| Oracle® Real User Experience Insightユーザーズ・ガイド 12c リリース6 (12.1.0.7) for Linux x86-64 E61771-02 |
|


 前 |
 次 |
| Oracle® Real User Experience Insightユーザーズ・ガイド 12c リリース6 (12.1.0.7) for Linux x86-64 E61771-02 |
|
前 |
次 |
この章では、監視対象トラフィックのレポートを情報要件に合うように最適化する方法について説明します。また、ネットワーク環境で使用するCookieテクノロジの仕様、名前付きWebサーバーとクライアント・グループの使用方法、および様々な高度な機能(ルール順序設定やデータ保存ポリシーなど)についても説明します。
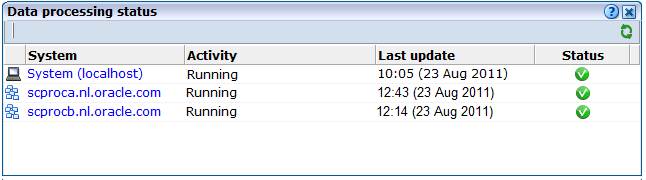
監視対象のネットワーク・トラフィックの概要を開くには、「システム」→「ステータス」→「データ処理」の順に選択します。RUEIのデプロイメントで処理中のシステムのリストが表示されます。例を図12-1に示します。
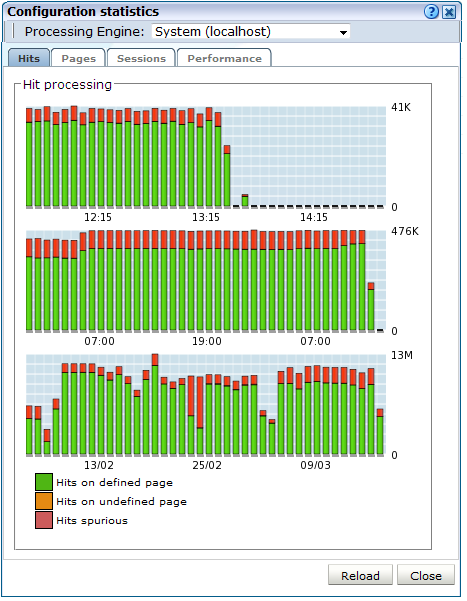
ヒット、ページ、セッション処理、システム・ロードに関する情報を表示する必要があるシステムをクリックしてください。例を図12-2に示します。
「パフォーマンス」タブの「使用可能なリソース使用率(%)」項目は、現在の処理レベルを示します。この値が100%に近づくと、データの処理に遅延が発生し始め、データをリアルタイムで処理できなくなります。
この機能はアプリケーション・ロジックに基づいているため、表示されるレポートには非アプリケーション(スイート、サービス、SSOなど)のトラフィックは示されません。
|
重要: RUEIが監視しているトラフィックに関して正確にレポートするには、このトラフィック・サマリーを定期的に確認することを強くお薦めします。必要であれば、RUEIの構成を確認して適切なものにしてください。たとえば、他のCookieテクノロジを追加します。また、システムでセッションを追跡できない場合は、ユーザー・フローも適切に追跡できません(ユーザー・フロー・レポートではセッションの追跡が必要になるため)。 |
RUEIによってユーザーのWeb環境を正確に監視するには、RUEIがユーザーのWebサイトで使用されているCookieテクノロジやその他のセッション・トラッキング・メカニズムを把握している必要があります。Cookieテクノロジは標準的なテクノロジ(ASPやColdFusionなど)かカスタム実装のいずれかになります。カスタム実装の場合には、関連する情報をシステムに提供する必要があります。
Cookieテクノロジは、特定のアプリケーションおよびスイートの他、グローバル・セッション・トラッキングにも指定できます。アプリケーション固有のセッション・トラッキング定義は、グローバル・セッション・トラッキングの設定よりも優先されることに注意してください。監視に使用するアプリケーション固有のCookieテクノロジおよびグローバルCookieテクノロジはそれぞれ最大9個まで定義できます。
アプリケーション固有のCookieテクノロジの指定
次を実行します。
「構成」、「アプリケーション」または「スイート」の順に選択し、必要なアプリケーションを選択します。「アプリケーション概要」が表示されます。「拡張」タブ→「セッション・トラッキング」タブの順にクリックします。
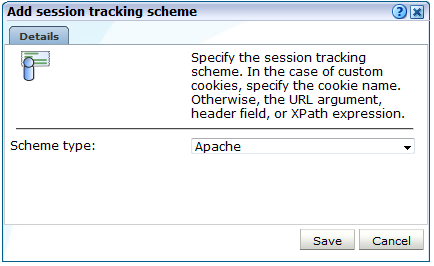
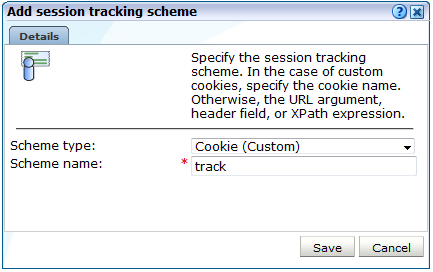
新規セッション・トラッキング・メカニズムの追加または既存の定義をクリックします。図12-3に示すようなダイアログが表示されます。
Web環境で使用しているCookieテクノロジを「スキーム・タイプ」メニューから選択します。非標準テクノロジを使用している場合は、(カスタム)を選択し、組織で使用しているCookieの名前を指定します。ワイルドカード文字(*)をCookie名の一部として指定できます。Cookie名では大文字と小文字が区別されることに注意してください。
「XPath(カスタム)」オプションは、リクエストまたはレスポンスに適用されたXPath式に基づくセッション・トラッキングであることを指定します。XPath式の使用方法の詳細は、付録F「XPath問合せの使用」を参照してください。「ヘッダー(カスタム)」オプションは、指定されたリクエストまたはレスポンスに基づくセッション・トラッキングであることを示します。
(URL引数)を選択した場合は、組織で使用しているURL引数の名前を指定する必要があります。セッションの追跡でのURL引数の使用方法は、付録B「Cookieの構造」に記載されています。
次に、「保存」をクリックします。変更は、少しの間隔(通常5分から10分)を置いて適用され、さらにその少し後にレポータ・システムに表示されます。
グローバル・セッション・トラッキング・メカニズムの指定
次を実行します。
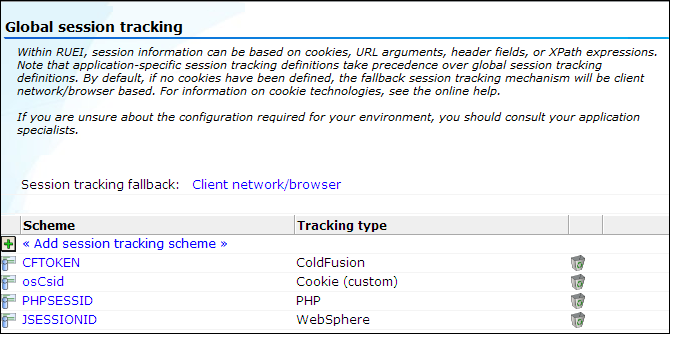
「構成」→「アプリケーション」→「グローバル・セッション・トラッキング」の順に選択します。このオプションを使用できるのは管理者のみです。現在定義されているグローバル設定が表示されます。例を図12-4に示します。
「セッション・トラッキング・スキームの追加」または既存の定義をクリックします。手順は、前述の手順と同じです。
「セッション・トラッキング・フォールバック」設定の使用方法の詳細は、12.2.2項「代替セッション・トラッキング・メカニズムの指定」に記載されています。
複数の構成されたCookie
複数の構成されたCookieが同じヒットで検出されると、RUEIは、複数のCookie値を持つすべてのヒットを単一のユーザー・セッションにマージします。たとえば、3つのヒットが次のCookie値を持つ状況を考えてみます。
