Introduction to BEA AquaLogic Service Registry Locate
BEA AquaLogic Service Registry is a fully V3-compliant implementation of UDDI (Universal Description, Discovery and Integration), and is a key component of a Service Oriented Architecture (SOA). A UDDI registry provides a standards-based foundation infrastructure for locating services, invoking services and managing metadata about services (security, transport or quality of service). The UDDI registry can store and provide these metadata using arbitrary categorizations. These categorizations are called taxonomies.
This introduction has the following sections:
UDDI's Role in Web Services World - UDDI Benefits Locate
When development teams start to build Web services interfaces into their applications, they face such issues as code reuse, ongoing maintenance, and documentation. The need to manage these services can increase rapidly.
The UDDI registry can help to address these issues and provides the following benefits:
It delivers visibility when identifying which services within the organization can be reused to address a business need.
It promotes reuse and prevents reinvention. It accelerates development time and improves productivity. This ability of UDDI to categorize a growing portfolio of services makes it easier to manage them. It helps to understand relationships among components, supports versioning, and manages dependencies.
It supports services' configurability and adaptability by using the service-oriented architectural principle of location and transport independence. Users can dynamically discover services stored in the UDDI registry.
It allows you to understand and manage relationships among services, component versioning, and dependencies.
It makes it possible to manage the business service life cycle. For example, the process of moving services through each phase of development, from coding to public deployment. For more information, see the Approval Process.
Typical Application of a UDDI Registry Locate
A UDDI registry stores data and metadata about business services. A UDDI registry offers a standards-based mechanism to classify, catalog and manage Web services so that they can be discovered and consumed by other applications. As part of a generalized strategy of indirection among services-based applications, UDDI offers several benefits to IT managers as both design-time and run-time, including increasing code reuse and improving infrastructure management by:
Publishing information about Web services and categorization rules (taxonomies) specific to an organization.
Finding Web services that meet given criteria.
Determining the security and transport protocols supported by a given Web service and the parameters necessary to invoke the service.
Providing a means to insulate applications (and providing fail-over and intelligent routing) from failures or changes in invoked services.
Basic Concepts of the UDDI Specification Locate
UDDI is based upon several established industry standards, including HTTP, XML, XML Schema (XSD), SOAP, and WSDL. The latest version of the UDDI specification is available at: http://www.oasis-open.org/committees/uddi-spec/doc/tcspecs.htm#uddiv3.
The UDDI specification describes a registry of Web services and its programmatic interfaces. UDDI itself is a set of Web services. The UDDI specification defines services that support the description and discovery of:
Businesses, organizations and other Web services providers
The Web services they make available
The technical interfaces which may be used to access and manage those services.
UDDI Data Model Locate
The basic information model and interaction framework of UDDI registries consist of the following data structures:
A description of a service business function is represented as a businessService.
Information about a provider that publishes the service is put into a businessEntity.
The service's technical details, including a reference to the service's programmatic interface or API, is stored in a bindingTemplate.
Various other attributes, or metadata, such as taxonomy, transports, and policies, are stored in tModels.
These UDDI data structures are expressed in XML and are stored persistently by a UDDI registry. Within a UDDI registry, each core data structure is assigned a unique identifier according to a standard scheme. This identifier is referred as a UDDI key.
Business Entity Locate
A business entity represents an organization or group of people responsible for a set of services (a service provider). It can also represent anything that overreaches a set of services; for example a development project, department or organization. The business entity structure contains the following elements:
Names and Descriptions. The business entity can have a set of names and descriptions, in a variety of languages if necessary.
Contacts. The list of people who are associated with the business entity. A contact can include, for example, a contact name, addresses, phone numbers, and use type.
Categories. Set of categories that represent the business entity's features or quantities. For example the business entity can be associated with the category California to say that the business entity is located in that geographical area.
Identifiers. The business entity can be associated with arbitrary number of identifiers that uniquely identify it. For example, the business entity can be identified by a department number or D-U-N-S number.
Discovery URLs are additional links to documents describing the business entity.
Business entities can be linked to one another using so-called assertions that model a relationships between them.
