| Solstice Enterprise Manager 4.1 Customizing Guide |
Building Templates for SunNet Manager Event Requests
Solstice Enterprise Manager (Solstice EM) is shipped with a suite of agents developed for the Site/SunNet/Domain Manager (SNM) network management system. These agents communicate with a network manager, such as Solstice EM, using Remote Procedure Call (RPC) protocol within an Internet (TCP/IP) network environment.
This chapter describes the following topics:
- Section 17.1 RPC Agents
- Section 17.2 Nerve Center's SNM Event Request Capability
- Section 17.3 SNM Alarms
- Section 17.4 Building SNM Event Request Templates
17.1 RPC Agents
These RPC agents have the ability to poll managed resources to check for predefined thresholds and send an event notification, called an SNM event, to a specified management station. This polling activity is initiated by a one-shot message from a management station, called an SNM event request. The SNM event request defines the threshold and polling interval for the agent's polling activity. The agent thus acts as a proxy for the manager. Polling activity is offloaded from the management station to the RPC proxy agents, which may be distributed to various sites around your network. For example, a certain machine (either a PC running Solaris for x86 or a SPARC workstation running SunOs 4.x or Solaris 2.x), called a proxy host, may contain the proxy agents for polling of resources in a particular subnet.
The Solstice EM Nerve Center has the ability to initiate SNM event requests. This enables Solstice EM to offload the polling of the managed resource from the MIS. If the threshold defined in the event request obtains on the managed resource, the RPC agent sends an SNM event to the SNM Event Dispatcher (na.event) (by default, this is sent to the management station that initiated the request). This information is forwarded to the Solstice EM MIS by Solstice EM's SNM Event Forwarder (em_snmfwd).
As illustrated in the following figure, RPC proxy agents use Remote Procedure Call (RPC) protocol (over IP) to communicate with the Solstice EM MIS. However, an RPC proxy agent may use a different management protocol in gathering information from other agents. In the example in the following figure, SNM's Simple Network Management Protocol (SNMP) proxy agent (na.snmp) is used to manage devices that support the SNMP protocol.
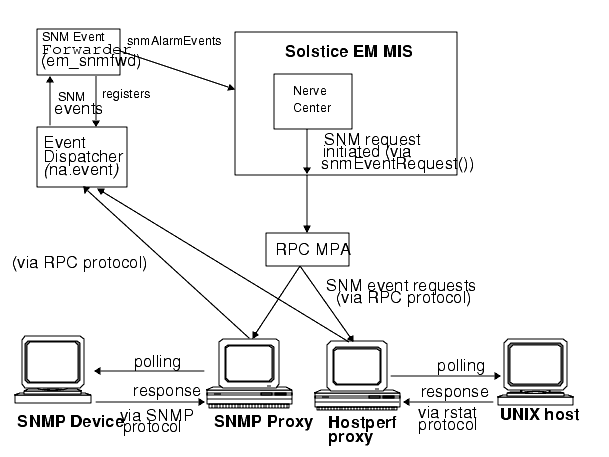
FIGURE 17-1 Using SNM Event Requests with Solstice EMFor information on the installation of RPC proxy agents, refer to Chapter 6 in Installation Guide.
Note – SNM events that are received by SunNet Manager Consoles managing segments of your network can also be forwarded to the Solstice EM MIS using Cooperative Consoles. This type of distributed management scenario is described in Chapter 7.
For general information on using SunNet Manager RPC agents with Solstice EM, see Chapter 6.
17.2 Nerve Center's SNM Event Request Capability
The Nerve Center module in the MIS contains the request-handling capabilities of Solstice EM. Nerve Center requests are based on request templates, which are built using the Design Advanced Requests application. A key building block in request templates are request conditions -- sets of instructions defined using the Solstice EM Request Condition Language (RCL). RCL provides two built-in functions, snmEventRequest() and snmKillRequest(), for starting and stopping SNM event requests. For general guidance in building request templates, read Chapter 15. For information on the RCL functions, see Chapter 22.
SNM event requests can be launched from the Solstice EM management station using the request-handling capabilities of the Solstice EM Nerve Center. Request templates built using the Solstice EM Request Condition Language (RCL) can initiate SNM event requests via the RCL snmEventRequest() function. When SNM event requests are launched at target managed objects, the Nerve Center communicates the request to the appropriate SNM agent or proxy through the RPC Protocol Driver Module (PDM) in the MIS.
When the snmEventRequest() function initiates a request, the following information is passed to the target SNM agent or proxy:
- The agent attribute--for example, the mempct attribute, supported by the hostmem agent, reports the percentage of network memory in use on a machine running SunOS 4.x. A request might use this attribute to generate an SNM event if the network memory usage on a router is greater than 80%.
- The agent attribute group--for example, the load_stats group, supported by the cpustat agent, reports load statistics for a particular CPU in a multi-processor machine.