hit1: CookieA=123; hit2: CookieB=321;CookieA=123; hit3: CookieB=321;
この場合、すべての3つのヒットは、同じユーザー・セッションに属するとみなされます。
重要:
同一セッションで複数のアプリケーションがレポートされるようにする場合を除いて、アプリケーション固有ベースでCookie定義を構成することをお薦めします。
前述のように、セッションの追跡はCookieに基づいて実行できます。ただし、Cookieが適していない状況または使用できない状況があります。たとえば、次の状況について考えてみます。
Cookieがヒットごとに変化する場合(たとえば、ObSSOCookieのケース)。
Cookieに設定されているパスがアプリケーションの一部にしか対応しない場合。
Webサーバーで構成されているプライバシ・ポリシーのためにCookieの使用が無効な場合。
セッションの追跡のために適切なCookieがない場合は、JavaScriptを使用してクライアント側のCookieメカニズムを実装することをお薦めします。
クライアント側のCookieメカニズムの構成
次を実行します。
該当するログイン・ページに次のようなコードを追加します。
<SCRIPT
LANGUAGE="JavaScript">if(document.cookie.indexOf('track=')==-1){document.cookie
='track='+parseInt(Math.random()*2147418112)+new
Date().getTime()+';path=/;domain='+document.location.host.substring(
document.location.host.lastIndexOf('.',
document.location.host.lastIndexOf('.') - 1)) ;}</SCRIPT>
前述のコードは情報提供のみを目的としています。特定の要件に応じて変更が必要になる場合があります。
「構成」→「アプリケーション」→「セッション・トラッキング」の順に選択します。「新規Cookieの追加」をクリックします。図12-5に示すダイアログが表示されます。
Cookieテクノロジ(カスタム)を「スキーム・タイプ」メニューから選択し、適切なCookie名を指定します。前のJavaScriptコードではCookie名はtrackです。これはログイン・ページのJavaScriptコードに指定した名前と一致する必要があります。使用できるのは英数字のみです。また、ヘッダー・サイズを最小限にするためにCookie名は10文字以下にすることをお薦めします。次に、「保存」をクリックします。
Cookieの構成の確認
Cookie構成が正しく追跡されることを確認する手順は、次のとおりです。
ブラウザですべてのCookieを消去します。
監視対象のアプリケーションに(再)ログインします。
いくつかのページ表示を実行します。
監視対象のアプリケーションからログアウトします。
少なくとも10分間待機します。
RUEIレポータ環境を開き、「データの参照」を選択し、「すべてのセッション」グループを開いて「セッション診断」を選択します。記録されたセッション(ユーザーID別または時間別)を探します。アプリケーションについてフィルタリングできます。
セッションを開き、ログイン・ページ以外にページ・ビューがあることを確認します。これで、セッションIDがログイン後に保存されていることが確認されます。
Cookieテクノロジを指定しない場合は、クライアント・ネットワークとクライアント・ブラウザの組合せを使用してセッションを追跡します(デフォルト)。ただし、この方法が環境に適していない場合は、代替追跡メカニズムとしてクライアントIPアドレスを使用できます。
代替セッション・トラッキング・メカニズムを指定する手順は、次のとおりです。
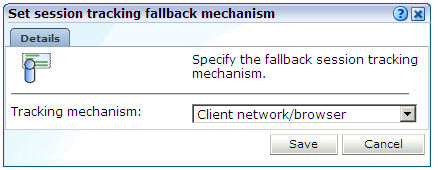
「構成」→「アプリケーション」→「セッション・トラッキング」の順に選択します。現時点で定義されているCookieの設定が表示されます。現時点で定義されているセッション・トラッキングの代替メカニズムをクリックします。図12-6に示すダイアログが表示されます。
「トラッキング・メカニズム」メニューを使用して、クライアント・ネットワークとブラウザの組合せを使用する(デフォルト)かクライアントIPアドレスを使用するかを指定します。
次に、「保存」をクリックします。行った変更は、即座に有効になります。
代替セッション・トラッキング・メカニズムの選択
どちらの代替メカニズムを使用するかを検討するとき、外部用アプリケーションではデフォルトのネットワークとブラウザの組合せを使用し、内部用アプリケーションではクライアントIPアドレスを使用するのが原則です。同じプロキシ・サーバーで複数のユーザーが存在する場合は、デフォルトの代替メカニズムの使用をお薦めします。ただし、この場合は、すべてのユーザーが1つのセッションに記録されることに注意してください。通常、次の状況ではクライアントIPアドレス・メカニズムの使用をお薦めします。
すべてのユーザーに一意のIPアドレスがある場合。アプリケーションごとに、クライアントIPアドレスをTCPパケットから取得するか、特定のHTTPリクエスト・ヘッダーから取得するかを指定できることに注意してください。この詳細は、付録Q「NATトラフィックの監視」に記載されています。
組織で定められたブラウザが使用されている場合。つまり、標準のバージョンおよびプラグインの標準ブラウザ(Internet ExplorerまたはMozilla Firefoxなど)。
管理対象のアプリケーションの一部(またはすべて)が部分的にJavaで実装されている場合。Oracle E-Business Suite(EBS)は、このようなアプリケーション・アーキテクチャの例です。このようなアプリケーションでは、クライアントIPアドレス・メカニズムの使用により、Javaとクライアント・リクエストの両方が同じレポート・セッションに表示されないようになります。
