 Overview
OverviewThis chapter provides an overview of EPM and discusses:
EPM Architecture.
Extract, Transform, and Load (ETL) in EPM .
Operational Warehouse - Staging (OWS).
Operational Warehouse - Enriched (OWE).
Multidimensional Warehouse (MDW).
EPM Foundation Toolset.
PeopleSoft EPM Analytical Applications.
PeopleSoft EPM Warehouses and Reporting.
OverviewPeopleSoft EPM is a comprehensive, integrated analytic business solution designed to increase the efficiency of your organization. PeopleSoft EPM helps your organization achieve operational excellence by providing insight into the information you need to drive predictability, accountability, and manage operational risk. EPM enables you to produce detailed activity analyses and resource plans, understand the cause-and-effect relationship between cost and behavior, organize strategic thinking and performance measurement, use continuous, collaborative forecasting to manage the plan and budget in real-time, and clearly communicate strategy and success measures.
EPM is supported by data warehouses, related data models, robust infrastructure and metadata, and the EPM Foundation toolset. EPM provides all the necessary tools to gather and manage data from PeopleSoft, legacy, and external data sources, enrich that data, and store it in an intuitive analytic context for you to analyze in a variety of ways and at a variety of levels. EPM enables you to deliver a single, accurate view of information across your organization.
PeopleSoft EPM Architecture
PeopleSoft EPM Warehouses and Analytical Applications are built on a foundation of specialized data warehouses, target warehouse tables, ETL jobs, metadata, and other prepackaged content that enable complex analysis and reporting of your data.
EPM target warehouse tables provide a way to consolidate and store your source transaction data. EPM target warehouse tables reside in two high-level data warehouse structures:
the Operational Warehouse (OW)
the Multidimensional Warehouse (MDW)
The Operational Warehouse can be further divided into the Operational Warehouse - Staging (OWS) and the Operational Warehouse - Enriched (OWE).
Each warehouse structure has its own set of specialized target warehouse tables that are unique to that structure. For example, the Operational Warehouse - Enriched (OWE) structure stores enriched data that is arranged in a normalized format to promote complex analytics. And the Multidimensional Warehouse (MDW) structure stores data that is arranged in a denormalized format (dimensional schema) for enhanced reporting capabilities.
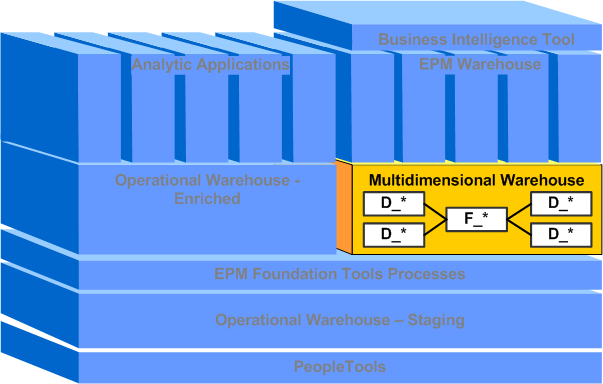
The following graphic illustrates the various components comprising the EPM architecture and how each component relates to the others, including shared components which act as the foundation for both the EPM Warehouses and Analytical Applications.
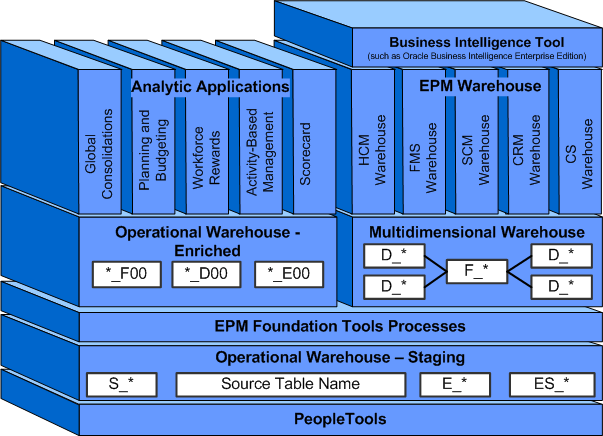
EPM architecture
The dual data warehouse architecture helps to:
Isolate and channel specific source data to the appropriate data warehouse structure for individual enrichment and modeling.
PeopleSoft provides extract, transform, and load (ETL) jobs to extract information contained in your source systems, load it into the Operational Warehouse - Staging (OWS) structure, and migrate that data to the Operational Warehouse - Enriched (OWE) and the Multidimensional Warehouse (MDW) structures. And because the warehouse structures are logically separated, the ETL jobs can isolate and channel specific source data to the OWE or the MDW.
Facilitate specialized, or tailored, data enrichment for your source data.
PeopleSoft provides EPM Foundation tools and processes (a set of specialized tools, processes, and metadata) that prepare and enrich your source data for the EPM Warehouses and Analytical Applications.
The delivered target warehouse tables, ETL jobs, Foundation tools, and other packaged content work together to provide the underlying infrastructure on which the EPM Warehouses and Analytical Applications are built. Detailed information regarding the OWS, OWE, MDW, and EPM Foundation tools can be found in this chapter.
Note. EPM data warehouse structures refer to the OWS, OWE, and MDW, whereas EPM Warehouses refer to the PeopleSoft packaged warehouse solutions available for licensing, such as the Campus Solutions Warehouse and the Human Capital Management Warehouse.
Definition of a Data Warehouse
A textbook definition of a data warehouse is: a copy of transaction data specifically structured for query and analysis.
