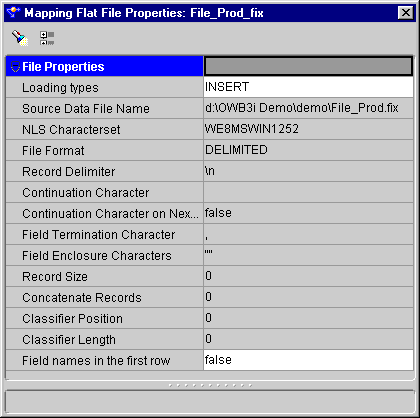
INSERT- Creates a new target file. If a target file already exists, then it is replaced with a new target file.
UPDATE-Creates a new target file. If a target file already exists, then it is appended.
NONE-No operation is performed on the data target. This setting is useful for test runs, where all transformations and extractions are run but have no effect on the target.
The following settings are read-only. See "Adding Transformations" for more information on transformations.
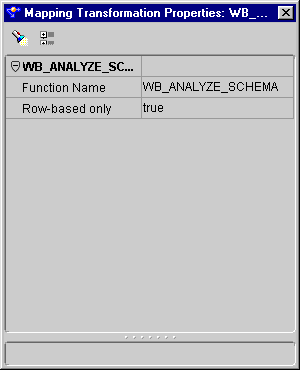
Function/Procedure Name: Name of the transformation.
Row-based Only: Indicates if the transformation is loaded using row-based mode. Some transformations can use set-based mode or row-based mode.
You set most mapping operator attributes when you define them during the module definition phase. However, if you want to alter operator attributes to execute your mapping, you can do this directly from the Attribute Properties inspectors.
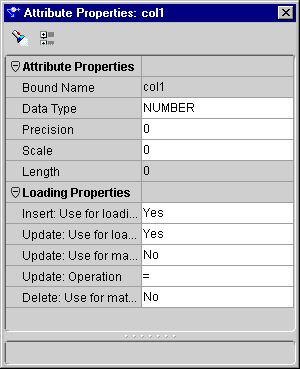
This category contains the data object attribute settings.
The mapping table, mapping dimension, mapping fact, mapping view, and mapping materialized view operators have a Loading Properties category. This category contains the following settings:
|
target:= source |
|
|
target:= source + target |
|
|
target:= target - source |
|
|
target:= source - target |
|
|
target:= target||source |
|
|
target:= source||target |
After you set the mapping operator properties, you can configure the physical properties of the mapping using the Configuration Properties dialog. The following sections describe the basic steps for configuring the physical properties of a mapping containing tables, flat files, and SAP files.
The Configuration Properties inspector displays the physical properties of the mapping grouped into different categories:
The properties that are available for configuration vary according to the type of object. Use the properties inspectors to review and configure each object you are planning to deploy.

To configure mapping physical properties:
The Configuration Properties inspector displays.
See "Setting Runtime Parameters" below for information on these settings.
See "Setting Sources and Targets" for information on these settings.
This setting enables Warehouse Builder to generate a set of scripts to create a data warehouse object for those mapping entities marked as deployable.
A mapping step is the result of the implicit mapping graph analysis performed on a mapping. Mapping steps are automatically created and maintained; you cannot add, delete, or rename them. A step can be one of the following types:
Each type has related physical configuration parameters that you can configure using the Configuration Property inspector. Code can be generated for mapping steps in its associated language.
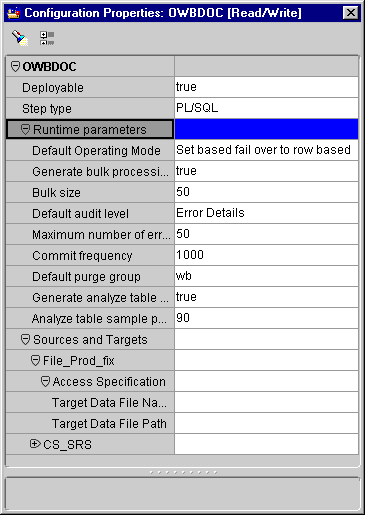
This section describes the runtime parameters.