|
重要: ネットワーク・トラフィックの正確なレポートのため、Webサイトで使用するCookieテクノロジを正確に指定することを強くお薦めします。また、ビジター・セッションの追跡に指定するCookieがブラインディングされないようにしてください。ブラインディングが行われると、Cookieに基づくセッション作成が失敗します。 |
名前付きサーバー機能を使用すると、監視対象Webサイトでのサーバーの使用状況を詳細に洞察することができます。この機能を使用すると、サーバーIPアドレスの範囲を1つのWebサーバー・グループおよび個別のWebサーバーに割り当てることが可能です。たとえば、サーバー・グループとして部門またはデータ・センターを使用し、そのグループに属する特定のWebサーバー名をサーバー名として指定できます。これにより、問題(ページの失敗など)が発生したときに、該当するWebサーバーの場所を簡単に特定できます。名前付きサーバー機能を使用できるのは、完全なITユーザー・アクセスを持つユーザーのみです(表14-2を参照)。
サーバー情報の表示
監視中に収集したWebサーバー情報は、データ・ブラウザで、全ページ、キー・ページ、全機能、失敗した機能グループ、失敗したURL、失敗したページおよび遅いURLグループの各項目別に表示できます。サーバーのIPには指定したIPアドレスが表示され、サーバー・グループにはグループ名が表示されます。サーバー・グループにズーム・インすると、そのグループを構成する個々のWebサーバー名を表示できます。さらにズーム・インすると、そのWebサーバーに割り当てられた単一のIPアドレスを表示できます。
名前付きサーバーIDのソース
名前付きサーバーをレポートするとき、デフォルトではサーバーのIPアドレスはIPパケットからフェッチされます。しかし、WebサーバーがNATデバイスの前面に配置されている場合は、特定のHTTPヘッダーやCookieなどからIPアドレスが取得される方が便利なこともあります。そのため、IPアドレスを取得するソースを階層として指定することができます。グループおよびサーバー名には、類似のソース・スキームを指定することもできます。これらのスキームから値が生成されないときに使用する代替識別情報も定義できます。
Webサーバーを識別およびレポートする方法を定義するには、次の手順を実行します。
「構成」→「一般」→「指定サーバー」の順に選択します。次のいずれかのオプションを選択します。
IPアドレス・ソース: このオプションを使用して、サーバーのIPアドレスを取得するソースを指定します。
名前付きソース: このオプションを使用して、サーバー名を取得するソースを指定します。
グループ・ソース: このオプションを使用して、サーバーのグループ名を取得するソースを指定します。
識別代替: このオプションを使用して、定義されたソースから取得できない場合にサーバーIDに使用するIPアドレス範囲、グループおよび名前を指定します。このオプションの使用方法の詳細は、12.2.2項「代替セッション・トラッキング・メカニズムの指定」に記載されています。
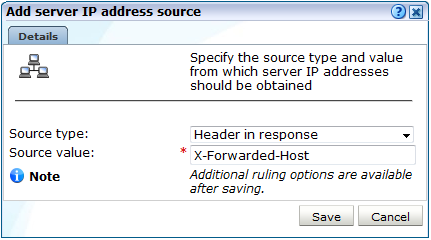
「新規ソースの追加」をクリックします。図12-7に示すようなダイアログが表示されます。
「ソース・タイプ」と「ソース値」のフィールドを使用して、選択した項目に使用する識別スキームを指定します。表12-1に、使用可能なオプションを示します。次に、「保存」をクリックします。
ルーリング機能を作成すると、それを使用して、新規作成する定義を調整する追加の一致ルールを指定できます。この詳細は、8.3.5項「規則指定機能の使用方法」に記載されています。
サーバーの識別情報として定義されるソースは、リストに出現する順序で評価される点に注意してください。必要な場合は、項目のコンテキスト・メニューで「上に移動」と「下に移動」のオプションを使用して、リストでの位置を変更できます。
指定されたソースからサーバーの情報を取得できない場合に使用する、サーバー識別方法を定義することができます。これをサーバー識別代替と言います。識別の代替方法を定義するには、次の手順を実行します。
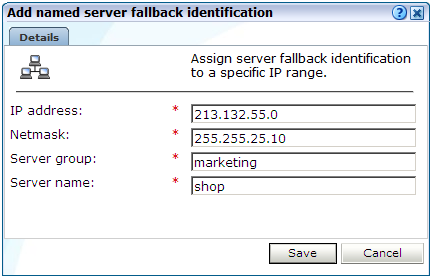
「構成」、「一般」、「指定サーバー」、「識別代替」の順に選択します。「新規サーバーの追加」をクリックします。図12-8に示すダイアログが表示されます。
ネットマスクで限定した一連のIPアドレス(または特定のIPアドレス)および関連するWebサーバーとグループ名を指定します。次に、「保存」をクリックします。
|
重要: 指定するIPアドレスとネットマスクの組合せは、一意である必要があります。また、ネットマスクだけ異なる重複したIPアドレスを指定した場合、レポートの目的には固有性の高い方が使用されます。 |
代替識別のリストのアップロード
オプションで、「アップロード」をクリックすると、現在定義されている代替識別情報に、代替識別情報のリストをマージすることができます。リストのファイルでは1行が1エントリである必要があり、各サーバーに関する情報(図12-8のように表示される情報)はタブで区切っておく必要があります。マージしたファイル内にすでに定義されているサーバー識別情報の定義がある場合には、その既存の定義が上書きされます。
ビジターのIPアドレスに関連する情報の拡張が必要な場合もあります。イントラネットのトラフィックを監視しているときに、ユーザー独自のクライアント分類を使用する必要がある場合に、これは特に便利です。
この機能を使用する手順は、次のとおりです。
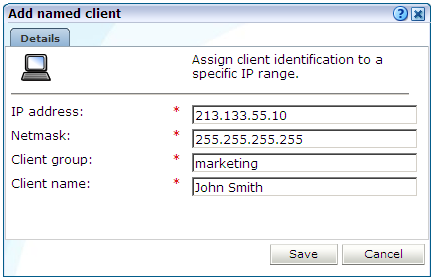
「構成」→「一般」→「指定クライアント」の順に選択します。現時点で定義されている名前付きサーバーがリストされます。「追加」をクリックします。このオプションを使用できるのは、ITの完全なアクセス権限を持つユーザーのみです。図12-9に示すダイアログが表示されます。