- The relation is used to define the threshold--relations such as Equal To, Greater Than, Not Equal To, can be used to define situations that generate SNM events if they occur.
- The threshold value to test for--for example, if the threshold value is 1 and the relation is Not Equal To, then Not Equal To 1 is the threshold that will generate an SNM event if it occurs for the specified attribute.
- The SNM priority of an alarm generated if the threshold obtains--the possible priorities for SNM events are High, Medium, or Low. These correspond to perceivedSeverity values of Solstice EM alarms as indicated in TABLE 17-1.
- Polling interval (in seconds)--the delay between polls of the target object by the SNM agent or proxy.
- The number of times the device is polled before terminating the request--this can be unlimited, or a finite number of polls can be specified. (The number 0 is used to indicate that polling should continue indefinitely.)
- A specific resource to target within the agent system--for example, a specific file system can be checked for its percent of capacity in use via the diskInfo agent. A request could be defined to generate an SNM event if the capacity attribute value is greater than 90% on the target file system.
Once the Nerve Center has initiated the SNM request, polling of the managed resource at the specified intervals is handled by the SNM proxy rather than the Solstice EM Nerve Center, thus minimizing network traffic and the polling work required of the Nerve Center.
When a SNM agent or proxy receives a request, two agent processes are started: one is a parent process and one is a child process to handle the request. Subsequent requests sent to the same agent will cause the agent to start additional child processes.
Information on the attributes and attribute groups supported by SNM agents and proxy agents can be found in the Site/SunNet/Domain Manager Reference Manual.
17.3 SNM Alarms
When a critical threshold defined in an SNM request is detected by the SNM agent, a response--called an event in SNM terminology--is sent via RPC protocol to the SNM Event Dispatcher (na.event). The SNM Event Forwarder daemon (em_snmfwd) registers with the SNM Event Dispatcher to receive incoming SNM events. SNM events received by em_snmfwd contain the following information:
- Name of the target system where the managed resource resides
- Name of the system which sent the event
- The pertinent agent attribute, and the threshold which obtained, thus causing the event
- Priority of the event
- RPC number of the agent
If the sending agent is a proxy agent, the target system name and the agent system name will be distinct.
The SNM Event Forwarder uses the SNM event to build a snmAlarmEvent, which will be sent to the Solstice EM MIS. The Event Forwarder maps SNM event severities to the perceivedSeverity values used by the Alarm Service in the manner indicated in the following table.
TABLE 17-1 Mapping of SNM Event Severities Low Minor Cyan Medium Major Orange High Critical Red
The attributes in the snmAlarmEvent include the following:
- perceivedSeverity--This is mapped to SNM priorities as indicated in the table.
- managedObjectInstance--This represents the target element within the agent system.
- probableCause--This indicates the threshold that was defined in the SNM request; the event was generated because this threshold obtained.
- additionalText--This contains the name of the RPC agent and the threshold that generated the event.
- notificationIdentifier--This a timestamp of the moment when the MIS sent the SNM event request; this enables the MIS to identify the request that is responsible for the event.
For the structure of snmAlarmEvents, refer to the Management Information Server (MIS) Guide.
As snmAlarmEvents are, by default, not logged to the AlarmLog, they are not monitored by the Alarm Service and therefore do not affect fault status indication (icon color) in the Network Views. By default, only alarms logged to the AlarmLog affect fault status color in the Network Views. The Alarm Service is a module in the Log Server that monitors the alarm log and uses the highest severity of outstanding (uncleared) alarms to determine the fault status color for the device. For information about the Alarm Service, see Chapter 4.
However, a request that listens for incoming snmAlarmEvents can use the RCL alarm-logging functions to post appropriate nerveCenterAlarms to the Alarms Log. The RCL subscription functions enable a request to listen for specified types of events. Thus, you will want to design your SNM event request templates to listen for incoming snmAlarmEvents from SNM agents and take appropriate action.
17.4 Building SNM Event Request Templates
An example of a Nerve Center request template that initiates a SNM event request is the DeviceReachablePing template, shipped with Solstice EM. Examining this template may give you some ideas for building other SNM event request templates.
When a DeviceReachablePing request is launched against a target host, a SNM event request is sent to the ping proxy agent with a polling interval of 30 seconds and a threshold of reachable Not Equal To true. A high priority SNM event is generated by the ping proxy agent if it finds the target device not reachable when it polls. As indicated in TABLE 17-1, the SNM Event Forwarder translates the high priority SNM event into an snmAlarmEvent with a perceivedSeverity of critical. The DeviceReachablePing request listens for incoming snmAlarmEvents from the target device and posts a nerveCenterAlarm with a perceivedSeverity of critical if an SNM event is received.