Transactional database applications have been widely used by the corporate world for over 30 years. Although data has been entered into dedicated transaction applications for decades, it has become apparent that extracting data from these systems for analytic purposes can be cumbersome and difficult.
Data warehousing is the process of taking data from legacy and transaction database systems and transforming it into organized information in a user-friendly format to encourage data analysis and support fact-based business decision-making.
A data warehouse is a central, integrated database that contains data from one or more operational sources and archive systems in an organization. It contains a copy of transaction data that is specifically structured for query analysis.
The mission of the data warehouse is to publish an organization's data assets to most effectively support decision-making. Because the data warehouse is a decision-support system, the main criterion of success is whether the data warehouse contributes to the most important decision-making processes in the organization.
See Also
Operational Warehouse - Staging (OWS)
Multidimensional Warehouse (MDW)
Extract, Transform, and Load (ETL) in EPM
PeopleSoft has an original equipment manufacturer (OEM) agreement with IBM WebSphere to supply extract, transform, and load (ETL) technology that supports source data acquisition and data movement within EPM . The ETL tool, IBM WebSphere DataStage, is delivered with EPM.
PeopleSoft uses IBM WebSphere DataStage to deliver prepackaged ETL jobs that extract information contained in PeopleSoft source systems, load it into the Operational Warehouse - Staging (OWS), and migrate that data to the Operational Warehouse - Enriched (OWE) and the Multidimensional Warehouse (MDW). But ETL jobs do more than migrate data; they also identify data for extraction and ensure the consistency and validity of your data. Because the ETL jobs are so versatile, separate tools and engines that extract, stage, and move data are not necessary.
The following graphic illustrates the various components comprising the EPM architecture and how data flows from source systems to the Operational and Multidimensional warehouses via the ETL process.
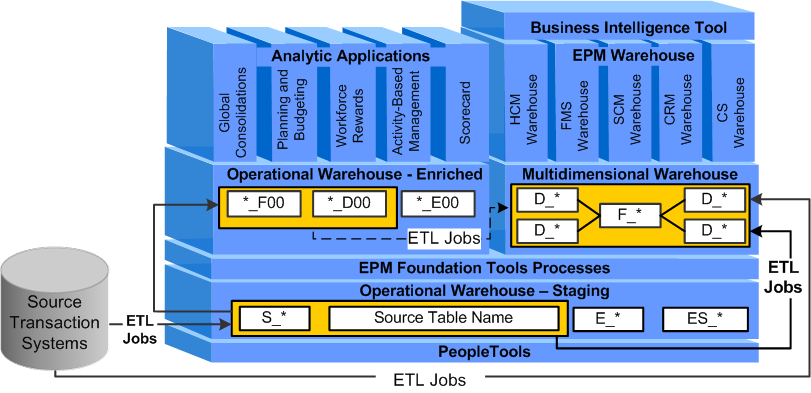
ETL process in EPM
As depicted in the diagram, source transaction data is extracted into OWS tables and migrated across warehouse layers using the aforementioned ETL jobs. Also, source data is sometimes extracted directly into the MDW.
You can use IBM WebSphere DataStage to build custom jobs for mapping your data into EPM . However, PeopleSoft does not support custom jobs.
Detailed information regarding the ETL process can be found in the ETL section of this PeopleBook.
See Preparing to Load Source Data Into EPM.
Operational Warehouse - Staging (OWS)
The OWS structure is one of two subcomponents that comprise the Operational Warehouse. The OWS acts as an entry-point for your source transaction data into EPM and can house data from one or more of your PeopleSoft, legacy, or external source systems. The main function of the OWS is to provide a platform to offload, consolidate, and stage your source transaction data in preparation for enrichment.
The following graphic illustrates the OWS component of the EPM architecture and the target tables that are present in the OWS.
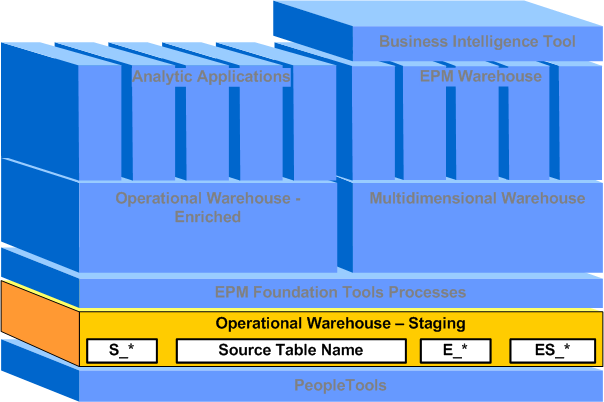
Operational Warehouse - Staging (OWS)
Source data is extracted into the OWS using prepackaged ETL jobs and loaded into target staging tables. No transformations are performed on your source data during this process and the system maintains the same source-level of granularity for your data. Source tables are extracted into the OWS, including all logically related tables, to ensure your source data is semantically complete in EPM. For example, a table extracted into the OWS may have an associated related language table in the source system. The related language data from the associated table is also extracted into the OWS to maintain completeness and data integrity. Data stored in the OWS is used as input for the Operational Warehouse - Enriched (OWE) and the Multidimensional Warehouse (MDW) structures.
Note. The OWS does not contain reporting tables nor prepackaged reports built on the core OWS target tables.
 OWS Core Target Tables
OWS Core Target Tables
OWS core target tables contain data extracted from PeopleSoft source systems. OWS target tables are permanent tables (as opposed to temporary tables), and can store historical data. However, it is not the recommended location for historical data as the tables can be purged from time to time depending on your operational needs. The structure of the OWS target tables match the structure of the source transaction tables with the addition of a source system identification column (SRC_SYS_ID) , which enables you to track the origin of your data.
