このトピックでは、Oracle EDQの様々なパフォーマンス・チューニング・オプションに関するガイドを提供します。
EDQでパフォーマンスを最大にするために使用できる、すべてのタイプのプロセスに適用可能な4つの一般的な手法があります。
各手法の詳細は、次の見出しをクリックしてください。
パースおよびマッチ処理の場合、各プロセッサに多数の処理ステージがあるため、個々のプロセッサで大量の作業が実行されます。このような場合は、プロセッサ・レベルでパフォーマンスを最適化するためのオプションを使用できます。
データのパースまたはマッチ処理時にパフォーマンスを最大化する方法の詳細は、次の見出しをクリックしてください。
EDQのデータをストリーミングするオプションを使用すると、データの読取りまたは書込み時に、EDQリポジトリ・データベース内のデータのステージング・タスクを回避できます。
完全にストリーミングされたプロセスまたはジョブはパイプとして機能し、データ・ストアからレコードを直接読み取り、EDQリポジトリにレコードを書き込むことなく、データ・ターゲットにレコードを書き込みます。
プロセスの実行時に、スナップショットの実行を完全にバイパスし、スナップショットを使用せずに、データ・ストアからプロセスに直接データをストリーミングすることをお薦めします。たとえば、プロセスの設計時にデータのスナップショットを使用する場合がありますが、プロセスを本番にデプロイする際には、常にソース・システムの最新のレコード・セットを使用し、ユーザーに対して結果へのドリルダウンを要求しないことがわかっているため、データをリポジトリにコピーするステップを回避する必要がある場合があります。
データをプロセスにストリーミングする(および結果的にEDQリポジトリのデータのステージング・プロセスをバイパスする)には、ジョブを作成し、スナップショットとプロセスの両方をタスクとして追加します。次に、スナップショット・タスクとプロセスの間にあるステージング・データ表をクリックし、無効にします。これで、プロセスによってソース・システムからデータが直接ストリーミングされるようになります。スナップショットの一部として構成された選択パラメータはそのまま適用されることに注意してください。
レコード選択基準(スナップショット・フィルタまたはサンプリング・オプション)は、データのストリーミング時にそのまま適用されることに注意してください。また、ストリーミング・オプションは、スナップショットのデータ・ストアがクライアント側である場合は、サーバーからアクセスできないため使用できないことに注意してください。
ただし、スナップショットのストリーミングは、必ずしも最速または最適なオプションではありません。複数のプロセスを同じデータ・セットで実行する必要がある場合は、ジョブの最初のタスクとしてデータのスナップショットを作成し、次に従属プロセスを実行する方が効率的な場合があります。スナップショット用のソース・システムが稼働中の場合は、ソース・システムへの影響を最小限にするように、通常はスナップショットを個別のタスクとして(その独自のフェーズで)実行する方法が最良です。
データ・ストアへのデータ書込み時に、データをストリーミングすることもできます。この際、ステージング・データ・セットのエクスポートが、ステージング・データ表を書き込むプロセスの後に同じジョブで実行するように構成されている場合、エクスポートでは常に、(レコードがリポジトリ内のステージング・データ表にも書き込まれるかどうかに関係なく)レコードの処理時にレコードが書き込まれるため、パフォーマンスの改善はわずかです。
ただし、データをリポジトリに書き込む必要がないことがわかっている(データを外部にのみ書き込む必要がある)場合は、このステップをバイパスでき、パフォーマンスを多少改善できます。これは、デプロイ済のデータ・クレンジング・プロセスの場合、またはアプリケーション間で共有される外部ステージング・データベースに書き込んでいる場合、たとえば、EDQとETLツール間のデータ受渡しに外部ステージング・データベースを使用して、比較的大規模なETLプロセスの一部としてデータ品質ジョブを実行している場合などです。
エクスポートをストリーミングするには、ジョブを作成して、データを書き込むプロセスをタスクとして追加し、データを外部に書き込むエクスポートを別のタスクとして追加します。次に、プロセスとエクスポート・タスク間にあるステージング・データを無効にします。これは、プロセスによってその出力データが外部ターゲットに直接書き込まれることを意味します。