Business Service Locate
Business services represent functionality or resources provided by business entities. A business entity can reference multiple business services. A business service is described by the following elements:
Names and descriptions. The business service can have a set of names and descriptions, in a variety of languages if necessary.
Categories. A set of categories that represent the business service features and quantities. For example, the business service can be associated by a category that represents service availability, version, etc.
A business service in a UDDI registry does not necessarily represent a Web service. The UDDI registry can register arbitrary services such as example EJB, CORBA, etc.
Binding Template Locate
A business service can contain one or more binding templates. A binding template represents the technical details of how to invoke its service. Binding templates are described by the following elements:
Access point represents the service endpoint. It contains endpoint URI and specification of the protocol.
tModel instance infos can be used to represent any other information about the binding template
Categories. The binding template can be associated with categories to reference specific features of the binding template, for example certification status (test, production) or versions.
tModel Locate
The tModel provides a reference to an abstraction describing compliance with a specification and concepts. TModels are described by the following elements:
Name and description. The tModel can have a set of names and descriptions, in different languages if required.
An overview document is a reference to a document that specifies the tModel's purpose.
Categories. Like all the other UDDI entities, tModels can be categorized.
Identifiers. The tModel can be associated with an arbitrary number of identifiers that uniquely identify it.
UDDI entities are categorized through tModels via taxonomies. Business entities, business services, and binding templates declare associations to a certain category by presence of specific tModels in their categoryBags.
Taxonomic Classifications Locate
UDDI provides a foundation and best practices that help provide semantic structure to the information about Web services contained in a registry. UDDI allows users to define multiple taxonomies that can be used in a registry. Users can employ an unlimited number of appropriate classification systems simultaneously. UDDI also defines a consistent way for a publisher to add new classification schemes to their registrations.
Taxonomies are used for representing various UDDI entity features and qualities (such as product types, geographical regions or departments in a company).
The UDDI specification mandates several standard taxonomies that must be shipped with each UDDI registry product. Some are internal UDDI taxonomies such as the UDDI types taxonomy or geographical taxonomy. A taxonomy can be marked as specific to business, service, binding template or tModel or it can be used with any type of the UDDI entity
Enterprise Taxonomies Locate
Enterprise taxonomies are taxonomies that are specific to the particular enterprise or application. These taxonomies reflect specific categories like company departments, types of applications, and access protocols.
BEA AquaLogic Service Registry allows definition of enterprise taxonomies. Users can also download and upload any taxonomy as an XML file. BEA AquaLogic Service Registry offers tools for creating, modifying and browsing taxonomies on both the web user interface and SOAP API levels.
Checked and Unchecked Taxonomies Locate
There are two types of taxonomies: checked and unchecked. Checked taxonomies are rigid, meaning that the UDDI registry does not allow the use of any categories other than those predefined in the taxonomy. Checked taxonomies are usually used when the taxonomy author can enumerate all distinct values within the taxonomy. A checked taxonomy can be validated using the internal validation service that is available in BEA AquaLogic Service Registry or by using an external validation service.
Unchecked taxonomies do not prescribe any set of fixed values and any name and value pair can be used for categorization of UDDI entities. Unchecked taxonomies are used for things like volume, weight, price, etc. A special case of the unchecked taxonomy is the general_keywords taxonomy that allows categorizations using arbitrary keywords.
Security Considerations Locate
UDDI specification does not define an access control mechanism. The UDDI specification allows modification of the specific entity only by its owner (creator). This does not scale in the enterprise environment where the right to modify or delete a specific UDDI entity must be assigned with more identities or even better with some role.
BEA AquaLogic Service Registry addresses this issue with the ACL (Access Control List) extension to the UDDI security model. Every UDDI entity can be associated with the ACL that defines who can find (list it in some UDDI query result), get (retrieve all details of the UDDI object), modify or delete it. The ACL can reference either the specific user account or user group.
The UDDI v3 specification provides support for digital signatures. In BEA AquaLogic Service Registry, the publisher of a UDDI structure can digitally sign that structure. The digital signature can be validated to verify the information is unmodified by any means and confirm the publisher's identity.