While it is listening for incoming SNM events, the DeviceReachablePing request counts the elapsed time since any previous "Device Down" event, and if the elapsed time is greater than the timeout used by the ping proxy agent in polling the device, the DeviceReachablePing request assumes the device is up and posts a minor alarm to indicate the device is up after having been down. See the following figure.
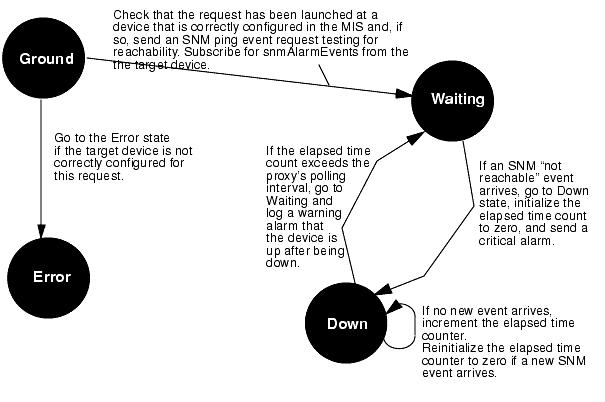
FIGURE 17-2 State Machine Diagram for DeviceReachablePing TemplateThe transition from the Ground state to the Waiting state is where the request's initialization is accomplished:
- The target device is checked to determine if it is correctly configured for a ping request. If the target device does not support the request, the request transitions to the Error state and an appropriate warning alarm is logged.
- The RCL subscribeOI() function is used to subscribe for incoming snmAlarmEvents from the target device.
- The RCL snmEventRequest() function is used to send the SNM event request to the ping proxy agent.
Each of these tasks is carried out by a separate condition defining a transition from the Ground state to the Waiting state. The first of these transitions is defined by the get_rpcAgent_name condition:
Using the RCL numElements() function, the first statement in the condition determines how many managed objects are configured for this device. This information is passed to the request in the $pollFdnSet variable when the request is launched against a target device in the Network Views. The condition then uses a WHILE loop to examine the distinguished name (FDN) pointing to each such object to determine if the device is manageable via RPC. If the device is manageable by RPC, the RPC proxy table for the device (which "contains" under it the various RPC agent attribute groups supported by that device) will be represented in the $pollFdnSet.
The Boolean variable $res is set to true if the device does support RPC, false otherwise. This condition is followed in the template by a transition defined by the check_for_rpc condition. If $res is false, that condition causes a transition to the Error state.
The get_rpcAgent_name condition also extracts from the RPC FDN the hostname of the device, which will be used in building the SNM event request. The RCL appendRdn() function is used to point $rpc_dn to the ping agent reach group contained under the RPC proxy table which will, then, be passed to the RCL snmEventRequest() function when initiating the SNM event request.
Note that the get_rpcAgent_name condition ends with a line that says "false;". This is to ensure that this condition does not cause a transition to the Waiting state. If this condition did cause a transition to the Waiting state, the conditions initiating the SNM event request and subscribing for incoming SNM events would never be executed. The conditions defining transitions are executed by Nerve Center in the order they occur in the template. The conditions in the later transitions out of the Ground state would not be executed by Nerve Center if any of the earlier conditions evaluate to true. If a condition defining one of these transitions evaluates to true, the request transitions to the Waiting state. Thus, if check_for_rpc evaluates to true, the request transitions to the Error state and the conditions initiating the SNM event request and subscribing for SNM alarms are never evaluated.
17.4.1 Subscribing for SNM Events
The subscription for snmAlarmEvents occurs in the following condition:
subscribeOi("snmAlarmEvent","{}",$dn);false;The subscribeOi() function is used to subscribe for events from a specified object. Note that $dn--the RPC proxy table for the target device, not the FDN pointing to the ping reach group ($rpc_dn), is the object that is the target of the subscription. For RPC requests, the RPC proxy table FDN contained in $pollFdnSet must be used for both event subscriptions and logging of alarms against the device.
As with the get_rpcAgent_name condition, the subscribe_snmAlarmEvent condition ends with "false;" to ensure that the request does not leave the Ground state after evaluating this condition but proceeds to the next transition in the Ground state.
17.4.2 Sending an SNM ping Event Request
After subscribing for snmAlarmEvents from the target device, the DeviceReachablePing request sends the SNM event request to the ping proxy agent. This is accomplished in the send_ping_reach condition:
The SNM event request parameters are passed to the snmEventRequest() function as the string $tmp. The hostname, which was extracted in the get_rpcAgent_name condition, is concatenated with the other parameters. If the RPC proxyhost setting for $hostname is configured as localhost, the request is sent to the ping proxy agent on the MIS system. However, polling by SNM agents can be offloaded to other machines if the managed resource is configured with a proxyhost other than localhost. (This can be configured in the Discover Properties window, when doing discovery of RPC-manageable devices on TCP/IP networks, or it can be configured manually using OCT.)