Note. Certain OWS target tables have specific non-key columns that can be "activated" as key columns if your business requirements necessitate it.
Sample OWS Target Table
The following is a sample OWS target table page shown in Application Designer.

OWS target table - ABS_CLASS_TBL
OWS Target Table Naming Convention
OWS target tables use the following naming conventions:
S_[source table name]
[source table name]
OWS Error Tables
The OWS contains error tables used in the data validation process. The data validation process uses ETL jobs to verify the integrity and completeness of the data entering OWE and MDW target tables. The validation process can perform dimension key validation (for example, verifying that customer ID fact value has a corresponding customer ID dimension value) and general key validation (for example, verifying the pre-fact customer ID in the OWS table has a corresponding customer ID in the OWE or MDW table), as well as ensure source business unit and setID are properly mapped to EPM values and source codes are properly mapped to EPM code values.
Data failing the validation process are sent to OWS error tables. It is important to note that the OWS error tables have a different structure than the error tables in the OWE and perform a very different function. The OWS error table mirrors the key structure and other columns of its corresponding data table and has additional fields to facilitate troubleshooting. The following OWS error table columns represent some of the columns provided for troubleshooting:
LOAD_OWS_SBR: The values for these columns are copied from the failing data row. The reason for copying values from the failed data row is that it provides vital load information such as batch ID and load timestamp for the data row.
Target Table: This column lists the target table for the job.
Failed data source table and column name: The source table and column from which the failing data originated. Knowing the name of the failed source data table is especially useful when the job loading the failed data contains a multi-source-table join.
Failed Data Value: The actual value that failed validation.
Lookup table and column name: The table and column against which the failed lookup was performed.
Detailed information regarding the data validation process can be found in the ETL section of this PeopleBook.
See Preparing to Load Source Data Into EPM.
Sample OWS Error Table
The following is a sample OWS error table page shown in Application Designer.

OWS error table - E_ABS_CLASS_TBL
OWS Error Table Naming Convention
OWS error tables use the following naming conventions:
PS_E_[OWS table name]
PS_ES_[OWS table name]
Operational Warehouse - Enriched (OWE)
The OWE structure is the second of two subcomponents that comprise the Operational Warehouse. The OWE stores enriched data that is arranged in a normalized format and mapped to warehouse business units (WBU). Enrichment can entail many transformations to your data, including (but not limited to) conversion to a common currency, common calendar, or a common ledger, or aggregating data to a common warehouse business unit. The PeopleSoft Analytical Applications use the enriched data in the OWE to perform analysis and reporting.
The following graphic illustrates the OWE component of the EPM architecture and the target tables that are present in the OWE.
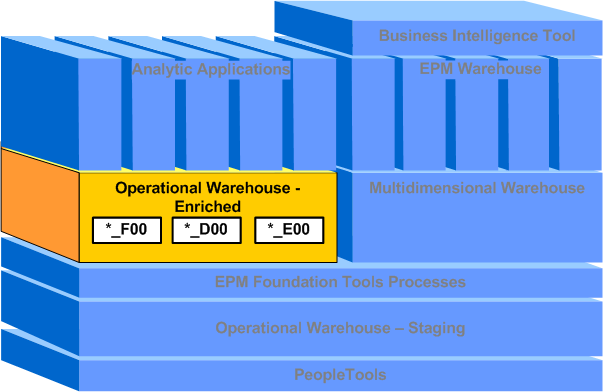
Operational Warehouse - Enriched (OWE)
Data is extracted into the OWE using prepackaged ETL jobs and loaded into target dimension (D00) and fact (F00) tables. The structure of these tables are quite different from the OWS tables because they are arranged in a normalized format and organized data around warehouse business units. In addition, OWE tables are augmented with subrecords which help facilitate the ETL process and tracking data lineage. OWE tables store data permanently and can maintain history (as opposed to temporary tables which remove data at the end of an ETL job).
Tools and Processes Associated with the OWE
EPM is delivered with several tools and processes that enable you to enrich and manage the data stored in the OWE. The following are some of the tools and processes used only with the OWE:
Performance ledger template setup.
Detail ledger setup.
Model and scenario setup.
Roll-up processing.
Profit manager.
EPM object auditing.
Mass validate processing.
Mass compile processing.
Tree utility setup.
Data manager processing.
Allocation manager processing.
OWE Dimension (D00) Tables
An OWE dimension table provides additional attributes about a fact for greater flexibility in reporting. Dimensions are derived from operational applications and are cleansed and transformed during data migration. Examples of dimension tables include: product, customer, channel, department, personal data, and accounts. Some of the fields associated with an OWE dimension table are:
SetID: Key column.
DIMENSION_ID: Key column.
EFFDT: This is the same date as the source. If an EFFDT or an alternative date, such as a date time stamp, does not exist, the system creates one and sets it to the date the dimension data is loaded.
EFF_STATUS.
KEY Fields from the source table.
SET CONTROL FIELD. This is BUSINESS_UNIT.
RELATED LANGUAGE RECORD. This is the same with an extension of _LNG.
Sample OWE Dimension Table
The following is a sample OWE dimension table page shown in Application Designer.