クライアント側データ・ストアへのエクスポートは、ジョブの一環として実行するタスクとして使用できないことに注意してください。これらは、データ・ストアへの接続にクライアントを使用するため、EDQDirectorクライアントから手動で実行する必要があります。
結果書込みの最小化は、EDQでプロセスからリポジトリに書き込まれる結果ドリルダウン・データの量に関係する、別のタイプのストリーミングです。
EDQの各プロセスは、3つの結果ドリルダウン・モードのいずれかで実行されます。
「All」モードは、すべてのレコードを各処理ポイントで完全に追跡できるように、少量のデータでのみ使用する必要があります。このモードは、小規模なデータ・セットの処理時、または少数のレコードを使用した複雑なプロセスのデバッグ時に有効です。
「Sample」モードは、大量のデータに適しており、各ドリルダウンに対して限定数のレコードが書き込まれるようにします。システム管理者は、ドリルダウンごとに書き込むレコードの数(デフォルトでは1000レコード)を設定できます。「Sample」モードがデフォルトです。
「None」モードは、本番で実行されている、ユーザーが結果と対話する必要のないテスト済プロセスのパフォーマンスを最大化するために使用する必要があります。
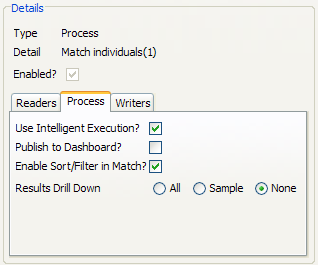
プロセスの実行時に結果ドリルダウン・モードを変更するには、「Process Execution Preferences」画面を使用するか、またはジョブを作成して、プロセス・タスクをクリックしてそれを構成します。
たとえば、次のプロセスは、本番にデプロイされる際に、ドリルダウン結果を書き込まないように変更されます。
大量のデータを処理する際に、ユーザーが結果ブラウザでデータをソートおよびフィルタ処理できるようにスナップショットや書き込まれたステージング・データに索引付けするには、長時間を要する場合があります。多くの場合、このソートおよびフィルタ機能は必要ないか、または比較的少量のデータのサンプルを処理する場合のみ必要となります。
システムによって、インテリジェントなソートおよびフィルタの有効化が適用され、この場合、比較的小規模なデータ・セットの処理時にソートおよびフィルタが有効化され、大規模なデータ・セットの場合はソートおよびフィルタが無効化されます。ただし、これらの設定は上書きでき、たとえば、多数の小規模データ・セットの処理時に最大スループットを実現するためなどに選択できます。
スナップショットが作成される場合、デフォルト設定はインテリジェントなソート/フィルタ・オプションを使用することであるため、システムによって、スナップショットのサイズに基づいてソートおよびフィルタを有効化するかどうかが決定されます。「スナップショットでのソートおよびフィルタの有効化」を参照してください。
ただし、いずれのユーザーも結果ブラウザでスナップショットに基づいた結果をソートまたはフィルタ処理する必要がないことがわかっている場合、またはユーザーが処理を必要とした時点でのみソートまたはフィルタを有効にする場合は、スナップショットの追加または編集時に、スナップショットのソートおよびフィルタを無効にできます。
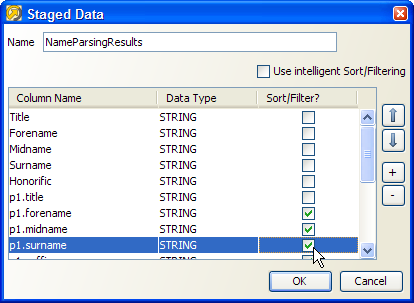
これを実行するには、スナップショットを編集し、3番目の画面(「Column Selection」)で、「Use intelligent Sort/Filtering」オプションの選択を解除し、すべての列の「Sort/Filter」列を選択しないままにします。
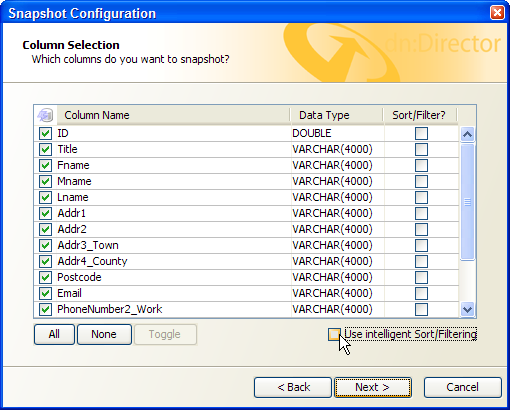
あるいは、ソートおよびフィルタが使用可能な列の一部でのみ必要になることがわかっている場合は、選択ボックスを使用して関連する列を選択します。
ソートおよびフィルタの無効化は、ソートおよびフィルタを有効にする追加のタスクがスキップされるため、スナップショットの合計処理時間が短縮されることを意味します。
ユーザーが、有効化されていない列に基づいて結果をソートまたはフィルタ処理しようとした場合は、その時点でユーザーに対して有効化するためのオプションが提示されます。
ステージング・データがプロセスによって書き込まれる際に、サーバーは、デフォルトでデータのソートまたはフィルタを有効化しません。したがって、デフォルトの設定は、パフォーマンスに関しては最大化されています。