Default Operating Mode: You can set your mapping to generate code using the following settings:
SET BASED-Enables Warehouse Builder to insert all of the data in a single SQL command. This option depends upon a correctly designed mapping. This setting assigns SQL as the implementation language to each operator unless an operator does not support SQL. If an operator does not support SQL, then all operators in the mapping use PL/SQL as the implementation language. You can use set based if you:
ROW BASED-Starts from the beginning of the mapping and assigns SQL as the implementation language to each operator. If the code generator finds an operator that supports PL/SQL, it assigns that language to all subsequent mapping operators. This setting offers the most auditing or debugging information since it is likely that the expressions or transformations in the mapping will be implemented in PL/SQL. You can use row based if:
ROW BASED (TARGET ONLY)-The implementation language of the data target operators using this setting is always PL/SQL. When used with Set Based Fail Over, this setting allows the error rows to be stored into the audit table when data is being loaded into the target. Although this is mainly used when the source data is clean, there may be errors when loading it into the targets. For example, a foreign key constraint violation when loading a fact with a missing primary key at the dimension, or an incompatible implicit data type conversion due to the limited length, scale, or precision of the data targets.
SET BASED FAIL OVER TO ROW BASED-The mapping is first executed in set based mode. If any error occurrs, the execution fails over to row based. If this operating mode cannot be implemented by the code generator, a runtime exception occurs.
SET BASED FAIL OVER TO ROW BASED (TARGET ONLY)-The mapping is first executed in set based mode. If any error occurrs, the execution fails over to row based (Target Only) mode. If this operating mode cannot be implemented by the code generator, a runtime exception occurs.
NONE-No auditing information is recorded in runtime.
STATISTICS-Statistical auditing information is recorded in runtime.
ERROR DETAILS-Statistical plus error information is recorded in runtime.
COMPLETE-All auditing information is recorded in runtime.
The Configuration Properties inspector displays each operator in a mapping by name under the Sources and Target node. Each operator contains a set of properties you can edit.
See "Configuring Partition Exchange Loading (PEL)" for more information on PEL. See "Creating Partitions" for information on partitioning.
To define hints for a mapping:
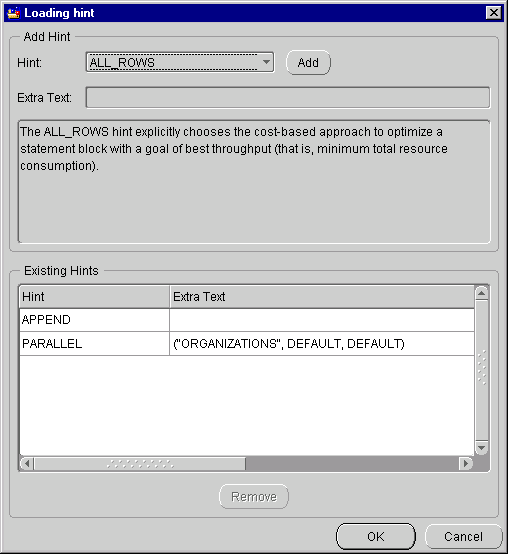
The hint appears in the Existing Hints field. Type additional text as appropriate in the Extra Text column.
The editor includes the hint in the mapping definition.
For information on optimizer hints and how to use them, see Oracle8i/9i Designing and Tuning for Performance.
Enable Constraints: Setting this parameter to false disables all referential constraints to and from the target table. This speeds loading by omitting constraint checking by the database. After all the data is loaded, the constraints are automatically enabled by Warehouse Builder. This property compromises referential integrity. If the data does not comply with the constraints, the constraint becomes invalid. In such cases, you have to manually resolve the referential integrity of the data. If set to the value true, then the REENABLE DISABLED_CONSTRAINTS clause is generated. This option automatically re-enables integrity constraints at the end of a direct-path load.
Exceptions Table Name: If set to a non-blank value, then the EXCEPTIONS table clause is generated. This option specifies a table that must exist when SQL*Loader is run. It is used to insert the records of all rows that have violated one of the integrity constraints when constraint re-enabling is processed during a direct path load.
A conventional path load executes a SQL INSERT statement to populate tables in an Oracle database. A direct path load eliminates much of the Oracle database overhead by formatting Oracle data blocks and writing the data blocks directly to the database files. Because a direct load does not compete with other users for database resources, it can usually load data at or near disk speed. Certain considerations such as restrictions, security, and backup implications are inherent to each method of access to database files. See Oracle9i Database Utilities for more information.