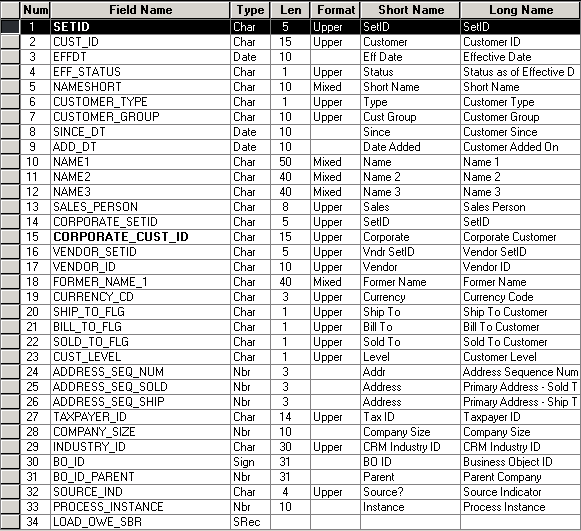
OWE dimension - CUSTOMER_D00
OWE Dimension Table Naming Convention
OWE dimension tables use the following naming convention, [table name]_D00
OWE Fact (F00) Tables
An OWE fact table contains measures for analyzing performance. Some of the fields associated with an OWE fact table are:
BUSINESS_UNIT: This field enables the fact data to be shared across different dimensions, as they are based on SetIDs.
FACT KEY.
ASOF_DT: This is for non-cumulative facts (for example, account balance).
PF_TRANS_DT: This is for cumulative facts (for example, billing transactions).
All KEY Fields: These are required for uniqueness.
DEFAULT VALUES include:
BUSINESS_UNIT: This will have a default table set to OPR_DEF_TBL_FS and a default field set to BUSINESS_UNIT.
EFFDT: This will have a default set to %DATE.
EFF_STATUS: This will have a default set to A.
TRANSLATE VALUES: These values, if any exist, must be set to the XLATTABLE.
PF_TRANS_DT: This is set to the source record's transaction date. In addition, the source transaction date field is included in the data warehouse fact table.
Sample OWE Fact Table
The following is a sample OWE fact table page shown in Application Designer.
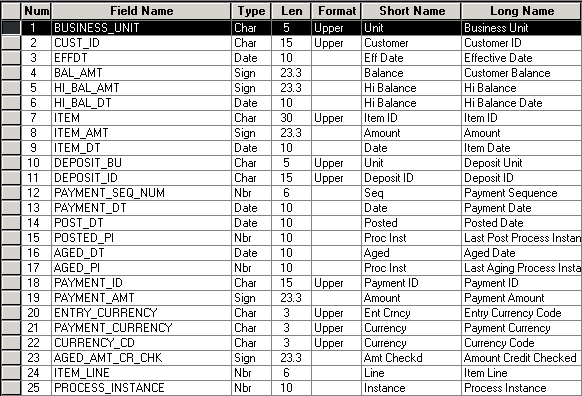
OWE fact - ACCT_REC_F00
OWE Fact Table Naming Convention
OWE fact tables use the following naming convention, [table name]_F00
OWE Temporary Tables
OWE temporary tables support parallel processing. A temporary table layout and key structure differs from its respective fact or dimension table in that the organizational unit (setID or business unit) and the effective date are not keys.
EPM is delivered with three sets of temporary tables. You can define additional sets of tables when needed. The project EPM_TEMP_TABLES contains one instance of every temporary table, enabling you to create new temporary table suites, if necessary. A temporary table layout and key structure differs from its respective fact or dimension data warehouse table in that the organizational unit (setID or business unit) and the effective date are not keys.
Note. If you must create more temporary tables than the ones delivered with PeopleSoft EPM, see the delivered project, EPM_TEMP_TABLES. It contains one instance of every temporary table, enabling you to create new temporary table suites, if necessary.
See Creating Additional Instances of Temporary Tables for Record Suites.
OWE Temporary Table Naming Convention
OWE temporary tables use the following naming convention, [table name]_T
Specialized Reporting Tables
The OWE features tables that have been designed specifically to enhance reporting capabilities. Those tables are the performance ledger table (PF_LEDGER_F00), performance journal table (PF_JRNL_F00), and the performance statistics table (PF_STAT_F00). Creating specialized tables in this manner enables you to move away from storing all of your accounting data in your general ledger to make your general ledger perform as it should—as a method for compliance reporting only.
The performance journal and performance ledger tables are described in more detail later in this PeopleBook.
Performance Ledger Table
The performance ledger table (PF_LEDGER_F00) is a central fact table within EPM. The performance ledger table is an accumulation of monetary amount facts over a period of time. The primary function of the performance ledger table is to support PeopleSoft EPM reporting. The PF_LEDGER_F00 is the source for one of the data marts.
Note. The performance ledger table should not be confused with a general ledger from an online transaction processing (OLTP) system. The performance ledger contains all information mapped from a general ledger and enriched through one (or more) of the PeopleSoft EPM engines.
Information that has been processed through an PeopleSoft EPM engine, for instance the ABM engine or Data Manager, is stored in a temporary performance journal staging table (PF_JRNL_T).
The PF Edit engine enables you to verify the data in the temporary journal table and moves valid data to the final table, the PF_JRNL_F00. Errors are placed in the PF_JRNL_E00, the error table for the journal table. The PF Post takes the detailed information from the performance journal table, aggregates it to the desired level of summarization and posts it to the PF_LEDGER_F00 for reporting.
PeopleSoft EPM reporting tools support multidimensional analysis based primarily on profitability dimensions such as customer, product, and channel. You can use one, two, or more of these dimensions within your models, or configure the application to add more dimensions, or change the existing ones. No matter which dimensions you select, however, you need to consider how to populate the performance ledger table with meaningful multidimensional data.
Performance Journal Table
The performance journal table (PF_JRNL_F00):
Contains data that is not yet summarized.