書き込まれたステージング・データでソートまたはフィルタを有効にする必要がある場合(たとえば、書き込まれたステージング・データが、対話型のデータ・ドリルダウンを必要とする別のプロセスによって読み取られるために有効にする必要がある場合)、これを有効にするには、ステージング・データ定義を編集して、インテリジェントなソート/フィルタ・オプションを適用するか(ソートおよびフィルタを有効にするかどうかはステージング・データ表のサイズに基づいて変わります)、または選択した列でオプションを有効にします(後述の説明を参照)。
マッチ処理の出力に対してソート/フィルタ有効化オプションを設定できます。「マッチ処理のパフォーマンス・オプション」を参照してください。
EDQサーバーは、最適なパフォーマンスを得るためには構成する必要があります。
Windowsサーバー・インストールの場合、EDQインストーラによって、インストールされたサーバーの仕様に従って、多数のパフォーマンス設定が自動的に設定されます。ただし、その他のプラットフォームの場合、設定を手動で変更する必要がある場合があります。
サーバー構成を変更するのは、管理者のみにする必要があることに注意してください。サーバー構成を変更するかどうか確定できない場合は、サポートに連絡してください。
パフォーマンスに関しては、2つの構成オプションが特に重要です。
Windowsサーバー・インストールの場合、ジョブの実行に使用されるプロセス・スレッド数は、インストーラによって使用可能なCPU数に自動的に設定されるため、変更する必要はありません。ただし、他のプラットフォーム(UnixまたはLinux)の場合、EDQがインストールされる構成ディレクトリ内のoverride.propertiesファイルに次の行を追加する必要があります。
processengine.processThreads = [number of threads]
Windowsに関しては、スレッド数をサーバーのCPU数に設定することをお薦めします。
大量の結果をEDQ結果リポジトリに書き込む必要がある場合は、EDQを特にプロファイリング、分析およびマッチ処理に使用する場合が典型的であるように、リポジトリに使用されるデータベースのタイプがパフォーマンスに対して非常に重要になります。
デフォルトのEDQリポジトリは、EDQ用に構成されたPostgreSQLデータベースです。
ただし、非常に大量のデータの場合、Oracleデータベース(バージョン10iまたは11i)を使用すると、リポジトリに対する読取りおよび書込み時にパフォーマンスが大幅に改善します。
リポジトリ・データベースのタイプを変更するには、EDQ起動パッドに移動し、「Configuration」を選択して、次に「Database Setup」を選択します。管理権限のあるEDQユーザーとしてログインする必要があります。
次に、EDQで使用される2つのデータベースである、Directorデータベース(プロジェクト構成データの格納に使用)と結果データベース(結果データの格納に使用)を変更できます。結果データベースはリポジトリ・データベースです。
たとえば、次のスクリーンショットは、Directorデータベースと結果データベースをOracleデータベースを使用するように変更する処理を示しています。
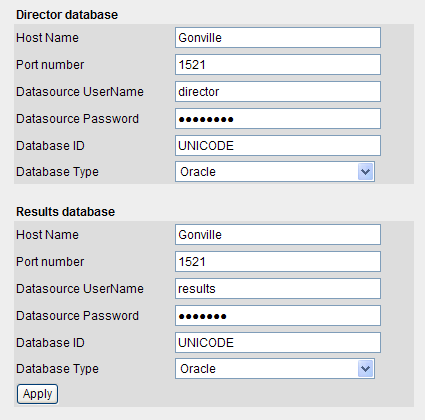
サーバーはEDQが実行されるアプリケーション・サーバーから離れていてもかまいませんが、高速ネットワーク接続上に存在する必要があることに注意してください。
パース・プロセッサから最大パフォーマンスが要求される場合は、「Parse and Profile」モードではなく、「Parse」モードで実行する必要があります。
これは、完全に構成された、分類済および未分類のトークンをパース出力で調査する必要のないパース・プロセッサに特に該当します。
パース・プロセッサからメトリックおよびデータ出力のみが要求される場合のパフォーマンスをさらに改善するために、パーサーを含むプロセスをドリルダウンなしで実行できます。前述の「結果書込みの最小化」を参照してください。
パース構成を繰返し設計する際に高速ドリルダウンが必要な場合、通常は少量のデータの処理が最善です。大量のデータを処理する場合は、Oracle結果リポジトリによってドリルダウン・パフォーマンスが大幅に改善します。
マッチ処理のパフォーマンスを最大化するために次の手法を使用できます。
マッチ処理のパフォーマンスは、マッチ・プロセッサの構成に応じて大きく変わる場合があり、マッチ・プロセッサの構成は、マッチ・プロセスに関係するデータの特性に依存します。正しく処理するための構成の最も重要な面は、マッチ・プロセッサにおけるクラスタリングの構成です。