このダイアログ内のフィールドを使用して、ネットマスクで限定した一連のIPアドレスまたは単一のIPアドレス、クライアントおよび関連するグループ(たとえば会社の部門)を指定します。次に、「保存」をクリックします。
重要:
指定するIPアドレスとネットマスクの組合せは、一意である必要があります。また、ネットマスクだけ異なる重複したIPアドレスを指定した場合、レポートの目的には固有性の高い方が使用されます。
オプションの「アップロード」をクリックすると、名前付きクライアントのリストを現時点で定義されているリストとマージできます。リストのファイルでは1行が1エントリである必要があり、各クライアントに関する情報(図12-9のように表示される情報)はタブで区切っておく必要があります。新しくマージするファイルの中に、すでに定義されている名前付きクライアントが含まれている場合は、既存の定義が上書きされるため、注意してください。
定義を変更した名前付きクライアント・グループは、少しの間隔(通常5分から10分)を置いて適用され、さらにその少し後にレポータ・システムに表示されます。
表3-3に記載されている遅いURLおよび遅い関数データ・グループは、関数コールのエンドツーエンド時間に基づいて、システムにより検出された、5分間での最も遅い5000のオブジェクトに関してレポートします。デフォルトでは、オブジェクトおよび関数コールには、それぞれのビューにレポートされる、少なくとも2000ミリ秒のエンドツーエンド時間が指定されている必要があることに注意してください。ただし、このしきい値は、レポート要件に合うように変更できます。
遅いレポートしきい値の変更
次を実行します。
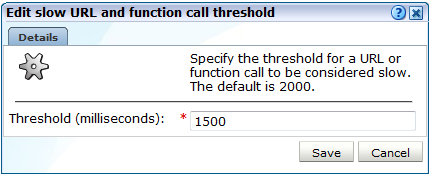
「構成」、「一般」、「詳細設定」、「URLの処理」、「遅いURLおよび関数コールのしきい値」の順に選択します。図12-10に示すダイアログが表示されます。
オブジェクトまたは関数コールが遅いと判断されるまでに必要なエンドツーエンド時間(ミリ秒単位)を指定します。次に、「保存」をクリックします。
ヒットの失敗は、失敗したURLグループの中に記録されます。ヒットの失敗は広範な理由で発生し得るため、どのようなヒットの失敗を記録するのかを設定しておく必要があります。たとえば、リモート・ロボット検索に関連したインシデントの記録が必要になることはほぼありません。次を実行します。
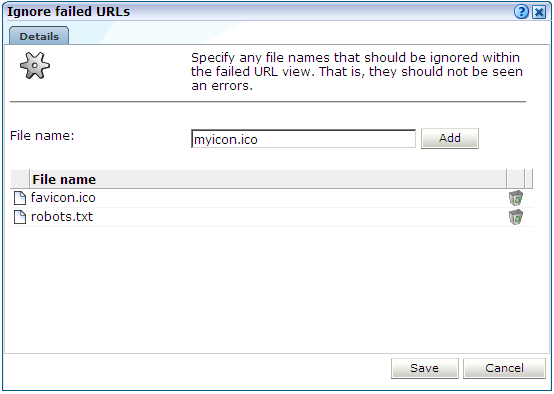
「構成」、「一般」、「詳細設定」、「URLの処理」、「失敗したURLの無視」の順に選択します。このオプションを使用できるのは管理者のみです。図12-11に示すようなダイアログが表示されます。
失敗したURLビュー内で無視する必要のあるファイル名を指定します。つまり、これらがエラーとして表示されないようにします。ファイル名定義内のディレクトリ情報はすべて無視され、定義されたファイルはリストされたオブジェクトURLからも削除されます。無視する必要のあるファイル名を新たに定義するには、「追加」をクリックします。また、定義されたファイルの右側にある「削除」 アイコンをクリックすると、無視するファイルのリストからそれが削除されます。
インストール時に、2つのデフォルト・ファイル(robots.txtおよびfavicon.ico)が自動的に構成されます。次に、「保存」をクリックします。この設定への変更は10分後に適用されます。この少し後に、指定した変更がレポータ・インタフェースに表示されます。
最低レベルのページURLディメンションに、URL引数をすべて記録するか、一部を記録するか、または記録しないかを設定できます。次を実行します。
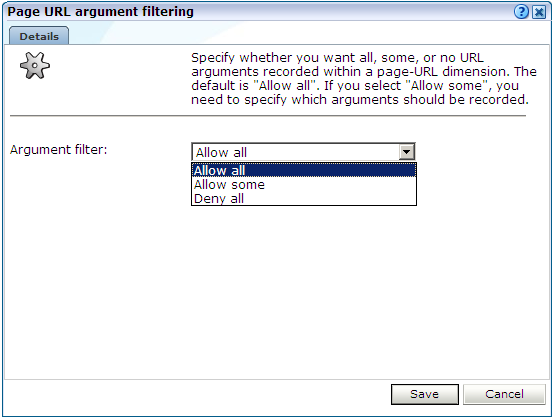
「構成」→「一般」→「詳細設定」→ページURL処理→「ページURL引数のフィルタ」の順に選択します。このオプションを使用できるのは管理者のみです。図12-12に示すダイアログが表示されます。
「引数フィルタ」メニューを使用して適切なフィルタを選択します。デフォルトは「すべて許可」です。つまり、引数がすべて記録されます。次に、「次へ」をクリックします。
「一部を許可」フィルタを選択した場合は、続くダイアログで、どの引数を記録するかを指定する必要があります。複数ある引数はアンパサンド(&)記号で区切ります。次に、「次へ」をクリックします。
新しい設定は10分後に適用されます。その少し後に、指定した変更がレポータ・インタフェースに表示されます。
|
注意: ユーザーのページURLにセッション引数またはその他任意の引数が含まれる場合は、この機能を使用することをお薦めします。この機能を使用しない場合は、ページベース・ビュー(全ページまたは失敗したURLなど)の内容が非常に大きくなることがあります。 |
RUEIでは、セッション情報は「すべてのセッション」グループ内でレポートされます。この機能では、ビジターのセッションに関する情報はセッション開始後約5分で表示されます。デフォルトでは、ビジターが活動しない時間が、定義されたセッション・アイドル時間(デフォルトは60分)を超えた場合に、ビジター・セッションが終了したとみなされます。
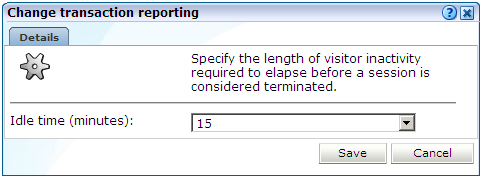
セッションのレポートを最適化するために、「セッション・アイドル時間」の詳細設定を使用して、ビジターのセッションが終了したとみなされる非アクティブな期間(分)を指定します。デフォルトは60分です。
|
重要: この設定は、システムのパフォーマンスおよびレポートされるデータの精度に影響することがあるため、Oracleサポート・サービスのアドバイスを受けた場合のみ変更することを強くお薦めします。 |
セッション設定の指定
セッションをレポートするときに使用するアイドル時間を指定する手順は、次のとおりです。
「構成」→「一般」→「詳細設定」→「セッション処理」→「セッション・アイドル時間」の順に選択します。図12-13に示すダイアログが表示されます。