Is a fact table, or multiple fact tables, within EPM.
Is a collection of batches of amount facts staged for validation and posting to the performance ledger table.
Supports drill down from reports produced against the performance ledger table.
The PF Edit engines moves data to the performance journal fact table. The PF Post process accumulates valid transactions from the performance journal table, and inserts summarized rows into the performance ledger. There is a "many to one" relationship between the performance journal and the performance ledger tables.
Performance Statistics Table
The performance statistics table (PF_STAT_F00) is similar to the performance ledger table (PF_LEDGER_F00) in its layout.
OWE Error Tables (for Profit Manager only)
The OWE contains error tables used to identify flawed data in certain OWE target tables. There are a small number of delivered OWE error tables and they are used only for Profit Manager. Profit Manager uses specific business rules to validate and format data in its related OWE target tables. If the business rules are not met, then the flawed records are written to an OWE error table and a message describing the error is written to a detail error message table (TSE table). If your load results in errors, you can use PF Modification to correct the errors. You can correct the errors using the PeopleSoft Application Designer and then migrate the corrected tables to the target. The following OWE error tables are delivered:
BP_LED_BUDG_E00
BP_LED_E00
BP_LED_KK_E00
BP_LED_PROJ_E00
GC_JRNL_MGT_E00
LEDGER_E00
PF_JRNL_E00
See Setting Up and Using Profit Manager.
Sample OWE Error Table
The following is a sample OWE error table page shown in Application Designer.
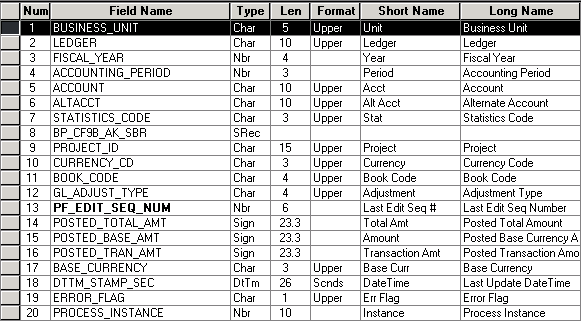
OWE error table - BP_LED_E00
OWE Error Table Naming Convention
OWE error tables use the following naming convention, [table name]_E00
Multidimensional Warehouse (MDW)
The Multidimensional Warehouse is the third data structure in EPM. The following graphic illustrates the MDW component of the EPM architecture and the target tables that are present in the MDW.
Multidimensional Warehouse (MDW)
The MDW stores dimensionalized data that is grouped into one or more business processes, better known as a dimensional schema, used for business intelligence and ad hoc reporting. The data is stored in a star schema (a fact table associated with a series of dimension tables) and generally contains data loaded from the OWS.
The star schema arrangement depends entirely on primary key and foreign key relationships. A primary key is a column (or columns) in a dimension table whose values uniquely identify each row in the table. Primary keys enforce entity integrity by uniquely identifying entity instances. A foreign key is a column or columns in a fact table whose values match the primary key values of a given dimension table. This way references can be made between a fact and dimension table. Foreign keys enforce referential integrity by completing an association between two entities.
Note. MDW dimensions use a surrogate key, a unique key generated from production keys by the ETL process. The surrogate key is not derived from any data in the EPM database and acts as the primary key in a MDW dimension. See the next section for more information on surrogate keys in the MDW.
The following graphic provides an example of a star schema and its primary and foreign key relationships:
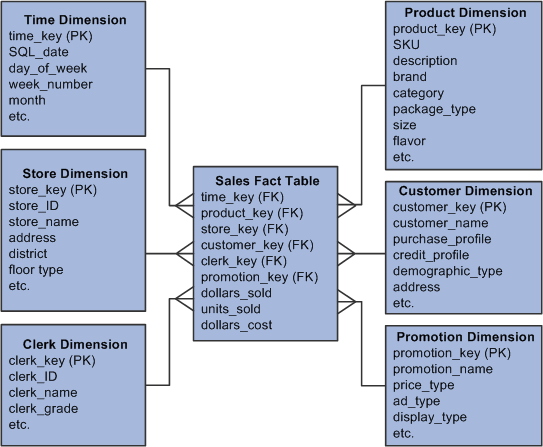
Dimensional Model Example
Although data loaded into the MDW is primarily derived from the OWS, there are exceptions to this rule. Profitability and Global Consolidations data for the Financial Management Solutions (FMS) Warehouse is loaded into the MDW from the OWE.
External survey data for the HCM Warehouse is loaded into the MDW from the OWE.
Online Marketing data is loaded into the MDW directly from the source system, and bypasses the Operational Warehouse entirely.
Surrogate Keys
Surrogate keys provide a means of defining unique keys whose values, with the exception of the Time and Calendar dimensions, are anonymous—that is, the value of a surrogate key has no significance to the application using it and is strictly an artificial value. The system uses surrogate keys specifically as a means of joining structures. To speed up query access, the MDW resolves PeopleSoft-specific programming constructs, such as SetIDs and effective dates and replaces them with surrogate IDs as key columns. Surrogate keys have no relationship to the business or production key. Surrogate keys are present in dimension tables as the primary key and in fact tables as foreign keys to dimensions. However, the dimension record retains the business key as an alternate-key attribute. Surrogate keys are four-byte integers and their size does not change even when production key changes in size.
Although surrogate keys usually do not have any "intelligence," that is, their value has no meaning, in certain situations, such as the Gregorian Calendar and Time dimensions, intelligent surrogate keys are used. These intelligent keys enable the ETL process to run more quickly by providing the option of avoiding a lookup on corresponding dimensions.