Notification and Subscription Locate
The UDDI v3 specification introduces notification and subscription features. Any UDDI registry user can subscribe to a set of UDDI entities and monitor their creation, modification and deletion. The subscription is defined using standard UDDI get or find API calls. The UDDI registry notifies the user whenever any entity that matches the subscription query changes even if the change causes the entity to not match the query anymore. It also notifies about entities that were changed in a way that after the change they match the subscription query.
The notification might be synchronous or asynchronous. By synchronous, we mean solicited notification when the interested party explicitly asks for all changes that have happened since the last notification. Asynchronous notifications are run periodically in a configurable interval and the interested party is notified whenever the matched entity is created, modified, or deleted.
Replication Locate
Content of the UDDI registry can be replicated using the simple master-slave model. The UDDI registry can replicate data according to multiple replication definitions that are defined using UDDI standard queries. The master-slave relationship is specific to the replication definition. So one registry might be master for one specific replication definition and slave for another. The security settings (ACL, users, and groups) are not subject to replication but you can set permissions on replicated data.
UDDI APIs Locate
The core data management tools functions of a UDDI registry are:
Publishing information about a service to a registry.
Searching a UDDI registry for information about a service.
The UDDI specification also includes concepts of:
Replicating and transferring custody of data about a service.
Registration key generation and management.
Registration subscription API set.
Security and authorization.
The UDDI specification divides these functions into Node API sets that are supported by a UDDI server and Client API Sets that are supported by a UDDI client .
Technical Notes Locate
Technical Notes (TN) are non-normative documents accompanying the UDDI Specification that provide guidance on how to use UDDI registries. Technical Notes can be found at http://www.oasis-open.org/committees/uddi-spec/doc/tns.htm. One of the most important TNs is "Using WSDL in a UDDI Registry".
Benefits of UDDI Version 3 Locate
The most important features include:
User-friendly identifiers facilitate reuse of service descriptions among registries.
Support for digital signatures allows UDDI to deliver a higher degree of data integrity and authenticity.
Extended discovery features can combine previous, multi-step queries into a single-step, complex query. UDDI now also provides the ability to nest sub-queries within a single query, letting clients narrow their searches much more efficiently.
Subscriptions in BEA AquaLogic Service Registry Locate
Subscriptions are used to alert interested users in changes made to structures in BEA AquaLogic Service Registry. The BEA AquaLogic Service Registry Subscription API provides users the ability to manage (save and delete) subscriptions and evaluate notification. Notifications are lists of changes made within a specified time interval. The Subscription mechanism allows the user to monitor new, changed, and deleted entries for businessEntities, businessServices, bindingTemplates, tModels or publisherAssertions. The set of entities in which a user is interested is expressed by a SubscriptionFilter, which can be any one of the following UDDI v3 API queries:
find_business, find_relatedBusinesses, find_services, find_bindings, find_tmodel
get_businessDetail, get_serviceDetail, get_bindingDetail, get_tModelDetail, get_assertionStatusReport
![[Note]](../images/note.gif) | Note |
|---|---|
In Business Service Console, users can also create subscriptions also resources (WSDL, XML, XSD and XSLT) without a detailed knowledge of how resources are mapped to UDDI data structures. | |
Subscription Arguments Locate
A subscription is the subscriber's interest in changes made to entities as defined by the following arguments:
SubscriptionKey - The identifier of the subscription, as generated by the server when the subscription is registered.
Subscription Filter - Specifies the set of entities in which the user is interested. This field is required. Note that once the subscription filter is set, it cannot be changed.
Expires After - The time after which the subscription is invalid (optional).
Notification Interval - How often the client will be notified (optional). The server can extend it to the minimum supported notification interval supported by the server as configured by the administrator.
For more information, please see Administrator's Guide, Registry Configuration.
Max Entities - how many entities can be listed in a notification (optional). When the number of entities in a notification exceeds max entities, the notification will contain only the number of entities specified here or in the registry configuration. A chunkToken different from "0" will be specified in the notification. This chunkToken can be used to retrieve trailing entities.