ビジターが非アクティブになってからセッションが終了したとみなされるまでの時間(分)を指定します。デフォルトは60分です。次に、「保存」をクリックします。
この設定は、変更すると、5分以内に有効になります。
デフォルトでは、RUEI内でアプリケーション、SSO、プロファイル、スイートおよびサービスの各フィルタで一致が行われる順序は、定義に指定されている詳細のレベルによって決まります。つまり、最も多くの情報が指定されている定義が最初に適用されます。ただし、フィルタの適用順序の変更が必要になる場合があります。
たとえば、ドメインshop.oracle.comのネットワーク・トラフィックを監視するとします。また、2つのアプリケーション(ドメインshop*用に1つおよびドメイン*oracle*用に1つ)を定義しておきます。文字列*oracle*は、文字列shop*より長いため、最初に適用されます。ただし、ドメインshop*のページIDを優先する必要があるとします。ルール順序設定機能を使用すると、デフォルトのルール一致順序を、必要なドメインのページを適用する順序で上書きできます。
|
注意: デフォルトのルール順序設定を使用すること、およびアプリケーション、SSOプロファイル、スイートおよびサービスが相互排他的になるように十分な情報を使用してそれぞれを定義することをお薦めします。 |
ルール順序設定機能を使用する手順は、次のとおりです。
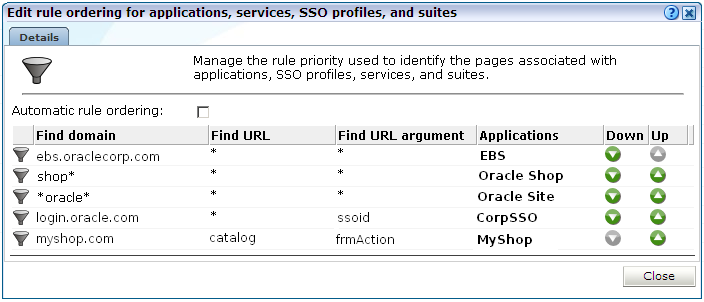
「構成」タブをクリックし、「構成」メニュー・オプションを選択してから「ルーリング順序の編集」オプションを選択します。このオプションを使用できるのは、ITユーザーで「完全」アクセス権限を持つユーザーのみであることに注意してください。図12-14に示すダイアログが表示されます。
「自動ルール順序」チェック・ボックスを使用して、現在定義されているアプリケーション、SSO、プロファイル、スイートおよびサービスからルール順序設定を自動的に導出するかどうかを指定します。前述のように、デフォルトでは、最も多くの情報が指定されている定義が最初に適用されます。「上へ」および「下へ」コントロールを使用してルールの適用順序を指定すると、このチェック・ボックスの選択が自動的に解除されます。このチェック・ボックスを再び選択すると、フィルタ順序設定が自動的にデフォルトにリセットされます。
行った変更は即座に有効になります。次に、「閉じる」をクリックします。
|
重要: デフォルトのルール順序設定を変更してから、新規のアプリケーション、SSOプロファイル、スイートまたはサービスを定義すると、関連付けられているフィルタが現在のルール順序設定の最下部に即座に配置されます。このため、新規フィルタの作成後には必ずルール順序設定を確認してください。 |
RUEIレポートの詳細レベルは、測定されたトラフィックの量と使用可能なディスク領域の量に応じて異なります。大規模なトラフィックの量を処理するため、データは、特定のレポート目的用にデータ型(「すべてのページ」、「すべてのセッション」および「遅いURL」)に加工され、時間の経過とともにデータ型ごとに集計されます。
時間ベースの集計メソッドは、データ集計と呼ばれます。次のデータ集計レベルを使用できます。
インスタンス: (デフォルトは8日)
5分: (デフォルトは15日)
毎時間: (デフォルトは32日)
日次: (デフォルトは90日)
月次: (デフォルトは60か月)
データ保存では、使用可能なディスク領域の量と、時間の経過に伴って使用できるレポートの詳細レベルとの間のバランスが問題になります。たとえば、アプリケーションで8から40日間の「インスタンス」データ集計を設定すると、高レベルなアプリケーション詳細をレポートで使用できます(ただし、多くのディスク領域が犠牲になります)。また、60から90か月の「月次」集計を設定すると、(詳細度の低い)傾向レポートが可能になりますが、相当なディスク領域が犠牲になります。
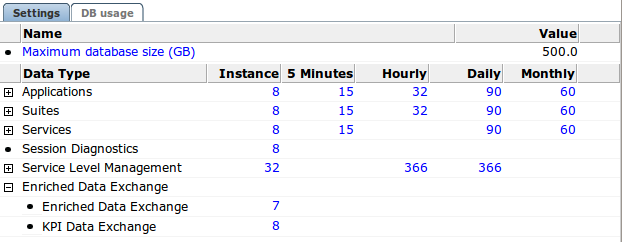
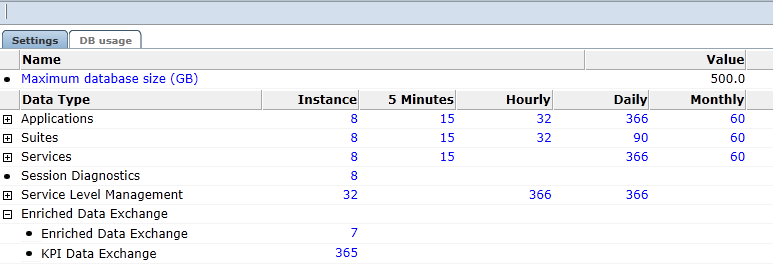
レポート・データの保存ポリシーの詳細設定画面は、「設定」と「DB使用率」の2つのタブで構成されています。「設定」タブを図12-15に示します。
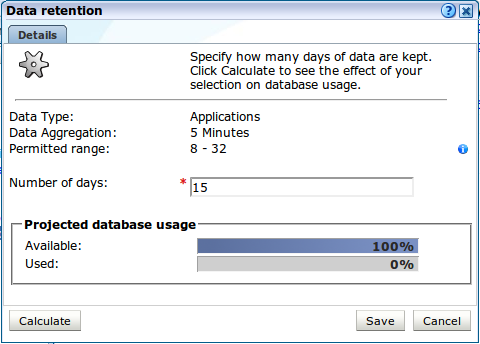
ポリシーはデータ型グループごとに、および各データ型の詳細レベルの+記号をクリックして指定できます。データ集計レベルはデータ型グループまたはデータ型ごとに構成できます。「データ保存」ダイアログ(図12-16)を開くには、「設定」タブ内の数字をクリックします。
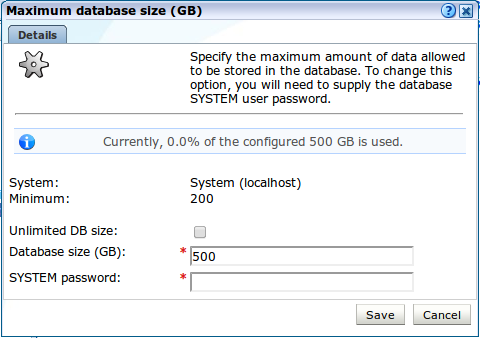
「設定」タブでは、各データベースの最大データベース・サイズを指定できます。スタンドアロン設定では構成できるデータベースは1つのみです。スケールアップ設定(複数の処理ノードを持つレポータ)の場合は、データベースごとに最大サイズを指定できます。「最大データベース・サイズ(GB)」をクリックすると、図12-17のようなダイアログが表示されます。
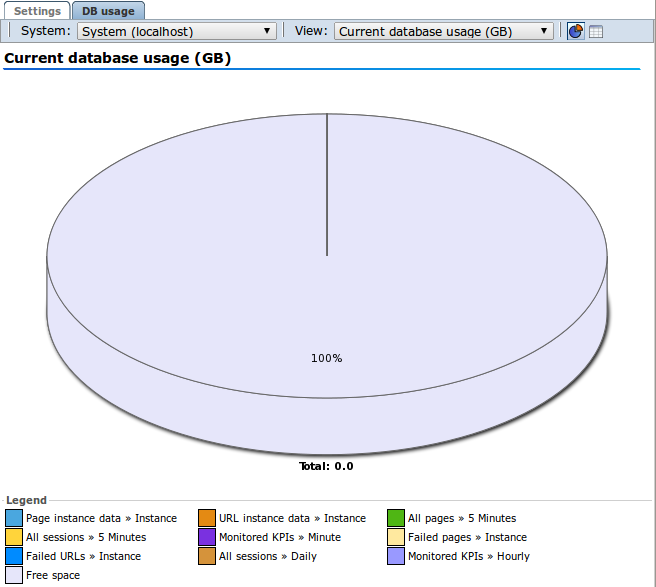
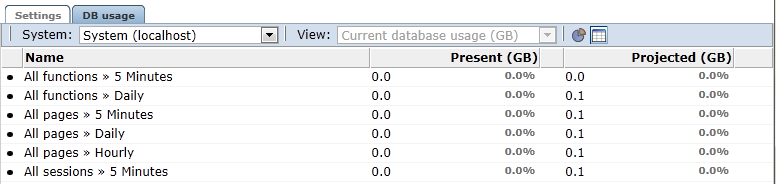
「DB使用率」タブには、現在および予測されるディスク使用量がデータベース(レポート対象のデータベースまたは処理ノード上のデータベース)ごとに表示されます。「システム」ドロップダウンを使用してノードを選択し、「ビュー」ドロップダウンで現在と予測のデータベース使用率を切り替えます。円グラフから表に切り替えるには、表アイコンをクリックします(図12-18)。
新規のデプロイメントの場合は特に、現在および予測されるデータベース使用率を定期的に確認することをお薦めします。測定データが多ければ多いほど、予測の精度も高くなります。新しいアプリケーションの追加や既存アプリケーションの変更などの理由で、RUEIの構成を変更した場合は、データベース使用率への影響を注意して監視してください。