Surrogate key fields usually have the suffix _SID (Surrogate ID).
Surrogate Keys and the ETL Process
Surrogate keys are generated from production keys using the DataStage routine KeyMgtNextValueConcurent(), which receives an input parameter and a name identifying the sequence. The surrogate key can be unique per single dimension target (D) or unique across the whole (W) multidimensional warehouse. This process is enabled by the environment parameter named SID_UNIQUENESS. The value for this parameter is provided at run time. If the value is D, then this routine is called with a dimension job name for which a surrogate key must be assigned and it returns the next available number. If not, the routine is called with EPM as the sequence identifier.
You do not have to take any action to create surrogate keys; they are generated during the ETL process within the aforementioned DataStage routine. The DataStage routine retrieves the next surrogate key value and assigns it to the surrogate key that it is currently creating. When the ETL process copies a dimension row from the source system into the MDW, the ETL process performs a lookup on the dimension table. If the dimension row (with same business keys) does not exist in the dimension table, the process inserts a row with a new surrogate key value. If the dimension row already exists in the dimension table, the process updates the existing row with the incoming row value. When the ETL process copies a fact row from the source system into the MDW, for each dimension key in the fact row, the system performs a lookup on the dimension table and retrieves the corresponding surrogate key value. This surrogate key is the foreign key value in the fact row in the MDW. If the system does not locate a dimension value in the fact row in the dimension table, that is a data exception and an error results.
Surrogate keys provide benefits such as:
The ability to easily and structurally conform a dimension when being sourced from multiple systems.
Disassociation from operational system changes.
Because surrogate key generation is controlled by the warehouse, it is not influenced by operational system changes.
The ability to handle unspecified or missing key values.
A graceful mechanism to handle changes in history.
Multiple versions of a dimension can be maintained with different surrogate (primary) keys, yet with the same business (identifying) key.
Performance enhancement of queries, because a surrogate key is a single column numeric key, thus the joins using surrogate keys are faster than ones using multi-column business keys.
Audit Fields
Audit fields track extract, transform, and load (ETL) loading information, such as when the row was loaded or last modified or the batch in which the row was loaded. This information is included in a subrecord. The subrecord added to MDW tables is called LOAD_MDW_SBR. Subrecords are always added at the end of a record; no fields exist after this subrecord in any table. The following example shows a typical LOAD_MDW_SBR subrecord.
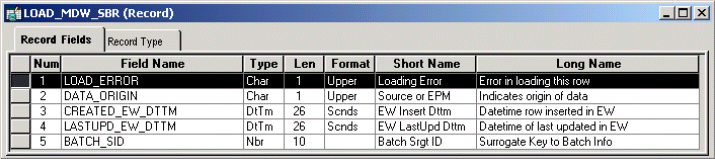
LOAD_MDW_SBR record example
Data Aggregation
Tables in the MDW contain source data at the same granularity as the source system. Required data aggregation is carried out at run time by the business intelligence tool. This allows for better control of aggregation strategies by the business intelligence tool, because aggregation requirements vary from customer to customer.
MDW Dimension Tables
Dimensions are sets of related attributes that you use to group or constrain detailed information that you measure in your data mart. Dimensions are usually text (in character data type), relatively static, and often hierarchical.
Dimension tables contain surrogate keys as the primary key and are a single column key containing only the surrogate key column. Surrogate keys usually have _SID (surrogate ID) appended to the field name. Dimension tables retain source system business key fields as non-key attribute columns in the dimension table. However, these are not used for joins with fact tables. For example, in the Customer dimension, the original business key field CUST_ID is retained, if it exists in the source table, but is no longer included in the key. The SetID is also retained, if it exists in the source table, as a nonkey attribute; the value contained in the SetID is the same as in the source system.
If a dimension is SetID-based, the MDW table contains the source SetID and the performance (PF) SetID, which is named SETID.
If a dimension contains a description text, a related language table is often defined for this dimension. The ETL process populates this table if a customer requires multilanguage processing. The key for this table is the surrogate key ID, plus the language code field, LANGUAGE_CD, which contains the code for the additional language.
Note. You can find more information about multilanguage processing for the multidimensional warehouse in your EPM Warehouse specific PeopleBook (for example, the PeopleSoft Campus Solutions Warehouse PeopleBook).
Dimensions such as Account, Customer, Department, or Person are examples of shared dimensions. Shared dimensions are either exactly the same—including key structure—or an exact subset of another dimension; that is, shared dimensions are structurally identical every place in which they are used. Shared dimensions are used across all EPM warehouse products, such as the Campus Solutions Warehouse and the Financial Management Solutions Warehouse.
When using a shared dimension, the system consistently interprets attributes; hence rollups across data marts are possible and consistent. When a warehouse is provided data from multiple sources, a shared dimension is typically (but not always) built from multiple source structures. The following is a sample MDW shared dimension shown in Application Designer.
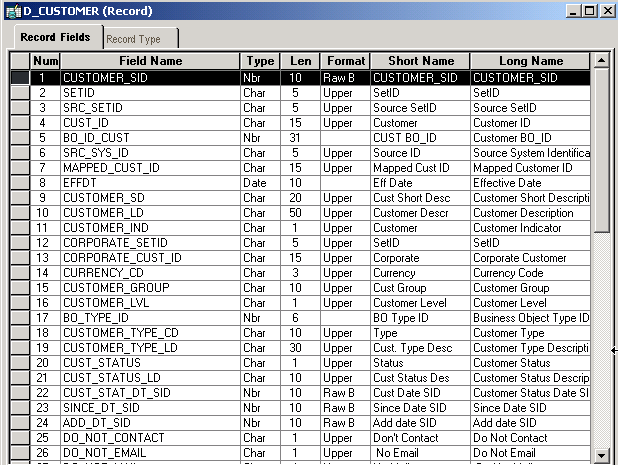
EPM conformed dimension
MDW Dimension Table Naming Convention
MDW dimension tables use the following naming convention: D_[table name].