BindingKey - points to the bindingTemplate that includes the endpoint of the notification handling service (optional). Only http and mail transports are currently supported. If this bindingKey is not specified, the notification can be retrieved only by synchronous calls.
Brief - By default, notifications contain results corresponding to the type of the Subscription Filter. For example, when the subscription filter is find_business, notifications contain Business Entities in the businessInfos form. If brief is toggled on, notifications will contain only the keys of entities. (optional)
Subscription Notification Locate
Notification is the mechanism by which subscribers learn about changes. Notifications inform subscribers about entities that:
Satisfy the Subscription Filter now and were last changed, or created, within a given time period. The entities are included in a list of the appropriate data type by default. For example, when find_business represents the Subscription Filter, notifications contain Business Entities in the businessList/businessInfo form. (If the brief switch is toggled on, only the entity keys in the keyBag are included.)
Were changed or deleted in the given time period and no longer satisfy the Subscription Filter. Only the keys of the appropriate entities are included in the keyBag structure and the deleted flag is toggled on.
There are two types of notifications:
Asynchronous notification - Using asynchronous notification, the server periodically checks for changes and offers them to the client via HTTP or SMTP. HTTP is suitable for services listening to UDDI changes. SMTP (that is, mail notification) is suitable for both services and users. With this transport, the user is notified at each notification interval by email. To perform asynchronous notification, the subscription must be populated with notification interval and bindingKey. See Developer's Guide, Writing a Subscription Notification Service for details.
Synchronous notification - Using synchronous notification, the server checks for changes and offers them when the client explicitly asks for them outside of periodical asynchronous notifications. It is useful for client applications which cannot listen for notifications, and for services that want to manage the time of notification by themselves. See Demos, Subscription for details.
XSLT Over Notification Locate
To improve the readability of notifications sent to users via email, BEA AquaLogic Service Registry provides the ability to process the XSL transformation before the notification is sent. To enable this feature:
Register the XSL transformation in UDDI as a tModel that refers to XSL transformation in its first overviewDoc.
Modify the bindingTemplate (with the bindingKey specified in the subscription) to refer to the XSLT tModel by its tModelInstanceInfo.
Tag the XSLT tModel by a keyedReference to uddi:uddi.org:resource:type with the keyValue="xslt".
Suppressing Empty Notifications Locate
Another BEA AquaLogic Service Registry extension to the specification is the ability to suppress empty notifications. To do this, tag the bindingTemplate referenced from the subscription with a keyedReference to the tModel uddi:uddi.org:categorization:general_keywords with keyValue="suppressEmptyNotification" and keyName="suppressEmptyNotification".
Related Links Locate
To manage subscriptions via the Business Service Console, see the section Business Service Console Subscriptions.
To manage subscriptions via the Registry Console, see the Registry Console Reference.
To use and manage subscriptions, see the Subscription API.
More details about subscriptions can be found in the Subscription API chapter of the UDDI v3 Specification.
Approval Process in BEA AquaLogic Service Registry Locate
The approval process provides functionality to ensure consistency and quality of data stored in BEA AquaLogic Service Registry. There are two types of Registries in the approval process: a publication registry and a discovery registry. The publication registry is used for testing and verification of data. The discovery registry is under full control of approvers. It means the discovery registry contains only data that has been promoted from the publication registry.
The approval process includes two types of users: A requestor is a user of the publication registry who can ask for the approval of data for promotion. Every user can ask for approval, but to have data considered for promotion, a user must have an administrator-assigned approver. The approver is a user or group given the ability to review published information on the publication registry and grant or deny approval to promote that information to the discovery registry. If the approver is a group then any of its members may approve or reject approval requests.