When designing and implementing a mapping to extract data from a flat file using SQL*Loader, there are several places where you can choose values for properties that affect the generated SQL*Loader script.
Each load operator in a map has an operator property called Loading Types. The value contained by this property affects how the SQL*Loader INTO TABLE clause for that load operator is generated. Table 8-3 lists the INTO TABLE clauses associated with each load type.
| Loading Types | INTO TABLE |
|---|---|
|
INSERT/UPDATE |
APPEND |
|
DELETE/INSERT |
REPLACE |
|
TRUNCATE/INSERT |
TRUNCATE |
|
CHECK/INSERT |
INSERT |
|
NONE |
INSERT |
You can supply physical configuration information to affect the generated SQL*Loader output from either the configuration properties inspector or by setting the values in the physical step configuration. The following parameters are available in the Configuration Properties inspector:
When a mapping contains a flat file operator, the Configuration Properties inspector contains additional settings. When a mapping includes a Mapping Flat File operator as target, it generates a PL/SQL deployment code package.
Mappings containing Mapping Flat File operators as sources generate SQL*Loader scripts. When a mapping uses SQL*Loader, the Configuration Properties inspector also contains settings for defining source file data and a category called Default that contains script parameters.

To configure a mapping with a flat file:
The Configuration Properties inspector displays.
See "Setting Runtime Parameters" for information on these settings.
See "Configuring Flat File Physical Properties" for information on these settings.
See "Configuring Flat File Physical Properties" for information on these settings.
This section describes the configuration parameters for a SQL*Loader mapping.
Parameters affecting script type:
Parameters affecting the OPTIONS clause:
Parameters affecting the INFILE clause:
The Data Files configuration parameter enables you to specify the characteristics of the physical files to be loaded. The initial values for these parameters are set from the properties of the flat file used in the mapping.
For more information on each SQL*Loader option and clause, see Oracle8i Utilities or Oracle9i Database Utilities.
To configure a mapping with a flat file as a target:
You must first set this path in the Init.ora file for your warehouse instance. The UTL_FILE_DIR parameter contains the path setting. For example, to load files in D:\Data\FlatFiles\File1.dat, set the parameter to:
UTL_FILE_DIR=D:\Data\FlatFiles\
You can create more than one valid path setting by copying and editing this line, ensuring the copied lines are consecutive:
UTL_FILE_DIR=D:\Data\FlatFiles\ UTL_FILE_DIR=E:\OtherData\
You can bypass this by setting the parameter to:
UTL_FILE_DIR=*
Do not bypass this setting for production databases.
This section describes how to configure the Step Type properties and Runtime Parameters specific to ABAP mappings. The configuration of a PL/SQL mapping from a transparent table in an SAP application is the same as the configuration of any other PL/SQL mapping.
This parameter enables you to choose the type of code you want to generate for your SAP mappings.
To choose the step type:
The Step Type dialog displays.
The following is the list of runtime parameters for SAP mappings and their recommended corresponding values. The default values are recommended for most parameters.
After you have set the Configuration Properties you are ready to validate and generate the scripts that deploy the mapping to the repository. Warehouse Builder generates code that executes the mapping. It can generate the following types of code:
Warehouse Builder selects the language based on the operators and objects you use in your mapping.
You can validate your mapping prior to generating it to check for errors. The validation procedures verify foreign key references, object references, data type matches, and other properties in your mapping. See "Viewing the Generated Code for a Mapping" for information on viewing generated code in the Mapping Editor, and "Validating Definitions and Generating Scripts" for more information on validation and generation from the Module Editor.
To validate a mapping:
The Validation Results dialog displays.