MDW Fact Tables
MDW fact tables (F_*) contain numeric performance measurement data—such as quantity, sales, and revenue—that is used to build a data warehouse and its related reports. Facts help to quantify a company's activities. A fact is a typically an additive business performance measurement. That is, you can usually perform arithmetic functions on facts.
In a star schema, a fact table is the central table, each element of which is a foreign key derived from a dimension table. Dimension tables have a surrogate ID column that is the primary key of that dimension. A fact table may use these dimension surrogate IDs as foreign keys to the dimension table. In the dimensional model example graphic presented previously, the Sales fact table contains six foreign keys, each one matching a dimension surrounding the fact table.
Periodic Snapshot Fact Tables
Periodic Snapshots provide a view of the cumulative performance of the business at regular, predictable time intervals. Unlike a transaction fact table that loads a row of data for each event occurrence, the periodic snapshot fact table captures the event at the interval of a day, week, or month, and another capture at the interval of the next period, and so on. These periodic snapshots are stacked consecutively into the fact table. The periodic snapshot fact table often is the only place to easily retrieve a regular, predictable, trend view of the key business performance metrics.
Accumulating Fact Tables
Accumulating snapshots represent an indeterminate time span, covering the complete life of a transaction or discrete product. Accumulating snapshots almost always have multiple date stamps, representing the predictable major events or phases that take place during the course of a lifetime. Since many of these dates are not known when the fact row is first loaded, we must use surrogate date keys to handle undefined dates.
MDW Fact Table Naming Convention
MDW fact tables use the following naming convention: F_[table name].
EPM Foundation Toolset
EPM is delivered with EPM Foundation tools. These set of tools enable you to enrich, audit, and manage the rich content included with EPM with a high degree of automation. For example, the Clone Metadata tool enables you to quickly and easily create a duplicate copy of your existing metadata. EPM Foundation tools can be used with content included in the Operational Warehouse and the Multidimensional Warehouse.
The following graphic illustrates how the EPM foundation tools and processes fit into the overall EPM architecture.
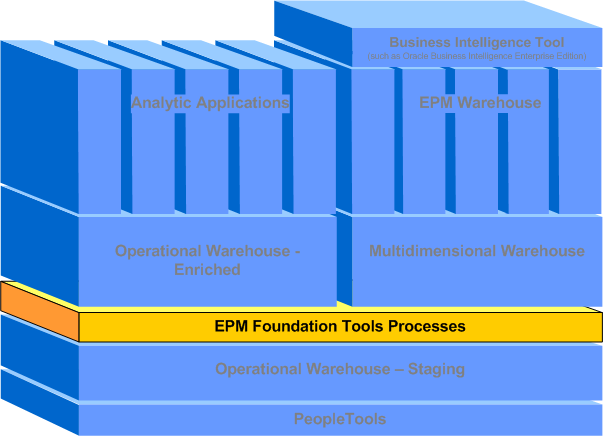
EPM Foundation
The following sections provide additional details about EPM Foundation tools.
Setup Tools
Implementing EPM requires that you specify parameters within the warehouse that reflect your organization's basic business processes and parameters. For example, you must define parameters for unit of measure, country, and accounting calenders in EPM .
EPM delivers several setup tools which enable you to quickly and easily setup basic information in the warehouse including unit of measure, multiple language and currency, and operator defaults.
See Setting Up EPM Business Rules.
Security Tools
EPM security enables you to set up data access at a variety of entry points and control access to meet your business needs, right down to an individual field. Security tools enable you to:
Use application security to control access to applications, menus, and objects. You can specify which applications are available to a group of users, which menus and EPM objects they can access.
Use row-level security, for example, to implement dimension-level access to particular products, customers, or key performance metrics. This ensures that highly sensitive data is protected.
You can also set up a specific security for the IBM WebSphere ETL tool.
Data Storage and Classification Tools
Implementing EPM involves configuring the system's structures to how your business operates. You can share common tables across reporting and analytical applications to minimize redundant data and system maintenance tasks.
Record metadata, for example, defines the first level of EPM metadata. It is used to identify and classify the tables that constitute the EPM data model. The record metadata identifies EPM tables as fact tables, fact reference tables, dimension tables, dimension reference tables, or transaction-dated tables. Each table is also classified to a specific data layer: the OWE or the MDW.
Tree manager provides an intuitive way to create, view, and maintain hierarchical definitions. An easy to understand user interface facilitates the creation and maintenance of trees. Tree mover enables you to moved PeopleSoft trees between different PeopleSoft application databases.
See Setting Up EPM Business Rules, Setting Up and Working with Metadata for the Operational Warehouse - Enriched.
Performance Management Related Tools
EPM utilizes shared components that provide functionality key to supporting high-volume analytical applications:
Reusable filters and constraints stored in the metadata enable you to define sets of rules that can be shared across applications.
Jobstreams streamline analytic processes and enable applications to run concurrently.
See Setting Up and Working with Metadata for the Operational Warehouse - Enriched, Streamlining Processing with Jobstreams.