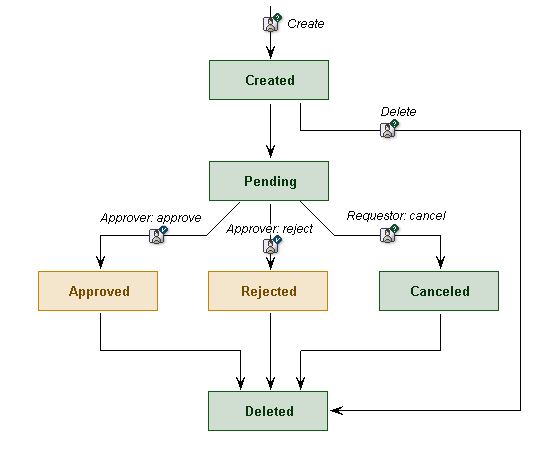
Approval requests have a lifecycle shown in Figure 1. A requestor can create a request. Once the request is created, the requestor can add UDDI data structures (described in UDDI Data Model) or resources (WSDL, XML, XSD and XSLT) to the request. Note that the requestor does not need to know how resources are mapped to UDDI data structures. When the requestor adds a resource to the request, all underlying UDDI structures (bindings, tModels) the resource represents are added automatically to the request. Once the requestor specifies all entities to promote, the request may be submitted for approval.
The approver will review incoming requests, and then can approve or reject the request. If the approver approves the request, the requested data is immediately promoted the discovery registry. If the requestor is not satisfied with the approver's response time, this user can remind the approver to review the requests. The requestor can also cancel submitted requests.
In the next sections, we will look at requestor's and approver's actions in detail.
Requestor's Actions Locate
The requestor may perform the following actions:
Submit a request for data promotion for approval
After submitting the request, all data referenced in the request is blocked (locked for writing) until the request is either canceled by the requestor, approved for promotion, or rejected by the approver.
Note A requestor may request approval for the promotion of the same set of data several times, and may have several unprocessed requests at one time.
Find request.
This action provides the requestor the ability to list information about all requests. If the requestor has privileged access on the Requestor API, then it is possible to get brief information on the requests of other users. Otherwise only the requestor's own requests may be viewed.
Get request
This action returns full information about the given request. If the requestor has privileged access on the Requestor API then full information about the requests of other requestors may be obtained. Otherwise only the requestor's own requests may be accessed.
Cancel request
Provides requestor the ability to cancel the given request. Only requestors with privileged access can cancel the requests of other requestors.
Synchronize data
This action enables the requestor to synchronize data on the publication registry with data on the discovery registry. There are three types of synchronization - publication priority, partial discovery priority, and full discovery priority. For detailed information about synchronization, please see Synchronization of Data.
To publish data to the discovery registry, the data must first be published to the publication registry and then approved by any appropriate approver. Once the requestor is satisfied with the quality of data, it is possible to ask for data promotion.
Requestors can publish data on the publication registry for testing. Once this data is ready for approval, the requestor asks for approval. An approval request contains two different sets of keys - keys for saving and keys for deletion. The data is specified by the keys. Keys for saving are used for entities to be published (saved or updated) into the discovery registry. Keys for deletion can be used for deletion of any entity from the discovery registry. Approval requests can contain data (entities' keys) either for saving or for deletion.
Both types of keys can contain keys for businessEntities, businessServices, bindingTemplates, tModels or publisherAssertions. For example, if a requestor wants to promote a businessEntity to the discovery registry and remove a bindingTemplate from a service on the discovery registry then the request for approval must contain the key of businessEntity in the keys for saving and the key of the bindingTemplate in the keys for deletion. After successful approval the business entity is saved (created or updated) to the discovery registry and the binding template is deleted from the discovery registry.
Context Checking Locate
During a request for approval, and when approval is granted, automatic context checking is processed to ensure the integrity of data from a request. The context checker has the following rules:
If an entity is contained in keys for saving, then the parent entity must already exist on the discovery registry or be contained in keys for saving to the discovery registry. For a businessService, the parent is businessEntity; for a bindingTemplate, the parent is businessService.
Any entity referenced by entities whose keys are in keys for saving may not be contained in keys for deletion.
Entities whose keys are contained in keys for deletion must exist on the discovery registry.
Deleting a tModel that is referenced by entities on the discovery registry is not allowed.