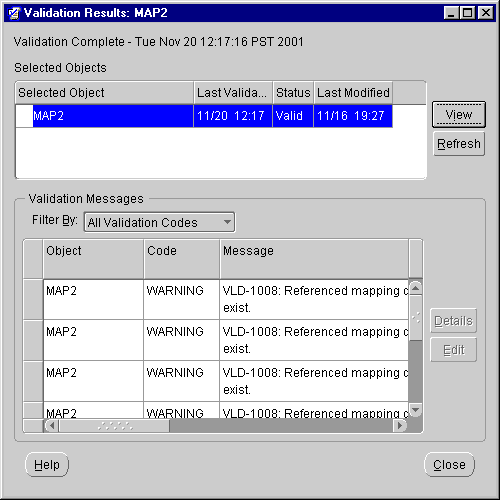
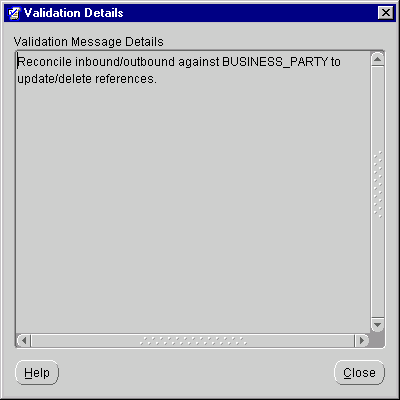
If you have errors, the Validation Details window title bar lists their numbers. The Validation Details window contains suggestions for correcting them. You can open an editor to make these corrections by clicking Edit in the Validation Results Window. See "Validating Definitions" for more information on the Validation Results window.
You can generate the code for a mapping from the:
When you generate a mapping, you are creating the SQL code that performs the DML and DDL commands necessary to move the data from the sources to the targets defined in your mapping. The code generator also validates the mapping before creating the code that implements your ETL design. See "Generating Scripts" for more information on generating scripts.
To generate code from the mapping editor:
Warehouse Builder generates the code for the mapping and displays the Generation Results dialog.
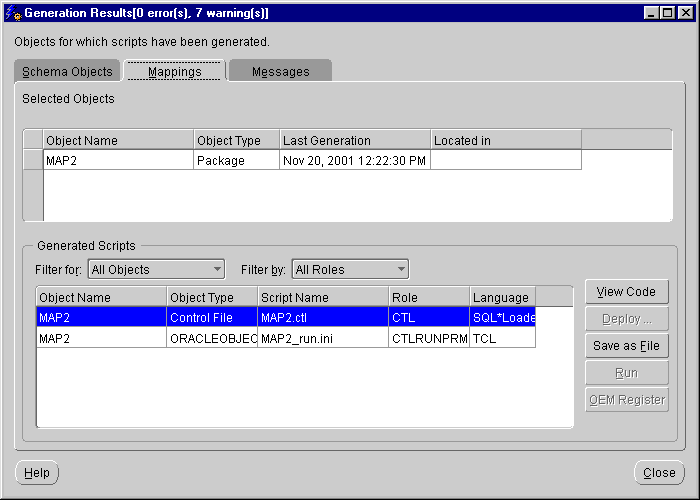
For a Mapping that extracts records from a flat file and loads them as rows into a target table, the generated code results in a SQL*Loader control file. The control file reflects a mapping definition from a flat file to a table source and includes a date stamp.
You can view generated code from the Mapping Editor at any stage of your mapping process. Warehouse Builder validates this code automatically before generating it. See "Validating Definitions and Generating Scripts" for more information on validation and generation from the Module Editor.
You can view the generated code for a mapping from the Mapping Editor as an intermediate result. This type of code generation produces mapping code up to the selected attribute group in the mapping. The Code Viewer displays the code that goes into an input attribute group, the code that goes out of an output attribute group, and the load code is generated for a terminating input group.
These incoming, outgoing, and load types of code are called aspects. You select aspects from the Code Viewer View menu. You can view one aspect at a time. For example, an output attribute group does not contain the input intermediate code result.
You can leave the Code Viewer open and select any attribute group on the mapping canvas. The Code Viewer displays the code generated for the selected attribute group.
To view intermediate results:
You can generate simplified code from the mapping editor showing how data extraction, transformation, and load are performed. The generated code does not include support for auditing or bulk-processing.
The code generator only generates code that handles the loading type specified in the data target operator. For example, if you choose INSERT/UPDATE as the loading type, only INSERT and UPDATE code appears in the generated code.
To generate mapping code:
The generated code contains all possible strategies that can be generated for that mapping. For PL/SQL mappings, a runtime parameter determines which operating mode to use when running the package.
|
|
 Copyright © 1996, 2002 Oracle Corporation. All Rights Reserved. |
|