この手順では、レポータの保存ポリシーを定義する方法について説明します。
|
注意: 次の設定では、現在のデータのレポータ・データ保存ポリシーを構成するだけでなく、リプレイ・ストアに対する時間ベースのコレクタ・データ保存ポリシーも制御します。
たとえば、「セッション診断(日)」が8日間に設定されている場合、セッション診断データには最大8日分のセッションと、最大8日分のフル・セッション・リプレイ・データが含まれます。 コレクタのデータ保存ポリシーの詳細は、13.9項「コレクタのデータ保存ポリシーの定義」を参照してください。 |
レポータ・システムで使用するデータ保存ポリシーを指定する手順は、次のとおりです。
「構成」→「一般」→「詳細設定」→「レポータ・データ保持ポリシー」の順に選択します。図12-19に示すような画面が表示されます。
目的の設定を選択します。
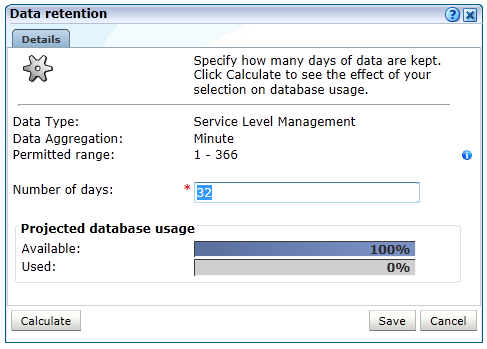
図12-20に示すようなダイアログが表示されます。
このダイアログのコントロールを使用して、選択したオプションの保存ポリシーを指定します。
推定されるデータベース使用率(監視対象トラフィックのレベルに基づく)が示されます。ディスク領域使用率の情報は、個別設定のダイアログ・ボックスに表示されます。これらの見積もりは、デプロイされた処理システム内の最も高い使用状況に基づいています。たとえば、レポータ内の使用状況が50%および処理エンジン内の使用状況が20%の項目の場合、高い値を使用して使用状況および可用性をレポートします。
ほとんどの設定では、「計算」をクリックすることで、データベース使用率とディスク領域使用率のうち、該当する方に対するユーザーの選択の影響を表示できます。
次に、「保存」をクリックします。ディスク領域割当ての変更は約10分で有効になりますが、データベース割当ての変更は午前0時を過ぎるまで有効にならないことに注意してください。
オプションで、項目に現在使用されている合計データベース領域(GB単位)およびデータベースの許可される最大サイズを表す比率の説明には、「DB使用率」タブをクリックします。例を図12-21に示します。
|
注意: 保持されるデータの量を増やすには、まず下位レベルのデータ保存設定、次に上位レベルのデータ保存設定を変更することをお薦めします。保持されるデータの量を減らす場合は、まず上位レベルのデータ保存設定、次に下位レベルのデータ保存設定を変更します。 |
必要な月数の計算
月次設定の最小値は、指定した日数をカバーするために必要な最大月数を計算することで決定されます。たとえば、90日を指定すると、月次設定の最小値は4になります(2月、3月、4月を組み合せても89日しかカバーされないため)。これに対し、3か月を指定すると、日次設定の最大値は89になります。
コレクタのデータ保存ポリシーの構成は、13.9項「コレクタのデータ保存ポリシーの定義」に記載されています。
デフォルトでは、最新の(未完了)期間の情報は、選択されている期間の現時点の分までが常に表示されます。グラフではこの部分は点線で表示されます。例を図12-22に示します。
未完了期間のレポート時期の指定
未完了の期間をいつレポートするかを指定する手順は、次のとおりです。
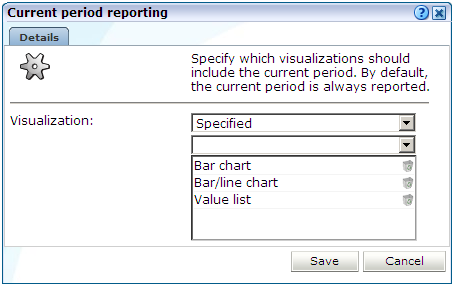
「構成」→「一般」→「詳細設定」→「データの視覚化」→「現在の期間のレポート」を順に選択します。図12-23に示すダイアログが表示されます。
最新期間をレポートするときに使用する視覚表現を選択します。表12-2に示すオプションがあります。
表12-2 「Visualization」のオプション
| オプション | 説明 |
|---|---|
|
有効 |
すべての未完了期間をすべてのグラフでレポートすることを指定します。値リスト、レポートおよびエクスポートにも含めます。これがデフォルトです。 |
|
無効 |
未完了期間はレポートしないように指定します。 |
|
指定済 |
未完了期間は特定の視覚表現のみでレポートすることを指定します。「値リスト」オプションには、データ・ブラウザの値リストだけでなく、レポートとエクスポートも含まれることに注意してください。 |
次に、「保存」をクリックします。この設定は、変更すると、即座に有効になります。
KPI値およびSLA値は一定レベルの精度でレポートされます。デフォルトでは小数点以下2桁です。ただし、これを変更してユーザーのレポート要件を反映できます。次を実行します。
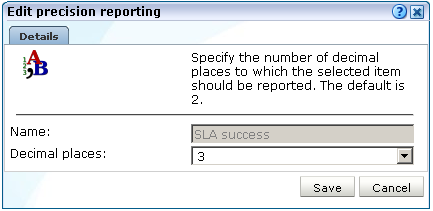
「構成」→「一般」→「詳細設定」→KPIおよびSLAのレポート精度の順に選択します。レポートを変更するアイテムを選択します。たとえば、「SLA成功」です。図12-24に示すようなダイアログが表示されます。
選択したアイテムをレポートする場合の小数点以下の桁数を指定します。次に、「保存」をクリックします。これらの設定は変更すると即座に有効になります。
しきい値プロファイルは、KPIの自動ターゲットの評価時に使用するパラメータを指定します(7.3.3項「自動ターゲットおよび固定ターゲット」を参照)。
RUEIには、「システム・デフォルト」しきい値プロファイルが含まれています。新規プロファイルを作成するかこのプロファイルを編集しますが、このプロファイルを削除しないことをお薦めします。
KPIしきい値プロファイルを定義する手順は、次のとおりです。
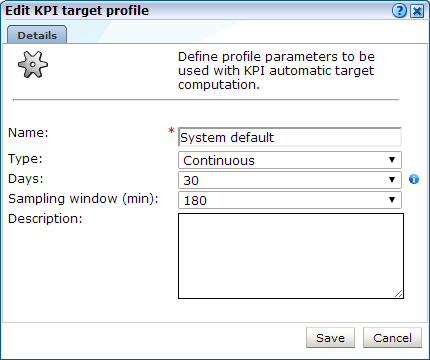
「構成」→「一般」→「詳細設定」→「KPIしきい値プロファイル」を選択します。変更するアイテムを選択するか、「追加」をクリックします。図12-25に示すようなダイアログが表示されます。
しきい値プロファイルの「名前」を指定します。
次のうちから「タイプ」を選択します。
「連続」は、プロファイルに使用可能なすべての日のデータを使用します。