If a publisher assertion is included in keys for saving, then its business entities (specified in fromKey, toKey) and tModel must already exist on the discovery registry or be contained in keys for saving.
If the data is valid, according to these rules, the request for approval is made.
If data is invalid (for example, an entity is included in keys for deletion that does not exist on the discovery registry), an exception is thrown and the request for approval is not made.
If context checking fails, the requestor is informed that the data must somehow be changed before requesting approval again.
A Special Approval Case Locate
If the registry administrator trusts a requestor, that requestor may be assigned the approval contact AutoApprover. Under this approval contact, there is no human review of the data. The data is automatically promoted to the discovery registry as long as automatic context checking is successful.
Approver's Actions Locate
Approval contacts are assigned by users who have permission to set up the approval process via the ApprovalConfiguration API (such as registry administrator) to review and approve data published by requestors. The approval contact reviews requests to promote data to the discovery server and approves or rejects these requests.
If enabled, content checking (additional rules applied to approved data) is performed at this time as well.
If context checking and content checking are successful, an email is sent to the requestor indicating the successful promotion of data, and any message entered in the Message for requestor box.
Optional Content Checking Locate
Optional content checking provides an approver the ability to programmatically check data for approval. For example, the approver can set a policy that:
Each business service must include a binding template, or
Each business service must be categorized by specified categories
To enforce such a policy, a developer can write an implementation of the Checker API to ensure these checks. The implementation is called automatically during the approval process when an approver presses the Approve request button. The approver, therefore, does not have to check it manually. For more information on setting up optional content checking, see Optional Content Checking Setup in the Administrator's Guide.
Synchronization of Data Locate
Requestor's synchronization is used to synchronize the information on the publication and discovery registries. There are three different kinds of synchronization described below - publication priority, partial discovery priority and full discovery priority. Each is performed on all data structures associated with the synchronizing user's account. Synchronization is performed only upon request.
| Note |
|---|---|
These tools do not change information on the discovery registry. The only way to change data on discovery registry is via the publication registry and the approval process. Only administrator can publish into discovery registry. | |
Publication priority Locate
Publication priority has the following rules:
If an entity exists only on the discovery registry then it is copied from the discovery registry to the publication registry.
If an entity exists only on the publication registry, then it is preserved.
If an entity exists on both registries, then the publication registry takes priority over the discovery registry.
Publication Priority Example Locate
Before synchronization, structures A and X exist on the publication registry and structures X and B exist on the discovery registry.
The Publication Priority synchronization copies structure B to the publication registry. Structure X on publication registry remains the same because when the same entity exists on both servers, Publication Priority synchronization favors the publication registry.
Partial Discovery Priority Locate
Partial discovery priority has the following rules:
If an entity exists only on the discovery registry, then it is copied from the discovery registry to the publication registry.
If an entity exists only on publication registry, then the entity is preserved.
If an entity exists on both registries, then data on the publication registry is overwritten by data from the discovery registry.
Partial Discovery Example Locate
Before this synchronization, structures A and X exist on the publication registry and structures X and B exist on the discovery registry.
The partial discovery synchronization copies structure B to the publication registry and overwrites the version of structure X on the publication registry with that from the discovery registry.
Full Discovery Priority Locate
Under this synchronization scenario, all the user's data on the publication registry is deleted, and all the user's data from discovery registry is copied to the publication registry. After the full discovery priority synchronization, data on the discovery and publication registry is identical.
![[Important]](../images/important.gif) | Important |
|---|---|
The BEA AquaLogic Service Registry Administrator cannot execute full discovery priority synchronization. | |
Full Discovery Example Locate
Before synchronizing, structures A, X, Y, and B exist on the publication registry and structures A, X, and B exist on the discovery registry.
Full discovery synchronization deletes structures A, X, Y, and B from the publication registry, and replaces them with A, X, and B from the discovery registry.
Related Links Locate
Installation of publication and discovery registries - Installation Guide, Approval Process Registry Installation
Approval process via Business Service Console - User's Guide, Approval Process
Configure requestors and approvers - Administrator's Guide, Approval Process Management