PeopleSoft EPM Analytical Applications
EPM provides the applications necessary to analyze business situations, model business scenarios, and monitor performance. The following graphic illustrates how the Analytical Applications fit into the overall EPM architecture.
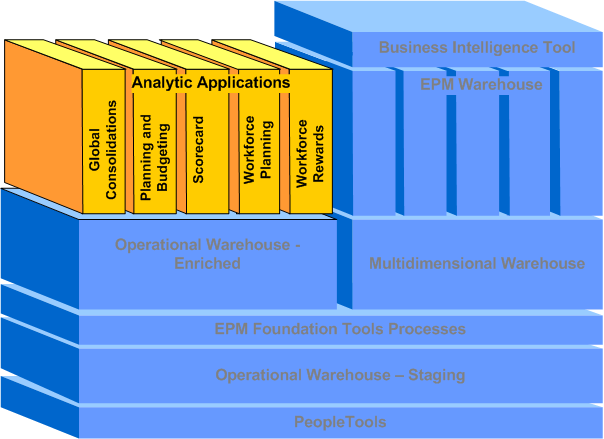
EPM Analytical Applications
PeopleSoft EPM analytical applications consist of a series of logically integrated dashboards, reports, scorecards, and models, which enable a wide range of users to access, analyze and act on integrated information within the context of a specific business processes, such as sales pipeline, accounts payable, or risk adjusted profitability analysis. These applications are built on normalized data from the OWE (rather than dimensionalized data from the MDW), and data is processed using the powerful Application Engine (AE) PeopleTool.
The analytical applications provide functional models for forecasting, trend analysis, and statistical analysis of your data to help drive decision-making within a business process. You model and analyze data using EPM PeopleSoft Internet Architecture (PIA) pages and application engines delivered with the analytical applications.
The EPM analytical applications enable you to:
Capture organization-wide financial and workforce information in a single data model.
Prepare and analyze plans in real time without having to move data between applications.
Create and revise forecasts based on data from previous planning scenarios.
View summary level information about your organization or drill back directly to transaction source system data.
Deliver information to all levels within the organization.
Continuously assess operational performance based on key performance indicators and historical trends.
Application Engine PeopleTool
The Application Engine is a PeopleTool that enables you to run and monitor SQL processing programs that process your data within the analytical applications. A program is defined in Application Designer and performs a specific business process. The program can consist of a set of SQL statements, PeopleCode, and program control actions that enable looping and conditional logic.
The Application Engine does not generate SQL or PeopleCode. It executes the SQL and PeopleCode included in an Application Engine action as part of a program. The Application Engine is designed for batch processing where data that must be processed without user intervention—for example, calculating salaries in payroll processing (although not printing the checks). Another example might be converting money from one currency to another.
PeopleSoft Delivered Analytical Applications
PeopleSoft delivers the following Applications:
PeopleSoft Activity-Based Management
PeopleSoft Application Fundamentals for Financial Services Industry
PeopleSoft Funds Transfer Pricing
PeopleSoft Global Consolidations
PeopleSoft Performance Management Portal Pack
PeopleSoft Planning and Budgeting
PeopleSoft Project Portfolio Management
PeopleSoft Risk Weighted Capital
PeopleSoft Scorecard
PeopleSoft Workforce Analytics Applications
PeopleSoft Workforce Planning
PeopleSoft Workforce Rewards
For more details on the application or applications you have licensed, please refer to the specific PeopleBook or PeopleBooks.
PeopleSoft EPM Warehouses and Reporting
The PeopleSoft EPM warehouses provide you with the tools and technology to manage your organization's information that is used for reporting and analysis. Each warehouse is divided into multiple subject areas, or data marts. Each data mart is aligned with a business process, which enables you to answer strategic questions essential to your organization's bottom line.
The following graphic illustrates how the EPM warehouses fit into the overall EPM architecture.
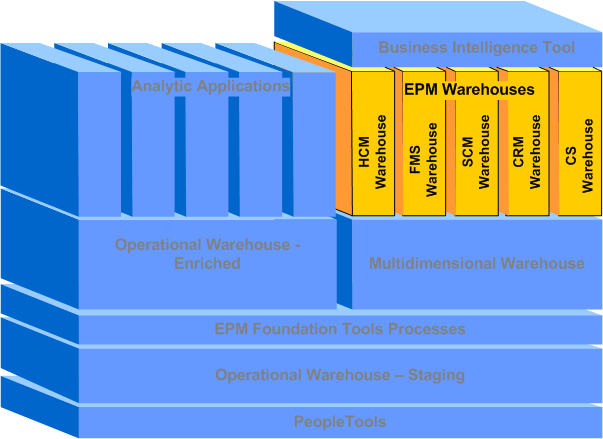
EPM Warehouses
PeopleSoft provides the following EPM warehouses:
Campus Solutions Warehouse
Customer Relationship Management (CRM) Warehouse
Financials Management Solution (FMS) Warehouse
Financials Warehouse for Public Sector and Higher Education
Human Capital Management (HCM) Warehouse
Supply Chain Management (SCM) Warehouse
Prepackaged Content
PeopleSoft delivers the following content with each EPM warehouse:
Extract Transform and Load (ETL) component
Infrastructure tables and tools
Security tables
Staging tables
Multidimensional Warehouse tables
Data Models
Measures
Reporting tables are built in the MDW to enable offloading of operational reports from your transactional systems. As part of your implementation, you need to consider which operational reports it makes sense to offload to the EPM warehouses.
The EPM warehouse PeopleBooks (such as the PeopleSoft Campus Solutions Warehouse PeopleBook) provide more details on the each of the EPM warehouses.