「週の同日」は、プロファイルに使用可能な同じ曜日のデータを使用します。たとえば、2つの使用可能な過去の月曜日のデータがある場合、そのデータを使用して月曜日の傾向を評価します。
「週労働日数」では、週の労働日を指定可能で、傾向評価用に2つの日のグループを作成します。たとえば、月曜日から金曜日のデータを月曜日から金曜日の傾向の評価に使用できます。同様に、土曜日と日曜日のデータを週末の傾向の評価に使用できます。
プロファイルに使用可能な「日」または「週」の数を指定します。「連続」タイプのしきい値プロファイルを選択した場合は、傾向の評価に使用できるようにするデータの日数を指定します。その他のしきい値プロファイルでは、使用可能にする必要があるデータの週の数を指定します。この設定の最大日数または最大週数は、12.10.1項「レポータの保存ポリシーの定義」で説明しているレポータ・データ保存によって決まります。
|
注意: より多くのデータを使用できる場合は、傾向評価のほうが精度が高くなります。「連続」タイプのしきい値プロファイルを選択して30日分のデータを提供する場合のほうが、「週の同日」タイプを選択して6週間分のデータを提供する場合(それぞれの日が照合され、月曜日など特定の曜日について6つの一致しか存在しない)よりも処理対象データが多くなります。 |
しきい値プロファイルに「サンプリング・ウィンドウ(分)」を選択します。これによって、データの変更に関連するターゲットのレスポンス時間が決まります。たとえば、90分ウィンドウは現在の1分間の前後45分間を調べてターゲットの最小と最大を決定することを意味します。ウィンドウの時間を長くすると、その期間にターゲットに影響を与える短期間のデータのバリエーションが少なくなる可能性があり、ウィンドウの値を小さくすると、自動ターゲットがより速く変動する可能性があることを意味します。
しきい値プロファイルの「説明」を入力し、「保存」をクリックします。
|
注意: KPIによって使用されているしきい値プロファイルを削除することはできません。 |
1.5項「環境のカスタマイズ」で説明されているとおり、ユーザーはセッションで使用される書式設定をカスタマイズできます。小数点に使用する文字、3桁区切りに使用する文字、および使用する日付書式を指定できます。管理者が、システム全体にわたるこれらの設定のデフォルト値を指定することもできます。それには、「システム」→「メンテナンス」→「書式設定プリファレンス」の順に選択します。
RUEIによって報告されるクライアントの場所の情報は、IPアドレスとネットマスクの特定の組合せに関連付けられている地理上の場所が指定されている事前定義済の表から導出されます。
この表に保持されている情報がレポートの要件を満たさない場合(不十分または不適切)、レポートの際に使用される例外を定義することができます。IPアドレスの場所の例外を定義するには、次の手順を実行します。
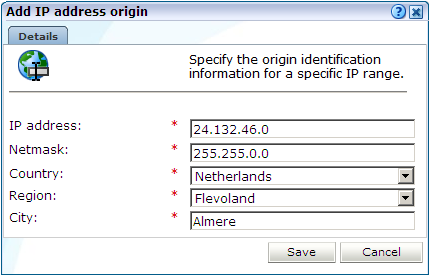
「構成」、「一般」、「IPアドレス・オリジン」の順に選択します。このオプションは、ITの完全なアクセス権限を持つユーザーのみが使用できます。現在定義されているIPアドレスの場所の例外がリストされます。「追加」をクリックして新しい例外を定義するか、既存の例外をクリックして変更します。図12-26に示すダイアログが表示されます。
ダイアログのフィールドを使用して、事前定義済のIPアドレスの場所に対する例外を指定します。次に、「保存」をクリックします。
重要:
指定するIPアドレスとネットマスクの組合せは、一意である必要があります。監視中のトラフィックのクライアントIPアドレスがIPアドレス/ネットマスクの複数の組合せに一致する場合は、レポートにはサブネットの範囲が最も小さい組合せが使用されます。
オプションで、「アップロード」をクリックすると、現在定義されているIPアドレスの場所の例外に、例外のリストをマージすることができます。アップロードするファイルは、1行が1エントリである必要があり、情報のフィールドはタブで区切られている必要があります。ファイルに、既存の例外に対する定義(つまりIPアドレス/ネットワークの同じ組合せ)がある場合、既存の例外が上書きされます。また、アップロードするファイルの各フィールドは、表12-3に示す要件を満たしている必要があります。
表12-3 アップロードしたファイルの要件
| フィールド | 要件 |
|---|---|
|
IPアドレス |
カンマ区切りの4つのフィールドで構成されます。各フィールドは、0から255の整数です。 |
|
サブネット・マスク |
カンマ区切りの4つのフィールドで構成されます。各フィールドは、0から255の整数です。ただし、0から255の範囲でも有効ではない数があります。 |
|
国番号 |
ISO 3166-1による2文字の有効な国コード(「AL」など)。サポートされている国コードの完全なリストは、次の場所にあります。
|
|
地域コード |
MaxMindデータベース(
|
|
市区町村名 |
このフィールドは、空白にすることはできませんが、それ以外の要件はありません。 |
RUEIでは、強制オブジェクトはページとしてではなく常にオブジェクトとして記録されます。これは、レスポンス時間の長さや、レポートされるエラーに関係ありません。強制オブジェクトに使用されるデフォルトのファイル拡張子は、表12-4のとおりです。
表12-4 デフォルトの強制オブジェクトのファイル拡張子
| 拡張子 | 拡張子 | 拡張子 |
|---|---|---|
.bmp |
.class |
.css |
|
|
.doc |
.gif |
.ico |
.jar |
.jpeg |
.jpg |
.js |
.mid |
.mpeg |
.mpg |
.png |
.ppt |
.properties |
.swf |
.tif |
.tiff |
.xls |
特定のファイル拡張子を持つオブジェクトを、強制オブジェクトとしてみなすかどうかを制御できます。次を実行します。
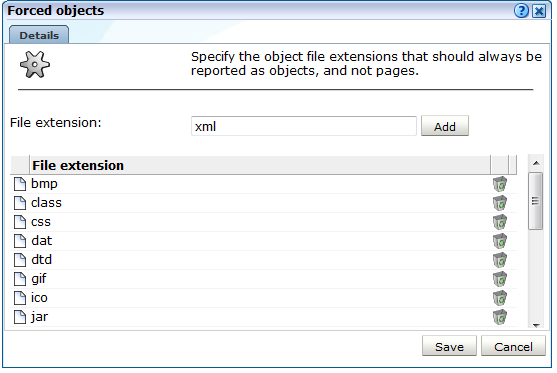