The event request passes the address of $handle to Nerve Center. This variable can be passed to snmKillRequest() function to kill the request. Note that handle must be initialized before calling snmEventRequest().
The parameters passed in the event request string are as follows:
- agentHost <hostname>--<hostname> was obtained from $pollFdnSet in the get_rpcAgent_name condition. This is the target device for the SNM event request.
- agentProgram 100115--The RPC number of the ping proxy agent.
- agentVersion 10--This is the software version number. This is contained in the entry for the agent in the /etc/initd.conf file. For example, 10 is the version number for na.snmp in the following inetd.conf entry:
- timeout 30--This is the length of time the ping proxy agent will wait for a response from the device before sending an alarm.
- interval 10--The ping proxy agent polls the target device every 10 seconds.
- \"reach\"--The name of the attribute group used in this request.
- threshold { <threshold> }--The name "threshold" introduces a set of values that define the threshold that the agent is to check for:
- \"reachable\"--The name of the attribute whose value is checked.
- 21--The data type of the operands of the relational operator.
- 1--The relational operator. A value of 1 indicates the operator is Equal To.
- \"0\"--"0" indicates false in this case.
- high--The priority to assign to the SNM event generated if the threshold obtains.
Thus, the ping proxy agent is instructed to check for reachability Equal To false and generate an SNM event notification if this should occur.
17.4.3 Waiting for a Response to the Event Request
After the DeviceReachablePing request subscribes for snmAlarmEvents from the target device and sends the SNM event request to the ping proxy agent, the request transitions to the Waiting state. The request "sleeps" until it is "woken up" by the arrival of an snmAlarmEvent. This happens when the is_snmAlarmEvent condition evaluates to true:
A $messType of 0 indicates that the request was woken up by the arrival of an event. The arrival of an snmAlarmEvent indicates that the target device is not reachable. The request then transitions to the Down state and executes two conditions as actions in the transition. One of these actions logs a nerveCenterAlarm:
This alarm is logged against the device indicated by the request's $pollfdn value. When the request is first launched, this is set by Nerve Center to point to the first object in $pollFdnSet. This critical alarm will cause the icon of the target device to turn red in the Network Views. The string passed to the alarmStr() function appears in the additionalText field for that alarm in the Alarms tool.
The other action in the transition from the Waiting to the Down state initializes a counter:
At this point the request knows that the device is down. But it would also be useful to be notified if the device comes back up. The request can assume that the device is back up if it stops receiving "Device Down" events from the ping proxy agent for a length of time that is longer than the timeout that the ping agent is using in waiting for responses from the target device. The request has set this timeout value to 30 seconds in the SNM event request. Therefore, the DeviceReachablePing request counts the time elapsed after each incoming "Device unreachable" event, and when it stops receiving such events for a period longer than the request timeout being used by the ping agent, the request assumes the device is back up.
After the request transitions to the Down state, it loops back to that state so long as the following condition evaluates to true:
Each time the request loops back from the Down to Down state due to the arrival of a new SNM event notification from the ping proxy agent, the time counter is reinitialized to zero.
Note that the polling interval is every 20 seconds in the Down state. If no new SNM event arrives after 20 seconds, the another_event condition will evaluate to false and the request will then evaluate the following condition:
The purpose of the first statement "$fake = topoNode;" is to retrieve some attribute (it may be irrelevant to the purposes of the request, as in this example) in order to force the request to be "woken up." If the request is not woken up, this condition would not be evaluated.
The wakeup_count condition increments the time counter and then checks to determine if the time elapsed since the last SNM event is greater than the ping proxy request timeout. If it is not, this condition will evaluate to false and will not cause a transition back to the Waiting state; the request then continues to loop in the Down state. If this condition does evaluate to true, the request assumes that the ping proxy agent is no longer sending "Not reachable" event notifications because the device is back up. This causes the request to transition back to the Waiting state, and in the transition a minor alarm is logged by the deviceBackUpWarningAlarm condition:
This is a minor alarm. This will only turn the icon cyan, however, after a user clears the previous critical alarm in the Alarms tool. If you wanted to implement an automatic "decay to cyan" feature, to automatically change the icon to cyan when a device becomes available after being unreachable, you could modify the DeviceReachablePing template to issue a "cleared" alarm before logging to the minor alarm. The following condition would send a "cleared" alarm to clear the previous critical alarm:
If the request did not clear the previous critical alarm, the icon would remain red because the Alarm Service sets fault status color to the highest severity of uncleared alarms. An outstanding critical alarm always takes precedence over alarms of lesser severity. The minor alarm only causes the icon to "decay to cyan" if the previous critical alarm has been cleared.
|
Sun Microsystems, Inc. Copyright information. All rights reserved. |
Doc Set | Contents | Previous | Next | Index |