通常、できるかぎり多くのマッチ候補が検出されるようにすることと、冗長な比較(マッチする確率の低いレコード間の比較)が実行されないようにすることの双方を両立させます。適切に両立させるには、多少の試行と誤りを伴う場合があり、たとえば、クラスタの範囲拡張時(おそらくクラスタ・キーに使用する識別子の文字数を減らす)または縮小時(おそらくクラスタ・キーに使用する識別子の文字数を増やす)、あるいはクラスタの追加または削除時のマッチ統計の差異の評価などがあります。
次の2つの一般的なガイドラインが有効な場合があります。
クラスタリングの動作方法およびデータに対する構成を最適化する方法の詳細は、「クラスタリングの概念ガイド」を参照してください。
デフォルトでは、ソート、フィルタおよび検索は、ユーザー・レビューに使用できるようにすべてのマッチ結果で有効化されます。ただし、大規模なデータ・セットでは、ソート、フィルタおよび検索の有効化に必要な索引付けプロセスに非常に時間を要する可能性があり、索引付けが必要のない場合もあります。
レビュー・アプリケーションを使用してマッチ処理の結果をレビューする機能が必要なく、結果ブラウザでマッチ処理の出力をソートまたはフィルタ処理できる必要がない場合は、パフォーマンスを改善するためにソートおよびフィルタを無効にする必要があります。たとえば、マッチ処理の結果が外部に書き込まれ、レビューされる場合、または本番にデプロイされる際にマッチ処理が完全に自動化される場合があります。
ソートおよびフィルタを有効または無効にする設定は、プロセッサの「Advanced Options」から使用可能な個別のマッチ・プロセッサ・レベル上(詳細は、「マッチ・プロセッサのソート/フィルタ・オプション」を参照)、およびプロセスまたはジョブ・レベルの上書きとしての両方で使用できます。
プロセス内のすべてのマッチ・プロセッサに関する個別の設定を上書きし、マッチ結果のソート、フィルタおよびレビューを無効にするには、ジョブ構成、またはプロセス実行プリファレンスで、「Enable Sort/Filter in Match processors」オプションの選択を解除します。

マッチ・プロセッサは、出力を3タイプまで書き出すことができます。
デフォルトでは、使用可能なすべての出力タイプが書き込まれます。(マージ済出力は、「Link」プロセッサから書き込むことはできません。)
ただし、使用可能なすべての出力がプロセスで必要なわけではありません。たとえば、マッチ・レコードのセットのみを識別する場合は、マージ済出力を無効にする必要があります。
いずれかの出力を無効にしても、マッチ・プロセッサの結果をレビューするユーザーの機能には影響を与えないことに注意してください。
マッチ(またはアラート)・グループの出力を無効にする手順は、次のとおりです。
あるいは、関連または非関連レコードのグループのみを出力することがわかっている場合は、画面の同じ部分にある他の選択ボックスを使用します。
関係出力を無効にする手順は、次のとおりです。
あるいは、一部の関係のみを出力することがわかっている場合(レビュー関係のみ、または特定のルールによって生成された関係のみなど)は、画面の同じ部分にある他の選択ボックスを使用します。
マージ済出力を無効にする手順は、次のとおりです。
あるいは、関連レコードまたは非関連レコードのみからマージ済出力レコードのみを出力することがわかっている場合は、画面の同じ部分にある他の選択ボックスを使用します。
バッチのマッチ・プロセスでは、レコードを効率的に比較するために、EDQリポジトリ内のデータのコピーが必要です。
データは、リーダーとプロセス内のマッチ・プロセッサ間で変換される場合があるため、およびマッチ・プロセスで使用されたスナップショットがリフレッシュされた場合にマッチ結果をレビューする機能を保持するために、マッチ・プロセッサによって常に、作業元のデータ(リアルタイム入力からのデータを除く。「リアルタイム・マッチ」を参照)の独自のスナップショットが生成されます。大規模データ・セットの場合、これには多少時間を要する場合があります。
マッチ・プロセスで最新のソース・データを使用する場合は、スナップショットを最初に実行して、その後でマッチ・プロセッサにデータをフィードするかわりに、スナップショットをストリーミングすることをお薦めします。これによって、独自の内部スナップショットが生成されます(データを2回効率的にコピー)。前述の「スナップショットのストリーミング」を参照してください。
Oracle (R) Enterprise Data Qualityオンライン・ヘルプ バージョン8.1
Copyright (C) 2006,2011 Oracle and/or its affiliates.All rights reserved.