「構成」、「一般」、「詳細設定」、「URLの処理」、「強制オブジェクト」の順に選択します。図12-27に示すダイアログが表示されます。
強制オブジェクトとして扱うオブジェクトのファイル拡張子を指定します(ピリオドは不要)。準備ができたら、「追加」をクリックします。ファイル拡張子が、表示されているリストにただちに追加されます。オブジェクトのファイル拡張子をリストから削除するには、リストのすぐ右にある「削除」をクリックします。次に、「保存」をクリックします。
定義された強制オブジェクトのファイル拡張子のリストの変更はすぐに有効になるので注意してください。
ネットワーク・トラフィックをより効果的に監視するために、Webサイトへのトラフィックのどの程度がWebクローラ(スパイダやロボットなど)に関連付けられているかを把握することが必要な場合があります。この場合、ロボットのユーザー・エージェントの元を識別するための一致内容を制御できます。ロボット・トラフィックは、クライアント・ブラウザ・ディメンション経由でレポートされることに注意してください。次を実行します。
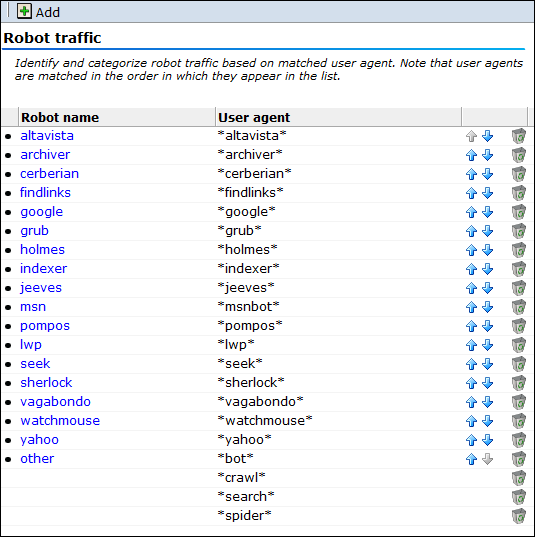
「構成」→「一般」→「詳細設定」→「ロボット・トラフィック」の順に選択します。現在定義されているロボット識別スキームが表示されます。例を図12-28に示します。
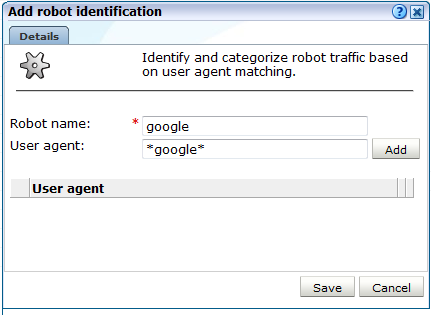
「追加」をクリックします。図12-29に示すダイアログが表示されます。
トラフィックをロボット・トラフィックとしてレポートする必要のあるユーザー・エージェント名、および報告元にする名前を指定します。各ユーザー・エージェントで、「追加」をクリックします。次に、「保存」をクリックします。図12-28に示す画面に戻ります。
「上に移動」および「下に移動」アイコンを使用して、リストの項目の順序を制御します。ユーザー・エージェントの一致はリスト内での出現順に行われることに注意してください。
ロボット・トラフィック除外
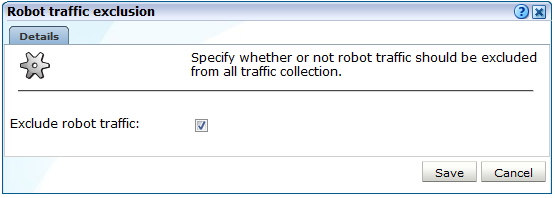
ロボット・トラフィックの識別のみでなく、レポート・トラフィックからの除外も指定できます。次を実行します。
「構成」→「一般」、「詳細設定」、「クライアントベースのトラフィック除外」の順に選択し、「ロボット・トラフィック除外」をクリックします。図12-30に示すダイアログが表示されます。
「ロボット・トラフィックの除外」チェック・ボックスを使用して、前述の指定したユーザー・エージェントに一致するトラフィックをレポートするかどうかを指定します。デフォルトではレポートされます。
原則では、監視中のすべてのトラフィックがレポートされます。ただし、特定のクライアントにより生成されたトラフィックを、収集から除外することができます。これは、内部ユーザーから大量のトラフィックがレポートされている場合などに便利です。また、12.17項「ロボット・トラフィックのレポートの制御」で説明するように、ロボット関連トラフィックのレポートを除外できます。
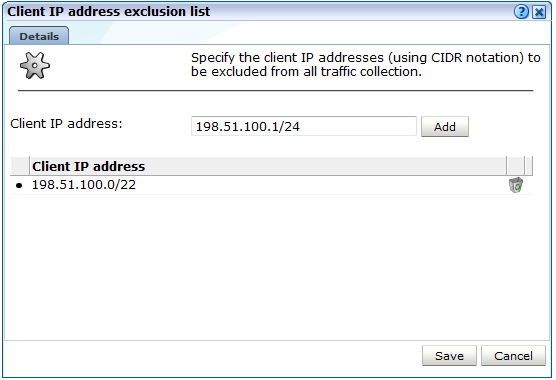
クライアント・トラフィックの収集を除外するには、次の手順を実行します。
「構成」→「一般」→「詳細設定」→クライアント・トラフィックの除外の順に選択します。「クライアントIPアドレスの除外リスト」をクリックします。図12-31に示すダイアログが表示されます。
トラフィックを監視しないクライアントのIPアドレスを指定します。CIDR形式で指定する必要があることに注意してください。各アドレスで、「追加」をクリックします。次に、「保存」をクリックします。
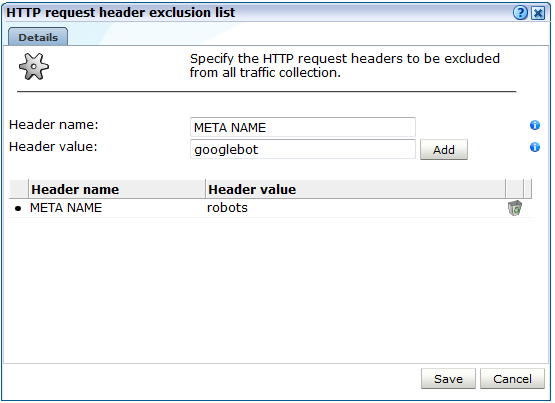
または、リクエストされたページのヘッダー情報のコンテンツに基づいて、クライアント・トラフィックのレポートを除外することも可能です。HTTPリクエスト・ヘッダーの除外リストをクリックします。図12-32に示すダイアログが表示されます。
リストに追加するヘッダーの名前=値ペアを指定します。それぞれのペアで、「追加」をクリックします。次に、「保存」をクリックします。
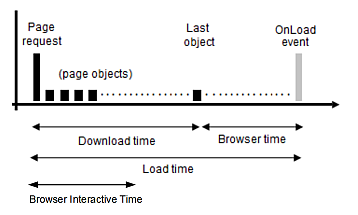
リクエストしたページがブラウザ内でユーザーに提供されるまでの時間は、次のとおりです。
ページ・ダウンロード時間は、配信される最初のページ・オブジェクト(通常はページ・リクエスト)から最後のページ・オブジェクトまでの経過時間です。
ページ・ブラウザ時間は、最後のページ・オブジェクトが配信されてから、クライアント側のインストゥルメンテーションによりレポートされたページ・ブラウザの完了時間までの経過時間です。クライアント側のインストゥルメンテーションは、ブラウザJSライブラリによって定義されます(8.3.1項「ブラウザJSライブラリ設定の定義」を参照)。
この期間は、WebページにJavaScriptコードが大量または複雑に含まれている場合や、Flashなどのブラウザ・プラグインが実行されている場合には非常に長くなることがあります。すべての主要なブラウザでは、ページの可用性はonLoadイベントの実行によって示されます。図12-33を参照してください。
ナビゲーション・タイミングが有効になっている場合、次のナビゲーション・タイミングが使用可能です。
ページ・ブラウザ・インタラクティブ時間: これは、ユーザーがページのアイテムをクリックできる(ページがインタラクティブになる)までの時間です。
ナビゲーション・タイミングの例は、図4-4を参照してください。
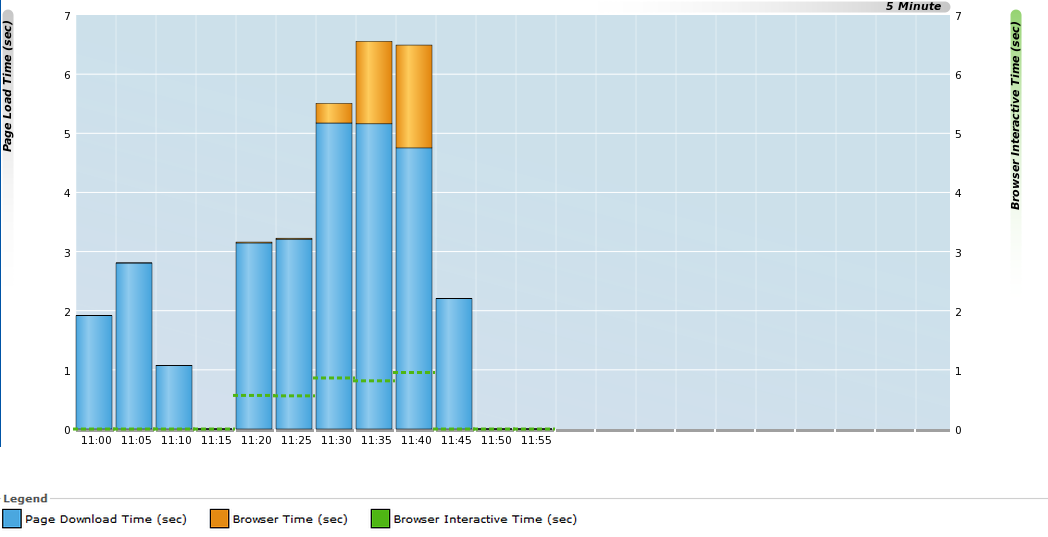
ページ・ダウンロードおよびブラウザ時間の表示
ページ・ダウンロード、ブラウザ時間およびブラウザ・インタラクティブ時間に関する情報は、ページ・ロード時間のブレークダウン・ビューに表示されます。例を図12-34に示します。
ブラウザJSライブラリの定義の詳細は、8.3.1項「ブラウザJSライブラリ設定の定義」に記載されています。